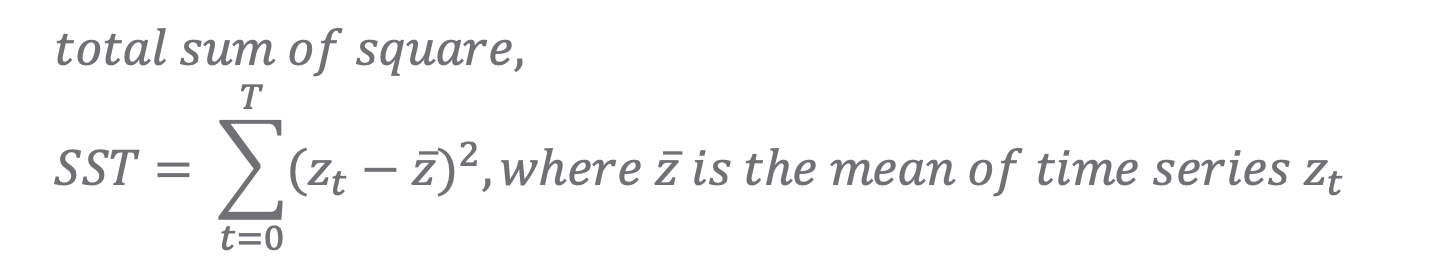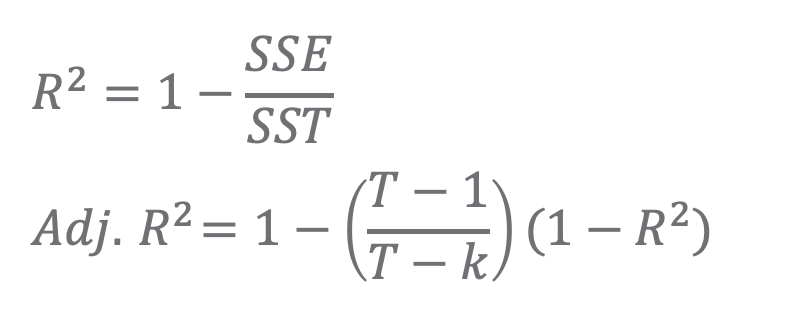그린 마일 (The Green Mile, 1999) 프랭크 다라본트 (Frank Darabont) 감독/ 각본 스티븐 킹 원작 톰 행크스, 마이클 클라크 덩컨 외 출연
영화 그린 마일 (The Green Mile, 1999)은 스티븐 킹의 소설을 원작으로 해서 프랭크 다라본트 감독이 만든 영화입니다. 20여년 전에 재미있고 인상깊게 봤었던 ‘쇼생크 탈출(The Shawshank Redemption, 1994)’과 ‘그린 마일(The Green Mile, 1999)’이 동일한 원작자와 감독에 의해서 만들어졌다는 것을 안 것은 올 해 초에 스티븐 킹의 ‘유혹하는 글쓰기’ 라는 책을 읽으면서 였습니다. 너무 놀랍지 않나요? 재능있는 소설가와 영화 감독의 만남이 인류에 선사할 수 있는 이런 멋진 선물이라니요!
20여년 전에 봤었던 그린 마일 영화는 포스터에 나오는 두 명의 영화 주인공(간수 톰 행크스와 죄수 마이클 클라크 덩컨) 얼굴과 슬펐었다는 느낌만 기억날 뿐이었구요, 저는 그린 마일 영화를 마치 처음보는 것처럼 새롭고 재미있게 봤습니다!(파우스트가 “망각”을 두고 신이 인간에게 주신 축복이라고 했던가요?!)
(* 주의 사항: 여기서 부터는 그린 마일 영화에 대한 내용이 나옵니다. 아직 영화를 안 보신 분은 스포일러 당하기 싫으시면 여기서부터 읽기를 삼가주시고, 영화를 다 본 후에 읽으시길 권합니다. 저는 분명히 경고 했습니당~ >_<*)
“Last Mile” 은 사형수가 사형을 당하기 전에 감옥에서 처형대까지 걸어가는 복도를 말한다고 해요. 영화에 나오는 사형수 감옥 E동은 복도가 녹색이어서 사형수가 마지막으로 걷게 되는 Last Mile을 “Green Mile”이라고 부른데서 이 영화의 제목이 나왔답니다.
이 영화를 보는데 있어서 7개의 주제로 풀어보았습니다.
(1) ‘쇼생크 탈출(The Shawshank Redemption, 1994)’과‘그린 마일(The Green Mile, 1999)’
그럼, 시작을 동일 원작에 동일 감독의 두 작품을 비교해보는 것으로 열어볼까요?
The Shawshank Redemption, The Green Mile
‘쇼생크 탈출’과 ‘그린 마일’ 두 영화 모두 감옥, 간수와 죄수를 주인공으로 하고 있고, 1900 년대 초중반의 미국을 배경으로 하고 있는 점은 비슷해요.
하지만 다른 점도 많이 있어요. ‘쇼생크 탈출’은 리얼리티적이고, 억울한 누명을 쓴 죄수(앤디, 팀 로빈스 분)를 주인공으로 해서 ‘자유(freedom)’에 대해 이야기하고 있습니다. 반면에 ‘그린 마일’은 환타지적인 장면이 여럿 나오고, 인간적인 면모를 지닌 간수(폴 에지콤, 톰 행크스 분)를 주인공으로 해서 ‘자비(mercy, kindness)’, 그리고 죄없는 죄수(존 커피, 마이클 클라크 덩컨 분)를 통해서 ‘기적, 죄와 구원’에 대해 이야기하고 있어요.
(2) 죄없는 죄수 John Coffey(J.C.)와 죄없는 어린양 Jesus Christ(J.C.)
병든 자를 치유하는 기적의 능력이 있는 존은 자신의 이름이 “커피(Coffee)”와 발음은 같고 스펠링은 다른 “John Coffey(J.C.)” 라고 천천히 또박또박 소개합니다. 이는 병을 치료할 뿐만 아니라 죽은 자도 살리시고, 죽음에서 부활하신 “예수 그리스도(Jesus Christ, J.C.)” 와 같은 이니셜을 염두에 두고 작가가 만든 이름일 것 같아요.
그 당시 가장 천대받던 흑인이었던 존이 감옥에 올 때 사형수로서 “Dead man walking” 이라는 모욕을 당합니다. 말구유에서 가장 낮은 자로 이 세상에 오신 예수님은 종교재판에서 신성모독이라는 죄명으로 “나사렛 예수 유대인의 왕” 이라는 모욕을 당하며 골고다 언덕을 오릅니다.
영화의 주인공 John Coffey와 Jesus Christ 모두 죄는 없지만 죄인(살인, 신성모독)의 신분이 됩니다. 그리고 결국에는 존은 다른 사람의 죄를 누명을 쓰고 물뭍은 스펀지를 머리 위에 얹고 감옥에서 전기의자에서 사형을 당하고, 예수님은 인류의 죄를 구원하기 위해 머리 위에 가시면류관을 쓰고 십자가에서 피흘리는 어린양이 되어 희생됩니다.
존은 어두운 것을 무서워하며 감방의 복도 불이 항상 켜져있기를 바라고, 전기의자 사형을 당할 때는 어둠이 무섭다면서 두건을 씌우지 말아달라(“Don’t put me in the dark”)고 합니다. 예수님은 “빛이요 생명”이신 주님, 하나님의 아들로 이 땅에 오셨지요.
간수 폴은 사형수 존이 죄가 없음을 알지만 사형을 면하게 할 방법이 없자 괴로워하면서 존에게 물어봐요.
폴: “나중에 내가 죽어서 하느님을 만났을 때 왜 당신의 기적을 죽였냐고 물어보시면 난 뭐라고 대답해야 하지?”
존: “자비를 베풀어 주셨다고 하세요.”
마태복음에 보면 예수님께서도 이런 말씀을 하셨어요.
“너희가 여기 내 형제 중에 지극히 작은 자 하나에게 한 것이 곧 내게 한 것이니라” (마태복음 25장 40절)
하나님의 아들이지만 전 인류를 구원하기 위해 인간으로 오신 예수님과 기적을 행하는 인간 존을 단순 비교하는 것은 무리가 있겠습니다만, 위에 비교한 내용을 살펴보면 원작가 스티븐 킹은 존을 묘사할 때 예수님을 염두에 두었을것 같습니다.
(3) 선과 악
인간의 본성은 선할 걸까요, 아니면 악할 걸까요? 그도 아니면 백지로 태어난 인간이 사회화 과정 속에서 선과 악의 비중이 사후적으로 형성이 되는 것 일까요? (성경에서는 인간의 본성이 악하다고 말하고 있습니다. 여러분의 생각은 어떠세요?)
이 영화에서 보면 한 인간이 속한 부류가 간수의 신분이건 혹은 죄수의 신분이건 간에 선한 사람도 있고 싸이코 패스, 쏘시오 패스도 섞여 있어요. 특히 이 영화에서 악한 포스를 풀풀 풍기면서 강렬한 인상을 남긴 간수 ‘퍼시’(더그 허치슨 분)와 살인마 죄수 ‘와일드 빌’(샘 록웰 분)이 나와요 (두 명 모두 연기를 너무나 잘 했어요! 둘 중에 한 명이라도 꿈에라도 나타날까봐 무서울 지경이예요).
The Green Mile
사람마다 정도의 차이는 있을 지언정 모두들 선과 악한 심성 모두를 우리는 가지고 있잖아요. 선과 악 중에서 어느쪽에게 먹이를 주고 북돋아 주느냐가 중요할 것 같아요. 그리고 이 영화에서 퍼시와 델의 서로 상처주고 상처입히는 과정을 보면서 다른 사람에게는 “친절하게(be kind)” 그리고 예의를 갖춰서 대해주는 것이 중요하다는 생각도 해봐요. 퍼시가 델의 손가락에 골절을 입혔고, 와일드 빌에게 농락을 당하고 바지에 오줌을 싸버린 퍼시를 델은 놀리고, 다시 델에게 모욕당했다고 느낀 퍼시는 델의 사형집행일에 스펀지에 물을 뭍히지 않아서 델이 끔찍한 고통 속에 죽어가게 해요. 상대가 그 누구이던지 간에 말과 행동은 예의를 갖춰 친절하게 하고 볼 일이예요. 누군가에게 상처를 주면 그 말과 행동이 돌고 돌아서 결국에게 나에게로 향하게 되는 경우를 많이 봐요. 선이든 악이든 전염성이 강한 것 같아요.
퍼시는 간수로서 사형수의 전기의자 사형을 집행을 한 후에 브라이어 리지 정신병원으로 전근을 가기로 했지만, 결국엔 와일드 빌을 권총으로 쏴 죽인 후에 넋이 나가서 정신병자로서 브라이어 리지 정신병원으로 가게 되지요. 뿌린대로 거둔다고 했던가요! 맨 정신(?)으로 정신병원에 가게 되었다면 약자인 환자들을 괴롭히면서 희열을 느꼈을 것 같은 퍼시를 알기에 존이 미리 손을 쓴 거 겠지요? (존은 인류를 구원할 수도, 죽은 이를 되살릴 수는 없지만, 죄와 악을 벌하고 정신병원 환자들에 대한 배려의 선물을 주고 떠납니다.)
(4) 백인과 흑인
영화는 아직 유색인종차별이 극심했던 1930년대 미국 남부를 배경으로 합니다. 그렇다보니 흑인 이란 이유만으로 “분명히 두 여자 아이들을 죽인 살인범임에 틀림없다”는 확신에 찬 범죄 혐의를 받고, 제대로 된 변호도 받지 못한 채 사형 판결을 받게 됩니다. 간수 폴은 존의 성품을 알아보고 존의 변호사를 찾아가 사건에 대해 물어보는데요, 이때 존의 변호사가 했던 말이 1930년대 남부 지역의 백인들이 가지고 있었던 흑인에 대한 인식을 표현한고 있다고 볼 수 있을 거예요.
The Green Mile
존 커피의 변호사 버트: “저희 집에는 잡종 개가 한마리 있었습니다. 어느날 그 개가 제 아들을 물어서 아들은 한쪽 눈을 실명했어요. 흑인은 잡종개와 같아서 주인이랑 잘 지내다가도 어느 순간 돌변해서 주인을 물을지 몰라요. 접종 개가 제 아들을 물었을 때 저는 추호의 주저함도 없이 총으로 개의 머리를 쏴버렸지요” (기억이 정확하지 않으므로 실제 대사는 조금 다를 것임. 대략 이런 내용이었음.)
존이 두 여자 아이를 껴안고 울부 짖으면서 "I couldn't help it!" 은 중의적으로 해석될 수 있는 말이예요. 첫째는 말 그대로 "나는 이 두 여자 아이들을 도와줄(help) 수 없었습니다"의 뜻이고, 이게 바로 존 커피가 하고자 했던 말이예요. 두번째로는 "나는 (살인을 저지르지 않고는) 어쩔 수(avoid) 없었습니다." 라고도 해석할 수 있어요. 두 어린 여자아이의 아빠와 백인 보안관, 주민들은 아마도 이 두번째 의미로 존 커피가 울면서 말한 "I couldn't help it"을 받아들였을 거예요. 만약 존 커피가 백인이었고, 깨끗한 옷에 말쑥한 외모였다면 어땠을까요?
(5) 죄와 벌
영화에서는 사형을 집행하기 전에 교도관이 근엄하게 선포해요. “법에 기반하여 저명하고 권위있는 재판관 000와 배심원들의 정의로운 재판 결과에 의해 죄수 000 에게 사형이 구형되었으며, 때가 되었기에 사형을 집행합니다.” 라구요. 뭔가 엄청난 권위와 신뢰 하에 판결이 된 듯한 인상을 주지만 우리 인간은 완벽하지 않잖아요.
법은 국민의 대리인인 국회의원들에 의해 사회적 합의를 반영하여 만들어지고 또 시대에 따라 변경이 됩니다. 사형제도의 범죄 예방 효과, 윤리적이고 인도적인 측면에 대한 찬반 논란이 뜨거우며, 국가별로도 사형제도의 존치와 집행 여부에 차이를 보이고 있습니다.
The Green Mile
이 영화에서는 전기 의자 사형집행 장소에 피해자와 관련된 사람들이 참관인으로서 전체 사형집행 과정을 보는 장면이 나옵니다. 특히 델이 사형을 당하는 장면에서는 델이 마지막으로 하는 말에서 “제가 큰 잘못을 저질렀습니다. 피해자 가족들에게 용서를 구하고 싶습니다. 저의 죄를 되돌리고 싶지만 이미 때가 늦어서 그럴 수가 없습니다”(정확한 대사는 아님. 대략 이런 내용) 라고 하였습니다. 반면에 피해자 가족은 가해자 델이 처참한 고통 속에 죽어가면 좋겠다고 저주를 퍼붓습니다. 그리고 델은 퍼시가 스펀지에 물을 적시지 않은 채로 사형을 집행하는 바람에 차마 눈을 뜨고 볼 수 없을 정도로 큰 고통 속에 죽어가게 되고, 참관인들은 아비규환이 되어 구토를 하면서 처형장을 빠져나가려 합니다. 용서를 구하는 죄인이 있고, 가해자와 다를 바 없는 잔인성을 표출하는 피해자 가족들이 있으며, 법의 이름으로 사형수를 사형하는 국가의 체제가 있습니다. 죄가 없었던 존 커피는 사형이 집행되었고, 되돌릴 수 없는 다리를 건너 죽음의 세계로 건너갔습니다.
죄와 벌, 용서와 구원은 종교의 영역에서만 가능한 것일까요?
(6) 죽음과 영생
죽음은 사람에게 있어 저주일까요? 그리고 영생은 축복일까요? 이 영화에서 폴은 존으로부터 신비로운 능력을 전달받아서 108세가 되었는데도 건강하게 지내고 있습니다. (서커스를 할 줄 아는 쥐 징글스도 64년이 되었는데도 살아있는 데요, 쥐의 수명이 10년이 안되는 것을 고려하먄 폴이 앞으로도 꽤 오랫동안 더 살 수 있을 것 같습니다.).
“무병장수”를 누리고 있는 폴은 자기가 사랑하는 아내, 자식, 그리고 요양원의 친구들이 하나 둘 씩 죽음을 맞아 곁을 떠나보내는 슬픔을 계속 마주해야 한다며 “죄없는 존을 죽인 벌을 받고 있는 거예요”라고 말합니다.
사회적 동물인 인간에게 영생은 저주 일지도 모르겠습니다. 삶을 의미있게 하고 또 “중년의 위기” 이후 후반기의 삶을 설계할 때 나침반이 되어주는 것을 꼽으라면 “메멘토 모리, 죽음을 기억하라”가 아닐까 싶습니다.
