먼저 범주의 정답(Y, Label)을 알고 있는 데이터의 실제 값 (Actual) 과 분류 모델을 통해 분류한 예측 값 (Predicted) 을 평가하여 아래와 같은 표의 형태로 객체의 수를 셉니다. Positive 는 '1'/ 'Success'/ 'Pass'/ 'Live' 등에 해당하며, Negative 는 '0'/ 'Fail'/ 'Non Pass'/ 'Dead' 등을 의미합니다.
TP (True Positive), FP (False Positive), FN (False Negative), TN (True Negative) 는 아래의 표를 보면 의미가 더 명확할거예요. (P와 N은 예측치를 의미하며, 이걸 실제 값과 비교했을 때 맞혔으면 True, 틀렸으면 False 로 표기한 것임)
책에 따라서 '실제 값 (Actual)'과 '예측 값 (Predicted)' 의 축이 다른 경우도 있으니 가로 축과 세로 축이 무엇을 의미하는지 꼭 확인이 필요합니다.
F-1 점수 (F-1 Score)는 정밀도와 재현율의 조화평균(harmonic mean, 역수의 산술평균의 역수)으로서, 정밀도와 재현율이 균형있게 둘 다 높을 때 F-1 점수도 높게 나타납니다. 정밀도와 재현율이 모두 중요한 경우에는 F-1 점수를 사용해서 모델을 평가하면 됩니다.
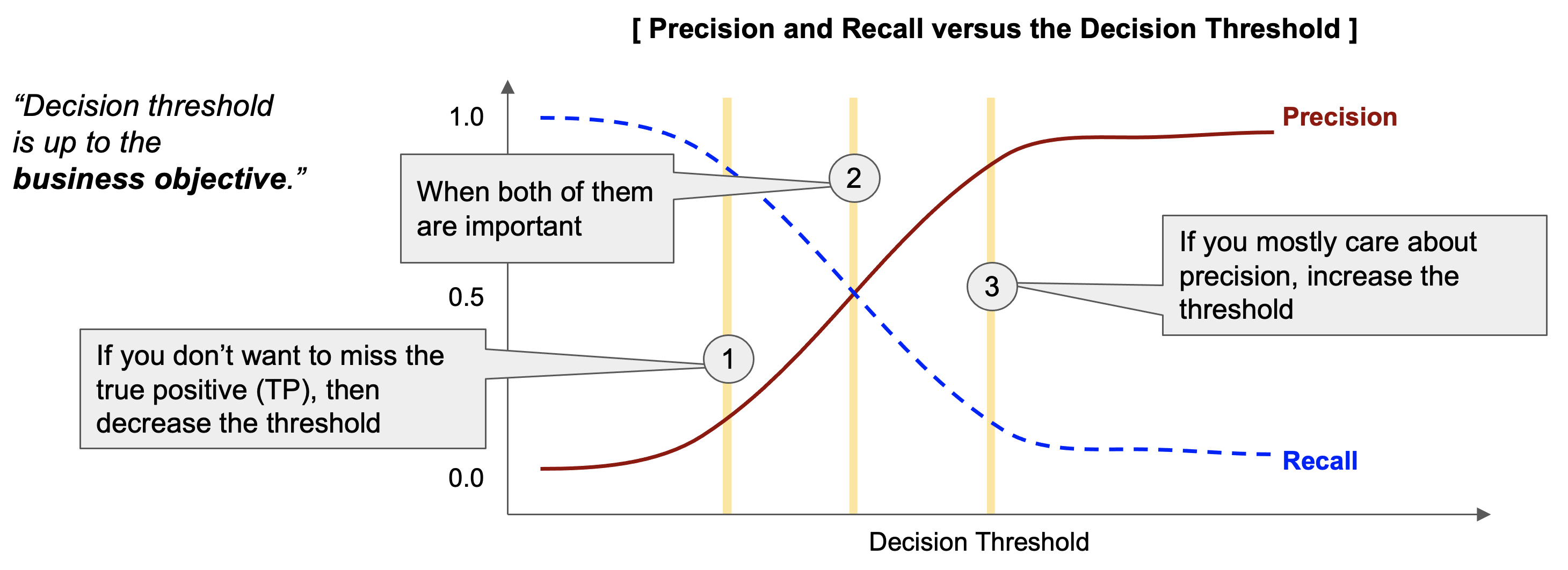
정밀도(Precision)와 재현율(Recall rate)은 분류 예측을 위한 의사결정 기준점(decision threshold)을 얼마로 하느냐에 따라 달라집니다. (의사결정 기준점에 따라 혼돈 매트릭스의 4사분면의 각 숫자가 달라짐)
정밀도와 재현율은 상충 관계에 있어서, 마치 시소 게임처럼 정밀도가 높아지면 재현율이 낮아지고, 반대로 재현율이 높아지면 정밀도는 낮아집니다. 이 상충관계를 잘 이해해야 왜 이렇게 많은 분류 모델 성과평가 지표가 존재하고 필요한지 이해할 수 있습니다.
보통은 '양성(Positive, 1)' 으로 분류할 확률이 의사결정 기준점 '0.5' 보다 크면 '양성 (Positive, 1)' 로 분류하고, '0.5' 보다 같거나 작으면 '음성 (Negative, 0)' 으로 분류를 합니다. (아래 그림의 (2)번 케이스)
만약 '실제 양성' (Actual Positive) 을 더 많이 잡아내고 싶으면 (실제 음성을 양성으로 오분류할 비용을 감수하고서라도), 의사결정 기준점을 내려주면 됩니다. (아래 그림의 (1)번 케이스) 그러면 재현율(Recall rate)은 올라가고, 정밀도(Precision) 은 낮아집니다.
만약 '예측한 양성'이 실제로도 양성인 비율 (즉, 정밀도, Precision)을 높이고 싶으면 의사결정 기준점을 올려주면 됩니다. (아래 그림의 (3)번 케이스). 그러면 정밀도(Precision)은 올라가고, 재현율(Recall rate)은 내려가게 됩니다.
precision/ recall trade-off
의사결정 기준점을 변경하고 싶다면 비즈니스 목적 상 재현율과 정밀도 중에서 무엇이 더 중요한 지표인지, 실제 양성을 놓쳤을 때의 비용과 예측한 양성이 실제로는 음성이었을 때의 비용 중에서 무엇이 더 끔찍한 것인지를 생각해보면 됩니다.
가령, 만약 코로나 진단 키트의 분류 모델이라면 '실제 양성 (즉, 코로나 감염)' 인 환자가 '음성'으로 오분류 되어 자가격리 대상에서 제외되고 지역사회에 코로나를 전파하는 비용이 '실제 음성 (즉, 코로나 미감염)' 인 사람을 '양성'으로 오분류했을 때보다 비용이 더 크다고 할 수 있으므로 (1) 번 케이스처럼 의사결정 기준점을 내려서 재현율(Recall rate)을 올리는게 유리합니다.
반면, 유튜브에서 영유아용 컨텐츠 적격 여부를 판단하는 분류모델을 만든다고 했을 때는, 일단 분류모델이 '영유아용 적격 판단 (Positive)' 을 내련 영상 컨텐츠는 성인물/폭력물/욕설 등의 영유아용 부적격 컨텐츠가 절대로 포함되어 있으면 안됩니다. 이럴경우 일부 실제 영유아용 적격 컨텐츠가 '부적격'으로 오분류되는 비용을 감수하고서라도 (3)번 케이스처럼 의사결정 기준점을 올려서 정밀도를 높게 해주는 것이 유리합니다.
그리고, 극도로 불균형한 데이터셋 (extremely imbalanced dataset) 의 경우 정확도(Accuracy) 지표는 모델을 평가하는 지표로 부적절합니다. 이때는 비즈니스 목적에 맞게 재현율과 정밀도 중에서 선택해서 사용하는 것이 필요합니다. (양성이 희소한 경우 모델이 모두 음성이라고 예측해도 정확도 지표는 매우 높게 나옴. 하지만 우리는 희소한 양성을 잘 찾아내는 모델을 원하지 모두가 다 음성이라고 예측하는 쓸모없는 모델을 원하지는 않음.)
(4) 분류 확률 기반 ROC Curve, AUC (Area Under the ROC Curve)
ROC 곡선(Receiver Operating Characteristic Curve)은 모든 분류 의사결정 기준값(decision threshold)에서 분류 모델의 성능을 보여주는 그래프입니다. X축은 False Positive Rate, Y축은 True Positive Rate 으로 하여 모든 의사결정 기준값 (Positive 일 확률) 별로 혼돈 매트릭스를 구하고, 여기에서 재현율과 특이도를 구해서 TPR과 FPR을 구하고, 이를 선으로 연결해주면 됩니다.
