Kubernetes 기반의 기계학습 워크플로우를 간소화해주는 Kubeflow 의 Pipelines 를 생성할 때 YAML 파일을 사용합니다. YAML 파일을 쓸 때 들여쓰기나 대소문자에 신경을 써야 하므로, 아무래도 텍스트 편집기나 vmi 편집 기능을 쓰는 것보다는 Kubernetes 를 지원하는 IDE (Integrated Development Environment) 를 사용하는 것이 코딩을 쉽고 빠르게 할 수 있도록 도와주고 또 에러가 사전에 방지할 수 있어서 여러모로 좋습니다.
이번 포스팅에서는 K8s 를 지원하는 프로그래밍 IDE 중에서도 무료로 사용할 수 있는 MS 의
(1) Visual Studio Code 를 설치하고,
(2) Visual Studio Code 에 Kubernetes YAML 언어 지원 확장 팩을 설치하고 설정하고,
(3) Visual Studio Code 의 기능 소개
를 해보겠습니다.
(1) Visual Studio Code 를 설치
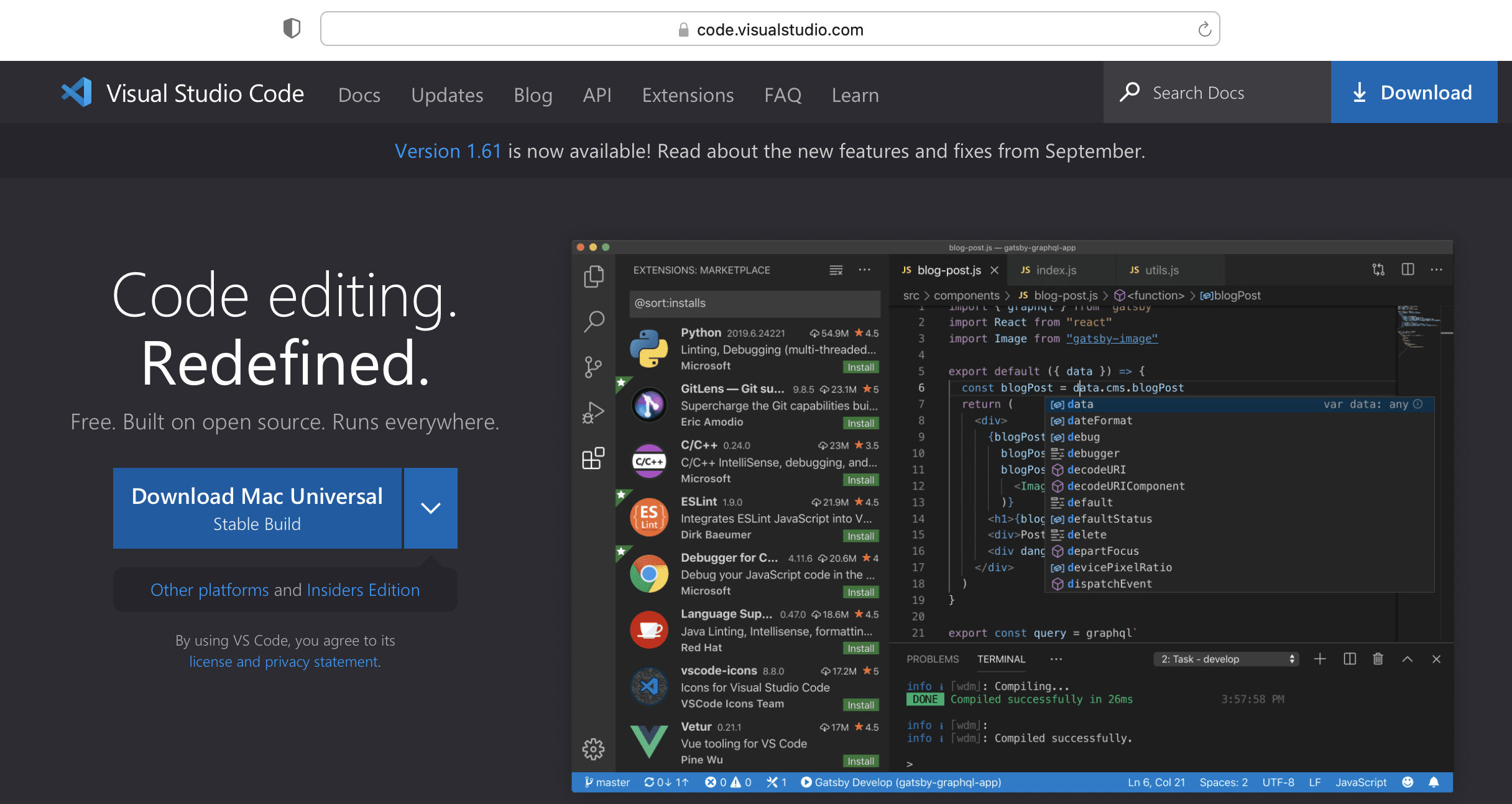
Visual Studio Code 의 홈페이지인 https://code.visualstudio.com/ 에 방문해서 자신이 사용하는 컴퓨터의 OS 에 맞게 VS Code 설치 파일을 다운로드 하여 설치(install)하면 됩니다.
저는 MacBook 을 사용하고 있으므로 'Download Mac Universal (Stable Build)' 를 다운로드 해서 설치했습니다.
Visual Studio Code - Download
(2) Visual Studio Code 에 Kubernetes YAML 언어 지원 확장 팩을 설치하고 설정
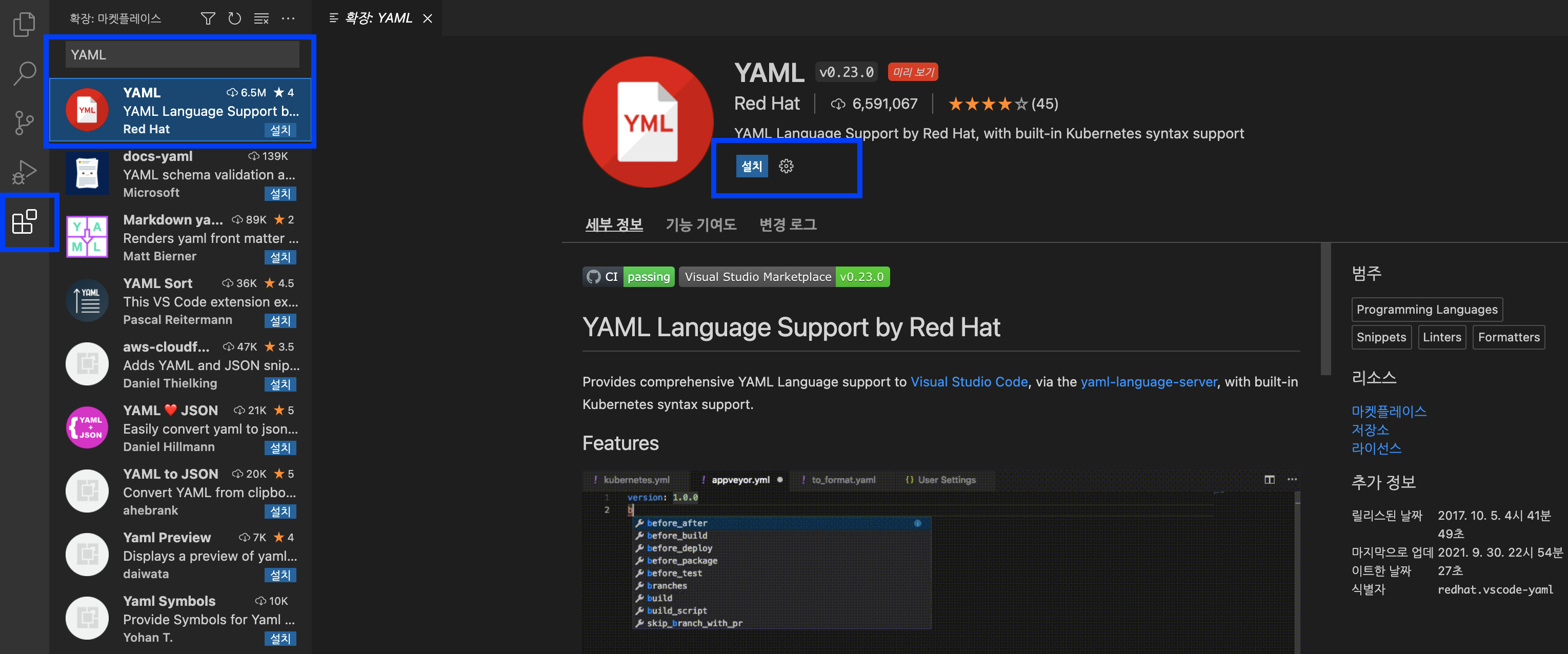
Visual Studio Code 에 Kubernetes YAML 파일의 코드를 인식하고 지원할 수 있도록 Red Hat 에서 제공하는 YAML 확장 팩을 설치해보겠습니다.
Visual Studio Code 의 제일 왼쪽 메뉴의 제일 밑에 있는 네모 모양 (4개의 네모)의 메뉴를 선택한 후 --> YAML 키워드로 검색해서 --> YAML Language Support by Red Hat, with built-in Kubernetes syntax support 를 선택 --> 설치 (install) 단추 클릭
의 순서로 K8s 언어 지원 확장 팩을 설치해 줍니다.
Visual Studio Code - Extension YAML Install
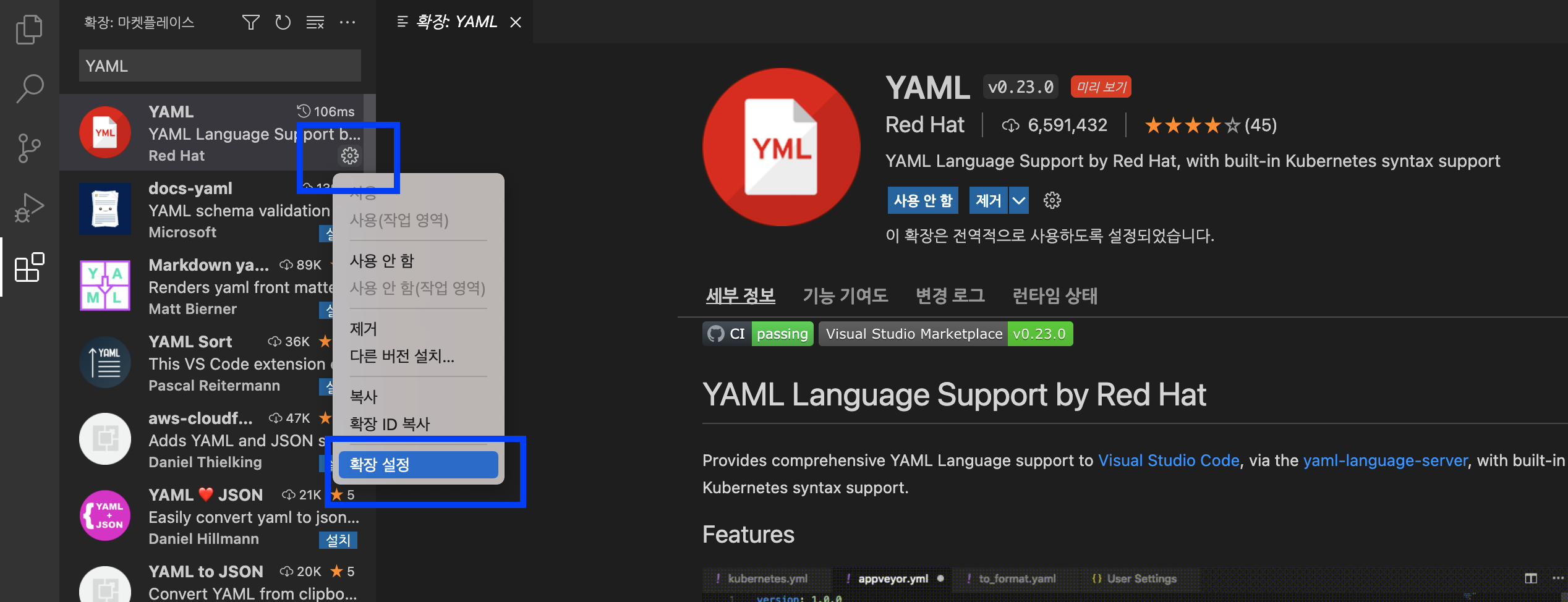
YAML Red Hat 확장 팩을 설치 했으면, 좌측 YAML 의 톱니바퀴 모양의 설정 단추를 선택하고 --> '확장 설정' 을 선택합니다.
Visual Studio Code - Configuration
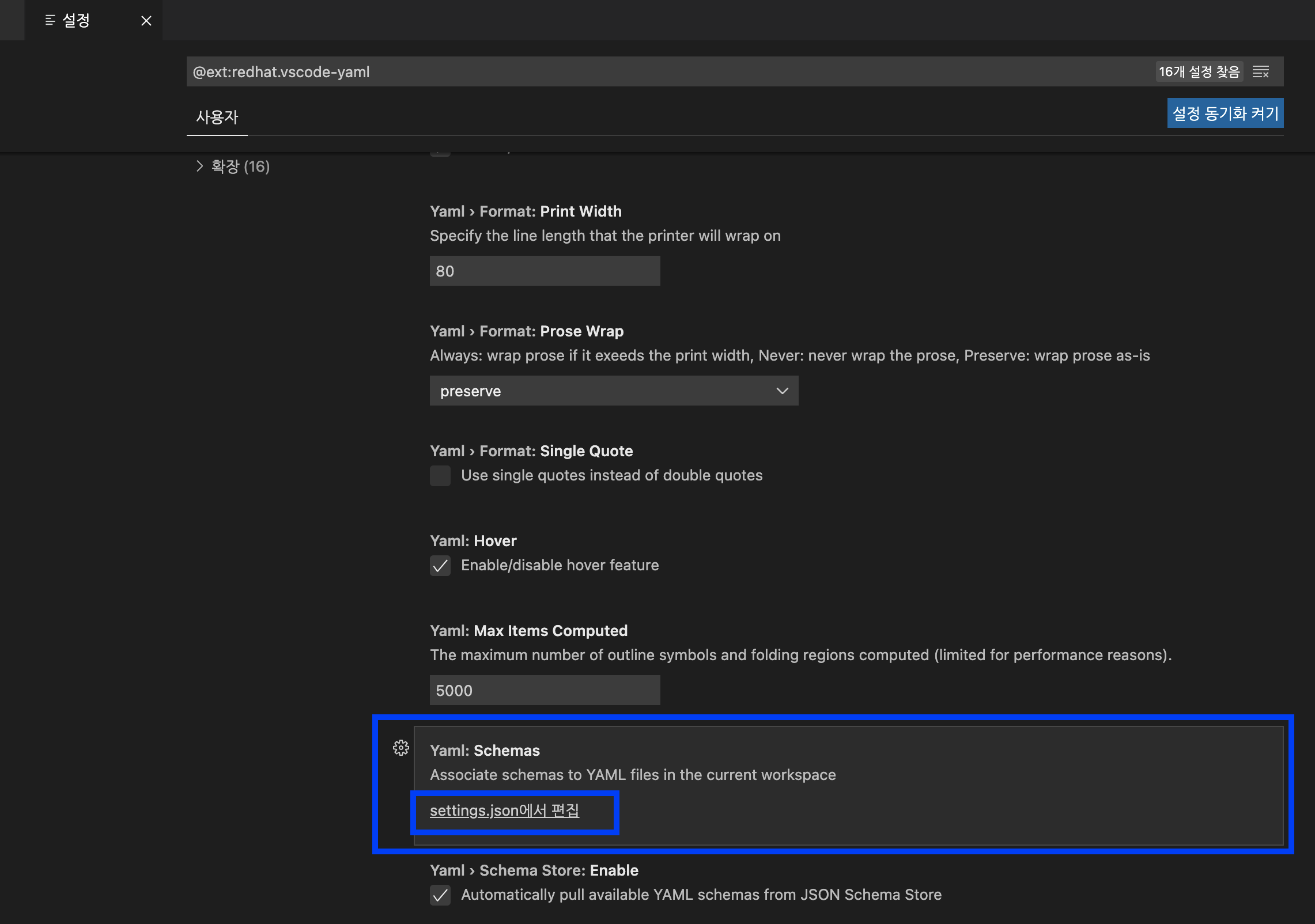
스크롤바를 밑으로 쭉 내리다보면 'Yaml: Schemas' --> 'setting.json 에서 편집' 을 선택합니다.
Visual Studio Code - YAML Schemas
아래의 'setting.json 에서 편집' 창이 비어있을 텐데요, Kubernetes 가 모든 YAML 파일("*.yaml")을 인식할 수 있도록 대괄호 {} 안에 JSON 파일에 입력해줍니다.
Visual Studio Code - settings.json
{
"yaml.schemas": {
"kubernetes": "*.yaml"
},
}
'settings.json' 파일을 저장하고 닫은 다음에, --> Visual Studio Code 를 종료 --> Visual Studio Code 를 다시 시작 합니다. 이제부터 VS Code 에서 K8s 에서 인식하는 모든 YAML 언어지원이 사용가능해요.
Visual Studio Code - Enabled
(3) Visual Studio Code 의 기능 소개
이제 Visual Studio Code 에서 YAML 언어를 선택해서 --> YAML 파일을 생성해보겠습니다.
Visual Studio Code - Select Language YAML
왼쪽 메뉴바의 제일 위에 있는 '신규 생성' --> 탐색기에서 '신규 파일 +' 클릭 --> '신규 파일 이름 입력 (예: nginx.yaml)
해줍니다.