존은 자신이 죄가 없지만 사형을 받아들이며 이렇게 말해요. 힘들고 지친 영혼에게 죽음은 마지막 안식처가 되어주기도 하나봅니다. 이 장면 너무 슬퍼요.
존 커피: “전 이제 끝내고 싶어요 전 지쳤어요. 비맞은 참새마냥 홀로 떠도는 것도 지쳤고, 인생을 나눌 친구가 없는 것에 지쳤고, 사람들의 추한 작태를 보는 것에 특히 지쳤고, 매일 세상속에서 느끼고 듣는 고통속에서 지쳤고, 그래서 항상 머리속에서 유리가 깨지는 것 같아요."
(7) 지옥과 천국
우리가 살고 있는 “바로 지금 여기”는 지옥인 걸까요? 우리가 종교에 귀의해서 구원받아야만 죽은 후에 갈 수 있는 곳이 천국일까요?
폴이 존에게 사형 당하기 전에 마지막으로 부탁하고 싶은 것이 있는지 물어봐요. 이때 존은 한평생 영화를 본 적이 없다면서 처음이자 마지막으로 영화를 볼 수 있겠냐고 부탁을 해요. 존과 간수들이 감옥에서 같이 본 영화가 바로 이 영화의 처음 시작 부분에서 요양원에서 노인 폴이 친구 일레인과 함께 우연히 TV에서 보고나서 오열했던 바로 그 영화예요.
뮤지컬 영화 “톱 햇(Top Hat, 1935)” 에서는 사랑에 빠진 연인이 춤을 추면서 “당신과 함께 있는 여기가 바로 천국”이라고 노래하는 장면이 스크린에 비추고 있고, 사형을 앞둔 존 커피도 역시 감동의 눈물을 흘리면서 “지금 여기가 천국이예요”라고 말해요.
Musical "Top Hat"The Green Mile, John Coffey
예수님도 하나님의 나라 천국이 “또 여기 있다 저기 있다고 못하리니 하나님의 나라는 너희 안에 있느니라” (누가복음 17:21) 라고 말씀하셨답니다.
이 글을 읽고 있는 모든 분들이 언제, 어디에 계시든 “바로 지금 여기가 천국” 이길 소원합니다.
상영 시간이 3시간이 조금 넘는 영화인데도 시간 가는 줄 모르고 영화를 보았습니다. 3시간 동안 슬프지만 마음 따뜻해지고 싶은 분에게 영화 그린 마일을 권합니다. 또 누가 알겠어요? 그린 마일 영화를 보면서 존 커피가 되뇌었던 "바로 지금 여기가 천국이네요!" 가 여러분의 입에서 나올런지요.
비록 코로나로 인해서 밖에 잘 나가지는 못한다지만, 집에 있으면서 영화와 함께 나날이 행복하시길 바래요. :-)
데이터 과학자가 다른 엔지니어의 도움없이 어떤 플랫폼(AWS, GCP, Azure, On-prem)에라도 스스로 분석 환경을 구성(Provisioning)하고, 데이터 전처리 및 모델 훈련을 해서, 모델 배포까지 하는 데이터 과학의 전체 워크플로우, 파이프라인을 관리할 수 있고, 필요 시 Scale out 할 수 있다면 정말 근사하겠지요? 업무 생산성도 획기적으로 향상되고, 절약한 시간만큼 데이터 분석 및 모델링에 더 투자할 수 있으니 모델의 예측 성과도 향상될 기회가 있겠구요.
데이터 과학자가 Kubernetes (K8s) 대한 약간(?)의 지식이 있다면 구글이 주도하는 오픈소스 Kubeflow 를 사용해서 앞서 말한 장점을 누릴 수 있습니다. 2021년 8월 현재 Kubeflow 1.3 버전까지 나왔는데요, 올 초 봤던 1.0 대비 Kale, Katib, RStudio 연동 등 향상된 기능들이 눈에 들어오고 무척 마음에 드네요.
Kubeflow 오픈소스 프로젝트는 Kubernetes 위에서 기계학습 워크플로우를 배포하는 것을 다양한 인프라(diverse infrastructures)에서 쉽고(simple), 이동 가능하고(portable), 확장 가능하게(scalable) 구현하는 것을 목표로 시작이 되었습니다. Kubernetes를 사용할 수 있는 어떤 Cloud 환경이라도 Kubeflow 도 사용할 수 있게 말이지요.
kubeflow
Kubeflow의 특징 및 기능을 소개해보겠습니다.
1-1. Notebooks
데이터 과학자들이 Jupyter Notebook 을 많이 사용하잖아요. Kubeflow 에서는 데이터 과학자가 Jupyter Notebook 을생성하고 관리할 수 있습니다. 이때 분석에 사용할 언어(Python, R 등)와 패키지가 포함되어 있는 도커 컨테이너 이미지를 선택할 수 있고, 또 분석에 필요로 하는 CPU, 메모리, GPU 에 대한 자원 할당 수준을 데이터 과학자가 직접 설정하여 분석환경을 수 초 내에 Kubernetes 위에 도커 컨테이너로 생성할 있습니다.
분석환경 생성(Provisioning)할 때는 UI를 제공하고 이후의 생성은 완전 자동화되어 있기 때문에 Kubernetes 를 몰라도 어렵지 않게 사용할 수 있습니다. 완전 멋지지요?! 세상 참 편해졌습니다!
1-2. TensorFlow model training
Kubeflow 는 TensorFlow 로 기계학습 모델 훈련을 위한 custom job operator 를 제공합니다. 특히, Kubeflow의 job operator는 TensorFlow 모델 훈련을 분산 병렬처리 (distributed TensorFlow training jobs) 할 수 있게 해줍니다. 그리고 TensorFlow 모델을 훈련할 때 CPU나 GPU를 사용할 수 있고 다양한 클러스터 크기에 적합하게 설정, 조정할 수 있도록 해줍니다.
1-3. Model serving
Kubeflow는 훈련이 된 TensorFlow 모델을 Kubernetes 에 배포할 때 사용하는 TensorFlow Serving 컨테이너를 지원합니다. 또한 Kubeflow는 훈련된 기계학습 모델을 Kubernetes 위에 배포할 수 있도록 해주는 오픈소스 플랫폼 Seldon Core 와도 통합이 되어 있습니다.
Kubeflow는 기계학습/딥러닝(ML/DL) 모델을 규모있게 배포할 때 GPU 활용을 극대화하기 위해 NVIDA Triton Inference Server 와도 통합이 되어있습니다. 그리고 ML/DL 모델 배포하고 실시간으로 모니터링을 할 때 사용하는 오픈소스 serverless 프레임웍인 MLRun Serving 도 지원합니다.
1-4. Pipelines
Kubeflow Pipelines 는 기계학습/딥러닝 학습 모델을 배포하고 관리하는 end-to-end 워크플로우에 대한 종합적인 솔루션입니다. KubeFlow Pipelines 를 사용하여 모델 학습/실험을 스케줄링(scheduling)하고, 실험 결과를 비교하고, 각 실험 결과에 대한 상세한 내용을 살펴볼 수 있어서, 신속하고 신뢰할만한 실험을 할 수 있습니다.
ML components and challenges
1-5. Multi-framework
KubeFlow 는 기계학습/딥러닝 프레임웍으로서 TensorFlow 뿐만이 아니라, PyTorch, Apache MXNet, MPI, XGBoost, Chainer 도 지원합니다. 또한 KubeFlow는 이종 서비스 간 트래픽 관리 및 보안을 위한 Istio, Ambassador 와도 통합되어 있으며, 신속한 다용도 서버리스 프레임웍인 Nuclio, 그리고 데이터 과학 파이프라인 관리를 위한 Pachyderm 과도 통합되어 있습니다.
비폭력 대화 (NVC, Nonviolent Communication), 일상에서 쓰는 평화의 언어, 삶의 언어
마셜 B. 로젠버그 지음,
캐서린 한 옮김,
한국NVC센터
비폭력 대화, 마셜 B. 로젠버그 지음
15년 전쯤에 퇴근 후에 저녁에 석 달 정도 상담 공부를 한 적이 있습니다. 그때 이 책도 커리큘럼 중의 하나여서 이 책 읽으면서 비폭력대화 연습을 했었고, 몇 달 간은 일상 생활 속에서도 잘 사용하면서 지냈던 기억이 나요. 그런데 언제부턴가 까맣게 잊고 살다가 이번에 책을 다시 보니 ‘아, 맞아. 이렇게 대화했어야 하는데…’ 싶은거 있죠. 인간은 망각의 동물이라더니 정말… ㅠ_ㅠ
집 여러번 이사할 때마다 책 수십~수백권씩을 버리곤 했었는데요, 이 책도 그때 아무 생각없이 버렸었나봐요. >_<
그래서 말인데요, 이 책은 눈에 잘 보이는 책꽂이에 꽂아놓고, 1년에 한두번씩 반복해서, 잊을만 하면 계속 반복적으로 읽으면서 다시 상기하고, 실생활에 계속 습관이 될 때까지 사용하고 해야 할거 같아요. 그리고 온 가족이 돌려가면서 같이 읽고, 서로 비폭력대화로 대화하면서 자극도 주고요.
교육부에서 초/중/고등학교에서 정규교육 커리큘럼에 ‘비폭력 대화’를 정기적으로 가르치는 것도 고려해보면 좋겠어요. 인간이란 결국 사회적 동물이고, 사람들 간의 관계는 대화 속에서 싹트고 무르익는 것이잖아요. 서로 상처주는 대화보다는 평화와 화해, 공감과 이해가 가득한 대화를 하는 방법만큼 중요한 삶의 기술(?)이 또 어디있겠습니까.
“이 세상은 우리가 만들어놓은 것이다. 오늘날 이 세상이 무자비하다면, 그것은 우리의 무자비한 태도와 행동이 그렇게 만든 것이다. 그러므로 우리 자신이 변하면 우리는 이 세상을 바꿀 수 있다. 우리 자신을 바꾸는 것은 우리가 매일 쓰는 언어와 대화 방식을 바꾸는 데서 시작한다.” (p7)
그럼, 이 책에서 저자 마셜 B. 로젠버그 박사가 알려주는 서로 마음으로 주고받는 관계를 이루기 위한 비폭력대화 모델의 네 가지 요소에 대해서 한번 알아볼까요?
(이번 포스팅은 이 책의 상당 부분을 인용하면서 내용을 소개하게 되네요.
(1) 있는 그대로 관찰하기
(2) 느낌을 알아차리고 표현하기
(3) 욕구를 의식함으로써 자신의 느낌에 대해 책임지기
(4) 삶을 풍요롭게 하기 위해 부탁하기
(1) 있는 그대로 관찰하기
있는 그대로 ‘관찰’하기는 ‘평가’와 섞지않는다는 뜻입니다. 관찰에 “평가”가 섞이는 순간 상대방은 이를 “비판”으로 받아들이고 방어적으로 반응하는 경우가 많다보니 이후에 제대로된 소통이 어려워질 수밖에 없습니다. 아래의 예는 책에 소개된 “평가”와 “관찰”의 비교 예인데요, 여러분의 대화 패턴은 어디에 속하는지 한번 보실래요?
평가 : “너는 내가 원하는 건 좀처럼 하지 않아.”
관찰: “최근에 너는 내가 제안한 세 가지를 다 하기 싫다고 했다.”
(2) 느낌을 알아차리고 표현하기
문제는 있는 그대로 관찰하고, 자신의 또는 상대방의 느낌을 알아차리고 표현하기가 쉽지 않다는 점입니다. 특히, 저를 포함해서 한국의 남자들은 자기의 감정과 느낌을 제대로 알아차리고 말로 표현하는걸 힘들어 하는 것 같아요. 아래는 이 책에서 소개하는 ‘느낌말 목록’ 인데요, 찬찬히 시간내서 읽어보시고 매 순간마다 ‘지금 내 느낌은?’ 이라고 질문을 던지고 답해보는 연습을 해보면 좋을거 같아요.
[ 느낌말 목록, 보편적인 욕구 목록 ]
비폭력 대화 (by 마셜 B. 로젠버그) - 느낌말 목록, 보편적인 욕구 목록
그리고 느낌과 생각을 혼동해서 ‘생각’을 마치 ‘느낌’인 것인냥 표현하는 것도 조심해야 된다고 저자는 말하고 있어요. 아래의 예는 ‘생각’을 ‘느낌’인양 잘못 표현한 것인데요, 얼핏 들으면 ‘아, 저게 느낌이 아니라 생각이었구나’를 눈치 못챌 수도 있어요.
“내가 오해를 받고 있다고 느껴져.”
여기서 ‘오해를 받고 있다’는 말은 실제 느낌이라기보다는 다른 사람이 나를 어떻게 이해하고 있는지를 평가한 말이다. 이 상황에서 느낌은 ‘걱정스럽다’ 또는 ‘괴롭다’라고 할 수 있을 것이다. (p79)
(3) 욕구를 의식함으로써 자신의 느낌에 대해 책임지기
인간은 상황 자체가 아니라 그 상황을 바라보는 관점 때문에 고통을 당한다.”
- 에픽테토스, 그리스 스토아학파 철학자-
듣기 힘든 말을 들었을 때 우리는 네가지 중에서 선택을 할 수 있다고 해요.
첫째, 자신을 탓하기.
둘째, 다른 사람을 탓하기.
셋째, 자신의 느낌과 욕구 인식하기.
넷째, 다른 사람의 느낌과 욕구 인식하기.
눈치 채셨겠지만, 자신이나 또는 다른 사람을 탓하는 것은 건강한 방법은 아니며, 대신 “자신이 필요한 것을 표현하면 그 욕구가 충족될 가능성이 커지기” 때문에 자신과 다른 사람의 느낌과 욕구를 인식하는 것이 중요하다고 저자는 말하고 있어요.
“다른 사람을 비판하고, 비난하고, 분석하고, 해석하는 것은 자신의 욕구를 돌려서 표현하는 것이다” (p93) 라는 통찰 가득한 문장, 진정 소름 돋지 않나요? 다른 사람의 말과 행동에 과도하게 반응한다면 그건 바로 자신의 그림자이고, 자신의 결핍된 욕구를 상대방은 남 눈치안보고 표현하고 누리고 있기 때문이라고, 나의 욕구에 대한 거울이라고 인식하는 것이 자신의 욕구를 충족시킬 수 있는 시발점이라는 것이지요!
이 책 p97의 소제목이 “욕구를 표현하는 것의 어려움과 욕구를 표현하지 못했을 때의 고통” 이예요. 눈에 쏙 들어오고, 오랫동안 머물러 있었던 소제목이예요. 이런 경험 모두 다 가지고 있지 않나요? 다른 사람의 눈치 보고 또 미움받는 것이 두려워서 나의 욕구를 표현하지 못하고, 나중에 제대로 표현못한 나에 대해 머리속으로 그 상황을 계속 떠올리면서 후회하고 탄식하는 그런 모습이요.
(4) 삶을 풍요롭게 하기 위해 부탁하기
NVC의 네번째 요소는 “우리가 원하는 것을 다른 사람에게 긍정적인 언어를 사용해서, 실행할 수 있는 구체적인 행동언어로 부탁하기”예요. 특히 가까운 사이일수록 구체적인 말로 표현 안해도 상대방이 나의 욕구를 알아줄 것이라고 예상하고 기대하잖아요. 그런데 그거 아니라는 거예요! 대놓고 자기가 원하는 것을 “긍정적이고 실행할 수 있는 구체적인 행동언어”로 표현하고 부탁하라는 것이예요. 만약 당신이 삶을 더 풍요롭고 만족스럽고 행복하게 살기를 원한다면 말이지요. 저는 이 챕터 읽으면서 부부 사이이 관계에서 서로가 상대방에게 원하는 것을 제대로 표현하기로 마음먹게 되더라구요. 부부라고 서로의 욕구에 대해서 잘 알것 같지만 꼭 그렇지도 않아요. 말을 안하는데 어떻게 제대로 알겠어요.
단, “부탁”과 “강요”는 구분할 필요가 있다고 해요. 만약 “듣는 사람이 자기가 그 부탁을 들어주지 않으면 비난이나 벌을 받을 것이라고 믿게 되면 그 부탁은 강요로 받아들여지는 것”이라고 해요. (p134) 상대방이 “부탁”이 아니라 “강요”를 받는다고 느낀다면 “복종” 아니면 “반항”을 선택할 수 밖에 없다고 해요. 자, 당신이 부탁을 했는데 상대방이 거절을 했을 때 만약 당신이 상대방을 비판하거나 비난하거나 하면 그땐 부탁이 아니라 강요가 되는거니깐요, 조심하셔야 해요. 상대방이 부탁을 거절한 자유가 있다는 것 잊지 마세요.