ROC Curve
ROC 곡선은 45도 대각선이 무작위로 추측하여 분류했을 때를 의미하며, ROC 곡선이 좌측 상단으로 붙으면 붙을 수록 분류 모델의 성능이 더 좋다고 해석합니다. (False Positive Rate 보다 True Positive Rate이 상대적으로 더 높을 수록 더 좋은 분류 모델임)
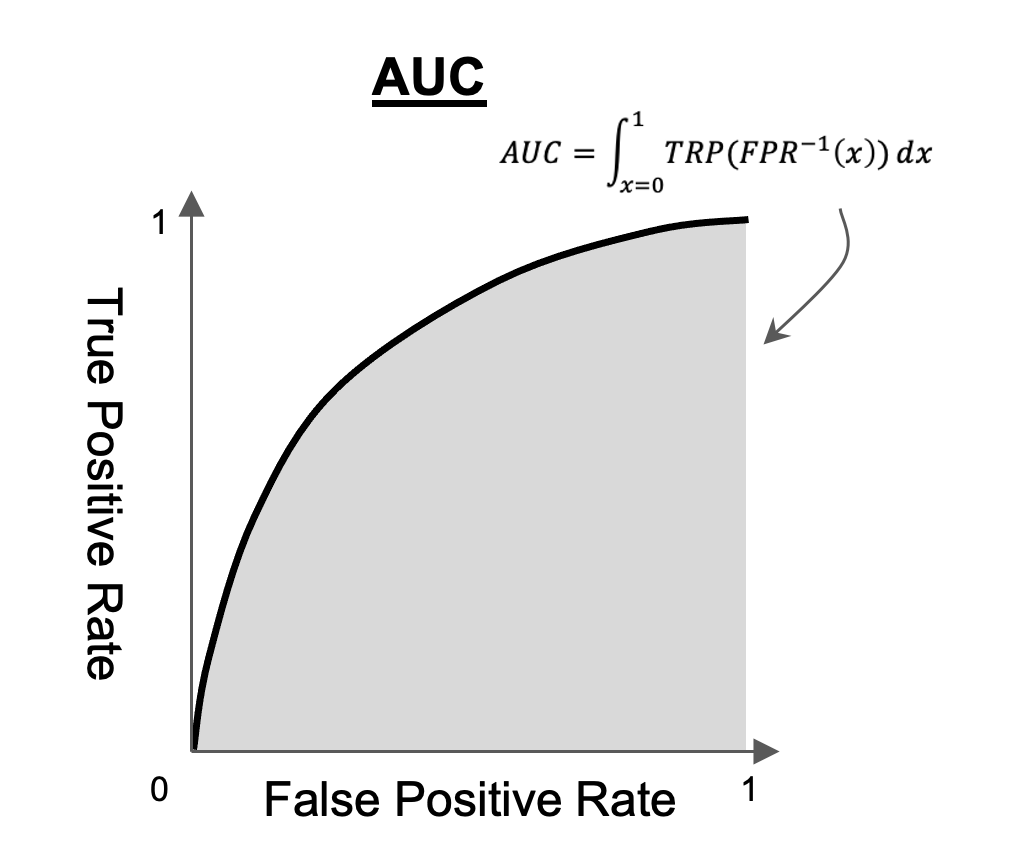
AUC (Area Under the ROC Curve) 점수는 위의 ROC 곡선의 아랫 부분을 적분하여 하나의 수치로 분류 모델의 성능을 표현한 것입니다. AUC 점수가 높으면 높을 수록 더 좋은 분류 모델입니다.
ROC 곡선과 AUC 모두 분류 모델이 '양성일 확률(probability)'을 반환할 때만 계산이 가능합니다.
(즉, 모델이 분류할 범주(category, class)로 예측값을 반환하면 ROC 곡선, AUC 계산 불가)
시계열 데이터를 분석할 때 제일 처음 확인하고 처리하는 일이 결측값(missing values) 입니다. 이번 포스팅에서는 시계열 데이터의 결측값을 선형 보간(linear interpolation)하는 2가지 방법을 소개하겠습니다.
(1) Python 으로 결측값을 포함하는 예제 시계열 데이터 생성하기
(2) Python 의 for loop 순환문으로 시계열 데이터 결측값을 보간하기
(interpolation sequentially using Python for loop statement)
(3) Greenplum에서 PL/Python으로 분산병렬처리하여 시계열 데이터 결측값을 보간하기
(interpolation in parallel using PL/Python on Greenplum)
(1) Python 으로 결측값을 포함하는 예제 시계열 데이터 생성하기
샘플 시계열 데이터를 저장할 폴더를 base_dir 에 지정해주었습니다.
분석 단위로 사용할 Lot, Cell, Parameter, TimeStamp 의 개수를 지정해 줍니다. 아래 예에서는 각 Lot, Cell, Parameter 별로 100개의 TimeStamp 별로 측정값을 수집하고, 각 분석 단위별로 10개의 결측값을 포함하도록 설정했습니다.
np.random.normal(10, 30, ts_num) : 측정값은 정규분포 X~N(10, 3) 의 분포로 부터 ts_num 인 100개를 난수 생성하여 만들었습니다.
: 각 분석 단위의 100 개의 측정치 중에서 무작위로 missing_num = 10 개를 뽑아서 np.nan 으로 교체하여 결측값으로 변경하였습니다.
하나의 Lot에 Cell 100개, 각 Cell별 Parameter 10개, 각 Parameter 별 TimeStamp의 측정치 100개, 이중 결측치 10개를 포함한 시계열 데이터를 Lot 별로 묶어서(concat) DataFrame을 만들고, 이를 CSV 파일로 내보냅니다.
#%% setting the directories and conditions
base_dir = '/Users/Documents/ts_data/'
## setting the number of IDs' conditions
lot_num = 1000
cell_num = 100
param_num = 10
missing_num = 10
ts_num = 100 # number of TimeStamps
#%% [Step 1] generating the sample dataset
import numpy as np
import pandas as pd
import os
from itertools import chain, repeat
## defining the UDF
def ts_random_generator(lot_id, cell_num, param_num, ts_num, missing_num, base_dir):
# blank DataFrame for saving the sample datasets later
ts_df = pd.DataFrame()
for cell_id in np.arange(cell_num):
for param_id in np.arange(param_num):
# making a DataFrame with colums of lot_id, cell_cd, param_id, ts_id, and measure_val
ts_df_tmp = pd.DataFrame({
'lot_id': list(chain.from_iterable(repeat([lot_id + 1], ts_num))),
'cell_id': list(chain.from_iterable(repeat([cell_id + 1], ts_num))),
'param_id': list(chain.from_iterable(repeat([param_id + 1], ts_num))),
'timestamp_id': (np.arange(ts_num) + 1),
'measure_val': np.random.normal(10, 3, ts_num)# X~N(mean, stddev, size)
})
# inserting the missing values randomly
nan_mask = np.random.choice(np.arange(ts_num), missing_num)
ts_df_tmp.loc[nan_mask, 'measure_val'] = np.nan
# concatenate the generated random dataset(ts_df_tmp) to the lot based DataFrame(ts_df)
ts_df = pd.concat([ts_df, ts_df_tmp], axis=0)
# exporting the DataFrame to local csv file
base_dir = base_dir
file_nm = 'lot_' + \
str(lot_id+1).zfill(4) + \
'.csv'
ts_df.to_csv(os.path.join(base_dir, file_nm), index=False)
#ts_df.to_csv('/Users/lhongdon/Documents/SK_ON_PoC/ts_data/lot_0001.csv')
print(file_nm, "is successfully generated.")
#%% Executing the ts_random_generator UDF above
## running the UDF above using for loop statement
for lot_id in np.arange(lot_num):
ts_random_generator(
lot_id,
cell_num,
param_num,
ts_num,
missing_num,
base_dir
)
위의 코드를 실행하면 for loop 순환문이 lot_num 수만큼 돌면서 ts_random_generator() 사용자 정의함수를 실행시키면서 결측값을 포함한 시계열 데이터 샘플 CSV 파일을 생성하여 지정된 base_dir 폴더에 저장을 합니다.
(아래 화면 캡쳐 참조)
sample time series data list
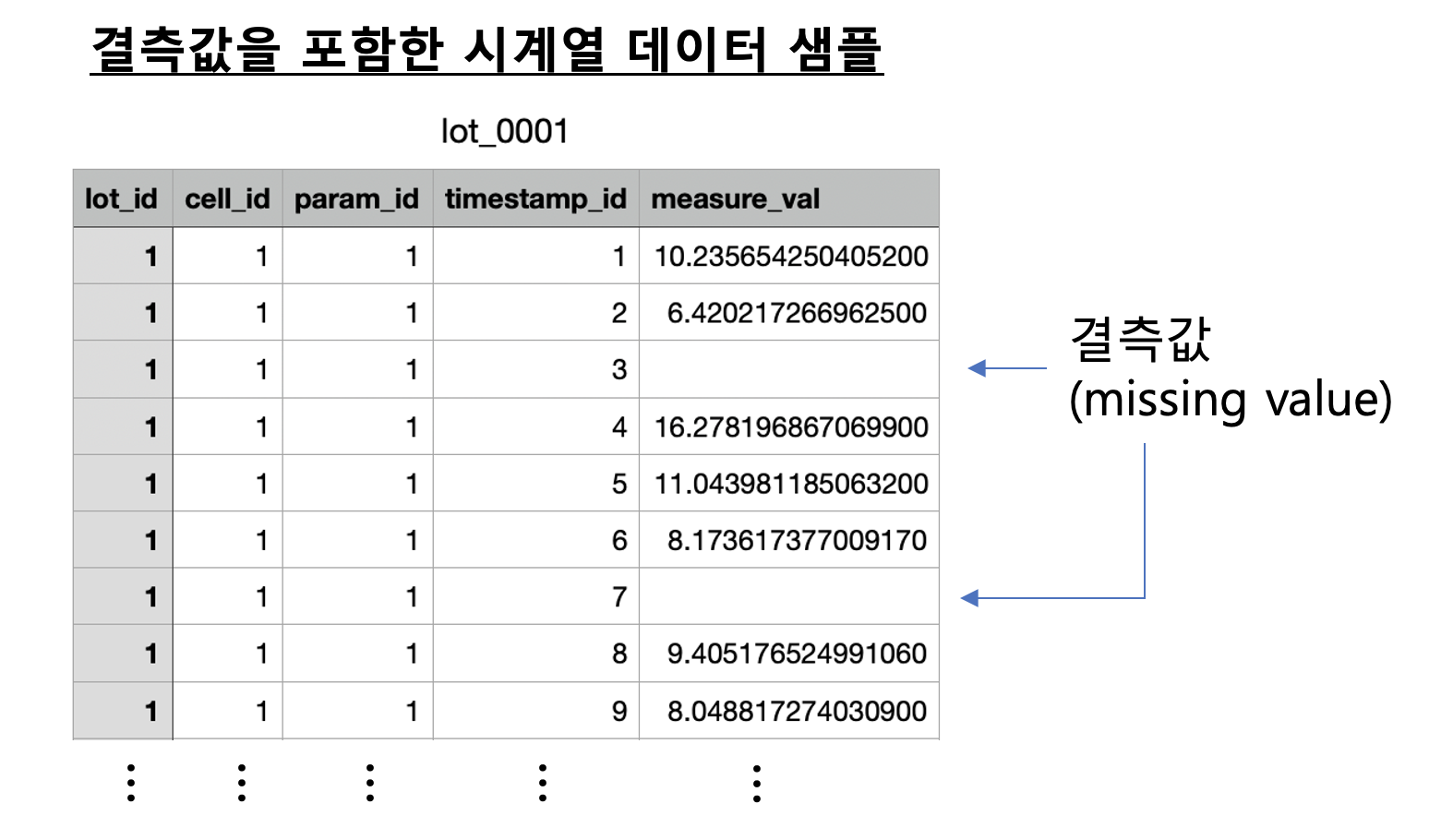
아래의 화면캡쳐는 결측값을 포함하는 시계열 데이터 샘플 중에서 LOT_0001 번의 예시입니다.
