[LangChain] 자연어로 질의해서 PostgreSQL, Greenplum DB에 SQL Query하여 답변하기 (Querying a PostgreSQL, Greenplum DB in natural language)
Deep Learning (TF, Keras, PyTorch)/Natural Language Processing 2023. 12. 27. 10:46대규모 언어 모델 (Large Language Model, LLM) 이 사실에 입각하지 않고 그럴싸한 답변을 생성하는 것을 환각 (Hallucinations) 이라고 합니다. LLM의 환각을 방지하는 방법 중의 하나로 RAG (Retrieval-Agumented Generation) 이 많이 사용되고 있는데요, 이전에 소개했던 RAG 는 비정형 데이터인 텍스트를 임베딩하여 Semactic Search를 하여 Context로 사용할 문서를 LLM에 인풋으로 넣어주는 방법이었습니다.
이번 포스팅에서는 LangChain과 ChatGTP를 이용해서 PostgreSQL, Greenplum Database의 테이블에 행, 열의 테이블에 저장되어 있는 정형 데이터 (Structured Data)에 대해서 SQL Query를 사용해서 질의를 해서 사실 (Fact) 데이터를 Query 해와서, 이를 기반으로 LLM 모델이 답변을 생성하는 방법을 소개하겠습니다. 자연어로 질문하고 자연어로 답변을 받게 되면 DB나 SQL Query를 모르는 일반 사용자도 DB에 저장되어 있는 사실에 기반한 최신의 내부 데이터까지도 활용해서 정확한 답변을 받을 수 있게 됩니다.
먼저, PostgreSQL, Greenplum 데이터베이스에 대해서 간략히 소개하겠습니다.
1. PostgreSQL 데이터베이스란?
PostgreSQL, 종종 Postgres로 불리는 이 데이터베이스는 강력한 오픈 소스 객체-관계형 데이터베이스 시스템입니다. 이는 신뢰성, 기능의 견고함, 그리고 성능 면에서 좋은 평판을 가지고 있습니다.
PostgreSQL은 객체-관계형 데이터베이스로서, 전통적인 관계형 데이터베이스 기능인 테이블 기반 데이터 저장 및 SQL(Structured Query Language) 쿼리와 더불어 객체 지향 데이터베이스 기능인 객체와 클래스에 데이터를 저장하는 것을 지원합니다.
이는 무료로 자유롭게 사용할 수 있는 오픈 소스 소프트웨어입니다. 그 소스 코드는 누구나 열람하거나 개선하길 원하는 사람에게 공개되어 있습니다.
PostgreSQL의 핵심 강점 중 하나는 확장성입니다. 사용자는 자신만의 데이터 타입, 인덱스 타입, 함수 언어 등을 정의할 수 있습니다.
2. Greenplum 데이터베이스란?
Greenplum 데이터베이스는 고급 기능을 갖춘 오픈 소스 데이터 웨어하우스입니다. 이는 페타바이트 규모의 빅데이터에 대해 강력하고 빠른 분석을 제공합니다. 원래 PostgreSQL에서 파생되었지만, Greenplum 데이터베이스는 그 능력과 성능을 크게 확장해 발전시켰습니다.
Greenplum은 Shared-Nothing, 대규모 병렬 처리 아키텍처(Massively Parallel Processing Architecture, MPP)를 사용합니다. 이는 데이터가 여러 세그먼트로 나뉘고 각 세그먼트가 병렬로 처리되어 고성능 및 대규모 데이터 분석을 가능하게 한다는 의미입니다.
확장성(Scalability)을 위해 설계된 Greenplum은 큰 데이터 볼륨을 처리할 수 있습니다. 이는 많은 서버에 걸쳐 확장되어 큰 데이터 볼륨과 복잡한 쿼리를 관리할 수 있습니다.
Greenplum은 고급 분석 기능을 지원합니다. 이는 Python, R 및 기타 통계 및 머신 러닝 라이브러리와 통합되어 데이터베이스 내에서 고급 데이터 분석을 직접 수행할 수 있게 합니다.