(5) 공감으로 듣기
“공감이란 다른 사람이 경험하고 있는 것을 존중하는 마음으로 이해하는 것”이라고 해요. (p155). 공감으로 듣는 것이 얼마나 어렵냐 하면요, 프랑스 작가 시몬 베유는 말하길 “고통을 받고 있는 사람에게 관심을 집중할 수 있는 능력은 매우 드물고 어려운 것이다. 그것은 거의 기적과 같은 일이다. 사실 기적이다. 스스로 그런 능력을 가졌다고 생각하는 사람들 대부분은 그것을 가지고 있지 않다”고 말하고 있어요.(p156)
이 챕터에서 우리가 다른 사람과 공감으로 듣기를 방해하는 장애물들 몇가지(p157)를 소개하고 있는데요, 이 내용들 읽으면서 저 소름돋았어요. 왜냐하면 이것들이 모두 다 제가 평상 시 참 잘도 사용하는 표현들이거든요. 오 마이 갓! ㅠ_ㅠ
- 조언하기: “내 생각에 너는 ~해야 해.” “왜 ~하지 않았니?”
- 한술 더 뜨기: “그건 아무것도 아니야, 나한테는 더한 일이 있었는데…….”
- 가르치려 들기: “이건 네게 정말 좋은 경험이니까 여기서 배워.”
- 위로하기: “그건 네 잘못이 아니야. 너는 최선을 다했어.”
- 다른 이야기 꺼내기: “그 말을 들으니 생각나는데…….”
- 말을 끊기: “그만하고 기운 내”
- 동정하기: “참 안됐다. 어쩌면 좋으니.”
- 심문하기: “언제부터 그랬어?”
- 설명하기: “그게 어떻게 된 거냐 하면…….”
- 바로잡기: “그건 네가 잘못 생각하고 있는거야.”
그러면서 저자는 공감으로 듣는 것을 방해하는 우리의 생각으로, “문제를 해결해주고, 다른 사람의 기분을 더 좋게 해주어야 한다는 생각이 우리가 온 존재로 그 자리에 있는 것을 방해한다”고 경각심을 일깨워주고 있어요. 특히, 회사에서 논리적이고 효율적인 문제해결, 솔루션, 업무중심적 사고로 하루종일, 일년 내내 강화학습을 하는 남자들은 특히 더 조심해야 할거 같아요.(네, 제 얘기입니다요! ㅠ_ㅠ)
이후의 챕터들도 내용을 짧게라도 소개하자니 포스팅이 너무 길어질 것 같으니 제목만 소개를 하자면요,
- 제 8장: 공감의 힘
- 제 9장: 우리 자신과 연민으로 연결하기
- 제 10장: 분노를 온전히 표현하기
- 제 11장: 보호를 위해 힘을 쓰기
- 제 12장: 자신을 자유롭게 하고 다른 사람을 돋기
- 제 13장: NVC로 감사 표현하기
들이예요. 어때요, 읽고 싶은 호기심이 무럭무럭 솓구치지 않나요? 꼭 제가 이 책 영업사원이 된거 같네요. ㅋㅋ
이 책의 각 챕터의 마지막에 ‘비폭력 대화 사례’도 나오고, ‘연습문제’도 있어서 책 내용을 복습할 기회도 준답니다. 저자의 생각을 엿보기 전에 꼭 직접 체크해보고 저자의 생각과 비교해보세요.
[에필로그] 강원도 양양 서피비치로 여름 휴가를 갔다가 돌아오는 길에 와이프와 딸에게 버럭 화를 낸 적이 있어요. 그때 와이프가 저한테 한 마디 하더라고요. “치이~ 비폭력 대화 책 읽으면 뭐해. 이렇게 버럭 화낼 거면서…”이 말 듣고 많이 부끄러웠어요. ㅜ_ㅠ 가장 가까운 가족 간에 비폭력 대화 방식으로 마음을 집중해서 대화하는게 쉬운건 아닌것 같긴 해요. ^^; 연습하고 또 연습해서 습관이 되고 자연스레 입에 착 달라붙게 해야 할텐데요. (혹시 이게 자신없으면… 저처럼 한소리 듣기 싫으신 분은 이 책은 가족들 눈에 안띄게 몰래 읽으세요. ^_-)
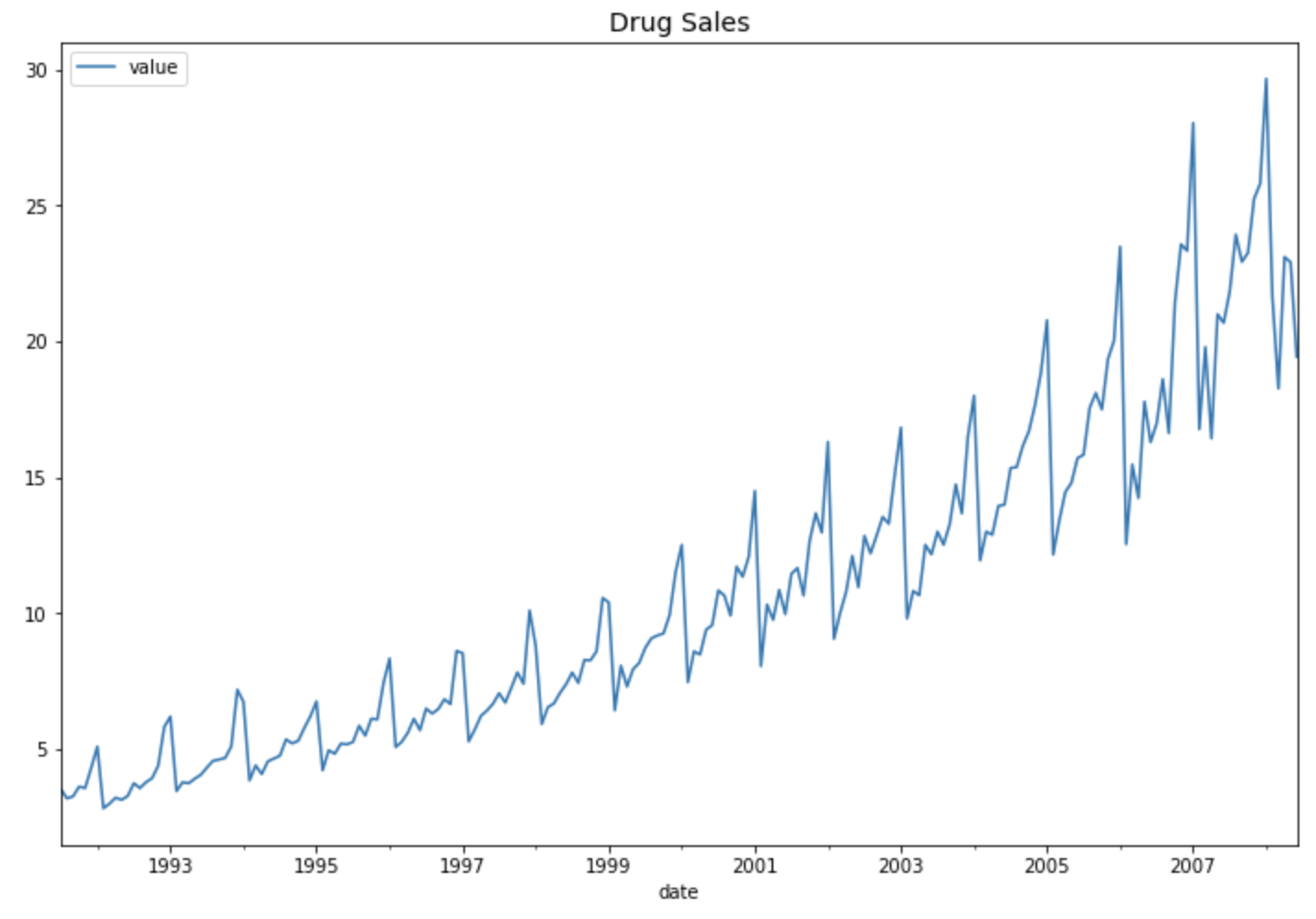
그럼, 실제로 다양한 지수평활법으로 위의 약 판매량 시계열 데이터에 대한 예측 모델을 만들어 예측을 해보고, 다양한 평가지표로 모델 간 비교를 해봐서 가장 우수한 모델이 무엇인지, 과연 앞서 말한 "Multiplicative Winters' method with Linear Trend" 모델이 가장 우수할 것인지 확인해보겠습니다. 보는게 믿는거 아니겠습니까!
이제 월 단위로 시간 순서대로 정렬된 시계열 데이터를 제일 뒤 (최근)의 12개월치는 시계열 예측 모델의 성능을 평가할 때 사용할 test set으로 따로 떼어놓고, 나머지 데이터는 시계열 예측모형 훈련에 사용할 training set 으로 분할 (splitting between the training and the test set)을 해보겠습니다.
## split between the training and the test data sets.
## The last 12 periods form the test data
df_train = df.iloc[:-12]
df_test = df.iloc[-12:]
(1) 지수평활법 기법으로 시계열 예측모형 적합하기 (training the exponential smoothing models in Python)
Python의 statsmodels 라이브러리는 시계열 데이터 분석을 위한 API를 제공합니다. 아래의 코드는 순서대로
statsmodels.tsa.api 메소드를 사용해서 적합한 시계열 데이터 예측 모델에 대해서는 model_object.summary() 메소드를 사용해서 적합 결과를 조회할 수 있습니다. 그리고 model_object.params['parameter_name'] 의 방식으로 지수평활법 시계열 적합 모델의 속성값(attributes of the fitted exponential smoothing results)에 대해서 조회할 수 있습니다.
## accessing the results of SimpleExpSmoothing Model
print(fit1.summary())
# SimpleExpSmoothing Model Results
# ==============================================================================
# Dep. Variable: value No. Observations: 192
# Model: SimpleExpSmoothing SSE 692.196
# Optimized: True AIC 250.216
# Trend: None BIC 256.731
# Seasonal: None AICC 250.430
# Seasonal Periods: None Date: Thu, 29 Jul 2021
# Box-Cox: False Time: 19:26:46
# Box-Cox Coeff.: None
# ==============================================================================
# coeff code optimized
# ------------------------------------------------------------------------------
# smoothing_level 0.3062819 alpha True
# initial_level 3.4872869 l.0 True
# ------------------------------------------------------------------------------
## getting all results by models
params = ['smoothing_level', 'smoothing_trend', 'damping_trend', 'initial_level', 'initial_trend']
results=pd.DataFrame(index=[r"$\alpha$",r"$\beta$",r"$\phi$",r"$l_0$","$b_0$","SSE"],
columns=['SES', "Holt's","Exponential", "Additive", "Multiplicative"])
results["SES"] = [fit1.params[p] for p in params] + [fit1.sse]
results["Holt's"] = [fit2.params[p] for p in params] + [fit2.sse]
results["Exponential"] = [fit3.params[p] for p in params] + [fit3.sse]
results["Additive"] = [fit4.params[p] for p in params] + [fit4.sse]
results["Multiplicative"] = [fit5.params[p] for p in params] + [fit5.sse]
results
# [Out]
# SES Holt's Exponential Additive Multiplicative
# 𝛼 0.306282 0.053290 1.655513e-08 0.064947 0.040053
# 𝛽 NaN 0.053290 1.187778e-08 0.064947 0.040053
# 𝜙 NaN NaN NaN 0.995000 0.995000
# 𝑙0 3.487287 3.279317 3.681273e+00 3.234974 3.382898
# 𝑏0 NaN 0.045952 1.009056e+00 0.052515 1.016242
# SSE 692.195826 631.551871 5.823167e+02 641.058197 621.344891
계절성(seasonality)을 포함한 지수평활법에 대해서는 statsmodels.tsa.holtwinters 내의 메소드를 사용해서 시계열 예측 모델을 적합해보겠습니다.
seasonal_periods 에는 계절 주기를 입력해주는데요, 이번 예제에서는 월 단위 집계 데이터에서 1년 단위로 계절성이 나타나고 있으므로 seasonal_periods = 12 를 입력해주었습니다.
trend = 'add' 로 일단 고정을 했으며, 대신에 계절성의 경우 (f) seasonal = 'add' (or 'additive'), (g) seasonal = 'mul' (or 'multiplicative') 로 구분해서 모델을 각각 적합해보았습니다.
위의 시계열 시도표를 보면 시간이 흐름에 따라 분산이 점점 커지고 있으므로 seasonal = 'mul' (or 'multiplicative') 가 더 적합할 것이라고 우리는 예상할 수 있습니다. 실제 그런지 데이터로 확인해보겠습니다.
## Holt's Winters's method for time series data with Seasonality
from statsmodels.tsa.holtwinters import ExponentialSmoothing as HWES
# additive model for fixed seasonal variation
fit6 = HWES(df_train,
seasonal_periods=12,
trend='add',
seasonal='add').fit(optimized=True, use_brute=True)
# multiplicative model for increasing seasonal variation
fit7 = HWES(df_train,
seasonal_periods=12,
trend='add',
seasonal='mul').fit(optimized=True, use_brute=True)
(2) 지수평활법 적합 모델로 예측하여 모델 간 성능 평가/비교하고 최적 모델 선택하기
(forecasting using the exponential smoothing models, model evaluation/ model comparison and best model selection)
(2-1) 향후 12개월 약 판매량 예측하기 (forecasting the drug sales for the next 12 months)
forecast() 함수를 사용하며, 괄호 안에는 예측하고자 하는 기간을 정수로 입력해줍니다.
Python의 scikit-learn 라이브러리의 metrics 메소드에 이미 정의되어 있는 MSE, MAE 지표는 가져다가 쓰구요, 없는 지표는 모델 적합도 (goodness-of-fit of time series model)를 평가하는 지표 (https://rfriend.tistory.com/667) 포스팅에서 소개했던 수식대로 Python 사용자 정의 함수(User Defined Funtion)을 만들어서 사용하겠습니다.
아래의 모델 성능 평가 지표 중에서 AIC, SBC, APC, Adjsted-R2 지표는 모델 적합에 사용된 모수의 개수 (the number of parameters) 를 알아야지 계산할 수 있으며, 모수의 개수는 지수평활법 모델 종류별로 다르므로, 적합된 모델 객체로부터 모수 개수를 세는 사용자 정의함수를 먼저 정의해보겠습니다.
## UDF for counting the number of parameters in model
def num_params(model):
n_params = 0
for p in list(model.params.values()):
if isinstance(p, np.ndarray):
n_params += len(p)
#print(p)
elif p in [np.nan, False, None]:
pass
elif np.isnan(float(p)):
pass
else:
n_params += 1
#print(p)
return n_params
num_params(fit1)
[Out] 2
num_params(fit7)
[Out] 17
이제 각 지표별로 Python을 사용해서 지수평활법 모델별로 성능을 평가하는 사용자 정의함수를 정의해보겠습니다. MSE와 MAE는 scikit-learn.metrics 에 있는 메소드를 가져다가 사용하며, 나머지는 공식에 맞추어서 정의해주었습니다.
(혹시 sklearn 라이브러리에 모델 성능 평가 지표 추가로 더 있으면 그거 가져다 사용하시면 됩니다. 저는 sklearn 튜토리얼 찾아보고 없는거 같아서 아래처럼 정의해봤어요. 혹시 코드 잘못된거 있으면 댓글에 남겨주시면 감사하겠습니다.)
