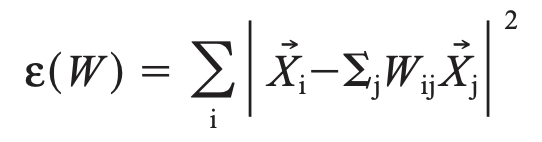이미 알만한 분들은 다 알고 계신 ‘일의 격’의 저자 신수정님께서 새로운 책으로 돌아오셨습니다. “깨어나게 하고 행동하게 하는 555개의 통찰” 이라는 부제목을 가진 책, “통찰의 시간”이예요.
통찰의 시간, 신수정 지음, 알투스
프로로그에서 저자가 ‘일의 격’과 ‘통찰의 시간’을 비교해주셨는데요,
“‘일의 격’의 글들은 필자가 50대에 쓴 비교적 긴 글들의 모음이기에 나만의 경험과 균형 있는 시각이 충분히 담겨 있다. 반면, 트위터에 쓴 글은 40대에 기록한 짧은 글들이며 나만의 경험과 통찰보다는 앞선 분들의 통찰을 정리한 글들이 많았다. 대신 간결하고 직설적이었다. 이 책은 그 글들을 기반으로 하되, 이후 페이스북의 글들 중 ‘일의 격’에 실리지 않았지만 해당 주제와 연결되는 최근의 글들도 일부 축약하여 추가했다.” - 저자 프롤로그 중에서 -
두 책을 모두 읽어본 저로서는 ‘일의 격’과 ‘통찰의 시간’을 세트로 같이 읽으시는걸 추천합니다. ‘일의 격’이 세련된 고급 식당에서 정갈하게 서빙되는 음식을 주방장이 떠먹여주듯 친절하고 맛있다면, ‘통찰의 시간’은 커피 머신으로 뜨거운 물을 통과시켜서 커피콩에 있는 커피의 액기스를 꾸욱 갓 내려서 마시는 에스프레소 같아요.
단위 투입 시간 당 가성비가 높은 것 중의 하나가 독서잖아요. 책을 한권 낸다는 것은 저자의 수년~수십년의 경험과 통찰의 정수를 뽑아서 독자에게 전달하는 것인 만큼 간접체험과 배움에 있어서는 독서가 단연 최고일텐데요, ‘통찰의 시간’ 저자는 책 중독, 활자 중독에 걸린 분이세요. 신수정 저자께서 책 수백권을 읽어보시고 거기에서 다시 액기스를 뽑아서 ‘통찰의 시간’에 한입에 먹기 좋게 요리를 해주셨다고 봐도 될거 같아요.
저자가 소개한대로, 아래의 책 사진에서 보는 것처럼 글이 대체적으로 짧아요. 책 형식이 참 파격적이예요. 마치 초콜렛 볼 하나 한입에 꿀꺽 하듯이 먹기에 부담이 없고 술술 읽혀요.
통찰의 시간, 신수정 지음
저자가 머리글에 밑줄 쫘악 그어서 강조한 부분도 소개할께요.
"나는 독자들이 이 책에 있는 555개의 모든 글을 처음부터 끝까지 읽기를 원하지 않는다. 마음에 드는 주제나 목차 중 아무것이나 읽으시라. 555개의 문장 중 한두 개라도 자신에게 공감과 영감을 준다면, 그래서 자신의 삶에 대한 생각과 관점을 바꿀 수 있다면, 그리고 행동하며 변화할 수 있다면 그것으로 충분하다. 내가 이 챆을 낸 보람과 가치는 바로 거기에 있다."
네, 마음에 드는 주제나 목차 중 아무것이나 읽으시면 되는데요, 아마 읽기 시작하면 끝까지 다 읽고 있는 자신을 보게 될 겁니다. ㅋㅋㅋㅋ
‘통찰의 시간’ 목차를 한번 살펴볼께요.
1장. 통찰 2장. 배움 3장. 행동 4장. 성공 5장. 리딩 6장. 행복
목차를 보면 우리의 삶과 관계의 변화, 사회에 선한 영향력을 끼치고 변화시키고 후대에 남기는 일련의 인생 여정에 있어 모두 필요한 것들이지요?
‘일의 격’ 책의 목차도 보면 ‘1장. 성장: 일의 성과를 극대화 시키는 기술’, ‘2장. 성공: 조직을 성공으로 이끄는 리더십의 발견’, ‘3장. 성숙: 일과 삶의 의미를 발견하는 방법’ 인 것에서 볼 수 있는 것처럼 저자가 중요시여기는 성장, 성공, 성숙이 ‘통찰의 시간’에서도 여전히 맥을 같이 하고 있다는 것을 알 수 있어요.
‘통찰의 시간’이 아무래도 트위터에서 140자 제약 아래 짧게 통찰력있는 내용을 요약한 글이 많다보니 아무래도 준비가 안된 상태라면 제대로 소화를 못 시키고 그냥 꿀꺽 삼켜버릴 수도 있을 거 같아요. 그렇다고 또 너무 걱정할 필요도 없는게, 책을 읽다보면 본인이 그 당시에 가장 치열하게 고민하고 갈망하는 주제에 대한 것이라면 아마도 20배 줌이 되어 비록 단 한줄의 글이더라도 눈 앞에 크게 살아숨쉬며 튀어나올 것이라고 저는 믿어요. 제 경험상이요. 그러니 가까운 곳에 책을 두고서 목차에서 눈에 끌리는 부분을 그때그때 부담스럽지 않게 읽다보면 ‘통찰의 시간’을 만끽할 수 있지 않을까요?! ^^*
제가 제일 좋아하는 부분을 뽑으라면, 저자 에필로그의 아래 글을 마지막으로 소개하고 싶어요. 저자의 진심이 느껴지고, 저자의 그동안의 일련의 활동들과 이 책이 일관성있게 연결이 되어요.
“수많은 사람들이 이 땅에 태어나고 사라진다. 이 중 뛰어나고 잘난 사람들도 많다. 최고의 선수, 최고의 CEO, 최고의 부자, 최고의 관료, 최고의 종교지도자, 최고의 의사, 최고의 변호사, 최고의 정치인…… 그러나 우리의 기억 속에 ‘위대한 사람’으로 남아 있는 분이 과연 몇분이나 되는가? 그렇다면, '위대함'은 어디에서 나오는가? 자신을 넘어선 '가치'를추구하고 변화를 만들어 내는 데서 나온다. 1등 부자, 1등 정치인, 1등 선수, 1등 CEO, 1등 합격자가 위대한 것이 아니다. 설령 많은 실패를 하고 권력이나 부가 없더라도 소명의식과 세상에 대한 공감이있고, 주위 사람들을 위해 의를 위해 진실을 위해 세상을 더 낫게 하기 위해 세상에 작은 빛으로 살아가신 분들이 위대하다. 최고는 해당 분야에 단 한 명밖에 주어지지 않는다. 그러나 위대함은 누구나 가능하다. 최고는 되지 못했어도 평범하지만 위대한 우리의 부모님, 우리의 선생님들도 있다. 후손들에게 더 나은 세상을 위해 분투한 우리의 선배들도 있다. 우리는 그들에게 빚을 졌다. 단 한 번뿐인 인생, 최고가 되기 위해서 살 것인가? 작더라도 조금더 큰 뜻을 품고 위대함을 만들어 볼 것인가? 이 작은 책을 내면서필자 스스로도 후자의 인생을 살 것을 다시금 다짐한다. 또한, 이 책을 통해 '통찰의 시간'을 살아가는 위대함을 선택하는 분들이 더 많아졌으면 한다.” - 저자 에필로그 중에서 -
신수정 저자님을 페이스북에서 팔로잉 하는 것도 추천합니다. 왜냐하면 ‘친구만 보기’로 페이스북에 포스팅하는 경우도 종종 있고, 매주 주말이면 맛있는 보약을 꼬박꼬박 챙겨먹듯이 마음에 울림이 있는 글들을 페이스북에서도 볼 수 있기 때문이예요.
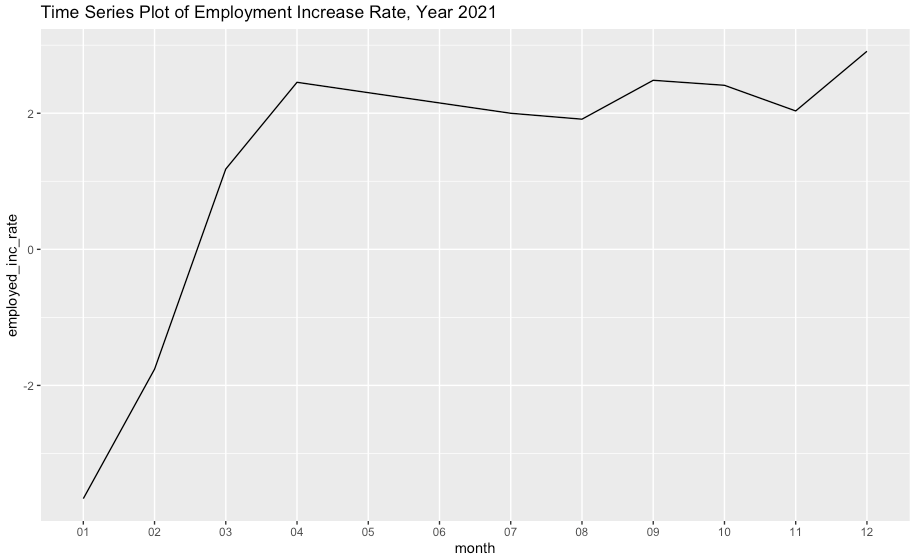
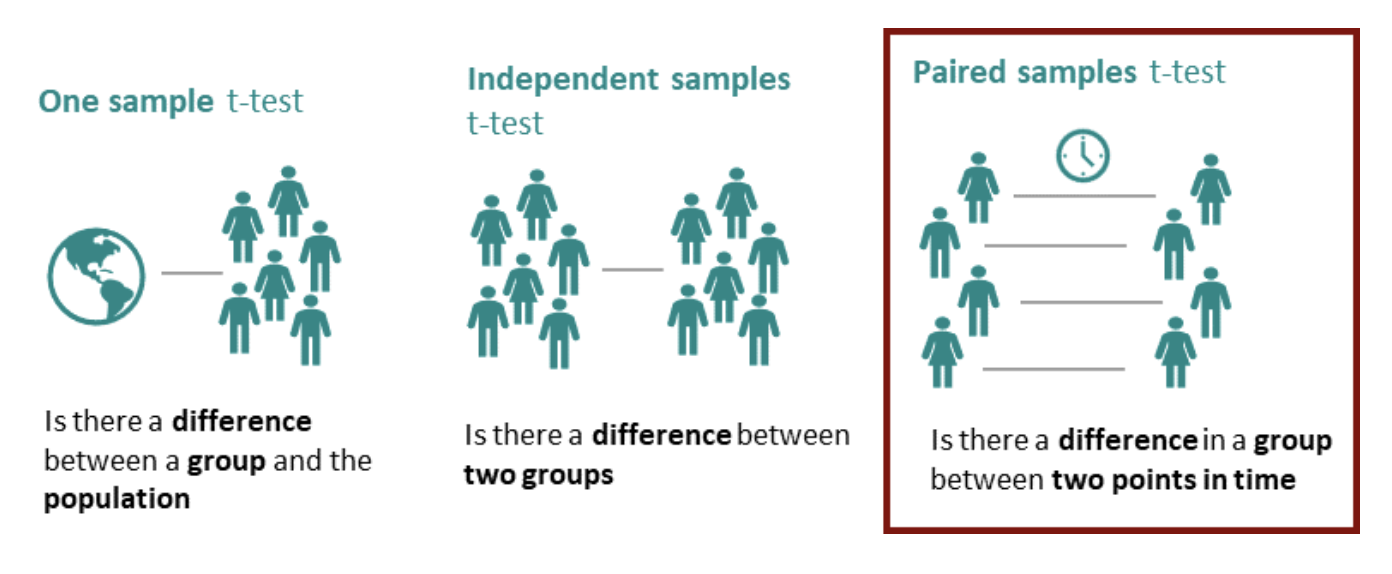
지난번 포스팅에서는 독립된 2개 표본의 평균 차이를 검정하는 t-test 에 대해서 알아보았습니다. 이번 포스팅에서는 Python을 이용한 짝을 이룬 표본의 평균 차이를 검정하는 paired t-test 에 대해서 소개하겠습니다. (R을 이용한 짝을 이룬 표본에 대한 평균 차이 검정은 https://rfriend.tistory.com/128 를 참고하세요)
짝을 이룬 t-test(paired t-test)는 짝을 이룬 측정치(paired measurements)의 평균 차이가 있는지 없는지를 검정하는 방법입니다. 데이터 값이 짝을 이루어서 측정되었다는 것에 대해 예를 들어보면, 사람들의 그룹에 대해 신약 효과를 알아보기 위해 (즉, 신약 투약 전과 후의 평균의 차이가 있는지) 신약 투약 전과 후(before-and-after)를 측정한 데이터를 생각해 볼 수 있습니다.
