[책] 나는 심리치료사입니다 (원서: Letters to a young therapist)
메리 파이퍼 (Mary Pipher) 지음, 안진희 옮김, 위고 출판사
이번에 소개할 책은 심리치료사이면서 작가이자 부모인 메리 파이퍼(Mary Pipher)가 제자 심리치료사인 로라에게 보내 편지를 엮은 책입니다. 영어 원서의 제목인 "Letters to a young therapist" 의 뜻 그대로 말이지요.
책이 전반적으로 참 따뜻하고 또 어른스러워요. 그때그때 유행하는 심리치료 기법이나 이론에 열광하거나 치우치기보다는, 사람들 삶이 그리 단순하지만은 않다는 것을 인정하고, 균형을 잡고 조바심 내지 않으면서 기본에 충실한 심리치료의 중요성과 필요성을 말하고 있어요. 30여년 간의 환자들을 만나면서 한 심리치료의 관록이겠지요.
(왼쪽 사진은 저자 Mary Pipher)
목차에 보면 겨울, 봄, 여름, 가을의 4계절로 구분이 되어있어요. 1년여에 걸쳐서 쓴 편지이기도 하고, 우리의 인생이 4계절과 닮은 면도 있어서겠지요? 책이 빨리 읽히지 않고, 대신에 편지 하나 읽고는 한참을 골몰히 나를 돌아보고 생각을 하게 만드는 책이예요. 사람의 마음을 움직이는 작가로서 글솜씨도 이 책의 매력 포인트 중의 하나예요.
나는 심리치료사입니다. Letters to a young therapist
아래의 영어 원서("Letter to a Young Therapist", Revised Edition)의 표지와 위의 번역서 표지("나는 심리치료사입니다")도 서로 다르네요. 번역서 내용이 너무 좋아서 ebook도 사서 원서로 읽어보려고 해요.
Letters to a Young Therapist by Mary Pipher
번역서의 표지에 있는 말, "좋은 심리치료는 마음의 풍경을 바꾸어야 합니다". 마음의 풍경을 바꾼다는 것은 그리 쉽지많은 않은 일이겠지만, 영향이 크다는 의미겠지요?
p69. 좋은 심리치료는 마음의 풍경을 바꾸어야 합니다. 심리치료를 받은 이후 사람들은 세상을 다른 방식으로 살아가게 됩니다. 이 모든 것운 균형의 문제입니다. 저는 소심하고 불안감이 심한 사람에게는 더 강해지고 대담해지라고 격려합니다. 또한 남자다움을 과시하는 남자들에게는 좀 더 온화해지라고 좀 더 자기표현을 잘할 수 있도록 독려합니다.
저자는 감사하며 사는 행복을 본인이 누리고 있으며, 타인의 성장에 큰 관심과 애정을 가지고 있어요.
p72. 빅토리아 시대의 시인인 엘리자베스 배럿 브라우닝은 이렇게 말했습니다. “세상은 천국으로 가득 차 있다.” 나이를 점점 먹어가고 모든 현상에서 삶을 더 가치 있게 여기게 될수록, 저는 파랗고 푸른 행성에서 보내는 시간이라는 선물을 받은 것이 더없이 귀중하게 느껴집니다. 제가 생각하는 가장 큰 비극은 아름다운 어떤 존재가 성장하고 싶어 하는데 다른 어떤 존재가 그것을 저지할 때입니다. 저는 손녀 케이트가 세상을 사랑하고 세상을 지키기 위해 노력하는 한 인간으로 활짝 꽃피우기를 바랍니다.
저자는 일상의 루틴을 지치지 않고, 꾸준히 하는 것의 중요성에 대해서도 강조하고 있어요. 정말 그렇지요?!
p77. 지속성은 우리 직업에서 과소평가된 자질입니다. 심리치료의 일부는 평범한 일을 꾸준히 하는 것입니다. 대식증 환자의 식단 일지 확인하기, 우울증에 걸린 대학생에게 운동하라고 권하기, 아이 엄마가 아이에게 "잠깐만”을 남용하지는 않는지 확인하기. 이런 일들은 마법처럼 느껴지거나 인상적인 영상을 남기지는 않습니다. 허지만 매일 이를 닦고 신선한 야채를 먹어야 하는 것과 마찬가지로, 이런 일들은 매우 중요합니다.
99. 우리가 내담자들을 위해 할 수 있는 최선 중 하나는 그들에게 일상을 건강하고 규칙적으로 꾸리라고 격려하는 것입니다. 이런 일상에는 명상, 마사지, 운동 같은 활동들이 포함될 수 있습니다. … 이런 리추얼들은 사람들에게 기대할 만한 무언가를 제공해줍니다.
저자는 성공적인 심리치료의 핵심에 사람 사이의 관계(relation)의 '연결'(connection)에 있다고 말하고 있어요.
82. 성공적인 부동산 투자의 비결이 ‘입지’라면 우리 일의 비결은 ‘연결’이라고 할 수 있습니다. 우리는 내담자들의 정서, 행동, 생각을 서로 연결시켜야 합니다. 우리는 내담자들이 심리치료사, 그들의 가족, 그리고 다른 사람들과 연결되기를 바랍니다.
114. 하지만 무엇보다 당신이 주로 그녀에게 이야기하거나 조언하게 될 것은, 테네시 윌리엄스의 말을 빌리자면 “우리는 버팀으로써 버틴다”하는 사실일 것입니다.
아래 문장은 제가 이 책에서 제일 좋아하는 구절 중의 하나예요. 40대가 되고 보니 더욱 와닿는 것 같아요.
117. 이런저런 조언으로 책 한 권을 채울 수도 있겠지만 제 생각은 다음의 세 단어로 요약될 수 있습니다. “스스로의 삶을 사세요.” 일에만 몰두하지 말고 다양한 인간관계를 맺고 취미생활을 즐기세요. 당신을 웃게 만들고 당신의 배터리를 재충전해주는 일들을 하세요. 아기를 꽉 껴안거나, 요리수업을 듣거나, 영화감상모임에 가입하세요.
168. 사람들이 자신의 유년기로부터 가장 즐겁게 기억하는 세 가지는 가족식사, 야외활동, 가족여행입니다. 그러니, 로라, 당신이 상담하는 가족들에게 함께 밥을 먹고, 함께 여행을 떠나고, 자연에서 함께 시간을 보내라고 권유하기 바랍니다.
우리는 미디어를 통해서 결혼의 환상에 많이 노출되어 있고, 또 많이들 결혼에 대한 환상을 가지고 있잖아요. 그런데 저자는 결혼에 대한 환상을 품지 말라고 경고하고 있어요. 환상은 말 그대로 현실이 아니니깐요.
136. 로라, 내담자들에게 결혼에 대해 환상을 품지 말라고 경고하세요. 사람을 평가하기 위해서는, 여러 상황 속에서 그 사람을 지켜봐야 합니다. 내담자들에게 애인의 가족과 친구들을 만나보라고 권유하세요. 그리고 가족이나 친구가 없는 사람을 조심하라고 하세요. 여성들에게는 남성이 다른 여성에 대해 어떻게 이야기하는지 잘 들어보고 그들이 자신의 어머니를 어떻게 대하는지 잘 살펴보라고 하세요. 또한 애인이 과거의 인연들을 어떻게 묘사하는지 주위를 기울여야 합니다. 상대를 비난하는 사람은 좋지 않습니다. 질투가 심하거나, 비밀이 많거나, 다른 사람을 조종하려 드는 사람도 마찬가지입니다. 자꾸 경계를 넘고 한계를 존중하지 않는 상대는 시간이 흐르면서 폭력을 휘두를 가능성이 높습니다. 지나치게 빨리 사이가 너무 뜨거워지는 것 또한 좋은 징조가 아닙니다. 안정된 사람들은 천천히 나아갑니다.