## number of observations in training set
T = df_train.shape[0]
print(T)
[Out] 192
## evaluation metrics
from sklearn.metrics import mean_squared_error as MSE
from sklearn.metrics import mean_absolute_error as MAE
# Mean Absolute Percentage Error
def SSE(y_test, y_pred):
y_test, y_pred = np.array(y_test), np.array(y_pred)
return np.sum((y_test - y_pred)**2)
def ME(y_test, y_pred):
y_test, y_pred = np.array(y_test), np.array(y_pred)
return np.mean(y_test - y_pred)
def RMSE(y_test, y_pred):
y_test, y_pred = np.array(y_test), np.array(y_pred)
return np.sqrt(np.mean((y_test - y_pred)**2))
#return np.sqrt(MSE(y_test - y_pred))
def MPE(y_test, y_pred):
y_test, y_pred = np.array(y_test), np.array(y_pred)
return np.mean((y_test - y_pred) / y_test) * 100
def MAPE(y_test, y_pred):
y_test, y_pred = np.array(y_test), np.array(y_pred)
return np.mean(np.abs((y_test - y_pred) / y_test)) * 100
def AIC(y_test, y_pred, T, model):
y_test, y_pred = np.array(y_test), np.array(y_pred)
sse = np.sum((y_test - y_pred)**2)
#T = len(y_train) # number of observations
k = num_params(model) # number of parameters
return T * np.log(sse/T) + 2*k
def SBC(y_test, y_pred, T, model):
y_test, y_pred = np.array(y_test), np.array(y_pred)
sse = np.sum((y_test - y_pred)**2)
#T = len(y_train) # number of observations
k = num_params(model) # number of parameters
return T * np.log(sse/T) + k * np.log(T)
def APC(y_test, y_pred, T, model):
y_test, y_pred = np.array(y_test), np.array(y_pred)
sse = np.sum((y_test - y_pred)**2)
#T = len(y_train) # number of observations
k = num_params(model) # number of parameters
return ((T+k)/(T-k)) * sse / T
def ADJ_R2(y_test, y_pred, T, model):
y_test, y_pred = np.array(y_test), np.array(y_pred)
sst = np.sum((y_test - np.mean(y_test))**2)
sse = np.sum((y_test - y_pred)**2)
#T = len(y_train) # number of observations
k = num_params(model) # number of parameters
r2 = 1 - sse/sst
return 1 - ((T - 1)/(T - k)) * (1 - r2)
## Combining all metrics together
def eval_all(y_test, y_pred, T, model):
sse = SSE(y_test, y_pred)
mse = MSE(y_test, y_pred)
rmse = RMSE(y_test, y_pred)
me = ME(y_test, y_pred)
mae = MAE(y_test, y_pred)
mpe = MPE(y_test, y_pred)
mape = MAPE(y_test, y_pred)
aic = AIC(y_test, y_pred, T, model)
sbc = SBC(y_test, y_pred, T, model)
apc = APC(y_test, y_pred, T, model)
adj_r2 = ADJ_R2(y_test, y_pred, T, model)
return [sse, mse, rmse, me, mae, mpe, mape, aic, sbc, apc, adj_r2]
위에서 정의한 시계열 예측 모델 성능평가 지표 사용자 정의 함수를 모델 성능 평가를 위해 따로 떼어놓았던 'test set' 에 적용하여 각 지수평활법 모델별/ 모델 성능평가 지표 별로 비교를 해보겠습니다.
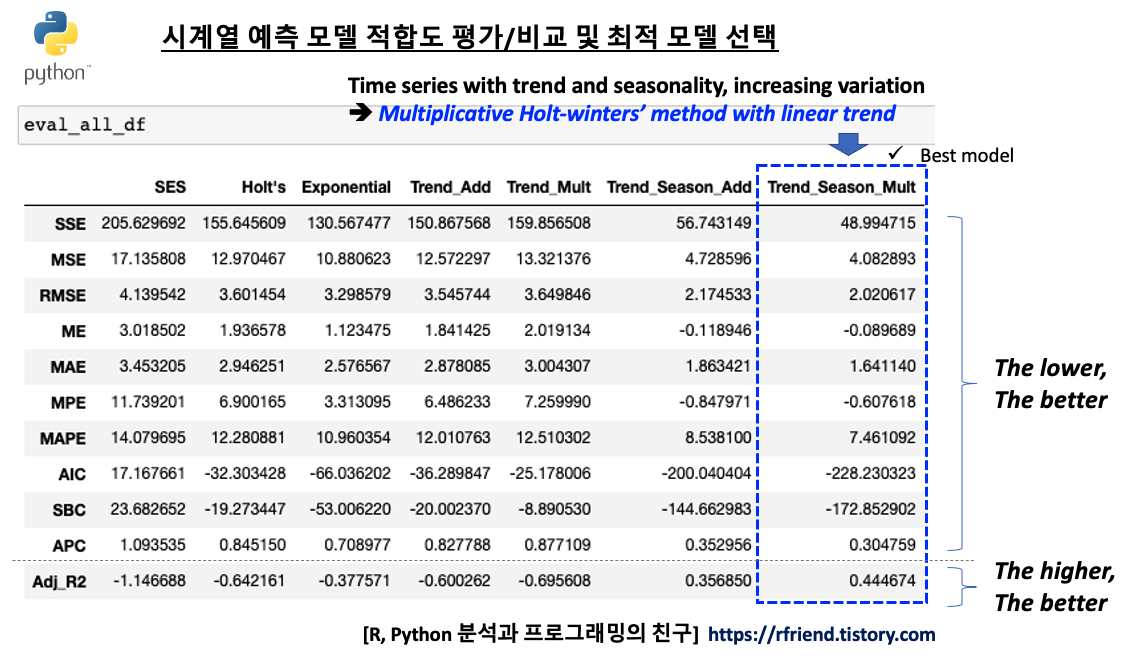
모델 성능평가 지표 중에서 실제값과 예측값의 차이인 잔차(residual)를 기반으로 한 MSE, RMSE, ME, MAE, MPE, MAPE, AIC, SBC, APC 는 낮을 수록 상대적으로 더 좋은 모델이라고 평가할 수 있으며, 실제값과 평균값의 차이 중에서 시계열 예측 모델이 설명할 수 있는 부분의 비중 (모델의 설명력) 을 나타내는 Adjusted-R2 는 값이 높을 수록 상대적으로 더 좋은 모델이라고 평가합니다. (Ajd.-R2 가 음수가 나온 값이 몇 개 보이는데요, 이는 예측 모델이 불량이어서 예측값이 실제값과 차이가 큼에 따라 SSE가 SST보다 크게 되었기 때문입니다.)
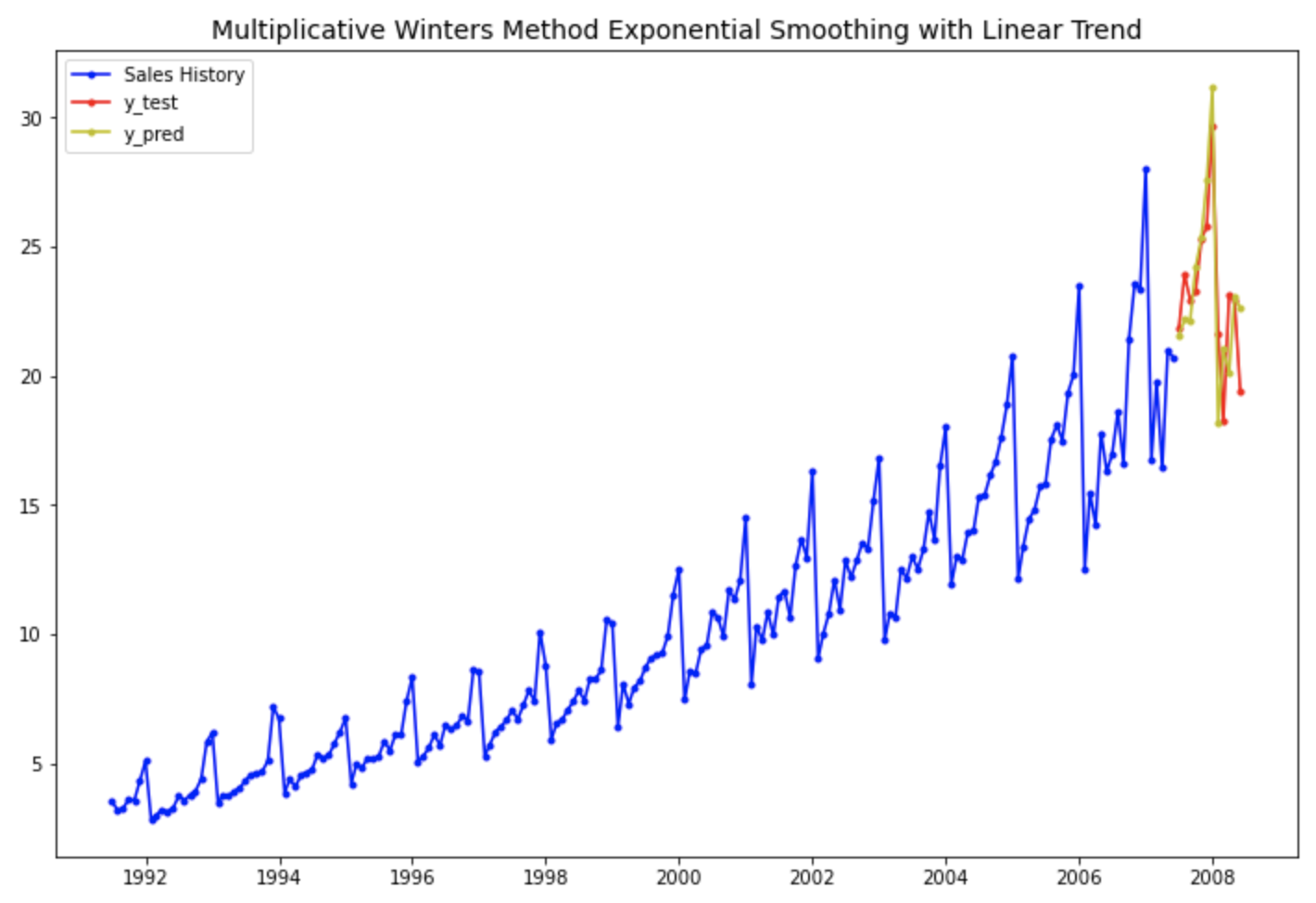
시계열 모델 성능 지표별로 보면 전반적으로 7번째 지수평활법 시계열 예측 모델인 "Multiplicative Winters' method with Linear Trend" 모델이 상대적으로 가장 우수함을 알 수 있습니다. 역시 시도표를 보고서 우리가 예상했던대로 결과가 나왔습니다.
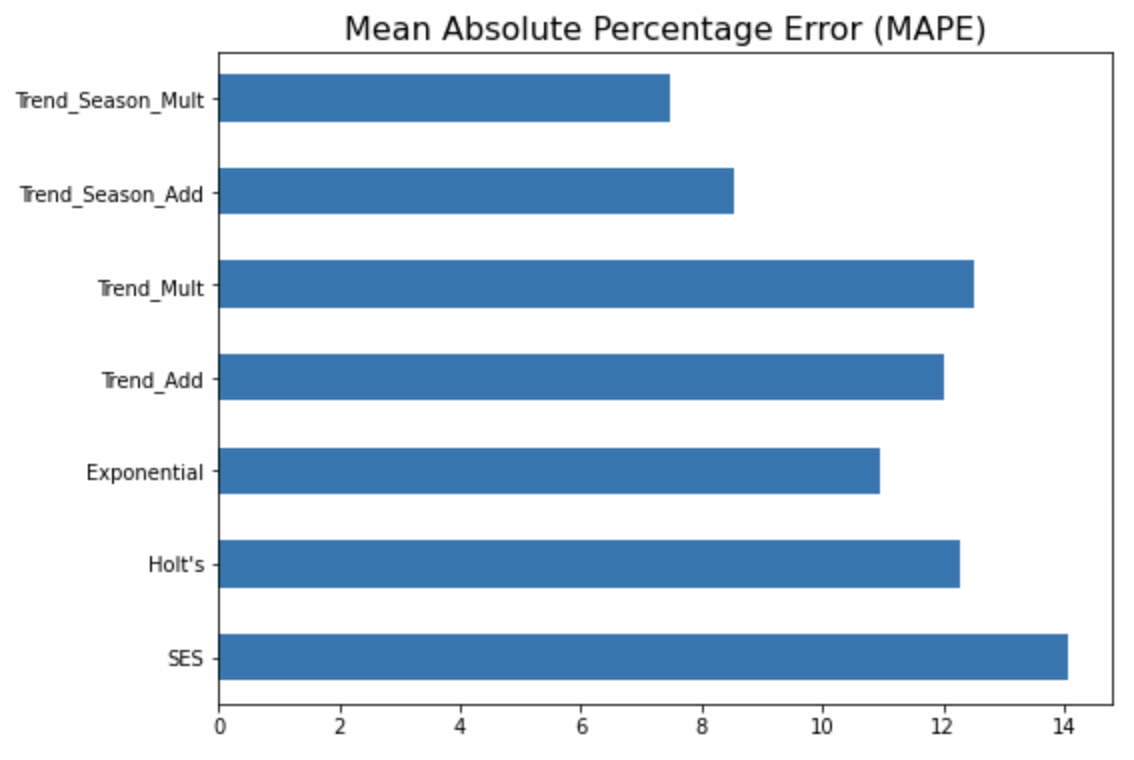
MAPE (Mean Absolute Percentage Error) 지표에 대해서만 옆으로 누운 막대그래프로 모델 간 성능을 비교해서 시각화를 해보면 아래와 같습니다. (MAPE 값이 작을수록 상대적으로 더 우수한 모델로 해석함.)
예상했던 대로 4번째의 "1차 선형 추세만 반영하고 계절성은 없는 이중 지수 평활법 모델" 보다는, 7번째의 "선형추세+계절성까지 반영한 multiplicative holt-winters method exponential smoothing with linear trend 지수평활법 모델" 이 더 실제값을 잘 모델링하여 근접하게 예측하고 있음을 눈으로 확인할 수 있습니다.
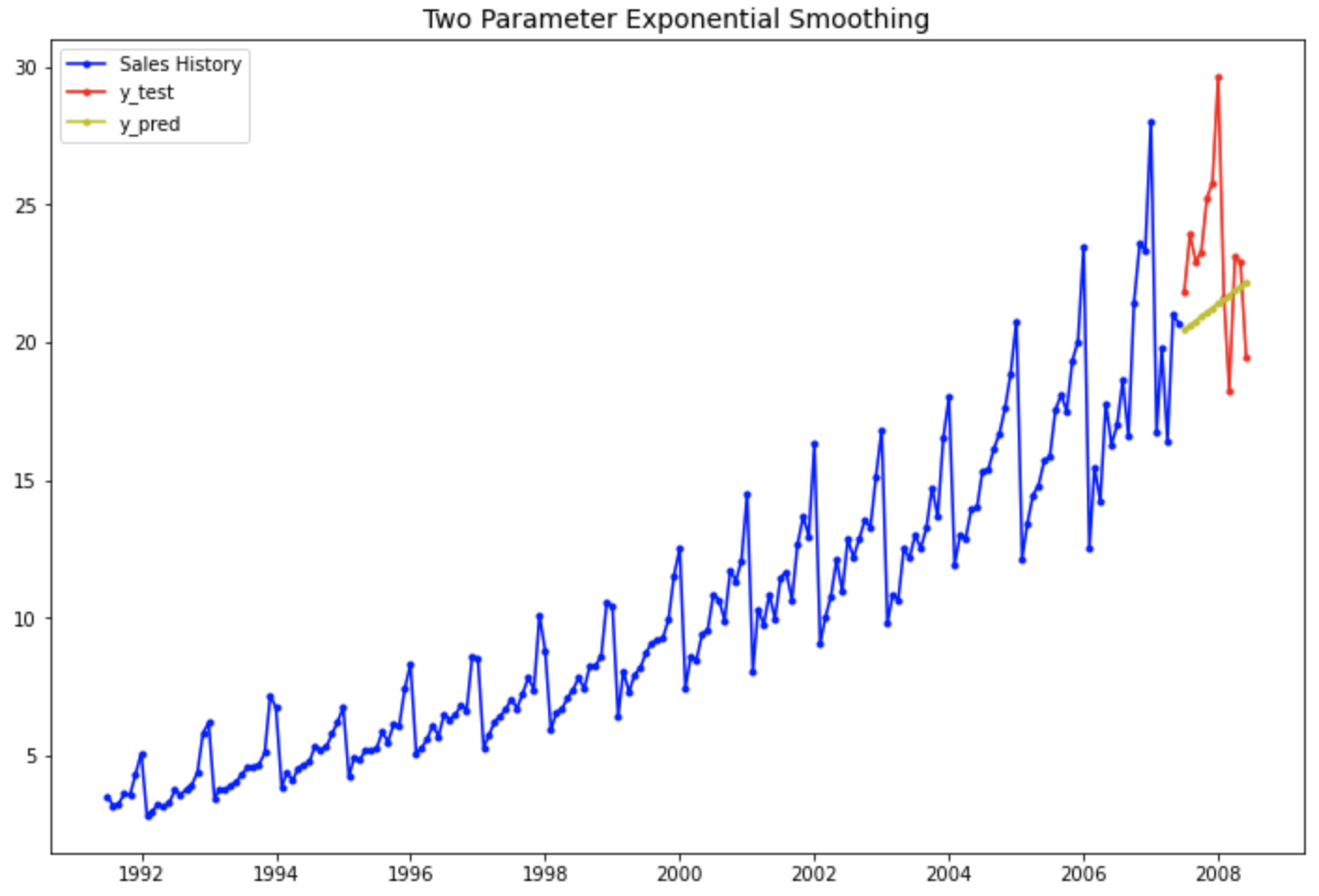
# 1차 선형 추세는 있고 계절성은 없는 이중 지수 평활법
plt.rcParams['figure.figsize']=[12, 8]
past, = plt.plot(df_train.index, df_train, 'b.-', label='Sales History')
test, = plt.plot(df_test.index, df_test, 'r.-', label='y_test')
pred, = plt.plot(df_test.index, forecast_4, 'y.-', label='y_pred')
plt.title('Two Parameter Exponential Smoothing', fontsize=14)
plt.legend(handles=[past, test, pred])
plt.show()
# 1차 선형 추세와 확산계절변동이 있는 승법 윈터스 지수평활법
plt.rcParams['figure.figsize']=[12, 8]
past, = plt.plot(df_train.index, df_train, 'b.-', label='Sales History')
test, = plt.plot(df_test.index, df_test, 'r.-', label='y_test')
pred, = plt.plot(df_test.index, forecast_7, 'y.-', label='y_pred')
plt.title('Multiplicative Winters Method Exponential Smoothing with Linear Trend', fontsize=14)
plt.legend(handles=[past, test, pred])
plt.show()
적합된 statsmodels.tsa 시계열 예측 모델에 대해 summary() 메소드를 사용해서 적합 결과를 조회할 수 있으며, model.params['param_name'] 으로 적합된 모델의 속성값에 접근할 수 있습니다.