[ One sample t-test vs. Independent samples t-test vs. Paired samples t-test ]
짝을 이룬 t-test(paired t-test)는 종속 표본 t-test (the dependent samples t-test), 짝을 이룬 차이 t-test (the paired-difference t-test), 매칭된 짝 t-test (the matched pairs t-test), 반복측정 표본 t-test (the repeated-sample t-teset) 등의 이름으로도 알려져있습니다. 동일한 객체에 대해서 전과 후로 나누어서 반복 측정을 합니다.
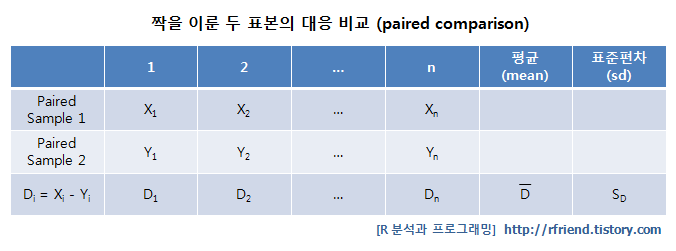
아래의 도표에는 짝을 이룬 두 표본의 대응 비교 데이터셋에 대한 모습입니다. (Xi, Yi) 가 동일한 대상에 대해서 before-after 로 반복 측정되어서, 각 동일 객체의 전-후의 차이 (즉, Di = Xi - Yi) 에 대해서 검정을 진행하게 됩니다.
paired t-test
[ 가정사항 (Assumptions) ]
(1) 측정 대상이 독립적(independent)이어야 합니다. 하나의 객체에 대한 측정은 어떤 다른 객체의 측정에 영향을 끼치지 않아야 합니다. (2) 각 짝을 이룬 측정치는 동일한 객체로 부터 얻어야 합니다. 예를 들면, 신약의 효과를 알아보기 위해 투약 전-후(before-after) 를 측정할 때 동일한 환자에 대해서 측정해야 합니다. (3) 짝을 이뤄 측정된 전-후의 차이 값은 정규분포를 따라야한다는 정규성(normality) 가정이 있습니다. 만약 정규성 가정을 충족시키지 못하면 비모수 검정(nonparametric test) 방법을 사용해야 합니다.
[ (예제) 신약 치료 효과 여부 검정 ]
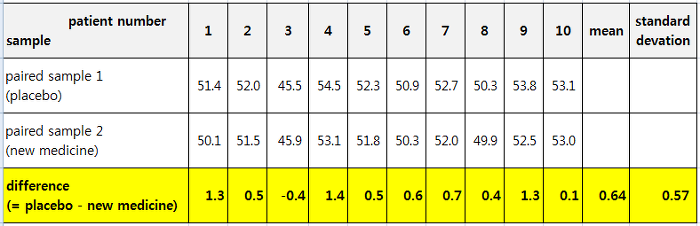
새로운 당뇨병 치료제를 개발한 제약사의 예를 계속 들자면, 치료에 지대한 영향을 주는 외부요인을 통제하기 위해 10명의 당뇨병 환자를 선별하여 1달 동안 '위약(placebo)'을 투여한 기간의 혈당 (Xi)과 동일 환자에게 '신약(new medicine)'을 투여한 1달 기간 동안의 혈당 수치(Yi)를 측정하여 짝을 이루어 혈당 차이를 유의수준 5%에서 비교하는 방법이 짝을 이룬 표본에 대한 검정이 되겠습니다. (palacebo 와 신약 투여 순서는 무작위로 선정. 아래 예는 그냥 예시로 아무 숫자나 입력해본 것임. 혈당 수치 이런거 전 잘 몰라요. ^^;)
scipy 모듈의 scipy.stats.ttest_rel 메소드를 사용해서 쌍을 이룬 t-test 를 실행합니다. "Calculate the t-test on TWO RELATED samples of scores, a and b." 라는 설명처럼 TWO RELATED samples 에서 rel 을 타서 메소드 이름을 지었습니다. (저라면 ttest_paired 라고 메소드 이름 지었을 듯요...)
alternative='two-sided' 가 디폴트 설정인데요, 이번 예제에서는 'H1: 신약이 효과가 있다. (즉, 신약 먹기 전보다 신약 먹은 후에 혈당이 떨어진다)' 는 가설을 검정하기 위한 것이므로 alternative='greater' 로 설정을 해주었습니다.
## -- Paired t-test
import numpy as np
from scipy import stats
## sample data-set (repeated measurements of Before vs. After for the same objects)
bef = np.array([51.4, 52.0, 45.5, 54.5, 52.3, 50.9, 52.7, 50.3, 53.8, 53.1])
aft = np.array([50.1, 51.5, 45.9, 53.1, 51.8, 50.3, 52.0, 49.9, 52.5, 53.0])
## paired t-test using Python scipy module
# H0: New medicine is not effective (i.e., no difference b/w before and after)
# H1: New medicine is effective (i.e., there is difference b/w before and after)
stat, p_val = stats.ttest_rel(bef, aft, alternative='greater')
print('statistic:', stat, ' p-value:', p_val)
# statistic: 3.550688262985491 p-value: 0.003104595950799298
분석 결과 p-value 가 0.003 으로서 유의수준 0.05 하에서 귀무가설 (H0: 신약은 효과가 없다. 즉, before와 after의 차이가 없다) 을 기각(reject)하고, 대립가설(H1: 신약은 효과가 있다. 즉, before 보다 after의 혈당 수치가 낮아졌다)을 채택(accept) 합니다.
모집단의 평균과 분산에 대해서는 알지 못하는 경우가 많으므로, 보통은 모집단에서 무작위로 표본을 추출(random sampling)해서 모집단의 평균과 분산을 추정합니다. 표본의 크기가 작은 집단 간 평균의 차이가 있는지를 검정할 때 t-분포에 기반한 t-통계량(t-statistics)을 사용하여 검정을 합니다.
t-검정은 대상 표본 집단이 1개인지 2개인지에 따라서 아래와 같이 구분할 수 있습니다.
* One-sample t-test : 모집단의 평균이 귀무가설의 특정 평균 값과 같은지를 검정
* Two-sample t-test: 두 모집단의 평균이 같다는 귀무가설을 검정
One-sample t-test와 Two-sample t-test에서 사용하는 통계량에 대해서는 아래에 정리해보았습니다.
여기서부터는 독립된 두 표본 간의 평균 차이에 대한 t-검정 (independent two-sample t-test) 에 대해서만 자세하게 소개하도록 하겠습니다.
t-test 를 통해 나온 p-value 가 유의수준보다 작으면 귀모가설을 기각하고 대립가설을 채택(즉, 두 모집단의 평균이 차이가 있다)하게 됩니다.
(2) Two-sample t-test 의 가정사항 (Assumptions)
Two-sample t-test 의 결과가 유효하기 위해서는 아래의 가정사항을 충족시켜야 합니다.
(a) 한 표본의 관측치는 다른 표본의 관측치와 독립이다. (independent)
(b) 데이터는 정규분포를 따른다. (normally distributed)
(c) 두 집단의 표본은 동일한 분산을 가진다. (the same variance).
(--> 이 가설을 만족하지 못하면 Welch's t-test 를 실행합니다.)
(d) 두 집단의 표본은 무작위 표본추출법을 사용합니다. (random sampling)
정규성 검정(normality test)을 위해서 Kolmogorov-Smirnov test, Shapiro-Wilk test, Anderson-Darling test 등을 사용합니다. 등분산성 검정(Equal-Variance test) 을 위해서 Bartlett test, Fligner test, Levene test 등을 사용합니다.
(3) Python을 이용한 Two-sample t-test 실행
(3-1) 샘플 데이터 생성
먼저 numpy 모듈을 사용해서 정규분포로 부터 각 관측치 30개를 가지는 표본을 3개 무작위 추출해보겠습니다. 이중 표본집단 2개는 평균과 분산이 동일한 정규분포로 부터 무작위 추출하였으며, 나머지 1개 집단은 평균이 다른 정규분포로 부터 무작위 추출하였습니다.
다음으로 집단 x1과 x2, 집단 x1과 x3에 대한 등분산 가정 검정 결과, p-value 가 모두 유의수준 0.05 보다 크므로 두 집단 간 분산이 같다고 할 수 있습니다. (귀무가설 H0: 두 집단 간 분산이 같다.)
## (2) Equal variance test using Bartlett's tes
var_test_stat_x1x2, var_test_p_val_x1x2 = stats.bartlett(x1, x2)
var_test_stat_x1x3, var_test_p_val_x1x3 = stats.bartlett(x1, x3)
print('[x1 vs. x2]', 'statistic:', var_test_stat_x1x2, ' p-value:', var_test_p_val_x1x2)
print('[x1 vs. x3]', 'statistic:', var_test_stat_x1x3, ' p-value:', var_test_p_val_x1x3)
# [x1 vs. x2] statistic: 0.4546474955289549 p-value: 0.5001361557169177
# [x1 vs. x3] statistic: 0.029962346601998174 p-value: 0.8625756934286083
처음에 샘플 데이터를 생성할 때 정규분포로 부터 분산을 동일하게 했었으므로 예상한 결과대로 잘 나왔네요.
