저희 집을 올 해 1월 중순부터 3월 초순까지 인테리어를 했습니다. 그런데 운이 좋아서 유튜브에서 화제가 되고 있는 그 유명한 '인쇼 (인테리어쇼)'와 함께 인테리어를 할 수 있게 되었습니다. ^___^
와이프가 네이버의 '셀인(셀프인테리어) 카페'에 '인쇼랑 인테리어' 라는 제목으로 연재한 글 들을 제 블로그에 옮겨놓습니다. 글은 제 와이프가 쓴 글이고요, 저는 퇴근 후에 그리고 주말에 부지런히 인테리어 공사 현장 방문해서 사진찍어서 와이프한테 전해주곤 했습니다. ^^' (인테리어에 관한 거의 대부분의 의사결정은 와이프님이 거의 다 했어요. ㅎㅎ)
저는 사실 하루 종일 일만 하고 공부만 할 줄 알지, 인테리어 안목은 아주 쌩 초보입니다만, 와이프가 잠자기 전에 침대에서 인테리어쇼 유튜브 방송 볼 때마다 귀동냥, 눈동냥하면서 저도 좀 보고 들은게 있기는 합니다. ㅋㅋ 서당개 삼년이면 풍월을 읇는다고 하잖아요? 아는게 병이라고, 저도 이제 다른 집 인테리어 볼 때면 몰딩이 눈에 들어오고 어찌나 거슬리는지 몰라요.
사실 처음에 썬글라스 낀 인쇼 대표님이 반말로 방송하는 걸 보고 속으로 기겁을 했었습니다. 아니, 저 양반은 언제 우리를 봤다고 반말은 반말이야? 잉? ^^;;; 그런데, 한번 보고, 두번 보고, 세번 보고, 보고 또 보다 보니 '썬글라스를 안 쓴 인쇼 대표', '반말은 안하는 인쇼 대표'님이 상상이 잘 안가네요. ㅋㅋ
>> 인테리오쇼의 유튜브 로고.
>> 인테리오쇼의 한 카리스마하시는 썬그라스 대표님, "유튜브 친구들 안녕~"
* 인테리어쇼 (인쇼)를 아직 모르는 분이라면 위의 유튜브 한번 봐보세요. 인쇼가 추구하는 인테리어가 이런 스타일이구나... 하고 감이 좀 잡히실 듯 해요. (위 유튜브는 저희 집은 아니고요, 저희 집도 이 유튜브랑 비슷하게 인테리어 했어요.)
인테리어를 고민하는 누군가에게는 그래도 좋은 정보가 될 수 있겠다 싶어 제 와이프 연재 글들을 제 블로그에 옮겨서 다시 정리해봅니다. 구글에서 검색하면 잘 안 찾아지더라구요.
그리고 유튜브에서 '인테리어쇼(인쇼)' 동영상을 보신 분들이 '실제 인쇼랑 해보면 어떤데? 실제 저게 돼?' 하는 궁금증 같은 것도 있을 실 것 같습니다. '실제 인쇼랑 인테리어를 하면 이렇게 된다'는 것도 공유를 해보고 싶었습니다. '대한민국의 인테리어 업계를 바꿔보겠다'는 포부를 가진 인쇼를 응원하고 싶은 마음도 큽니다. (누군가가 대한민국 인테리어의 역사에 대해서 책을 쓴다면 아마, "Before 인쇼, After 인쇼"로 시대가 구분이 되지 않을까 싶습니다. 인테리어 업계에서 인쇼 모르면 간첩!)
저희 집이 너무나 이쁘고 또 살기 좋게 인테리어가 잘 되어서 저희 가족 모두가 정말 만족하고 있습니다. 인쇼가 너무나 감사하고, 또 인쇼가 앞으로 더 잘 되었으면 합니다. (물론, 이미 유튜브로 너무 유명해져서 제 블로그 아니더라도 일거리가 차고도 넘칠 것임에는 의심의 여지가 없지만요.)
글 중간 중간에 중소기업들 이름도 나오곤 하는데요, 저희집은 이들 업체로 부터 사례로 받은거 1도 없습니다. 그냥 이들 중소기업들 제품을 사용해서 인테리어를 했고, 지금까진 아무 문제없이 만족하면서 사용하고 있어서요, 정보제공 차원에서 브랜드명 소개하는 것이니 참고하시구요, 최종 결정은 본인 책임하에 판단하시면 되겠습니다.
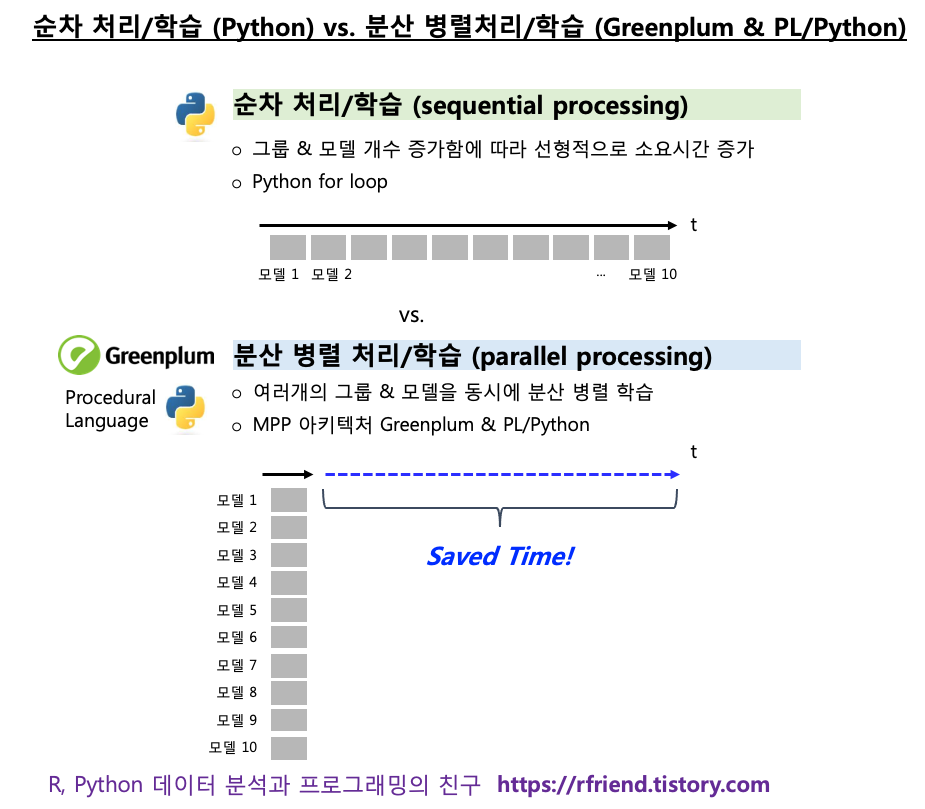
지난번 포스팅에서는 Python의 statsmodels 모듈을 이용하여 여러개의 숫자형 변수에 대해 집단 간 평균의 차이가 있는지를 for loop 순환문을 사용하여 검정하는 방법(rfriend.tistory.com/639)을 소개하였습니다.
Python에서 for loop 문을 사용하면 순차적으로 처리 (sequential processing) 를 하게 되므로, 일원분산분석을 해야 하는 숫자형 변수의 개수가 많아질 수록 선형적으로 처리 시간이 증가하게 됩니다.
Greenplum에서 PL/Python (또는 PL/R) 을 사용하면 일원분산분석의 대상의 되는 숫자형 변수가 매우 많고 데이터 크기가 크더라도 분산병렬처리 (distributed parallel processing) 하여 ANOVA test 를 처리할 수 있으므로 신속하게 분석을 할 수 있는 장점이 있습니다.
더불어서, 데이터가 저장되어 있는 DB에서 데이터의 이동 없이(no data I/O, no data movement), In-DB 처리/분석이 되므로 work-flow 가 간소화되고 batch scheduling 하기에도 편리한 장점이 있습니다.
만약 데이터는 DB에 있고, 애플리케이션도 DB를 바라보고 있고, 분석은 Python 서버 (또는 R 서버)에서 하는 경우라면, 분석을 위해 DB에서 데이터를 samfile 로 떨구고, 이를 Python에서 pd.read_csv()로 읽어들여서 분석하고, 다시 결과를 text file로 떨구고, 이 text file을 ftp로 DB 서버로 이동하고, psql로 COPY 문으로 테이블에 insert 하는 workflow ... 관리 포인트가 많아서 정신 사납고 복잡하지요?!
자, 이제 Greenplum database에서 PL/Python으로 일원분산분석을 병렬처리해서 집단 간 여러개의 개별 변수별 평균 차이가 있는지 검정을 해보겠습니다.
(1) 여러 개의 변수를 가지는 샘플 데이터 만들기
정규분포로 부터 난수를 발생시켜서 3개 그룹별로 각 30개 씩의 샘플 데이터를 생성하였습니다. 숫자형 변수로는 'x1', 'x2', 'x3', 'x4'의 네 개의 변수를 생성하였습니다. 이중에서 'x1', 'x2'는 3개 집단이 모두 동일한 평균과 분산을 가지는 정규분포로 부터 샘플을 추출하였고, 반면에 'x3', 'x4'는 3개 집단 중 2개는 동일한 평균과 분산의 정규분포로 부터 샘플을 추출하고 나머지 1개 집단은 다른 평균을 가지는 정규분포로 부터 샘플을 추출하였습니다. (뒤에 one-way ANOVA 검정을 해보면 'x3', 'x4'에 대한 집단 간 평균 차이가 있는 것으로 결과가 나오겠지요?!)
import numpy as np
import pandas as pd
# generate 90 IDs
id = np.arange(90) + 1
# Create 3 groups with 30 observations in each group.
from itertools import chain, repeat
grp = list(chain.from_iterable((repeat(number, 30) for number in [1, 2, 3])))
# generate random numbers per each groups from normal distribution
np.random.seed(1004)
# for 'x1' from group 1, 2 and 3
x1_g1 = np.random.normal(0, 1, 30)
x1_g2 = np.random.normal(0, 1, 30)
x1_g3 = np.random.normal(0, 1, 30)
# for 'x2' from group 1, 2 and 3
x2_g1 = np.random.normal(10, 1, 30)
x2_g2 = np.random.normal(10, 1, 30)
x2_g3 = np.random.normal(10, 1, 30)
# for 'x3' from group 1, 2 and 3
x3_g1 = np.random.normal(30, 1, 30)
x3_g2 = np.random.normal(30, 1, 30)
x3_g3 = np.random.normal(50, 1, 30)
# different mean
x4_g1 = np.random.normal(50, 1, 30)
x4_g2 = np.random.normal(50, 1, 30)
x4_g3 = np.random.normal(20, 1, 30)
# different mean # make a DataFrame with all together
df = pd.DataFrame({
'id': id, 'grp': grp,
'x1': np.concatenate([x1_g1, x1_g2, x1_g3]),
'x2': np.concatenate([x2_g1, x2_g2, x2_g3]),
'x3': np.concatenate([x3_g1, x3_g2, x3_g3]),
'x4': np.concatenate([x4_g1, x4_g2, x4_g3])})
df.head()
id
grp
x1
x2
x3
x4
1
1
0.594403
10.910982
29.431739
49.232193
2
1
0.402609
9.145831
28.548873
50.434544
3
1
-0.805162
9.714561
30.505179
49.459769
4
1
0.115126
8.885289
29.218484
50.040593
5
1
-0.753065
10.230208
30.072990
49.601211
위에서 만든 가상의 샘플 데이터를 Greenplum DB에 'sample_tbl' 이라는 이름의 테이블로 생성해보겠습니다. Python pandas의 to_sql() 메소드를 사용하면 pandas DataFrame을 쉽게 Greenplum DB (또는 PostgreSQL DB)에 uploading 할 수 있습니다.
# creating a table in Greenplum by importing pandas DataFrame
conn = "postgresql://gpadmin:changeme@localhost:5432/demo"
df.to_sql('sample_tbl',
conn,
schema = 'public',
if_exists = 'replace',
index = False)
Jupyter Notebook에서 Greenplum DB에 접속해서 SQL로 이후 작업을 진행하겠습니다.
PL/Python에서 작업하기 쉽도록 테이블 구조를 wide format에서 long format 으로 변경하겠습니다. union all 로 해서 칼럼 갯수 만큼 위/아래로 append 해나가면 되는데요, DB 에서 이런 형식의 데이터를 관리하고 있다면 아마도 이미 long format 으로 관리하고 있을 가능성이 높습니다. (새로운 데이터가 수집되면 계속 insert into 하면서 행을 밑으로 계속 쌓아갈 것이므로...)