우연히 ‘사랑도 통역이 되나요? (Lost In Translation, 2003)’ 라는 고전(?) 영화를 보게 되었어요. 원래 제 블로그에 ‘독서일기’라는 카테고리에 가끔씩 책 읽고 소감을 썼는데요, 이번에 처음으로 영화 얘기를 써봐요. (이 참에 ‘책이랑 영화랑’으로 블로그 카테고리 이름도 바꿨어요.)
굉장히 오래된 영화이기도 하고, 예전에 포스터를 봤었던 기억도 어렴풋이 있었는데요, 영화에 대해 검색을 해보니 2004년도에 아카데미 각본상과 골든 글로브 각본상을 수상했던 영화네요.
사랑도 통역이 되나요? Lost in Translation
(이 블로그 포스팅에는 스포일러가 들어있으니 아직 이 영화를 안보신 분은 여기서부터는 포스팅 읽기를 중단하시길 권합니다.)
영화의 줄거리를 아주 거칠게 요약하자면 ‘외로운 기혼 남녀가 썸타다가 다시 일상으로 돌아가는 이야기’예요. 소설책 ‘메디슨카운티의 다리’ 같은 그런…내용이 어찌보면 맨날 드라마에서 보는 뻔하다면 뻔한 내용인데요, 여운이 많이 남는 영화예요. 그래서 각본상을 두군데서나 탔겠지요?
영화는 밥 해리스 (Bill Murray) 가 위스키 광고를 촬영하러 일본에 출장온 장면에서 시작을 해요. 입국을 환영하러 온 여러명의 일본사람들로부터 명함을 건네받으면서 인사하는, 외국인 입장에서 보면 낯선 첫만남에서 시작해서, 시차로 호텔에서 잠을 못자고 뒤척이지요. 광고를 촬영할 때 감독이 일본어로 길게 샬라~ 샬라~ 연기 주문을 하는데요, 통역사가 “간단하게 말하자면, 고개를 오른쪽으로 돌리세요” 라고 통역을 해줘요. 그러자 밥이 “그게 다예요?” 라고 되묻지요. 그리고 “고개를 어느쪽부터 돌려요?”라고 밥이 한마디 짧게 물어보자 통역사가 일본어로 감독에게 또 길게 일본어로 자기들끼리 블라~블라~해요. ㅋㅋ 일본어를 못하는 밥 입장에서는 “Lost in Translation” 인거고, 당황스러웠을거 같아요. 이국땅에서 외지인으로 머물다 보면 “우리는 여기에 속하지 않아요.”라는 말이 저절로 튀어나오고, 그래서 고향 고국으로 돌아가고 싶어지지요.
호텔에 마사지사가 와서는 일본이 특유의 영어 발음을 하는데 밥이 못 알아들어요. 광고 사진사가 영어로 말하는데 역시 밥이 발음을 잘 못알아 듣지요. 병원에서 벤치에 앉아 옆에 있는 일본인 할머니와 영어로 얘기하는데 또 발음을 잘 못알아들어요. “Lost in Translation” 인데요, 웃기기도 하면서 또 영어가 원어가 아닌 저의 처지가 오버랩이 되면서 웃프기도 해요. (영어로 말했는데 원어민이 “Sorry? Pardon? What?…” 이러면 어찌나 당황스럽고 쑥스러운지요. 다들 그렇죠?)
(영화 제목 “Lost in Translation”의 경우 통역이 이미 실패했다, 소통에 뭔가 놓친게 있고 전부 전달이 안되었다, 말과 글로는 표현하는데 한계가 있다, 뭐 이런 느낌인데요, 이걸 한글로 번역한 “사랑도 통역이 되나요?”라는 제목의 어감과는 다소 차이가 있지요? 영어와 한글의 영화 제목 자체가바로 “Lost in Translation”의 대표적인 예라고 할 수 있겠습니다.)
하지만, 이 영화가 하고자 했던 “통역의 실패, 부족, 누수 (Lost in Translation)”은 단지 영어와 일본어를 쓰는 이국인들 간의 언어 장벽만을 말하고 있는 것은 아니예요. 같은 영어를 쓰는 미국인끼리도, 심지어 뜨겁게 사랑해서, 서로 같이 있기만 해도 좋아 죽을라고 하고 항상 붙어다니다가 결혼까지 한 부부 사이에서도 “소통과 공감의 실패 또는 부족(Lost in Translation)”이 있을 수 있다는 것을 보여주고 있어요. 바로 이게 우리가 이 영화에 여운을 느끼는 이유이겠지요.
사람이라는 존재 자체가 어찌보면 혼자이고, 외로움을 느낄 수 밖에 없긴 하지요. 사랑하고 또 사랑받고 싶고, 어딘가에 소속되어 유대감과 동질감도 느끼면서 소통하고 공감하고 싶고, 그러면서 또 자기만의 공간과 시간속에 자유를 느끼고 싶어하기도 하는 모순되고 미스테리어스한 욕구와 욕망 덩어리가 바로 인간이지요. 샬럿은 “삶의 의미와 목적”을 찾기위해 책을 읽어보기도 하지만 자신만의 답을 못찾고 있고, 밥은 노래방에서 (이해하기) 어려운 노래(hard song)라면서 “삶은 무의미해요. 바람처럼, 파도처럼…” 가사의 노래를 불러요. 이런게 바로 우리 인간의 모습이잖아요.
외로움에 치를 떠는 샬럿(Scarlett Ingrid Johansson)과 밥이 서로를 첫눈에 알아보고 또 빠르게 가까워졌던걸 보면 사람에게는 직감적으로 서로의 욕구 결핍을 알아채는 능력이 있는것 같아요. 마치 자석의 N극과 S극이 말하지 않아도 자신에게 없는 반쪽을 서로 끌어당기듯이 말이예요.
샬럿은 결혼 2년차, 밥은 결혼 25년차예요. 대충 계산해보면 샬럿은 26살(?), 밥은 50살(?) 정도 되겠네요. 나이 차이가 띠동갑(24살?) 인데도 서로 말이 통하고, 서로에게 끌릴 수 있다는게 신기해요. 5살 차이만 나도 서로의 공통 관심사가 다르고, 10살 차이만 나도 세대차이나서 10분 이상 같이 있기도 힘들것 같은데 말이지요.
그런데 둘이 대화하는 것을 가만히 들어보면 이해가 되기도 해요. 서로 각자의 속마음, 감정을 솔직하게 얘기해요. 그리고 서로의 말에만 집중하면서 잘 들어주고요. 영어로된 영화 포스터에 보면 상단에 "Everyone wants to be found"라는 문구가 있어요. 우리는 누구나 다 외롭고, 그래서 누군가가 내 얘기를 들어줬으면 하고, 또 누군가의 얘기를 듣고 싶어하잖아요. 마치 샬럿과 밥이 그렇듯이요.
밥이 샬럿에게 해줬던 말들 중에 샬럿에게 울림이 있었던 말들이 있었을거 같아요.(대사가 정확하지 않을 수 있어요. 기억이 가물가물….)
“전 엘리베이터에서 당신을 처음 봤어요. 그때 당신은 환하게 웃었는데… 그 이후로 당신이 그처럼 웃는 모습을 못봤어요. 자 웃어봐요.”
“살면서 내가 누구인지를 알아가고, 내가 원하는 것이 무엇인지를 알면 삶이 좀더 편해져요.”
…
샬럿과 밥이 서로 얘기하는 장면들은 이전의 샬럿의 전화 통화, 그리고 밥의 전화 통화 장면과 크게 대비가 돼요.
샬럿이 눈물을 흘리면서 전화로 엄마에게 말해요. “오늘 절에 갔는데 아무것도 느껴지지 않았어요.” 무언가 느껴지지 않는다는건 살아있는것 같지 않다는 절망의 표현일텐데… 하지만 대화는 여기서 끝나요. 전화 건너편의 엄마는 “I’ve got to go. Talk to you later” 라면서 전화를 끊어요. 그리고 이런 패턴이 계속 반복이 돼요. 샬럿의 남편은 독백하듯이 일 얘기만 하다가, “오늘은 하루 쉬면 안돼?”라며 외로움에 힘겨워하는 SOS를 치는 샬럿을 뒤로하고 부랴부랴 또 일하러 떠나요. 말로는 사랑한다고 하고 키스를 하지만, 같이 있어도 외로워하는 샬럿의 마음을 모르는 것 같아요. “Lost in Translation” 이예요.
이런 패턴은 밥도 마찬가지예요. 밥과 아내가 전화통화를 하다보면 아이들 얘기 80%, 인테리어 얘기 19%, 밥의 감정 1% 얘기(“나에 대해 걱정해줄 시간이 있기는 하구?”)하려고 하면 아내는 “I’ve got to go. I’ll call you later. Bye” 하면서 전화를 끊어버려요. 속깊은 얘기로 더 들어가지 못하고, 더 이상의 대화를 회피하면서 전화가 끝나요. 직면할 수 있는 용기가 부족하기 때문일까요, 아니면 대화하는 방법을 배우지 못해서 일까요. 이런 장면들은 저를 되돌아보게 하기도 해요.
밥이 결혼 25년차라고 하니 샬럿이 웃으면서 말해요. “그러면 당신은 분명 중년의 위기를 겪고 계시겠군요.” 라구요. 저도 나이를 먹고보니 “중년의 위기”라는 말이 귀에 쏙 들어오더군요. ㅎㅎ “위기”라는 말이 “위협과 기회”를 둘 다 내포하고 있는 말이잖아요. “중년의 위기”는 인생의 반환점에 전반기를 뒤돌아보고, ‘앞으로도 지금처럼같이 살 것인가?’라는 고민속에 후반기의 삶을 그려보는 시간이기에 참 귀한거 같아요. 나이 든다는 것에는 ‘젊음’의 눈부신 아름다움과 원기충만함을 잃어간다는 슬픔도 있지만, 또 품격과 여유 그리고 자신의 삶을 스스로 인식하고 더 지혜롭게 통제하고 누리고, 또 뭔가를 생산하면서 기여를 할 수있다는 분명한 혜택도 있어요.
샬럿이 이어서 물어봐요. “그래서 포르쉐는 사셨어요?” 라고요. ㅎㅎ누군가에게는 포르쉐가 로망일 수도 있고, 또 누군가는 포르쉐타는 사람을 보면서 세상사람 시선에 목말라하는 속물이라고 생각할수도 있을텐데요, 중년의 좋은 점 중의 하나가 자신의 욕망에 솔직하고 또 그걸 지를 수 있는 경제적이고 심리적인 능력과 용기(객기?) 아니겠어요?! 아, 저도 포르쉐 사고 타보고 싶어요. ㅋㅋ
영화를 다 보고 나서 ‘이 영화 여성감독이 만들었을것 같아’라는 생각이 들더군요. 검색해보니 Sofia Coppola 여성감독이던데요, 이 영화의 각복도 직접 썼어요. 어쩐지 미묘한 감정의 디테일이 대사나 화면에 살아있더라니!
왼쪽 사진의 여성 감독이 바로 Sofia Coppola 예요. 패션 디자이너에 모델로도 활동하고 있다니 다재다능한 분이예요.
영화 대부의 감독 포드 코폴라 감독의 외동딸이라네요. (대부3에 배우로도 출연했다고 하는데, 배우로서는 혹평을 받았다고 해요. 이때의 혹평 덕분에(?) 각본가 겸 영화감독으로 전향(?) 한거 같아요. 인생은 새옹지마!)
영화의 제일 마지막 장면에 리무진을 타고 공항으로 향하던 밥은 쓸쓸히 거리를 혼자 걷고 있는 샬롯을 보고는 리무진에서 내려 샬롯에게 향해요. 그리고는 샬롯을 꼬옥 껴안고서 귓속말로 무어라 말하고는 굿바이 인사를 하고 다시 각자의 일상으로, 각자의 가족에게로 돌아가지요. 이때 밥이 샬롯에게 귓속말로 무어라고 말했을지 궁금해요. 둘이 편안하게 씨익 웃었던걸 보면 혹시 이렇게 말하지 않았을까 상상해봐요.
“샬롯, 당신과 함께한 며칠이 내겐 너무나 행복하고 소중했어요. 만나면 설레고, 그래서 내가 살아있음을 느꼈어요. 함께 했던 순간 순간들이 그리울 거예요. 당신은 이쁘고 아직 젊어요. 당신이 하고 싶은걸 찾아서 해봐요. 계속 글도 쓰고요. 당신은 웃을 때가 더 이뻐요. 자, 한번 웃어봐요.” 뭐, 이렇게 말하지 않았을까요? ㅎㅎ 아니면 말고요.
둘은 이렇게 헤어졌고 각자의 길을 가겠지요. Life goes on. 샬롯과 밥의 삶, 가정은 이전과 같았을까요, 아니면 달라졌을까요?
ps. 스칼렛 요한슨하면 영화 ‘어벤져스’의 액션 히어로, 여전사로서의 ‘블랙위도우’가 떠올랐는데요, 이 영화를 보고 난 후로는 호텔 창가에 걸터앉아 빌딩숲을 쳐다보고 있는, 헤드폰을 끼고 버스를 타고 있는, 도시를 홀로 걷고 있는, 노래방에서 난 특별해라며 유혹하는 노래를 부르는, 외로우면서도 매력적인 여성으로서의 ‘샬럿’이 먼저 떠오를것 같아요. 스칼렛 요한슨이 이렇게 매력적인 배우였다니!!!
페이스북에서 제가 팔로우하면서 평소 즐겁고 유익하고 보고 있는 신수정님께서 그동안 써놓으셨던 글들 중에서 추려서 책으로 출간하셨다는 소식을 보고, 바로 사서 읽게 되었습니다. 그동안 페이스북에서 제가 ‘좋아요’를 가장 많이 누른 분이 신수정님이므로 이 책이 세상에 나오는데 저도 아주 미약하나마 힘을 보탠 셈입니다.(숟가락 얹기 신공.. ㅋㅋ) ^^v
일의 격, 신수정, 턴어라운드
이 책은 표지와 부제목에서도 알 수 있듯이, (1) 성장하는 나, (2) 성공하는 조직, (3) 성숙한 삶의 3 파트로 구성이 되어있으며, 글들이 1~2 페이지로 읽기에 부담없는 길이로 되어 있으며, 매 문단마다 숫자로 번호가 매겨져 있습니다. (페이스북에 글 올리시는 포맷 그대로 유지). 저는 (3) 성숙한 삶 파트를 가장 재미있게 음미하면서 읽었습니다. 책 읽는 분들마다 목차를 보면서 가장 땡기는 부분 먼저 부담없이 읽어나가도 아무런 문제가 없는데요, 그게 이 책의 좋은 점 중의 하나예요.
책 내용이 이론적인면과 현실적인 면이 잘 균형을 이루고 있어서 책을 읽다보면 수긍이 많이 갑니다. 책 내용이 설득력 있을 수 있는 이유 중의 하나가 신수정님의 인생 미션과 독특한 이력에 기인한다고 생각해요. 아래는 책의 서문에 나오는 저자 소개 글이예요.
“신수정, 현재 KT의 Enterprise 부문장을 맡고 있다. 공학과 경영학을 전공하였고 글로벌 기업, 창업, 벤처, 중견기업, 삼성, SK 등 다양한 기업들을 거치며 일, 리더십, 경영 역량을 쌓았다. 인간을 이해하는 데 관심이 많아 다양한 코칭, 심리, 자기계발 코스를 수료하였다. 삶, 일, 경영과 리더십에 대한 통찰을 나누어 사람들에게 파워와 자유를 주고 한계를 뛰어넘는 비범한 성과를 만들도록 돕는 선한 영향력을 추구하는 것을 삶의 미션으로 삼는다. Inspiring coach 이자 Leader 로 스스로의 역할을 정의한다.”