아래 글은 읽으면서 키득거리면서 웃었어요. 힘빼고 있는 모습 그대로 자연스럽게 상담하고, 글쓰고, 사람 만나기! ^__^
188. 심리상담이나 글쓰기를 할 때 지나치게 열심히 노력한다는 것은 잠을 잘 때나 오루가즘을 느낄 때, 다른 사람한테 호감을 얻고자 할 때 지나치게 열심히 노력하는 것과 마찬가지입니다. 아무 효과가 없죠.
저자는 '자신이 중시하는 가치'에 대해서 솔직하게 내담자에게 표현해야 한다고 말하는데요, 저도 동의해요. 과연 가치중립적일 수가 있을까 싶거든요.
200. 일부 이론가들의 주장에도 불구하고, 저는 우리가 가치중립을 표방할 수도 없고 또 가치중립적이 되어서도 안 된다고 생각합니다. 우리에게는 자신이 중시하는 가치에 대해 내담자들에게 솔직하게 표현해야 하는 윤리적 의무가 있습니다.
사람들은 다 똑같지요? 자신의 존재 자체가 거부당한다고 느낄 때 반발이 생기고 자신을 보호하고자 하는 본능이 불끈 솓아오른다는 점이요. 이게 '변화의 역설'이라고 하는 거군요.
214. 심리학자 칼 로저스는 ‘변화의 역설’에 대해 말했습니다. 사람들은 자신이 있는 그대로의 모습으로 받아들여지고 있다고 느낄 때에민 변화에 대해 진지하게 고민한다는 것입니다. 변화에 대한 저항은 인간의 자연스러운 조건입니다. 누가 어떤 사람이 “비판을 잘 받아들이지 않는다”라고 흉을 볼 때마다 저는 이렇게 반문하고 싶습니다. “비판을 잘 받아들이는 사람이 누가 있겠습니까?”
'말을 물가로 데려갈 수는 있지만, 말에게 물을 마시게 할 수는 없다'는 속담도 있잖아요. 변화의 주체는 결국은 자기 자신!
224. 그녀는 제 마술이 나타나기만을 기다리고 있었던 것입니다. 저는 이렇게 말했어야 했습니다.“저는 마술사가 아닙니다. 오직 당신만이 문제를 해결할 수 있어요.”
저자는 100% 만땅의 삶 대신에 70% 정도 달성하고 30% 정도는 여유가 있는 삶이 지속가능하다고 말하고 있어요. 완벽하려고 하다간, 부러지는 수가 있지요. '최대자 maximizers' 보다는 "충분히 괜찮아"라고 현재에 감사하는 '만족자 satisfizers'가 행복하게 삶을 누리는 사람이겠지요. 저도 이번 블로그 포스팅 "이정도면 충분히 괜찮아"라고 스스로 만족하는 걸로... ㅎㅎ
227. 부모이자 심리치료사이자 작가로서, 저는 목표를 70퍼센트 정도 달성합니다. 저 자신에게 이보다 더 많은 것을 기대한다면 중년의 인간이 발휘할 수 있는 수준 이상의 완벽을 기대하는 것일지 모릅니다.
236. 연구 결과 사람들은 기본적으로 두 가지 유형이 있다고 합니다. 바로 ‘만족자satisfizers’와 ‘최대자maximizers’입니다. 최대자는 항상 최고의 선택을 내리고 싶어하는 사람입니다. 반면 만족자는 “충분히 괜찮아”라고 말합니다. (중략) 인간이 겪는 고통의 대부분은 95퍼센트의 좋은 삶을 살면서도 나머지 5퍼센트를 달성하려고 할때 생깁니다.
다시한번 말하지만, 저자의 글은 참 따뜻하면서도 사람에 대한 애정이 느껴져요. "가장 순수한 형태의 사랑"인 심리치료사로서 자부심과 긍지, 보람이 전해져요.
248. 이 책을 쓰면서 저는 심리치료사로 일하는 것이 제게 있어서 단순히 생계를 유지하는 수단을 넘어서 저 자신의 삶을 일구어나가는 것 그 자체라는 사실을 깨달았습니다. 간단히 말해서, 심리상담은 다른 사람에게 관심을 기울이는 하나의 방식, 가장 순수한 형태의 사랑이죠.
비단 심리치료사나 심리치료/상담을 전공으로 하려는 학생 뿐만이 아니라, 심리치료/상담에 관심이 있는 일반인들에게도 충분히 공감이 되고 도움이 되는 생각거리와 지혜를 던져주는 책이기에 추천해요.
이번 포스팅에서는 텍스트를 컴퓨터가 이해할 수 있도록 재표현해주는 text representation 방법 중에서 vectorization approaches 의 하나로서 TF-IDF (Term Frequency - Inverse Document Frequency) 의 개념, 수식에 대해서 알아보고, 간단한 예제 텍스트를 사용해서 설명을 해보겠습니다. 그리고 Python 의 Scikit-Learn 모듈을 사용해서 분석을 해보겠습니다.
(1) TF-IDF (Term Frequency - Inverse Document Frequency) 개념 및 예시
(2) Python scikit-learn 모듈을 사용한 실습
(1) TF-IDF (Term Frequency - Inverse Document Frequency) 개념 및 예시
vectorization apporached 의 text representation 방법으로는
- One-Hot Encoding
- Bag of Words (BoW)
- Bag of N-Grams (BoN)
- Term Frequency - Inverse Document Frequency (TF-IDF)
등이 있습니다.
이중에서 One-Hot Encoding, Bag of Words (BoW), Bag of N-Grams (BoN) 의 방법은 텍스트 안의 모든 단어를 동일하게 중요하다고 간주합니다. 반면에, TF-IDF 는 문서와 말뭉치에서 어떤 단어가 주어졌을 때 다른 단어 대비 상대적인 중요도를 측정한다는 차이가 있습니다.
만약 어떤 단어 w 가 문서 Di 에서 자주 나타나지만, 다른 문서 Dj 에서는 별로 나타나지 않을 때, 단어 w 는 문서 Di 에서 매우 중요하다고 볼 수 있습니다.
- TF의 핵심 개념: 단어 w의 중요도는 문서 d(i) 에서 출현하는 빈도에 비례해서 증가.
- IDF의 핵심 개념: 반면에, 단어 w가 말뭉치의 중요도는 다른 문서 d(j) 에서의 출현 빈도에는 비례해서 감소.