%%sql
-- reshaping a table from wide to long
drop table if exists sample_tbl_long;
create table sample_tbl_long as (
select id, grp, 'x1' as col, x1 as val from sample_tbl
union all
select id, grp, 'x2' as col, x2 as val from sample_tbl
union all
select id, grp, 'x3' as col, x3 as val from sample_tbl
union all
select id, grp, 'x4' as col, x4 as val from sample_tbl
) distributed randomly;
* postgresql://gpadmin:***@localhost:5432/demo
Done.
360 rows affected.
%sql select * from sample_tbl_long order by id, grp, col limit 8;
[Out]
* postgresql://gpadmin:***@localhost:5432/demo
8 rows affected.
id grp col val
1 1 x1 0.594403067344276
1 1 x2 10.9109819091195
1 1 x3 29.4317394311833
1 1 x4 49.2321928075563
2 1 x1 0.402608708677309
2 1 x2 9.14583073327387
2 1 x3 28.54887315985
2 1 x4 50.4345438286737
(3) 분석 결과 반환 composite type 정의
일원분산분석 결과를 반환받을 때 각 분석 대상 변수 별로 (a) F-통계량, (b) p-value 의 두 개 값을 float8 데이터 형태로 반환받는 composite type 을 미리 정의해놓겠습니다.
%%sql
-- Creating a coposite return type
drop type if exists plpy_anova_type cascade;
create type plpy_anova_type as (
f_stat float8
, p_val float8
);
* postgresql://gpadmin:***@localhost:5432/demo
Done.
Done.
(4) 일원분산분석(one-way ANOVA) PL/Python 사용자 정의함수 정의
집단('grp')과 측정값('val')을 input 으로 받고, statsmodels 모듈의 sm.stats.anova_lm() 메소드로 일원분산분석을 하여 결과 테이블에서 'F-통계량'과 'p-value'만 인덱싱해서 반환하는 PL/Python 사용자 정의 함수를 정의해보겠습니다.
%%sql
-- Creating the PL/Python UDF of ANOVA
drop function if exists plpy_anova_func(text[], float8[]);
create or replace function plpy_anova_func(grp text[], val float8[])
returns plpy_anova_type
as $$
import pandas as pd
import statsmodels.api as sm
from statsmodels.formula.api import ols
df = pd.DataFrame({'grp': grp, 'val': val})
model = ols('val ~ grp', data=df).fit()
anova_result = sm.stats.anova_lm(model, typ=1)
return {'f_stat': anova_result.loc['grp', 'F'],
'p_val': anova_result.loc['grp', 'PR(>F)']}
$$ language 'plpythonu';
* postgresql://gpadmin:***@localhost:5432/demo
Done.
Done.
(5) 일원분산분석(one-way ANOVA) PL/Python 함수 분산병렬처리 실행
PL/Python 사용자 정의함수는 SQL query 문으로 실행합니다. 이때 PL/Python 이 'F-통계량'과 'p-value'를 반환하도록 UDF를 정의했으므로 아래처럼 (plpy_anova_func(grp_arr, val_arr)).* 처럼 ().* 으로 해서 모든 결과('F-통계량' & 'p-value')를 반환하도록 해줘야 합니다. (빼먹고 실수하기 쉬우므로 ().*를 빼먹지 않도록 주의가 필요합니다)
이렇게 하면 변수별로 segment nodes 에서 분산병렬로 각각 처리가 되므로, 변수가 수백~수천개가 있더라도 (segment nodes가 많이 있다는 가정하에) 분산병렬처리되어 신속하게 분석을 할 수 있습니다. 그리고 결과는 바로 Greenplum DB table에 적재가 되므로 이후의 application이나 API service에서 가져다 쓰기에도 무척 편리합니다.
%%sql
-- Executing the PL/Python UDF of ANOVA
drop table if exists plpy_anova_table;
create table plpy_anova_table as (
select
col
, (plpy_anova_func(grp_arr, val_arr)).*
from (
select
col
, array_agg(grp::text order by id) as grp_arr
, array_agg(val::float8 order by id) as val_arr
from sample_tbl_long
group by col
) a
) distributed randomly;
* postgresql://gpadmin:***@localhost:5432/demo
Done.
4 rows affected.
총 4개의 각 변수별 일원분산분석 결과를 조회해보면 아래와 같습니다.
%%sql
select * from plpy_anova_table order by col;
[Out]
* postgresql://gpadmin:***@localhost:5432/demo
4 rows affected.
col f_stat p_val
x1 0.773700830155438 0.46445029458511966
x2 0.20615939957339052 0.8140997216173114
x3 4520.512608893724 1.2379278415456727e-88
x4 9080.286130418674 1.015467388498996e-101
지난번 포스팅에서는 샘플 크기가 다른 2개 이상의 집단에 대해 평균의 차이가 존재하는지를 검정하는 일원분산분석(one-way ANOVA)에 대해 scipy 모듈의 scipy.stats.f_oneway() 메소드를 사용해서 분석하는 방법(rfriend.tistory.com/638)을 소개하였습니다.
이번 포스팅에서는 2개 이상의 집단에 대해 pandas DataFrame에 들어있는 여러 개의 숫자형 변수(one-way ANOVA for multiple numeric variables in pandas DataFrame) 별로 일원분산분석 검정(one-way ANOVA test)을 하는 방법을 소개하겠습니다.
숫자형 변수와 집단 변수의 모든 가능한 조합을 MultiIndex 로 만들어서 statsmodels.api 모듈의 stats.anova_lm() 메소드의 모델에 for loop 순환문으로 변수를 바꾸어 가면서 ANOVA 검정을 하도록 작성하였습니다.
먼저, 3개의 집단('grp 1', 'grp 2', 'grp 3')을 별로 'x1', 'x2', 'x3, 'x4' 의 4개의 숫자형 변수를 각각 30개씩 가지는 가상의 pandas DataFrame을 만들어보겠습니다. 이때 숫자형 변수는 모두 정규분포로 부터 난수를 발생시켜 생성하였으며, 'x3'와 'x4'에 대해서는 집단3 ('grp 3') 의 평균이 다른 2개 집단의 평균과는 다른 정규분포로 부터 난수를 발생시켜 생성하였습니다.
아래의 가상 데이터셋은 결측값이 없이 만들었습니다만, 실제 기업에서 쓰는 데이터셋에는 혹시 결측값이 존재할 수도 있으므로 결측값을 없애거나 또는 결측값을 그룹 별 평균으로 대체한 후에 one-way ANOVA 를 실행하기 바랍니다.
## Creating sample dataset
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# generate 90 IDs
id = np.arange(90) + 1
# Create 3 groups with 30 observations in each group.
from itertools import chain, repeat
grp = list(chain.from_iterable((repeat(number, 30) for number in [1, 2, 3])))
# generate random numbers per each groups from normal distribution
np.random.seed(1004)
# for 'x1' from group 1, 2 and 3
x1_g1 = np.random.normal(0, 1, 30)
x1_g2 = np.random.normal(0, 1, 30)
x1_g3 = np.random.normal(0, 1, 30)
# for 'x2' from group 1, 2 and 3
x2_g1 = np.random.normal(10, 1, 30)
x2_g2 = np.random.normal(10, 1, 30)
x2_g3 = np.random.normal(10, 1, 30)
# for 'x3' from group 1, 2 and 3
x3_g1 = np.random.normal(30, 1, 30)
x3_g2 = np.random.normal(30, 1, 30)
x3_g3 = np.random.normal(50, 1, 30) # different mean
x4_g1 = np.random.normal(50, 1, 30)
x4_g2 = np.random.normal(50, 1, 30)
x4_g3 = np.random.normal(20, 1, 30) # different mean
# make a DataFrame with all together
df = pd.DataFrame({'id': id,
'grp': grp,
'x1': np.concatenate([x1_g1, x1_g2, x1_g3]),
'x2': np.concatenate([x2_g1, x2_g2, x2_g3]),
'x3': np.concatenate([x3_g1, x3_g2, x3_g3]),
'x4': np.concatenate([x4_g1, x4_g2, x4_g3])})
df.head()
[Out]
id grp x1 x2 x3 x4
0 1 1 0.594403 10.910982 29.431739 49.232193
1 2 1 0.402609 9.145831 28.548873 50.434544
2 3 1 -0.805162 9.714561 30.505179 49.459769
3 4 1 0.115126 8.885289 29.218484 50.040593
4 5 1 -0.753065 10.230208 30.072990 49.601211
df[df['grp'] == 3].head()
[Out]
id grp x1 x2 x3 x4
60 61 3 -1.034244 11.751622 49.501195 20.363374
61 62 3 0.159294 10.043206 50.820755 19.800253
62 63 3 0.330536 9.967849 50.461775 20.993187
63 64 3 0.025636 9.430043 50.209187 17.892591
64 65 3 -0.092139 12.543271 51.795920 18.883919
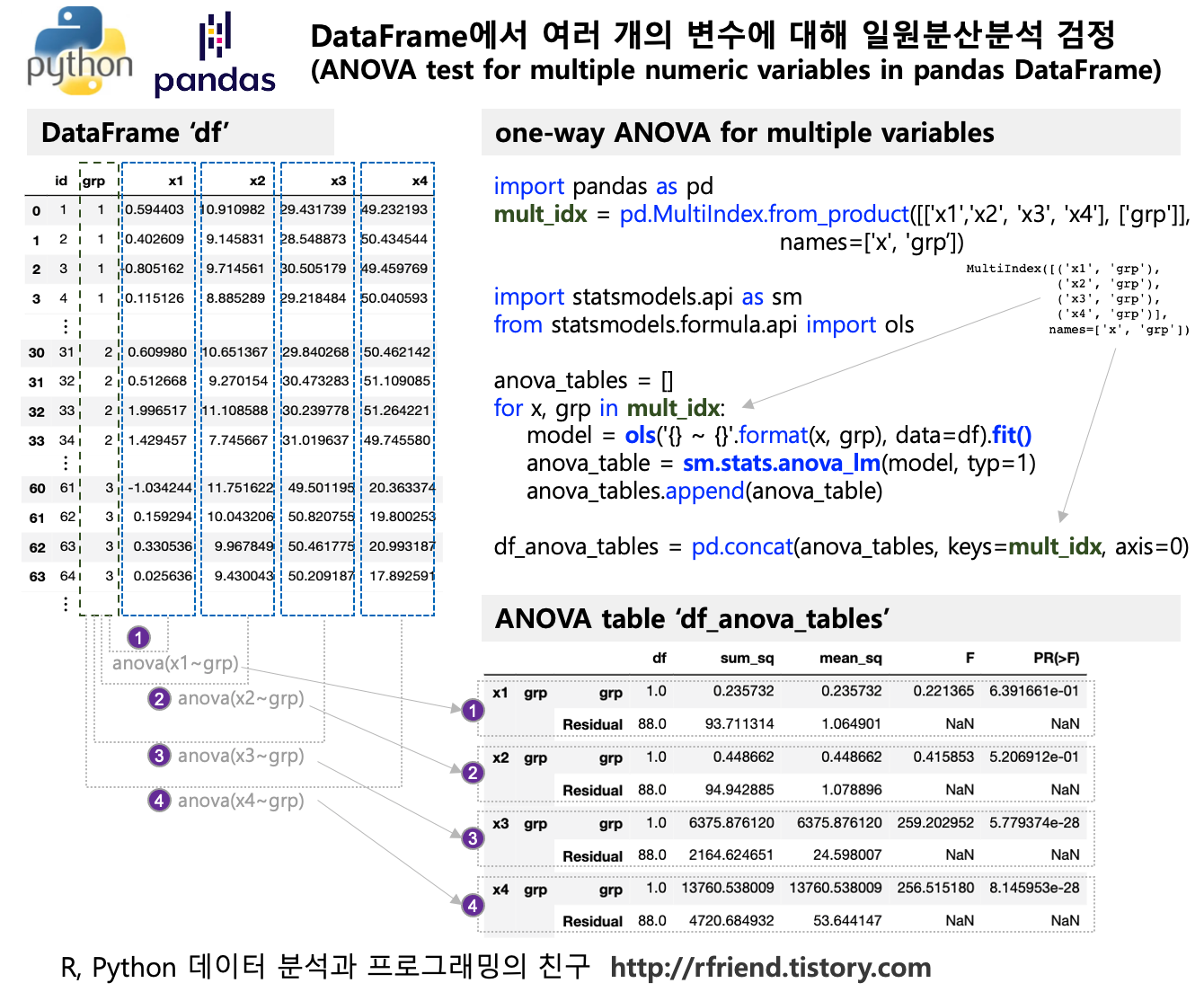
가령, 'x3' 변수에 대해 집단별로 상자 그래프 (Box plot for 'x3' by groups) 를 그려보면, 아래와 같이 집단1과 집단2는 유사한 반면에 집단3은 평균이 차이가 많이 나게 가상의 샘플 데이터가 생성되었음을 알 수 있습니다.
