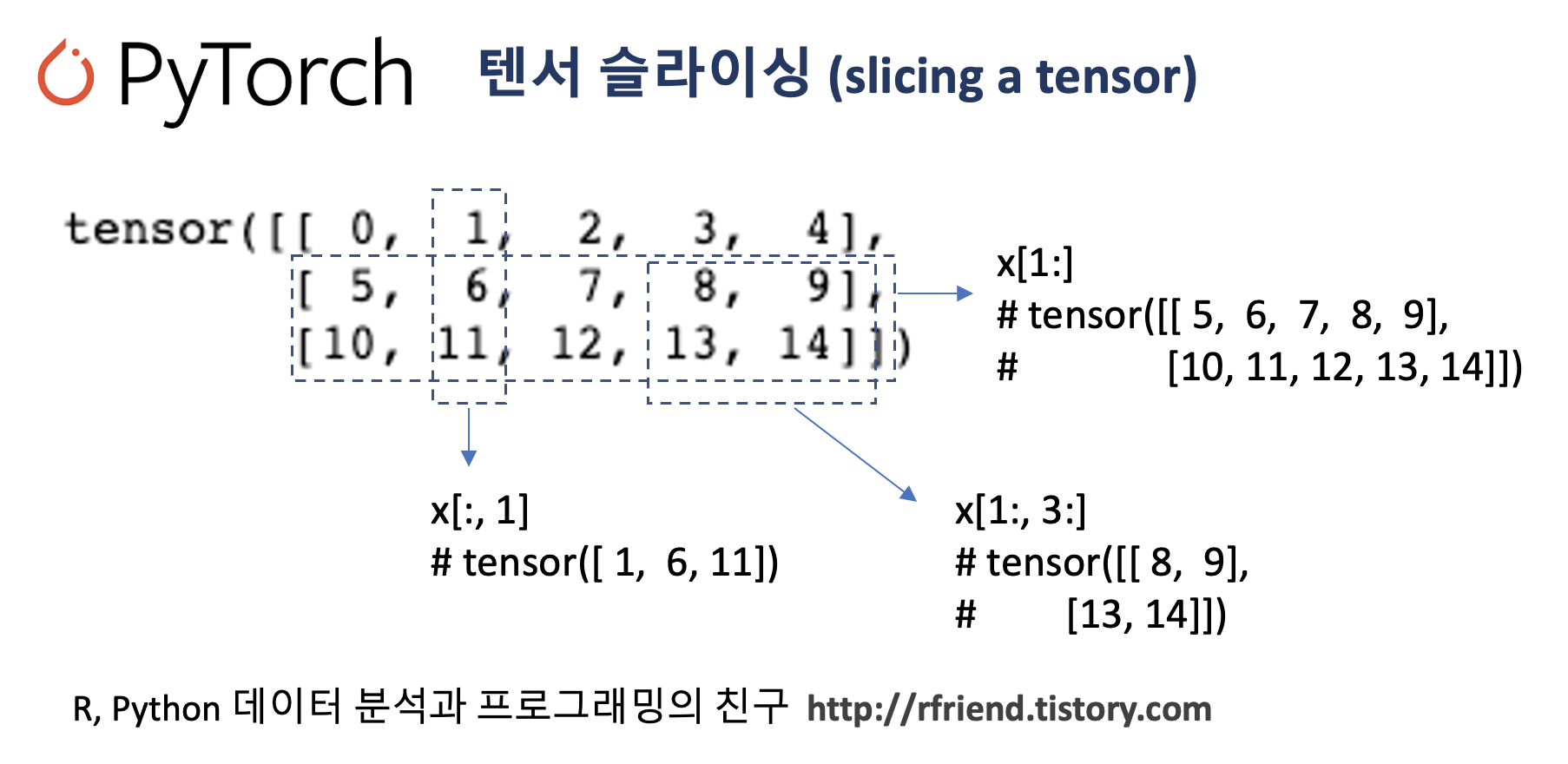
영화 "그린 북 (Green Book)"
감독: 피터 패럴리
출연: 비고 모텐슨 (토니 발레롱가 역), 마허샬라 알리(돈 셜리 역)
영화의 제목인 “그린 북(Green Book)”은 1950~60년대 아직도 흑인 인종차별이 심했던 미국 남부 지방에 흑인이 여행할 때 안심하고 묵을 수 있는 숙박시설을 안내해주는 책을 말합니다. 제목에서 알 수 있는 것처럼 “인종차별”에 대한 심각한 이야기를 흑인 천재 피아니스트와 백인 운전사의 로드 무비 형식을 빌려 때론 유머러스하게, 때론 인종차별의 민낯을 직시하며 생각할 거리를 주는 영화입니다.