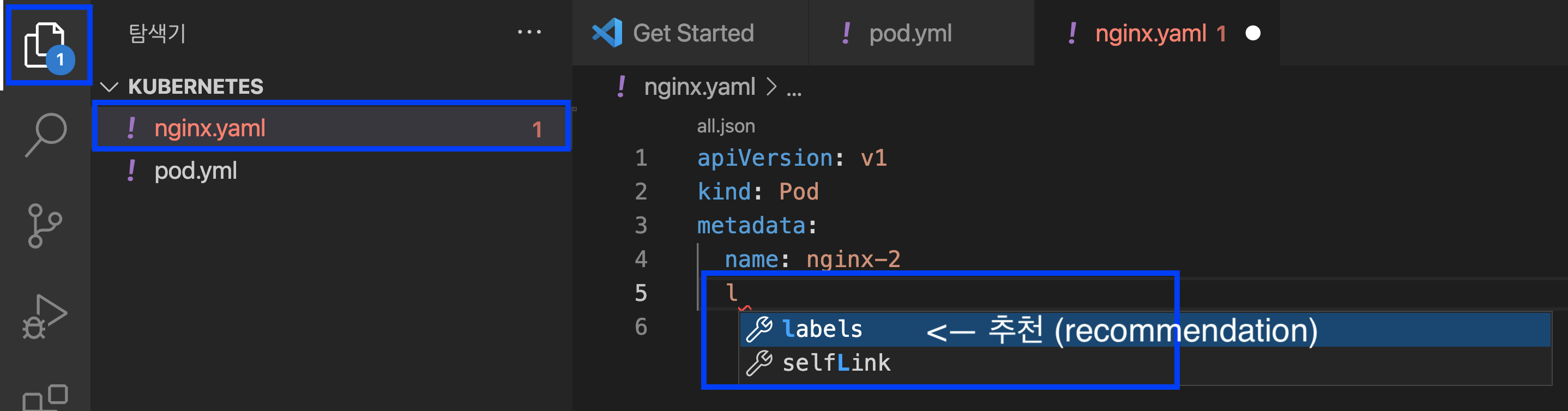
Visual Studio Code 는 신규 생성 파일이 YAML 임을 인식하고는 apiVersion, kind, metadata, spec 을 알려주고, 들여쓰기라든지, dictionary / array 포맷도 알아서 해주고ㅡ Kubernetes YAML 파일의 포맷에 맞추어서 적당한 명령어를 추천(Recommendation) 해줍니다. 이 기능은 편리하기도 하고, 휴먼 에러를 줄일 수 있어서 매우 유용합니다.
Visual Studio Code - Recommendation
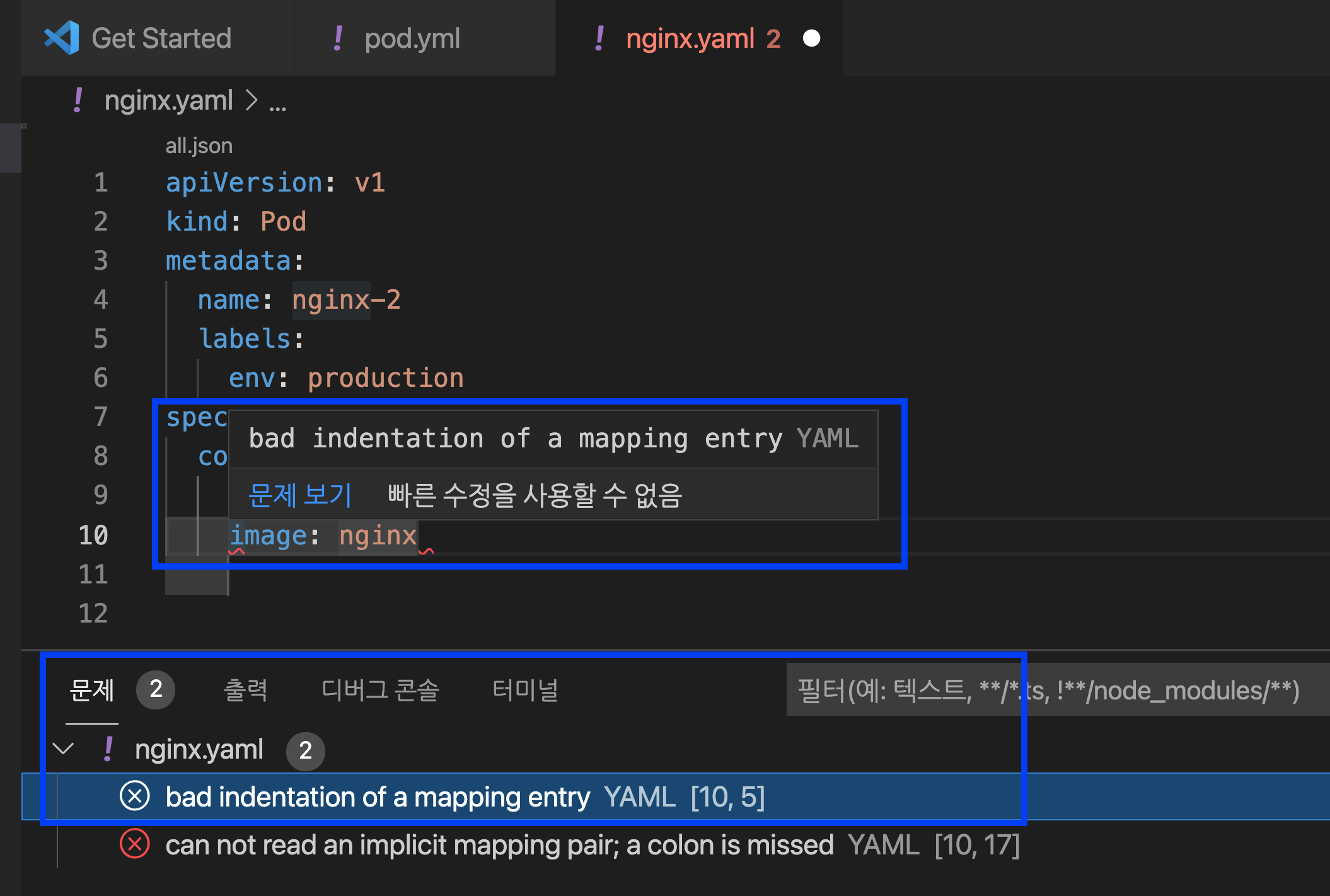
만약 Kubernetes YAML 코딩을 하다가 잘못된 부분이 있으면 에러 메시지를 팝업으로 띄워주고, 하단의 '문제 (problem)' 메뉴에도 에러가 있는 코드의 라인(예: line 10)과 문제(예: bad indentation of a mapping entry YAML [10, 5]) 의 에러 내용도 볼 수 있습니다. 이 기능은 디버깅을 할 때 매우 유용합니다.
Visual Studio Code - Error Message
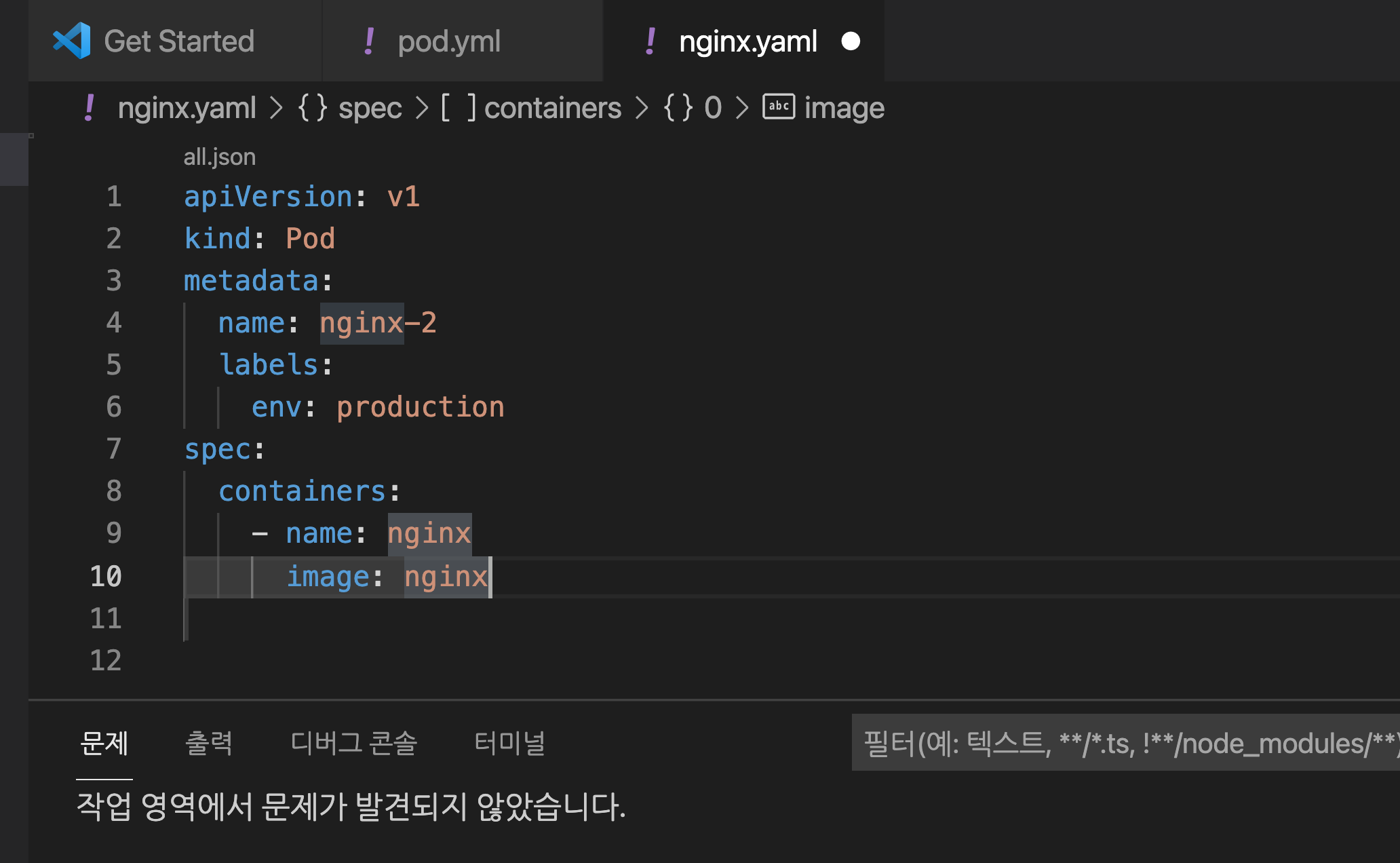
들여쓰기 에러를 바로잡아 주니 에러 메시지가 사라졌습니다. :-)
Visual Studio Code - Error Fixed
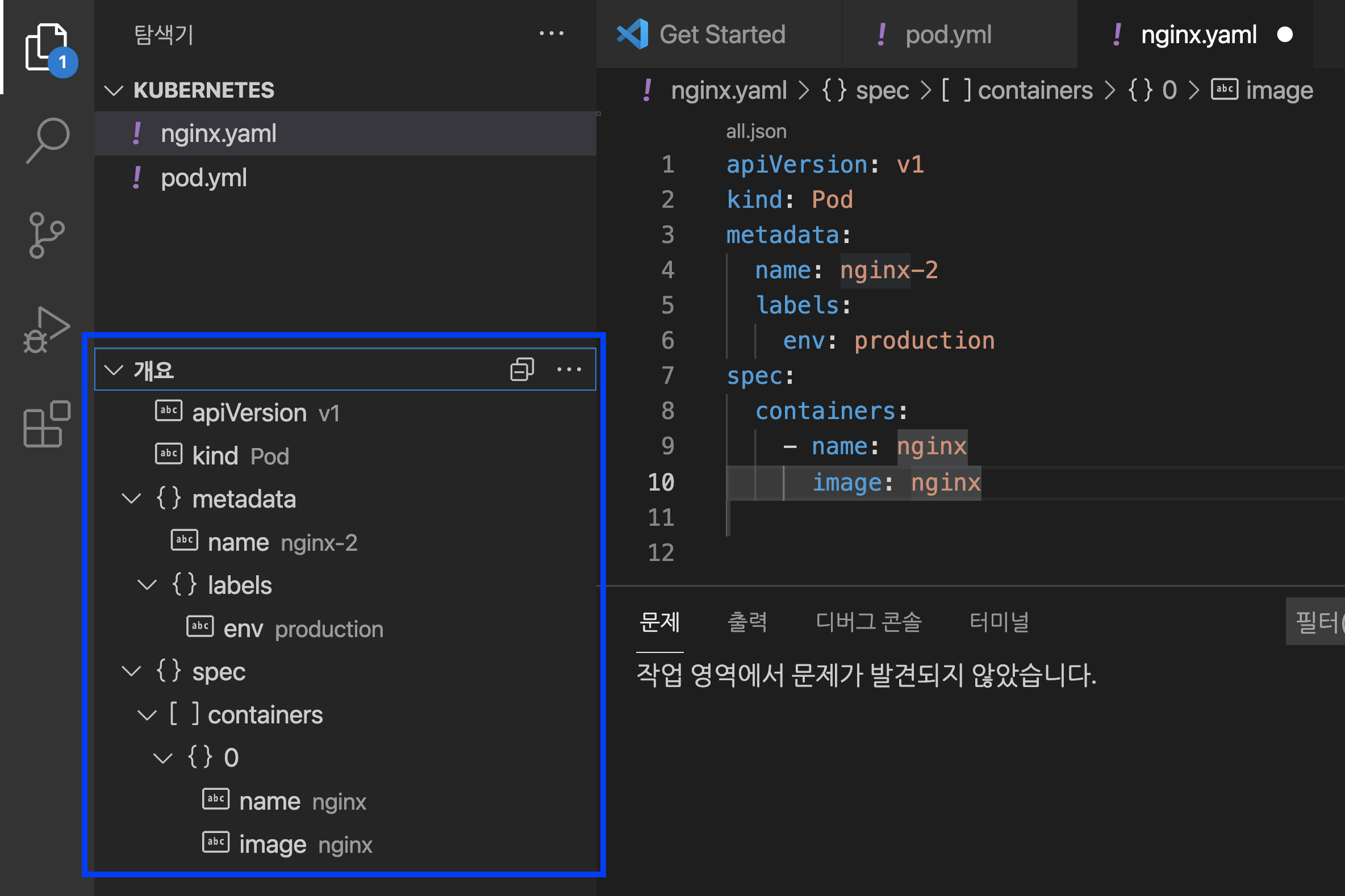
Visual Studio Code 의 왼쪽 하단에 '개요 (Outline)' 메뉴를 선택하면 아래와 같이 YAML 파일의 전체 구조(structure)를 한눈에 빠르게 살펴볼 수 있습니다.
Visual Studio Code - Outline
터미널에서 방금 전에 새로 만든 nginx.yaml 파일을 cat 으로 열어서 살펴보면 아래와 같습니다. 물론 터미널에서 vim 에디터로도 YAML 파일을 만들고 수정할 수 있기는 합니다만, Visual Studio Code 의 편리한 기능들을 생각하면 역시 VS Code IDE 가 훨씬 매력적이긴 합니다.
(base) lhongdon@Hongui-MacBookPro ~ % ls
Applications Downloads Music VirtualBox VMs minikf seaborn-data
Desktop Library Pictures examples minikf-kubeconfig
Documents Movies Public kubernetes opt
(base) lhongdon@Hongui-MacBookPro ~ % cd kubernetes
(base) lhongdon@Hongui-MacBookPro kubernetes % ls
nginx.yaml pod.yml
(base) lhongdon@Hongui-MacBookPro kubernetes %
(base) lhongdon@Hongui-MacBookPro kubernetes %
(base) lhongdon@Hongui-MacBookPro kubernetes % cat nginx.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-2
labels:
env: production
spec:
containers:
- name: nginx
image: nginx
(base) lhongdon@Hongui-MacBookPro kubernetes %
지난번 포스팅에서는 백색잡음과정(White noise process), 확률보행과정(Random walk process), 정상확률과정(Stationary process)에 대해서 소개하였습니다. (https://rfriend.tistory.com/691)
지난번 포스팅에서 특히 ARIMA와 같은 시계열 통계 분석 모형이 정상확률과정(Stationary Process)을 가정한다고 했습니다. 따라서 시계열 통계 모형을 적합하기 전에 분석 대상이 되는 시계열이 정상성 가정(Stationarity assumption)을 만족하는지 확인을 해야 합니다.
[ 정상확률과정 (stationary process) 정의 ]
1. 평균이 일정하다. 2. 분산이 존재하며, 상수이다. 3. 두 시점 사이의 자기공분산은 시차(時差, time lag)에만 의존한다.
정상 시계열 (stationary time series) 여부를 확인하는 방법에는 3가지가 있습니다.
[1] 시계열 그래프 (time series plot)
[2] 통계적 가설 검정 (statistical hypothesis test)
[3] 자기상관함수(ACF), 편자기상관함수(PACF)
정상성 확인하는 방법 (how to check the stationarity)
이번 포스팅에서는 이중에서 통계적 가설 검정 (Statistical Hypothesis Test) 을 이용해 정상성(stationarity) 여부를 확인하는 방법을 소개하겠습니다.
ADF 검정은 시계열에 단위근(unit root)이 존재하는지의 여부를 검정함으로써 정상 시계열인지 여부를 판단합니다. 단위근이 존재하면 정상 시계열이 아닙니다.
단위근(unit root)이란 확률론의 데이터 검정에서 쓰이는 개념입니다. 주로 ‘단위근 검정’의 형식으로 등장합니다. 일반적으로 시계열 데이터는 시간에 따라 일정한 규칙을 가짐을 가정합니다. 따라서 매우 복잡한 형태를 갖는 시계열 데이터라도 다음과 같은 식으로 어떻게든 단순화시킬 수 있을 것이라 생각해볼 수 있습니다.
즉, ‘t시점의 확률변수는 t-1, t-2 시점의 확률변수와 관계를 가지면서 거기에 에러가 포함된 것’이라는 의미입니다. 여기서 편의를 위해 y0=0이라 가정합니다. 이제 아래의 방정식을 볼까요.
여기서 m=1이 위 식의 근이 된다면 이때의 시계열 과정을 단위근을 가진다고 합니다. 단위근 모형은 주로 복잡한 시계열 데이터를 단순하게나마 계산하려 할 때 사용됩니다.
Python으로 가상의 시계열 데이터셋(1개의 정상 시계열, 3개의 비정상 시계열)을 만들어서 위의 ADF test, KPSS test 를 각각 해보겠습니다. 위의 정상확률과정의 정의에 따라서, 추세(trend)가 있거나, 분산(variance)이 시간의 흐름에 따라 변하거나(증가 또는 감소), 계절성(seasonality)을 가지고 있는 시계열은 정상성(stationarity) 가정을 만족하지 않습니다.
- (1) 정상 시계열 데이터 (stationary time series)
- (2) 추세를 가진 비정상 시계열 데이터 (non-stationary time series with trend)
- (3) 분산이 변하는 비정상 시계열 데이터 (non-stationary time series with changing variance)
- (4) 계절성을 가지는 비정상 시계열 데이터 (non-stationary time series with seasonality)
이제 (1)~(4)번 데이터별로 (a) ADF test, (b) KPSS test 로 정상성 여부를 차례대로 가설 검정해보겠습니다.