## Boxplot for 'x3' by 'grp'
plt.rcParams['figure.figsize'] = [10, 6]
sns.boxplot(x='grp', y='x3', data=df)
plt.show()
여러개의 변수에 대해 일원분산분석을 하기 전에, 먼저 이해를 돕기 위해 Python의 statsmodels.api 모듈의 stats.anova_lm() 메소드를 사용해서 'x1' 변수에 대해 집단(집단 1/2/3)별로 평균이 같은지 일원분산분석으로 검정을 해보겠습니다.
- 귀무가설(H0) : 집단1의 x1 평균 = 집단2의 x1 평균 = 집단3의 x1 평균
- 대립가설(H1) : 적어도 1개 이상의 집단의 x1 평균이 다른 집단의 평균과 다르다. (Not H0)
# ANOVA for x1 and grp
import statsmodels.api as sm
from statsmodels.formula.api import ols
model = ols('x1 ~ grp', data=df).fit()
sm.stats.anova_lm(model, typ=1)
[Out]
df sum_sq mean_sq F PR(>F)
grp 1.0 0.235732 0.235732 0.221365 0.639166
Residual 88.0 93.711314 1.064901 NaN NaN
일원분산분석 결과 F 통계량이 0.221365, p-value가 0.639 로서 유의수준 5% 하에서 귀무가설을 채택합니다. 즉, 3개 집단 간 x1의 평균의 차이는 없다고 판단할 수 있습니다. (정규분포 X ~ N(0, 1) 를 따르는 모집단으로 부터 무작위로 3개 집단의 샘플을 추출했으므로 차이가 없게 나오는게 맞겠습니다.)
한개의 변수에 대한 일원분산분석하는 방법을 알아보았으니, 다음으로는 3개 집단별로 여러개의 연속형 변수인 'x1', 'x2', 'x3', 'x4' 에 대해서 for loop 순환문으로 돌아가면서 일원분산분석을 하고, 그 결과를 하나의 DataFrame에 모아보도록 하겠습니다.
(1) 먼저, 일원분산분석을 하려는 모든 숫자형 변수와 집단 변수에 대한 가능한 조합의 MultiIndex 를 생성해줍니다.
# make a multiindex for possible combinations of Xs and Group
num_col = ['x1','x2', 'x3', 'x4']
cat_col = ['grp']
mult_idx = pd.MultiIndex.from_product([num_col, cat_col],
names=['x', 'grp'])
print(mult_idx)
[Out]
MultiIndex([('x1', 'grp'),
('x2', 'grp'),
('x3', 'grp'),
('x4', 'grp')],
names=['x', 'grp'])
(2) for loop 순환문(for x, grp in mult_idx:)으로 model = ols('{} ~ {}'.format(x, grp) 의 선형모델의 y, x 부분의 변수 이름을 바꾸어가면서 sm.stats.anova_lm(model, typ=1) 로 일원분산분석을 수행합니다. 이렇게 해서 나온 일원분산분석 결과 테이블을 anova_tables.append(anova_table) 로 순차적으로 append 해나가면 됩니다.
# ANOVA test for multiple combinations of X and Group
import statsmodels.api as sm
from statsmodels.formula.api import ols
anova_tables = []
for x, grp in mult_idx:
model = ols('{} ~ {}'.format(x, grp), data=df).fit()
anova_table = sm.stats.anova_lm(model, typ=1)
anova_tables.append(anova_table)
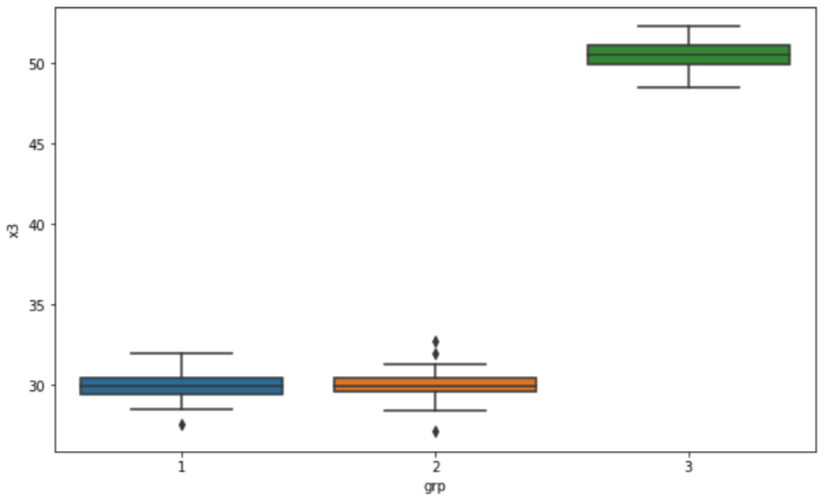
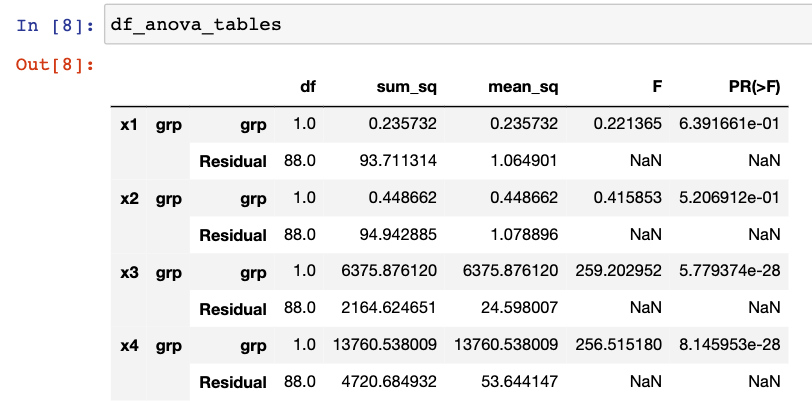
df_anova_tables = pd.concat(anova_tables, keys=mult_idx, axis=0)
df_anova_tables
[Out]
df sum_sq mean_sq F PR(>F)
x1 grp grp 1.0 0.235732 0.235732 0.221365 6.391661e-01
Residual 88.0 93.711314 1.064901 NaN NaN
x2 grp grp 1.0 0.448662 0.448662 0.415853 5.206912e-01
Residual 88.0 94.942885 1.078896 NaN NaN
x3 grp grp 1.0 6375.876120 6375.876120 259.202952 5.779374e-28
Residual 88.0 2164.624651 24.598007 NaN NaN
x4 grp grp 1.0 13760.538009 13760.538009 256.515180 8.145953e-28
Residual 88.0 4720.684932 53.644147 NaN NaN
anova tables
만약 특정 변수에 대한 일원분산분석 결과만을 조회하고 싶다면, 아래처럼 DataFrame의 MultiIndex 에 대해 인덱싱을 해오면 됩니다. 가령, 'x3' 에 대한 집단별 평균 차이 여부를 검정한 결과는 아래처럼 인덱싱해오면 됩니다.
## Getting values of 'x3' from ANOVA tables
df_anova_tables.loc[('x3', 'grp', 'grp')]
[Out]
df 1.000000e+00
sum_sq 6.375876e+03
mean_sq 6.375876e+03
F 2.592030e+02
PR(>F) 5.779374e-28
Name: (x3, grp, grp), dtype: float64
F 통계량과 p-value 에 대해서 조회하고 싶으면 위의 결과에서 DataFrame 의 칼럼 이름으로 선택해오면 됩니다.
Greenplum DB에서 PL/Python (또는 PL/R)을 사용하여 여러개의 숫자형 변수에 대해 일원분산분석을 분산병렬처리하는 방법(one-way ANOVA in parallel using PL/Python on Greenplum DB)은 rfriend.tistory.com/640 를 참고하세요.
2개의 모집단에 대한 평균을 비교, 분석하는 통계적 기법으로 t-Test를 활용하였다면, 비교하고자 하는 집단이 2개 이상일 경우에는분산분석 (ANOVA : Analysis Of Variance)를 이용합니다.
설명변수는 범주형 자료(categorical data)이어야 하며, 종속변수는 연속형 자료(continuous data) 일 때 2개 이상집단 간 평균 비교분석에 분산분석(ANOVA) 을 사용하게 됩니다.
분산분석(ANOVA)은 기본적으로분산의 개념을 이용하여 분석하는 방법으로서, 분산을 계산할 때처럼 편차의 각각의 제곱합을 해당 자유도로 나누어서 얻게 되는 값을 이용하여 수준평균들간의 차이가 존재하는 지를 판단하게 됩니다. 이론적인 부분에 대한 좀더 자세한 내용은 https://rfriend.tistory.com/131 를 참고하세요.
one-way ANOVA 일원분산분석
이번 포스팅에서는 Python의 scipy 모듈의 stats.f_oneway() 메소드를 사용하여 샘플의 크기가 서로 다른 3개 그룹 간 평균에 차이가 존재하는지 여부를 일원분산분석(one-way ANOVA)으로 분석하는 방법을 소개하겠습니다.
분산분석(Analysis Of Variance) 검정의 3가지 가정사항을 고려해서, 샘플 크기가 서로 다른 가상의 3개 그룹의 예제 데이터셋을 만들어보겠습니다.
[ 분산분석 검정의 가정사항 (assumptions of ANOVA test) ]
(1) 독립성: 각 샘플 데이터는 서로 독립이다. (2) 정규성: 각 샘플 데이터는 정규분포를 따르는 모집단으로 부터 추출되었다. (3) 등분산성: 그룹들의 모집단의 분산은 모두 동일하다.
먼저, 아래의 예제 샘플 데이터셋은 그룹1과 그룹2의 평균은 '0'으로 같고, 그룹3의 평균은 '5'로서 나머지 두 그룹과 다르게 난수를 발생시켜 가상으로 만든 것입니다.
이제 scipy 모듈의 scipy.stats.f_oneway() 메소드를 사용해서 서로 다른 개수의 샘플을 가진 3개 집단에 대해 평균의 차이가 존재하는지 여부를 일원분산분석을 통해 검정을 해보겠습니다.
- 귀무가설(H0): 3 집단의 평균은 모두 같다. (mu1 = mu2 = m3)
- 대립가설(H1): 3 집단의 평균은 같지 않다.(적어도 1개 집단의 평균은 같지 않다) (Not H0)
F통계량은 매우 큰 값이고 p-value가 매우 작은 값이 나왔으므로 유의수준 5% 하에서 귀무가설을 기각하고 대립가설을 채택합니다. 즉, 3개 집단 간 평균의 차이가 존재한다고 평가할 수 있습니다.
# ANOVA with different sized samples using scipy
from scipy import stats
stats.f_oneway(data1, data2, data3)
[Out]
F_onewayResult(statistic=262.7129127080777, pvalue=5.385523527223916e-44)
scipy 모듈의 stats.f_oneway() 메소드를 사용할 때 만약 데이터에 결측값(NAN)이 포함되어 있으면 'NAN'을 반환합니다. 위에서 만들었던 'data1' numpy array 의 첫번째 값을 np.nan 으로 대체한 후에 scipy.stats.f_oneway() 로 일원분산분석 검정을 해보면 'NAN'(Not A Number)을 반환한 것을 볼 수 있습니다.
샘플 데이터에 결측값이 포함되어 있는 경우, 결측값을 먼저 제거해주고 일원분산분석 검정을 실시해주시기 바랍니다.
# get rid of the missing values before applying ANOVA test
stats.f_oneway(data1[~np.isnan(data1)], data2, data3)
[Out]
F_onewayResult(statistic=260.766426640122, pvalue=1.1951277551195217e-43)
위의 일원분산분석(one-way ANOVA) 는 2개 이상의 그룹 간 평균의 차이가 존재하는지만을 검정할 뿐이며, 집단 간 평균의 차이가 존재한다는 대립가설을 채택하게 된 경우 어느 그룹 간 차이가 존재하는지는 사후검정 다중비교(post-hoc pair-wise multiple comparisons)를 통해서 알 수 있습니다. (rfriend.tistory.com/133)
pandas DataFrame 데이터셋에서 여러개의 숫자형 변수에 대해 for loop 순환문을 사용하여 집단 간 평균 차이 여부를 검정하는 방법은 rfriend.tistory.com/639 포스팅을 참고하세요.