이 영화는 1962년 뉴욕을 배경으로 하고 있으며, 실화에 바탕을 둔 영화입니다. 영화 마지막에 영화의 모티브가 되었던 두 명의 실존 인물 사진이 나와요. 유족은 이 영화에 허구가 많이 가미되었다면서 반발했다고는 하네요.
제91회 아카데미 시상식에서 작품상, 각본상, 남우조연상을 수상했으며, 극장 총 수익이 3억 416억 달러로 영화 흥행도 큰 성공을 거둔 영화예요.
영화는 교양과 품위를 갖춘 “흑인” 천재 피아니스트 돈 셜리(마허샬라 알리) 박사와, 말과 행동이 거칠고 서민적이며 허풍과 임기응변 선수인 “백인” 운전사 토니 발레롱가(비고 모텐슨)의 8주 간의 미국 남부 트리오 공연 (피아노, 첼로, 베이스) 동안 둘 사이에 벌어지는 일을 다룹니다. 일반적으로 “흑인”과 “백인” 하면 떠오르는 선입관과는 정반대의 설정인데요, 이런 선입관에 반하는 관계 속에서 인종 차별에 대한 얘기를 풀어나가는 감독의 줄타기가 대단합니다. 아래의 영화 장면처럼 돈 셜리 박사는 마치 왕족처럼 차려입고 상아 의자에 앉아 내려다보고 있고, 토니 발레롱가는 직업을 얻기 위해 인터뷰를 보는 입장에서 아래쪽 허름한 의자에 앉아 올려다보고 있어요. 처음엔 좀 어색하지 않으세요? (우리가 이리 세뇌되어있어요. -,-;)

저는 이 영화에 나오는 자잘한 유머가 무척 재미있었어요. 돈 셜리 ‘박사(Doctor)’ 라고 해서 병원에서 일하는 의사인줄 알았는데 카네기홀에 사는 피아니스트라고 해서 놀랐다는 토니 부부의 얘기, 핏츠버그에는 가슴 큰 여자가 많아서 찌찌버그라고 불린다는 얘기를 들었다면서 핏츠버그에 가면 직접 두 눈으로 확인을 해보겠다는 토니, “죠팽”은 아무나 칠 수 있지만 이런 음악은 당신만 연주할 수 있다는 토니의 응원성 멘트에 돈 셜리가 “쇼팽”을 나처럼 치는건 아무나 못하죠 하면서 정중하게 바로잡아 주는 장면이라든지… 방긋 미소지게 하는 소소한 장면들이 여럿 있어요. :-)
영화 마지막 즈음에 첼리스트가 말해주는 장면 중에 돈 셜리가 북부에서 공연하면 남부에서보다 3배나 더 많은 공연료를 받고 또 인간적으로 대접을 받을 수 있음에도 불구하고 왜 남부지역에서 인종차별을 당하면서 낮은 공연료에도 순회공연을 하게 되었는지에 대한 이야기가 나와요. 돈 셜리가 남부 지역 공연을 자원했는데요, 흑인에 대한 인종차별에 대해 자신이 할 수 있는 한에서 사람들 마음을 움직이고자 용기를 냈다는 말이 큰 감동이 있었어요.
“왜냐면 천재성만으론 부족하거든요. 사람의 마음을 움직이려면 용기가 필요해요.”
(Because genius is not enough. It takes courage to change people's hearts.)
토니와 돈 셜리가 여행을 하면서 처음에는 서로의 다름으로 인해 갈등하지만 점차 서로를 존중하고, 이해하고 또 서로 약한 부분을 도와주면서 일면 닮아가는 과정이 기분좋게 그려졌어요. 가령, 토니가 부인에게 편지를 쓸 때 돈 셜리가 세익스피어처럼 아름다운 문장으로 편지를 쓸 수 있도록 도와준다든지, 후라이드 치킨을 손으로 잡고 먹어본 적이 없는 돈 셜리에게 토니가 강권하면서 기어이 손으로 먹는 후라이드 치킨의 맛을 볼 수 있게 해준다던지… 편지 코치를 받던 토니가 동생과 연락을 끊고 지내는 돈 셜리 박사에게 먼저 편지를 써보라고 권하는 장면… 마지막 공연을 깽판치고 크리스마스 전에 뉴욕 집으로 돌아오는 길에 잠을 못자고 운전하다가 지친 토니가 도저히 안되겠다며 숙박시설에서 잠을 자고 가자고 하자 돈 셜리는 운전대를 잡고 교대로 운전을 해주는 장면… 참 훈훈하고 따뜻한 장면들이예요.