time series data sample with missing values
(2) Python 의 for loop 순환문으로 시계열 데이터 결측값을 보간하기
(interpolation sequentially using Python for loop statement)
아래 코드는 Python으로 Lot, Cell, Parameter ID 별로 for loop 순환문을 사용해서 pandas 의 interpolate() 메소드를 사용해서 시계열 데이터의 결측값을 선형 보간(linear interpolation) 한 것입니다.
(forward fill 로 먼저 선형 보간을 해주고, 그 다음에 만약에 첫번째 행에 결측값이 있을 경우에 backward fill 로 이후 값과 같은 값으로 결측값을 채워줍니다.)
순차적으로 for loop 순환문을 돌기 때문에 시간이 오래 걸립니다.
#%% [Step 2] linear interpolation
from datetime import datetime
start_time = datetime.now()
## reading csv files in the base_dir
file_list = os.listdir(base_dir)
for file_nm in file_list:
# by Lot
if file_nm[-3:] == "csv":
# read csv file
ts_df = pd.read_csv(os.path.join(base_dir, file_nm))
# blank DataFrame for saving the interpolated time series later
ts_df_interpolated = pd.DataFrame()
# cell & param ID lists
cell_list = np.unique(ts_df['cell_id'])
param_list = np.unique(ts_df['param_id'])
# interpolation by lot, cell, and param IDs
for cell_id in cell_list:
for param_id in param_list:
ts_df_tmp = ts_df[(ts_df.cell_id == cell_id) & (ts_df.param_id == param_id)]
## interpolating the missing values for equaly spaced time series data
ts_df_tmp.sort_values(by='timestamp_id', ascending=True) # sorting by TimeStamp first
ts_df_interpolated_tmp = ts_df_tmp.interpolate(method='values') # linear interploation
ts_df_interpolated_tmp = ts_df_interpolated_tmp.fillna(method='bfill') # backward fill for the first missing row
ts_df_interpolated = pd.concat([ts_df_interpolated, ts_df_interpolated_tmp], axis=0)
# export DataFrame to local folder as a csv file
ts_df_interpolated.to_csv(os.path.join(interpolated_dir, file_nm), index=False)
print(file_nm, "is successfully interpolated.")
time_elapsed = datetime.now() - start_time
print("----------" * 5)
print("Time elapsed (hh:mm:ss.ms) {}".format(time_elapsed))
print("----------" * 5)
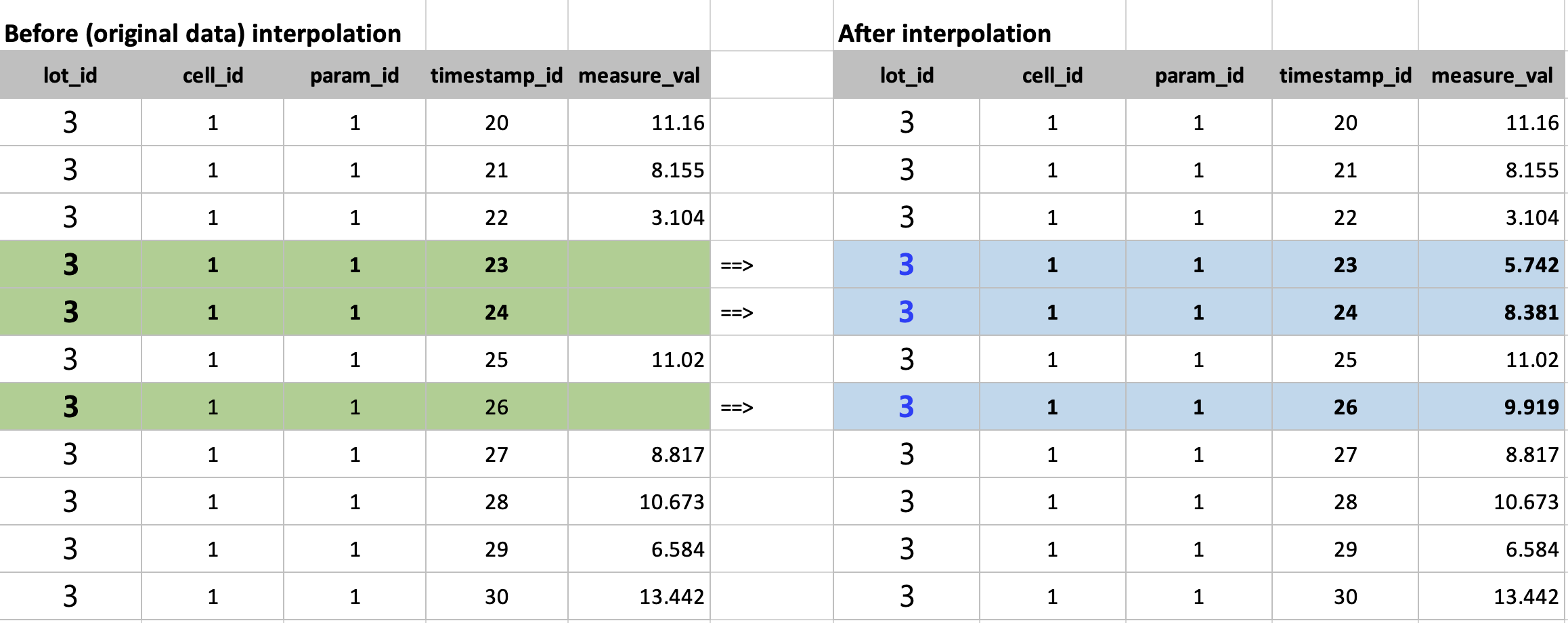
# # Before interplolation
# 3,1,1,20,11.160795506036791
# 3,1,1,21,8.155949904188175
# 3,1,1,22,3.1040644143505407
# 3,1,1,23, <-- missing
# 3,1,1,24, <-- missing
# 3,1,1,25,11.020504352275342
# 3,1,1,26, <-- missing
# 3,1,1,27,8.817922501760519
# 3,1,1,28,10.673174873272234
# 3,1,1,29,6.584669096660191
# 3,1,1,30,13.442427337943553
# # After interpolation
# 3,1,1,20,11.160795506036791
# 3,1,1,21,8.155949904188175
# 3,1,1,22,3.1040644143505407
# 3,1,1,23,5.742877726992141 <-- interpolated
# 3,1,1,24,8.381691039633742 <-- interpolated
# 3,1,1,25,11.020504352275342
# 3,1,1,26,9.919213427017931 <-- interpolated
# 3,1,1,27,8.81792250176052
# 3,1,1,28,10.673174873272234
# 3,1,1,29,6.584669096660191
# 3,1,1,30,13.442427337943554
아래 화면캡쳐는 선형보간하기 전에 결측값이 있을 때와, 이를 선형보간으로 값을 생성한 후의 예시입니다.