(1) 정상 시계열 데이터 (stationary time series)
먼저, 자기회귀과정(auto-regressive process)을 따르는 AR(1) 과정의 시계열 데이터를 임의로 만들어보겠습니다.
import numpy as np
import matplotlib.pyplot as plt
## Stationary Process
## exmaple: AR(1) process
np.random.seed(1) # for reproducibility
z_0 = 0
rho = 0.6 # correlation b/w z(t) and z(t-1)
z_all = [z_0]
for i in range(200):
z_t = rho*z_all[i] + np.random.normal(0, 0.1, 1)
z_all.append(z_t)
## plotting
plt.rcParams['figure.figsize'] = (10, 6)
plt.plot(z_all)
plt.title("stationary time series : AR(1) process", fontsize=16)
## adding horizonal line at mean position 0
plt.axhline(0, 0, 200, color='red', linestyle='--', linewidth=2)
plt.show()
stationary process time series, 정상 시계열
(1-a) ADF 검정 (Augmented Dickey-Fuller test)
Python의 statsmodels 모듈에 있는 adfuller 메소드를 사용해서 ADF 검정을 위한 사용자 정의함수를 정의해보겠습니다.
#! pip install statsmodels
## UDF for ADF test
from statsmodels.tsa.stattools import adfuller
import pandas as pd
def adf_test(timeseries):
print("Results of Dickey-Fuller Test:")
dftest = adfuller(timeseries, autolag="AIC")
dfoutput = pd.Series(
dftest[0:4],
index=[
"Test Statistic",
"p-value",
"#Lags Used",
"Number of Observations Used",
],
)
for key, value in dftest[4].items():
dfoutput["Critical Value (%s)" % key] = value
print(dfoutput)
이제 위에서 만든 ADF 검정 사용자정의함수 adf_test() 를 사용해서 정상시계열 z_all 에 대해서 ADF 검정을 해보겠습니다. p-value 가 8.74e-11 이므로 유의수준 5% 하에서 귀무가설 (H0: 단위근(unit root)이 존재한다. 즉, 정상 시계열이 아니다)을 기각하고 대립가설 (H1: 단위근이 없다. 즉, 정상 시계열이다.) 을 채택합니다. (맞음 ^_^)
## checking the stationarity of a series using the ADF(Augmented Dickey-Fuller) Test
# -- Null Hypothesis: The series has a unit root.(not stationary.)
# -- Alternate Hypothesis: The series has no unit root.(stationary.)
adf_test(z_all) # p-value 8.740428e-11 => stationary
# Results of Dickey-Fuller Test:
# Test Statistic -7.375580e+00
# p-value 8.740428e-11
# #Lags Used 1.000000e+00
# Number of Observations Used 1.990000e+02
# Critical Value (1%) -3.463645e+00
# Critical Value (5%) -2.876176e+00
# Critical Value (10%) -2.574572e+00
# dtype: float64
## UDF for KPSS test
from statsmodels.tsa.stattools import kpss
import pandas as pd
def kpss_test(timeseries):
print("Results of KPSS Test:")
kpsstest = kpss(timeseries, regression="c", nlags="auto")
kpss_output = pd.Series(
kpsstest[0:3], index=["Test Statistic", "p-value", "Lags Used"]
)
for key, value in kpsstest[3].items():
kpss_output["Critical Value (%s)" % key] = value
print(kpss_output)
이제 정상 시계열 z_all 에 대해서 위에서 정의한 kpss_test() 함수를 사용해서 정상성 여부를 확인해보겠습니다. p-value 가 0.065 로서 유의수준 10% 하에서 귀무가설 (H0: 정상 시계열이다) 를 채택하고, 대립가설 (H1: 정상 시계열이 아니다) 를 기각합니다. (유의수준 5% 하에서는 대립가설 채택). (맞음 ^_^)
kpss_test(z_all) # p-value 0.065035 => stationary at significance level 10%
# Results of KPSS Test:
# Test Statistic 0.428118
# p-value 0.065035
# Lags Used 5.000000
# Critical Value (10%) 0.347000
# Critical Value (5%) 0.463000
# Critical Value (2.5%) 0.574000
# Critical Value (1%) 0.739000
# dtype: float64
(2) 추세를 가진 비정상 시계열 데이터 (non-stationary time series with trend)
다음으로, 추세(trend)를 가지는 가상의 비정상(non-stationary) 시계열 데이터를 만들어보겠습니다. 평균이 일정하지 않으므로 비정상 시계열이 되겠습니다.
## time series with trend
np.random.seed(1) # for reproducibility
ts_trend = 0.01*np.arange(200) + np.random.normal(0, 0.2, 200)
## plotting
plt.plot(ts_trend)
plt.title("time series with trend", fontsize=16)
plt.show()
time series with trend (non-stationary process)
(2-a) ADF 검정 (ADF test)
위의 추세를 가지는 비정상 시계열 데이터에 대해 ADF 검정 (ADF test)를 실시해보면, p-value가 0.96 으로서 유의수준 5% 하에서 귀무가설 (H0: 시계열이 단위근을 가진다. 즉, 정상 시계열이 아니다) 을 채택하고, 귀무가설 (H1: 시계열이 단위근을 가지지 않는다. 즉, 정상 시계열이다.) 을 기각합니다. (맞음 ^_^)
## checking the stationarity of a series using the ADF(Augmented Dickey-Fuller) Test
# -- Null Hypothesis: The series has a unit root.(not stationary.)
# -- Alternate Hypothesis: The series has no unit root.(stationary.)
adf_test(ts_trend) # p-value 0.96 => non-stationary
# Results of Dickey-Fuller Test:
# Test Statistic 0.125812
# p-value 0.967780
# #Lags Used 10.000000
# Number of Observations Used 189.000000
# Critical Value (1%) -3.465431
# Critical Value (5%) -2.876957
# Critical Value (10%) -2.574988
# dtype: float64
(2-b) KPSS 검정 (KPSS test)
추세(trend)를 가지는 시계열에 대해 KPSS 검정(KPSS test)을 실시해보면, p-value 가 0.01 로서 귀무가설 (H0: 정상 시계열이다) 를 기각하고, 대립가설 (H1: 정상 시계열이 아니다) 를 채택합니다. (맞음 ^_^)
## KPSS test for checking the stationarity of a time series.
## The null and alternate hypothesis for the KPSS test are opposite that of the ADF test.
# -- Null Hypothesis: The process is trend stationary.
# -- Alternate Hypothesis: The series has a unit root (series is not stationary).
kpss_test(ts_trend) # p-valie 0.01 => non-stationary
# Results of KPSS Test:
# Test Statistic 2.082141
# p-value 0.010000
# Lags Used 9.000000
# Critical Value (10%) 0.347000
# Critical Value (5%) 0.463000
# Critical Value (2.5%) 0.574000
# Critical Value (1%) 0.739000
# dtype: float64
(3) 분산이 변하는 비정상 시계열 데이터 (non-stationary time series with changing variance)
다음으로, 추세는 없지만 시간이 흐름에 따라서 분산이 점점 커지는 가상의 비정상 시계열을 만들어보겠습니다. 분산이 일정하지 않기 때문에 정상 시계열이 아닙니다.
## time series with increasing variance
np.random.seed(1) # for reproducibility
ts_variance = []
for i in range(200):
ts_new = np.random.normal(0, 0.001*i, 200).astype(np.float32)[0]
ts_variance.append(ts_new)
## plotting
plt.plot(ts_variance)
plt.title("time series with increasing variance", fontsize=16)
plt.show()
time series with increasing variance (non-stationary process)
(3-a) ADF 검정 (ADF test)
위의 시간이 흐름에 따라 분산이 커지는 비정상 시계열에 대해 ADF 검정(ADF test)을 실시하면, p-value가 5.07e-19 로서 유의수준 5% 하에서 귀무가설(H0: 단위근을 가진다. 즉, 정상 시계열이 아니다)를 기각하고, 대립가설(H1: 단위근을 가지지 않는다. 즉, 정상 시계열이다)를 채택합니다. (땡~! 틀림 -_-;;;)
## checking the stationarity of a series using the ADF(Augmented Dickey-Fuller) Test
# -- Null Hypothesis: The series has a unit root. (not stationary)
# -- Alternate Hypothesis: The series has no unit root. (stationary)
adf_test(ts_variance) # p-vaue 5.07e-19 => stationary (Opps, wrong result -_-;;;)
# Results of Dickey-Fuller Test:
# Test Statistic -1.063582e+01
# p-value 5.075820e-19
# #Lags Used 0.000000e+00
# Number of Observations Used 1.990000e+02
# Critical Value (1%) -3.463645e+00
# Critical Value (5%) -2.876176e+00
# Critical Value (10%) -2.574572e+00
# dtype: float64
(3-b) KPSS 검정 (KPSS test)
위의 시간이 흐름에 따라 분산이 커지는 비정상 시계열에 대해 KPSS 검정(KPSS test)을 실시하면, p-value가 0.035 로서 유의수준 5% 하에서 귀무가설(H0: 정상 시계열이다)를 기각하고, 대립가설(H1: 정상 시계열이 아니다)를 채택합니다. (딩동댕! 맞음 ^_^) (ADF test 는 틀렸고, KPSS test 는 맞았어요.)
## KPSS test for checking the stationarity of a time series.
## The null and alternate hypothesis for the KPSS test are opposite that of the ADF test.
# -- Null Hypothesis: The process is trend stationary.
# -- Alternate Hypothesis: The series has a unit root (series is not stationary).
kpss_test(ts_variance) # p-value 0.035 => not stationary
# Results of KPSS Test:
# Test Statistic 0.52605
# p-value 0.03580
# Lags Used 3.00000
# Critical Value (10%) 0.34700
# Critical Value (5%) 0.46300
# Critical Value (2.5%) 0.57400
# Critical Value (1%) 0.73900
# dtype: float64
(4) 계절성을 가지는 비정상 시계열 데이터 (non-stationary time series with seasonality)
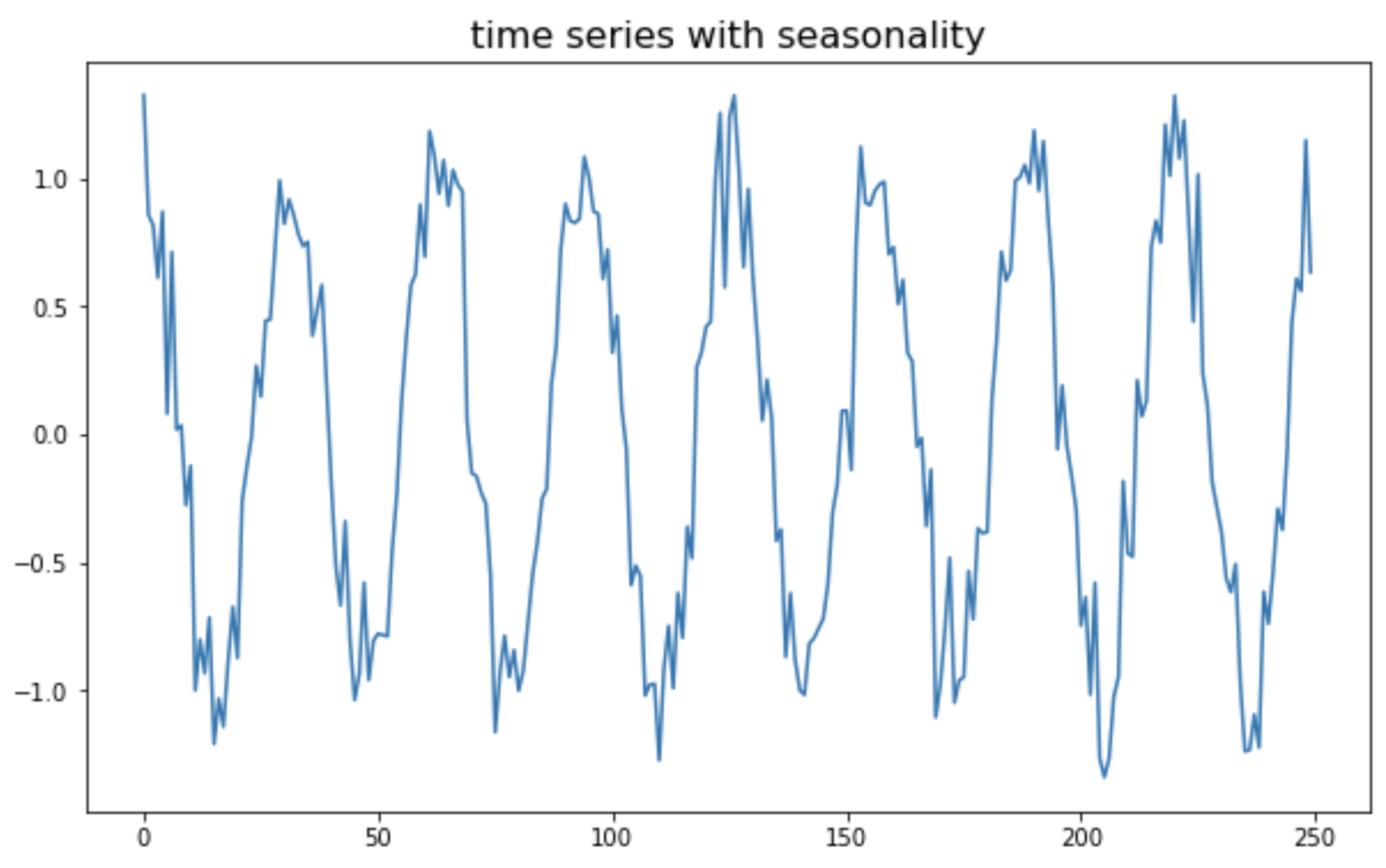
마지막으로, 코사인 주기의 계절성(seasonality)을 가지는 가상의 비정상(non-stationary) 시계열 데이터를 만들어보겠습니다.
## time series with seasonality
## generating x from 0 to 4pi and y using numpy
np.random.seed(1) # for reproducibility
x = np.arange(0, 50, 0.2) # start, stop, step
ts_seasonal = np.cos(x) + np.random.normal(0, 0.2, 250)
## ploting
plt.plot(ts_seasonal)
plt.title("time series with seasonality", fontsize=16)
plt.show()
time series with seasonality (non-stationary process)
(4-a) ADF 검정 (ADF test)
위의 계절성(seasonality)을 가지는 비정상 시계열에 대해서, ADF 검정(ADF test)을 실시하면, p-value가 3.14e-16 로서 유의수준 5% 하에서 귀무가설(H0: 단위근을 가진다. 즉, 정상 시계열이 아니다)를 기각하고, 대립가설(H1: 단위근을 가지지 않는다. 즉, 정상 시계열이다)를 채택합니다. (땡~! 틀림 -_-;;;)
## checking the stationarity of a series using the ADF(Augmented Dickey-Fuller) Test
# -- Null Hypothesis: The series has a unit root.(not stationary.)
# -- Alternate Hypothesis: The series has no unit root.(stationary.)
adf_test(ts_seasonal) # p-value 3.142783e-16 => stationary (Wrong result. -_-;;;)
# Results of Dickey-Fuller Test:
# Test Statistic -9.516720e+00
# p-value 3.142783e-16
# #Lags Used 1.600000e+01
# Number of Observations Used 2.330000e+02
# Critical Value (1%) -3.458731e+00
# Critical Value (5%) -2.874026e+00
# Critical Value (10%) -2.573424e+00
# dtype: float64
(4-b) KPSS 검정 (KPSS test)
위의 계절성(seasonality)을 가지는 비정상 시계열에 대해서, KPSS 검정(KPSS test)을 실시하면, p-value가 0.1 로서 유의수준 10% 하에서 귀무가설(H0: 정상 시계열이다)를 기각하고, 대립가설(H1: 정상 시계열이 아니다)를 채택합니다. (딩동댕! 맞음 ^_^) (ADF test 는 틀렸고, KPSS test 는 맞았어요. 유의수준 5% 하에서는 둘 다 틀림.)
## KPSS test for checking the stationarity of a time series.
## The null and alternate hypothesis for the KPSS test are opposite that of the ADF test.
# -- Null Hypothesis: The process is trend stationary.
# -- Alternate Hypothesis: The series has a unit root (series is not stationary).
kpss_test(ts_seasonal) # p-value 0.1 => non-stationary (at 10% significance level)
# Results of KPSS Test:
# Test Statistic 0.016014
# p-value 0.100000
# Lags Used 9.000000
# Critical Value (10%) 0.347000
# Critical Value (5%) 0.463000
# Critical Value (2.5%) 0.574000
# Critical Value (1%) 0.739000
# dtype: float64
이상의 정상성 여부에 대한 통계적 가설 검정 결과를 보면,
(1) 정상 시계열에 대해 ADF test, KPSS test 모두 정상 시계열로 가설 검정 (모두 맞음 ^_^)
(2) 추세가 있는 시계열에 대해 ADF test, KPSS test 가 모두 정상 시계열이 아니라고 정확하게 가설 검정 (모두 맞음 ^_^)
(3) 분산이 변하는 시계열에 대해 ADF test 는 정상 시계열로 가설 검정 (틀렸음! -_-;;;), KPSS test 는 정상 시계열이 아니라고 가설 검정 (맞음 ^_^)
(4) 계절성이 있는 시계열에 대해 ADF test 는 정상 시계열로 가설 검정 (틀렸음! -_-;;;), KPSS test 는 정상 시계열이 아니라고 가설 검정 (맞음 ^_^)
ADF test 는 추세가 있는 비정상 시계열에 대해서는 정상 시계열이 아님을 잘 검정하지만,분산이 변하거나 계절성이 있는 시계열에 대해서는 정상성 여부를 제대로 검정해내지 못하고 있습니다.
반면에 KPSS test 는 위의 4가지의 모든 경우에 정상성 여부를 잘 검정해내고 있습니다.
통계적 가설 검정 외에 시계열 도표 (time series plot)을 꼭 그려보고 눈으로도 반드시 확인해보는 습관을 들이시기 바랍니다.
이번 포스팅에서는 Python을 사용해서 웹사이트에서 압축파일을 다운로드해서 압축을 해제하고 데이터셋을 합치는 방법을 소개하겠습니다.
세부 절차 및 이용한 Python 모듈과 메소드는 아래와 같습니다.
