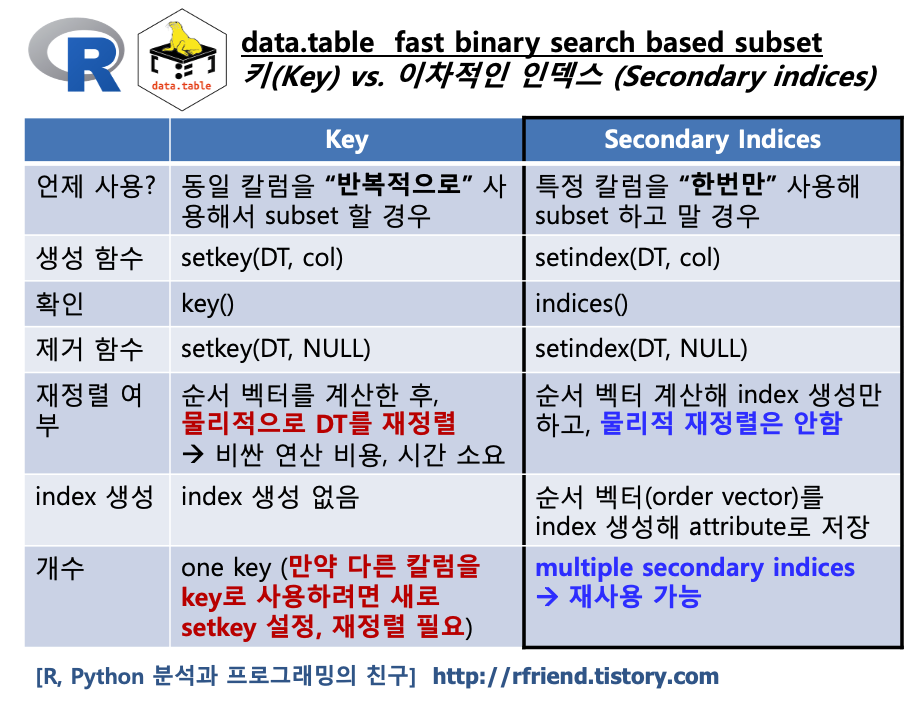
지난번 포스팅에서는 R data.table에서 (a) 키(Key)와 빠른 이진 탐색 기반의 Subsetting 하는 방법 (rfriend.tistory.com/569), (b) 2차 인덱스 (secondary indices) 를 활용하여 data.table 의 재정렬 없이 빠른 탐색 기반 Subsetting 하는 방법을 소개하였습니다. (rfriend.tistory.com/615)
이번 포스팅에서는 R data.table에서 이진 연산자(binary operators) 인 '=='와 '%in%' 를 수행하는 과정에서 이차 인덱스(secondary indices)가 자동으로 인덱싱(Auto indexing)이 되어 빠르게 subsetting 하는 내용을 소개하겠습니다. (이 글을 쓰는 2021년 2월 현재는 '=='와 '%in%' 연산자만 자동 인덱싱이 지원되며, 향후 더 많은 연산자로 확대 전망)
(1) '==' 이진 연산자로 자동 인덱싱하고 속도 비교하기
(2) '%in%' 이진 연산자로 자동 인덱싱하고 속도 비교하기
(3) 전역으로 자동 인덱싱을 비활성화하기 (disable auto indexing globally)
자동 인덱싱의 속도 개선 효과를 확인해 보기 위해서 천만개의 행을 가진 예제 data.table을 난수를 발생시켜서 생성해 보겠습니다. DT data.table의 크기를 object.size()로 재어보니 114.4 Mb 이네요.
## =========================
## R data.table
## : Auto indexing
## =========================
library(data.table)
## create a data.table big enough
set.seed(1L)
DT = data.table(x = sample(x = 1e5L,
size = 1e7L,
replace = TRUE),
y = runif(100L))
head(DT)
# x y
# 1: 24388 0.4023457
# 2: 59521 0.9142361
# 3: 43307 0.2847435
# 4: 69586 0.3440578
# 5: 11571 0.1822614
# 6: 25173 0.8130521
dim(DT)
# [1] 10000000 2
print(object.size(DT), units = "Mb")
# 114.4 Mb
(1) '==' 이진 연산자로 자동 인덱싱하고 속도 비교하기
이전 포스팅의 이차 인덱스(secondary index)에서는 setindex(DT, column) 으로 이차 인덱스를 명시적으로 설정하거나, 또는 'on' 매개변수로 subsetting을 하면 실행 중에 (on the fly) 기존 이차 인덱스가 있는지 여부를 확인해서, 없으면 바로 이차 인덱스를 설정해주다고 하였습니다.