linear interpolation for missing data in time series
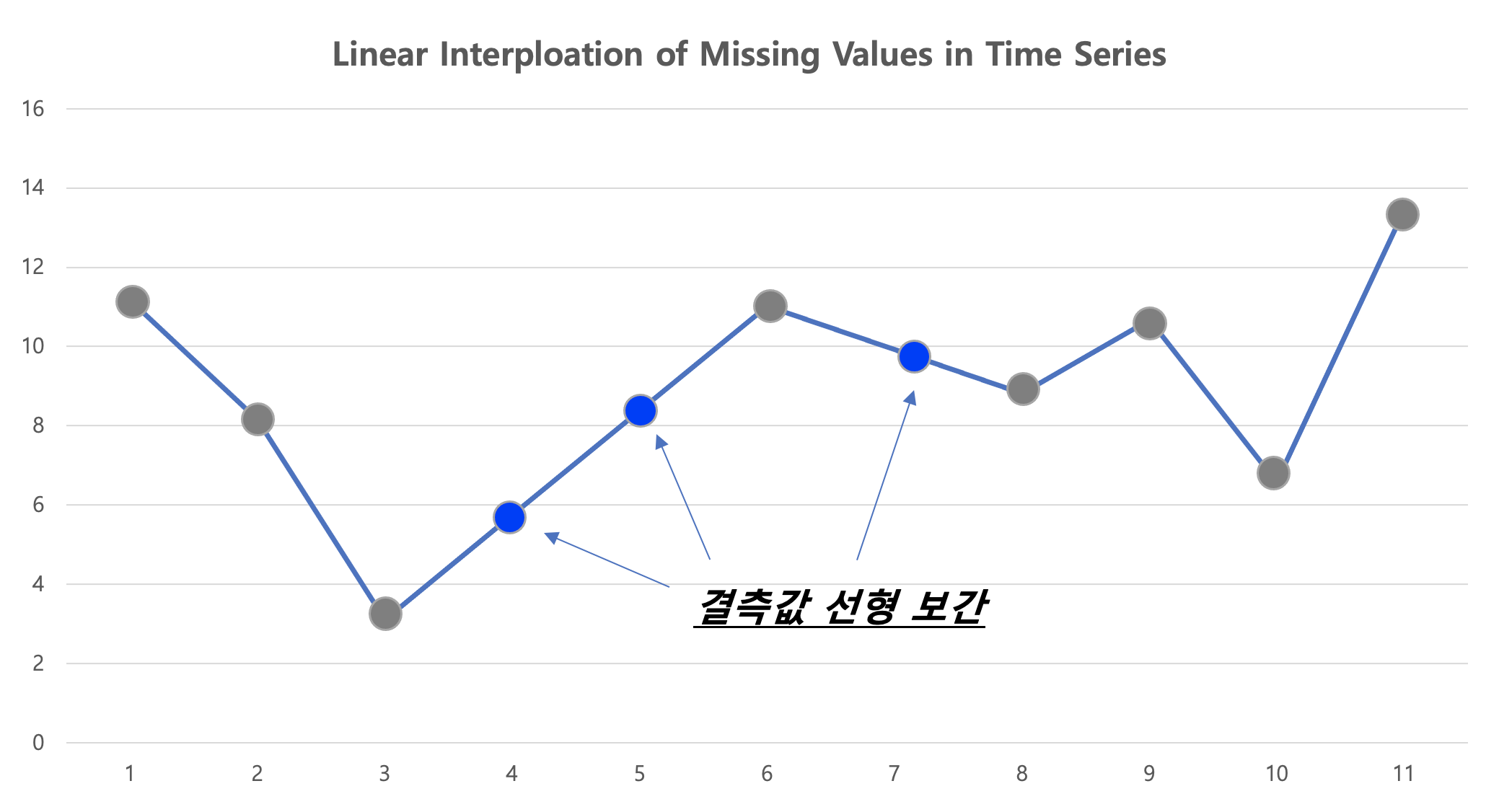
아래 선 그래프의 파란색 점 부분이 원래 값에서는 결측값 이었던 것을 선형 보간(linear interpolation)으로 채워준 후의 모습입니다. 선형보간이므로 측정된 값으로 선형회귀식을 적합하고, 결측값 부분의 X 값을 입력해서 Y를 예측하는 방식으로 결측값을 보간합니다.
linear interpolation of missing values in time series
아래 코드는 데이터가 Greenplum DB에 적재되어 있다고 했을 때,
(2-1) Python으로 Greenplum DB에 access하여 데이터를 Query 해와서 pandas DataFrame으로 만들고
(2-2) Pytnon pandas 의 interpolate() 메소드를 사용해서 선형보간을 한 다음에
(2-3) 선형보간된 DataFrame을 pandas 의 to_sql() 메소드를 사용해서 다시 Greenplum DB에 적재
하는 코드입니다. 이를 for loop 순환문을 사용해서 Lot 의 개수만큼 실행시켜 주었습니다.
순차적으로 for loop 순환문을 돌기 때문에 시간이 오래 걸립니다.
#%% Greenplum credentials
user = 'username'
password = 'password'
host = 'ip_address'
port = 'port'
db = 'databasename'
connection_string = "postgresql://{user}:{password}@{host}:{port}/{db}".\
format(user=user,
password=password,
host=host,
port=port,
db=db)
#%%
# helper function: query to pandas DataFrame
def gpdb_query(query):
import psycopg2 as pg
import pandas as pd
conn = pg.connect(connection_string)
cursor = conn.cursor()
cursor.execute(query)
col_names = [desc[0] for desc in cursor.description]
result_df = pd.DataFrame(cursor.fetchall(), columns=col_names)
cursor.close()
conn.close()
return result_df
#%%
# UDF for running a query
def interpolator(lot_id):
#import pandas as pd
query = """
SELECT *
FROM ts_data
WHERE
lot_id = {lot_id}
""".format(
lot_id = lot_id)
ts_df = gpdb_query(query)
ts_df = ts_df.astype({
'measure_val': float
})
## interpolating the missing values for equaly spaced time series data
ts_df_interpolated = pd.DataFrame()
for cell_id in (np.arange(cell_num)+1):
for param_id in (np.arange(param_num)+1):
ts_df_tmp = ts_df[(ts_df.cell_id == cell_id) & (ts_df.param_id == param_id)]
ts_df_tmp.sort_values(by='timestamp_id', ascending=True) # sorting by TimeStamp first
ts_df_interpolated_tmp = ts_df_tmp.interpolate(method='values') # linear interploation
ts_df_interpolated_tmp = ts_df_interpolated_tmp.fillna(method='bfill') # backward fill for the first missing row
ts_df_interpolated = pd.concat([ts_df_interpolated, ts_df_interpolated_tmp], axis=0)
# export DataFrame to local folder as a csv file
#ts_df_interpolated.to_csv(os.path.join(interpolated_dir, file_nm), index=False)
#print(file_nm, "is successfully interpolated.")
return ts_df_interpolated
#%%
# UDF for importing pandas DataFrame to Greenplum DB
def gpdb_importer(lot_id, connection_string):
import sqlalchemy
from sqlalchemy import create_engine
engine = create_engine(connection_string)
# interpolation
ts_data_interpolated = interpolator(lot_id)
# inserting to Greenplum
ts_data_interpolated.to_sql(
name = 'ts_data_interpolated_python',
con = engine,
schema = 'equipment',
if_exists = 'append',
index = False,
dtype = {'lot_id': sqlalchemy.types.INTEGER(),
'cell_id': sqlalchemy.types.INTEGER(),
'param_id': sqlalchemy.types.INTEGER(),
'timestamp_id': sqlalchemy.types.INTEGER(),
'measure_val': sqlalchemy.types.Float(precision=6)
})
#%%
from datetime import datetime
start_time = datetime.now()
import pandas as pd
import os
import numpy as np
for lot_id in (np.arange(lot_num)+1):
gpdb_importer(lot_id, connection_string)
print("lot_id", lot_id, "is successfully interpolated.")
time_elapsed = datetime.now() - start_time
print("----------" * 5)
print("Time elapsed (hh:mm:ss.ms) {}".format(time_elapsed))
print("----------" * 5)
(3) Greenplum에서 PL/Python으로 분산병렬처리하여 시계열 데이터 결측값을 보간하기
(interpolation in parallel using PL/Python on Greenplum)
Greenplum에서 PL/Python으로 병렬처리할 때는 (a) 사용자 정의 함수(UDF) 정의, (b) 사용자 정의 함수 실행의 두 단계를 거칩니다.
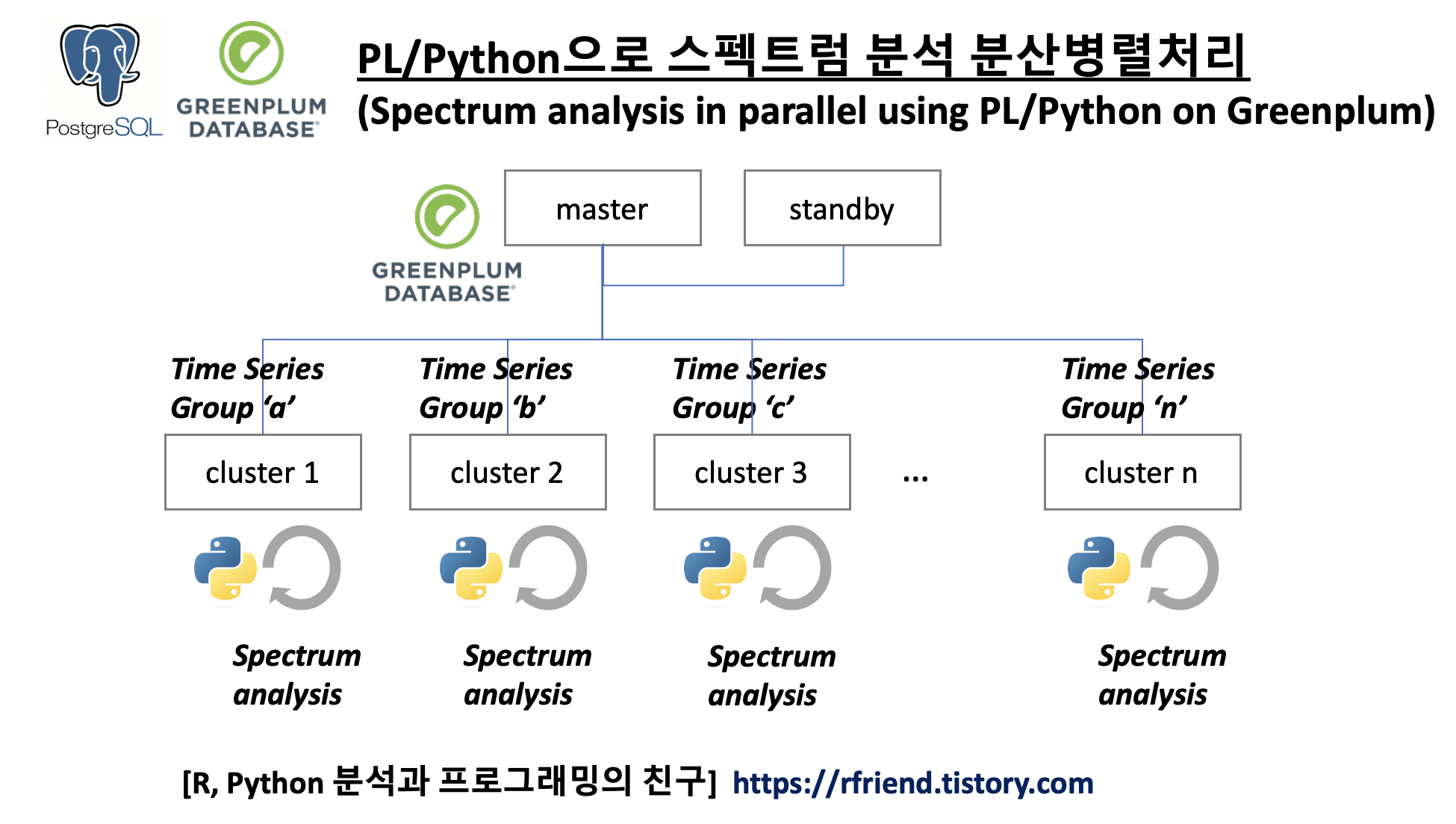
Greenplum DB에서 PL/Python으로 분산병렬처리를 하면 위의 (2)번에서 Python으로 for loop 순환문으로 순차처리한 것 대비 Greenplum DB 내 노드의 개수에 비례하여 처리 속도가 줄어들게 됩니다. (가령, 노드가 8개이면 병렬처리의 총 처리 소요시간은 순차처리했을 때의 총 소요시간의 1/8 로 줄어듭니다.)