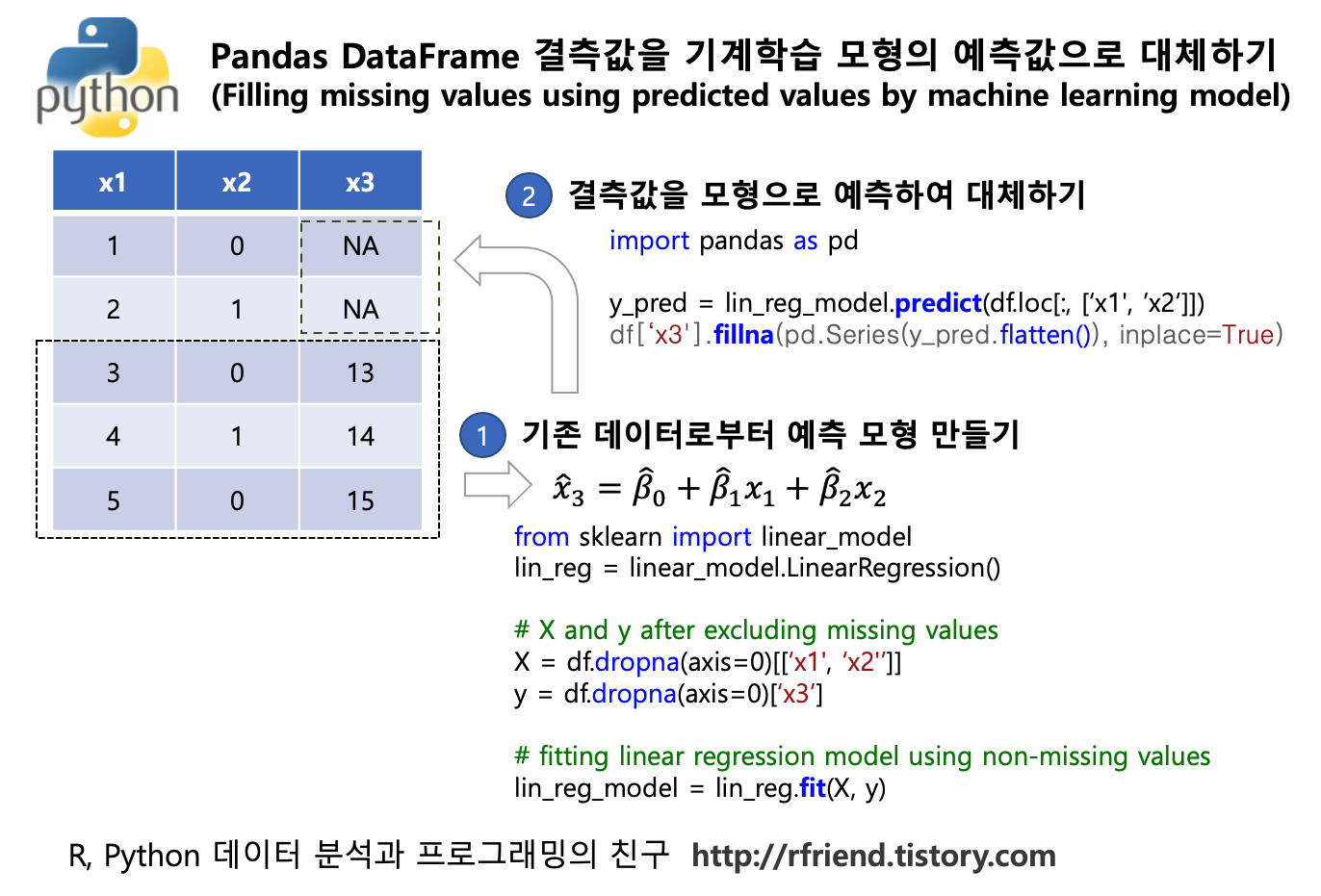
이전 포스팅의 rfriend.tistory.com/262 에서는 Python pandas DataFrame의 결측값을 fillna() 메소드를 사용해서 특정 값으로 채우거나 평균으로 대체하는 방법을 소개하였습니다.
이번 포스팅에서는 Python pandas DataFrame 의 결측값을 선형회귀모형(linear regression model) 을 사용하여 예측/추정하여 채워넣는 방법을 소개하겠습니다. (물론, 아래의 동일한 방법을 사용하여 선형회귀모형 말고 다른 통계, 기계학습 모형을 사용하여 예측/추정한 값으로 대체할 수 있습니다.)
(1) 결측값을 제외한 데이터로부터 선형회귀모형 훈련하기
(training, fitting a linear regression model using non-missing values)
(2) 선형회귀모형으로 부터 추정값 계산하기 (prediction using linear regression model)
(3) pandas 의 fillna() 메소드 또는 numpy의 np.where() 메소드를 사용해서 결측값인 경우 선형회귀모형 추정값으로 대체하기 (filling missing values using the predicted values by linear regression model)
fill missing values of pandas DataFrame using predicted values by machine learning model
아래에는 예제로 사용할 데이터로 전복(abalone) 공개 데이터셋을 읽어와서 1행~3행의 'whole_weight' 칼럼 값을 결측값(NA) 으로 변환해주었습니다.
import pandas as pd
import numpy as np
# read abalone dataset from website
abalone = pd.read_csv("http://archive.ics.uci.edu/ml/machine-learning-databases/abalone/abalone.data",
header=None,
names=['sex', 'length', 'diameter', 'height',
'whole_weight', 'shucked_weight',
'viscera_weight', 'shell_weight', 'rings'])
# get 10 observations as an example
df = abalone.copy()[:10]
# check missing values : no missing value at all
pd.isnull(df).sum()
# sex 0
# length 0
# diameter 0
# height 0
# whole_weight 0
# shucked_weight 0
# viscera_weight 0
# shell_weight 0
# rings 0
# dtype: int64
# insert NA values as an example
df.loc[0:2, 'whole_weight'] = np.nan
df
# sex length diameter height whole_weight shucked_weight viscera_weight shell_weight rings
# 0 M 0.455 0.365 0.095 NaN 0.2245 0.1010 0.150 15
# 1 M 0.350 0.265 0.090 NaN 0.0995 0.0485 0.070 7
# 2 F 0.530 0.420 0.135 NaN 0.2565 0.1415 0.210 9
# 3 M 0.440 0.365 0.125 0.5160 0.2155 0.1140 0.155 10
# 4 I 0.330 0.255 0.080 0.2050 0.0895 0.0395 0.055 7
# 5 I 0.425 0.300 0.095 0.3515 0.1410 0.0775 0.120 8
# 6 F 0.530 0.415 0.150 0.7775 0.2370 0.1415 0.330 20
# 7 F 0.545 0.425 0.125 0.7680 0.2940 0.1495 0.260 16
# 8 M 0.475 0.370 0.125 0.5095 0.2165 0.1125 0.165 9
# 9 F 0.550 0.440 0.150 0.8945 0.3145 0.1510 0.320 19
(1) 결측값을 제외한 데이터로부터 선형회귀모형 훈련하기 (training, fitting a linear regression model using non-missing values)
pandas 패키지의 dropna() 메소드를 이용해서 결측값이 포함된 행을 제거한 후의 설명변수 ' diameter', 'height', 'shell_weight' 를 'X' DataFrame 객체로 만들고, ' whole_weight' 를 종속변수 'y' Series로 만든 후에, sklearn의 linear_model.LinearRegression() 메소드로 lin_reg.fit(X, y) 로 선형회귀모형을 적합하였습니다.
# initiate sklearn's linear regression
from sklearn import linear_model
lin_reg = linear_model.LinearRegression()
# X and y after excluding missing values
X = df.dropna(axis=0)[['diameter', 'height', 'shell_weight']]
y = df.dropna(axis=0)['whole_weight']
# fitting linear regression model using non-missing values
lin_reg_model = lin_reg.fit(X, y)
(2) 선형회귀모형으로 부터 추정값 계산하기 (prediction using linear regression model)
위의 (1)번에서 적합한 모델에 predict() 함수를 사용해서 'whole_weight' 의 값을 추정하였습니다.
(3) pandas 의 fillna() 메소드 또는 numpy의 np.where() 메소드를 사용해서 결측값인 경우 선형회귀모형 추정값으로 대체하기 (filling missing values using the predicted values by linear regression model)
(방법 1) pandas 의 fillna() 메소드를 사용해서 'whole_weight' 값이 결측값인 경우에는 위의 (2)번에서 선형회귀모형을 이용해 추정한 값으로 대체를 합니다. 이때 'y_pred' 는 2D numpy array 형태이므로, 이를 flatten() 메소드를 사용해서 1D array 로 바꾸어주고, 이를 pd.Series() 메소드를 사용해서 Series 데이터 유형으로 변환을 해주었습니다. inplace=True 옵션을 사용해서 df DataFrame 내에서 결측값이 선형회귀모형 추정값으로 대체되고 나서 저장되도록 하였습니다.
(방법 2) numpy의 where() 메소드를 사용해서, 결측값인 경우 (즉, isnull() 이 True) pd.Series(y_pred.flatten()) 값을 가져옥, 결측값이 아닌 경우 기존 값을 가져와서 'whole_weight' 에 값을 할당하도록 하였습니다.
(방법 3) for loop 을 돌면서 매 행의 'whole_weight' 값이 결측값인지 여부를 확인 후, 만약 결측값이면 (isnull() 이 True 이면) 위의 (1)에서 적합된 회귀모형에 X값들을 넣어줘서 예측을 해서 결측값을 채워넣는 사용자 정의함수를 만들고 이를 apply() 함수로 적용하는 방법도 생각해볼 수는 있으나, 데이터 크기가 큰 경우 for loop 연산은 위의 (방법 1), (방법 2) 의 vectorized operation 대비 성능이 많이 뒤떨어지므로 소개는 생략합니다.
## filling missing values using predicted values by a linear regression model
## -- (방법 1) pd.fillna() methods
df['whole_weight'].fillna(pd.Series(y_pred.flatten()), inplace=True)
## -- (방법 2) np.where()
df['whole_weight'] = np.where(df['whole_weight'].isnull(),
pd.Series(y_pred.flatten()),
df['whole_weight'])
## results
df
# sex length diameter height whole_weight shucked_weight viscera_weight shell_weight rings
# 0 M 0.455 0.365 0.095 0.548570 0.2245 0.1010 0.150 15
# 1 M 0.350 0.265 0.090 0.218690 0.0995 0.0485 0.070 7
# 2 F 0.530 0.420 0.135 0.690915 0.2565 0.1415 0.210 9
# 3 M 0.440 0.365 0.125 0.516000 0.2155 0.1140 0.155 10
# 4 I 0.330 0.255 0.080 0.205000 0.0895 0.0395 0.055 7
# 5 I 0.425 0.300 0.095 0.351500 0.1410 0.0775 0.120 8
# 6 F 0.530 0.415 0.150 0.777500 0.2370 0.1415 0.330 20
# 7 F 0.545 0.425 0.125 0.768000 0.2940 0.1495 0.260 16
# 8 M 0.475 0.370 0.125 0.509500 0.2165 0.1125 0.165 9
# 9 F 0.550 0.440 0.150 0.894500 0.3145 0.1510 0.320 19
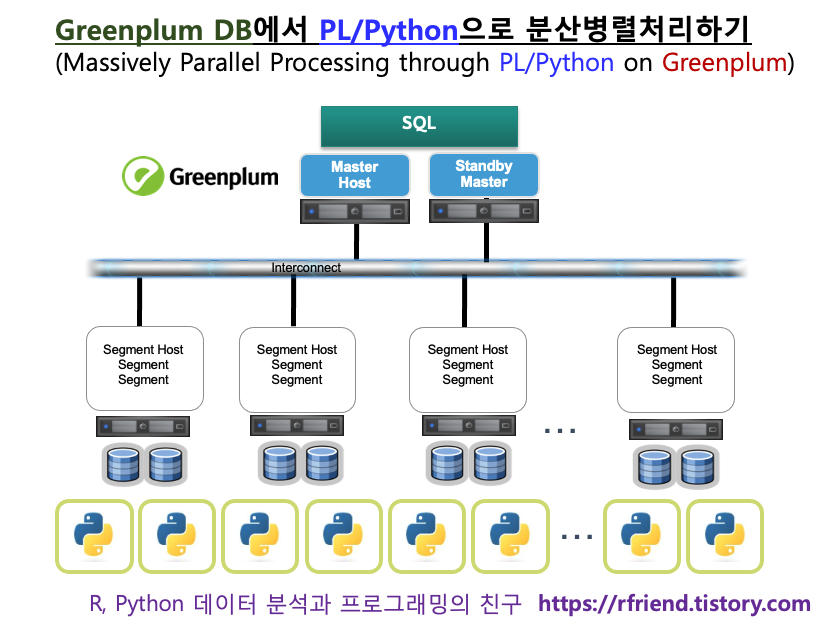
Greenplum DB는 여려개의 PostgreSQL DB를 합쳐놓은 shared-nothing architecture 의 MPP (Massively Parallel Processing) Database 입니다. 손과 발이 되는 여러개의 cluster nodes에 머리가 되는 Master host 가 조율/조정/지시해가면서 분산하여 병렬로 일을 시키고, 각 cluster nodes의 연산처리 결과를 master host 가 모아서 취합하여 최종 결과를 반환하는 방식으로 일을 하기 때문에 (1) 대용량 데이터도 (2) 매우 빠르게 처리할 수 있습니다.