(3-3) 독립된 두 표본에 대한 t-test 평균 동질성 여부 검정
이제 독립된 두 표본에 대해 t-test 를 실행해서 두 표본의 평균이 같은지 다른지 검정을 해보겠습니다.
- (귀무가설 H0) Mu1 = Mu2 (두 집단의 평균이 같다)
- (대립가설 H1) Mu1 ≠ Mu2 (두 집단의 평균이 다르다)
분산은 서로 같으므로 equal_var = True 라고 매개변수를 설정해주었습니다.
그리고 양측검정(two-sided test) 을 할 것이므로 alternative='two-sided' 를 설정(default)해주면 됩니다. (왜그런지 자꾸 에러가 나서 일단 코멘트 부호 # 로 막아놨어요. scipy 버전 문제인거 같은데요... 흠... 'two-sided'가 default 설정이므로 # 로 막아놔도 문제는 없습니다.)
## (3) Identification test using Independent 2 sample t-test
## x1 vs. x2
import scipy.stats as stats
t_stat, p_val = stats.ttest_ind(x1, x2,
#alternative='two-sided', #‘less’, ‘greater’
equal_var=True)
print('t-statistic:', t_stat, ' p-value:', p_val)
#t-statistic: -0.737991822907993 p-value: 0.46349499774375136
#==> equal mean
## x1 vs. x3
import scipy.stats as stats
t_stat, p_val = stats.ttest_ind(x1, x3,
#alternative='two-sided', #‘less’, ‘greater’
equal_var=True)
print('t-statistic:', t_stat, ' p-value:', p_val)
#t-statistic: -15.34800563666855 p-value: 4.370531118607397e-22
#==> different mean
(3-1)에서 샘플 데이터를 만들 때 x1, x2 는 동일한 평균과 분산의 정규분포에서 무작위 추출을 하였으며, x3만 평균이 다른 정규분포에서 무작위 추출을 하였습니다.
위의 (3-3) t-test 결과를 보면 x1, x2 간 t-test 에서는 p-value 가 0.46으로서 유의수준 0.05 하에서 귀무가설(H0)을 채택하여 두 집단 x1, x2 의 평균은 같다고 판단할 수 있습니다.
x1, x3 집단 간 t-test 결과를 보면 p-value 가 4.37e-22 로서 유의수준 0.05 하에서 귀무가설(H0)을 기각(reject)하고 대립가설(H1)을 채택(accept)하여 x1, x3 의 평균이 다르다고 판단할 수 있습니다.
이번 포스팅에서는 manifold learning approche 에 해당하는 비지도학습, 비선형 차원축소 방법으로서 LLE (Locally Linear Embedding) 알고리즘을 설명하겠습니다.
(1) 매니폴드 학습 (Manifold Learning)
(2) Locally Linear Embedding (LLE) 알고리즘
(3) sklearn 을 사용한 LLE 실습
(1) 매니폴드 학습 (Maniflod Learning)
먼저 매니폴드 학습(Manifold Learning)에 대해서 간략하게 살펴보고 넘어가겠습니다.
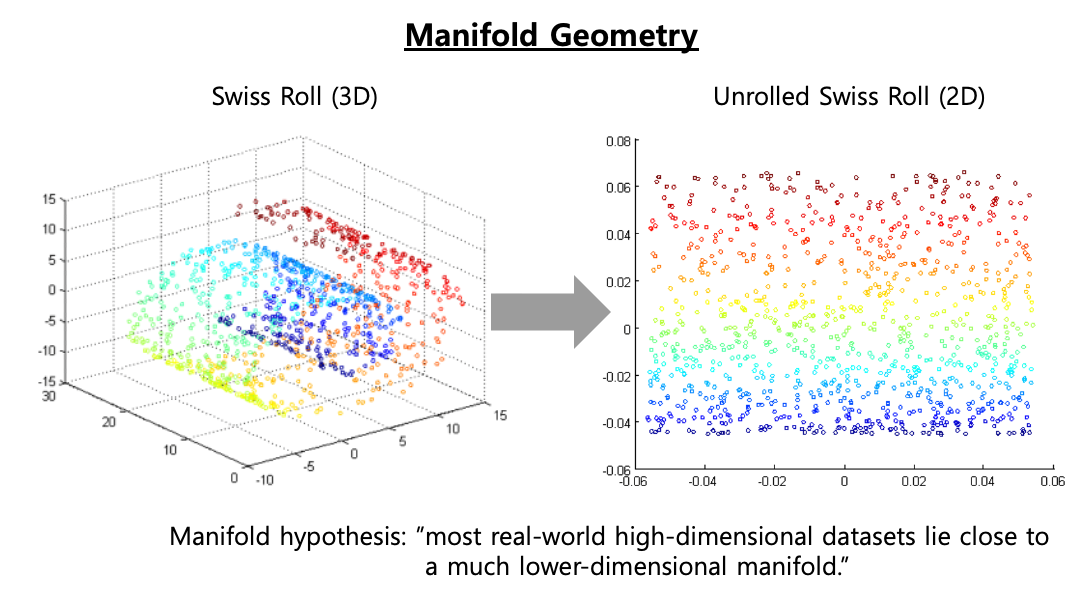
매니폴드란 각 점 근처의 유클리드 공간과 국부적으로 유사한 위상 공간을 말합니다. (A manifold is a topological space that locally resembles Eucludian space near each point.) [1] d-차원의 매니폴드는 n-차원 공간 (이때 d < n) 의 부분으로서 d-차원의 초평면(d-dimensional hyperplane)을 국부적으로 닮았습니다. 아래의 3차원 공간의 Swiss Roll 에서 데이터의 구성 특성과 속성을 잘 간직한 2차원의 평면(plane)을 생각해볼 수 있는데요, Swiss Roll 을 마치 돌돌 말린 종이(매니폴드)를 펼쳐서 2차원 공간으로 표현해본 것이 오른쪽 그림입니다.
manifold geometry: unroll the swiss roll
매니폴드 학습(Manifold Learning)이란 데이터에 존재하는 매니폴드를 모델링하여 차원을 축소하는 기법을 말합니다. 매니폴드 학습은 대부분 실세계의 고차원 데이터가 훨씬 저차원의 매니폴드에 가깝게 놓여있다는 매니폴드 가정(Manifold Assumption) 혹은 매니폴드 가설(Maniflod Hypothesis)에 기반하고 있습니다. [2]
위의 비선형인 3차원 Swiss Roll 데이터를 선형 투영 기반의 주성분 분석(PCA, Principal Component Analysis)이나 다차원척도법(MDS, Multi-Dimensional Scaling) 로 2차원으로 차원을 축소하려고 하면 데이터 내 존재하는 매너폴드를 학습하지 못하고 데이터가 뭉개지고 겹쳐지게 됩니다.
매니폴드 가설은 분류나 회귀모형과 같은 지도학습을 할 때 고차원의 데이터를 저차원의 매니폴드 공간으로 재표현했을 때 더 간단하고 성과가 좋을 것이라는 묵시적인 또 다른 가설과 종종 같이 가기도 합니다. 하지만 이는 항상 그런 것은 아니며, 데이터셋이 어떻게 구성되어 있느냐에 전적으로 의존합니다.
(2) Locally Linear Embedding (LLE) 알고리즘
LLE 알고리즘은 "Nonlinear Dimensionality Reduction by Locally Linear Embedding (2000)" [3] 논문에서 주요 내용을 간추려서 소개하겠습니다.
LLE 알고리즘은 주성분분석이나(PCA) 다차원척도법(MDS)와는 달리 광범위하게 흩어져있는 데이터 점들 간의 쌍을 이룬 거리를 추정할 필요가 없습니다. LLE는 국소적인 선형 적합으로 부터 전역적인 비선형 구조를 복원합니다 (LLE revocers global nonlinear structure from locally linear fits.).
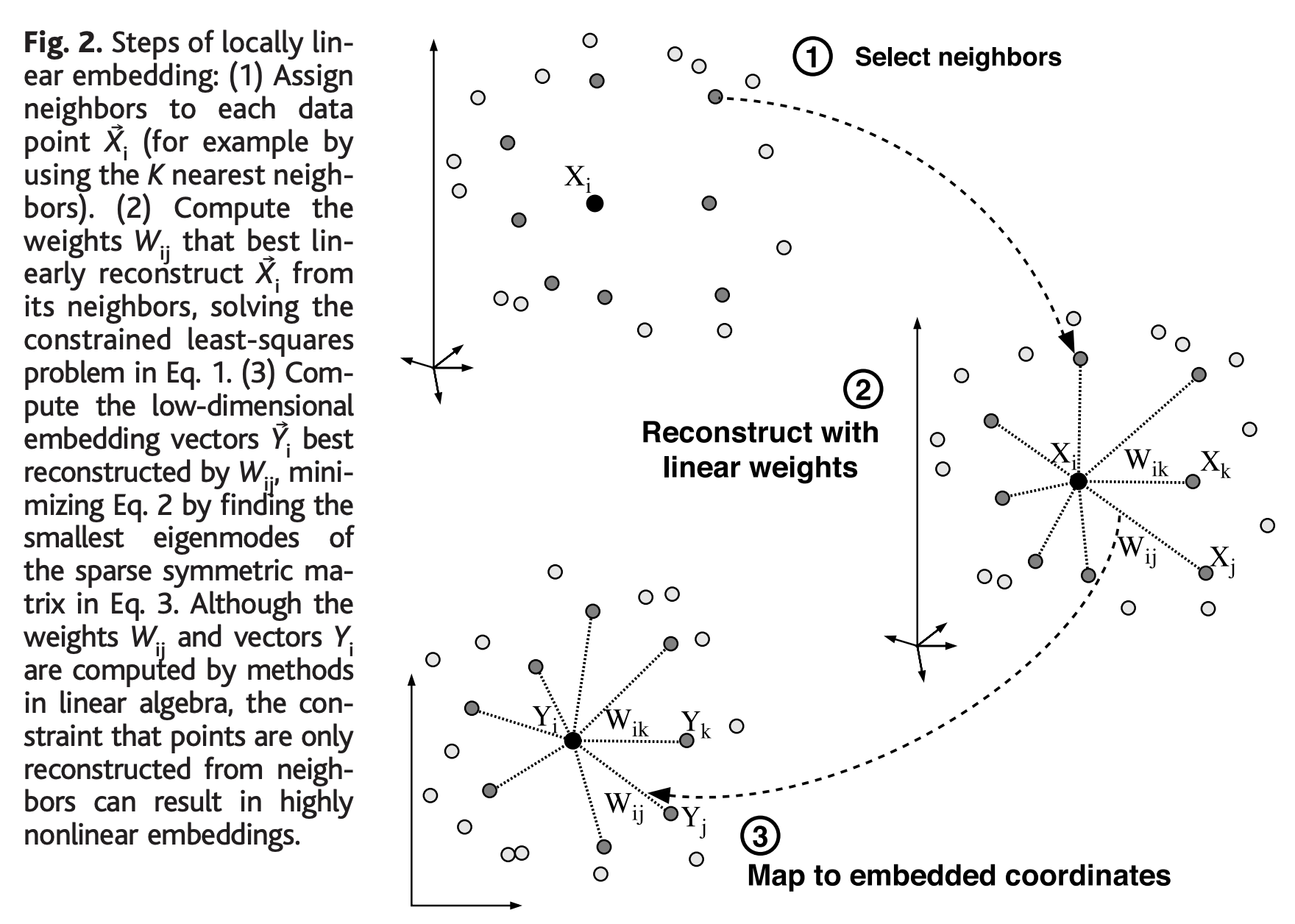
논문에서 소개한 LLE 3단계 절차(steps of locally linear embedding)는 꽤 간단합니다.