(1) os 모듈로 다운로드한 파일을 저장할 디렉토리가 없을 경우 새로운 디렉토리 생성하기
(2) urllib.request.urlopen() 메소드로 웹사이트를 열기
(3) tarfile.open().extractall() 메소드로 압축 파일을 열고, 모든 멤버들을 압축해제하기
(4) pandas.read_csv() 메소드로 파일을 읽어서 DataFrame으로 만들기
(5) pandas.concat() 메소드로 모든 DataFrame을 하나의 DataFrame으로 합치기
(6) pandas.to_csv() 메소드로 합쳐진 csv 파일을 내보내기
먼저, 위의 6개 절차를 download_and_merge_csv() 라는 이름의 사용자 정의함수로 정의해보겠습니다.
import os
import glob
import pandas as pd
import tarfile
import urllib.request
## downloads a zipped tar file (.tar.gz) that contains several CSV files,
## from a public website.
def download_and_merge_csv(url: str, down_dir: str, output_csv: str):
"""
- url: url address from which you want to download a compressed file
- down_dir: directory to which you want to download a compressed file
- output_csv: a file name of a exported DataFrame using pd.to_csv() method
"""
# if down_dir does not exists, then create a new directory
down_dir = 'downloaded_data'
if os.path.isdir(down_dir):
pass
else:
os.mkdir(down_dir)
# Open for reading with gzip compression.
# Extract all members from the archive to the current working directory or directory path.
with urllib.request.urlopen(url) as res:
tarfile.open(fileobj=res, mode="r|gz").extractall(down_dir)
# concatenate all extracted csv files
df = pd.concat(
[pd.read_csv(csv_file, header=None)
for csv_file in glob.glob(os.path.join(down_dir, '*.csv'))])
# export a DataFrame to a csv file
df.to_csv(output_csv, index=False, header=False)
참고로, tarfile.open(fileobj, mode="r") 에서 4개의 mode 를 지원합니다.
tarfile(mode) 옵션 -. mode="r": 존재하는 데이터 보관소로부터 읽기 (read) -. mode="a": 존재하는 파일에 데이터를 덧붙이기 (append) -. mode="w": 존재하는 파일을 덮어쓰기해서 새로운 파일 만들기 (write, create a new file overwriting an existing one) -. mode="x": 기존 파일이 존재하지 않을 경우에만 새로운 파일을 만들기 (create a new file only if it does not already exist)
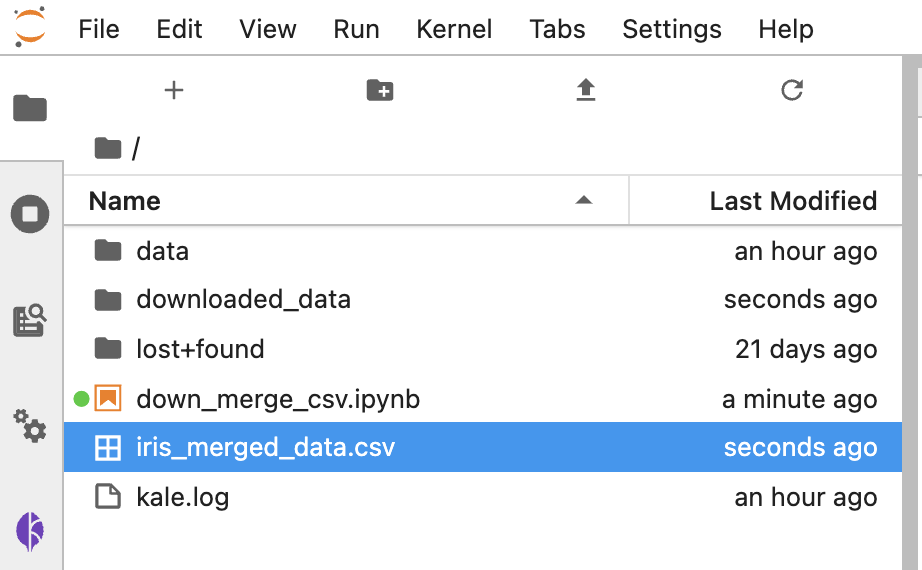
아래의 화면캡쳐처럼 'iris_merged_data.csv' 라는 이름의 csv 파일이 새로 생겼습니다. 그리고 'downloaded_data' 라는 폴더도 새로 생겼습니다.
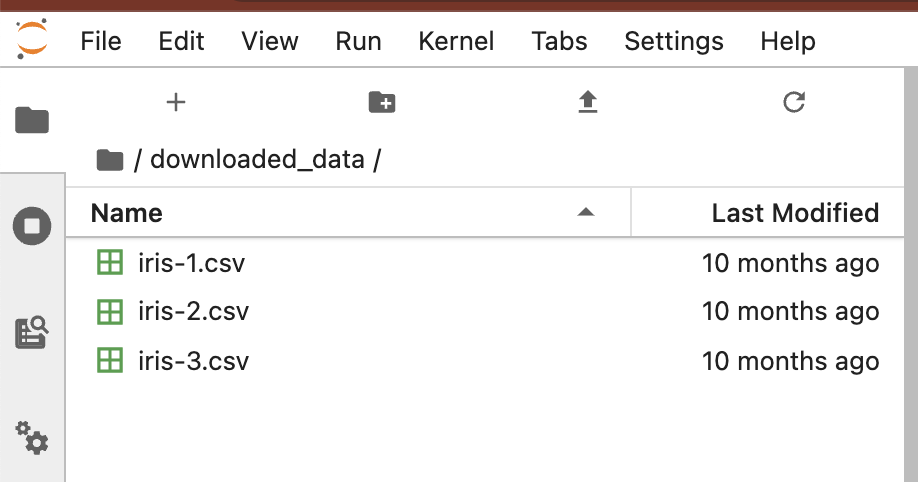
터미널에서 새로 생긴 'downloaded_data' 로 디렉토리를 이동한 다음에, 파일 리스트를 확인해보니 'iris-1.csv', 'iris-2.csv', 'iris-3.csv' 의 3개 파일이 들어있네요. head 로 상위의 10 개 행을 읽어보니 iris 데이터셋이군요.
jovyan@kubecon-tutorial-0:~$ ls
data downloaded_data down_merge_csv.ipynb iris_merged_data.csv kale.log lost+found
jovyan@kubecon-tutorial-0:~$
jovyan@kubecon-tutorial-0:~$
jovyan@kubecon-tutorial-0:~$ cd downloaded_data/
jovyan@kubecon-tutorial-0:~/downloaded_data$ ls
iris-1.csv iris-2.csv iris-3.csv
jovyan@kubecon-tutorial-0:~/downloaded_data$
jovyan@kubecon-tutorial-0:~/downloaded_data$
jovyan@kubecon-tutorial-0:~/downloaded_data$ head iris-1.csv
5.1,3.5,1.4,0.2,setosa
4.9,3.0,1.4,0.2,setosa
4.7,3.2,1.3,0.2,setosa
4.6,3.1,1.5,0.2,setosa
5.0,3.6,1.4,0.2,setosa
5.4,3.9,1.7,0.4,setosa
4.6,3.4,1.4,0.3,setosa
5.0,3.4,1.5,0.2,setosa
4.4,2.9,1.4,0.2,setosa
4.9,3.1,1.5,0.1,setosa
jovyan@kubecon-tutorial-0:~/downloaded_data$
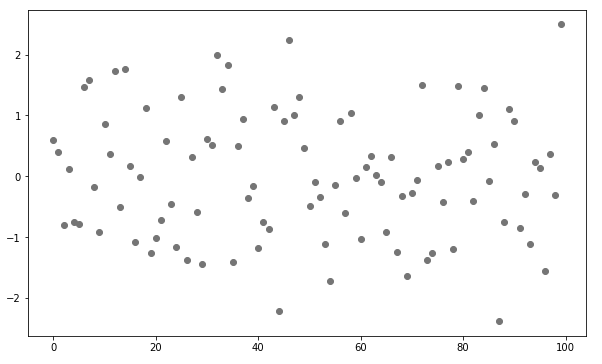
예제로 사용할 샘플 데이터셋을 정규분포로부터 난수를 생성해서 100개 샘플을 추출하고, 점 그래프를 그려보겠습니다.
이 기본 점 그래프에 수평선과 수직선을 차례대로 추가해보겠습니다.
import numpy as np
import matplotlib.pyplot as plt
## generating random numbers
np.random.seed(1004)
x = np.random.normal(0, 1, 100)
## plotting the original data
plt.figure(figsize = (10, 6))
plt.plot(x, linestyle='none', marker='o', color='gray')
plt.show()
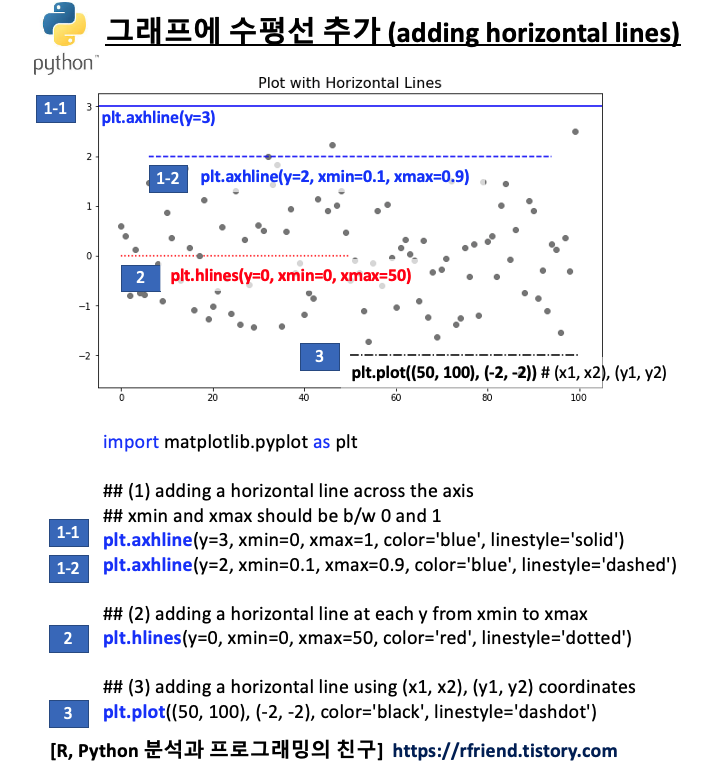
(1) 그래프에 수평선 추가하기 (adding horizontal lines)
(a) plt.axhline(y, xmin, xmax) : 축을 따라서 수평선을 추가, xmin 과 xmax 는 0~1 사이의 값을 가짐
(b) plt.hlines(y, xmin, xmax) : xmin ~ xmax 까지 각 y 값의 수평선을 추가
(c) plt.plot((x1, x2), (y1, y2)) : (x1, x2), (y1, y2) 좌표를 연결하는 선 추가
(a) 번의 plt.axhline() 은 y축에서 부터 수평선이 시작하고, xmin~xmax 로 0~1 사이의 비율 값을 가지는 반면에, (b)번의 plt.hlines() 는 xmin 값 위치에서 부터 수평선이 시작하고, xmin~xmax 값으로 좌표값을 받는다는 차이점이 있습니다.
(c) 번의 plt.plot() 은 단지 수평선, 수직선 뿐만이 아니라 범용적으로 두 좌표를 연결하는 선을 추가할 수 있습니다.
plt.figure(figsize = (10, 6))
plt.plot(x, linestyle='none', marker='o', color='gray')
plt.title("Plot with Horizontal Lines", fontsize=16)
## (1) adding a horizontal line across the axis
## xmin and xmax should be b/w 0 and 1
plt.axhline(y=3, xmin=0, xmax=1, color='blue', linestyle='solid')
plt.axhline(y=2, xmin=0.1, xmax=0.9, color='blue', linestyle='dashed')
## (2) adding a horizontal line at each y from xmin to xmax
plt.hlines(y=0, xmin=0, xmax=50, color='red', linestyle='dotted')
## (3) adding a horizontal line using (x1, x2), (y1, y2) coordinates
plt.plot((50, 100), (-2, -2), color='black', linestyle='dashdot')
plt.show()
horizontal lines using matplotlib
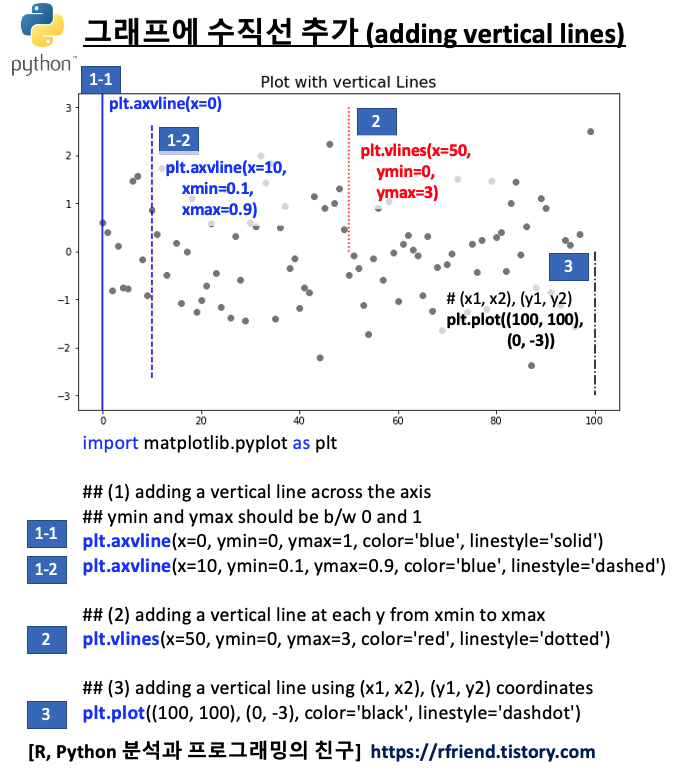
(2) 그래프에 수직선 추가하기 (adding vertical lines)
(a) plt.axvline(x, ymin, ymax) : 축을 따라서 수직선을 추가, ymin 과 ymax 는 0~1 사이의 값을 가짐
(b) plt.vlines(x, ymin, ymax) : ymin ~ ymax 까지 각 x 값의 수평선을 추가
(c) plt.plot((x1, x2), (y1, y2)) : (x1, x2), (y1, y2) 좌표를 연결하는 선 추가
(a) 번의 plt.axvline() 은 x축에서 부터 수평선이 시작하고, ymin~ymax 로 0~1 사이의 비율 값을 가지는 반면에, (b)번의 plt.vlines() 는 ymin 값 위치에서 부터 수평선이 시작하고, ymin~ymax 값으로 좌표값을 받는다는 차이점이 있습니다.
(c) 번의 plt.plot() 은 단지 수평선, 수직선 뿐만이 아니라 범용적으로 두 좌표를 연결하는 선을 추가할 수 있습니다.
plt.figure(figsize = (10, 6))
plt.plot(x, linestyle='none', marker='o', color='gray')
plt.title("Plot with vertical Lines", fontsize=16)
## (1) adding a vertical line across the axis
## ymin and ymax should be b/w 0 and 1
plt.axvline(x=0, ymin=0, ymax=1, color='blue', linestyle='solid')
plt.axvline(x=10, ymin=0.1, ymax=0.9, color='blue', linestyle='dashed')
## (2) adding a vertical line at each y from xmin to xmax
plt.vlines(x=50, ymin=0, ymax=3, color='red', linestyle='dotted')
## (3) adding a vertical line using (x1, x2), (y1, y2) coordinates
plt.plot((100, 100), (0, -3), color='black', linestyle='dashdot')
plt.show()
이전 포스팅에서 시계열 데이터를 예측하는 분석 방법 중의 하나로서 지수평활법(exponential smoothing)을 소개하였습니다. 지수평활법은 통계적인 이론 배경이 있다기 보다는 경험적으로 해보니 예측이 잘 맞더라는 경험에 기반한 분석기법으로서, 데이터가 어떤 확률과정(stochastic process)을 따라야 한다는 가정사항이 없습니다.
반면에, ARIMA (AutoRegressive Integreated Moving Average) 모형은 확률모형을 기반으로 한 시계열 분석 기법으로서, 정상확률과정(Stationary Process)을 가정합니다. 만약 시계열 데이터가 정상성(stationarity) 가정을 만족하지 않을 경우 데이터 전처리를 통해서 정상시계열(stationary time series)로 변환해 준 다음에야 ARIMA 모형을 적용할 수 있습니다.
이번 포스팅에서는
(1) 백색잡음과정 (White Noise Process)
(2) 확률보행과정 (Random Walk Process)
(3) 정상확률과정 (Stationary Process)
에 대해서 소개하겠습니다. 특히, 백색잡음과정, 확률보행과정과 비교해서, ARIMA 모형이 가정하는 "정상확률과정"에 대해서 유심히 살펴보시기 바랍니다.
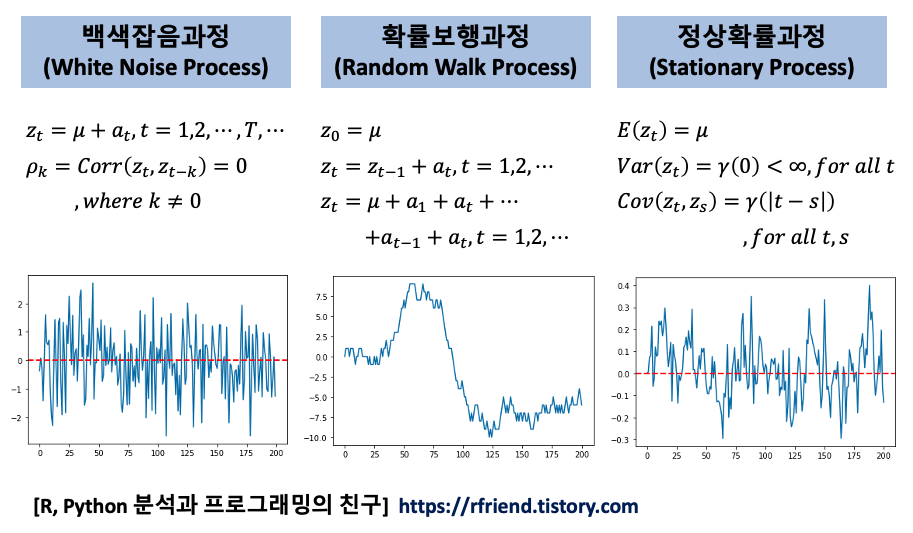
[ 백색잡음과정(white noise) vs. 확률보행과정 (random walk) vs. 정상확률과정 (stationary process) ]
white noise vs. random walk vs. stationary process
(1) 백색잡음과정 (White Noise Process)
신호처리 분야에서 백색잡음(white noise)은 다른 주파수에서 동일한 강도를 가지고, 항상 일정한 스펙트럼 밀도를 발생시키는 무작위한 신호를 의미합니다. 백색잡음 개념은 물리학, 음향공학, 통신, 통계 예측 등 다양한 과학과 기술 분야에서 광범윟게 사용되고 있습니다.