이처럼 저자의 다양한 경험과 학습으로 부터 나오는 연결과 공감의 힘, 어느 극단으로 치우침없는 균형과 절제의 미덕은 이 책은 큰 차별화 요소입니다. 실리콘밸리의 첨단 기업경영 기법, 조직문화, 방법론 등을 무비판적으로 선진사례라면서 받아들이기 보다는 Context, 자기 회사의 실력을 감안해서 비판적으로 받아들일 것을 강조합니다.
저자는 젊었을 때 신학자, 목사가 되고자 성경공부에 매진했던 경험도 있어서 책의 여기 저기에 성경 말씀을 인용하고 있는데요, 적재적소에 설명과 함께 인용하다보니 종교가 무엇이든지 간에 거리낌 없이 받아들일 수 있다는게 좀 신기하기는 해요. 가령, “비둘기처럼 순수하되 뱀처럼 지혜로워라”라는 성경 말씀을 인용하면서, 직장이나 조직에서 뭔가 성과를 이루고 변혁을 만들려면 순수한 의도 못지않게 이를 추진할 수 있는 정치력, 냉철함, 손에 진흙 뭍히기를 주저하지 않는 추진력이 필요하다고도 말합니다.
책 내용과 주제가 워낙 방대해서 요약해서 정리하기는 어려울거 같구요, 인상깊었던 내용이나 구절 몇 개 맛보기로 소개해봅니다.
1장. 성장 (成長) : 일의 성과를 극대화 시키는 기술
‘성공의 가장 큰 적은 실패가 아닌 지루함’
1. 한 책(‘아주 작은 습관의 힘’, 제임스 클리어, 비즈니스북스, 2019)을 읽다보니 이런 이야기가 나온다. 작가는 유명 코치에게 물었다. “뛰어난 선수와 보통 선수의 차이는 무엇인가요?” 능력, 운 이런 답을 기대했는데 코치는 이렇게 답했다. “지루함을 견디는 것입니다. 매일매일 훈련하다 보면 어느 시점 지루해집니다. 보통 선수는 이 지루함을 이기지 못하고 훈련을 소홀히 하기 시작합니다.”
2. 아마추어는 기분 좋을 때만 훈련한다. 보통 선수는 매일 훈련하지만 지루할 때면 대충 한다. 그러나 뛰어난 선수는 상관없이 훈련한다.
정말 그런거 같아요. 저도 처음엔 타고난 능력, 운 이런게 제일 먼저 떠올랐는데요, '지루함을 이기고 꾸준히 나아갈 수 있는 힘'이 차이를 만든다는 통찰. 요즘 일본에서 올림픽이 시작되어서 금메달을 딴 선수들의 훈련 이야기가 많이 나오게 될텐데요, 이들도 '지루함을 이겨내고 자신과의 싸움에서 이긴 선수들' 이겠지요. 피겨퀸 김연아 선수도 그렇고, 프리미어리그의 손흥민 선수도 그렇고, 모두 지독한 연습벌레 였다는 얘기는 많이 들어보셨을거 같아요.
이처럼 '독서광', '책 중독'에 빠져 있는 저자 덕분에 다양한 분야의 책들에서 뽑은 인사이트를 저자가 자신의 경험과 해석을 더해서 떠먹기 좋게 밥상을 떠억하고 차려놓았답니다.
‘바쁜 사람은 항상 바쁘다’
3. 가끔 ‘저는 너무 바빠요. 좀 여유롭게 일할 수 없을까요?’라고 상담하는 분들을 만난다. 그런데 흥미롭게도 이런 분들의 상당수는 여유를 부릴 수 있는 환경에서조차 스스로를 바쁘게 굴린다는 것을 발견했다. 이에 대개 (항상은 아니다) 바쁜 사람은 여유로운 일을 맡아도 바쁘고, 여유로은 사람은 정신없는 일을 맡아도 여유롭다.
이 또한 정말 그런거 같아요. 중요한 일과 그렇지 않은 일을 구분하지 못하고 다 똑같이 전력질주 한다거나, 위임하지 못하고 혼자서 다 하려한다거나, 안해도 되는 일을 하면서 안바빠도 되는데 바쁘면서 ‘오늘도 열심히 살고 있구나’ 하고 자기위안을 삼고 있는건 아닌지 되돌아보게 되더군요.
‘과연 연주를 가장 잘 하는 연주자가 최고의 성공을 할까?’
3. 포뮬러라는 책을 읽으니 이런 내용이 나온다. 런던의 한 연구팀은 클래식 경연 대회에 결선에 오른 세 사람 중 누가 우승할지 한 집단에는 소리만 들려주고, 또 한 집단은 연주 모습과 소리를 같이 들려주고, 또 한 집단은 소리는 끈 채 연주 모습만 보여주었다. 이 평가 집단은 아마추어와 프로 심사원들로 구성했다.
4. 당연히 연구팀은 소리만 들려준 그룹이 가장 정확할 것이라 예상했으나 결론은 그렇지 않았다. 흥미롭게도 아마추어 심사원이든 프로 심사원이든 소리를 끈 채 연주 모습만을 보여준 그룹이 우승자를 가장 높은 확률로 맞추었다. 소리만이 실제 경쟁력이 아니었다는 이야기이다.
이 또한 놀라운 통찰력 아닌가요? 실력만 중요한게 아니라 보이는 모습도 중요하다는 점이요. 실력만이 중요하다고 여기고 외모, 패션, 제스쳐, 포즈, 성량… 등 보여지는 모습에서 우러나는 매력도 무시 못할만큼 중요하다는 점은 인정하기 좋든 싫든 사람들에게 작동하고 있는 현실이라는 점을 인식하고 가꾸는 노력도 필요하겠습니다. 나이를 한참이나 먹은 저도, 이젠 외모와 패션에 신경을 좀 쓰면서 다닙니다.
여기서 잠깐, 인상적인 글이 너무 많아서 몇 개 추려서 쓰려고 하다 보니 책 내용 인용으로 블로그 포스팅이 도배가 될 거 같아서 여기서 그만 하렵니다. ^^;
저자가 애정을 가지고 썼다는 ‘우연과 필연’에 대한 부분, 성공하는 사람의 특징으로 아마존의 제프 베조스가 했다는 말을 인용했던 부분 (하나만 고집하는 것이 아니라 새로운 정보가 추가로 수집되면 이 피드백을 반영해서 필요 시 방향을 바꿀 줄 아는 사람) 의 경우 통계학을 전공한 사람한테는 확률론이라는 매우 익숙한 개념이예요. 베이지언 통계학(Bayesian inference)이 다루는 게 선험적인 경험과 지식(prior probability)에 더해서 새로 획득한 데이터로 부터 얻은 정보를 업데이트 해서 새로운 확률(posteria probablity)을 계산하고, 이에 기반해서 의사결정을 하는 것이 거든요. 위대한 철학과 사상들 끼리는 만나는 지점이 있다니깐요. 비록 사용하는 언어는 다르더라도 말이지요.
SW 개발 방법론에 '애자일 개발 방법론 (Agile methodology )' 이라고 있는데요, Pivotal Labs 에서 실리콘밸리의 테크 기업들을 대상으로 전파해온 방법론도 애플리케이션의 핵심 효용과 가치를 담을 수 있는 최소한의 기능과 UI/UX를 담은 MVP(Minimum Viable Product) 를 정의해서 빨리 서비스를 최종사용자를 대상으로 론칭을 하고, 이로부터 피드백을 받아 애플리케이션을 업그레이드 하는 반복 과정(iteration cycle, process)을 빨리, 여러번, 반복적으로 하면서 하라는 것과 일맥 상통합니다. 기존의 Waterfall 방법론에서 하는 것처럼 완벽한(?) 마스터플랜 하에 순차적으로 진행하는 것보다, 빨리 실패하고 그로부터 빨리 배워서, 빨리 적응하고, 필요하면 Pivot(방향 전환)을 할 수도 있는 것이 더 효과적이고 효율적이라는 것이지요.(Pivotal 은 작년에 VMware로 인수합병되었고, Pivotal Labs는 VMware Labs로 이름이 바뀌었습니다.)
저는 저자가 딱딱한 경영학 기술, 기법에만 의존하지 않고 심리학, 상담, 코칭 등에 대해서도 책도 많이 읽으시고, 세미나도 참석하시고, 코칭도 받아보면서 쌓은 경험과 지식을 더해서 개인, 조직의 성장과 성공에 대해 얘기하고, 더 나아가 성숙과 품격의 단계까지 다같이 올라가기를 조언하는 모습이 보기 좋고 그래서 더 효과적인거 같아요. 다른 경영학 책들은 사람 냄새가 안나거든요.
특히, 아들러 심리학에서 말하는 나 자신의 선택과 책임, 자유, 남들로 부터 미움받을 용기에 대해서 책의 이곳 저곳에서 반복해서 소개해주는게 좋더라구요. ‘잘 안돼도 괜찮아. 나는 지금 이대로도 사랑받을 가치가 있는 존재야’라며 매사에 너무 심각하지 말고, 잘 안돼도 다시 일어서서 앞으로 나아가고, 남에게 인정받기 위해 눈치보지 말고, 있는 그대로의 나를 사랑할 줄 알아야 매 순간 행복을 느끼면서 살 수 있다고 말해줄 때는 이 시대가 필요로 하는 상담가, 날 위로해주는 어른 같습니다.
저자는 글을 꾸준히 쓰기 위한 마음가짐, 태도에 대해서 말씀해주시는데요, 너무 길게, 잘 쓰려, 완벽하려 하지 말고, 일단 짧게라도 꾸준하게 쓰기를 강조해요. 유명하지 않으면 누가 신경쓸 사람도 없고, 자꾸 글을 쓰다보면 글쓰는 힘과 실력이 쌓이니깐요. ‘축적과 발산’의 관점에서 보면 글쓰기도 예외는 아니어서, 일단 많이 읽고 또 쓰면서 실력을 축적하고, 그 중에서 사람들이 공감하는 글이 빛을 발하면서 발산하는 시점이 오기를 준비하라는 것이지요.
이 글을 읽었을 때 일주일에 하나씩 꾸준히 블로그 포스팅하고 있는 제 자신이 자랑스러웠습니다. 블로그 포스팅 하나 하려면 공부하고, 코딩하고, 도식화해서 파워포인트 슬라이드로 정리하고, 글쓰고 하는데 3~4시간씩 걸리거든요. 블로그 포스팅을 매 주말마다 5년째 해오고 있으니 나름 뿌뜻해요.
독서후기가 일관된 스토리가 없이, 주저리 주저리, 왔다갔다 한거 같아요. ^^;
요약하자면, 책 값 하나도 안 아까우니 목차 한번 보시고 마음에 드시면 책 사서 일독 권합니다.
페이스북에서 그동안 쭉 봐왔던 글들인데도 다시 책으로 묶여진 내용을 다시 보니 또 새롭고, 와닿고 그래요.
(인간은 망각의 동물!)
ps. 이 책의 폰트가 너무 작아서요, 책 읽는 내내 ‘그래, 나 노안이 왔지!’를 상기시켜주어서 속상하더군요. 출판사 편집자가 테스트 리딩 몇 명 해봤다면 폰트 크기 키우라는 피드백을 분명 받았을거 같은데요, 좀 아쉽습니다. 폰트 키우고 문장 간 간격 줄이면 책 페이지 수가 많이 늘어날것 같지는 않습니다.
ps. 책 표지도 우중충 하고, 책 제목 '일의 격'도 맨날 일만 하는 회사원 대상으로 쓴 재미없는 책처럼 보여요. 제 와이프랑 제 딸한테 재미있으니 읽어보라고 권했더니 표지랑 제목을 보고서는 도망갈라고 그래요. 저자는 생각하고 행동하는 방식이나, 만나는 사람들을 보면 제가 아는 어느 누구보다 젊게 사는 분이세요. 하지만 책 표지나 제목은 너무 나이든 티를 팍팍 내셨다는 생각이 들어요. 너무 엄격하고, 무겁고, 진지하고, 딱딱하기만 하고, 힘이 너무 들어가 있고... 40대 직딩 아저씨 타켓이라면 잘 소구하는 편이구요, 그게 아니라면 솔직히 세련된 멋이 없고 formal 하게 느껴져요. -_-;
ps. 책 페이지 마다의 제일 마지막 한 두줄에는 상당한 위트와 엑기스가 녹아들어가 있어요. 질문으로 끝나는 경우도 많아서 다음 장으로 바로 못 넘어가고 제 자신을 되돌아보면 생각하게끔 하기도 해요. 이 책을 읽는 솔솔한 재미 중의 하나가 제일 마지막줄 읽는 것이었어요. 이제 여러분 차례네요. Enjoy reading! Happy reading!!!
이번 포스팅에서는 시계열 자료 예측 모형의 성능, 모델 적합도 (goodness-of-fit of the time series model) 를 평가할 수 있는 지표, 통계량을 알아보겠습니다.
아래의 모델 적합도 평가 지표들의 리스트를 살펴보시면 선형회귀모형의 모델 적합도 평가 지표와 유사하다는 것을 알 수 있습니다.(실제값과 예측값의 차이 또는 설명비율에 기반한 성능 평가라는 측면에서는 동일하며, 회귀모형은 종속변수와 독립변수간 상관관계에 기반한 반면에 시계열 모형은 종속변수와 자기자신의 과거 데이터와의 자기상관관계에 기반한 다는것이 다른점 입니다.)
아래 평가지표들 중에서 전체 분산 중에서 모델이 설명할 수 있는 비율을 나타내는 수정결정계수는 통계량 값이 높을 수록 좋은 모델이며, 나머지 오차에 기반한 평가 지표(통계량)들은 값이 낮을 수록 상대적으로 더 좋은 모델이라고 평가를 합니다. (단, SST는 제외)
이들 각 지표별로 좋은 모델 여부를 평가하는 절대 기준값(threshold)이 있는 것은 아니며, 여러개의 모델 간 성능을 상대적으로 비교 평가할 때 사용합니다.
- 전체제곱합 (SST, total sum of square)
- 오차제곱합 (SSE, error sum of square)
- 평균오차제곱합 (MSE, mean square error)
- 제곱근 평균오차제곱합 (RMSE, root mean square error)
- 평균오차 (ME, mean error)
- 평균절대오차 (MAE, mean absolute error)
- 평균비율오차 (MPE, mean percentage error)
- 평균절대비율오차 (MAPE, mean absolute percentage error)
- 수정결정계수 (Adj. R-square)
- AIC (Akaike's Information Criterion)
- SBC (Schwarz's Bayesian Criterion)
- APC (Amemiya's Prediction Criterion)
[ 시계열 데이터 예측 모형 적합도 평가 지표 (goodness-of-fit measures for time series prediction models) ]
goodness-of-fit measures for time series models
1. 전체제곱합 (SST, total sum of square)
total sum of square, SST
SST는 시계열 값에서 시계열의 전체 평균 값을 뺀 값으로, 시계열 예측 모델을 사용하지 않았을 때 (모든 모수들이 '0' 일 때) 의 오차 제곱 합입니다. 나중에 결정계수(R2), 수정결정계수(Adj. R2)를 계산할 때 사용됩니다. (SST 는 모델 성능 평가에서는 제외)
2. 오차제곱합 (SSE, error sum of square)
error sum of square, SSE
3. 평균오차제곱합 (MSE, mean square error), 제곱근 평균오차제곱합 (RMSE, root mean square error)
root mean squared error
MSE는 많은 통계 분석 패키지, 라이브러리에서 모델 훈련 시 비용함수(cost function) 또는 모델 성능 평가시 기본 설정 통계량으로 많이 사용합니다.
RMSE (Root Mean Square Error) 는 MSE에 제곱근을 취해준 값으로서, SSE를 제곱해서 구한 MSE에 역으로 제곱근을 취해주어 척도를 원래 값의 단위로 맞추어 준 값입니다.
4. 평균오차 (ME, mean error)
mean error
ME(Mean Error) 는 MAE(Mean Absolute Error)와 함께 해석하는 것이 필요합니다. 왜냐하면 큰 오차 값들이 존재한다고 하더라도 ME 값만 볼 경우 + 와 - 값이 서로 상쇄되어 매우 작은 값이 나올 수도 있기 때문입니다. 따라서 MAE 값을 통해 실제값과 예측값 간에 오차가 평균적으로 얼마나 큰지를 확인하고, ME 값의 부호를 통해 평균적으로 과다예측(부호가 '+'인 경우) 혹은 과소예측(부호가 '-'인 경우) 인지를 가늠해 볼 수 있습니다.