(1단계) 각 데이터 점의 이웃을 선택 (Select neighbors)
(2단계) 이웃으로부터 선형적으로 가장 잘 재구성하는 가중치를 계산 (Reconstruct with linear weights)
(3단계) 가중치를 사용해 저차원의 임베딩 좌표로 매핑 (Map to embedded coordinates)
Steps of locally linear embedding (source: Sam T. Roweis and Lawrence K. Saul)
1단계에서 각 데이터 점별로 이웃을 할당할 때는 데이터 점들 간의 거리를 계산하는데요, 가령 K 최근접이웃(K nearest neighbors) 기법을 사용할 수 있습니다.
2단계에서 각 데이터 점들의 이웃들로부터 각 점을 가장 잘 재구성하는 선형 회귀계수(linear coefficients, linear weights)를 계산해서 국소적인 기하 특성을 간직한 매너폴드를 학습합니다. 아래는 재구성 에러를 측정하는 비용함수인데요, 원래의 데이터점과 이웃들로 부터 계산한 선형 모형으로 재구성한 값과의 거리를 제곱하여 모두 더한 값입니다.
the cost function of reconstruction
위의 비용함수를 최소로 하는 가중치 벡터 Wij 를 계산하게 되는데요, 이때 2가지 제약조건(constraints)이 있습니다.
- (a) 각 데이터 점은 단지 그들의 이웃들로 부터만 재구성됩니다.
(만약 Xj 가 Xi의 이웃에 속하지 않는 데이터점이면 가중치 Wij = 0 이 됩니다.)
- (b) 가중치 행렬 행의 합은 1이 됩니다. (sum(Wij) = 1)
위의 2가지 제약조건을 만족하면서 비용함수를 최소로 하는 가중치 Wij 를 구하면 특정 데이터 점에 대해 회전(rotations), 스케일 조정(recalings), 그리고 해당 데이터 점과 인접한 데이터 점의 변환(translations) 에 있어 대칭(symmetry)을 따릅니다. 이 대칭에 의해서 (특정 참조 틀에 의존하는 방법과는 달리) LLE의 재구성 가중치는 각 이웃 데이터들에 내재하는 고유한 기하학적 특성(저차원의 매너폴드)을 모델링할 수 있게됩니다.
3단계에서는 고차원(D) 벡터의 각 데이터 점 Xi 를 위의 2단계에서 계산한 가중치를 사용하여 매니폴드 위에 전역적인 내부 좌표를 표현하는 저차원(d) 벡터 Yi 로 매핑합니다. 이것은 아래의 임베팅 비용 함수를 최소로 하는 저차원 좌표 Yi (d-mimensional coordinates) 를 선택하는 것으로 수행됩니다.
the cost function of embedding
임베팅 비용 함수는 이전의 선형 가중치 비용함수와 마찬가지로 국소 선형 재구성 오차를 기반으로 합니다. 하지만 여기서 우리는 Yi 좌표를 최적화하는 동안 선형 가중치 Wij 를 고정합니다. 임베팅 비용 함수는 희소 N x N 고유값 문제(a sparse N X N eignevalue problem)를 풀어서 최소화할 수 있습니다. 이 선형대수 문제를 풀면 하단의 d차원의 0이 아닌 고객벡터는 원점을 중심으로 정렬된 직교 좌표 집합을 제공합니다.
LLE 알고리즘은 희소 행렬 알고리듬(sparse matrix algorithms)을 활용하기 위해 구현될 때 비선형 차원축소 기법 중 하나인 Isomap 보다 더 빠른 최적화와 많은 문제에 대해 더 나은 결과를 얻을 수 있는 몇 가지 장점이 있습니다. [4]
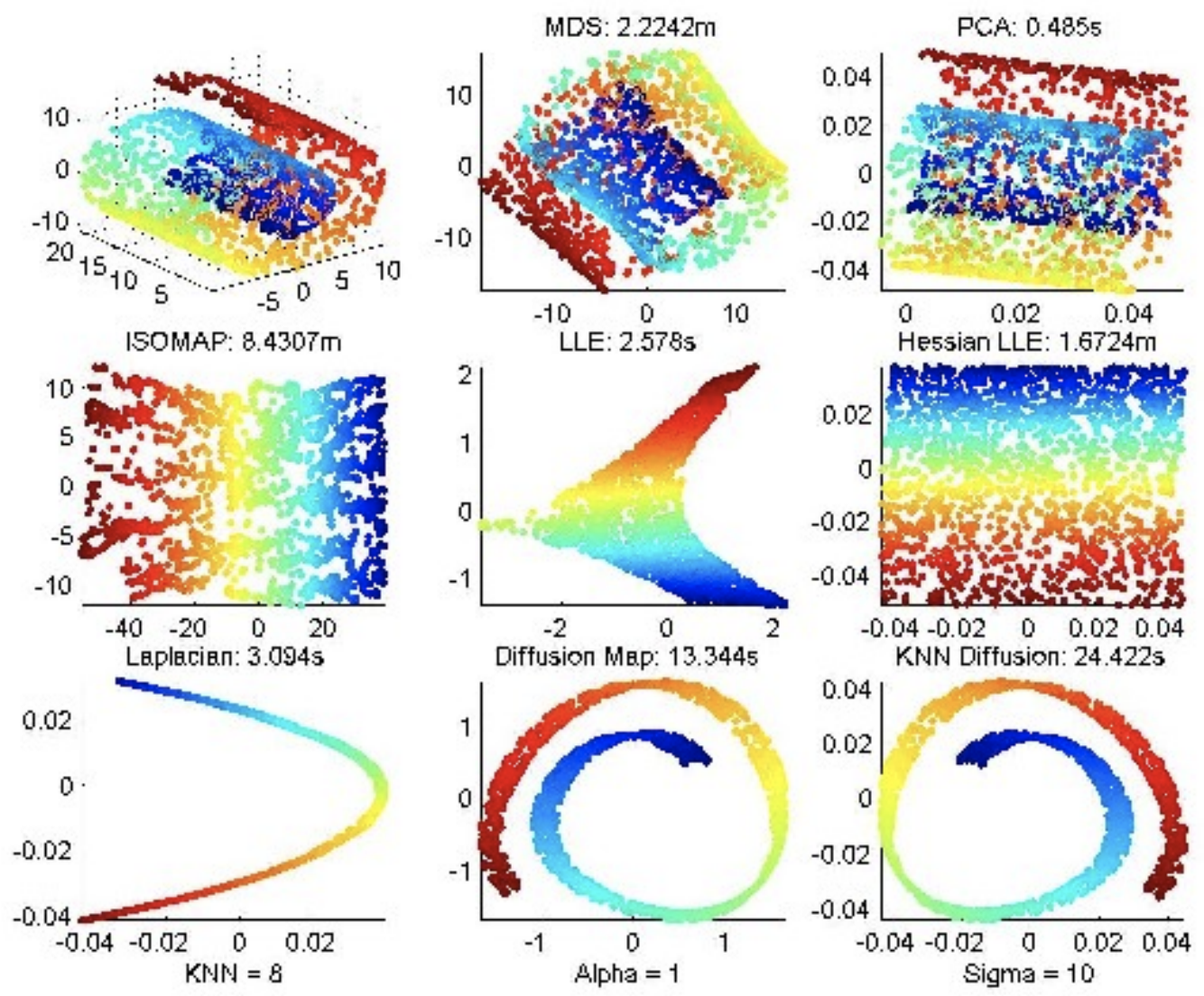
아래에 3차원 Swiss Roll 데이터를 여러가지 비선형 차원 축소 기법을 사용해서 적용한 결과인데요 [5], LLE 는 수행 시간이 짧은 장점이 있지만 매니폴드가 약간 찌그러져 있는 한계가 있는 반면에, Isomap과 Hessian LLE 는 국지적인 데이터 형상과 관계를 잘 재표현한 저차원 매니폴드를 잘 잡아내지만 수행 시간이 LLE 대비 굉장히 오래걸리는 단점이 있습니다.
(3) sklearn 을 사용한 LLE 실습
먼저 sklearn 모듈의 make_swiss_roll 메소드를 사용해서 데이터 점 1,000개를 가지는 3차원의 Swiss Roll 샘플 데이터셋을 만들어보겠습니다. X 는 데이터 점이고, t는 매니폴드 내 점의 주 차원에 따른 샘플의 단변량 위치입니다.