(Greenplum DB 소개 참고: https://rfriend.tistory.com/377)
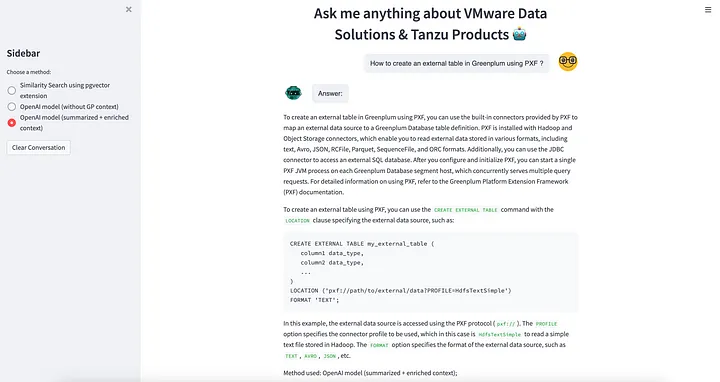
[ LangChain과 ChatGPT를 사용하여 자연어로 PostgreSQL, Greenplum에 Query하는 Workflow ]

3. LangChain, ChatGPT로 PostgreSQL에 자연어로 Query해서 답변 생성하기
(1) 사용자가 애플리케이션에서 자연어로 질의
(2) LangChain이 LLM 모델에 사용자 질문을 SQL Query로 변환 요청
(3) LLM 모델이 DB Schema 정보에 기반해 사용자 질문에 대한 SQL Query를 생성해서 반환
(4) LangChain이 PostgreSQL, Greenplum DB에 SQL Query 실행 요청
(5) PostgreSQL, Greenplum DB에서 SQL Query 실행하여 결과 반환
(6) LangChain이 사용자 질문과 SQL Query, Query 결과를 기반으로 LLM 모델에 답변 생성 요청
(7) LLM 모델이 사용자 질문과 Query 결과를 기반으로 생성한 자연어 답변 반환
(8) LangChain이 애플리케이션의 사용자 UI에 LLM 모델이 생성한 자연어 답변 반환
(0) 준비사항: PostgreSQL에 예제 테이블 생성하고 데이터 집어넣기
먼저, 예제로 사용할 PostgreSQL DB에 iris 라는 테이블을 만들어보겠습니다. 그리고, 나중에 자연어로 질의할 내용을 미리 SQL Query로 결과를 조회해보았습니다.
DROP TABLE IF EXISTS iris;
CREATE TABLE iris (id INT, sepal_length FLOAT, sepal_width FLOAT,
petal_length FLOAT, petal_width FLOAT,
class_name text);
INSERT INTO iris VALUES
(1,5.1,3.5,1.4,0.2,'Iris-setosa'),
(2,4.9,3.0,1.4,0.2,'Iris-setosa'),
(3,4.7,3.2,1.3,0.2,'Iris-setosa'),
(4,4.6,3.1,1.5,0.2,'Iris-setosa'),
(5,5.0,3.6,1.4,0.2,'Iris-setosa'),
(6,5.4,3.9,1.7,0.4,'Iris-setosa'),
(7,4.6,3.4,1.4,0.3,'Iris-setosa'),
(8,5.0,3.4,1.5,0.2,'Iris-setosa'),
(9,4.4,2.9,1.4,0.2,'Iris-setosa'),
(10,4.9,3.1,1.5,0.1,'Iris-setosa'),
(11,7.0,3.2,4.7,1.4,'Iris-versicolor'),
(12,6.4,3.2,4.5,1.5,'Iris-versicolor'),
(13,6.9,3.1,4.9,1.5,'Iris-versicolor'),
(14,5.5,2.3,4.0,1.3,'Iris-versicolor'),
(15,6.5,2.8,4.6,1.5,'Iris-versicolor'),
(16,5.7,2.8,4.5,1.3,'Iris-versicolor'),
(17,6.3,3.3,4.7,1.6,'Iris-versicolor'),
(18,4.9,2.4,3.3,1.0,'Iris-versicolor'),
(19,6.6,2.9,4.6,1.3,'Iris-versicolor'),
(20,5.2,2.7,3.9,1.4,'Iris-versicolor'),
(21,6.3,3.3,6.0,2.5,'Iris-virginica'),
(22,5.8,2.7,5.1,1.9,'Iris-virginica'),
(23,7.1,3.0,5.9,2.1,'Iris-virginica'),
(24,6.3,2.9,5.6,1.8,'Iris-virginica'),
(25,6.5,3.0,5.8,2.2,'Iris-virginica'),
(26,7.6,3.0,6.6,2.1,'Iris-virginica'),
(27,4.9,2.5,4.5,1.7,'Iris-virginica'),
(28,7.3,2.9,6.3,1.8,'Iris-virginica'),
(29,6.7,2.5,5.8,1.8,'Iris-virginica'),
(30,7.2,3.6,6.1,2.5,'Iris-virginica');
SELECT * FROM iris ORDER BY id LIMIT 5;
-- 5.1 3.5 1.4 0.2 "Iris-setosa"
-- 4.9 3 1.4 0.2 "Iris-setosa"
-- 4.7 3.2 1.3 0.2 "Iris-setosa"
-- 4.6 3.1 1.5 0.2 "Iris-setosa"
-- 5 3.6 1.4 0.2 "Iris-setosa"
SELECT
AVG(sepal_length)
FROM iris
WHERE class_name = 'Iris-setosa';
-- 4.859999999999999
SELECT
class_name,
AVG(sepal_length)
FROM iris
GROUP BY class_name
ORDER BY class_name;
-- class_name avg
-- "Iris-setosa" 4.85
-- "Iris-versicolor" 6.10
-- "Iris-virginica" 6.57
SELECT
class_name
, MAX(sepal_width)
FROM iris
GROUP BY class_name
ORDER BY class_name;
-- class_name max
-- "Iris-setosa" 3.9
-- "Iris-versicolor" 3.3
-- "Iris-virginica" 3.6
(0) 준비사항: Python 모듈 설치
LLM 모델을 통한 답변 생성에 필요한 openai, langchain, 그리고 PostgreSQL, Greenplum DB access를 위해 필요한 psycopg2 모듈을 pip install을 사용해서 설치합니다.