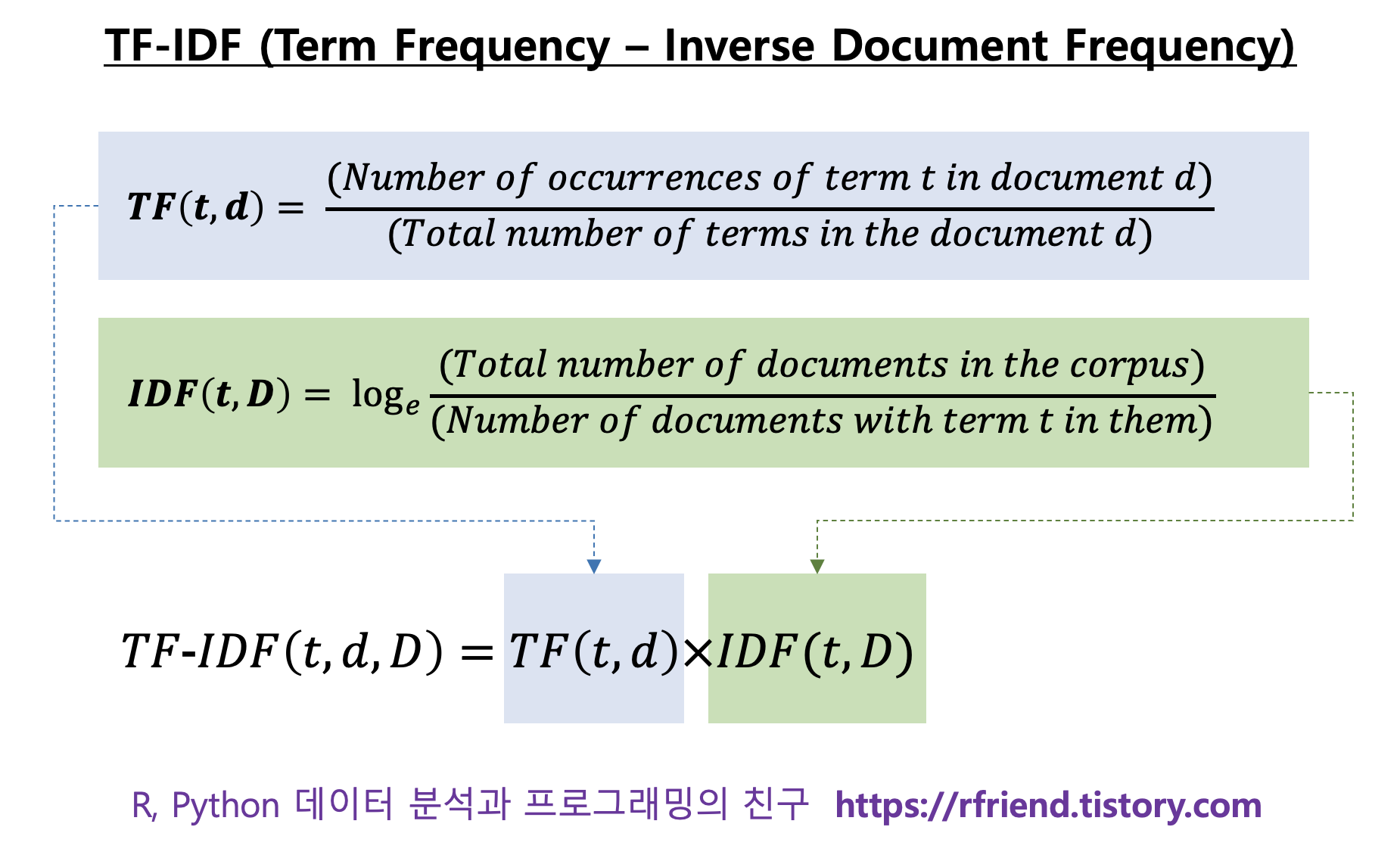
TF-IDF 점수는 TF 점수와 IDF 점수를 곱해서 구합니다. (수식은 아래 참조)
TF-IDF
TF (Term Freqneucy) 는 문서(document)에서 주어진 단어(term t) 가 얼마나 자주 출현하는지를 측정합니다. 말뭉치(corpus) 안의 여러 문서들은 길이가 서로 다를텐데요, 아무래도 주어진 단어는 길이가 짧은 문서보다는 길이가 긴 문서에서 더 자주 출현할 가능성이 높습니다. 따라서 이런 문제를 해결하기 위해 문서 d(i)에서 단어 t (term t)의 출현 빈도를 문서 d(i)의 총 단어의 수로 나누어서 표준화를 해줍니다.
TF(t, d) = (문서 d 에서 단어 t 의 출현 빈도) / (문서 d 에서 총 단어의 수)
IDF (Inverse Document Frequency) 는 말뭉치(corpus)에서 단어 t 의 중요도를 측정합니다. 앞서 TF 를 계산할 때 모든 단어에는 동일한 중요도(가중치)가 부여되었습니다. 하지만 관사(a, the), be 동사(is, am, are) 등의 불용어(stop words)와 같이 문서에서 자주 출현하지만 별로 중요하지 않은 단어도 있습니다. 이런 문제를 해결하기 위해, IDF 는 말뭉치의 여러 문서에 공통적으로 출현하는 단어에 대해서는 중요도(가중치)를 낮추고, 반대로 말뭉치의 여러 문서 중에서 일부 문서에만 드물게 출현하는 단어에 대해서는 중요도(가중치)를 높입니다.
IDF(t, D) = log(말뭉치에서 총 문서의 개수 / 단어 t를 포함하는 문서의 개수)
TF-IDF score 는 위의 TF점수와 IDF 점수를 곱해주면 됩니다.
TF-IDF(t, d, D) = TF(t, d) x IDF(t, D)
아래에는 4개의 문서에 나오는 단어를 추출하여 만든 말뭉치를 가지고 TF-IDF 점수를 계산해본 예제입니다.
"Practical Natural Language Processing" (Sowmya Vajjala, et.al. 저) 책의 예제를 사용했는데요, 원서의 계산이 틀렸길레 수정해서 올립니다. (원서에서는 dog와 man의 TF score 가 틀리게 계산됨. IDF score 계산할 때는 밑이 e 이 자연 log 가 아니라 밑이 2인 log를 사용해서 계산함. 암튼, 원서 계산 다 틀렸음)
TF-IDF example
Bag of Words(BoW)와 비슷하게 TF-IDF 벡터는 코사인 거리(cosine distance)나 유클리디언 거리(euclidean distance) 를 사용하여 두 텍스트의 유사성을 계산하는데 사용할 수 있습니다. TF-IDF 는 정보 추출(information retrieval) 이나 텍스트 분류(text classification)에 많이 사용되고 있습니다.
TF-IDF 는 단어 간의 관계를 파악하는데는 한계가 있습니다. 그리고 TF-IDF 는 텍스트를 희소하고 고차원(sparse and high-dimensional)의 행렬로 표현하므로 차원의 저주(curse of dimensionality) 문제가 있습니다. 또한 학습 데이터셋에 없는 단어에 대해서는 처리를 못하는 한계(Out of Vocabulary problem)가 있습니다.
(2) Python scikit-learn 모듈을 사용한 실습
먼저, 실습에 사용할 텍스트로서 4개 문서의 간단한 문장을 아래와 같이 리스트로 입력해주고, 대문자를 소문자로 변환하고 불용어(stop words)인 마침표(.)는 없애주는 텍스트 데이터 전처리를 해보겠습니다.
앞에서 전처리한 텍스트 리스트를 TfidfVectorizer().fit_transform() 메소드를 사용하면 단어 추출과 TF-IDF 점수 계산이 한꺼번에 됩니다.