이번 포스팅에서는 여기에서 한발 더 나아가서, Procedural Language Extension (PL/X) 을 사용하여 Python, R, Java, C, Perl, SQL 등의 프로그래밍 언어를 Greenplum DB 내에서 사용하여 데이터의 이동 없이 분산 병렬처리하는 방법을 소개하겠습니다.
Massively Parallel Processing through PL/Python on Greenplum DB
난수를 발생시켜서 만든 가상의 데이터셋을 사용하여 PL/Python으로 Random Forest의 Feature Importance를 숫자형 목표변수('y1_num') 그룹과 범주형 목표변수('y2_cat') 그룹 별로 분산병렬처리하는 간단한 예를 들어보겠습니다.
(b) y2_cat = case when (x4*7.0 + x5*6.0 - x6*4.0 + x4*5.0 + 0.001*random()) >= 9 then 1 else 0 의 함수로 부터 만듦.
(2) PL/Python 함수 정의하기 : (a) 숫자형 목표변수('y1_num') 그룹은 Random Forest Regressor를, (b) 범주형 목표변수('y2_cat') 그룹은 Random Forest Classifier 를 각 그룹별로 분산병렬로 훈련시킨 후, : 각 그룹별 Random Forest Regressor 모델별 200개의 숫자형 변수별 Feature Importance를 반환
(3) PL/Python 함수 실행하기
(4) 각 그룹별 변수별 Random Forest 의 Feature Importance 를 조회하기
를 해 보겠습니다.
(1) 가상의 예제 데이터셋 만들기
- group: 2개의 그룹
(목표변수로 하나는 숫자형, 하나는 범주형 값을 가지는 2개의 X&y 데이터셋 그룹을 생성함.)
(b) y2_cat = case when (x4*7.0 + x5*6.0 - x6*4.0 + x4*5.0 + 0.001*random()) >= 9 then 1 else 0
(y1_num, y2_cat 값을 만들때 x 변수에 곱하는데 사용한 *7.0, *6.0, *5.0 은 아무런 의미 없습니다.
그냥 가상의 예제 샘플 데이터를 만들려고 임의로 선택해서 곱해준 값입니다.)
아래의 예제는 In-DB 처리를 염두에 두고, 200개의 숫자형 X 변수들과 한개의 숫자형 y 변수를 DB의 테이블에 "col_nm"이라는 칼럼에는 변수 이름을, "col_val"에는 변수 값을 long form 으로 생성해서 저장해 놓은 것입니다.
나중에 PL/Python의 함수 안에서 pandas 의 pivot_table() 함수를 사용해서 wide form 으로 DataFrame의 형태를 재구조화해서 random forest 를 분석하게 됩니다.
제 맥북에서 도커로 만든 Greenplum 에는 1개의 master node와 2개의 segment nodes 가 있는데요, 편의상 cross join 으로 똑같은 칼럼과 값을 가지는 설명변수 X 데이터셋을 2의 segment nodes에 replication 해서 그룹1('grp=1'), 그룹2('grp=2')를 만들었습니다.
그리고 여기에 목표변수 y 값으로는 숫자형 목표변수 'y1_num' 칼럼의 값에 대해서는 그룹1('grp=1'), 범주형 목표변수 'y2_cat' 칼럼의 값에 대해서는 그룹2('grp=2')를 부여한 후에, 앞서 만든 설명변수 X 데이터셋에 union all 로 'y1_num'과 'y2_cat' 데이터를 합쳐서 최종으로 하나의 long format의 테이블을 만들었습니다.
첫번째 그룹은 200개의 숫자형 X 변수 중에서 'x1', 'x2', 'x3'의 3개 변수만 숫자형 목표변수(numeric target variable) 인 'y1_num'과 관련이 있고, 나머지 194개의 설명변수와는 관련이 없게끔 y1_num = x1*7.0 + x2*6.0 + x3*5.0 + 0.001*random() 함수를 사용해서 'y1_num' 을 만들었습니다 (*7.0, *6.0, *5.0 은 가상의 예제 데이터를 만들기 위해 임의로 선택한 값으로서, 아무 이유 없습니다). 뒤에서 PL/Python으로 Random Forest Regressor 의 feature importance 결과에서 'x1', 'x2', 'x3' 변수의 Feature Importance 값이 높게 나오는지 살펴보겠습니다.
두번째 그룹은 200개의 숫자형 X변수 중에서 'x4', 'x5', 'x6'의 3개 변수만 범주형 목표변수(categorical target variable) 인 'y2_cat'과 관련이 있고, 나머지 194개의 설명변수와는 연관이 없게끔 y2_cat = case when (x4*7.0 + x5*6.0 - x6*4.0 + x4*5.0 + 0.001*random()) >= 9 then 1 else 0 함수로 부터 가상으로 생성하였습니다. 뒤에서 PL/Python으로 Random Forest Classifier 의 feature importance 결과에서 'x4', 'x5', 'x6' 변수의 Feature Importance 값이 높게 나오는지 살펴보겠습니다.
------------------------------------------------------------------
-- Random Forest's Feature Importance using PL/Python on Greenplum
------------------------------------------------------------------
-- (1) Generate sample data
-- 2 groups
-- 100 observations(ID) per group
-- X: 200 numeric input variables per observation(ID)
-- y : a numeric target variable by a function of y = x1*5.0 + x2*4.5 - x3*4.0 + x4*3.5 + 0.001*random()
-- distributed by 'grp' (group)
-- (1-1) 100 IDs of observations
drop table if exists id_tmp;
create table id_tmp (
id integer
) distributed randomly;
insert into id_tmp (select * from generate_series(1, 100, 1));
select * from id_tmp order by id limit 3;
--id
--1
--2
--3
-- (1-2) 200 X variables
drop table if exists x_tmp;
create table x_tmp (
x integer
) distributed randomly;
insert into x_tmp (select * from generate_series(1, 200, 1));
select * from x_tmp order by x limit 3;
--x
--1
--2
--3
-- (1-3) Cross join of ID and Xs
drop table if exists id_x_tmp;
create table id_x_tmp as (
select * from id_tmp
cross join x_tmp
) distributed randomly;
select count(1) from id_x_tmp;
-- 20,000 -- (id 100 * x 200 = 20,000)
select * from id_x_tmp order by id, x limit 3;
--id x
--1 1
--1 2
--1 3
-- (1-4) Generate X values randomly
drop table if exists x_long_tmp;
create table x_long_tmp as (
select
a.id as id
, x
, 'x'||a.x::text as x_col
, round(random()::numeric, 3) as x_val
from id_x_tmp a
) distributed randomly;
select count(1) from x_long_tmp;
-- 20,000
select * from x_long_tmp order by id, x limit 3;
--id x x_col x_val
--1 1 x1 0.956
--1 2 x2 0.123
--1 3 x3 0.716
select min(x_val) as x_min_val, max(x_val) as x_max_val from x_long_tmp;
--x_min_val x_max_val
--0.000 1.000
-- (1-5) create y values
drop table if exists y_tmp;
create table y_tmp as (
select
s.id
, (s.x1*7.0 + s.x2*6.0 + s.x3*5.0 + 0.001*random()) as y1_num -- numeric
, case when (s.x4*7.0 + s.x5*6.0 + s.x6*5.0 + 0.001*random()) >= 9
then 1
else 0
end as y2_cat -- categorical
from (
select distinct(a.id) as id, x1, x2, x3, x4, x5, x6 from x_long_tmp as a
left join (select id, x_val as x1 from x_long_tmp where x_col = 'x1') b
on a.id = b.id
left join (select id, x_val as x2 from x_long_tmp where x_col = 'x2') c
on a.id = c.id
left join (select id, x_val as x3 from x_long_tmp where x_col = 'x3') d
on a.id = d.id
left join (select id, x_val as x4 from x_long_tmp where x_col = 'x4') e
on a.id = e.id
left join (select id, x_val as x5 from x_long_tmp where x_col = 'x5') f
on a.id = f.id
left join (select id, x_val as x6 from x_long_tmp where x_col = 'x6') g
on a.id = g.id
) s
) distributed randomly;
select count(1) from y_tmp;
--100
select * from y_tmp order by id limit 5;
--id y1_num y2_cat
--1 11.0104868695838 1
--2 10.2772997177048 0
--3 7.81790575686749 0
--4 8.89387259676540 1
--5 2.47530914815422 1
-- (1-6) replicate X table to all clusters
-- by the number of 'y' varialbes. (in this case, there are 2 y variables, 'y1_num' and 'y2_cat'
drop table if exists long_x_grp_tmp;
create table long_x_grp_tmp as (
select
b.grp as grp
, a.id as id
, a.x_col as col_nm
, a.x_val as col_val
from x_long_tmp as a
cross join (
select generate_series(1, c.y_col_cnt) as grp
from (
select (count(distinct column_name) - 1) as y_col_cnt
from information_schema.columns
where table_name = 'y_tmp' and table_schema = 'public') c
) as b -- number of clusters
) distributed randomly;
select count(1) from long_x_grp_tmp;
-- 40,000 -- 2 (y_col_cnt) * 20,000 (x_col_cnt)
select * from long_x_grp_tmp order by id limit 5;
--grp id col_nm col_val
--1 1 x161 0.499
--2 1 x114 0.087
--1 1 x170 0.683
--2 1 x4 0.037
--2 1 x45 0.995
-- (1-7) create table in long format with x and y
drop table if exists long_x_y;
create table long_x_y as (
select x.*
from long_x_grp_tmp as x
union all
select 1::int as grp, y1.id as id, 'y1_num'::text as col_nm, y1.y1_num as col_val
from y_tmp as y1
union all
select 2::int as grp, y2.id as id, 'y2_cat'::text as col_nm, y2.y2_cat as col_val
from y_tmp as y2
) distributed randomly;
select count(1) from long_x_y;
-- 40,200 (x 40,000 + y1_num 100 + y2_cat 100)
select grp, count(1) from long_x_y group by 1 order by 1;
--grp count
--1 20100
--2 20100
select * from long_x_y where grp=1 order by id, col_nm desc limit 5;
--grp id col_nm col_val
--1 1 y1_num 11.010
--1 1 x99 0.737
--1 1 x98 0.071
--1 1 x97 0.223
--1 1 x96 0.289
select * from long_x_y where grp=2 order by id, col_nm desc limit 5;
--grp id col_nm col_val
--2 1 y2_cat 1.0
--2 1 x99 0.737
--2 1 x98 0.071
--2 1 x97 0.223
--2 1 x96 0.289
-- drop temparary tables
drop table if exists id_tmp;
drop table if exists x_tmp;
drop table if exists id_x_tmp;
drop table if exists x_long_tmp;
drop table if exists y_tmp;
drop table if exists long_x_grp_tmp;
(2) PL/Python 사용자 정의함수 정의하기
- (2-1) composite return type 정의하기
PL/Python로 분산병렬로 연산한 Random Forest의 feature importance (또는 variable importance) 결과를 반환할 때 텍스트 데이터 유형의 '목표변수 이름(y_col_nm)', '설명변수 이름(x_col_nm)'과 '변수 중요도(feat_impo)' 의 array 형태로 반환하게 됩니다. 반환하는 데이터가 '텍스트'와 'float8' 로 서로 다른 데이터 유형이 섞여 있으므로 composite type 의 return type 을 만들어줍니다. 그리고 PL/Python은 array 형태로 반환하므로 text[], text[] 과 같이 '[]' 로서 array 형태로 반환함을 명시합니다.