(돈 셜리 유족은 영화가 너무 미화되었다고 반발했다고 하네요. -,-;)
돈 셜리와 토니 발레롱가가 항상 사이좋게 공연을 다녔던 건 아니고, 싸우기도 했는데요, 돈 셜리가 비가 내리는 와중에 차를 박차고 나가서 울부짖는 장면이 인상적이었어요.
돈 셜리는 “나는 충분히 흑인도 아니고, 난 충분히 백인도 아니고, 난 충분히 남자도 아니고… 그럼 난 뭐지?” 라고 소리쳐요.
흑인이면서 최고의 교육을 받은 앵글로색슨 백인처럼 교양있고 품위있게 말하고 행동하는 돈 셜리. 남부지방에서 흑인 여러명이 농장에서 일하고 있고, 백인 토니가 고장난 차를 수리하고, 돈 셜리 박사는 차 옆에서 기다리고, 농장의 흑인들과 돈 셜리가 눈이 마주치는 장면은 느리게 지나가면서 긴 여운을 남겨요. 돈 셜리는 수영장에서 남자랑 둘이 같이 있었다는 이유로 경찰에게 잡히기도 해요. 돈 셜리는 어디에도 속하지 못하면서 사회에서 비주류로서 당할 수 있는 차별을 당하고 있는지라 얼마나 외롭고 힘들까 싶어요. 그럼에도 돈 셜리는 남 탓, 사회 탓만 하고 주저앉는게 아니라 사람들의 마음을 움직이기 위해 자신이 할 수 있는 일, 남부지방 순회공연을 해요. 그래서 더 감동이예요.
돈 셜리는 인종차별에 뚜껑이 열려서 주먹이 먼저 나가는 토니에게 "폭력으로는 못 이겨요. 품위(dignity)가 이겨요." 라고 말해요. 마하트마 간디가 연상되는 장면이었어요.
저는 이 영화 그린북을 인종 차별을 너무 심각하지 않으면서도 사람들에게 생각할 거리를 준 미덕을 갖춘 영화라고 생각해요. 그런데 language exchange 를 하고 있는 미국 변호사분과 이 영화 얘기를 나누었는데요, 미국 내 흑인들 중에는 이 영화에 대해서 비판적인 시선을 가진 이들이 꽤 있다고 해요. 이 영화가 백인이 각본을 쓰고, 백인이 제작을 하고, 백인이 감독을 했고, 백인 역할의 토니가 더 주목을 받은 영화이고, 백인 토니는 문제해결사로, 흑인 돈 셜리는 문제를 일이키고 도움을 받는 인물로 묘사가 되었다면서 흑인 사회에서는 이 영화에 화가 난 이들이 많다고 하더라구요. 제가 한국인이다보니 영화를 이렇게 못 봤구나, 흑인들은 기분 안좋게 이 영화를 볼 수도 있구나 싶어서 좀 놀랬어요. 자라온 배경과 정체성이 누구의 시선이냐에 따라서 영화가 달리 보일 수도 있겠구나 싶어서요.
그럼에도 불구하고 저는 이 영화의 미덕, 인종차별에 대해서 문제제기하고, 흑인과 백인이라는 두 세계의 굉장히 다른 두 사람이 서로를 인정하고, 존중하고, 또 가르쳐주고 배우면서 같이 성장하고 변화해가는 모습을 때론 미소짓게, 때론 뭉클하게 이야기로 풀어낸 이 영화의 미덕은 높여사줘야 한다고 생각해요.
이번 주말에 뭘 하면 좋을지 고민이세요? 맥주 한잔 곁들이면서 그린북(Green Book)’ 영화 한편 때리세요! ^_-*
'책이랑 영화랑' 카테고리의 다른 글
| [영화] 만추 (Late Autumn, 김태용 감독, 2011년) (6) | 2024.10.05 |
|---|---|
| [영화] 서부 전선 이상없다 (All Quiet On the Western Front, 2022) (0) | 2023.02.26 |
| [책] "심리학 직장 생활을 도와줘", 박진우 지음, 비지니스맵 출판사 (4) | 2023.01.08 |
| [책] "나는 기다립니다..." (다비드 칼리 글, 세르주 블로크 그림, 안수연 옮김, 문학동네) (0) | 2022.12.31 |
| [책] 통찰의 시간 (신수정 지음, 알투스 출판사) (5) | 2022.10.10 |