- tfidf.fit_transform() : 말뭉치 안의 단어 추출 및 TF-IDF 점수 계산
- tfidf.get_feature_names() : 말뭉치 안의 모든 단어 리스트
- sorted(tfidf.vocabulary_.items(), key=lambda x: x[1]) : 단어 사전을 index 기준으로 내림차순 정렬
- tfidf.idf_ : IDF score
##------------------------------
## TF-IDF using sklearn module
##------------------------------
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer()
bow_rep_tfidf = tfidf.fit_transform(processed_docs)
## All words in the vocabulary.
print(tfidf.get_feature_names())
#[Out] ['bites', 'dog', 'eats', 'food', 'man', 'meat']
## sorting vocabulary dict by values in ascending order
sorted(tfidf.vocabulary_.items(), key=lambda x: x[1])
#[Out] [('bites', 0), ('dog', 1), ('eats', 2), ('food', 3), ('man', 4), ('meat', 5)]
## IDF for all words in the vocabulary
print("IDF :",tfidf.idf_)
#[Out] IDF : [1.51082562 1.22314355 1.51082562 1.91629073 1.22314355 1.91629073]
본문 상단에 제시한 예제에서 손으로 계산한 TF-IDF 점수와 아래에 Scikit-learn 의 TfidfVedtorizer() 메소드로 계산한 TF-IDF 점수가 서로 다릅니다.
두가지 이유가 있는데요, 첫째 Scikit-learn 에서 사용한 IDF 수식이 조금 다릅니다. (소스코드 공식은 여기 참조). 분모가 '0' 일때 'Zero Division Error' 가 발생하지 않도록 분모에 '1'을 더해주었으며, 분자에도 log(0) 도 계산이 안되므로 에러가 발생하지 않도록 분자에도 '1' 을 더해주었고, 전체 값이 '1'을 더해주었습니다.
Scikit-Learn의 TF-IDF score 가 원래 TF-IDF 결과와 다른 두번째 이유는 위의 Scikit-Learn 의 TF-IDF 점수 계산 결과를 유클리디언 거리를 사용해서 표준화를 해주기 때문입니다. (자세한 설명은 여기 참조)
## IDF for all words in the vocabulary
## “Sklearn’s TF-IDF” vs “Standard TF-IDF”
## : https://towardsdatascience.com/how-sklearns-tf-idf-is-different-from-the-standard-tf-idf-275fa582e73d
## Scikit-Learn's IDF: IDF(t) = log((1+n)/(1+df(t))) + 1
## normalization by the Euclidean norm
print("IDF :",tfidf.idf_)
#[Out] IDF : [1.51082562 1.22314355 1.51082562 1.91629073 1.22314355 1.91629073]
# IDF for 'dog' word
# number of documents, nN=4
# number of documents which include term t, df(t) = 3
import numpy as np
np.log((1+4)/(1+3)) + 1 # IDF(t) = log((1+n)/(1+df(t))) + 1
#[Out] 1.2231435513142097
- bow_rep_tfidf.toarray() : 말뭉치의 모든 문서 내 단어에 대한 TF-IDF 점수를 2차원 배열로 표현
## TF-IDF representation for all documents in our corpus
print("TF-IDF representation for all documents in our corpus\n", bow_rep_tfidf.toarray())
#[Out] TF-IDF representation for all documents in our corpus
# [[0.65782931 0.53256952 0. 0. 0.53256952 0. ]
# [0.65782931 0.53256952 0. 0. 0.53256952 0. ]
# [0. 0.44809973 0.55349232 0. 0. 0.70203482]
# [0. 0. 0.55349232 0.70203482 0.44809973 0. ]]
- tfidf.transform(new document) : 새로운 문서 내 단어에 대한 TF-IDF 점수 계산
## Get the TF-IDF score using this vocabulary, for a new text
temp = tfidf.transform(["dog and man are friends"])
print("Tfidf representation for 'dog and man are friends':\n", temp.toarray())
#[Out] Tfidf representation for 'dog and man are friends':
# [[0. 0.70710678 0. 0. 0.70710678 0. ]]
[Reference]
(1) Sowmya Vajjala, et.al., "Practical Natural Language Processing", O'Reilly
1. 컨테이너는 무엇이고, 도커는 무엇인가? (What is a Container and Docker?)
2. 왜 도커인가 (Why Docker?)
3. 도커 컨테이너 vs. 도커 이미지 (Docker Container vs. Docker Image)
1. 컨테이너는 무엇이고, 도커는 무엇인가? (What is a Container and Docker?)
컨테이너(Container)는 애플리케이션이 컴퓨팅 환경 간에 신속하고 신뢰성 있게 실행될 수 있도록 코드와 그 모든 종속성 있는 것들을 패키징하는 소프트웨어의 표준 단위입니다.도커 컨테이너 이미지(Docker container)는 어플리케이션 실행에 필요한 모든 것(코드, 런타임, 시스템 도구, 시스템 라이브러리 및 설정)을 포함 가볍고 스탠드얼론의 실행 가능한 소프트웨어 패키지입니다.
Docker (www.docker.com)
컨테이너 이미지는 실행 시 컨테이너가 되며, 도커 컨테이너의 경우 이미지가 도커 엔진에서 실행되면 컨테이너가 됩니다. 컨테이너형 소프트웨어는 Linux 기반 애플리케이션과 Windows 기반 애플리케이션 모두에서 사용할 수 있으며, 인프라스트럭처에 관계없이 항상 동일하게 실행됩니다. 컨테이너는 소프트웨어를 환경에서 격리하고 개발 및 스테이징 간의 차이에도 불구하고 균등하게 작동하도록 보장합니다.
도커 컨테이너 기술은 2013년 오픈 소스 도커 엔진으로 출시되었습니다. 도커 컨테이너는 Linux, Windows, 데이터센터, 클라우드, 서버리스 등 어디에서나 사용할 수 있습니다.[1]
Docker is Everywhere (www.docker.com)
2. 왜 도커 인가? (Why Docker?)
오늘날 앱을 개발하려면 코드 작성 이상의 것이 필요합니다. 라이프 사이클 단계별로 여러 언어, 프레임워크, 아키텍처 및 도구 간의 불연속적인 인터페이스로 인해 엄청난 복잡성이 발생합니다. Docker는 워크플로우를 단순화하고 가속화하는 동시에 개발자가 각 프로젝트에 사용할 툴, 애플리케이션 스택 및 구현 환경을 자유롭게 선택할 수 있도록 지원합니다.