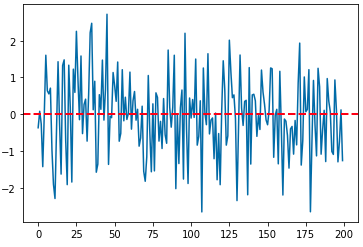
시계열 데이터 통계 분석에서 백색잡음과정(white noise process)은 평균이 0, 분산은 유한한 상수(sigma^2)인 확률분포(random variables)로 부터 서로 상관되지 않게(uncorrelated) 무작위로 샘플을 추출한 이산 신호(discrete signal)를 말합니다.
white noise process
특히, 평균이 0 인 동일한 정규분포로부터 서로 독립적으로 샘플을 추출한 백색잡음을 가법 백색 가우시언 잡음(additive white Gaussian noise) 라고 합니다. 아래 Python 코드는 평균이 0, 분산이 1인 정규분포로부터 200개의 백색잡음 샘플을 추출하고 시각화 해본 것입니다.
import numpy as np
import matplotlib.pyplot as plt
## generating white noise from normal distribution
x1 = np.random.normal(0, 1, 200) # additive white Gaussian noise
plt.plot(x1, linestyle='-') # marker='o'
## addidng horizontal line at mean '0'
plt.axhline(0, 0, 200, color='red', linestyle='--', linewidth=2)
plt.show()
white Gaussian noise
(2) 확률보행과정 (Random Walk Process)
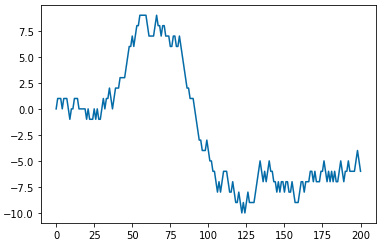
수학에서 확률보행과정(random walk process)은 어떤 수학적인 공간 (예: 정수)에서 연속적인 무작위 스텝의 이동경로를 묘사하는 수학적인 객체를 말합니다.
가장 기본적인 확률보행과정의 예를 들자면, 동전을 던져서 앞면이 나오면(0.5의 확률) 위(up)로 +1 계단을 올라가고, 동전의 뒷면이 나오면(0.5의 확률) 아래(down)로 -1 계단을 내려가는 보행과정을 생각해 볼 수 있습니다. 액체나 기체 속에서 분자가 이동하는 경로를 추적한 브라운 운동(Brownian motion), 수렵채집을 하는 동물의 탐색경로, 요동치는 주식의 가격, 도박꾼의 재무상태 등을 확률보행과정으로 설명할 수 있습니다.
아래의 Python 코드는 위로(up)로 0.3의 확률, 아래(down)로 0.7의 발생확률을 가지고 계단을 오르락 내리락 하는 확률보행과정을 만들어보고, 이를 시각화해 본 것입니다. 마치 잠깐 상승하다가 하락장으로 돌아선 주식시장 차트 같이 생기지 않았나요?
# Probability to move up or down
prob = [0.3, 0.7]
# starting position
start = 0
rand_walks = [start]
# creating the random points
rr = np.random.random(200)
downp = rr < prob[0]
upp = rr >= prob[1]
# random walk process
# z(t) = z(t-1) + a(t), where a(t) is white noise
for idown, iup in zip(downp, upp):
rand_walks.append(rand_walks[-1] - idown + iup)
# plot
plt.plot(rand_walks)
plt.show()
random walk process (example)
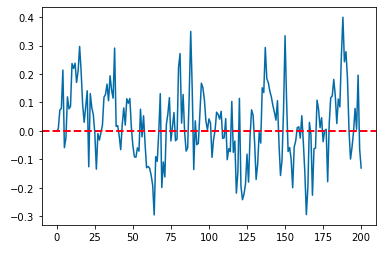
(3) 정상확률과정 (Stationary Process)
서두에서 ARIMA 시계열 통계모형은 시계열 데이터의 정상성(stationarity) 조건을 만족하는 경우에 사용할 수 있다고 했습니다. 정상확률과정은 다음의 세 조건을 만족하는 확률과정을 말합니다.
[ 정상시계열의 조건 (conditions for stationary time series)]
(a) 평균이 일정하다.
(b) 분산이 존재하며 상수이다.
(c) 두 시점 사이의 자기공분산은 시차(time lag)에만 의존한다.
만약 추세(trend)가 있거나 시간이 갈 수록 분산이 커지거나 작아지는 시계열 데이터라면 정상확률과정 시계열이 아닙니다. 추세가 있거나 분산이 달라지게 되면 ARIMA 모형을 적합하기 전에, 먼저 추세를 없애 주고 분산을 안정화 시켜주는 변환을 통해 정상확률과정으로 만들어주어야 합니다.
stationary process 정상확률과정
정상확률과정 중에서 대표적인 모수적 확률모형은 ARMA(p, q) 로 표기되는 자기회귀이동평균과정(AutoRegressive Moving Average Process) 입니다. 아래의 Python 코드는 AR(1) 인 자기회귀과정을 생성해서 시각화해본 것입니다.
AR(1) 과정: z(t) = Phi * z(t-1) + a(t)
(이때 Phi 는 절대값이 1 미만이고, a(t) 는 평균이 0이고 분산이 sigma^2 인 백색잡음과정임.)
## Stationary Process
## exmaple: AR(1) process
z_0 = 0
rho = 0.65 # correlation b/w z(t) and z(t-1)
z_all = [z_0]
for i in range(200):
z_t = rho*z_all[i] + np.random.normal(0, 0.1, 1)
z_all.append(z_t)
## plotting
plt.plot(z_all)
## adding horizonal line at mean position 0
plt.axhline(0, 0, 200, color='red', linestyle='--', linewidth=2)
plt.show()
stationary process plot (example)
위의 1번의 백색잡음과정과 3번의 정상확률과정이 눈으로만 봐서는 구분이 잘 안가지요?
백색잡음과정, 확률보행과정, 정상확률과장이 서로 관련이 있고, 얼핏 봐서는 비슷하기도 해서 참 헷갈립니다. 정확하게 이 셋을 구분해서 이해하시기 바래요.
이번 포스팅에서는 주기성을 가지는 센서 시계열 데이터, 음향 데이터, 신호 처리 데이터 등에서 많이 사용되는 스펙트럼 분석 (spectral analysis) 에 대해서 소개하겠습니다.
많은 시계열 데이터는 주기적인 패턴 (periodic behavior) 을 보입니다. 스펙트럼 분석 은 시계열 데이터에 내재되어 있는 주기성(periodicity) 을 찾아내는 분석기법으로서, spectral analysis, spectrum analysis, frequency domain analysis 등의 이름으로 불립니다.
스펙트럼 분석을 할 때 우리는 먼저 시계열 데이터를 시간 영역(time domain)에서 주파수 영역(frequency domain)로 변환을 합니다. 시계열의 공분산은 스펙트럼 확률밀도함수 (spectral density function) 로 알려진 함수로 재표현될 수 있습니다. 스펙트럼 밀도함수는 시계열과 다른 주파수의 사인/코사인 파동 간의 제곱 상관계수로 구하는 주기도(periodogram) 를 사용하여 추정할 수 있습니다. (Venables & Ripley, 2002)
아래의 그림은 시계열(time series)과 스펙트럼(spectrum, frequency) 간의 관계를 직관적으로 이해할 수 있게 도와줍니다.
[ Time Series vs. Spectrum/ Frequency, Fourier Transform(FT) vs. Inverse FT ]
time-series vs. spectrum
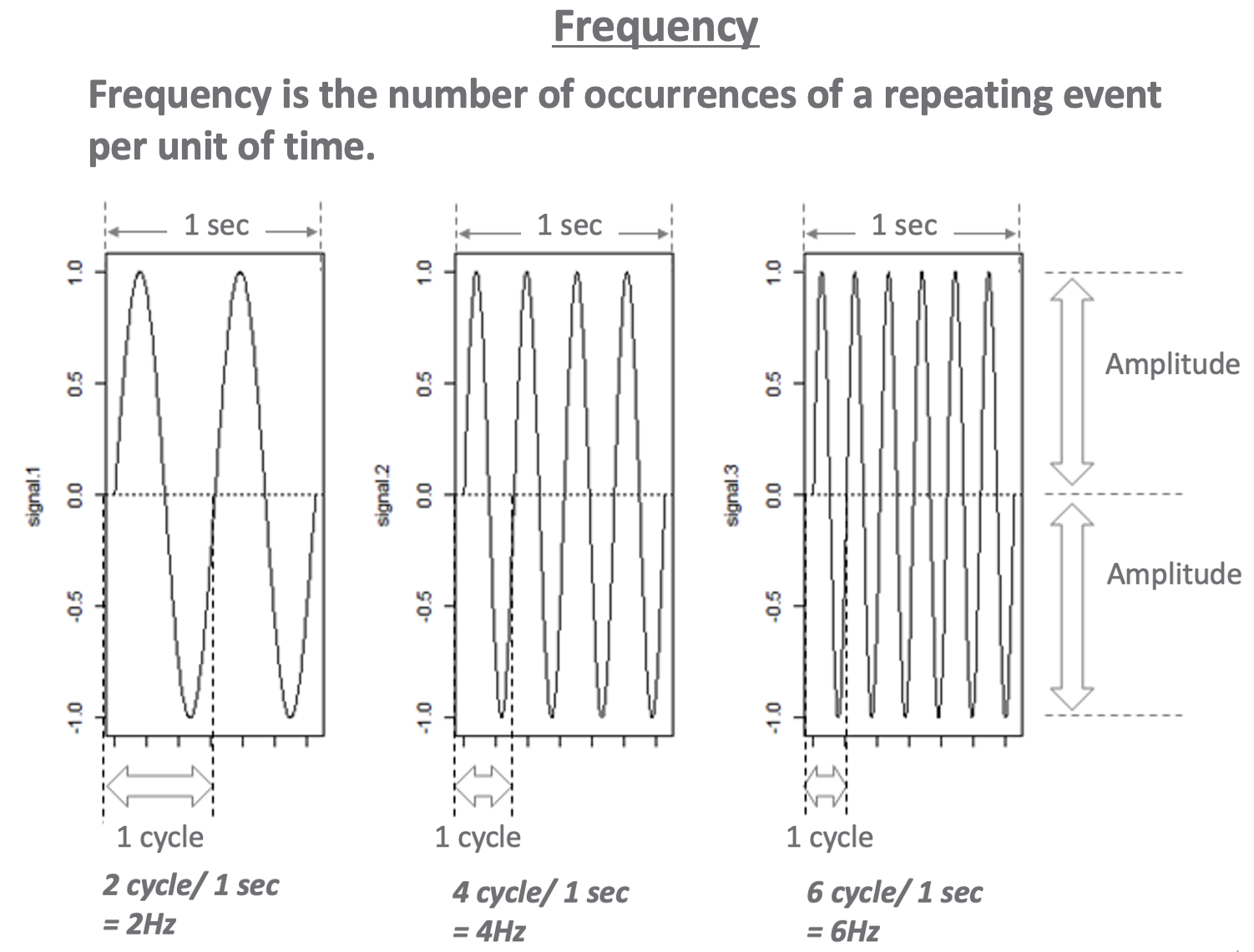
참고로, 주파수(frequency)는 단위 시간 당 반복되는 이벤트가 발생하는 회수를 의미합니다. 주파수를 측정하는데 사용되는 단위인 Hz (Hertz, 헤르쯔) 는 전자기파의 존재를 처음으로 증명한 Heinrich Rudolf Hertz 의 이름에서 따온 것인데요, 가령 2 Hz 는 1초에 2번의 반복 사이클이 발생하는 시계열의 경우, 4 Hz 는 1초에 4번의 반복 사이클이 발행하는 시계열의 주파수에 해당합니다. (아래 그림 예시 참조)
frequency (* https://rfriend.tistory.com)
주기성을 띠는 시계열 데이터나 공간 데이터로 부터 주파수 (spectrum, frequency) 를 계산하거나, 반대로 주파수로 부터 원래의 데이터로 변환할 때 고속 푸리에 변환 (Fast Fourier Transform, 줄여서 FFT) 알고리즘을 많이 사용합니다. 시계열을 주파수로 변환하는 과정 자체를 Fourier Transform 이라고 하며, 이산 푸리에 변환 (Discrete Fourier Transform, DFT) 은 시계열 값을 다른 주파수의 구성요소들로 분해함으로써 구할 수 있습니다. 지금까지 가장 널리 사용되는 고속 푸리에 변환 (FFT) 알고리즘은 Cooley-Tukey 알고리즘 입니다. 이것은 분할-정복 알고리즘 (divide-and-conqer algorithm) 으로서, 반복적으로(recursively) 원래의 시계열 데이터를 훨씬 적은 개수의 주파수로 분할합니다.
[ Fast Fourier Transform(FFT) vs. Inverse FFT]
FFT vs. Inverse FFT
이제 Python 의 spectrum 모듈을 사용해서 스펙트럼 분석을 해보겠습니다. 터미널에서 $ pip install spectrum 으로 먼저 spectrum 모듈을 설치해줍니다.
## installment of spectrum python library at a terminal
$ pip install spectrum
예제로 사용할 샘플데이터로서, data_cosine() 메소드를 사용해서 200 Hz 주파수 (freq=200) 의 주기성을 띠는 코사인 신호(cosine signal)에 백색 잡음 (amplitude 0.1) 도 포함되어 있는 이산형 샘플 데이터 1,024개 (N=1024, sampling=1024) 를 생성해보겠습니다.
## -- importing modules
from spectrum import Periodogram, data_cosine
## generating a toy data sets
## data contains a cosine signal with a frequency of 200Hz
## buried in white noise (amplitude 0.1).
## The data has a length of N=1024 and the sampling is 1024Hz.
data = data_cosine(N=1024, A=0.1, sampling=1024, freq=200)
## plotting the generated data
plt.rcParams['figure.figsize'] = [18, 8]
plt.plot(data)
plt.show()
위의 시계열 그래프가 1,024개 데이터 포인트가 모두 포함되다보니 코사인 신호의 주기성이 눈에 잘 안보이는데요, 앞 부분의 50개만 가져다가 시도표로 그려보면 아래처럼 코사인 파동 모양의 주기성을 띠는 데이터임을 눈으로 확인할 수 있습니다.
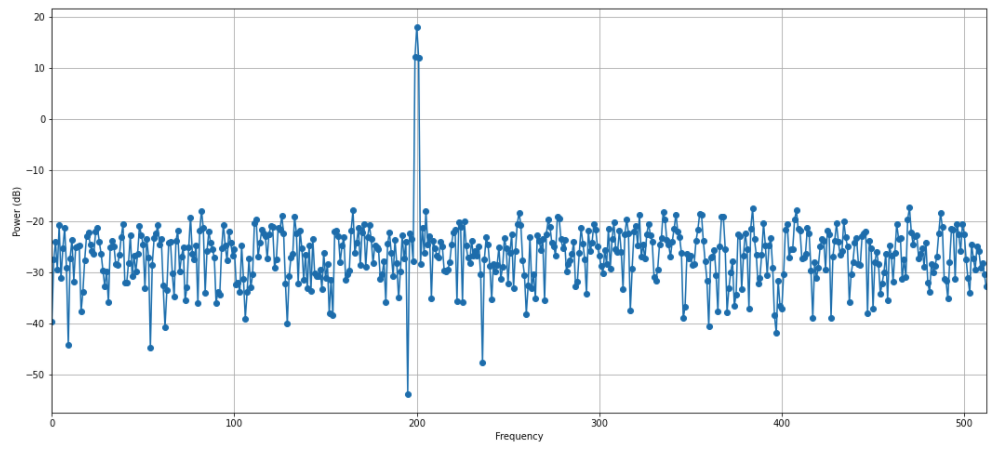
spectrum 모듈의 Periodogram() 메소드에 위에서 생성한 샘플 데이터를 적용해서 periodogram 객체를 만든 후에 run() 함수를 실행시켜서 스펙트럼을 추정할 수 있고, p.plot() 으로 간단하게 추정한 스펙트럼을 시각화할 수 있습니다.
## the Power Spectrum Estimation method provided in spectrum.
## creating an object Periodogram.
p = Periodogram(data, sampling=1024)
## running the spectrum estimation
p.run() # or p()
p.plot(marker='o')
스펙트럼 분석 결과 중 개수(N), 주파수의 세기 (power of spectrum dendity) 속성값을 확인할 수 있습니다.
## some information are stored and can be retrieved later on.
p.N
[Out] 1024
p.psd
# [Out] array([1.06569152e-04, 1.74100855e-03, 3.93335837e-03, 1.10485152e-03,
# 8.28499278e-03, 7.64848301e-04, 2.94332240e-03, 7.35029918e-03,
# 1.21273520e-03, 3.72342384e-05, 1.87058542e-03, 4.35817479e-03,
# 6.60803332e-04, 3.01094523e-03, 3.14914528e-03, 3.40040266e-03,
# 1.70112710e-04, 4.04579597e-04, 1.73102721e-03, 5.17048610e-03,
# 5.89537834e-03, 3.43004928e-03, 2.60894164e-03, 2.29556960e-03,
# 6.23836725e-03, 7.35588289e-03, 3.88793797e-03, 2.25691304e-03,
# ... 중간 생략함 ...
# 2.57852156e-03, 1.23483225e-03, 1.49139300e-03, 9.09082081e-04,
# 5.24999741e-04])
우리가 위에서 data_cosine(N=1024, A=0.1, sampling=1024, freq=200) 메소드를 사용해서 200 Hz 의 데이터를 생성하였기 때문에, 이 샘플 데이터로부터 주파수를 분해하면 200 Hz 가 되어야 할텐데요, 스펙트럼 분석 결과도 역시 200 Hz 에서 스파이크가 엄청 높게 튀는군요.
이번 포스팅에서는 Python의 matplotlib 모듈을 사용하여, X축의 값은 동일하지만 Y축의 값은 척도가 다르고 값이 서로 크게 차이가 나는 2개의 Y값 데이터에 대해서 이중축 그래프 (plot with 2 axes for a dataset with different scales)를 그리는 방법을 소개하겠습니다.
먼저 간단한 예제 데이터셋을 만들어보겠습니다.
* x 축은 2021-10-01 ~ 2021-10-10 일까지의 10개 날짜로 만든 index 값을 동일하게 사용하겠습니다.
* y1 값은 0~9 까지 정수에 표준정규분포 Z~N(0, 1) 로 부터 생성한 난수를 더하여 만들었습니다.