-- define composite return type
drop type if exists plpy_rf_feat_impo_type cascade;
create type plpy_rf_feat_impo_type as (
y_col_nm text[]
, x_col_nm text[]
, feat_impo float8[]
);
- (2-2) Random Forest feature importance 결과를 반환하는 PL/Python 함수 정의하기
PL/Python 사용자 정의 함수를 정의할 때는 아래와 같이 PostgreSQL의 Procedural Language 함수 정의하는 표준 SQL 문을 사용합니다.
input data 는 array 형태이므로 칼럼 이름 뒤에 데이터 유형에는 '[]'를 붙여줍니다.
중간의 $$ ... python code block ... $$ 부분에 pure python code 를 넣어줍니다.
제일 마지막에 PL/X 언어로서 language 'plpythonu' 으로 PL/Python 임을 명시적으로 지정해줍니다.
create or replace function function_name(column1 data_type1[], column2 data_type2[], ...) returns return_type as $$ ... python code block ... $$ language 'plpythonu';
만약 PL/Container 를 사용한다면 명령 프롬프트 창에서 아래처럼 $ plcontainer runtime-show 로 Runtime ID를 확인 한 후에,
PL/Python 코드블록의 시작 부분에 $$ # container: container_Runtime_ID 로서 사용하고자 하는 docker container 의 runtime ID를 지정해주고, 제일 마지막 부분에 $$ language 'plcontainer'; 로 확장 언어를 'plcontainer'로 지정해주면 됩니다. PL/Container를 사용하면 최신의 Python 3.x 버전을 사용할 수 있는 장점이 있습니다.
create or replace function function_name(column1 data_type1[], column2 data_type2[], ...) returns return_type as $$ # container: plc_python3_shared ... python code block ... $$ LANGUAGE 'plcontainer';
아래 코드에서는 array 형태의 'id', 'col_nm', 'col_val'의 3개 칼럼을 input 으로 받아서 먼저 pandas DataFrame으로 만들어 준 후에, 이를 pandas pivot_table() 함수를 사용해서 long form --> wide form 으로 데이터를 재구조화 해주었습니다.
다음으로, 숫자형의 목표변수('y1_num')를 가지는 그룹1 데이터셋에 대해서는 sklearn 패키지의 RandomForestRegressor 클래스를 사용해서 Random Forest 모델을 훈련하고, 범주형의 목표변수('y2_cat')를 가지는 그룹2의 데이터셋에 대해서는 sklearn 패키지의 RandomForestClassifier 클래스를 사용하여 모델을 훈련하였습니다. 그리고 'rf_regr_fitted.feature_importances_' , 'rf_clas_fitted.feature_importances_'를 사용해서 200개의 각 변수별 feature importance 속성을 리스트로 가져왔습니다.
마지막에 return {'y_col_nm': y_col_nm, 'x_col_nm': x_col_nm_list, 'feat_impo': feat_impo} 에서 전체 변수 리스트와 변수 중요도 연산 결과를 array 형태로 반환하게 했습니다.
----------------------------------
-- PL/Python UDF for Random Forest
----------------------------------
-- define PL/Python function
drop function if exists plpy_rf_feat_impo_func(text[], text[], text[]);
create or replace function plpy_rf_feat_impo_func(
id_arr text[]
, col_nm_arr text[]
, col_val_arr text[]
) returns plpy_rf_feat_impo_type as
$$
#import numpy as np
import pandas as pd
# making a DataFrame
xy_df = pd.DataFrame({
'id': id_arr
, 'col_nm': col_nm_arr
, 'col_val': col_val_arr
})
# pivoting a table
xy_pvt = pd.pivot_table(xy_df
, index = ['id']
, columns = 'col_nm'
, values = 'col_val'
, aggfunc = 'first'
, fill_value = 0)
X = xy_pvt[xy_pvt.columns.difference(['y1_num', 'y2_cat'])]
X = X.astype(float)
x_col_nm_list = X.columns
# UDF for Feature Importance by RandomForestRegressor
def rf_regr_feat_impo(X, y):
# training RandomForestRegressor
from sklearn.ensemble import RandomForestRegressor
rf_regr = RandomForestRegressor(n_estimators=200)
rf_regr_fitted = rf_regr.fit(X, y)
# The impurity-based feature importances.
rf_regr_feat_impo = rf_regr_fitted.feature_importances_
return rf_regr_feat_impo
# UDF for Feature Importance by RandomForestClassifier
def rf_clas_feat_impo(X, y):
# training RandomForestClassifier with balanced class_weight
from sklearn.ensemble import RandomForestClassifier
rf_clas = RandomForestClassifier(n_estimators=200, class_weight='balanced')
rf_clas_fitted = rf_clas.fit(X, y)
# The impurity-based feature importances.
rf_clas_feat_impo = rf_clas_fitted.feature_importances_
return rf_clas_feat_impo
# training RandomForest and getting variable(feature) importance
if 'y1_num' in xy_pvt.columns:
y_target = 'y1_num'
y = xy_pvt[y_target]
feat_impo = rf_regr_feat_impo(X, y)
if 'y2_cat' in xy_pvt.columns:
y_target = 'y2_cat'
y = xy_pvt[y_target]
y = y.astype(int)
feat_impo = rf_clas_feat_impo(X, y)
feat_impo_df = pd.DataFrame({
'y_col_nm': y_target
, 'x_col_nm': x_col_nm_list
, 'feat_impo': feat_impo
})
# returning the results of feature importances
return {
'y_col_nm': feat_impo_df['y_col_nm']
, 'x_col_nm': feat_impo_df['x_col_nm']
, 'feat_impo': feat_impo_df['feat_impo']
}
$$ language 'plpythonu';
(3) PL/Python 함수 실행하기
PL/Python 함수를 실행할 때는 표준 SQL Query 문의 "SELECT group_name, pl_python_function() FROM table_name" 처럼 함수를 SELECT 문으로 직접 호출해서 사용합니다.
PL/Python의 input 으로 array 형태의 데이터를 넣어주므로, 아래처럼 FROM 절의 sub query 에 array_agg() 함수로 먼저 데이터를 'grp' 그룹 별로 array aggregation 하였습니다.
PL/Python 함수의 전체 결과를 모두 반환할 것이므로(plpy_rf_var_impo_func()).* 처럼 함수를 모두 감싼 후에 ().* 를 사용하였습니다. (실수해서 빼먹기 쉬우므로 유의하시기 바랍니다.)
목표변수가 숫자형('y1_num')과 범주형('y2_cat')'별로 그룹1과 그룹2로 나누어서, 'grp' 그룹별로 분산병렬로 Random Forest 분석이 진행되며, Variable importance 결과를 'grp' 그룹 ID를 기준으로 분산해서 저장(distributed by (grp);)하게끔 해주었습니다.
-- execute PL/Python function
drop table if exists rf_feat_impo_result;
create table rf_feat_impo_result as (
select
a.grp
, (plpy_rf_feat_impo_func(
a.id_arr
, a.col_nm_arr
, a.col_val_arr
)).*
from (
select
c.grp
, array_agg(c.id::text order by id) as id_arr
, array_agg(c.col_nm::text order by id) as col_nm_arr
, array_agg(c.col_val::text order by id) as col_val_arr
from long_x_y as c
group by grp
) a
) distributed by (grp);
(4) 각 그룹별 변수별 Random Forest 의 Feature Importance 조회하기
위의 (3)번을 실행해서 나온 결과를 조회하면 아래와 같이 'grp=1', 'grp=2' 별로 각 칼럼별로 Random Forest에 의해 계산된 변수 중요도(variable importance) 가 array 형태로 저장되어 있음을 알 수 있습니다.
select count(1) from rf_feat_impo_result;
-- 2
-- results in array-format
select * from rf_feat_impo_result order by grp;
plpython_random_forest_feature_importance_array
위의 array 형태의 결과는 사람이 눈으로 보기에 불편하므로, unnest() 함수를 써서 long form 으로 길게 풀어서 결과를 조회해 보겠습니다.
이번 예제에서는 난수로 생성한 X설명변수에 임의로 함수를 사용해서 숫자형 목표변수('y1_num')를 가지는 그룹1에 대해서는 'x1', 'x2', 'x3' 의 순서대로 변수가 중요하고, 범주형 목표변수('y2_cat')를 가지는 그룹2에서는 'x4', 'x5', 'x6'의 순서대로 변수가 중요하게 가상의 예제 데이터셋을 만들어주었습니다. (random() 함수로 난수를 생성해서 예제 데이터셋을 만들었으므로, 매번 실행할 때마다 숫자는 달라집니다).
아래 feature importance 결과를 보니, 역시 그룹1의 데이터셋에 대해서는 'x1', 'x2', 'x3' 변수가 중요하게 나왔고, 그룹2의 데이터셋에 대해서는 'x4', 'x5', 'x6' 변수가 중요하다고 나왔네요.
-- display the results using unnest()
select
grp
, unnest(y_col_nm) as y_col_nm
, unnest(x_col_nm) as x_col_nm
, unnest(feat_impo) as feat_impo
from rf_feat_impo_result
where grp = 1
order by feat_impo desc
limit 10;
--grp y_col_nm x_col_nm feat_impo
--1 y1_num x1 0.4538784064497847
--1 y1_num x2 0.1328532144509229
--1 y1_num x3 0.10484121806286809
--1 y1_num x34 0.006843343319633915
--1 y1_num x42 0.006804819286213849
--1 y1_num x182 0.005771113354638556
--1 y1_num x143 0.005220090515711377
--1 y1_num x154 0.005101366229848041
--1 y1_num x46 0.004571420249598611
--1 y1_num x57 0.004375780774099066
select
grp
, unnest(y_col_nm) as y_col_nm
, unnest(x_col_nm) as x_col_nm
, unnest(feat_impo) as feat_impo
from rf_feat_impo_result
where grp = 2
order by feat_impo desc
limit 10;
--grp y_col_nm x_col_nm feat_impo
--2 y2_cat x4 0.07490484681851341
--2 y2_cat x5 0.04099924609654107
--2 y2_cat x6 0.03431643243509608
--2 y2_cat x12 0.01474464870781392
--2 y2_cat x40 0.013865405628514437
--2 y2_cat x37 0.013435535581862938
--2 y2_cat x167 0.013236591006394367
--2 y2_cat x133 0.012570295279560963
--2 y2_cat x142 0.012177597741973058
--2 y2_cat x116 0.011713289042962961
-- The end.
2. pandas DataFrame 에 특정 칼럼 포함 여부 확인하기 : 'col' in df.columns
'column_name' in df.columns 구문 형식으로 특정 칼럼이 포함되어있는지 여부를 True, False 의 boolean 형식으로 반환받을 수 있습니다. 이를 if 조건문과 함께 사용해서 특정 칼럼의 포함 여부에 따라 분기문을 만들 수 있습니다.