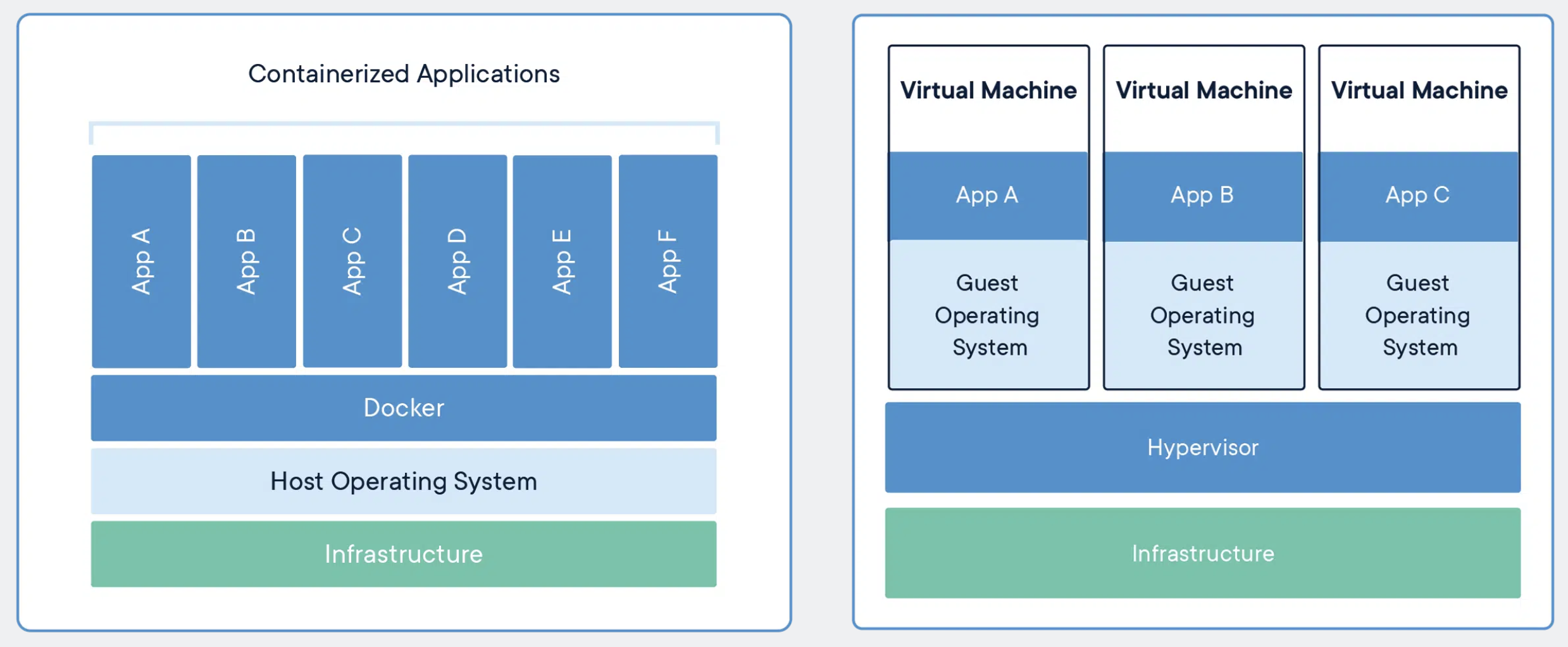
도커 컨테이너(Docker Container)와 가상 머신(Virtual Machine)은 리소스 분리 및 할당에 유사한 이점이 있지만, 도커 컨테이너는 하드웨어 대신 운영 체제(Operating System)를 가상화하기 때문에 다르게 작동합니다. 도커 컨테이너가 가상머신보다 휴대성과 효율이 뛰어납니다. [1]
Docker vs. Virtual Machine (www.docker.com)
기존의 가상화 기술은 하이퍼바이저를 이용해 여러 개의 운영체제를 하나의 호스트에서 생성해 사용하는 방식이었습니다. 이러한 여러 개의 운영체제는 가상 머신이라는 단위로 구별되고, 각 가상 머신에는 우분투, CentOS 등의 운영체제가 설치되어 사용됩니다. 하이퍼바이저에 의해 생성되고 관리되는 운영체제는 게스트 운영체제(Guest OS)라고 하며, 각 게스트 운영체제는 다른 게스트 운영체제와는 완전히 독립된 공간과 시스템 자원을 할당받아 사용합니다. 이러한 가상화 방식을 사용할 수 있는 대표적인 가상화 툴로 VirtualBox, VMware 등이 있습니다.
그러나 각종 시스템 자원을 가상화하고 독립된 공간을 생성하는 작업은 하이퍼바이저를 반드시 거쳐기 때문에 일반 호스트에 비해 성능의 손실이 발생합니다. 그뿐만 아니라 가상 머신은 게스트 운영체제를 사용하기 위한 라이브러리, 커널 등을 전부 포함하기 때문에 가상 머신을 배포하기 위한 이미지로 만들었을 때 이미지의 크기 또한 커집니다. 즉, 가상 머신은 완벽한 운영체제를 생성할 수 있다는 장점은 있지만 일반 호스트에 비해 성능 손실이 있으며, 수 기가바이트에 달하는 가상 머신 이미지를 애플리케이션으로 배포하기는 부담스럽다는 단점이 있습니다.
이에 비해 도커 컨테이너는 가상화된 공간을 생성하기 위해 리눅스의 자체 기능인 chroot, namespace, cgroup 을 사용함으로써 프로세스 단위의 격리 환경을 만들기 때문에 성능 손실이 거의 없습니다. 컨테이너에 필요한 커널은 호스트의 커널을 공유해 사용하고, 컨테이너 안에는 애플리케이션을 구도하는 데 필요한 라이브러리 및 실행 파일만 존재하기 때문에 컨테이너를 이미지로 만들었을 때 이미지의 용량 또한 가상 머시에 비해 대폭 줄어듭니다. 따라서 컨테이너를 이미지로 만들어 배포하는 시간이 가상 머신에 비해 빠르며, 가상화된 공간을 사용할 때의 성능 손실도 거의 없다는 장점이 있습니다. [2]
3. 도커 컨테이너 vs. 도커 이미지 (Docker Container vs. Docker Image)
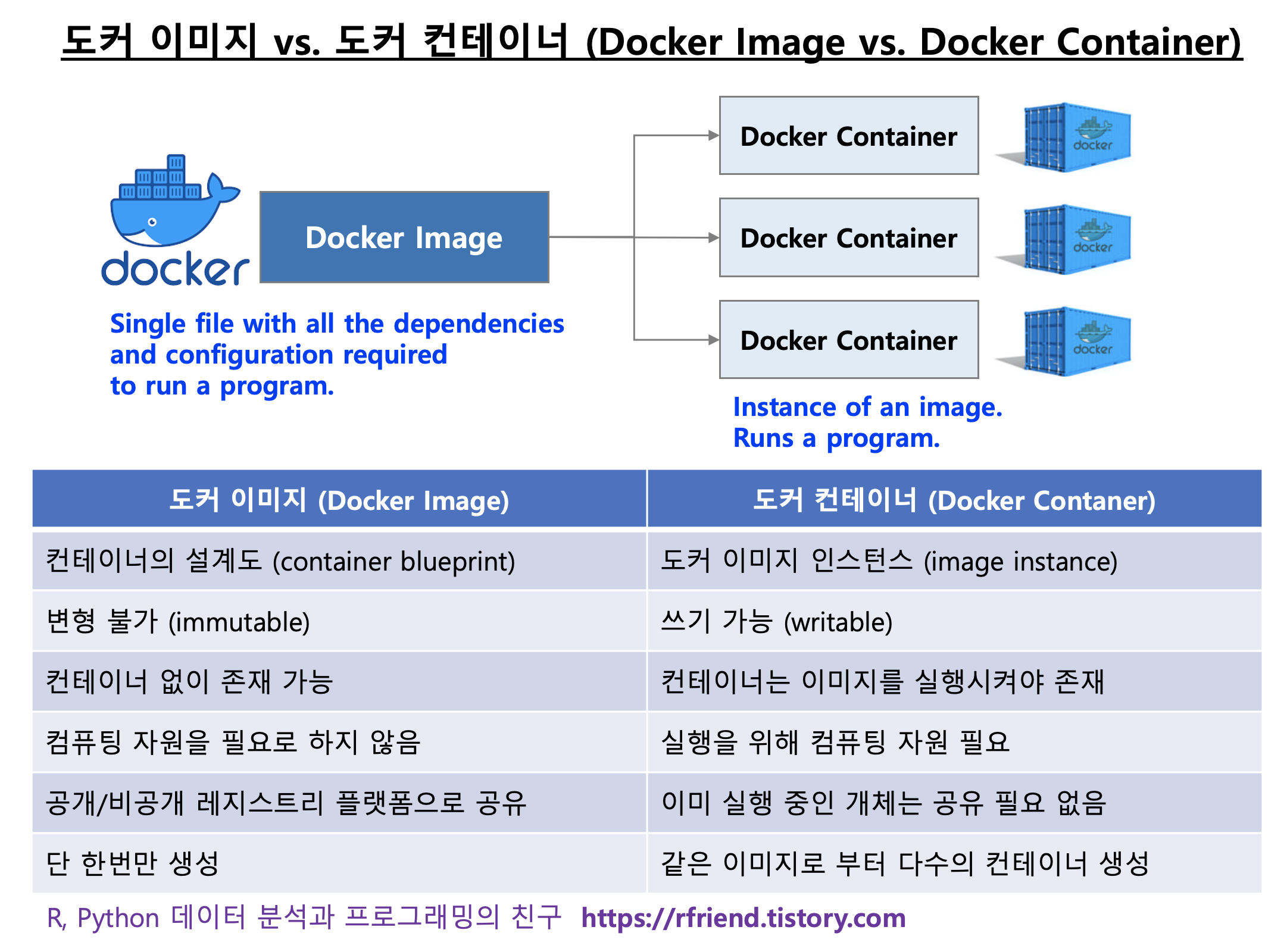
Docker 이미지와 컨테이너가 함께 작동하여 혁신적인 Docker 기술의 잠재력을 최대한 끌어낼 수 있습니다. 하지만, 그들은 특히 초보자에게는 알아차리기 어려울 수 있는 미묘한 차이를 가지고 있습니다.