! pip install -q openai langchain psycopg2
(0) 준비사항: OpenAI API Key 설정
OpenAI의 ChatGPT를 사용하기 위해 필요한 OpenAI API Key를 등록합니다.
(OpenAI API Key 발급 방법은 https://rfriend.tistory.com/794 를 참고하세요)
import os
# setup OpenAI API Key with yours
os.environ["OPENAI_API_KEY"]="sk-xxxx..." # set with yours
(0) 준비사항: PostgreSQL DB 연결
이제 LangChain의 SQLDatabase() 클래스를 사용해서 PostgreSQL DB에 연결하겠습니다.
(DB credientials 는 사용 중인 걸로 바꿔주세요)
# Connect to the PostgreSQL DB
from langchain.utilities import SQLDatabase
# set with yours
username='postgres'
password='changeme'
host='localhost'
port='5432'
database='postgres'
pg_uri = f"postgresql+psycopg2://{username}:{password}@{host}:{port}/{database}"
db = SQLDatabase.from_uri(pg_uri)
(0) 준비사항: Query를 위한 Helper Function 정의
DB의 Table 정보 (테이블 이름, 칼럼 정보) 를 가져오고, SQL Query를 실행할 수 있는 Helper 함수를 정의합니다. 이제 준비가 다 되었네요.
# Helper functions
def get_schema(_):
return db.get_table_info()
def run_query(query):
return db.run(query)
(1) 사용자가 애플리케이션에서 자연어로 질의
사용자가 자연어로 질의한 질문과 DB테이블 정보를 인풋으로 받아서, "DB 테이블 정보 ("scheam")와 사용자 질문 ("question")이 주어졌을 때 PostgreSQL Query를 생성하라"고 프롬프트에 지시문을 생성하였습니다.
# Prompt for generating a SQL query
from langchain.prompts import ChatPromptTemplate
template_query = """
Based on the table schema below, \
Write a PostgreSQL query that answer the user's question:
{schema}
Question: {question}
SQL Query:"""
prompt = ChatPromptTemplate.from_template(template_query)
(2) LangChain이 LLM 모델에 사용자 질문을 SQL Query로 변환 요청
LLM에는 ChatGPT-4 모델을 사용하고, temperature=0 으로 해서 사실에 기반해서 일관성 있고 보수적인 답변을 생성하도록 설정했습니다.
# Chaining prompt, LLM model, and Output Parser
from langchain.chat_models import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
model = ChatOpenAI(temperature=0, model_name='gpt-4')
sql_response = (
RunnablePassthrough.assign(schema=get_schema)
| prompt
| model.bind(stop=["\nSQLResult:"])
| StrOutputParser()
)
(3) LLM 모델이 DB Schema 정보에 기반해 사용자 질문에 대한 SQL Query를 생성해서 반환
sql_response.invoke({"question": "What is the average of sepal length for Iris-setosa?"})
# "SELECT AVG(sepal_length) \nFROM iris \nWHERE class_name = 'Iris-setosa';"
(4) LangChain이 PostgreSQL, Greenplum DB에 SQL Query 실행 요청
아래와 같이 "DB 테이블 정보 ("schema"), 사용자 질문 ("question"), SQL Query ("query"), SQL Query 결과 ("response") 가 주어졌을 때 자연어(natural language)로 답변을 생성하라"고 프롬프트 지시문을 만들었습니다.