5. 평균절대오차 (MAE, mean absolute error)
mean absolute error
6. 평균비율오차 (MPE, mean percentage error)
mean percentage error
위의 ME와 MAE 는 척도 문제 (scale problem) 을 가지고 있습니다. 반면에 MPE (Mean Percentage Error)와 MAPE (Mean Absolute Percentage Error) 는 0~100%로 표준화를 해주어서 척도 문제가 없다는 특징, 장점이 있습니다. 역시 MAE 와 MAPE 값을 함께 확인해서 해석하는 것이 필요합니다. 0에 근접할 수록 시계열 예측모델이 잘 적합되었다고 평가할 수 있으며, MAE의 부호(+, -)로 과대 혹은 과소예측의 방향을 파악할 수 있습니다.
7. 평균절대비율오차 (MAPE, mean absolute percentage error)
mean absolute percentage error
8. 수정결정계수 (Adj. R-square)
adjusted R2
결정계수 R2 는 SST 에서 예측 모델이 설명하는 부분의 비율(R2 = SSR/SST=1-SSE/SST)을 의미합니다. 그런데 결정계수 R2는 모수의 개수가 증가할 수록 이에 비례하여 증가하는 경향이 있습니다. 이러한 문제점을 바로잡기 위해 예측에 기여하지 못하는 모수가 포함될 경우 패널티를 부여해서 결정계수의 값을 낮추어주게 수정한 것이 바로 수정결정계수(Adjusted R2) 입니다. (위의 식에서 k 는 모델에 포함된 모수의 개수를 의미합니다.)
위의 2~7번의 통계량들은 SSE(Error Sum of Square)를 기반으로 하다보니 값이 작을 수록 좋은 모델을 의미하였다면, 8번의 수정결정계수(Adj. R2)는 예측모델이 설명력과 관련된 지표로서 값이 클 수록 더 좋은 모델을 의미합니다.(1에 가까울 수록 우수)
9. AIC, SBC, APC
AIC (Akaike's Information Criterion),
SBC (Schwarz's Bayesian Criterion),
APC (Amemiya's Prediction Criterion)
AIC, SBC, APC
위의 AIC, SBC, APC 지표들도 SSE(Error Sum of Square) 에 기반한 지표들로서, 값이 작을 수록 더 잘 적합된 모델을 의미합니다. 이들 지표 역시 SSE 를 기본으로 해서 여기에 모델에서 사용한 모수의 개수(k, 패널티로 사용됨), 관측치의 개수(T, 관측치가 많을 수록 리워드로 사용됨)를 추가하여 조금씩 변형을 한 통계량들입니다.
다음번 포스팅에서는 이들 지표를 사용해서 Python으로 하나의 시계열 자료에 대해 여러 개의 지수 평활법 기법들을 적용해서 가장 모형 적합도가 높은 모델을 찾아보겠습니다.(https://rfriend.tistory.com/671)
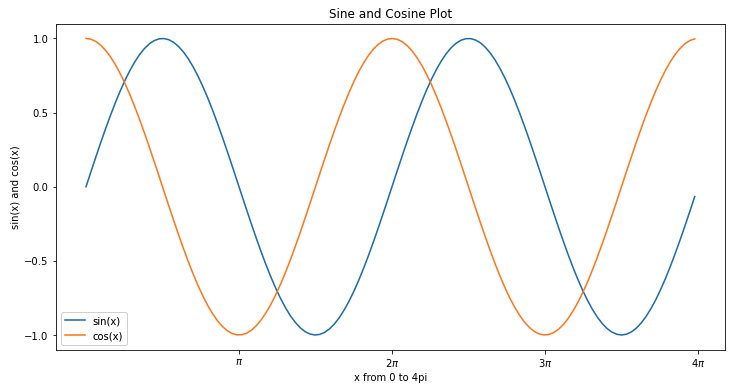
이번 포스팅에서는 Python 의 matplotlib 라이브러리를 사용해서 사인 곡선, 코사인 곡선을 그려보겠습니다.
(1) matplotlib, numpy 라이브러리를 사용해서 사인 곡선, 코사인 곡선 그리기
(Plotting sine, cosine curve using python matplotlib, numpy)
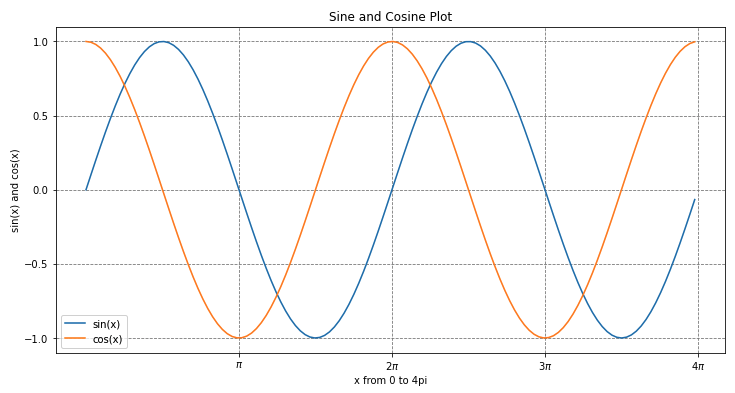
(2) x축과 y축의 눈금값(xticks, yticks), 범례(legend) 를 설정하기
(3) 그래프에 가로, 세로 그리드 선 추가하기 (adding grid lines)
이번 포스팅은 그리 어렵지는 않은데요, 눈금값, 범례, 그리드 선 추가와 같은 소소한 팁들이 필요할 때 참고하라고 정리해 놓습니다.
(1) matplotlib, numpy 라이브러리를 사용해서 사인 곡선, 코사인 곡선 그리기
(Plotting sine, cosine curve using python matplotlib, numpy)
numpy 로 0부터 4 pi 까지 0.1씩 증가하는 배열의 x축 값을 만들고, 이들 값들을 대입하여서 사인 y값, 코사인 z값을 생성하였습니다.
이들 x 값들에 대한 사인 y값, 코사인 z값을 가장 간단하게 matplotlib 으로 시각화하면 아래와 같습니다.
import numpy as np
import matplotlib.pyplot as plt
# using Jupyter Notebook
%matplotlib inline
## generating x from 0 to 4pi and y using numpy library
x = np.arange(0, 4*np.pi, 0.1) # start, stop, step
y = np.sin(x)
z = np.cos(x)
## ploting sine and cosine curve using matplotlb
plt.plot(x, y, x, z)
plt.show()
(2) x축과 y축의 눈금값(xticks, yticks), 범례(legend) 를 설정하기
위의 (1)번 사인 곡선, 코사인 곡선을 보면 그래프 크기가 작고, x축 눈금값과 y축 눈금값이 정수로 되어있으며, x축과 y축의 라벨도 없고, 범례가 없다보니 사인 곡선과 코사인 곡선을 구분하려면 신경을 좀 써야 합니다.
제가 소설 쓰는 작가 지망생은 아니지만, 호기심이 발동하여 스티븐 킹(Stephen King)의 "유혹하는 글쓰기 (On Writing)" (김진준 옮김, 김영사, 2002) 책을 읽어보았습니다.
네, 맞습니다. 샤이닝(The Shining), 쇼생크 탈출(The Shawshank Redemption), 캐리(Carrie), 미저리(Misery), 그린 마일(The Green Mile), 그것(It) 등 우리가 이미 익숙하게 알고 있는 영화들의 원작 소설 작가가 바로 스티븐 킹입니다.
이 소설가가 글쓰기, 창작론에 대한 글을 썼습니다. 이미 엄청난 소설의 인세 만으로도 엄청난 수익을 올리고 있어서 굳이 "유혹하는 글쓰기"라는 창작론을 쓰지 않아도 될텐데 말이지요. 머리말에 스티븐 킹이 이 책에 대해 뭐라고 말하고 있는지 한번 들어볼까요?
"나처럼 많은 소설책을 팔아먹은 사람은 글쓰기에 대하여 '뭔가' 할 말이 있을 것이라고 쉽게 생각할 수도 있겠다. 그러나 쉬운 답이 항상 옳은 것은 아니다. 가령 샌더스 대령(케이에프씨)이 엄청난 양의 닭튀김을 팔아치웠지만 그 과정에 대해 알고 싶어 할 사람은 별로 없을 듯 하다. 주제넘게 글쓰기에 대해 말하겠다고 나서려면 적어도 대중적인 성공보다 더 그럴듯한 이유가 있어야 할 것 같았다. 다시 말해, 이렇게 짤막한 책일망정 혹시라도 나중에 내가 무슨 문단의 허풍쟁이나 고상한 체하는 얼간이처럼 취급받고 싶지 않았다. 그런 책이나 작가라면 이미 세상에 숱하게 널려 있다. ..그러나 문장에 대하여 묻는 사람은 아무도 없다. 델릴로나 업다이크나 스타이런 같은 작가에게는 물어보지만 대중소설가에게는 묻지 않는다. .. 이제부터 나는 내가 창작을 하게 된 과정, 지금 내가 창작에 대해 알고 있는 것들, 그리고 창작의 방법 등에 대하여 말해보려고 한다. 이것은 내 본업에 대한 책이며 문장에 대한 책이다." - 머리말 중에서
스티븐 킹의 창작론, 유혹하는 글쓰기
이 책은 크게 아래와 같이 4개의 챕터로 구성되어 있습니다.
"글 쓰기에 대한 책에는 대개 헛소리가 가득하다. 그래서 이 책은 오히려 짧다.나를 포함하여 소설가들은 자기들이 하는 일에 대하여 그리 잘 알지 못한다. 소설이 훌륭하거나 형편없다면 그것이 무엇 때문인지 모르는 것이다. 그래서 나는 책이 짧을수록 헛소리도 줄어들 것이라고 생각한다." - 머리말 둘
(1) 이력서: 스티븐 킹이 작가가 되기까지의 과정을 자서전 형식으로 서술한 부분
(2) 연장통: 창작에 필요한 자세와 작가로서 갖추야 할 기본적인 도구들을 이야기한 부분
(3) 창작론: 창작의 방법을 구체적으로 설명한 부분
(4) 인생론: 이 책을 쓰는 도중에 일어났던 교통 사고와 그 결과로 얻은 깨달음을 이야기한 부분
저는 이들 4개 챕터 중에서 (1) 이력서 부분을 가장 재미있게 읽었습니다. 대신 (2) 연장통, (3) 창작론은 좀 재미없게, 더디게 읽었어요. 아무래도 제가 글쓰는 작가가 되어보려고 이 책을 읽었던게 아니다 보니 아무래도 관여도나 몰입도가 떨어지는건 어쩔 수 없더군요. ^^; (4) 인생론을 읽을 때는 산다는게 뭔지에 대해서 곰곰히 생각해 보게 되더군요.
(1) 이력서 부분을 읽을 때 정말 많이, 크게, 눈물까지 흘리면서 웃으면서 읽었습니다. 책을 읽으면서 이렇게 배꼽을 잡고 눈물 흘리면서 웃어제끼면서 책을 읽었던 적이... 이 책 말고는 기억이 없습니다. 저는 아직까지 스티븐 킹의 소설 원작을 읽어본 적은 없는데요, 이 책을 보고 나서는 스티븐 킹의 소설을 찾아 읽어보고 싶어졌습니다.
가령, 여러 재미있는 에피소드 중에 하나만 소개해보자면요,
" (중략) 나는 볼일을 마치고 형이 가르쳐준 대로 뒤처리를 했다. 윤기 흐르는 푸른 잎을 잔뜩 뜯어 밑을 닦은 것이다. 그런데 그게 하필이면 덩굴옻나무였다. 이틀 후 나는 무릎 뒤에서부터 어깨뼈까지 온몸이 새빨갛게 물들었다. 고추는 무사했지만 볼알은 두 개의 정지 신호등으로 바뀌었다. 엉덩이에서 갈비뼈까지 안 가려운 곳이 없었다. 그러나 그중에서도 최악이었던 것은 그날 사용한 손이었다. 그 손은 도널드 덕의 망치에 얻어맞은 미키 마우스의 손만큼 크게 부어올랐고, 손가락끼리 스치는 부위마다 거대한 물집이 일어났다. 물집이 터지면 빨간 생살이 드러났다. 그로부터 6주 동안은 녹말을 푼 미지근한 물 속에서 좌욕을 했다. 나만 바보가 된 기분, 정말 비참하고 모욕적이었다. 열린 문틈으로 어머니와 형이 카드놀이를 하며 웃고 떠드는 소리, 그리고 라디오에서 피터 트립이 히트곡을 발표하는 소리가 들려왔다." - p35
스티븐 킹은 어렸을 때 귀와 편도선에 병이 심해서 학교를 1년 쉰 적이 있더군요. 1년을 쉬는 동안에 만화책, 소설책을 닥치는 대로 읽었고, 아마도 그때의 인풋이 훗날 공포 소설의 왕이 되는데 큰 자양분이 되었을 것입니다.
만약 제가 어렸을 때 몸이 아파서 학교에 1년 못가게 되었다면 또래 친구들에게 뒤떨어지고, 사회에서 낙오되고, 인생의 큰 흠집이라고 여기고 안절부절 했을 것 같습니다. 인생 길게보면 정말 "인생지사 새옹지마" 인데 말이지요. 인생 살아오면서 일어나는 크고 작은 일들이 하나의 점이 되고 쌓여, 나중에는 그 점들이 연결이 되면서 선이 되고 면이 되고 하잖아요. 모든 순간이 허투루 지나가는 일이 없고, 그게 다 나중의 내가 되는 것을요. 뭔일 일어났다고 호들갑 떨지 말고 좀더 세상 살이에 편안해지는게 좋겠다는 생각이 들었습니다.
스티븐 킹의 이력서 부분에 소개된 다사다난했던 사건 사고들을 보자니 '이렇게 파란만장하고 재미나게 살았기 때문에 사람들을 매료시키는 소설가가 되었구만...' 하고 납득이 되더군요. 한국의 수많은 학생들(저의 학생때 포함, 현재의 제 자식들 포함해서)은 새벽에 일어나서 학교 갔다가, 밤 늦게 까지 학원 다니고, 주말에도 학원가고.... 다들 똑같고, 재미난 거라곤 별 것 없는 학창 시절을 보내고 나면, 그 경험들 속에서 어떤 소설의 이야기 꺼리를 만들어 낼 수 있을 까 하는 생각이 들더군요.
'아, 내가 참 재미없게 살았구나. 그냥 범생이 처럼 살았구나..... 지금부터라도 재미있게......'
스티븐 킹의 집은 어렸을 때 무척 가난했고, 아버지가 없이 어머니 그리고 형과 함께 살았어요. 스티븐 킹의 어머니가 해주셨던 말 한마디가 스티븐 킹의 운명에 지대한 영향을 끼쳤던 장면도 무척 인상적이었습니다.
어머니는 그 이야기를 내가 지어낸 것이냐고 물으셨다. 나는 대부분을 만화책에서 베꼈다는 사실을 실토할 수밖에 없었다. 어머니는 실망하시는 것 같았고, 따라서 내 기쁨도 사라지고 말았다. 이윽고 어머니가 공책을 돌려주셨다. "기왕이면 네 얘기를 써봐라, 스티브. <컴뱃 케이시> 만화책은 허섭쓰레기야. 주온공이 걸핏하면 남의 이빨이나 부러뜨리잖니. 너라면 휠씬 잘 쓸 수 있을 거다. 네 얘기를 만들어봐." ... 나는 어머니가 즐거워하시는 것을 알 수 있었지만 -웃어야 할 장면에서는 틀림없이 웃으셨다- 사랑하는 아들을 기쁘게 하려고 웃으셨는지, 아니면 정말 재미가 있어서 웃으셨는지는 알 길이 없었다. "이번에 베끼지 않은 거니?" 끝까지 읽은 후 어머니가 물었다. 나는 그렇다고 대답했다. 어머니는 책으로 내도 될 만큼 훌륭하다고 말씀하셨다. 그렇게 나를 행복하게 만드는 말은 지금껏 어느 누구에게서도 들어본 적이 없다. 나는 래빗 트릭과 친구들의 이야기를 네 편 더 썼다. 어머니는 한편이 완성될 때마다 나에게 25센트 동전 하나를 주셨고, 네 명의 언니들에게 보내어 두루 읽혔다. 이모들은 마아 어머니를 불쌍하게 생각했을 것이다. ... 네 편의 이야기. 편당 25센트. 그것은 내가 이 일로 벌어들인 최초의 1달러였다. - p33
'인생론: 후기를 대신하여' 부분에서는 이 책을 쓰는 도중에 산책을 나갔다가 승합차에 치여 수차례 수술을 받으면서 죽을 고비를 여러차례 넘겼던 얘기가 나옵니다. 스티븐 킹은 이때 "죽음"을 그 어느때보다도 가깝게 느꼈을 것입니다. 6주 동안 제대로 움직이지도 못하고, 고통스러운 재활의 기간을 거치는 와중에 "글쓰기 창작"은 스티븐 킹에게 살아야 할 목적이었고, 살아갈 수 있는 '생명수'가 되어주었습니다. 세상에 빈손으로 태어나서, 세상에 의미있는 무언가를 창조해내고, 세상이 이전보다는 더 나아질 수 있도록 조금이나마 기여를 하는 것만큼 사람을 행복하게 하는 게 있을까요?