## Swiss Roll sample dataset
## ref: https://scikit-learn.org/stable/modules/generated/sklearn.datasets.make_swiss_roll.html
from sklearn.datasets import make_swiss_roll
X, t = make_swiss_roll(n_samples=1000, noise=0.1, random_state=1004)
## X: The points.
X[:5]
# array([[ 1.8743272 , 18.2196214 , -4.75535504],
# [12.43382272, 13.9545544 , 2.91609936],
# [ 8.02375359, 14.23271056, -8.67338106],
# [12.23095692, 2.37167446, 3.64973091],
# [-8.44058318, 15.47560926, -5.46533069]])
## t: The univariate position of the sample according to the main dimension of the points in the manifold.
t[:10]
# array([ 5.07949952, 12.78467229, 11.74798863, 12.85471755, 9.99011767,
# 5.47092408, 6.89550966, 6.99567358, 10.51333994, 10.43425738])
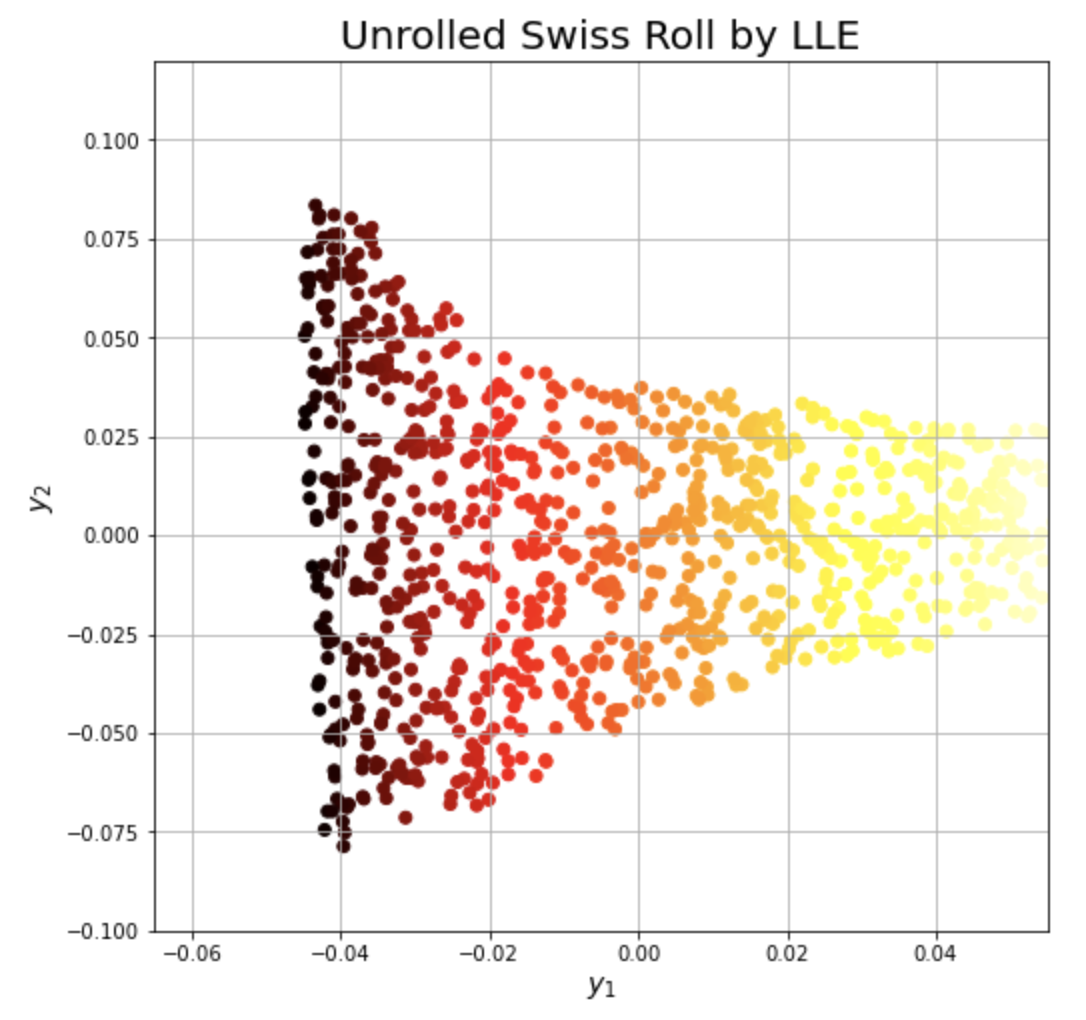
다음으로 sklearn 모듈에 있는 LocallyLinearEmbedding 메소드를 사용해서 위에서 생성한 Swiss Roll 데이터에 대해 LLE 알고리즘을 적용하여 2차원 데이터로 변환을 해보겠습니다.
지난 포스팅에서는 차원 축소란 무엇이고 왜 하는지, 무슨 방법이 있는지에 대해서 알아보았습니다.
(https://rfriend.tistory.com/736) 차원축소하는 방법에는 크게 Projection-based dimensionality reduction, Manifold Learning 의 두가지 방법이 있다고 했습니다.
이번 포스팅에서는 투사를 통한 차원축소 방법(dimensionality reduction via projection approach) 으로서 주성분분석을 통한 차원축소(dimensionality reduction using PCA, Principal Component Analysis)에 대해서 소개하겠습니다.
(1) 주성분분석(PCA, Principal Component Analysis)을 통한 차원 축소
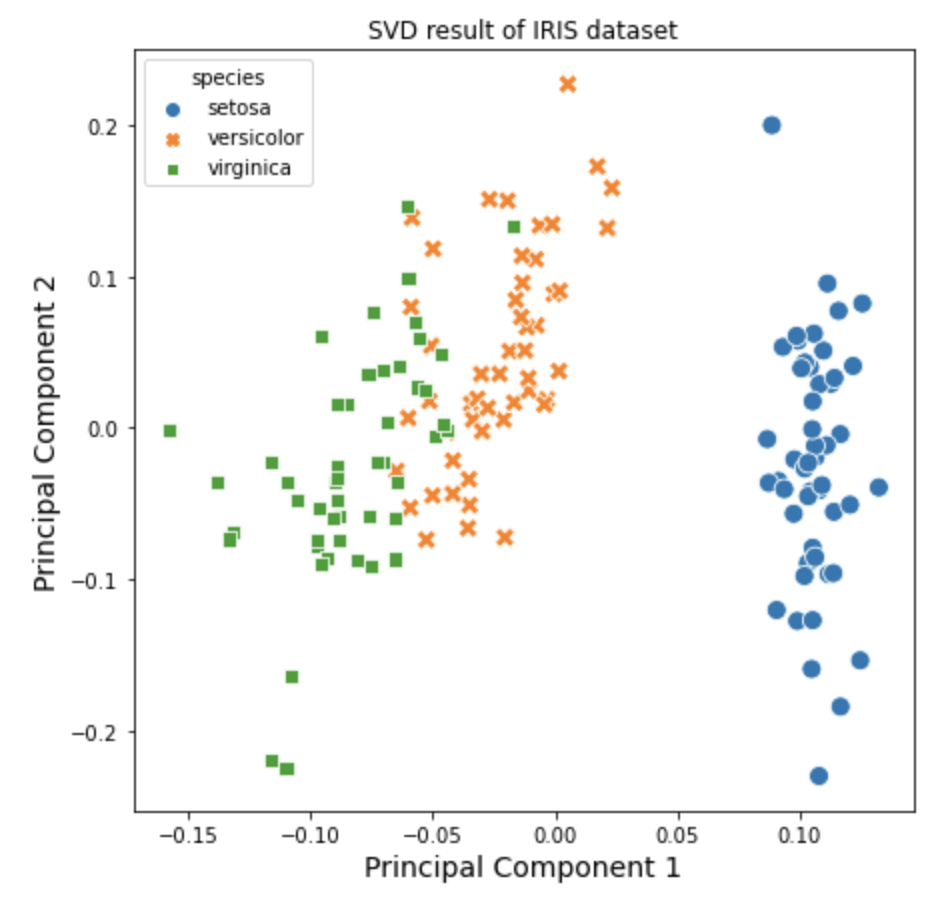
(2) 특이값 분해 (SVD, Singular Value Decomposition)을 통한 차원 축소
(1) 주성분 분석(PCA, Principal Component Analysis)을 통한 차원 축소
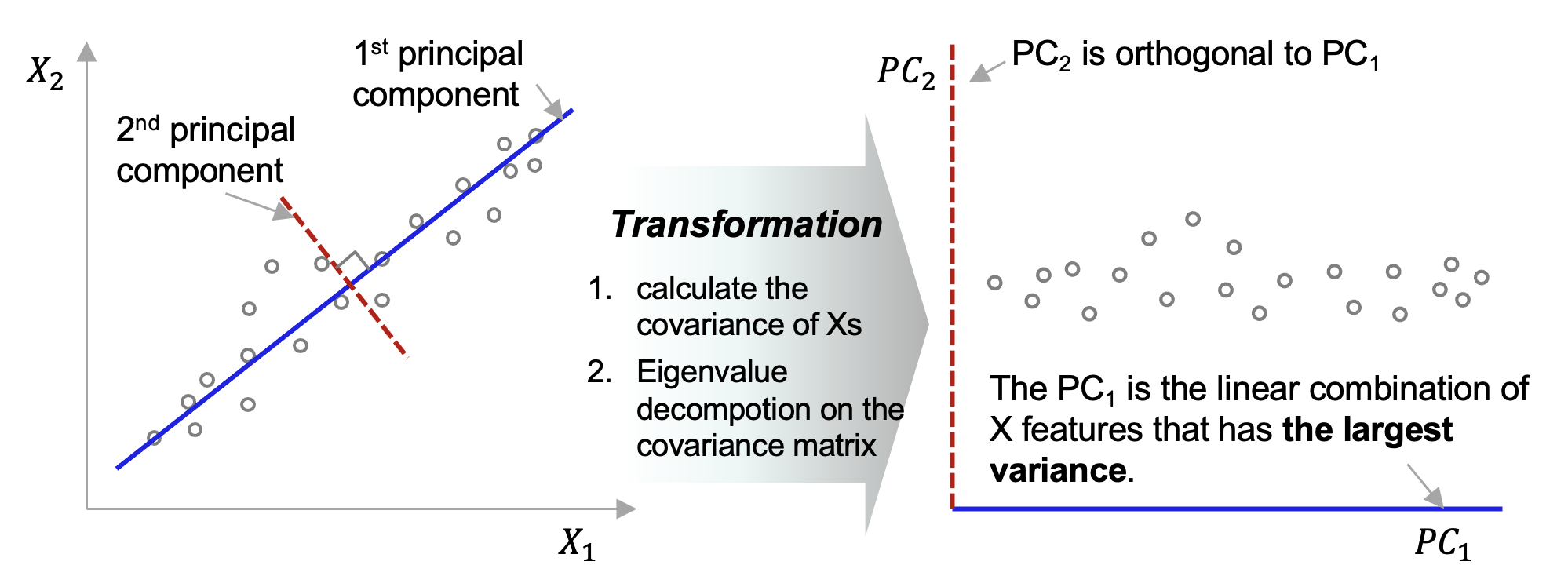
주성분 분석(PCA)의 핵심 아이디어만 간략하게 소개하자면요, 피쳐 공간(Feature Space)에서 데이터의 분산을 최대로 잡아낼 수 있는 축을 제1 주성분 축으로 잡고, 이 제1 주성분 축과 직교(orthogonal)하는 축을 제2 주성분 축으로 잡고, ..., 이렇게 최대 변수의 개수 p 개 만큼 주성분 축을 잡아줍니다. (물론, 차원축소를 하는 목적이면 주성분 개수 m 이 변수 개수 p 보다는 작아야 겠지요). 그리고 축을 회전시켜주면 돼요.
아래의 예시 도면을 보면 파란색 제 1 주성분 축 (1st principal component axis)이 데이터 분산을 가장 많이 설명하고 있는 것을 알 수 있습니다. 빨간색 점선의 제 2 주성분 축(2nd principal component axis) 은 제1 주성분 축과 직교하구요.
먼저 예제로 사용할 iris 데이터셋을 가져오겠습니다. sepal_length, sepal_width, petal_length, petal_width 의 4개 변수를 가진 데이터셋인데요, 4개 변수 간 상관관계 분석을 해보니 상관계수가 0.8 이상으로 꽤 높게 나온 게 있네요. 주성분분석으로 차원축소 해보면 이쁘게 나올거 같아요.