parallel processing using PL/Python on Greenplum DB
(3-1) PL/Python 으로 시계열 데이터 결측값을 선형보간하는 사용자 정의함수 정의 (define a UDF)
-- defining the PL/Python UDF
DROP FUNCTION IF EXISTS plpy_interp(numeric[]);
CREATE OR REPLACE FUNCTION plpy_interp(measure_val_arr numeric[])
RETURNS numeric[]
AS $$
import numpy as np
import pandas as pd
measure_val = np.array(measure_val_arr, dtype='float')
ts_df = pd.DataFrame({
'measure_val': measure_val
})
# interpolation by lot, cell, and param IDs
ts_df_interpolated = ts_df.interpolate(method='values') # linear interploation
ts_df_interpolated = ts_df_interpolated.fillna(method='bfill') # backward fill for the first missing row
return ts_df_interpolated['measure_val']
$$ LANGUAGE 'plpythonu';
(3-2) 위에서 정의한 시계열 데이터 결측값을 선형보간하는 PL/Python 사용자 정의함수 실행
PL/Python의 input 으로는 SQL의 array_agg() 함수를 사용해서 만든 Array 데이터를 사용하며, PL/Python에서는 SQL의 Array를 Python의 List 로 변환(converting) 합니다.
-- array aggregation as an input
DROP TABLE IF EXISTS tab1;
CREATE TEMPORARY TABLE tab1 AS
SELECT
lot_id
, cell_id
, param_id
, ARRAY_AGG(timestamp_id ORDER BY timestamp_id) AS timestamp_id_arr
, ARRAY_AGG(measure_val ORDER BY timestamp_id) AS measure_val_arr
FROM ts_data
GROUP BY lot_id, cell_id, param_id
DISTRIBUTED RANDOMLY ;
ANALYZE tab1;
-- executing the PL/Python UDF
DROP TABLE IF EXISTS ts_data_interpolated;
CREATE TABLE ts_data_interpolated AS (
SELECT
lot_id
, cell_id
, param_id
, timestamp_id_arr
, plpy_interp(measure_val_arr) AS measure_val_arr -- plpython UDF
FROM tab1 AS a
) DISTRIBUTED BY (lot_id);
아래 코드는 numeric array 형태로 반환한 선형보간 후의 데이터를 unnest() 함수를 사용해서 보기에 편하도록 long format 으로 풀어준 것입니다.
-- display the interpolated result
SELECT
lot_id
, cell_id
, param_id
, UNNEST(timestamp_id_arr) AS timestamp_id
, UNNEST(measure_val_arr) AS measure_val
FROM ts_data_interpolated
WHERE lot_id = 1 AND cell_id = 1 AND param_id = 1
ORDER BY lot_id, cell_id, param_id, timestamp_id
LIMIT 100;
결측값을 포함하고 있는 원래 데이터셋을 아래 SQL query 로 조회해서, 위의 선형보간 된 후의 데이터셋과 비교해볼 수 있습니다.
-- original dataset with missing value
SELECT
lot_id
, cell_id
, param_id
, timestamp_id
, measure_val
FROM ts_data
WHERE lot_id = 1 AND cell_id = 1 AND param_id = 1
ORDER BY lot_id, cell_id, param_id, timestamp_id
LIMIT 100;
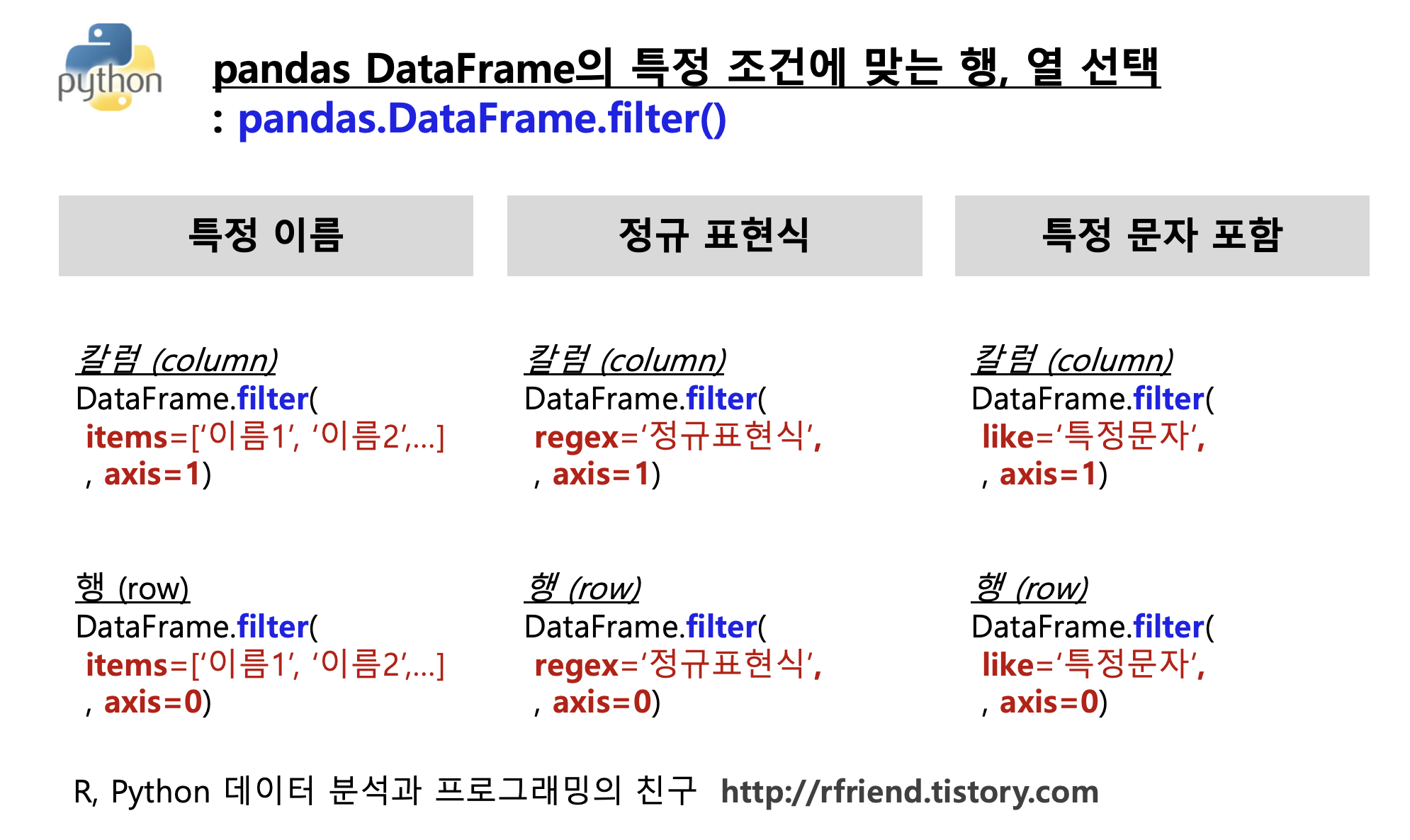
(1) pd.DataFrame.filter() 함수의 items 옵션을 사용하여 '이름'으로 행이나 열을 선택해서 가져오기
(1-1) pd.DataFrame.filter(items = ['칼럼 이름 1', '칼럼 이름 2', ...], axis=1) 옵션을 사용해서 '특정 칼럼 이름'의 데이터를 선택해서 가져올 수 있습니다. 칼럼 이름은 리스트 형태 (list-like) 로 나열해줍니다. axis 의 디폴트 옵션은 axis = 1 로서 칼럼 기준입니다.
참고로, 일상적으로 많이 사용하는 df[['칼럼 이름 1', '칼럼 이름 2', ...]] 와 같습니다.
## pd.DataFrame.filter()
## : Subset the dataframe rows or columns according to the specified index labels.
## reference: https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.filter.html
## (1-1) items: select columns by name
## equivalently: df[['x_1', 'var2']]
df.filter(items=['x_1', 'var2'], axis=1)
# x_1 var2
# abc 0 3
# bbb 4 7
# ccc 8 11
(1-2) pd.DataFrame.filter(items = ['열 이름 1', '열 이름 2', ...], axis=0) 옵션을 사용해서 '특정 열 이름'의 데이터를 선택해서 가져올 수 있습니다.
참고로, 자주 사용하는 df.loc[['열 이름 1', '열 이름 2', ...]] 와 같습니다.
(2) pd.DataFrame.filter() 함수의 regex 옵션을 사용하여 '정규 표현식'으로 행이나 열을 선택해서 가져오기
DataFrame.filter() 함수의 힘은 정규 표현식(regular expression)을 사용해서 행이나 열을 선택할 수 있다는 점입니다. 정규 표현식은 너무 광범위해서 이 포스팅에서 세부적으로 다루기에는 무리구요, 아래에는 정규 표현식의 강력함에 대한 맛보기로 세 개의 예시를 준비해봤습니다.