스티븐 킹이 자동차 사고를 당하고 죽을 고비를 넘긴 후에 쓴 "글씨기의 목적"에 대해서 한번 들어보시지요.
"글쓰기의 목적은 돈을 벌거나 유명해지거나 데이트 상대를 구하거나 잠자리 파트너를 만나거나 친구를 사귀는 것이 아니다. 궁극적으로 글쓰기란 작품을 읽는 이들의 삶을 풍요롭게 하고 아울러 작가 자신의 삶도 풍요롭게 해준다. 글쓰기의 목적은 살아남고 이겨내고 일어서는 것이다. 행복해지는 것이다. 행복해지는 것. 이 책의 일부분은--어쩌면 너무 많은 부분이--내가 그런 사실을 깨닫게 된 과정을 설명하고 있다. 그리고 많은 부분이 나보다 더 잘할 수 있는 방법을 설명한 내용이다. 나머지는--이 부분이 가장 쓸모있는 부분일지도 모른다--허가증이랄까. 여러분도 할 수 있다는, 여러분도 해야 한다는, 그리고 시작할 용기만 있다면 여러분도 해내게 될 것이라는 나의 장담이다. 글쓰기는 마술과 같다. 창조적인 예술이 모두 그렇듯이, 생명수와도 같다. 이 물은 공짜다. 그러니 마음껏 마셔도 좋다. 부디 실컷 마시고 허전한 속을 채우시기를." - p332
'연장통'과 '창작론' 부분에서는 이 책의 본래 주제인 "유혹하는 글쓰기"를 할 수 있는 부분인데요, 저는 데이터 분석하는 사람이지 글쓰기가 본업은 아니므로 주저리주저리 이 포스팅에서 옮겨적지는 않겠습니다. 다만, 비단 '글쓰기, 창작론' 뿐만이 아니라 모든 영역이 다 그렇듯이, "유혹하는 글쓰기"를 하려면 "많이 읽고, 많이 써봐라"는 조언으로 요약이 될 수 있겠습니다. 뭐, 뻔하다면 뻔한 조언인데, 이것만한 진실이 또 없지 않겠습니까?! 그 어떤 영역이 되었든지 간에요.
저도 2016년 부터 일주일에 한편씩 블로그 포스팅을 꾸준히 해오고 있고, 2021년 7월 현재 620여 편의 글을 포스팅 했으니 "많이 읽고, 많이 써봐라"는 조언에 대해서는 어깨 뿌듯하게 펼 수 있겠네요. 주말마다 2시간~4시간씩 투자해서 꾸준히 글 포스팅해온 제가 자랑스럽고 뿌듯합니다. ^__^
스티븐 킹은 소설의 속도감을 높이기 위해서 [ 수정본 = 초고 - 10% ] 라는 공식에 따라 불필요한 단어를 생략하는 것을 중요하게 여기고 있습니다. 책의 마지막 부분에 <호텔 이야기> 라는 짧은 초벌 소설을 보여주고, 이어서는 [수정본 = 초고 - 10%] 의 공식에 맞게 불필요한 단어를 생략하고 수정한 -- 필요에 따라서는 필요한 부분을 추가하기도 하지만...-- 예시를 보여주고 있습니다.
그럼, 저도 이 포스팅의 초고에서 불필요한 10%를 한번 빼볼까하고 살펴보려니... 뺄게 없어 보이네요. ㅎㅎ 이번 포스팅 글이 그리 길지도 않고, 또 읽다보면 다 재미있죠? 그쵸? ... 요 문장만 삭제하는 걸로 하겠습니다. 재미 없죠? -_-;
스티븐 킹은 쓸데없는 "부사의 남발"을 징글징글하게 싫어합니다. 저는 전문 소설가가 아니므로 이 조언은 심각하게 받아들이지 않기로 했습니다. 부사 좀 여기저기 가져다 쓰면 뭐 어때서요... 부사 쓴다고 지구가 망하나? ㅎㅎ (스티븐 킹이 한글 번역해가면서 제 글 읽는 일은 없겠죠? ㅋㅋ)
모처럼 즐거운 책 소개할 수 있어서 저도 신나네요!
스티븐 킹의 "유혹하는 글쓰기" 책 읽어보시고 행복하세요! :-)
ps. 이 책은 이성을 유혹하는 연애의 기술, 이런 내용 아닙니다. 그냥 글쓰기 관련 책이예요. 혹시 제목을 오해해서 낚이는 분이 있을까 해서 노파심에... ㅎㅎ
제목이 길죠. 그동안 글을 띄엄띄엄이지만 제법 많이 썼네요. 바쁘기도 했지만 그래도 마무리를 못해서 살짝 찝찝했어요. 아직 집에 몇가지 추가할 것들이 있지만, 이젠 마무리 해도 될것 같아요. 이글이 마지막이 될 것도 같고, 그동안 좋은것들만 적었으니 아쉬운거 정리해서 한번정도 더 올릴수도 있고요...
며칠전 동현팀장님이 몇가지 손봐주고 다녀 가셨어요. 거실 티비 위로 LED 시계를 달고 싶은데 전선 안보이게 설치 가능한지 물어봤더니 해주신다고 하시더라고요. 벽에 목공 작업을 하면 좋은게 이런거였어요. 근처 콘센트에서 전선을 추가로 따서 안 보이게 설치할수 있어요. mdf 뒤로 감춰서... 물론 팀장님이 거의 전기기사처럼 이런걸 뚝딱뚝딱 혼자서 뭐든지 하실수 있으니 가능한 얘기지요. 제눈엔 맥가이버 수준입니다. 부엌 광파렌지 아래쪽에도 콘센트 추가해주셔서 멀티탭 없이 선정리 됐어요.
쇼파도 에어컨도 다 들어왔으니 이제 얼추 갖춰진 우리집... 사진 공개할께요~~~
전 원래 아날로그 감성인데, 우리집 거실엔 아무래도 아날로그 시계보다는 디지털 LED가 어울릴것 같더라고요..
벽에 타공하고, 전선을 목공 벽 안쪽으로 해서 티비쪽 뒤 콘센트 방향으로 내렸어요. 근데 목공 합판중 가로막이 있어서 그거 통과시키느라 팀장님이 엄청 애먹었네요. 부탁해놓고 미안하더라고요.. 그래도 해놓고 나니 너무 맘에 듭니다. 티비옆에 디지털 시계 하실분은 미리 선을 따놓으시길~!
인쇼랑 작업한 다른 집들은 벽에 못질하기 싫어서 시계를 어떻게들 하냐니까, 오브제 형식으로 장식장 위에 많이들 올린다네요. 우리집 거실엔 장식장이 없는 관계로 뒤늦게 벽 타공하고 걸었어요. 저 자리가 딱! 알맞기도 하고요..
라탄 바구니로 옷입은 화분들이 예쁘지 않나요. 저 자리가 좋은데... 에어컨 바람이 직통으로 얘들한테 가는고로, 여름엔 창가쪽으로 옮겨놓아야겠네요. 지금은 사진을 위한 연출... ㅎㅎ
쇼파는... 아이보리가 더 예뻤는데, 고민하다 그레이로 했어요. 벽면이나 바닥이나 화이트가 많아 아무래도 생활하는데 신경쓰이고 조심스러운게 사실이예요. 근데 소파까지 밝은색으로 하면 소파에서 편히 뒹굴지도 못하고 이놈의 소파까지 모시고 살것 같더라고요. 머리염색하면 그것도 묻을수 있다고 하고...그래서 짙은색으로... 자코모 달리아 인가 그래요 모델명은.. 2-3주 된거 같은데 아직 가죽 냄새가 제법 많이 나네요. ㅠ.ㅠ
말 나온김에.. 흰색이 집에 많으면 좀 불편하긴 해요.. 청소기 돌리거나 물건 나를 때 벽에 안 부딪치게 조심하는 건 기본이고요.. 집에 모기가 들어왔는데 벽에 앉아도 파리채로 시원하게 때려잡을 수가 없어요~. 흰벽에 뭐 묻을까봐.. ㅋ
부엌은... 이건 지난번 올린 사진입니다.. 광파오븐 전선 땜에 멀티탭을 보기싫게 써야했던 초기사진..
이젠...
바구니 옆면 벽에 콘센트 추가한거 보이시나요? 공사 끝나고도 이런걸 뚝딱뚝딱 할수 있다는게 신기해요.. 인쇼 목공의 장점~!
올린김에 부엌 사진 몇개 더 올렸구요.. 싱크대 사진은 이전꺼 싱크대편 참조하세요~~ 식탁 너머로 보이는 문이 안방문입니다.
그럼 그방 열고 안방컷도 한두개 올릴께요.. 안방도 에어컨 들였어요 드디어.. ㅎㅎ..
안방 붙박이랑 페인트 관련글은 제 13번 글 참고하시고요. 13번글 처음 글 올리고 수정해서 사진과 내용이 많이 추가됐으니 보신분도 다시 봐주셔도 좋을듯 해요.
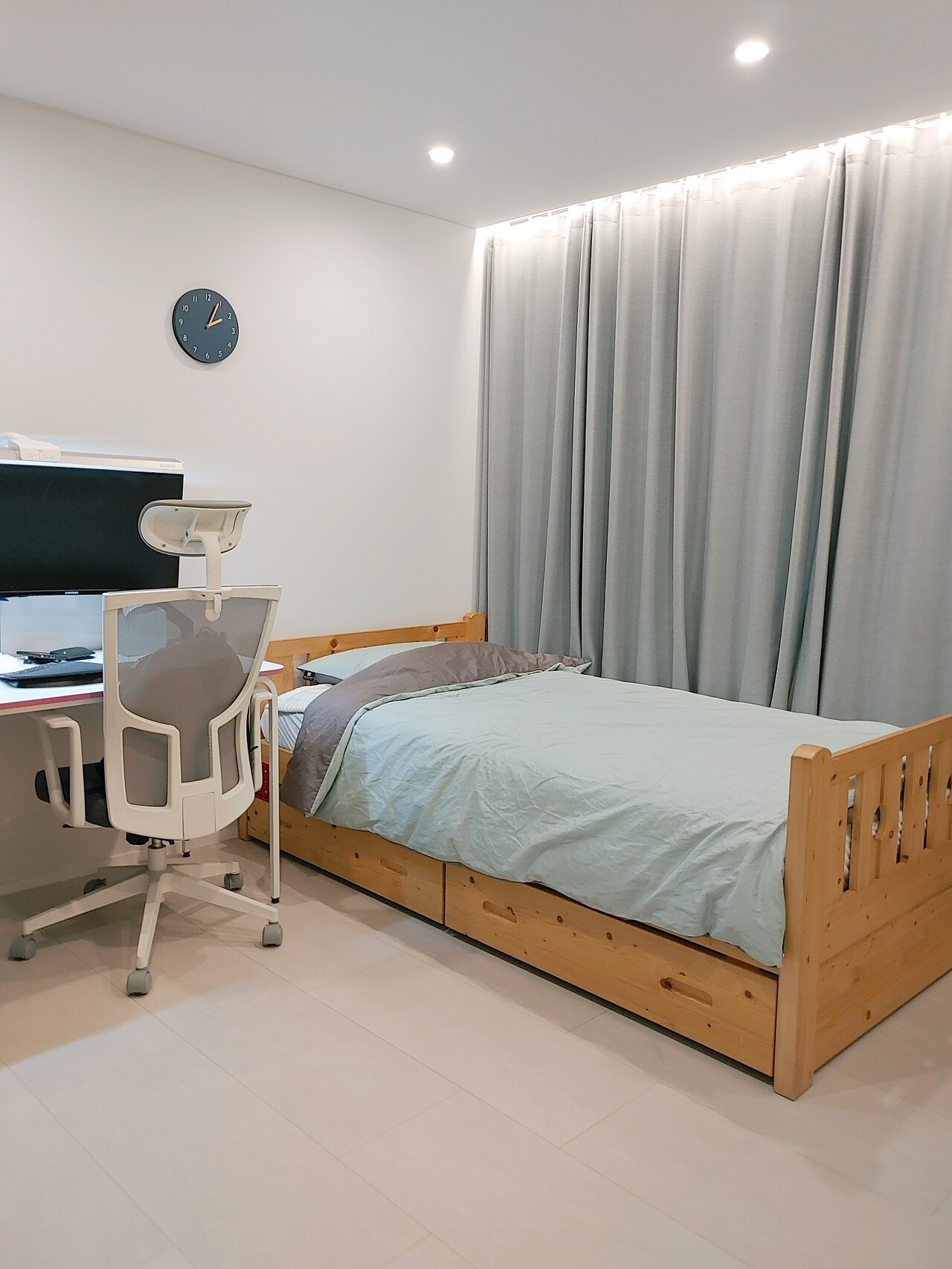
다음은 대학생이 된 아들방입니다. 이놈의 코로나 땜에 하루종일 집에 계십니다. 삼식이 아드님이...
가구 중 이케아옷장 과 데스커 서랍장, 시디즈 흰색프레임 의자는 샀고요. 다른건 기존것들 그냥 썼어요.
참.. 저희집 가전은 20년만에 거의다 바꿨어요. 엘지 오브제 라인으로다~~ 20년 썼음 ㅂㅏ꿀만 하죠 뭐.. 바꾸고 나서 느낀건.. ㅠ.ㅠ 그동안 저희집은 원시시대를 살았던 거였어요.. 가장 편한것중 하나는 오브제 정수기~! 원래는 싱크대 매립형 퓨리케어 하려다 오브제 다품목할인 땜에 이거 했는데, 완전 만족합니다. 이전의 미개한 15년된 정수기는 찬물 한종류 뿐이었는데 이건 냉수 정수 온수 다 되고 온수는 온도도 3종류로 선택되어요. 아침에 조용히 일어나 앉아 음악들으며 따뜻한 차를 마시려고 할때 굳이 물 안끓여도 된다는거.. 삶의 질이 좀 더 높아진 느낌입니다 ㅎㅎ
물 양도 한잔 마시기 딱.좋은 120밀리/ 요리용 500밀리/ 1리터 이렇게 선택할수 있어서 물 많이 받을때 눌러놓고 다른일 봐도 되고, 넘칠걱정 안해도 되고... 아, 세상좋아요~ ㅋㅋ (다른분들은 옛날부터 이런거 썼다고요? )
암튼 가전은 엘쥐~~!! 칭찬합니다.
그래도 인덕션은 흰색이 없어서,
식세기는 인쇼의 미적감각에 맞는 패널교체형 빌트인이 안되어서 결국 엘지꺼로 못했습니다.
전 국산 가전이 정말 세계적인 수준이라고 생각하고 또 AS도 편해서 웬만하면 국산 사고 싶었는데... 인덕션과 식세기는 그렇게 못했네요. 인덕션은 국내꺼 전자파 허용치가 너무 심하게 높아서... 고심하다 어쩔수 없이 디트리쉬직구했어요.. 가스렌지만 20년 쓰던 미개주부가 이것도 신세계더라요.. ㅎㅎ 흰색 인덕션, 관리 그닥 안 어렵네요. 예뻐서, 강추합니다.
식세기는 오랜 고심끝에 밀레껄로~~
이전에 보일러실에 있던 세탁기는 앞쪽 베란다로 이동했어요. 세탁기 물 빠지는 관은 안방을 지나서 안방 화장실로 관을 빼줬어요. 앞 베란다의 우수관으로 세탁기 물 버리면 겨울에 얼어서 물 역류할 수 있어서 저층에 난리나는거 다들 아시죠? 세탁기 위치가 여기로 바뀌고 나서 좋은 점은 샤워 후에 갈아입은 옷을 창문 열고 휙 던져서 빨래통에 넣을 수 있다는 점. (이전에는 빙글 돌아서 한참 가야... ㅋㅋ)
헉헉.. 그동안 많이 읽어주시고 댓글달아주시고 예쁘다 해주셔서 재미있었어요~~! 감사합니다.
무엇보다 이예쁜집 정성스레 잘 만들어준 인쇼대표님이랑 동현팀장님 너무 고마워요~~ . 인테리어 의 이응자도 모르던 나도 열심히 이것저것 알아보고 모르는 와중에 수많은 선택을 고통스럽게 하느라 수고 많았답니다. 필요한거 열심히 준비하고 사다준 우리 신랑도요~! (토닥토닥~!) ㅋㅋ 인쇼아카데미 여우조연상 수상소감 같네요.