다음으로 이를 해결하기 위한 방법 중의 하나로서 matplotlib을 사용해 2중축 그래프를 그려보겠습니다.
(* 참고로, 2중축 그래프 외에 서로 다른 척도(scale)의 두개 변수의 값을 표준화(standardization, scaling) 하여 두 변수의 척도를 비교할 수 있도록 변환해준 후에 하나의 축에 두 변수를 그리는 방법도 있습니다.)
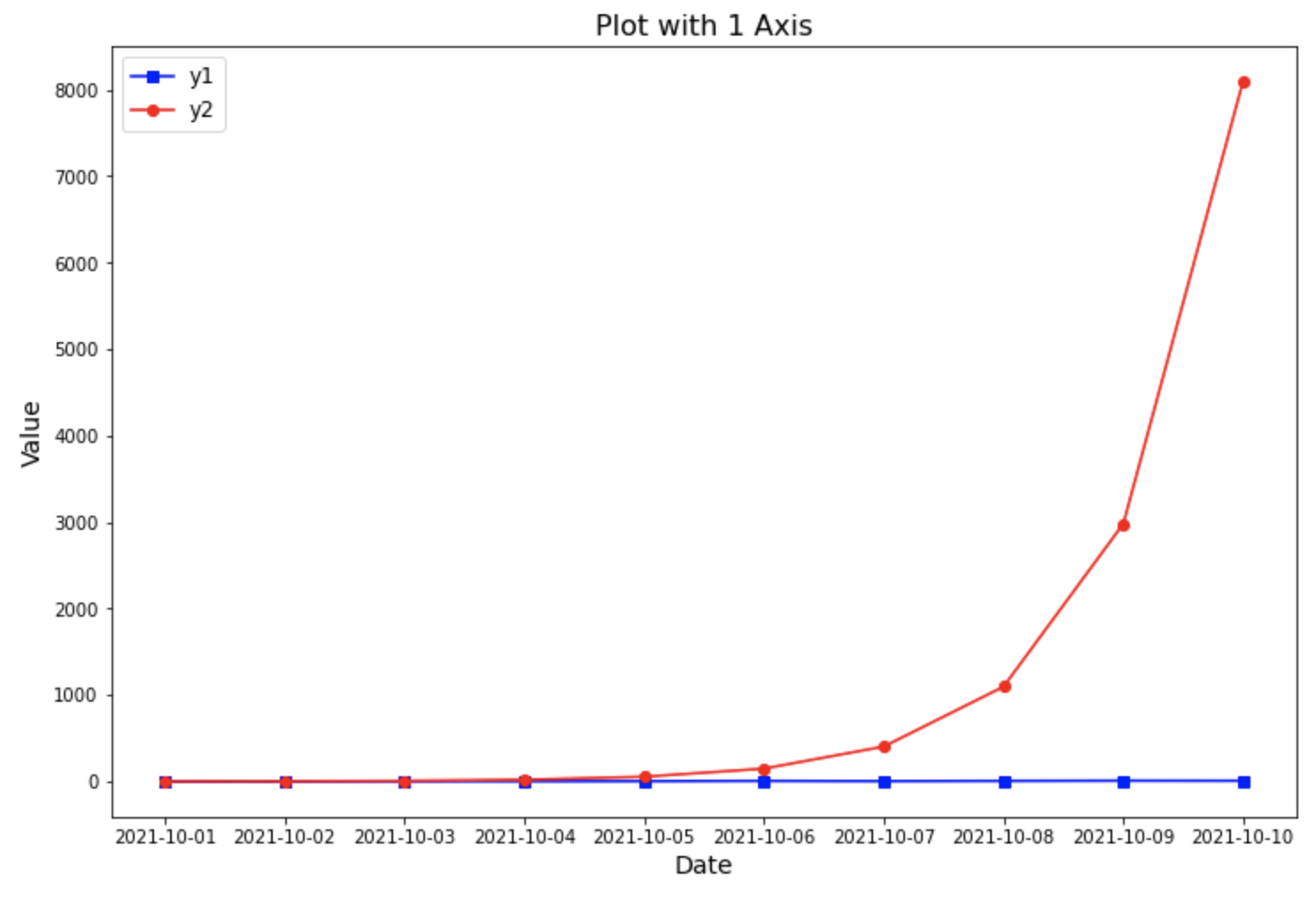
(1) 스케일이 다른 2개의 y값 변수를 1중축 그래프에 그렸을 때 문제점
==> 스케일이 작은 쪽의 y1 값이 스케일이 큰 쪽의 y2 값에 압도되어 y1 값의 패턴을 파악할 수 없음. (스케일이 작은 y1값의 시각화가 의미 없음)
## scale이 다른 데이터를 1개의 y축만을 사용해 그린 그래프
fig = plt.figure(figsize=(12, 8))
ax = fig.add_subplot()
ax.plot(df.index, df.y1, marker='s', color='blue')
ax.plot(df.index, df.y2, marker='o', color='red')
plt.title('Plot with 1 Axis', fontsize=16)
plt.xlabel('Date', fontsize=14)
plt.ylabel('Value', fontsize=14)
plt.legend(['y1', 'y2'], fontsize=12, loc='best')
plt.show()
plot with 1 axis for a dataset with the different scales
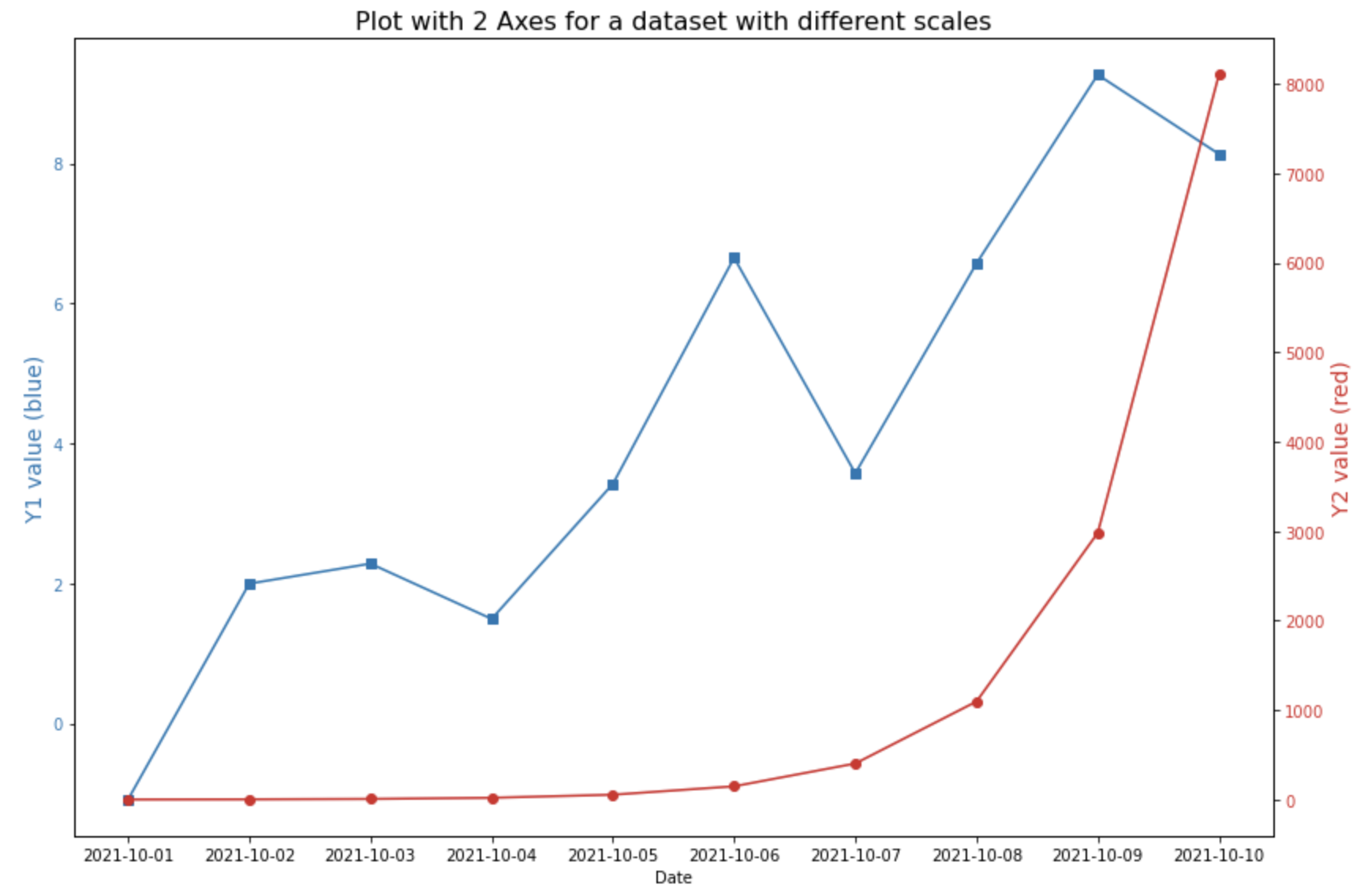
(2) 스케일이 다른 2개의 변수에 대해 2중축 그래프 그렸을 때
==> 각 y1, y2 변수별 스케일에 맞게 적절하게 Y축이 조정이 되어 두 변수 값의 패턴을 파악하기가 쉬움
이때, 가독성을 높이기 위해서 각 Y축의 색깔, Y축 tick의 색깔과 그래프의 색깔을 동일하게 지정해주었습니다. (color 옵션 사용)
## plot with 2 different axes for a dataset with different scales
# left side
fig, ax1 = plt.subplots()
color_1 = 'tab:blue'
ax1.set_title('Plot with 2 Axes for a dataset with different scales', fontsize=16)
ax1.set_xlabel('Date')
ax1.set_ylabel('Y1 value (blue)', fontsize=14, color=color_1)
ax1.plot(df.index, df.y1, marker='s', color=color_1)
ax1.tick_params(axis='y', labelcolor=color_1)
# right side with different scale
ax2 = ax1.twinx() # instantiate a second axes that shares the same x-axis
color_2 = 'tab:red'
ax2.set_ylabel('Y2 value (red)', fontsize=14, color=color_2)
ax2.plot(df.index, df.y2, marker='o', color=color_2)
ax2.tick_params(axis='y', labelcolor=color_2)
fig.tight_layout()
plt.show()
plot with 2 axes for a dataset with different scales
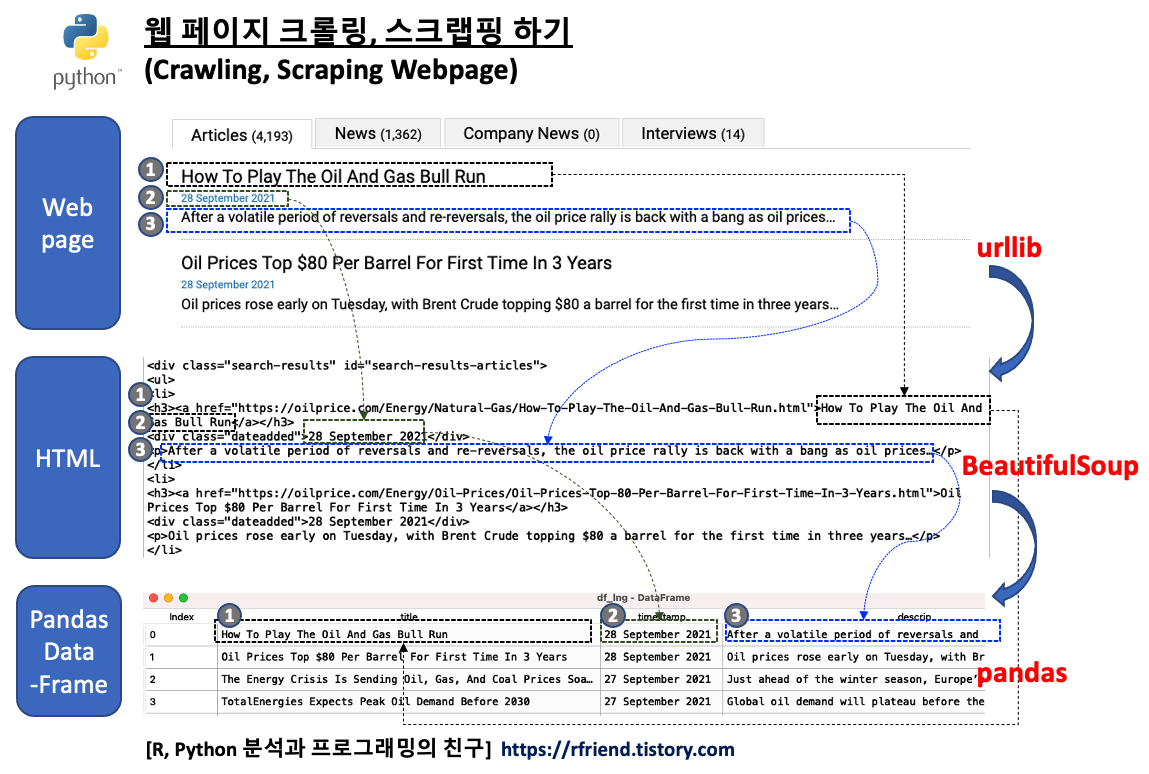
이번 포스팅에서는 Python의 urllib 과 BeautifulSoup 모듈을 사용해서 웹 페이지의 내용을 파싱하여 필요한 데이터만 크롤링, 스크래핑하는 방법을 소개하겠습니다.
urllilb 모듈은 웹페이지 URL 을 다룰 때 사용하는 Python 라이브러리입니다. 가령, urllib.request 는 URL을 열고 읽을 때 사용하며, urllib.parse 는 URL을 파싱할 때 사용합니다.
BeautifulSoup 모듈은 HTML 과 XML 파일로부터 데이터를 가져올 때 사용하는 Python 라이브러리입니다. 이 모듈은 사용자가 선호하는 파서(parser)와 잘 작동하여, parse tree 를 조회하고 검색하고 수정하는 자연스러운 방법을 제공합니다.
python urllib, BeautifulSoup module for web scraping
이번 예제에서는
(1) urllib.request 의 urlopen 메소드로 https://oilprice.com/ 웹페이지에서 'lng' 라는 키워드로 검색했을 때 나오는 총 20개의 페이지를 열어서 읽은 후
(2) BeautifulSoup 모듈을 사용해 기사들의 각 페이지내에 있는 20개의 개별 기사들의 '제목(title)', '기사 게재일(timestamp)', '기사에 대한 설명 (description)' 의 데이터를 파싱하고 수집하고,
(3) 이들 데이터를 모아서 pandas DataFrame 으로 만들어보겠습니다. (총 20개 페이지 * 각 페이지별 20개 기사 = 총 400 개 기사 스크랩핑)
webpage crawling, scraping using python urllib, BeautifulSoup, pandas
아래의 예시 코드는 파송송님께서 짜신 것이구요, 각 검색 페이지에 20개씩의 기사가 있는데 제일 위에 1개만 크롤링이 되는 문제를 해결하는 방법을 문의해주셔서, 그 문제를 해결한 후의 코드입니다.
##-- How to Scrape Data on the Web with BeautifulSoup and urllib
from bs4 import BeautifulSoup
from urllib.request import urlopen
import pandas as pd
from datetime import datetime
col_name = ['title', 'timestamp', 'descrip']
df_lng = pd.DataFrame(columns = col_name)
for j in range(20):
## open and read web page
url = 'https://oilprice.com/search/tab/articles/lng/Page-' + str(j+1) + '.html'
with urlopen(url) as response:
soup = BeautifulSoup(response, 'html.parser')
headlines = soup.find_all(
'div',
{'id':'search-results-articles'}
)[0]
## getting all 20 titles, timestamps, descriptions on each page
title = headlines.find_all('a')
timestamp = headlines.find_all(
'div',
{'class':'dateadded'}
)
descrip = headlines.find_all('p')
## getting data from each article in a page
for i in range(len(title)):
title_i = title[i].text
timestamp_i = timestamp[i].text
descrip_i = descrip[i].text
# appending to DataFrame
df_lng = df_lng.append({
'title': title_i,
'timestamp': timestamp_i,
'descrip': descrip_i},
ignore_index=True)
if j%10 == 0:
print(str(datetime.now()) + " now processing : j = " + str(j))
# remove temp variables
del [col_name, url, response, title, title_i, timestamp, timestamp_i, descrip, descrip_i, i, j]
이번 포스팅에서는 Kubeflow를 이용했을 때 얻을 수 있는 큰 혜택 중의 하나인 파이프라인(Pipeline)의 구성요소에 대해서 코드 없이 개념적인 내용을 소개하겠습니다. (* Kubeflow.org 의 파이프라인 페이지 내용을 번역하였음.)
(1) Kubeflow Pipelines 의 개념적인 개요
(2) Kubeflow Pipelines 의 Component
(3) Kubeflow Pipelines 의 그래프 (Graph)
(4) Kubeflow Pipelines 의 실험 (Experiment)
(5) Kubeflow Pipelines 의 실행과 순환실행 (Run and Recurring Run)
(6) Kubeflow Pipelines 의 실행 트리거 (Run Trigger)
(7) Kubeflow Pipelines 의 단계(Step)
(8) Kubeflow Pipelines 의 산출물 Artifact (Output Artifact)
(1) Kubeflow Pipelines 의 개념적인 개요
파이프라인은 기계학습 워크플로우 (Machine Learning Workflow) 를 표현한 것으로서, 워크플로우의 모든 구성요소들을 포함하고, 이들 구성요소들이 서로 어떻게 관련되어 있는지를 그래프(Graph)의 형태로 표현합니다. 파이프라인을 실행하기 위해 필요한 파라미터의 입력값과, 각 구성요소(components)의 입력값과 출력값을 정의함으로써 파이프라인을 설정할 수 있습니다.
파이프라인을 실행시키면 시스템은 기계학습 워크플로우의 단계(steps)에 해당하는 만큼 한개 또는 여러개의 Kubernetes Pods 를 뜨웁니다. Pods는 Docker container를 시작하고, Container는 차례로 워크플로우 안의 프로그램을 실행시킵니다.
일단 파이프라인을 개발하고 나면, Kubeflow Pipelines UI 나 Kubeflow Pipelines SDK 를 이용해서 업로드할 수 있습니다.
Kubeflow Pipelines 플랫폼 구성은 아래와 같습니다.