R data.table에서 '==' 이진 연산자를 사용해서 행의 부분집합을 가져오기(subsetting)을 하면 기존 이차 인덱스가 없을 경우 자동으로 인덱싱을 해줍니다. 그래서 처음에 '=='로 subsetting 할 때는 (a) 인덱스를 생성하고 + (b) 부분집합 행 가져오기 (subsetting)를 수행하느라 시간이 오래 소요되지만, 두번째로 실행할 때는 인덱스가 생성이 되어 있으므로 속도가 무척 빨라지게 됩니다!
아래의 예에서 보면 처음으로 DT[x == 500L] 을 실행했을 때는 0.406초가 소요(elapsed time)되었습니다. names(attributes(DT)) 로 확인해 보면 애초에 없던 index 가 새로 생성되었음을 확인할 수 있고, indices(DT) 로 확인해보면 "x" 칼럼에 대해 이차 인덱스가 생성되었네요.
## -- when we use '==' or '%in%' on a single column for the first time,
## a secondary index is created automatically, and used to perform the subset.
## have a look at all the attribute names (no index here)
names(attributes(DT))
# [1] "names" "row.names" "class" ".internal.selfref"
## run the first time
## system.time = the time to create the index + the time to subset
(t1 <- system.time(ans <- DT[x == 500L]))
# user system elapsed
# 0.392 0.014 0.406
head(ans)
# x y
# 1: 500 0.7845248
# 2: 500 0.9612705
# 3: 500 0.4023457
# 4: 500 0.9139429
# 5: 500 0.8280599
# 6: 500 0.2847435
## secondary index is created
names(attributes(DT))
# [1] "names" "row.names" "class" ".internal.selfref"
# [5] "index"
indices(DT)
# [1] "x"
이제 위에서 수행했던 연산과 동일하게 DT[x == 500L] 을 수행해서 소요 시간(elapsed time)을 측정해보면, 연속해서 두번째 수행했을 때는 0.001 초가 걸렸습니다.
## secondary indices are extremely fast in successive subsets.
## successive subsets
(t2 <- system.time(DT[x == 500L]))
# user system elapsed
# 0.001 0.000 0.001
처음 수행했을 때는 0.406초가 걸렸던 것이, 처음 수행할 때 자동 인덱싱(auto indexing)이 된 후에 연속해서 수행했을 때 0.001초가 걸려서 400배 이상 빨라졌습니다! 와우!!!
barplot(c(0.406, 0.001),
horiz = TRUE,
xlab = "elapsed time",
col = c("red", "blue"),
legend.text = c("first time", "second time(auto indexing)"),
main = "R data.table Auto Indexing")

(2) '%in%' 이진 연산자로 자동 인덱싱하고 속도 비교하기
'==' 연산자와 더불어 포함되어 있는지 여부를 확인해서 블리언을 반환하는 '%in%' 연산자를 활용해서 부분집합 행을 가져올 때도 R data.table은 자동 인덱싱(auto indexing)을 하여 이차 인덱스를 생성하고, 기존에 인덱스가 생성되어 있으면 이차 인덱스를 활용하여 빠르게 탐색하고 subsetting 결과를 반환합니다.
아래 예는 x 에 1989~2912 까지의 정수가 포함되어 있는 행을 부분집합으로 가져오기(DT[ x %in% 1989:2912]) 하는 것으로서, 이때 자동으로 인덱스를 생성(auto indexing)해 줍니다.
## '%in%' operator create auto indexing as well
system.time(DT[x %in% 1989:2912])
# user system elapsed
# 0.010 0.016 0.027
행을 subsetting 할 때 사용하는 조건절이 여러개의 칼럼을 대상으로 하는 경우 '&' 연산자를 사용하여 자동 인덱싱을 할 수 있습니다.
## auto indexing to expressions involving more than one column with '&' operator
(t3 <- system.time(DT[x == 500L & y >= 0.5]))
# user system elapsed
# 0.070 0.025 0.097
(3) 전역으로 자동 인덱싱을 비활성화하기 (disable auto indexing globally)
지난번 포스팅에서 지역적으로 특정 칼럼의 이차 인덱스를 제거할 때 setindex(DT, NULL) 을 사용한다고 소개하였습니다.
(a) '전역적으로 자동 인덱싱을 비활성화' 하려면 options(datatable.auto.index = FALSE) 를 설정해주면 됩니다.
(b) '전역으로 전체 인덱스를 비활성화' 하려면 options(datatable.use.index = FALSE) 를 설정해주면 됩니다.
## Auto indexing can be disabled by setting the global argument
options(datatable.auto.index = FALSE)
## You can disable indices fully by setting global argument
options(datatable.use.index = FALSE)
[ Reference ]
* R data.table vignettes 'Secondary indices and auto indexing'
: cran.r-project.org/web/packages/data.table/vignettes/datatable-secondary-indices-and-auto-indexing.html
이번 포스팅이 많은 도움이 되었기를 바랍니다.
행복한 데이터 과학자 되세요. :-)

728x90
반응형