주성분 분석은 비지도 학습 (Unsupervised Learning) 이다보니 정답이라는게 없습니다. 그래서 분석가가 주성분의 개수를 지정해주어야 하는데요, 주성분의 개수가 적을 수록 차원 축소가 많이 되는 반면 정보 손실(information loss)가 발생하게 되며, 반면 주성분 개수가 많을 수록 정보 손실은 적겠지만 차원 축소하는 의미가 퇴색됩니다. 그래서 적절한 주성분 개수를 선택(hot to decide the number of principal components)하는게 중요한데요, 주성분의 개수별로 설명 가능한 분산의 비율 (percentage of explained variance by principal components) 을 많이 사용합니다.
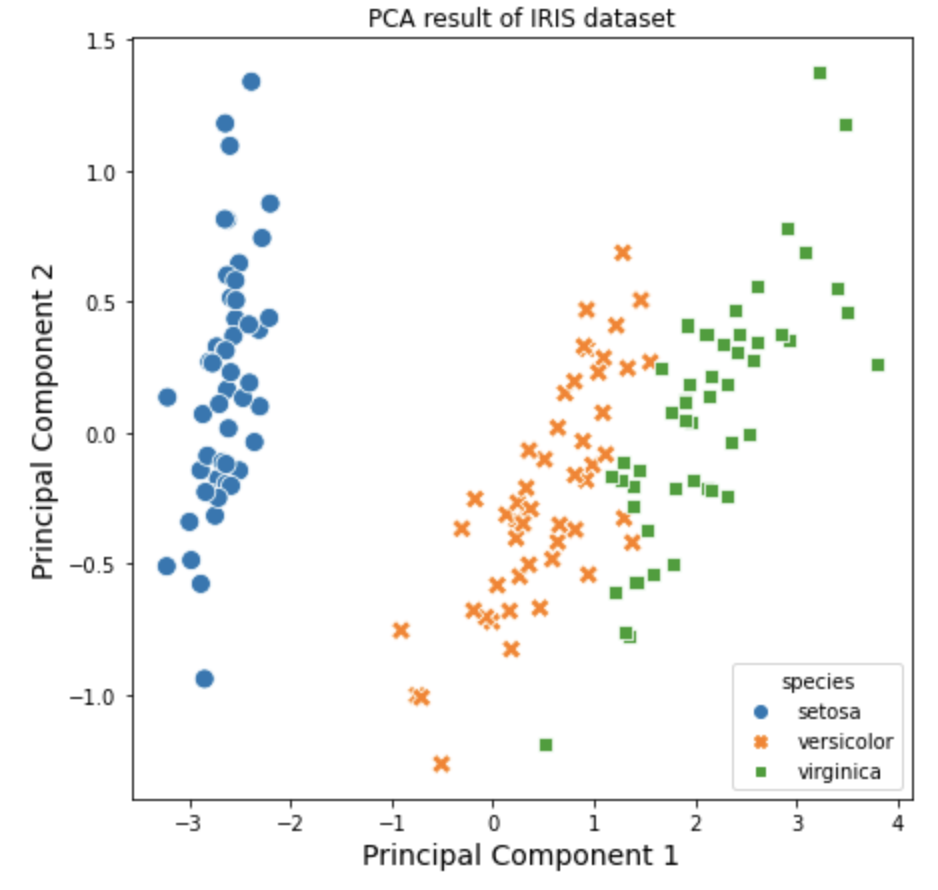
아래의 예에서는 첫번째 주성분이 분산의 92.4%를 설명하고, 두번째 주성분이 분산의 5.3%를 설명하므로, 주성분 1 & 2 까지 사용하면 전체 분산의 97.7%를 설명할 수 있게 됩니다. (즉, 원래 4개 변수를 2개의 차원으로 축소하더라도 분산의 97.7%를 설명 가능하다는 뜻)
참고로, 만약 주성분분석 결과를 지도학습(가령, 회귀분석)의 설명변수 인풋으로 사용한다면, cross validation을 사용해서 주성분 개수별로 모델의 성능을 평가(가령, 회귀분석의 경우 MSE)해서, 모델 성능지표가 가장 좋은 주성분 개수를 선택하는 것도 좋은 방법입니다.
## how to decide the number of Principal Components
from sklearn.decomposition import PCA
pca = PCA(random_state=1004)
pca.fit_transform(iris_df)
## percentage of variance explained
print(pca.explained_variance_ratio_)
# [0.92461872 0.05306648 0.01710261 0.00521218]
## Principal 1 & 2 explain about 97.8% of variance
plt.rcParams['figure.figsize'] = (7, 7)
plt.plot(range(1, iris_df.shape[1]+1), pca.explained_variance_ratio_)
plt.xlabel("number of Principal Components", fontsize=12)
plt.ylabel("% of Variance Explained", fontsize=12)
plt.show()
Explained Variance by Principal Components
이제 주성분 개수를 2개로 지정(n_components=2)해서 주성분 분석을 실행해보겠습니다. Python의 sklearn 모듈의 decomposition.PCA 메소드를 사용하겠습니다.
위에서 실행한 주성분분석 결과를 가지고 시각화를 해보겠습니다. 4개 변수를 2개의 차원으로 축소를 했기 때문에 2차원의 산점도로 시각화를 할 수 있습니다. 이때 iris 데이터셋의 target 속성정보를 이용해서 붓꽃의 품종별로 색깔과 모양을 달리해서 산점도로 시각화해보겠습니다.
Database에서 가상의 샘플 데이터를 만들어서 SQL이 버그없이 잘 작동하는지 확인을 한다든지, DB의 성능을 테스트 해봐야 할 때가 있습니다.
이번 포스팅에서는 PostgreSQL, Greenplum DB를 사용해서 정규분포(Normal Distribution)로부터 난수 (random number)를 생성하여 샘플 테이블을 만들어보겠습니다.
(1) 테이블 생성 : create table
(2) 정규분포로 부터 난수 생성하는 사용자 정의 함수 정의 : random_normal(count, mean, stddev)
(3) 테이블에 정규분포로 부터 생성한 난수 추가하기 : generate_series(), to_char(), insert into
(4) Instance 별 데이터 개수 확인하기 : count() group by gp_segment_id
creating a sample table using random numbers in PostgreSQL, Greenplum
아래 SQL 예제 코드는 PostgreSQL 9.4.26 버전, Greenplum 6.19.2 버전에서, Greenplum Database 의 분산 저장, 분산병렬처리 고려해서 작성하였습니다.
-- version check
SELECT version();
-- PostgreSQL 9.4.26 (Greenplum Database 6.19.2 build commit:0e1f6307eb4e368b79cbf67a0dc6af53362d26c0) on x86_64-unknown-linux-gnu, compiled by gcc (GCC) 6.4.0, 64-bit compiled on Feb 14 2022 23:03:52
(1) 테이블 생성 : create table
CREATE TABLE 함수를 사용해서 분석의 대상 기준으로 사용할 문자열의 cell_id, param_id 와 숫자형의 측정값 meas_val 을 가지는 빈 껍데기 samp_tbl 테이블을 만들어보겠습니다. WITH 절에 압축 옵션을 설정하였으며, DISTRIBUTED BY (cell_id) 로 분산 저장하는 기준을 설정해주었습니다.
분산키를 잘 잡아주는 것이 향후 분산병렬처리의 성능을 좌지우지 합니다. 분석이나 데이터 처리(조인 등) 기준이 되고, 한쪽 노드로 쏠리지 않고 골고루 분산시킬 수 있는 분산키를 설정해주어야 합니다.
-- creating a sample table
DROP TABLE IF EXISTS samp_tbl;
CREATE TABLE samp_tbl (
cell_id varchar(10)
, param_id varchar(2)
, meas_val numeric
) WITH(appendonly=TRUE, compresslevel=7, compresstype=zstd)
DISTRIBUTED BY (cell_id);
(2) 정규분포로 부터 난수 생성하는 사용자 정의 함수 정의 : random_normal(count, mean, stddev)
PostgreSQL 버전 10 이상부터 정규분포(normal distribution)로 부터 난수를 생성(generating random numbers) 하는 함수 normal_rand() 를 쓸 수 있습니다.
-- over PostgreSQL version 10
-- Produces a set of normally distributed random values.
normal_rand ( numvals integer, mean float8, stddev float8 ) → setof float8
PostgreSQL 9.6 이전 버전에서는PL/Python, PL/R, PL/SQL 로 정규분포로 부터 난수를 생성하는 사용자 정의함수를 정의해서 사용해야 합니다. (아래는 PL/SQL 이구요, PL/Python이나 PL/R 로도 가능해요)
-- UDF of random number generator from a normal distribution, X~N(mean, stddev)
-- random_normal() built-in function over PostgreSQL version 10.x
DROP FUNCTION IF EXISTS random_normal(INTEGER, DOUBLE PRECISION, DOUBLE PRECISION);
CREATE OR REPLACE FUNCTION random_normal(
count INTEGER DEFAULT 1,
mean DOUBLE PRECISION DEFAULT 0.0,
stddev DOUBLE PRECISION DEFAULT 1.0
) RETURNS SETOF DOUBLE PRECISION
RETURNS NULL ON NULL INPUT AS $$
DECLARE
u DOUBLE PRECISION;
v DOUBLE PRECISION;
s DOUBLE PRECISION;
BEGIN
WHILE count > 0 LOOP
u = RANDOM() * 2 - 1; -- range: -1.0 <= u < 1.0
v = RANDOM() * 2 - 1; -- range: -1.0 <= v < 1.0
s = u^2 + v^2;
IF s != 0.0 AND s < 1.0 THEN
s = SQRT(-2 * LN(s) / s);
RETURN NEXT mean + stddev * s * u;
count = count - 1;
IF count > 0 THEN
RETURN NEXT mean + stddev * s * v;
count = count - 1;
END IF;
END IF;
END LOOP;
END;
$$ LANGUAGE plpgsql;
-- credit: https://bugfactory.io/blog/generating-random-numbers-according-to-a-continuous-probability-distribution-with-postgresql/
(3) 테이블에 정규분포로 부터 생성한 난수 추가하기 : generate_series(), to_char(), insert into
이제 위의 (1)번에서 생성한 samp_tbl 테이블에 insert into 구문을 사용해서 가상의 샘플 데이터 추가해보겠습니다. 이때 From 절에서 generate_series(from, to) 함수를 사용해서 정수의 수열을 생성해주고, SELECT 절의 TO_CHAR(a, '0000000000'), TO_CHAR(b, '00') 에서 generate_series()에서 생성한 정수를자리수가 10자리, 2자리인 문자열로 바꾸어줍니다. (빈 자리는 '0'으로 자리수만큼 채워줍니다.) TRIP() 함수는 화이트 스페이스를 제거해줍니다.
-- inserting data
-- cell_id 1,000 * param_id 4 * meas_val 25 = 100,000 rows in total
-- good cases 99,999,000 vs. bad cases 1,000 (cell_id 10 * param_id 4 * meas_val 25 = 1,000 rows)
-- cell_id '000000001' will be used as a control group (good case) later.