(2-1) 정규 표현식을 이용해서 특정 문자로 시작(^)하는 모든 칼럼 선택해서 가져오기: regex='^(특정문자).+'
## (2) select columns by regular expression
## (2-1) 'x_' 로 시작하는 모든 칼럼 선택
## 캐럿 기호 ^는 텍스트의 시작,
df.filter(regex='^(x_).+', axis=1)
# x_1 x_2
# abc 0 1
# bbb 4 5
# ccc 8 9
(2-2) 정규 표현식을 이용해서 특정 문자로 끝나는($) 모든 칼럼 선택해서 가져오기: regex='특정문자$'
## (2-2) '2' 루 끝나는 모든 칼럼 선택
## 달러 기호 $는 텍스트의 끝
df.filter(regex='2$', axis=1)
# x_2 var2
# abc 1 3
# bbb 5 7
# ccc 9 11
(2-3) 정규 표현식을 이용해서 특정 문자로 시작하지 않는 모든 칼럼 선택해서 가져오기: regex='^(?!특정문자).+'
## (2-3) 'x_' 로 시작하지 않는 모든 칼럼 선택
df.filter(regex='^(?!x_).+', axis=1)
# var1 var2
# abc 2 3
# bbb 6 7
# ccc 10 11
(2-4)정규 표현식을 이용해서 행 이름의 끝에 특정 문자를 포함하는 행(row)을 선택하기 : DataFrame.filter(regex='특정문자$', axis=0)
## select rows(axis=0) containing 'c' at the end using regular expression.
df.filter(regex='c$', axis=0)
# x_1 x_2 var1 var2
# abc 0 1 2 3
# ccc 8 9 10 11
(3) pd.DataFrame.filter() 함수의 like 옵션을 사용하여 '특정 문자를 포함'하는 행이나 열을 선택해서 가져오기
(3-1) 특정 문자를 포함하는 칼럼(column)을 선택해서 가져오기: df.filter(like='특정 문자', axis=1)
이번에는 직장인 들에게 피와 살이 될 심리학 책 한권 소개할께요. 작년 연말 휴가 때 정말 재미있고 유익하게 단숨에 읽은 책이기도 하고, 이 책을 좋아할 만한 친구에게 기쁜 맘으로 선물한 책이기도 해요.
회사에서 무기가 되는 28가지 심리 기술 <심리학 직장 생활을 도와줘>, 박진우 지음, 비즈니스맵
심리학 직장 생활을 도와줘, 박진우 지음, 비즈니스맵
저자인 박진우 조직심리학 박사는 “직장인의 안녕감과 조직의 성과 향상을 위해 심리학 연구를 업무 현장에 쉽게 적용할 수 있도록 노력하고 있다”고 자신을 소개하고 있는데요, “조직의 성과 향상”은 많이 들어봤어도 “직장인의 안녕감”은 생소하면서도 왠지 따뜻하고 고맙게 느껴져요. 안녕감이라… ^^b
에필로그에서 박진우 저자가 이 책을 쓴 이유를 보면 우리 인생의 상당 부분을 차지하는 직장 생활의 행복을 위해 심리학이 크게 기여할 수 있을 것이라는 저자의 믿음과 이 책이 그 역할을 할 수 있기를 바라는 마음을 알 수 있어요.
“‘심리학이 직장 생활에 도움을 줄 수 있을까?’ 하는 질문에서 출발해 모두 28개 주제에 관한 얘기를 전달했다. 지그문트 프로이트가 일과 사랑이 삶의 전부라고 말했을 만큼 일과 일터에서 벌어지는 다양한 상활들을 해결하는 것은 인생의 중요한 문제다. 일터에서는 불안, 스트레스, 좌절감, 시기, 질투 등 부정 정서도 경험하지만 자긍심, 효능감, 통제력, 성취감 등 인생에 있어 최고의 순간도 함께 겪는다. 우리가 원하는 방향으로 일터에서 잘 적응하기 위해선 상황을 제대로 파악하고 효과적인 대안을 찾아내 실행하는 과정이 필요하다. 심리학이 이 과정에 완벽한 답을 줄 수는 없지만, 무엇인가 시도해 볼 수 있는 단초는 제공할 수 있다고 믿는다. 내 글이 독자들의 소중한 일터에서의 삶에 조금이라도 도움이 되었기를 바란다.”
이 책은 ‘성장’, ‘관계’, ‘성취(성공)’, ‘리더쉽’ 이라는 크게 네 개의 파트, 총 28개의 주제로 구성되어 있습니다. 28개의 각 주제는 모두 ‘착각’, ‘진실’, ‘직장 속으로’, ‘자가 진단 검사와 점수 계산’, ‘심리학이 알려주는 진실’, ‘심리학이 제안하는 슬기로운 직장 생활 팁’, ‘요약’의 순서로 구성이 되어있습니다. 일반적으로 많이 알고 있다고 생각하는 '착각'으로 시작해서 심리학이 알려주는 '진실'로 포문을 열고, ‘직장 속으로’에서는 우리 주변에서 실제로 볼 수 있을 법한 상사, 동료, 후배를 등장시켜서 독자의 관심을 블랙홀처럼 빨아들이는 마력이 있는 책이예요. (저자가 고민 많이 하신 듯…)
심리학 직장 생활을 도와줘, 목차
저자는 산업 및 조직심리학으로 석사와 박사 학위를 받은 만큼 ‘과학적 방법론’ 으로서의 심리학에 충실해요. “현상에 관해 기술”하고 “인과 관계를 설명”할 수 있으며, 이를 기반으로 “예측”에도 활용할 수 있는 과학으로서의 심리학이 우리가 “착각”하고 있거나 그럴싸한 말 뿐인 가짜 심리학으로부터 우리를 구해줄 수 있다고 말하고 있어요. 그래서 책에 보면 집착적으로 과학적 실험으로 검증된 연구 결과만을 인용하고 근거로 하여 책의 주장을 펼치고 있습니다. 저자가 매일 매일 논문 읽기로 연구를 거듭했을 나날들이 책에서 고스란히 느껴져요.
심리학 직장 생활을 도와줘, 착각
심리학 직장 생활을 도와줘, 진실
28개의 매 주제마다 ‘자가 진단 검사와 점수 계산’이 나오는데요, 독자의 참여를 유도하고 자신을 돌아보게끔 하는 몇 안되는 특이한 책이기도 해요. 각 주제별로 이 자가 진단 점수의 결과에 기반해서 (단 하나의 정답을 따르라가 아니라), 독자별로 각자 다른 각 유형별로 서로 다른 조언을 해주고 있답니다. 꽤 똑똑하고 설득력있는 책이지요?!
심리학 직장생활을 도와줘, 자가진단 및 점수 계산
만약 저보고 ‘직장 속으로’에 나왔던 고민을 듣고는 조언을 해주라고 누군가가 부탁을 했다면 어떻게 말해줘야 할까 참 고민이 많고 자신있게 대답을 못하고 머뭇거렸을거 같은게 대부분이예요. 그직장 속으로’에서 나왔던 나와 내 동료, 상사, 후배의 고민에 대해서 ‘심리학이 제안하는 슬기로운 직장 생활 팁’에서는 심리학의 과학적 연구에 기반한 통찰로 부터 얻을 수 있는 조언을 들을 수 있는데요, 상당히 설득력이 있고, 또 직장생활에 실질적인 도움이 돼는 내용들이예요! 소위 공자님 맹자님 말씀 마냥 그냥 듣기 좋은 소리, 뜬구름 잡는 소리가 아니구요, 매우 현실적이면서도 근거가 있는 팁들이예요.
심리학 직장 생활을 도와줘, 직장 속으로
심리학이 제안하는 슬기로운 직장 생활 팁
각 주제의 마지막 ‘요약’은 본문의 핵심 내용을 한번 더 요약해서 정리하고 복습하는 시간이예요. 저자가 정말 친절한 분이구나 싶어요. 아니면 세뇌를 시켜서 정말로 정말로 직장 생활에 도움이 되기를 바라는 마음이 충만한 분이라고 해야 하려나요. ㅎㅎ
심리학 직장 생활을 도와줘, 요약
499 페이지에 달하는 두꺼운 책이기에 부담이 될 수도 있는데요, 저자도 말하듯이, 목차를 보고서 먼저 읽고 싶은 주제 먼저 눈이 가는대로, 손이 가는대로 읽어나가면 좋을 거 같아요.(함정이 있다면, 모든 주제가 다 재미있을 거 같아서 뭘 먼저 읽어야 할지 참 고민이라는… ㅋㅋ) 책을 일단 읽다보면 재미있어서 계속 읽게 되더라구요. 그리고 편집이 잘 되어 있어서 가독성도 좋고, 중간 중간 쉬어가기도 좋구요.
페이스북에서 저자를 팔로우 하고 있는데요, 가요의 가사와 심리학을 연결시켜서 브런치에 쓰는 칼럼을 잊을만 하면 올려주세요. 그런데 그 글들이 참 기가 막히게 위트있고 재미있으면서도 역시 유익한 글들이예요. 박진우 저자의 ‘가요와 심리학의 만남’(?)에 관한 책도 언제가 될지는 모르겠지만 기대하게 돼요. ^^*
직장 생활을 행복하게 하고 성과를 내고자 하는 이 세상의 모든 리더, 동료, 상사, 후배들에게 이 책을 흐뭇하게 권합니다.
## (1) pd.DataFrame.dtypes: data type of each column.
df.dtypes
# x1 int64
# x2 object
# x3 bool
# x4 float64
# x5 datetime64[ns]
# dtype: object
(2) pandas DataFrame 에서 특정 데이터 유형의 칼럼을 선택하기 (include)
pd.DataFrame.select_dtypes(include=None) 메소드를 사용하여 원하는 데이터 유형을 include = 'data type' 옵션에 넣어주면 됩니다. 아래 예시에서는 차례대로 include='int64', 'object', 'bool', float64', 'datetime64' 별로 칼럼을 선택해보았습니다.