# Prompt for generating the final answer by running a SQL query on DB
template_response = """
Based on the table schema below, question, sql query, and sql response, \
write a natural language response:
{schema}
Question: {question}
SQL Query: {query}
SQL Response: {response}"""
prompt_response = ChatPromptTemplate.from_template(template_response)
(5) PostgreSQL, Greenplum DB에서 SQL Query 실행하여 결과 반환
'|' 를 사용해서 앞에서 정의한 SQL Query 생성하는 chain과 Query를 실행한 결과를 받아서 자연어로 답변을 생성하는 chain을 모두 엮어서 Chaining 하였습니다.
full_chain = (
RunnablePassthrough.assign(query=sql_response)
| RunnablePassthrough.assign(
schema=get_schema,
response=lambda x: db.run(x["query"]),
)
| prompt_response
| model
| StrOutputParser()
)
(6) LangChain이 사용자 질문과 SQL Query, Query 결과를 기반으로 LLM 모델에 답변 생성 요청
(7) LLM 모델이 사용자 질문과 Query 결과를 기반으로 생성한 자연어 답변 반환
자연어로 3개의 질문을 해보았는데요, 기대했던 SQL Query 문이 생성되고 Query 질의 결과를 기반으로 답변이 모두 정확하게 생성되었습니다.
Q1: What is the average of sepal length for Iris-setosa?
## Q: What is the average of sepal length for Iris-setosa?
sql_response.invoke({"question": "What is the average of sepal length for Iris-setosa?"})
# "SELECT AVG(sepal_length) \nFROM iris \nWHERE class_name = 'Iris-setosa';"
full_chain.invoke({"question": "What is the average of sepal length for Iris-setosa?"})
# 'The average sepal length for Iris-setosa is approximately 4.86.'
Q2: What is the average of sepal length by class name?
## Q: What is the average of sepal length by class name?
sql_response.invoke({"question": "What is the average of sepal length by class name?"})
# 'SELECT class_name, AVG(sepal_length) \nFROM iris \nGROUP BY class_name;'
full_chain.invoke({"question": "What is the average of sepal length by class name?"})
#'The average sepal length for the Iris-versicolor class is 6.1,
#for the Iris-setosa class is approximately 4.86,
#and for the Iris-virginica class is 6.57.'
Q3: What is the maximum value of sepal width by class name?
## Q: What is the maximum value of sepal width by class name?
sql_response.invoke({"question": "What is the maximum value of sepal width by class name?"})
# 'SELECT class_name, MAX(sepal_width) \nFROM iris \nGROUP BY class_name;'
full_chain.invoke({"question": "What is the maximum value of sepal width by class name?"})
# "The maximum sepal width for the class 'Iris-versicolor' is 3.3,
# for 'Iris-setosa' is 3.9,
# and for 'Iris-virginica' is 3.6."
위의 예는 매우 간단한 질문이어서 하나의 테이블 내에서 Join 없이도 모두 정확하게 Querying 이 되었는데요, 그래도 mission critical한 업무에서는 사용에 유의할 필요가 있습니다. 왜냐하면 실무에서 사용하는 SQL Query 문의 경우 여러개의 테이블을 Join 해야 될 수도 있고, Where 조건절에 Business Logic이 복잡하게 반영되어야 할 경우도 있고, 테이블 이름/설명이나 변수명/설명이 LLM 모델이 사용자의 질의와 매핑해서 사용하기에 부적절한 경우도 있을 수 있어서 SQL Query가 부정확할 수 있기 때문입니다.
따라서 반드시 사용자 질의에 대한 SQL Query 문을 같이 확인해보는 절차가 필요합니다.
그리고 SQL Query Generator 를 잘하는 LLM 모델, 자사 회사 내 SQL Query 문으로 Fine-tuning한 LLM 모델에 대한 시도도 의미있어 보입니다.
[ Reference ]
* LangChain - Querying a SQL DB:
https://python.langchain.com/docs/expression_language/cookbook/sql_db
* PostgreSQL 설치(OS 별 packages, installers): https://www.postgresql.org/download/
이번 포스팅이 많은 도움이 되었기를 바랍니다.
행복한 데이터 과학자 되세요! :-)

'Deep Learning (TF, Keras, PyTorch) > Natural Language Processing' 카테고리의 다른 글
| [LangChain] 시맨틱 유사도를 통해 질문과 유사한 템플릿으로 라우팅하기 (0) | 2023.12.31 |
|---|---|
| [LangChain] 자연어로 Python code 쓰고 실행하기 (0) | 2023.12.27 |
| [LangChain] 여러 개의 체인을 나누고 합치기 (Branching and Merging of Multiple Chains) (0) | 2023.12.26 |
| [LangChain] Chroma Vector DB를 사용해서 RAG (Retireval-Augmented Generation) 구현 (0) | 2023.12.25 |
| [LangChain] Redis를 사용하여 이전 대화 기억을 가진 LLM 챗봇 만들기 (Adding Message History, Memory by Redis) (0) | 2023.12.24 |