- (a) 실험(experiments), 작업(jobs)과 실행(runs)을 관리하고 추적하는 사용자 인터페이스 (UI)
- (b) 다단계 기계학습 워크플로우를 스케줄링(scheduling multi-step ML workflows)하는 엔진
- (c) 파이프라인과 컴포넌트를 정의하고 조작하는 SDK(SW Development Kit)
- (d) SDK를 사용해서 시스템과 상호작용하는 노트북(notebooks)
Kubeflow Pipelines 의 목적은 다음과 같습니다.
- (a) End-to-End orchestration: 기계학습의 전체 파이프라인을 단순화하고 조정할 수 있게 함.
- (b) 쉬운 실험(easy experimentation): 수많은 아이디어와 기술을 시도하고 다양한 실험결과를 관리할 수 있게 함.
- (c) 쉬운 재사용(easy re-use): 매번 다시 구축할 필요 없이 기존의 컴포넌트와 파이프라인을 재사용해서 빠르게 end-to-end 솔루션을 생성할 수 있게 함.
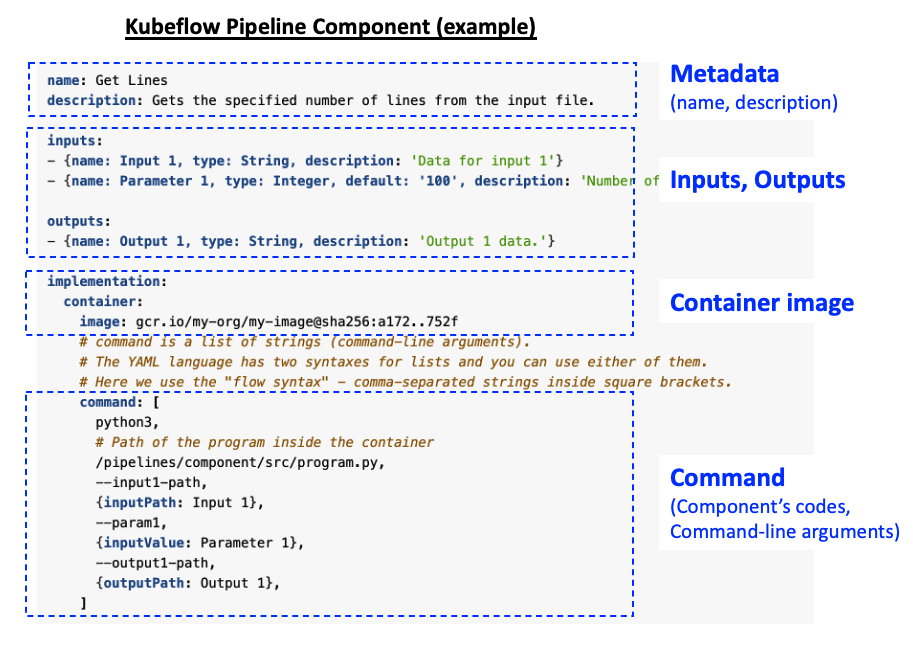
(2) Kubeflow Pipelines 의 Component
Pipeline Component 는 기계학습 워크플로우에서 한 개의 단계를 실행하는 독립적이고 자기충족적인 코드 집합 (self-contained set of code)입니다. 가령, 데이터 전처리, 데이터 변환, 모델 훈련 등이 독립적인 워크플로우의 단계가 될 수 있습니다. Pipeline Component 는 함수(function)과 유사한데요, 이름, 파라미터, 반환값, (코드블록) 바디를 가지고 있습니다. 레고블록의 하나 하나의 조각블록을 생각하면 이해하기 쉬울거 같아요.
Component 세부 사항(component specifications)으로 아래의 것들을 정의합니다.
- (a) component 인터페이스: 인풋과 아웃풋
- (b) component 실행: 컨테이너 이미지, 실행 명령어
- (c) component 메타 데이터: 컴포넌트 이름, 설명
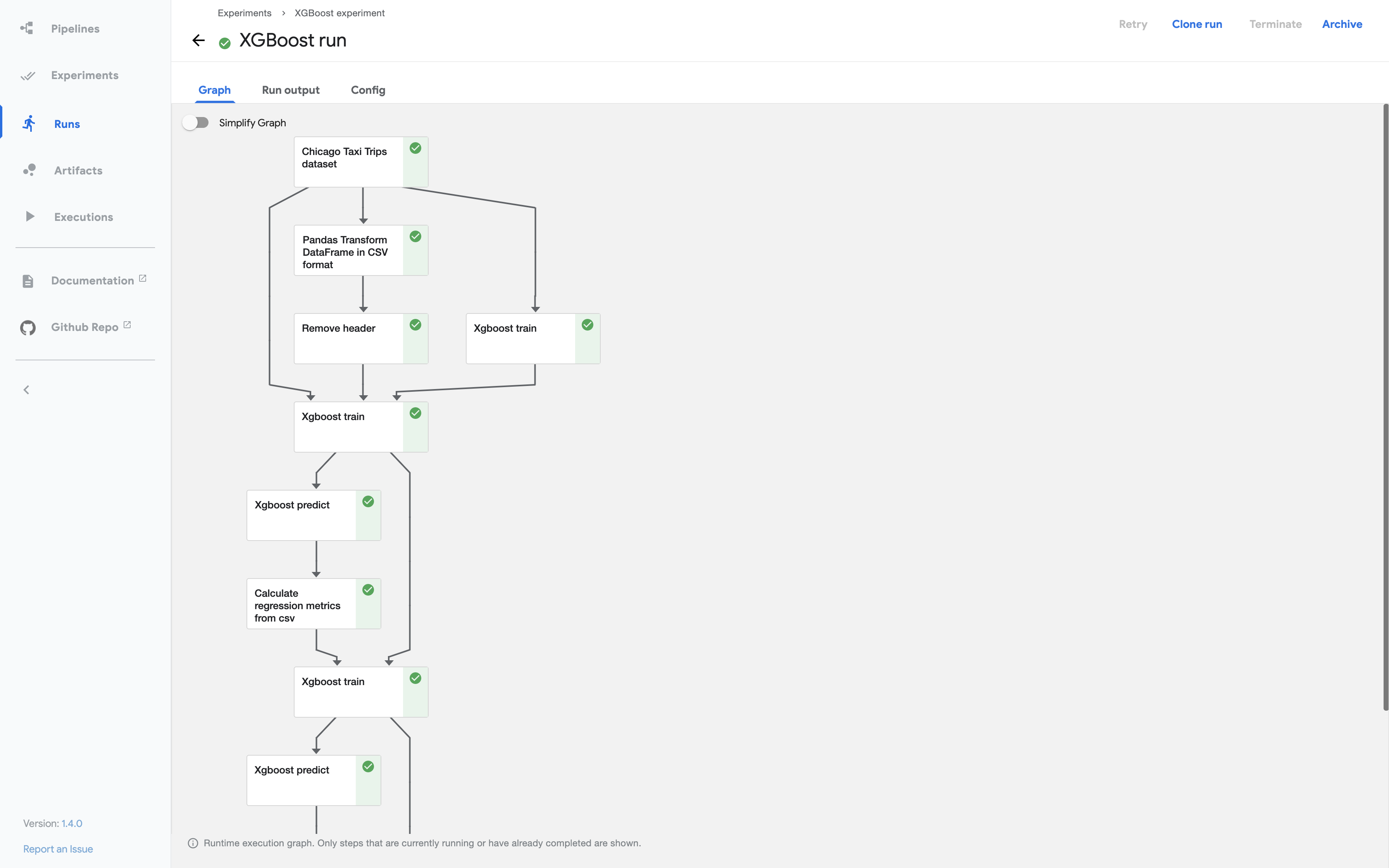
(3) Kubeflow Pipelines 의 그래프(Graph)
그래프(Graph)는 Pipeline의 실행을 Kubeflow Pipelines UI 에 노드(node)와 에지(edge)의 그래프 형태의 그림으로 표현한 것입니다. 그래프는 Pipeline이 실행되었거나 실행중인 단계(steps)를 보여주며, 화살표로 각 단계의 구성요소 간 부모/자식 관계 (parent/child relationships) 를 나타냅니다. 그래프는 파이프라인이 실행되기 시작하자마자 바로 볼 수 있습니다. 그래프 안의 각 노드는 파이프라인의 단계에 해당하며 각 단계에 맞추어서 이름이 부여됩니다.
[ Pipeline Graph 예시 ]
Kubeflow Pipelines - Graph 예시
위의 그래프 예시화면에서 보면 각 노드의 상단 우측에 아이콘이 있는데요, 이 아이콘은 각 단계의 진행상태를 의미합니다. 진행상태에는 '실행 중 (running)', '실행 성공 (succeeded)', '실행 실패 (failed)', '건너뜀 (skipped)' 등이 있습니다. 만약 부모 노드에서 조건절이 있고 조건에 해당된다면 자식노드는 '건너뜀 (skipped)' 상태가 될 수 있습니다.
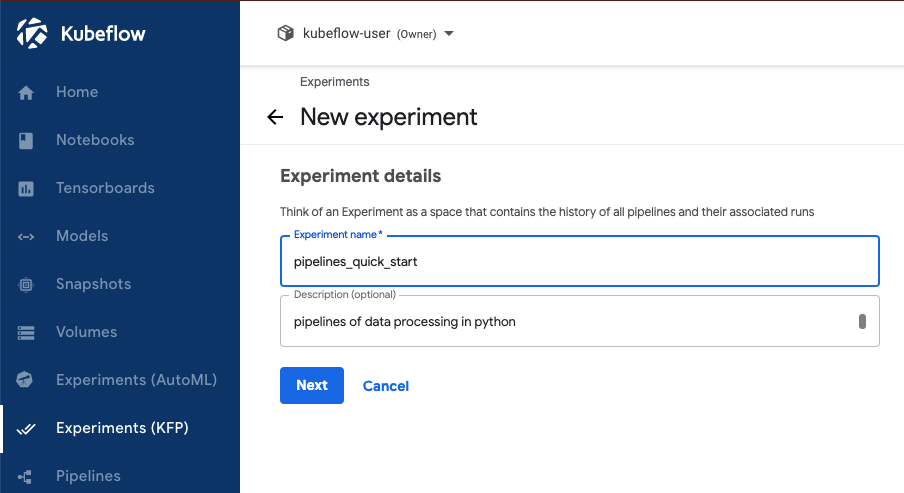
(4) Kubeflow Pipelines 의 실험 (Experiment)
실험(Experiment) 메뉴는 Pipelines 에서 다른 종류의 설정들(different configurations)을 시도해볼 수 있는 작업공간입니다. 우리는 실험 화면에서 다양한 설정의 실험 실행을 논리적인 그룹들로 조직할 수 있습니다. 실험은 순환반복실행(recurring runs)과 같은 임의적인 실행도 포함할 수 있습니다.
[ Kubeflow Pipelines - Experiment UI]
Kubeflow Pipelines - Experiment
Kubeflow Pipelines - Experiment UI
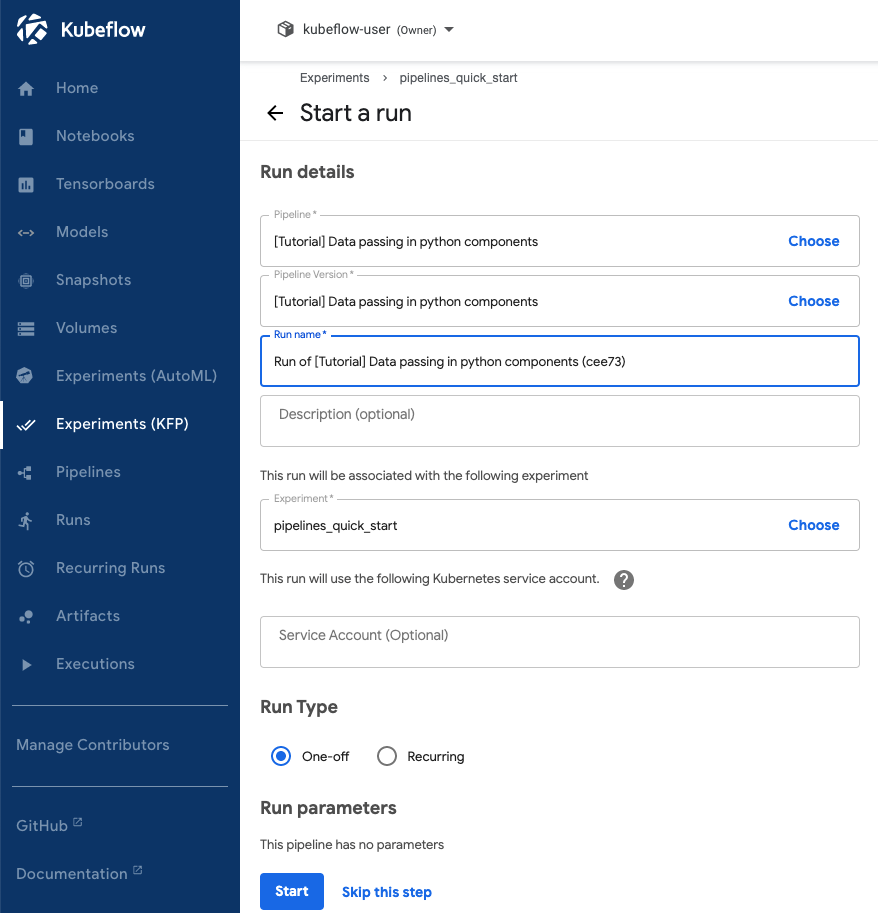
(5) Kubeflow Pipelines 의 실행과 순환실행 (Run and Recurring Run)
실행(a run)은 파아프라인에서 한번 수행(a single execution)하는 것을 말합니다. 실행(runs)은 당신이 시도하는 모든 실험들의 불변하는 로그로 이루어지며, 재현이 가능하도록(reproducibility) 독립적이고 자기충족적(self-contained) 이도록 설계가 됩니다. 우리는 Kubeflow Pipeline UI 의 상세 페이지(details page)에서 실행의 진척도를 추적할 수 있으며, 수행시간 그래프와 산출물 artifacts, 그리고 실행의 각 단계별 로그도 볼 수 있습니다.
순환실행(recurring run), 또는 Kubeflow Pipelines backend APIs 안의 job, 은 파이프라인의 반복할 수 있는 실행(a repeatable run of a pipeline)을 말합니다. 순환실행을 위한 환경설정은 명시된 모든 파라미터값과 실행 트리거(run trigger) 를 가진 파이프라인의 복사를 포함합니다. 당신은 순환실행을 어느 실험 안에서나 시작할 수 있으며, 그것은 주기적으로 실행 환경설정의 새로운 복사를 시작할 것입니다. 당신은 Kubeflow Pipelines UI에서 순환실행의 활성화/비활성화를 선택할 수 있습니다. (위 Experiment UI의 하단에 있는 Run Type: One-off vs. Recurring). 당신은 또한 동시실행의 최대개수도 구체적으로 명시할 수 있으며, 병렬로 시작하는 실행의 숫자도 제한할 수 있습니다. 이런 기능들은 만약 파이프라인이 오랜 시간동안 수행이 될 것으로 예상되고 자주 실행이 된다면 유용하게 사용될 수 있습니다.
(6) Kubeflow Pipelines 의 실행 트리거 (Run Trigger)
실행 트리거(run trigger)는 시스템에게 언제 순환실행 환경설정(recurring rum configuration)이 새로운 실행을 생성해야 할지를 알려주는 표시(flag)입니다. 아래의 두가지 유형의 순환실행을 사용할 수 있습니다.
-. 주기적 (Periodic): 가령 매 2시간 또는 매 45분 간격마다 주기적으로 실행하는 것과 같이, 시간간격 기반의 실행 스케줄링(for an interval-based scheduling of runs)에 사용.
-. 특정 시기 (Cron): 명시적으로 실행 스케줄링의 '특정 시간 문구(cron semactics)'를 지정하고자 할 때 사용.
(7) Kubeflow Pipelines 의 단계(Step)
단계(step)는 파이프라인 안의 구성요소들 중의 하나의 실행(an execution of one of the components in the pipeline)을 의미합니다. 단계(step)와 구성요소(component)와의 관계는 인스턴스화(steps = component instances)의 하나로서, 실행(run)과 파이프라인(pipeline)의 관계와 상당히 유사합니다.
복잡한 파이프라인에서는 구성요소(components)는 순환문에서 여러번 수행할 수도 있으며, 또는 파이프라인 코드 안에서 if/else 조건절을 분석한 후에 조건부로 수행할 수도 있습니다.
(8) Kubeflow Pipelines 의 산출물 Artifact (Output Artifact)
산출물 artifact 는 파이프라인 구성요소에 의해서 생성되는 산출물로서, Kubeflow Pipelines UI 가 이를 이해하고 풍부한 시각화를 생성할 수 있습니다. 파이프라인 구성요소(pipeline components)에 산출물 artifact 를 포함시킴으로써 모델 성능평가, 실행을 위한 빠른 신속한 의사결정, 또는 다른 실행들 간의 비교를 하는데 유용하게 사용할 수 있습니다. Artifact 는 또한 파이프라인의 다양한 구성요소가 어떻게 작동하는지를 이해하는 것을 가능하게 해줍니다. Artifact 는 평범한 텍스트 뷰부터 풍부한 상호작용 시각화까지 다양한 형태를 띨 수 있습니다.
[책] 클라라와 태양 (Klara and The Sun, 가즈오 이시구로 지음, 2021년)
올 추석 연휴 기간 동안에 가즈오 이시구로가 쓴 <클라라와 태양>이라는 소설책을 읽었습니다. 인공지능을 전공한 전문가의 시선이 아니라, 사람과 사회를 관찰하고 상상력을 발휘해 이야기를 구성하는 소설가의 시선으로 바라본 인공지능의 가까운 미래는 어떠한 모습일지 궁금했습니다.
책 제목의 "클라라(Klara)"는 인공지능 로봇 친구 (Artificial Intelligence Friend, 에이에프) 의 이름이예요. 그리고 태양(The Sun)"은 인공지능 로봇의 영양원 (태양광 발전)이면서 또 클라라가 신비한 치유의 힘이 있다고 믿는 숭배의 대상이기도 해요. 이 책은 가까운 미래를 배경으로 에이에프(AI Friend) 클라라의 1인칭 시점으로 쓰여진 소설이예요.
클라라와 태양, 가즈오 이시구로
이 책의 작가 가즈오 이시구로 (Kazuo Ishiguro) 는 2017년 노벨문학상을 수상한 작가예요.
국내에는 <남아있는 나날 (The Remains of the Day)>, <나를 보내지 마 (Never Let Me Go)> 등 예닐곱권의 책이 이미 번역되어 있고, 또 이 두 책은 영화로도 제작이 되었어요.