## (2) DataFrame.select_dtypes(include=None, exclude=None)
## Return a subset of the DataFrame’s columns based on the column dtypes.
## including the dtypes in include.
df.select_dtypes(include='int64') # int
# x1
# 0 1
# 1 2
# 2 3
# 3 4
df.select_dtypes(include='object')
# x2
# 0 a
# 1 b
# 2 c
# 3 d
df.select_dtypes(include='bool')
# x3
# 0 True
# 1 False
# 2 False
# 3 True
df.select_dtypes(include='float64') # float
# x4
# 0 1.0
# 1 2.0
# 2 3.0
# 3 4.0
df.select_dtypes(include='datetime64') # datetime
# x5
# 0 2023-01-01
# 1 2023-01-02
# 2 2023-01-03
# 3 2023-01-04
한꺼번에 여러개의 데이터 유형의 칼럼을 선택하고자 할 때는 df.select_dtypes(include=[dtype1, dtype2, ...]) 처럼 include 옵션에 여러개의 데이터 유형을 리스트로 넣어주면 됩니다. 아래 예시에서는 ['int64', 'float64'] 의 두 개의 숫자형 칼럼을 선택해 보았습니다.
숫자형 (numeric data type) 의 칼럼을 선택하는 또 다른 방법은 df.select_dtypes(include='number') 를 해도 됩니다.
숫자형('int64', 'float64') 의 칼럼 이름을 리스트로 반환하려면 columns 로 칼럼 이름을 가져와서 list() 로 묶어주면 됩니다.
## column names of numeric types
list(df.select_dtypes(include='number').columns)
# ['x1', 'x4']
(3) pandas DataFrame 에서 특정 데이터 유형의 칼럼을 제외하기 (exclude)
위의 (2)번이 특정 데이터 유형을 포함(include)하는 칼럼을 선택하는 것이었다면, 이번에는 특정 데이터 유형을 제외(exclude) 한 나머지 칼럼을 선택하는 방법입니다. 아래 예시에서는 'int64' 데이터 유형을 제외(exclude='int64')한 나머지 칼럼을 반환하였습니다.
## excluding the dtypes in exclude.
df.select_dtypes(exclude='int64')
# x2 x3 x4 x5
# 0 a True 1.0 2023-01-01
# 1 b False 2.0 2023-01-02
# 2 c False 3.0 2023-01-03
# 3 d True 4.0 2023-01-04
이번 포스팅에서는 리스트(List) 자료형에 대한 유용한 활용 팁 네가지를 소개하려고 합니다.
(1) 리스트의 문자형 원소를 숫자형 원소로 바꾸기 (혹은 그 반대)
(2) 리스트의 원소를 사전형의 Key:Value 기준으로 매핑하여 변환하기
(3) 리스트에서 또 다른 리스트의 겹치는 원소를 빼기
(4) 리스트 원소 정렬하기 (내림차순, 오름차순)
(1) 리스트의 문자형 원소를 숫자형 원소로 바꾸기 (혹은 그 반대)
list(map(data type, list)) 으로 리스트 내 원소의 데이터 유형을 변환할 수 있습니다. 아래는 순서대로 리스트 내 문자형 원소를 숫자형으로 변환, 숫자형 원소를 문자형 원소로 변환한 예입니다.
## convert a list with string-type elements into a list with numeric-type elements
list(map(int, ['1', '2', '3'])) # 문자형 원소
# [1, 2, 3] # --> 숫자형으로 변환됨
## convert a list with numeric-type elements into a list with string-type elements
list(map(str, [1, 2, 3])) # 숫자형 원소
# ['1', '2', '3'] # --> 문자형으로 변환됨
(2) 리스트의 원소를 사전형의 Key:Value 기준으로 매핑하여 변환하기
리스트 내 원소를 다른 값으로 변환할 때 사전형(Dictionary)의 Key:Value 매핑을 이용하면 편리합니다. List Comprehension 을 이용해서 리스트 원소별로 for loop 을 돌면서 Dictionary 의 Dict[Key] 로 Value에 접근해서 키별로 값을 매핑해서 변환된 값으로 새로운 리스트를 만들어줍니다.
converting elements in a list using Dictionary(Key: Value)
## a List
my_list = ['c', 'a', 'd', 'b']
## a Dictionary, which will be used for mapping, converting
my_dict = {
'a': 1,
'b': 2,
'c': 3,
'd': 4
}
## accessing the value in a Dictionary using the key
my_dict['a']
# 1
## converting elements in a list using a Dictionary (Key: Value)
[my_dict[k] for k in my_list]
# [3, 1, 4, 2]
(3) 리스트에서 또 다른 리스트의 겹치는 원소를 빼기
리스트와 리스트 간 중복되는 원소 값 빼기는 TypeError: unsupported operand type(s) for -: 'list' and 'list' 에러를 반환합니다.
## sample lists
a = [1, 2, 3, 4, 5]
b = [4, 5, 6, 7, 8]
## TypeError: unsupported operand type(s) for -: 'list' and 'list'
a - b
# ---------------------------------------------------------------------------
# TypeError Traceback (most recent call last)
# <ipython-input-36-4dfa3698e4b8> in <module>
# ----> 1 a- b
# TypeError: unsupported operand type(s) for -: 'list' and 'list'
리스트 간 겹치는 값을 제거하려면 먼저 리스트를 Set 으로 변환을 해주고, 두 개의 Sets 간에 빼기를 해준 다음에, 집합 간 빼기 가 된 결과를 다시 list() 를 사용해서 리스트로 최종 변환해주면 됩니다.
## substraction between lists using set
list(set(a) - set(b))
# [1, 2, 3]
list(set(b) - set(a))
# [8, 6, 7]
(4) 리스트 원소 정렬하기 (내림차순, 오름차순)
list.sort() 메소드를 사용해서 리스트 원소 (숫자형) 를 오름차순으로 정렬할 수 있습니다.
2007년 7월에 1판 1쇄로 시작해서 2022년 5월에 1판 28쇄를 기록했네요. 이미 많이 유명한 책인가봐요. 역시! ^^b
그림책하면 어린아이만을 위한 책이라고 생각하기 쉽지만, 꼭 그렇지만은 않은거 같아요. 심지어는 어른이 되어서 읽으면 더 와닿는 그림책도 있잖아요. 이번에 소개하려는 “나는 기다립니다…” 그림책도 엄마, 아빠랑 아이가 함께 읽기에 참 좋은 책이예요.
어른이 읽어도, 아니 어른이 읽으면 더 느끼는게 많은 그런 그림책인거 같아요.
먼저, 책의 형태가 가로로 길고 세로로는 짧은 특이한 모양이지요?! 책의 제목처럼 “기다림” 이라는 주제에 걸맞게 가로로 길~~~~게 기다리는 모습을 표현했어요.
나는 기다립니다. 어서 키가 크기를
그리고 표지의 그림에서 보듯이 빨간색 선이 보이잖아요. 이 빨간색 선은 뜨개질을 할 때 쓰는 끈이예요. 사람과 사람의 인연과 관계, 그리고 오~랜~ 기다림을 끈으로 표현했어요.
“나는 기다립니다” 그림책은 우리 인생에 관한 이야기예요.
“어서 키가 크기를” 기다리는 어린아이가 점점 커서 엄마 아빠와 놀고, 먹고, 크고, 그러다가 사랑하는 연인을 만나서 데이트 하고, 전쟁터에 나가서 싸우다가 부상을 입고, 전쟁이 끝나고 일상으로 돌아와 사랑하는 연인과 결혼을 하고, 아이를 낳고, 아이들과 놀고, 부부가 마냥 행복하기만 하지는 않기에 가끔은 싸우기도 하면서 “미안해”라는 한 마디를 기다리고, 커가는 아이들의 안부 전화를 기다리고, 나이가 들어가면서 아프고, 그러다가 사랑하는 이와 사별을 하고, 깊은 슬픔 속에 다시 봄이 오기를 기다리고, 장성한 아이들이 결혼을 하고, 새 식구가 될 아기를 기다린다는 이야기예요.
드라마틱한 반전이나 과장없이 담담하게 우리의 일생을 이야기해요. 빽빽한 설명없이, 기다란 책의 대부분을 하얀 색 여백으로 남겨놓은 채, 단지 한두줄의 짧은 말 몇마디로 우리의 일생을 이야기해요. 지루해서 견디기 힘든 기다림’이 아니라, 소망과 희망을 담은 ‘기다림’으로 우리의 일생을 이야기해요.
새 식구가 될 아기를 나는 기다립니다
행복하기만 한, 장밋빛 일생만을 그렸다기 보다는 우리의 진짜 일생, 일상을 담담하게 그렸어요.
아래의 그림 "나는 기다립니다. "미안해."라는 한 마디를..." 을 보면 심드렁 삐져있는 부부의 모습에 ㅋㅋ 하고 웃게 돼요.
서로에게 속상하고 화나 있어 꼬일대로 꼬여있는 마음 한켠에는 "미안해."라는 한 마디를 기다리는 우리의 연약하면서도 진솔한 모습을 보게 돼요. 정말 그래요. 좀더 마음의 여유가 있고, 좀더 성숙하고, 좀더 용기있는 사람이 먼저 "미안해."라고 말해주면, 언제 그랬냐는 듯이 화가 풀리고, 화해하고 용서하게 되고, 그러고나면 한단계 더 성숙한 우리의 모습을 보게 되잖아요.
나는 기다립니다. "미안해."라는 한 마디를...
이 그림책을 처음 봤을 때 그림이 어린아이가 대충 끄적끄적 그린 것처럼 보였어요. 그런데 그림책을 자꾸 볼 수록, 찬찬히 들여다볼 수록, 각 장의 글의 핵심을 정확하면서도 간결하게 표현해놓은 그림에 놀라게 돼요. 아래 그림에 나와있는 얼굴의 표정을 한번 보세요. 아이들의 안부전화를 기다리는 아빠의 궁금해하면서도 뭔가 흐믓해하는 마음이 전해지지 않나요? ^^
나는 기다립니다. 아이들의 안부 전화를나는 기다립니다. 아이들의 안부 전화를...