# DataFrame의 칼럼 포함 여부 확인하기
'x1' in df.columns
[Out]: True
'x5' in df.columns
[Out]: False
if 'x1' in df.columns:
print('column x1 is in df DataFrame')
[Out]: column x1 is in df DataFrame
3. pandas DataFrame 에서 특정 칼럼 선택하기
# 특정 칼럼 선택하기
y = df['y']
y
[Out]:
1 1
2 2
3 3
4 10
Name: y, dtype: int64
# 여러개 칼럼 선택하기
X = df[['x1', 'x2', 'x3']]
X
[Out]:
x1 x2 x3
1 0.1 10 0.1
2 0.1 20 0.3
3 0.2 30 0.2
4 0.2 80 0.6
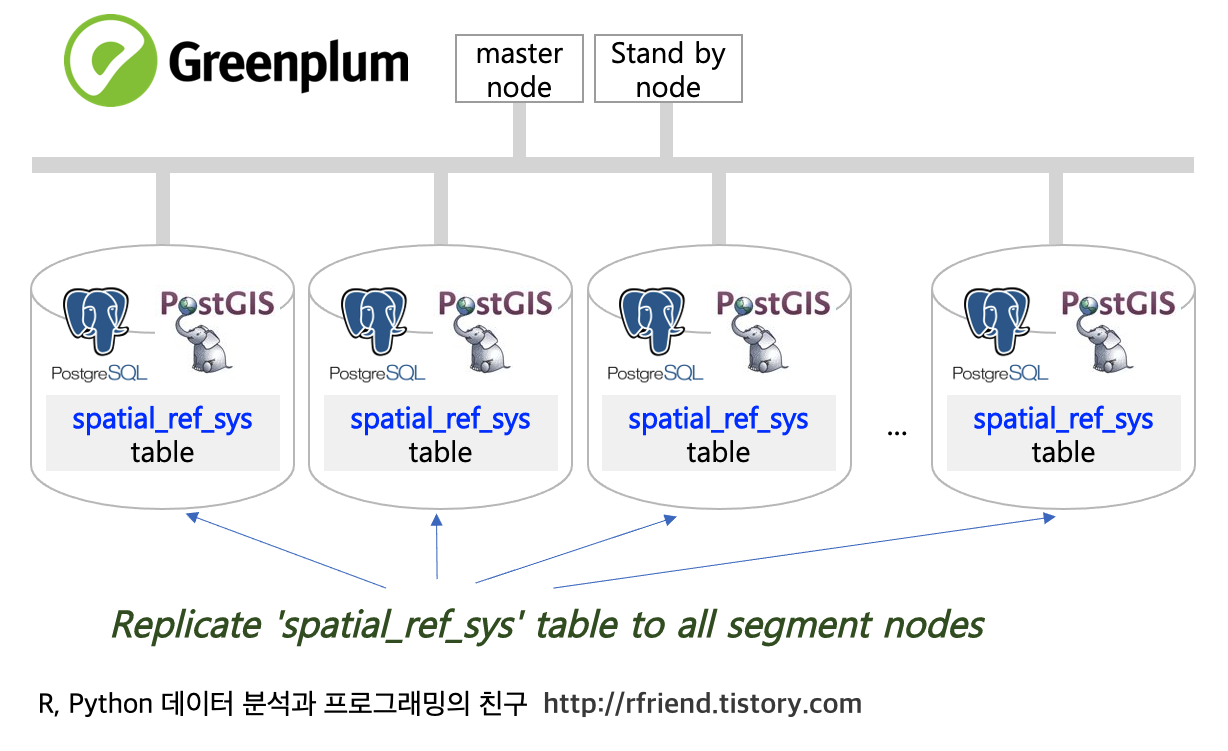
지난번 포스팅 (rfriend.tistory.com/631) 에서는 Greenplum DB에서 PostGIS 를 사용하여 좌표 인식, 변환, 계산을 하기 위해서 필요한 좌표계 참조 테이블인 PostGIS의 spatial_ref_sys 테이블을 모든 segment nodes 에 복제하는 방법을 소개하였습니다.
이번 포스팅에서는 PostGIS의 원래의 spatial_ref_sys 테이블에는 없는 좌표계 (Coordinate Reference System) 를 사용해서 두 개의 좌표계간 변환을 하는 방법을 소개하겠습니다.
(방법 1) spatial_ref_sys 테이블에 새로운 좌표계를 등록하고 (즉, insert into spatial_ref_sys 테이블),
--> PostGIS의 ST_Transform() 함수를 사용해서 좌표계 간 변환하기
(방법 2) PostGIS_Transform_Geometry() 함수를 사용해서 직접 새로운 좌표계로 변환하기
transforming Coordinate Reference System in PostGIS, PostgreSQL, Greenplum
예로서 KATECH 좌표계와 WGS84 좌표계 간 변환하는 방법을 소개하겠습니다.
참고로 KATECH 좌표계는 국내의 포털 사이트의 지도 API 서비스나 국내 네비게이션에서 사용하고 있는 비공식 좌표계로서, 원점으로 위도 38도, 경도 128도의 단일원점을 사용하기 때문에 TM128 좌표계라고도 합니다. KATECH 좌표계는 국내 CNS(자동차 항법장치)를 위해서 만들어진 것으로 3개(서부,중부,동부)의 투영원점을 위도38도, 경도127도 30분의 단일원점으로 통합한 것입니다. (* 출처:hmjkor.tistory.com/377).
(방법 1) (step 1) spatial_ref_sys 테이블에 새로운 좌표계를 등록하고 (즉, insert into spatial_ref_sys 테이블),
--> (step 2) PostGIS의 ST_Transform() 함수를 사용해서 좌표계 간 변환하기
(step 1) spatial_ref_sys 테이블에 미등록되어 있는 KATECH 좌표계를 등록하기
* 사전에 Greenplum DB 의 모든 segment nodes에 spatial_ref_sys 테이블이 복제(replication)되어 있어야 합니다.
(step 2) PostGIS 의 ST_Transform() 함수를 사용해서 WGS 84 (SRID 4326) 좌표계를 KATECH (SRID 10000, 위에서 지정한 번호로서, SRID 번호는 지정하기 나름임) 좌표계로 변환.
-- (1st method) using ST_Transform() and CRS information from spatial_ref_sys table
SELECT ST_Transform(ST_SetSRID(ST_Point(-123.365556, 48.428611), 4326), 10000) AS katech_geom;
(방법 2) PostGIS_Transform_Geometry() 함수를 사용해서 직접 새로운 좌표계로 변환하기
두번째는 spatial_ref_sys 테이블에 새로운 좌표계를 등록할 필요없이, PostGIS_Transform_Geometry() 함수안에 (a) 기존의 변환하려는 대상 좌표계 : proj_from, (b) 앞으로 변환하려고 하는 기준 좌표계 : proj_to 를 직접 넣어주는 방식입니다.
위의 (방법 1)에서 사용한 PostGIS의 ST_Transform() 함수의 소스 코드를 까서 살펴보면 그 안에 PostGIS_Transform_Geometry() 함수를 사용하고 있습니다.
아래의 예는 table_with_geometry 라는 from 절의 테이블에서 x_axis, y_axis 의 경도, 위도 좌표를 가져와서 25를 더하고 뺀 값을 ST_MakeEnvelope() 함수로 만든 사각형 Polygon 의 좌표를 WGS 84 에서 KATECH 좌표계로 PostGIS_Transform_Geometry() 함수를 써서 변환해본 것입니다.
이렇게 수작업으로 하면 Greenplum DB의 각 segment nodes에 복제되어 있는 spatial_ref_sys 테이블에 (방법 1 - a) 처럼 KATECH 좌표계를 미리 등록 (insert into) 하지 않고 바로 사용할 수 있는 장점이 있습니다. 하지만, 이런 좌표계 변환을 여러 사용처에서, 반복적으로 해야 하는 경우라면 매번 이렇게 복잡하게 좌표계 정보를 직접 입력하는 것은 번거로고 어려운 뿐만 아니라, human error 를 유발할 위험도 다분히 있기 때문에 추천하지는 않습니다.
PostgreSQL database에서 오픈소스 PostGIS 를 사용하여 지리공간 데이터 변환, 연산 및 분석을 하는데 있어 첫번째로 챙겨야 하는 것이 있다면 지리공간의 기준이 되는 좌표계(Coordinate Reference System)인 SRID (Spatial Reference IDentifier) 를 spatial_ref_sys 테이블의 값으로 설정해주는 것입니다.
SRID 별로 지리공간 좌표 참조 정보가 들어있는 spatial_ref_sys 테이블은 아래와 같이 srid, auth_name, auth_srid, srtext, proj4text 의 칼럼으로 구성되어 있습니다.
예를 들어서, WGS(World Geodetic System) 84 좌표계는 SRID = 4326 으로 조회를 하면 됩니다.
SRID 설정은 PostGIS의 ST_SetSRID() 함수를 사용합니다.
SELECT ST_SetSRID(ST_Point(-123.365556, 48.428611), 4326) AS wgs84long_lat;
wgs84long_lat
-------------------------
POINT(-123.365556 48.428611)
PostgreSQL DB 에서 PostGIS 를 사용해서 두 개의 좌표계 간에 좌표 변환을 하려면 ST_Transform() 함수를 사용하면 간단하게 좌표 변환을 할 수 있습니다. 그런데 만약 Greenplum DB 에서 PostGIS 의 좌표변환 함수인 ST_Transform() 함수를 사용한다면 아래와 같은 에러가 발생할 것입니다. (몇 년 전에 POC를 하는데 아래 에러 해결하려고 workaround 만드느라 반나절 고생했던게 생각나네요. ^^;;;)
"ERROR: function cannot execute on QE slice because it accesses relation spatial_ref_sys"
이런 에러가 발생하는 이유는 Greenplum database의 경우 PostgreSQL 엔진을 기반으로 하고 있지만, Shared nothing 아키텍쳐의 MPP (Massively Parallel Processing) database 로서, ST_Transform() 함수 실행 시 각 segment nodes 가 spatial_ref_sys 좌표계 테이블을 참조하지 못하기 때문입니다. Greenplum DB 에서 이 에러를 해결하기 위해서는 spatial_ref_sys 좌표계 정보가 들어있는 테이블을 여러개의 segment nodes에 복제를 해주면 됩니다.
Greenplum 6.x 버전 부터는 'DISTRIBUTED REPLICATED' 를 사용해서 쉽게 테이블을 각 segment nodes 에 복제할 수 있습니다. (Greenplum 5.x 버전에서는 CROSS JOIN 을 사용해서 각 segment nodes 에 복제해주면 됩니다.)
[ Greenplum 6.x 버전에서 spatial_ref_sys 테이블을 각 segment nodes 에 복제하여 생성하는 절차 ]
(1) 기존의 spatial_ref_sys 테이블을 spatial_ref_sys_old 로 테이블 이름을 바꿔줍니다.
(2) spatial_ref_sys 라는 이름의 테이블을 'DISTRIBUTED REPLICATED' 모드로 해서 각 segment nodes에 복제해서 생성해줍니다. 이때 칼럼 이름과 속성, 제약조건은 아래의 SQL query 를 그래도 복사해서 사용하시면 됩니다.
(3) 위의 (1)번에서 이름을 바꿔놓았던 기존의 테이블인 spatial_ref_sys_old 테이블에서 SELECT 문으로 데이터를 조회해와서 새로 각 테이블에 복제 모드로 생성해놓은 spatial_ref_sys 테이블에 데이터를 삽입해줍니다.
-- (1) changing the spatial_ref_sys table's name
ALTER TABLE spatial_ref_sys RENAME TO spatial_ref_sys_old;
-- (2) creating spatial_ref_sys table using DISTRIBUTED REPLICATED
CREATE TABLE spatial_ref_sys(
srid int4 NOT NULL
, auth_name VARCHAR(256) NULL
, auth_srid INT4 NULL
, srtext VARCHAR(2048) NULL
, proj4text TEXT NOT NULL
, CONSTRAINT spatial_ref_sys_pkey_1 PRIMARY KEY (srid)
, CONSTRAINT spatial_ref_sys_srid_check_1 CHECK (((srid > 0) AND (srid <= 998999)))
)
DISTRIBUTED REPLICATED;
-- (3) inserting spatial_ref_sys_old data inot replicated segments' tables
INSERT INTO spatial_ref_sys SELECT * FROM spatial_ref_sys_old;
이제 spatial_ref_sys 테이블이 모든 segment nodes에 복제가 되었으니 Greenplum DB에서 PostGIS의 ST_Transform() 함수를 사용해서 좌표계 SRID 4326 (WGS 84) 인 데이터를 좌표계 SRID 3785 로 변환해보겠습니다.
-- Mark a point as WGS 84 long lat and then transform to web mercator (Spherical Mercator) --
SELECT ST_Transform(ST_SetSRID(ST_Point(-123.365556, 48.428611), 4326), 3785) AS spere_merc;
spere_merc
---------------------------------
SRID=3785;POINT(-13732990.8753491 6178458.96425423)
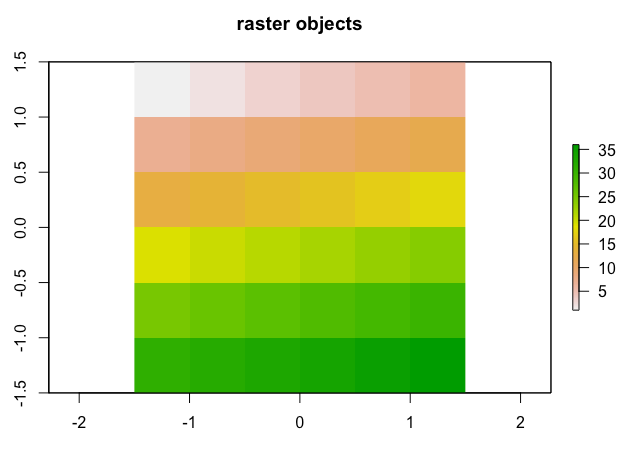
레스터 객체에 대해 summary(raster_obj) 함수를 사용하면 레스터 객체의 픽셀 속성값에 대한 최소값(Minimum value), 1사분위수(1st Quantile), 중위값(Median), 3사분위수(3rd Quantile), 최대값(Maximum value), 결측값 개수(NA's) 에 대한 기술통계량(descriptive statistics)을 확인할 수 있습니다.