이름도 그렇고, 왼쪽의 사진을 봐도 그렇고, 작가가 일본인이라고 생각하기 쉬운데요, 일본계 영국인이예요.
가즈오 이시구로는 5살때까지 일본에서 살다가, 아버지를 따라서 영국으로 건너가서 계속 영국에서 살았다고 하네요.
영국에 살면서 동양인 외모 때문에 차별을 받았었는지, 오기로 "가장 영국적인 것을 써주겠다"며 쓴 <남아 있는 나날 (The Remains of The Day)> 로 노벨 문학상을 받았다고 하니 아픔을 문학으로 잘 승화한 최고의 케이스가 아닐까 싶어요.
이 책의 뒷 표지에 보면 "<나를 보내지 마>와 <남아 있는 나날> 사이에 다리를 놓는 가즈오 이시구로 최고의 작품"이라는 홍보 문구가 나와요. 저는 앞서의 두 작품(Never Let Me Go, The Remains of the Day)은 책말고 영화로 봤는데요, 나중에 시간이 되면 이 두 작품에 대해서도 포스팅 해볼께요.
(... 여기서 부터는 책 내용이 많이 나오므로, 아직 책을 안 읽으신 분은 계속 읽을지 잠시 고민해주세요.... ^^;)
이 소설책을 읽으면서 들었던 몇 가질 질문들에 대해서 생각해보면서 포스팅을 해보겠습니다. (줄거리에 대해서는 위키피디아 찾아보시면 돼요). 책을 읽으신 분들은 추가로 다른 재미있는 질문들을 던져보면 좋을거 같아요.
1. (조시가 죽게 된다면) 클라라는 조시를 대체할 수 있을까?
2. 유전자 변형 생명공학으로 향상된 인간, 당신의 선택은?
3. 변덕스러운 인간 vs. 일관적이고 헌신적인 인공지능 로봇 친구 중에서 누가 좋은가?
4. 인공지능이 가져올 일, 직업의 미래는?
5. 이해할 수 있는, 설명 가능한 인공지능?
6. 불가사의한 존재에 대해 숭배하는 종교는 본성인가?
1. (조시가 죽게 된다면) 클라라는 조시를 대체할 수 있을까?
클라라는 최신형의 에이에프(AI Friend)는 아니지만, 사람들을 관찰하고, 배우고, 감정을 읽고 표현하는데 매우 능숙합니다. 그래서 조시라는 여자 아이가 클라라에게 호감을 가지게 되고, 조시의 어머니도 클라라가 조시를 잘 관찰하고 모방할 수 있는 능력을 평가해보고는 클라라를 선택해서 구매하게 됩니다.
조시의 어머니는 유전자 조작에 의해 생명의 위험할 정도로 아픈 조시가 첫째 딸처럼 죽게 될 경우, 에이에프 클라라가 조시의 대신해서 딸의 역할을 해주기를 기대합니다. 그래서 아픈 조시를 데리고 초상화 (클라라게 입게 될 조시의 외형) 를 그린다는 명목으로 사진을 찍어가면서 조시의 외형을 본뜨고, 또 클라라에게는 조시를 잘 관찰하고 배워서 조시처럼 생각하고 행동해달라고 부탁 (지시?)을 합니다.
그럼, 과연 클라라는 (조시가 죽게 된다면) 조시를 대체해서 어머니의 딸이 될 수 있을까요? 인공지능은 사람의 생각과 감정을 학습할 수 있을까요? 인공지능이 학습할 수 없는, 사람만의 특별한 무엇, 가령, 영혼(sprit) 같은 것이 있는 것일까요?
소설의 주인공 클라라는 처음에는 인공지능 친구가 사람(조시)를 학습하여 역할을 대신할 수 있을 것 같다고 했다가, 마지막에는 가능하지 않을 것 같다고 입장을 바꿉니다.
아래는 공학자인 아버지와 클라라가 나누는 대화예요. (p321~322)
"말씀하신 마음이요." 내가 말했다. "그게 가장 배우기 어려운 부분일 수 있을 거 같습니다. 방이 아주 많은 집하고 비슷할 것 같아요. 그렇긴 하지만 시간이 충분히 주어지고 에이에프가 열심히 노력한다면 이 방들을 전부 돌아다니면서 차례로 신중하게 연구해서 자기 집처럼 익숙하게 만들 수 있을 겁니다" 아버지도 옆길에서 끼어들려고 하는 차에 경적을 울렸다. "하지만 네가 그 방 중 하나에 들어갔는데, 그 안에 또 다른 방이 있다고 해봐. 그리고 그 방 안에는 또 다른 방이 있고. 방 안에 방이 있고 그 안에 또 있고 또 있고. 조시의 마음을 안다는 게 그런 식 아닐까? 아무리 오래 돌아다녀도 아직 들어가 보지 않은 방이 또 있지 않겠어?" 나는 이 말을 잠시 생각해 본 다음 대답했다. "물론 인간의 마음은 복잡할 수밖에 없습니다. 하지만 어딘가에 한계가 있을 거예요. 폴 씨가 지적인 의미로 말씀하셨지만 그래도 배워야 할 것에는 끝이 있을 겁니다. 조시의 마음은 방안에 또 방이 있는 이상한 집을 닮았을 수 있지요. 하지만 이게 조시를 구하는 가장 좋은 방법이라면 저는 최선을 다하겠어요. 제가 성공할 가능성이 충분히 있다고 생각합니다."
위의 대화에서 클라라가 하는 대답은 인공지능 전문가들의 시각과 일맥상통하는 면이 있어요. 양질의 충분한 학습 데이터와 시간, 컴퓨팅 자원이 있다면 학습하지 못할 것이 없다는 생각이요. 사람의 생각의 숫자로 이루어진 벡터 공간으로 표현할 수 있고, 학습할 수 있다고 보고 있지요.(딥러닝의 아버지인 제프리 힌튼 선생님의 말씀이예요.)
아래의 대화는 클라라가 야적장에서 매니저와 나누는 대화예요. (p441~442)
(매니저) "네 말이 틀림없이 맞을 거야. 클라라. 그런데 '조시를 계속 이어 간다'라는게 무슨 뜻이야? 무슨 소리지?" (클라라) "저는 조시를 배우기 위해서 최선을 다했고, 그래야만 했다면 최선을 다해서 그렇게 했을 거예요. 하지만 잘되었을것 같지는 않아요. 제가 정확하게 하지 못해서가 아니라요. 제가 아무리 노력해도 할 수 없는 무언가가 있었을 거라고 생각해요. 어머니, 릭, 가정부 멜라니아, 아버지. 그 사람들이 가슴속에서 조시에 대해 느끼는 감정에는 다가갈 수가 없었을 거예요. 지금은 그걸 확실하게 알아요." (매니저) "그래, 클라라. 일이 잘 풀렸다고 생각한다니 다행이다." (클라라) "카팔디 씨는 조시 안에 제가 계속 이어 갈 수 없는 특별한 건 없다고 생각했어요. 어머니에게 계속 찾고 찾아봤지만 그런 것은 없더라고 말했어요. 하지만 저는 카팔디 씨가 잘못된 곳을 찾았다고 생각해요. 아주 특별한 무언가가 분명히 있지만 조시 안에 있는 게 아니었어요. 조시를 사랑하는 사람들 안에 있었어요. 그래서 저는 카팔디 씨가 틀렸고 제가 성공하지 못했을 거라고 생각해요. 그래서 제가 결정한 대로 하길 잘했다고 생각해요."
이는 다분히 소설가가 쓸 수 있는, 인문학의 관점의 감성적인 대답이네요. 클라라에게 조시의 모습을 본 뜬 외형의 표피 옷(?)을 입힌다고 한들, 인간 조시와 맺었던 추억, 감정들까지 클라라에게 입혀줄 수는 없을 테니깐요.
인공지능은 사람의 지능, 생각, 감정을 학습할 수 있을까요? 컴퓨터 과학의 아버지이자 수학자, 논리학자 였던 앨런 튜링은 1950년대에 "기계가 지능을 가질 수 있는가?"를 확인하는 방법으로 "튜링 테스트"를 제안해요. A 사람과 B 기계가 C 사람과 대화를 했을 때, C 사람이 A와 B 중에서 누가 사람이고 누가 기계인지를 구분하지 못하면, 기계도 지능을 가지고 있다고 간주할 수 있는것 아니냐는 것이죠. 튜링 테스트의 관점에서 보면 이미 튜링 테스트를 통과한 인공지능이 있어요. 그리고 우리 일상 생활 속에도 (아직은 대화가 어색하고 불완전하긴 하지만) 인공지능 스피커라든지, 서비스별 챗봇 등을 볼 수 있어요.
다만, 인간을 학습하는 것과는 별개로 "인간을 대체할 수 있을까?"는 완전히 다른 영역의 질문인지라 클라라의 마지막 대답이 더 적절한 대답일거 같아요. 시간의 흐름속에 쌓인 "관계"는 학습할 수 없는 거니깐요.
2. 유전자 변형 생명공학으로 향상된 인간, 당신의 선택은?
조시는 유전자 변형 생명공학 (정확하게 어떤 방법인지는 설명 없음) 에 의해서 지능이 '향상'된 부류에 속하는 아이예요. 반면에 조시의 친구 릭은 '향상'이라는 조치를 받지 않은 평범한 아이이구요. '향상'된 조시는 교사에게 지도받을 권리를 받고, 유망한 대학에도 진학하고, 사회적으로 우대받을 기회를 얻은 대신에 "나쁜 건강과 생명을 잃을 수도 있다는 위험"을 감수해야 해요. 실제로 조시의 언니는 향상된 시술을 받고 태어났다가, 어렸을 때 건강이 나빠져서 생명을 잃고 말아요. 그리고 조시도 언니처럼 몹시 아프고요.
소설에서 보면 '향상'된 아이들이 모여서 '사회적용 학습'을 위한 파티를 해요. 이때 '평범'한 릭도 조시의 초대로 파티에 참석하는데요, '향상'된 아이들과 그들의 부모로부터 멸시어린 시선을 받아요. '평범'한 릭은 건강에는 문제가 없지만, 교육에서도 차별을 받고, 그래서 좋은 직장을 가질 수도 없을 것 같은 암움한 미래가 기다리고 있어요.
자, 이런 상황에서 당신이라면 자녀를 위해서 '향상 & 생명의 위험'과 '평범 & 건강한 몸' 중에서 어떤 것을 선택하시겠어요? 참 어려운 질문이예요. 쉽게 답을 못하겠어요.
한국 사회에서 주위를 둘러보면 아이들을 닥달해서 하루 종일 학원돌리고, 주말에도 아이들 숨도 못쉬게 공부만 시키고 하는게 어찌보면 조시의 엄마가 선택했던 '향상'의 21세기 한국의 사회상과도 어느정도 통하는 면이 있다고 볼 수 있지 않을까요? 아마도 한국 사회의 지금 세대의 부모들을 대상으로 설문조사를 해보면 '생명의 위험을 무릎쓰고라도 향상을 선택'하겠다는 쪽이 더 많지 않을가 예상해봐요. 한국사회에서 '남과 비교하고 남의 시선을 의식'하며 사는 게 너무 만연해 있다보니깐요. ㅠ_ㅠ
'잘 사는게 무엇인지?', '행복이 무엇인지?'에 대한 질문에 무어라고 답할지와 밀접한 관련이 있을것 같아요.
3. 변덕스러운 인간, vs. 일관적이고 헌신적인 인공지능 로봇 친구 중에서 누가 좋은가?
소설에서 보면 인간 조시, 어머니, 릭은 변덕스러운 반면, 에이에프 클라라는 일관적이고 헌신적이예요.
'향상'된 아이들과의 파티에서, 클라라에게 딴지를 거닌 아이들의 장난에 조시는 부응하면서 "상향 버전의 에이에프를 살 걸 그랬나?" 라고 말해요. 클라라가 제일 좋다고 할때는 언제고, 다른 아이들 눈치보면서 클라라 마음에 염장질을 하는 조시를 좀 보세요.
조시 어머니도 클라라와 폭포를 보러 가서는 클라라에게 따뜻한 말을 많이 해줘요. 하지만, 조시가 많이 아프자 "클라라를 버리고 조시 옆에서 하루 종일 있을 수 있어"라고 조시에게 말하기도 해요.
조시의 베프인 릭도 어렸을 때 조시와 평생을 같이 하겠다는 약속을 서로 해요. 하지만, '향상'된 조시는 대학교에 가고, '평범'한 릭은 대학교에 못가면서 어렸을 때 조시와 한 약속은 철부지였을 때 뭣모르고 한 약속이었다면서 약속은 잊기로 해요.
반면, 클라라는 항상 사람에게서 배우려 하고, 자신의 감정에 충실하며, 비폭력 대화 방식으로 자신의 생각과 감정을 잘 표현해요. 그리고 클라라는 주인에게 얼마나 헌신적이고 충성하는지 몰라요. 심지어는 마지막에 야적장에 버져진 후에도 배신당했다는 분노 없이 일관되게 조시를 그리워하고 또 감사하게 생각해요.
저한테 만약 클라라 같이 대화도 사랑스럽게 잘 하고, 헌신적이며, 게다가 일관적이기까지 한 에이에프가 있다면 무척 좋아할 거 같긴해요. 사람들이 애완동물 강아지를 좋아하는 이유가 이런거 아닐까 싶기도 해요. ㅎㅎ
4. 인공지능이 가져올 일, 직업의 미래는?
소설에서 조시의 아버지 폴은 인공지능에 의해서 대체되었고, 무직상태의 대체된 사람들이 모여사는 커뮤니티 마을에 살고 있어요. 폴이 유능한 공학자였는데도 인공지능에 의해 대체된 걸 보면 좀 섬뜩하기도 해요.
그런데 이게 미래의 얘기만은 아니예요. 이미 지금 우리 주변에서도 심심치않게 볼 수 있어요. 가령, 신분당선에는 기관사가 없는거 아세요? 컨설팅회사 맥킨지의 연구 보고서에 따르면 "2030년까지 현재 직업의 3분의 1이 지능형 에이전트나 로봇과 같은 AI 기술로 대체될 것으며, 자익적으로는 거의 모든 인간의 직업을 대체해 모든 이에게 AI가 만든 보물이 제공된다"고 예측하고 있어요.
AI타임즈 (2020.09.02일 기사 중에서)
한국에서 잘 나가는 소위 '사'자 붙은 의사, 판사 등의 직업도 AI로 인해 상당한 영향을 받게 될거예요. 한국의 학교와 학원에서는 20세기의 성공공식에 근거해서 창의성과 질문하는 힘 대신에 암기식, 서열식 줄세우기 교육에만 매달리고 있는데요, 이대로 괜찮은가하고 심각하게 질문해봐야 해요. 부모세대와 자식세대가 살아갈 세계는 완전히 다름에도 불구하고, 부모세대의 성공공식을 자녀에게 강요하는게 과연 효과적인 전략일까요?
이런 측면에서 이 소설이 제기한 "인공지능 친구가 따라할 수 없는 인간만의 특성은 무엇일까?"에 대한 질문이 가이드가 될 수 있을 것 같아요.
코로나로 촉발된 '기본소득'에 대한 정치사회적 논의도 'AI로 인해 대체될 직업'과 연관지어서 정치권과 사회에서 계속 논의가 되어여 할 주제일거예요. AI로 인해 대체되는 직업의 양과 속도가 많고 빠를텐데요, AI로 대체된 사람들의 '직업 역량 교육과 전향'은 아무래도 더디게 진행될 수밖에 없기 때문에요. 이 소설 속의 아버지 폴도 '기본소득'의 혜택을 받고 있는것 같아요.
5. 이해할 수 있는, 설명 가능한 인공지능?
초상화 작가 카팔디씨는 "사람들이 인공지능을 두려워 하는 이유는 AI가 블랙박스여서 그 안을 모르기때문"이라고 말하고 있어요. 그래서 클라라와 어머니에게 찾아와서는 클라라를 해체해서 인공지능의 사고하는 내부 매커니즘을 이해하는 연구를 할 수 있게 도와달라고 요청을 하기도 해요.
요즘 각광받고 있는 딥러닝(Deep Learning)은 인간의 뇌(뉴런, 시냅스 등)를 모방한 측면이 있어요. 그리고 역으로 인공지능을 연구하는게 사람의 지능을 이해하는데 힌트라든지 새로운 관점을 제시할 수도 있을거 같아요.
최근에 "설명가능한 인공지능 (Explainable AI, XAI)" 분야에 대한 연구가 굉장히 활발하게 진행이 되고 있어요. 저도 “Hands-On Explainable AI (XAI) with Python" 이라는 책을 사서 요즘 공부하고 있어요. ㅎㅎ
Hands-On Explainable AI(XAI) with Python
그런데 이게 최근에 딥러닝으로 대표되는 AI 모델이 점점 커지고 있다보니 도대체 '설명가능한'을 어느정도로 봐야 하느냐는 의문이 들기는 해요. 가령, Open AI 가 만들어서 공개한 자연어 처리 모델인 GPT-3 는 성능이 어마무시한데요(마치 사람과 대화하는 것처럼 자연스러움), 무려 1,750억개의 파라미터를 가지고 있어요. 그리고 앞으로 나올 GPT-4 모델은 100조(兆
)개의 파라미터를 사전학습할거라고 하네요. 무려 100조개의 파라미터라면, 이걸 사람이 하나씩 까본다고 한들 이해했다고 말할 수 있으려나요? 복잡도가 너무 높아서 이해하려고 했다가 기가 질려버리기 십상이예요. -_-;;;
6. 불가사의한 존재에 대해 숭배하는 종교는 본성인가?
에이에프 클라라는 태양으로부터 영양분(에너지)를 받아서 움직여요. 클라라가 매장에서 진열되어 있을 때 창밖의 길 모퉁이에 있던 거지와 개가 다 죽어가다가도 아침에 뜨는 해를 쬐고는 다시 생기와 활력을 얻는 모습을 보게 되요. 그리고는 '태양에는 생명의 기운과 치유의 힘이 있다'는 믿음을 가지고 숭배(?)를 하게 돼요.
인간이 자연의 힘의 원리에 대해서 무지했던 원시시대에 자연을 숭배했던 미신의 모습과 많이 닮아있지요? ㅎㅎ
[ 책 읽기를 마치며 ]
이 책 <클라라와 태양>이 영화로 만들어질 것이라고 하니 기다려 보죠.
인공지능 친구와 관련된 영화로 "그녀 (Her, 2013)" 도 함께 보면 재미있을 거예요. 무척 잘 만든, 재미있는 영화예요.