마지막 장은 “끝”이 아니라 “끈”이예요. ^_^ (원서에는 어떻게 표현이 되어있을 지 궁금해요. 한글 번역본에서만 “끝”을 “끈”으로 해놨을 듯 해서요. 안수연 옮긴이의 위트겠죠?!)
여러분은 일생을 살면서 누구를, 무엇을 기다리시나요? 저는 2022년 12월 31일, 올 해의 마지막날에 마지막 블로그 포스팅을 하면서 2023년 1월 1일 희망찬 새해를 기다려봐요.
이번 포스팅에서는 Python의 Dictionary로 Key: Value 매핑하여 문자열을 변경해주는 replace() 함수를 사용하여 SQL query 코드의 여러개의 문자열을 변경하는 방법을 소개하겠습니다.
코드가 길고 동일한 특정 변수나 테이블 이름이 여러번 나오는 경우, 수작업으로 일일이 하나씩 찾아가면서 변수나 테이블 이름을 변경하다보면 사람의 실수(human error)가 발생할 위험이 큽니다. 이럴 때 Dictionary에 (변경 전 : 변경 후) 매핑을 관리하고 컴퓨터에게 코드 변경을 시킬 수 있다면 사람의 실수를 예방하는데 도움이 될 것입니다.
먼저, 예제로 사용할 SQL query와 Key(Before, 변경 전): Value(After, 변경 후) 를 매핑한 Dictionary 를 만들어보겠습니다.
아래에는 여러개의 줄(lines)을 가지는 문자열을 하나의 줄(line)로 나누어주는 splitlines() 메소드와, Dictionary의 Key, Value를 쌍으로 반환해주는 items() 메소드를 소개하였습니다.
## splitlines()
for l in sql_query.splitlines():
print(l)
# select
# x1, x2, x3
# from mytable
# where x2 > 10
# limit 10;
## replace(a, b) method convert a string 'a' with 'b'
s = 'Hello Python World.'
s.replace('Hello', 'Hi')
# 'Hi Python World.'
# dictionary.items() ==> returns key, value
for k, v in map_dict.items():
print(k, ':', v)
# X1 : "변수1"
# X2 : "변수2"
# X3 : "변수3"
# MYTABLE : TEST_TABLE
위에서 기본적인 splitlines(), replace(), items() 메소드에 대한 사용법을 알았으니, 이제 이를 엮어서 코드에 있는 여러개의 특정 변수나 테이블 이름을 Dictionary(변경 전 이름 Key: 변경 후 이름 Value 매핑) 에서 가져와서 replace() 메소드로 변경해주는 사용자 정의함수를 만들어보겠습니다.
## User Defined Function for converting codes
## using replace() function and dictionary(Before: After mapping)
def code_converter(codes_old, map_dict):
# blank string to save the converted codes
codes_converted = ''
# converting codes using replace() function and dictionary(Before: After mapping)
for code in codes_old.splitlines():
for before, after in map_dict.items():
code = code.upper().replace(before, after)
codes_converted = codes_converted + code + '\n'
return codes_converted
## executing the UDF above
sql_query_new = code_converter(sql_query, map_dict)
print(sql_query_new)
# SELECT
# "변수1", "변수2", "변수3"
# FROM TEST_TABLE
# WHERE "변수2" > 10
# LIMIT 10;
이전 포스팅에서 스펙트럼 분석(spectrum analysis, spectral analysis, frequency domain analysis) 에 대해서 소개하였습니다. ==> https://rfriend.tistory.com/690 참조
이번 포스팅에서는 Greenplum 에서 PL/Python (Procedural Language)을 활용하여 여러개 그룹의 시계열 데이터에 대해 스펙트럼 분석을 분산병렬처리하는 방법을 소개하겠습니다. (spectrum analysis in parallel using PL/Python on Greenplum database)
spectrum analysis in parallel using PL/Python on Greenplum
(1) 다른 주파수를 가진 3개 그룹의 샘플 데이터셋 생성
먼저, spectrum 모듈에서 data_cosine() 메소드를 사용하여 주파수(frequency)가 100, 200, 250 인 3개 그룹의 코사인 파동 샘플 데이터를 생성해보겠습니다. (노이즈 A=0.1 만큼이 추가된 1,024개 코사인 데이터 포인트를 가진 예제 데이터)
## generating 3 cosine signals with frequency of (100Hz, 200Hz, 250Hz) respectively
## buried in white noise (amplitude 0.1), a length of N=1024 and the sampling is 1024Hz.
from spectrum import data_cosine
data1 = data_cosine(N=1024, A=0.1, sampling=1024, freq=100)
data2 = data_cosine(N=1024, A=0.1, sampling=1024, freq=200)
data3 = data_cosine(N=1024, A=0.1, sampling=1024, freq=250)
다음으로 Python pandas 모듈을 사용해서 'grp' 라는 칼럼에 'a', 'b', 'c'의 구분자를 추가하고, 'val' 칼럼에는 위에서 생성한 각기 다른 주파수를 가지는 3개의 샘플 데이터셋을 값으로 가지는 DataFrame을 생성합니다.
## making a pandas DataFrame with a group name
import pandas as pd
df1 = pd.DataFrame({'grp': 'a', 'val': data1})
df2 = pd.DataFrame({'grp': 'b', 'val': data2})
df3 = pd.DataFrame({'grp': 'c', 'val': data3})
df = pd.concat([df1, df2, df3])
df.shape
# (3072, 2)
df.head()
# grp val
# 0 a 1.056002
# 1 a 0.863020
# 2 a 0.463375
# 3 a -0.311347
# 4 a -0.756723
sqlalchemy 모듈의 create_engine("driver://user:password@host:port/database") 메소드를 사용해서 Greenplum 데이터베이스에 접속한 후에 pandas의 DataFrame.to_sql() 메소드를 사용해서 위에서 만든 pandas DataFrame을 Greenplum DB에 import 하도록 하겠습니다.
이때 index = True, indx_label = 'id' 를 꼭 설정해주어야만 합니다. 그렇지 않을 경우 Greenplum DB에 데이터가 import 될 때 시계열 데이터의 특성이 sequence 가 없이 순서가 뒤죽박죽이 되어서, 이후에 스펙트럼 분석을 할 수 없게 됩니다.
## importing data to Greenplum using pandas
import sqlalchemy
from sqlalchemy import create_engine
# engine = sqlalchemy.create_engine("postgresql://user:password@host:port/database")
engine = create_engine("postgresql://user:password@ip:5432/database") # set with yours
df.to_sql(name = 'data_cosine',
con = engine,
schema = 'public',
if_exists = 'replace', # {'fail', 'replace', 'append'), default to 'fail'
index = True,
index_label = 'id',
chunksize = 100,
dtype = {
'id': sqlalchemy.types.INTEGER(),
'grp': sqlalchemy.types.TEXT(),
'val': sqlalchemy.types.Float(precision=6)
})
SELECT * FROM data_cosine order by grp, id LIMIT 5;
# id grp val
# 0 a 1.056
# 1 a 0.86302
# 2 a 0.463375
# 3 a -0.311347
# 4 a -0.756723
SELECT count(1) AS cnt FROM data_cosine;
# cnt
# 3072
(2) 스펙트럼 분석을 분산병렬처리하는 PL/Python 사용자 정의 함수 정의 (UDF definition)
아래의 스펙트럼 분석은 Python scipy 모듈의 signal() 메소드를 사용하였습니다. (spectrum 모듈의 Periodogram() 메소드를 사용해도 동일합니다. https://rfriend.tistory.com/690 참조)
(Greenplum database의 master node와 segment nodes 에는 numpy와 scipy 모듈이 각각 미리 설치되어 있어야 합니다.)
사용자 정의함수의 인풋으로는 (a) 시계열 데이터 array 와 (b) sampling frequency 를 받으며, 아웃풋으로는 스펙트럼 분석을 통해 추출한 주파수(frequency, spectrum)를 텍스트(혹은 int)로 반환하도록 하였습니다.
DROP FUNCTION IF EXISTS spectrum_func(float8[], int);
CREATE OR REPLACE FUNCTION spectrum_func(x float8[], fs int)
RETURNS text
AS $$
from scipy import signal
import numpy as np
# x: Time series of measurement values
# fs: Sampling frequency of the x time series. Defaults to 1.0.
f, PSD = signal.periodogram(x, fs=fs)
freq = np.argmax(PSD)
return freq
$$ LANGUAGE 'plpythonu';
(3) 스펙트럼 분석을 분산병렬처리하는 PL/Python 사용자 정의함수 실행 (Execution of Spectrum Analysis in parallel on Greenplum)
위의 (2)번에서 정의한 스펙트럼 분석 PL/Python 사용자 정의함수 spectrum_func(x, fs) 를 Select 문으로 호출하여 실행합니다. FROM 절에는 sub query로 input에 해당하는 시계열 데이터를 ARRAY_AGG() 함수를 사용해 array 로 묶어주는데요, 이때 ARRAY_AGG(val::float8 ORDER BY id) 로 id 기준으로 반드시 시간의 순서에 맞게 정렬을 해주어야 제대로 스펙트럼 분석이 진행이 됩니다.
SELECT
grp
, spectrum_func(val_agg, 1024)::int AS freq
FROM (
SELECT
grp
, ARRAY_AGG(val::float8 ORDER BY id) AS val_agg
FROM data_cosine
GROUP BY grp
) a
ORDER BY grp;
# grp freq
# a 100
# b 200
# c 250
우리가 (1)번에서 주파수가 각 100, 200, 250인 샘플 데이터셋을 만들었는데요, 스펙트럼 분석을 해보니 정확하게 주파수를 도출해 내었네요!.