도커 이미지(Docker Image)는 컨테이너(Container)를 만드는 데 사용되는 읽기 전용 템플릿(Read-only templates)입니다. 컨테이너(Docner Container)는 이러한 템플릿에서 생성된 배포된 인스턴스(Deployed Instances)입니다.
그들의 차이점을 비교하는 간단한 비유는 Docker 이미지를 레시피로 생각하고 Docker Container를 그 레시피에서 준비된 케이크로 생각하는 것이다. 그 요리법은 케이크를 굽는 방법을 설명하고 있다. 만약 당신이 그 레서피를 따라서 요리를 하지 않는다면, 당신은 그 케이크를 먹는 것을 즐길 수 없습니다. 마찬가지로 Docker 이미지의 지침에 따라 Docker Container 를 만들고 시작해야 Docker의 이점을 누릴 수 있습니다. 하나의 레시피에서 가능한 한 많은 케이크를 구울 수 있는 것처럼, 하나의 Docker Image로 여러 개의 Docker Container를 만들 수 있습니다. 하지만 레시피를 바꿔도 기존 케이크의 맛은 변하지 않고, 새로 구운 케이크만 수정된 레시피를 사용할 것입니다. 마찬가지로, Docker Image를 변경해도 이미 실행 중인 Docker Container에는 영향을 미치지 않습니다.
Docker Image와 Container 간의 차이점을 설명하는 표는 다음과 같습니다. [3] [4]
도커 이미지 vs. 도커 컨테이너 (docker image vs. docker container)
이번 포스팅에서는 Python의 SciPy 모듈을 사용해서 각 원소 간 짝을 이루어서 유클리디언 거리를 계산(calculating pair-wise distances)하는 방법을 소개하겠습니다. 본문에서 scipy 의 거리 계산함수로서 pdist()와 cdist()를 소개할건데요, 반환하는 결과물의 형태에 따라 적절한 것을 선택해서 사용하면 되겠습니다. 마지막으로 scipy 에서 제공하는 거리를 계산하는 기준(distance metric)에 대해서 알아보겠습니다.
(Scikit-Learn 모듈에도 거리 계산 함수가 있는데요, SciPy 모듈에 거리 측정 기준이 더 많아서 SciPy 모듈로 소개합니다.)
(1) scipy.spatial.distance.pdist(): returns condensed distance matrix Y.
(2) scipy.spatial.distance.cdist(): returns M by N distance matrix.
(3) 거리 측정 기준(distance metric)
calculating pair-wise distances using python SciPy
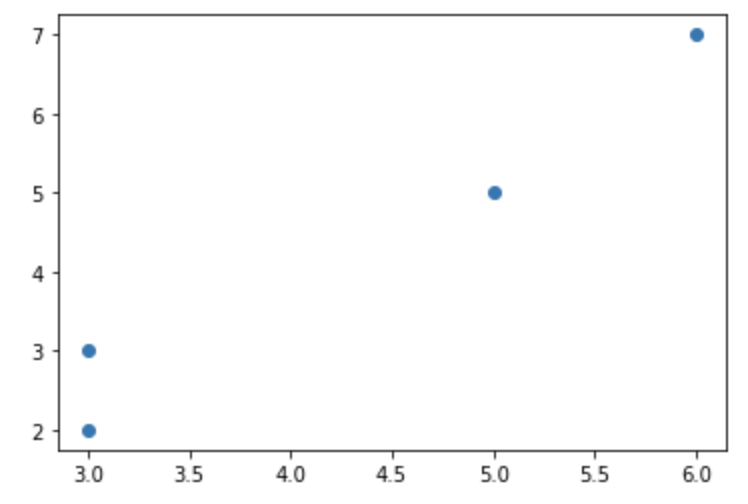
먼저, 예제로 사용할 간단한 샘플 데이터셋으로서 x와 y의 두 개의 칼럼에 대해 4개의 원소를 가지는 numpy array 로 만들어보겠습니다. 그리고 matplotlib 으로 산점도를 그려서 4개의 원소에 대해 x와 y의 좌표에 산점도를 그려서 확인해보겠습니다.