-- it took 8 min. 4 sec.
TRUNCATE TABLE samp_tbl;
INSERT INTO samp_tbl
SELECT
trim(to_char(a, '0000000000')) AS cell_id
, trim(to_char(b, '00')) AS param_id
, random_normal(25, 0, 1) AS meas_val -- X~N(0, 1), from Normal distribution
FROM generate_series(1, 1000) AS a -- cell_id
, generate_series(1, 4) AS b -- param_id
;
(4) Instance 별 데이터 개수 확인하기 : count() group by gp_segment_id
위의 (1)~(3)번에서 테이블을 만들고, 가짜 데이터를 정규분포로 부터 난수를 발생시켜서 테이블에 추가를 하였으니, Greenplum의 각 nodes 에 골고루 잘 분산이 되었는지 확인을 해보겠습니다. (아래는 AWS에서 2개 노드, 노드별 6개 instance, 총 12개 instances 환경에서 테스트한 것임)
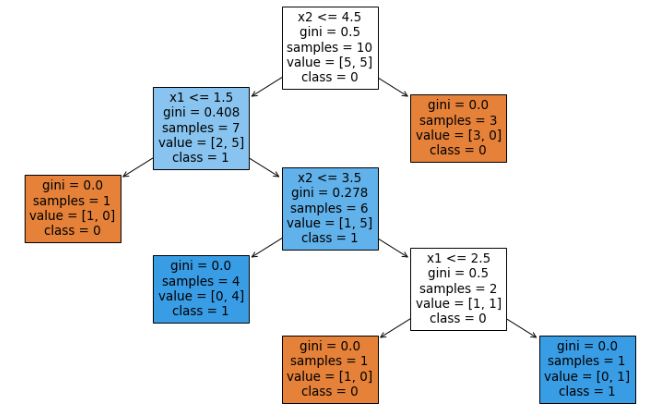
(0) sklearn.tree 메소드를 이용해서 의사결정나무(Decision Tree) 모델 훈련하기
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
from sklearn import tree
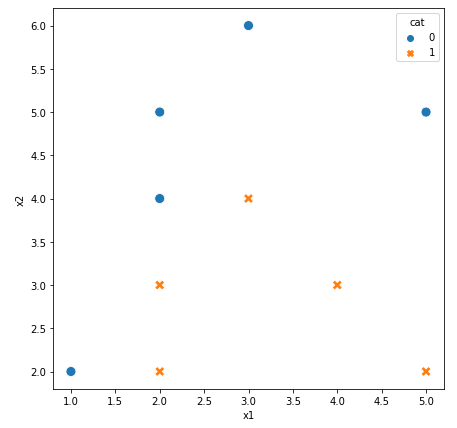
## getting X, y values
X = df[['x1', 'x2']]
y = df['cat']
## initiating DecisionTreeClassifer method
dt_clf = DecisionTreeClassifier(random_state = 1004)
## fitting a decision tree classifier
dt_clf_model = dt_clf.fit(X, y)
## feature importances
dt_clf_model.feature_importances_
#array([0.43809524, 0.56190476])
(1) sklearn.tree.export_text 메소드를 이용해서 의사결정나무를 텍스트로 인쇄하기 (text representation)
의사결정나무 모델을 적합한 후에 사용자 인터페이스가 없는 애플리케이션에서 로그(log) 텍스트로 모델 적합 결과를 확인할 때 사용할 수 있습니다. 또는 의사결정나무의 적합된 룰을 SQL 로 구현하여 운영 모드로 적용하고자 할 때 아래처럼 텍스트로 인쇄를 하면 유용하게 사용할 수 있습니다.
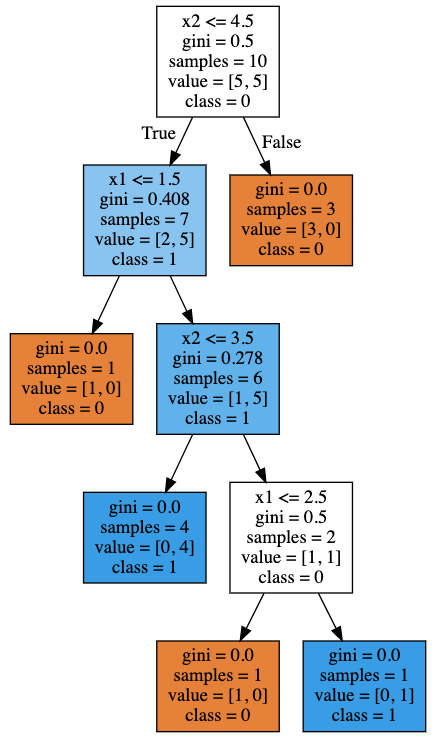
## Visualizing Tree using Graphviz
from sklearn import tree
import graphviz
## exporting tree in DOT format
## refer to: https://scikit-learn.org/stable/modules/generated/sklearn.tree.export_graphviz.html
tree_dot = tree.export_graphviz(
dt_clf_model,
feature_names=['x1', 'x2'],
class_names=['0', '1'],
filled=True
)
## draw graph using Graphviz
dt_graph = graphviz.Source(tree_dot, format='png')
dt_graph
텍스트 데이터 전처리를 하는데는 (a) Python의 텍스트 처리 내장 메소드 (Python built-in methods)와 (b) 정규 표현식 매칭 연산(regular expression matching operations)을 제공하는 Python re 패키지를 사용하겠습니다. re 패키지는 Python을 설치할 때 디폴트로 같이 설치가 되므로 별도로 설치할 필요는 없습니다.
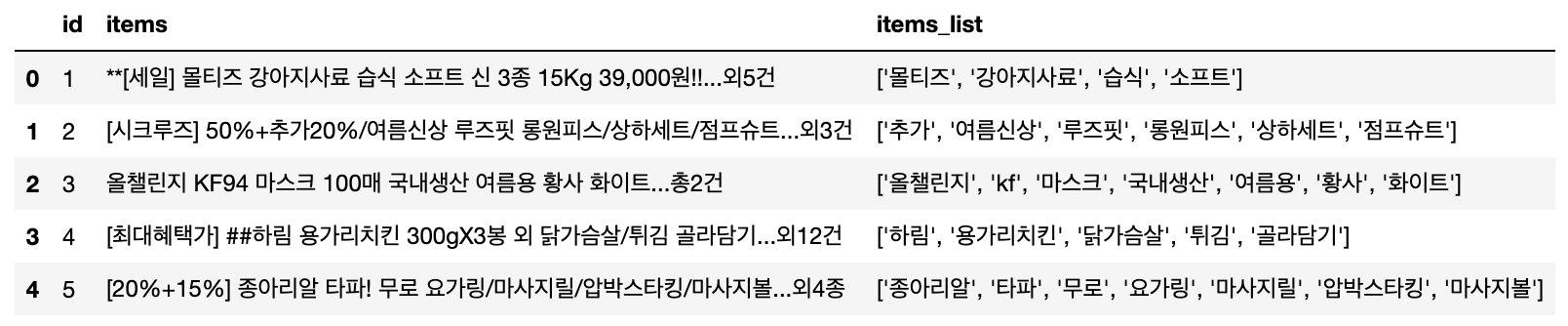
예제로 사용할 Input 텍스트는 인터넷쇼핑몰의 고객별 거래내역에 있는 구매 품목 텍스트 데이터이며, Output 은 텍스트 전처리 후의 고객별 구매 품목의 리스트입니다.
(1-7) 텍스트 데이터 전처리 사용자 정의함수(User Defined Function) 정의
(1-8) pandas DataFrame의 텍스트 칼럼에 데이터 전처리 사용자 정의함수 적용
(1-1) [], (), {}, <> 괄호와 괄호 안 문자 제거하기
Python의 정규 표현식(regular expression)을 다루는 re 패키지를 사용해서 다양한 형태의 괄호와 괄호안의 문자를 매칭한 후에 '' 로 대체함으로써 결과적으로 제거하였습니다. re.sub() 는 pattern 과 매치되는 문자열을 repl 의 문자열로 대체를 시켜줍니다.
정규표현식에서 문자 클래스를 만드는 메타 문자인 [ ]로 만들어지는 정규표현식은 [ ]사이에 들어가는 문자 중 어느 한개라도 매치가 되면 매치를 시켜줍니다. 가령, [abc] 의 경우 'a', 'b', 'c' 중에서 어느 하나의 문자라도 매치가 되면 매치가 되는 것으로 간주합니다.
## Python Regular expression operations
import re
## sample text
s = '**[세일]** 말티즈 강아지사료 습식 소프트 신 3종 15Kg 39,000원!!...외5건'
## (1-1) [], (), {}, <> 괄호와 괄호 안 문자 제거하기
pattern = r'\([^)]*\)' # ()
s = re.sub(pattern=pattern, repl='', string=s)
pattern = r'\[[^)]*\]' # []
s = re.sub(pattern=pattern, repl='', string=s)
pattern = r'\<[^)]*\>' # <>
s = re.sub(pattern=pattern, repl='', string=s)
pattern = r'\{[^)]*\}' # {}
s = re.sub(pattern=pattern, repl='', string=s)
print(s)
[Out]
# **** 말티즈 강아지사료 습식 소프트 신 3종 15Kg 39,000원!!...외5건
(1-2) '...외', '...총' 제거하기
Python의 내장 문자열 메소드인 replace() 를 사용해서 '...외', '...총' 을 ' ' 로 대체함으로써 제거하였습니다.
## (1-2) '...외', '...총' 제거하기
s = s.replace('...외', ' ')
s = s.replace('...총', ' ')
print(s)
[Out]
# **** 말티즈 강아지사료 습식 소프트 신 3종 15Kg 39,000원!! 5건
(1-3) 특수문자, 숫자 제거
정규표현식에서 하이픈(-)은 from ~ to 의 범위를 나타냅니다. [a-zA-Z] 는 소문자와 대문자 영어 모두를 의미하며, [가-힣] 은 한글 전체를 의미합니다.
정규표현식에서 [^] 는 not 의 의미이며, 아래의 [^a-zA-Z가-힣] 은 앞에 '^' 가 붙었으므로 영어와 한글이 아닌(not, ^) 문자, 즉 특수문자와 숫자와 매칭이 됩니다.
## (1-3) 특수문자, 숫자 제거
pattern = r'[^a-zA-Z가-힣]'
s = re.sub(pattern=pattern, repl=' ', string=s)
print(s)
[Out]
# 말티즈 강아지사료 습식 소프트 신 종 Kg 원 건
(1-4) 단위 제거: cm, km, etc.
## (1-4) 단위 제거: cm, km, etc.
units = ['mm', 'cm', 'km', 'ml', 'kg', 'g']
for unit in units:
s = s.lower() # 대문자를 소문자로 변환
s = s.replace(unit, '')
print(s)
[Out]
# 말티즈 강아지사료 습식 소프트 신 종 원 건
(1-5) 공백 기준으로 분할하기
Python 내장형 문자열 메소드인 split() 을 사용해서 공백(space)을 기준으로 문자열을 분할하였습니다.