## summary() function for raster objects
summary(elev)
# layer
# Min. 1.00
# 1st Qu. 9.75
# Median 18.50
# 3rd Qu. 27.25
# Max. 36.00
# NA's 0.00
레스터 객체의 픽셀 속성값에 대해 cellStats(raster_obj, summary_function) 함수를 사용하여 평균(mean), 분산(variance), 표준편차(standard deviation), 사분위수(quantile), 합계(summation) 를 구할 수 있습니다.
RasterBlack Calss, RasterStack Class와 같이 여러개의 층을 가지는 레스터 클래스 객체 (multi-layered raster classes objects) 에 대해서 앞서 소개한 요약 통계량을 구하는 함수를 적용하면 각 층별로 따로 따로 요약 통계량이 계산됩니다.
(2) 레스터 객체 시각화 하기 (visualizing raster objects)
## -- visualization of raster objects
## plot()
plot(elev, main = "raster objects")
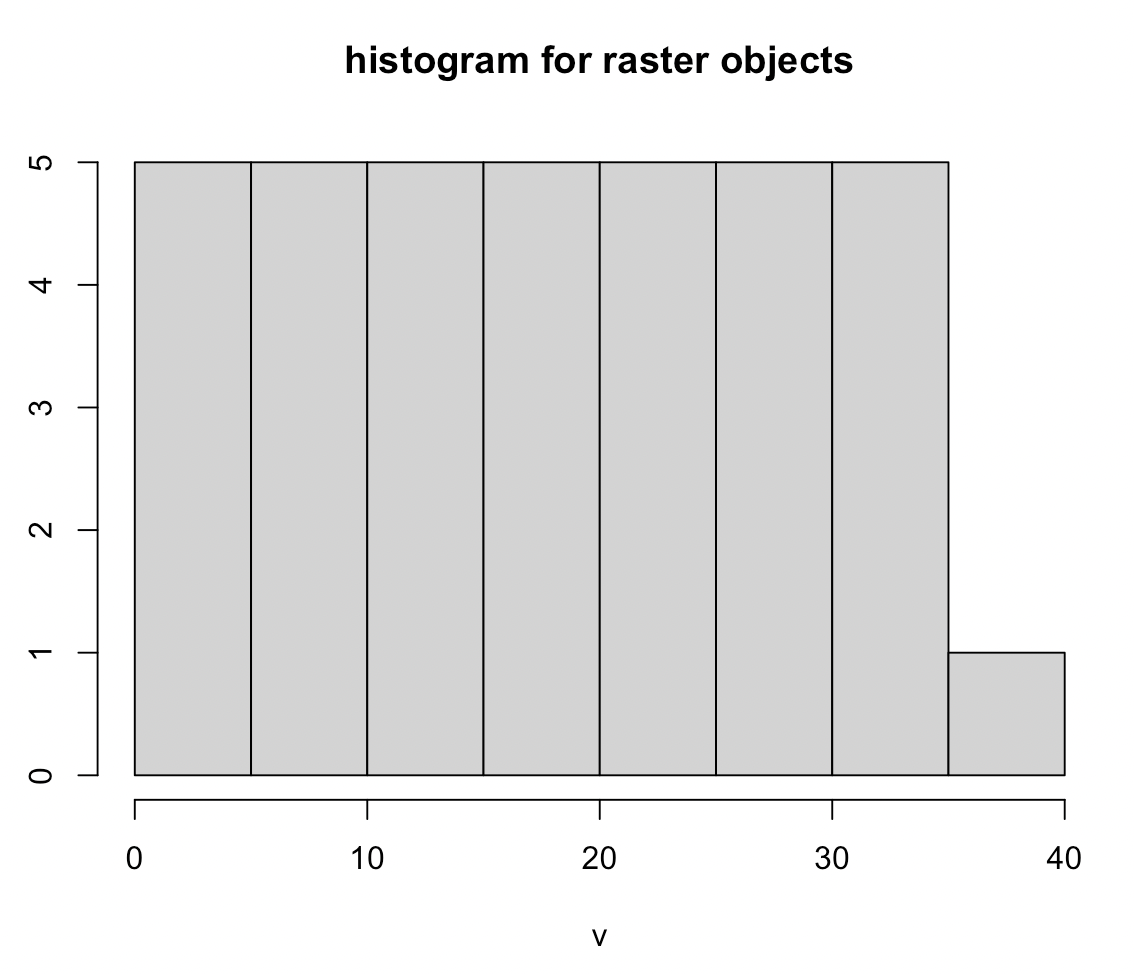
레스터 객체의 픽셀 속성값에 대해 히스토그램(histogram for raster objects)을 그리려면 hist() 함수를 사용하면 됩니다.
## histogram
hist(elev, main = "histogram for raster objects")
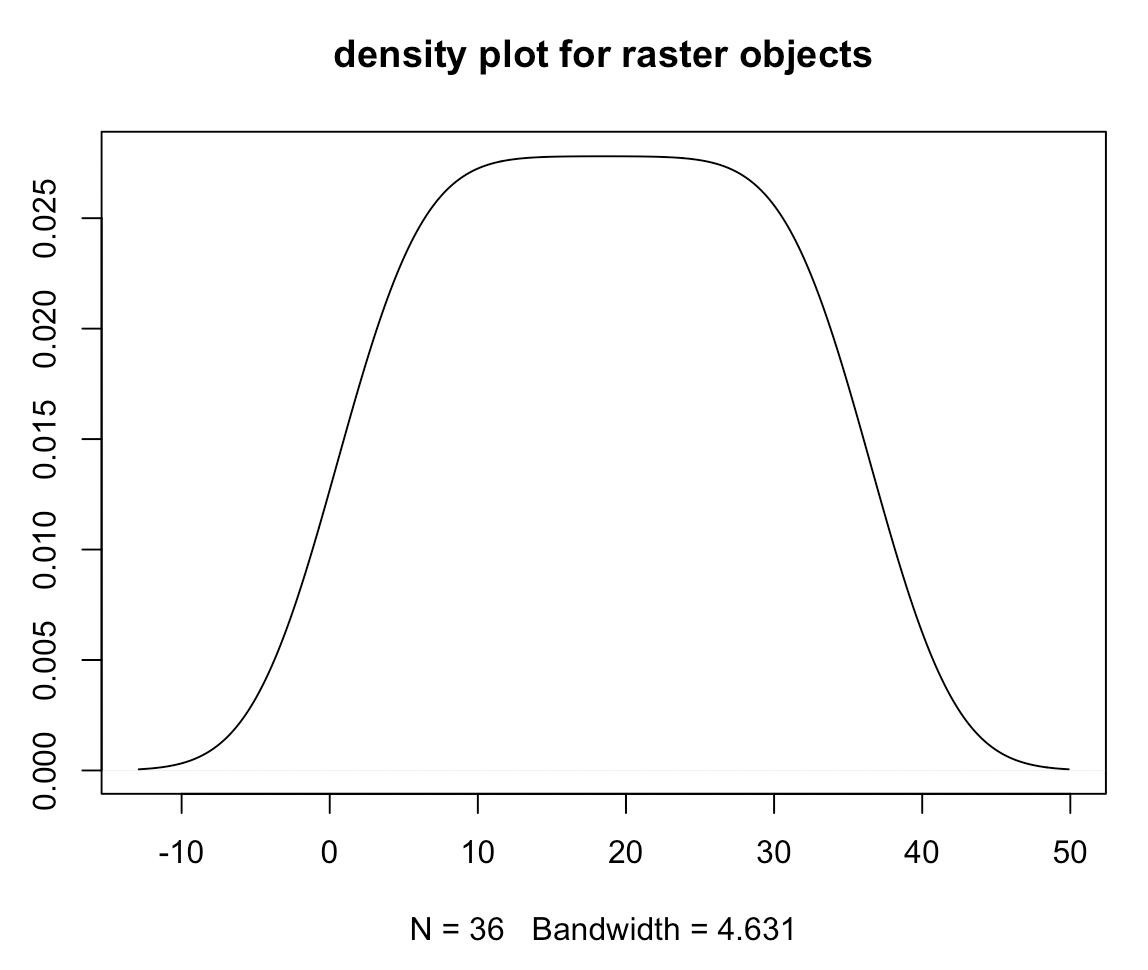
레스터 객체의 픽셀 속성값에 대해서 raster 패키지의 raster::density() 함수를 사용하여 추정 밀도 곡선(smoothed density estimates curve) 을 그릴 수 있습니다.
## raster::density() : density plot (smoothed density estimates)
density(elev, main = "density plot for raster objects")
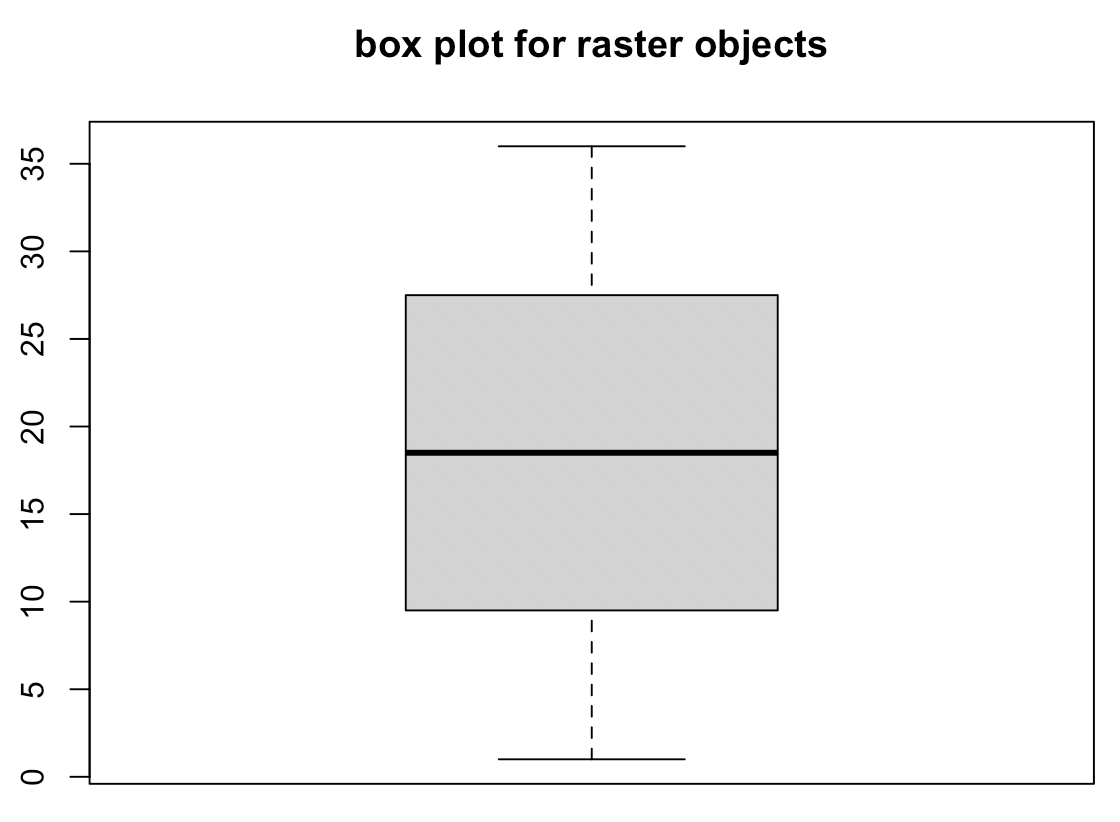
레스터 객체의 픽셀 속성값에 대해 boxplot() 함수를 사용하면 상자그림(box plot for raster objects)을 그릴 수 있습니다.
## boxplot
boxplot(elev, main = "box plot for raster objects")
만약 레스터 객체에 대해 시각화를 하려고 하는데 안된다면 values() 또는 getValues() 함수를 사용해서 레스터 객체로 부터 픽셀의 속성값을 반환받은 결과에 대해서 시각화를 하면 됩니다.