ID
x
y
1
3
2
2
3
3
3
5
5
4
6
7
import numpy as np
import matplotlib.pyplot as plt
X = np.array([
# x, y
[3, 2], # ID 1
[3, 3], # ID 2
[5, 5], # ID 3
[6, 7], # ID 4
])
plt.plot(X[:, 0], X[:, 1], 'o')
plt.show()
scatter plot
(1) scipy.spatial.distance.pdist(X, metric='euclidean'): returns condensed distance matrix Y.
scipy.spatial.distance.pdist(X, metric='euclidean') 함수는 X 벡터 또는 행렬에서 각 원소(관측치) 간 짝을 이루어서 유클리디언 거리를 계산해줍니다. 그리고 응축된 형태의 거리 행렬(condensed distance matrix)을 반환합니다. 아래의 (1)번 pdist() 계산 결과가 반환된 형태를 (2) cdist() 로 계산 결과가 반환된 형태와 비교해보면 이해가 쉬울 거예요.
pdist(X, metric='eudlidean') 계산 결과는 각 관측치 간 짝을 이룬 거리 계산이므로 아래 값들의 계산 결과입니다. 거리 계산 결과는 자기 자신과의 거리인 대각행렬 부분은 제외하고, 각 원소 간 쌍을 이룬 부분에 대해서만 관측치의 순서에 따라서 반환되었습니다. (예: ID1 : ID2, ID1 : ID3, ID1 : ID4, ID2 : ID3, ID2 : ID4, ID3 : ID4)
# scipy.spatial.distance.pdist(X, metric='euclidean', *, out=None, **kwargs)
# : Pairwise distances between observations in n-dimensional space.
# : Returns a condensed distance matrix Y.
from scipy.spatial import distance
X_pdist = distance.pdist(X, metric='euclidean')
X_pdist
# array([1. , 3.60555128, 5.83095189, 2.82842712, 5. ,
# 2.23606798])
(2) scipy.spatial.distance.cdist(): returns M by N distance matrix.
scipy.spatial.distance.cdist(XA, XB, metric='euclidean') 함수는 원소(관측치) 간 쌍을 이루어 유클리디언 거리를 계산합니다만, 위의 (1) pdist() 함수와는 달리,
- (a) input 으로 XA, XB 의 두 개의 행렬 (혹은 벡터)를 받으며, (vs. pdist() 는 X 행렬 한 개만 받음)
- (b) output 으로 M by N 거리 행렬을 반환합니다. (vs. pdist() 는 condensed distance matrix 를 반환)
하는 차이점이 있습니다. 위의 (1)번 scipy.spatial.distance.pdist() 함수와 (2) scipy.spatial.distance.cdist() 함수의 input, output을 비교해보면 이해가 쉬울 거예요.
# scipy.spatial.distance.cdist(XA, XB, metric='euclidean', *, out=None, **kwargs)
# : Compute distance between each pair of the two collections of inputs.
# : A M by N distance matrix is returned.(M for X, N for Y)
from scipy.spatial import distance
X_cdist = distance.cdist(X, X, metric='euclidean')
X_cdist
# array([[0. , 1. , 5.83095189, 3.60555128],
# [1. , 0. , 5. , 2.82842712],
# [5.83095189, 5. , 0. , 2.23606798],
# [3.60555128, 2.82842712, 2.23606798, 0. ]])
(3) 거리 측정 기준(distance metric)
위의 (1), (2)번에서는 거리 측정 기준으로 디폴트 옵션인 '유클리디언 거리(metric='euclidean distance') 를 사용해서 원소 간 쌍을 이룬 거리를 계산하였습니다.
scipy 모듈은 유클리디어 거리 외에도 다양한 거리 측정 기준을 제공합니다. (맨하탄 거리, 표준화 거리, 마할라노비스 거리, 자카드 거리, 코사인 거리, 편집 거리에 대해서는 아래의 Reference 의 링크를 참고하세요.)
[ scipy.spatial.distance.pdist(), cdist() 함수의 metric options (알파벳 순서) ]
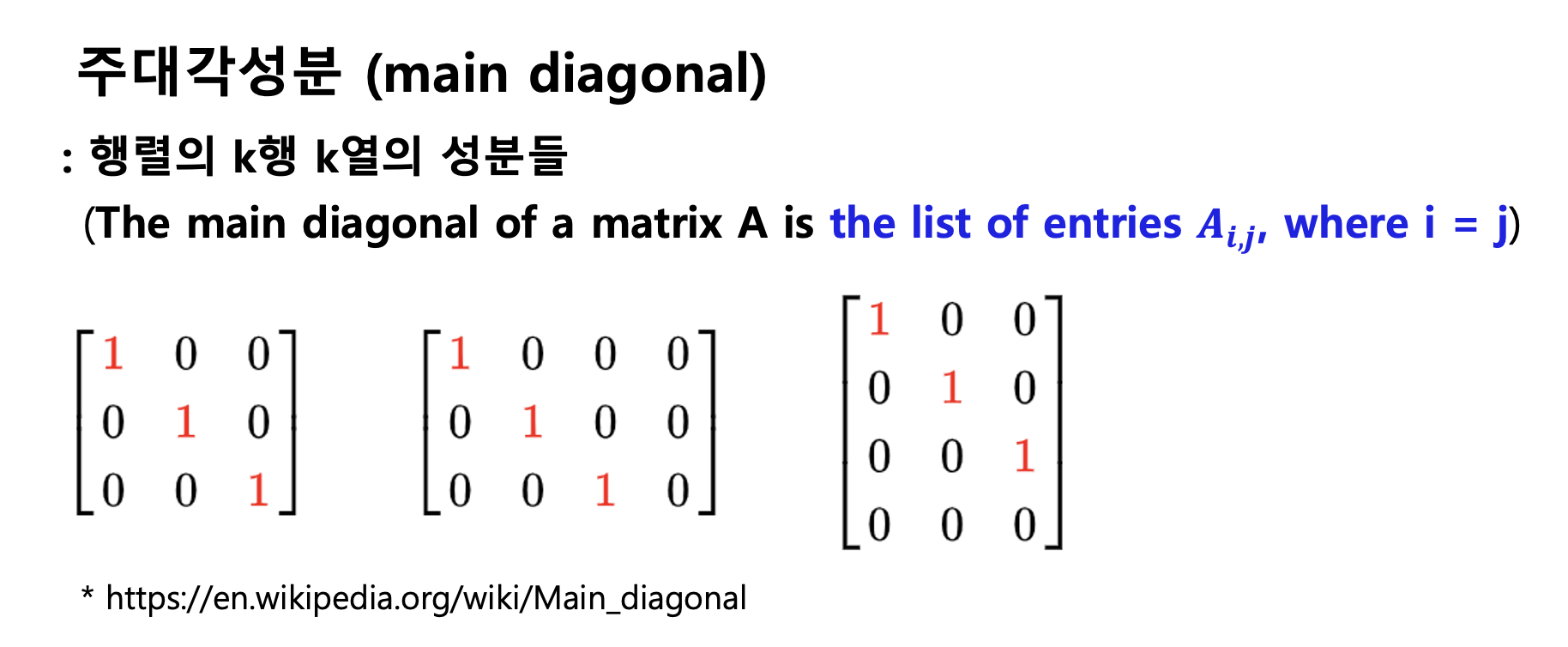
이번 포스팅에서는 Python NumPy 를 이용해서 주대각성분(main diagonal)을 다루는 방법을 소개하겠습니다.