글자 길이가 1 보다 큰 (len(word) != 1) 글자만 s_list 의 리스트에 계속 추가(append) 하였습니다.
## (1-6) 글자 1개만 있으면 제외하기
s_list = []
for word in s_split:
if len(word) !=1:
s_list.append(word)
print(s_list)
[Out]
# ['말티즈', '강아지사료', '습식', '소프트']
(1-7) 텍스트 데이터 전처리 사용자 정의함수(User Defined Function) 정의
위의 (1-1) ~ (1-6) 까지의 텍스트 전처리 과정을 아래에 사용자 정의함수로 정의하였습니다. 문자열 s 를 input으로 받아서 텍스트 전처리 후에 s_list 의 단어들을 분할해서 모아놓은 리스트를 반환합니다.
## 텍스트 전처리 사용자 정의함수(UDF of text pre-processing)
def text_preprocessor(s):
import re
## (1) [], (), {}, <> 괄호와 괄호 안 문자 제거하기
pattern = r'\([^)]*\)' # ()
s = re.sub(pattern=pattern, repl='', string=s)
pattern = r'\[[^)]*\]' # []
s = re.sub(pattern=pattern, repl='', string=s)
pattern = r'\<[^)]*\>' # <>
s = re.sub(pattern=pattern, repl='', string=s)
pattern = r'\{[^)]*\}' # {}
s = re.sub(pattern=pattern, repl='', string=s)
## (2) '...외', '...총' 제거하기
s = s.replace('...외', ' ')
s = s.replace('...총', ' ')
## (3) 특수문자 제거
pattern = r'[^a-zA-Z가-힣]'
s = re.sub(pattern=pattern, repl=' ', string=s)
## (4) 단위 제거: cm, km, etc.
units = ['mm', 'cm', 'km', 'ml', 'kg', 'g']
for unit in units:
s = s.lower() # 대문자를 소문자로 변환
s = s.replace(unit, '')
# (5) 공백 기준으로 분할하기
s_split = s.split()
# (6) 글자 1개만 있으면 제외하기
s_list = []
for word in s_split:
if len(word) !=1:
s_list.append(word)
return s_list
## sample text
s = '**[세일]** 말티즈 강아지사료 습식 소프트 신 3종 15Kg 39,000원!!...외5건'
## apply the UDF above
s_list = text_preprocessor(s)
print(s_list)
[Out]
# ['말티즈', '강아지사료', '습식', '소프트']
(1-8) pandas DataFrame의 텍스트 칼럼에 데이터 전처리 사용자정의함수 적용
pandas DataFrame에 위의 (1-7) 텍스트 전처리 사용자 정의함수를 적용하기 위해서는 apply() 와 lambda function 을 사용합니다.
위에 Jupyter Notebook 에서 pandas DataFrame을 출력한 결과가 중앙 정렬로 되어있어서 보기가 불편한데요, 아래처럼 좌측 정렬 (left alignment) 을 해서 보기에 편하도록 해보았습니다.
## align text of pandas DataFrame to left in Jupyter Notebook
dfStyler = df.style.set_properties(**{'text-align': 'left'})
dfStyler.set_table_styles([dict(selector='th', props=[('text-align', 'left')])])
text preprocessing using regular expressions
(2) 토큰화 (tokenization)
토큰화(Tokenization)는 말뭉치(Corpus)를 토큰이라고 불리는 단어 또는 문장으로 나누는 것을 말합니다. 이러한 토큰은 문맥(Context)을 이해하거나 NLP에 대한 모델을 개발하는 데 사용됩니다.
POS 태킹 (Part-of-Speech Tagging) 은 널리 사용되는 자연어 처리 프로세스로, 단어의 정의와 문맥에 따라 언어의 특정 부분에 대응하여 텍스트(corpus)의 단어를 분류하는 것을 말합니다.
아래 코드는 위 (1)번의 텍스트 전처리에 이어서, 띄어쓰기가 제대로 되지 않아서 붙어 있는 단어들을, Python KoNLpy 패키지를 사용해서 형태소 분석의 명사를 기준으로 단어 토근화를 한 것입니다. ((2)번 words_tokonizer() UDF 안에 (1)번 text_preprocessor() UDF가 포함되어 있으며, 순차적으로 수행됩니다.)
KoNLpy 패키지는 Python으로 한국어 자연어 처리(NLP) 을 할 수 있게 해주는 패키지입니다. 그리고 Kkma 는 서울대학교의 IDS 랩에서 JAVA로 개발한 형태소 분석기(morphological analyzer)입니다.
## insatll konlpy if it is not istalled yet
# ! pip install konlpy
## KoNLpy : NLP of the Korean language
## reference ==> https://konlpy.org/en/latest/
## Kkma is a morphological analyzer
## and natural language processing system written in Java,
## developed by the Intelligent Data Systems (IDS) Laboratory at SNU.
from konlpy.tag import Kkma
## define words tokenizer UDF
def words_tokonizer(text):
from konlpy.tag import Kkma # NLP of the Korean language
kkma = Kkma()
words = []
# Text preprocessing using the UDF above
s_list = text_preprocessor(text)
# POS tagging
for s in s_list:
words_ = kkma.pos(s)
# NNG indexing
for word in words_:
if word[1] == 'NNG':
words.append(word[0])
return words
## apply the UDF above as an example
words_tokonizer('강아지사료')
[Out] ['강아지', '사료']
words_tokonizer('상하세트')
[Out] ['상하', '세트']
위의 (2) words_tokenizer() UDF를 pandas DataFrame에 적용하기 위해서 apply() 함수와 lambda function 을 사용하면 됩니다.
## apply the text tokenization UDF to pandas DataFrame using apply() and lambda function
df['items'].apply(lambda text: words_tokonizer(text))
[Out]
# 0 [몰티즈, 강아지, 사료, 습식, 소프트]
# 1 [추가, 여름, 신상, 루즈, 핏, 원피스, 상하, 세트, 점프, 슈트]
# 2 [챌린지, 마스크, 국내, 생산, 여름, 황사, 화이트]
# 3 [하림, 용가리, 치킨, 닭, 가슴살, 튀김]
# 4 [종아리, 타파, 무로, 요가, 링, 마사지, 압박, 스타, 킹, 마사지]
# Name: items, dtype: object
먼저 예제로 사용할 샘플 테이블을 만들어보겠습니다. 과일가게에서 장바구니 ID별로 구매한 과일 품목이 문자열로 들어있는 테이블입니다.
-- create a sample table
DROP TABLE IF EXISTS basket_tbl;
CREATE TABLE basket_tbl (
id int
, item text
);
INSERT INTO basket_tbl VALUES
(1, 'orange, apple, grape')
, (2, 'guava, apple, durian')
, (3, 'strawberry, lime, leomon')
, (4, 'mango, mangosteen, plum')
, (5, 'plum, guava, peach');
SELECT * FROM basket_tbl ORDER BY id;
--id|item |
----+------------------------+
-- 1|orange, apple, grape |
-- 2|guava, apple, durian |
-- 3|strawberry, lime, leomon|
-- 4|mango, mangosteen, plum |
-- 5|plum, guava, peach |
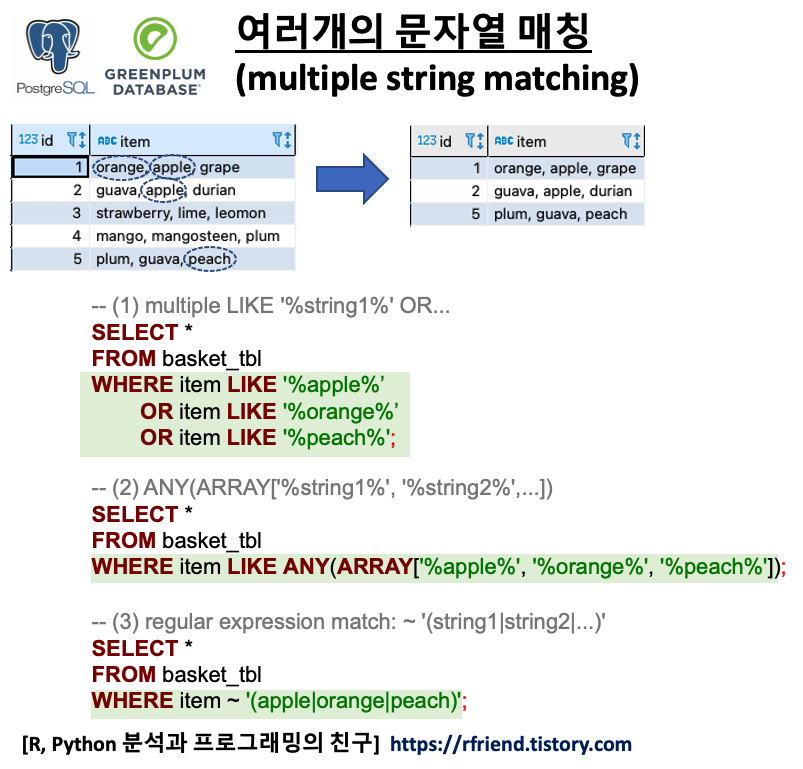
위의 샘플 테이블의 item 칼럼의 문자열에서 'apple', 'orange', 'peach' 중에 하나라도(OR) 문자열이 매칭(string matching)이 되면 SELECT 문으로 조회를 해오는 SQL query 를 3가지 방법으로 작성해보겠습니다.
(1) LIKE '%string1%' OR LIKE '%string2%' ...
가장 단순한 반면에, 조건절 항목이 많아질 경우 SQL query 가 굉장히 길어지고 비효율적인 단점이 있습니다.
-- (1) multiple LIKE '%string1%' OR LIKE '%string2%' OR...
SELECT *
FROM basket_tbl
WHERE item LIKE '%apple%'
OR item LIKE '%orange%'
OR item LIKE '%peach%'
ORDER BY id;
--id|item |
----+--------------------+
-- 1|orange, apple, grape|
-- 2|guava, apple, durian|
-- 5|plum, guava, peach |
(2) ANY(ARRAY['%string1%', '%string2%', ...])
문자열 매칭 조건절의 각 문자열 항목을 ARRAY[] 에 나열을 해주고, any() 연산자를 사용해서 이들 문자열 조건 중에서 하나라도 매칭이 되면 반환을 하도록 하는 방법입니다. 위의 (1)번 보다는 SQL query 가 짧고 깔끔해졌습니다.
-- (2) ANY(ARRAY['%string1%', '%string2%',...])
SELECT *
FROM basket_tbl
WHERE item LIKE ANY(ARRAY['%apple%', '%orange%', '%peach%'])
ORDER BY id;
--id|item |
----+--------------------+
-- 1|orange, apple, grape|
-- 2|guava, apple, durian|
-- 5|plum, guava, peach |