(1) 주대각성분 가져오기 (returning a main diagonal)
(2) 주대각성분을 기준으로 수평/ 수직으로 뒤집기 (flip horizontally/ vertically by main diagonal)
(3) 주대각성분 채우기 (filling main diagonal)
(4) 대각행렬 만들기 (creating a diagonal matrix)
(1) 주대각성분 가져오기 (returning a main diagonal): np.diagonal()
import numpy as np
## making a sample 2-D array
arr = np.arange(9).reshape(3, 3)
arr
# array([[0, 1, 2],
# [3, 4, 5],
# [6, 7, 8]])
## (1) main diagonal
np.diagonal(arr)
# array([0, 4, 8])
## (2) main diagonal
arr.diagonal()
# array([0, 4, 8])
(2) 수평/ 수직으로 뒤집은 후 주대각성분 가져오기 (returning main diagonal after flipping)
(2-1) 수평으로 뒤집은 후 주대각성분 가져오기 (returning main diagonal after flipping horizontally) : np.fliplr(arr).diagonal()
# Horizontal flip
np.fliplr(arr) # flip from left to right
# array([[2, 1, 0],
# [5, 4, 3],
# [8, 7, 6]])
## main diagonal of horizontal flip
np.fliplr(arr).diagonal()
# array([2, 4, 6])
(2-2) 수직으로 뒤집은 후 주대각성분 가져오기 (returning main diagonal after flipping vertically) : np.flipud(arr).diagonal()
# Vertical flip
np.flipud(arr) # flip from up to down
# array([[6, 7, 8],
# [3, 4, 5],
# [0, 1, 2]])
## main diagonal of vertical flip
np.flipud(arr).diagonal()
# array([6, 4, 2])
(3) 주대각성분 채우기 (filling main diagonal) : np.fill_diagonal()
## filling the main diagonal of the given array of any dimensionality
## using np.fill_diagonal(a, val)
np.fill_diagonal(arr, val=999)
arr
# array([[999, 1, 2],
# [ 3, 999, 5],
# [ 6, 7, 999]])
(4) 대각행렬 만들기 (creating a diagonal matrix)
대각행렬(diagonal matrix)은 주대각성분에만 원소 값이 있고, 주대각성분 외의 원소는 값이 모두 '0'인 행렬을 말합니다.
아래의 예에서는 NumPy로 대각행렬을 만들기 위해서, 먼저 np.zeros([m, n]) 로 '0'의 값만을 가지는 m by n 행렬을 만든 후에, np.fill_diagonal(array, val) 의 val 부분에 원하는 주대각성분의 값(예: val=[1, 2, 3])을 입력해주어서 대각행렬(diag(1, 2, 3))을 만들어 보겠습니다.
지난 주말이랑 삼일절 휴일에 뮤지컬 음악감독 김문정씨의 첫번째 에세이, <이토록 찬란한 어둠> (김문정, 흐름출판, 2021) 책을 읽었어요.
책의 표지에 있는 저자 소개글을 인용해보자면, 김문정씨는 "대한민국 최고의 뮤지컬 음악감독. 국내 최초 뮤지컬 전문 오케스트라 THE PIT ORCHESTRA의 지휘자. 한세대학교 공연예술학과 교수. <명성황후> 건반 연주자로 뮤지컬 음악을 시작한 저자는 2001년부터 본격적으로 뮤지컬 음악감독으로 활동하며 지금까지 <레미제라블>, <맘마미아>, <미스 사이공>, <명성황후>, <맨 오브 라만차>, <에비타>, <모차르트!>, <영웅>, <서편제>, <레베카>, <웃는 남자>, <마리 앙투아네트>, <팬텀>, <광화문 연가> 등 50여 편의 뮤지컬 공연 음악감독을 맡았다."
이 정도면 대한민국 최고의 뮤지컬 음악감독이라고 말해도 이견이 없을거 같아요.
이토록 찬란한 어둠 (김문정, 흐름출판)
이 책을 읽고 나서 처음 든 생각이, '아, 뮤지컬 보고 싶다!' 였어요. 저의 경우 저자 소개란에 나와있는 뮤지컬 중에서 직접 극장에 가서 관람한 것은 하나도 없었구요, <레미제라블>과 <맘마미아>만 영화로 본 정도예요. 이렇게 많은 뮤지컬에 국내에서 공연이 되었다는걸 몰랐기도 했고, 뮤지컬에 미처 관심을 못 가졌어요. 그런데 이 책을 읽고 나니 음악과 춤과 연극이 총 망라된 종합예술로서의 뮤지컬이 참 매력적으로 다가오더라구요. 저자는 "뮤지컬이라는 마법 (Musical, Magical)"이라고 표현하고 있는데요, 딱 맞는 말 같아요. 코로나 끝나면 온 가족 다 같이 "뮤지컬이라는 마법"을 보고, 느끼고, 즐기러 가고 싶어졌어요!
이토록 찬란한 어둠: 뮤지컬이라는 마법
저자의 살아온 이야기를 읽다보면, "자기가 하고 싶어하는 일을, 미친듯이 몰입해서 프로세셔널하게 하면서, 사회에 선한 영향력을 끼치는 전문가이자 리더"의 모습이 참 아름답다는 생각을 하게 돼요. 뮤지컬 건반 연주자로, 작곡가로, 그리고 뮤지컬 음악감독으로 확대하고 성장하는 모습, 그 속에서 치열하게 부딪치고 두렵더라도 꿈을 쫒아 앞으로 나아가는 모습, 육아와 일을 병행하면서 힘겨워하면서도 주어진 시간 속에서 초집중하면서 성과를 일궈내는 모습, 어느정도 명성을 쌓고 난 후에는 후배들을 위해 없던 길을 닦고 시스템(가령, THE PIT ORCHESTRA)을 만들어 나가는 모습 등이 나와요. 어느 하나 쉽지 않은 과정일텐데, 지쳐 나가떨어지지 않고 계속 나아갈 수 있었던 것은 아마도 "뮤지컬이라는 마법"의 힘에 저자 스스로가 흠뻑 빠져있었기 때문일거예요.
아래의 사진은 저자가 참여한 뮤지컬 전문 오케스트라 "THE PIT"가 공연한 콘서트 <ONLY>의 한 장면이예요. 비록 이 콘서트를 가보지는 못했지만 사진으로 전해지는 장면에서 뮤지컬 피트가 오롯이(ONLY) 주인공이 되어 자신들의 이야기를 연주하는 음악이 풋풋하고 상쾌한 숲 속의 공기를 따라서 전해지는 듯해요. 저자가 "THE PIT"에 대해 소개하는 글을 읽어보면 한 업계의 영향력 있는 리더가 되어 영향력을 행사하는게 이렇게 멋있고 의미있는 일이구나 감명받게 돼요.
"뮤지컬 전문 오케스트라를 만든 지 15년 만에 오케스트라를 중심으로 제대로 된 비지니스를 진행할 수 있는 전문 기획사를 세웠다. 이름은 'THE PIT'. 오보에 연주자인 김진욱이 대표를 맡았고 나를 비롯한 오케스트라 연주자들이 단원으로 함께 하고 있다. 회사를 만든 이유는 시스템을 갖추고 싶기 때문이었다. 누구도 신경 쓰지 않고 나이질 기미가 보이지 않는, 비정규직 연주자들의 안정된 생활을 위해서 우리 스스로 나서기로 했다. 하늘에서 답이 뚝하고 떨어질 일은 없으니 기약 없이 기다릴 바에 우리기리 구조적인 문제를 해결해보자, 혼자라면 힘든 문제도 함께 움직이면 가능하지 않을까, 다수가 함께하면우리의 의견을 펼 수 있고, 그러면 조금은 아주 조금은 바뀌고 나아지지 않을까, 그런 취지였다. 평범한 직장인처럼 4대 보험이라는 혜택도 받고 안정적인 노후를 기대하는 삶을 우리도 살 수 있게 되었으면 싶었다. 2019년 회사를 설립했고 완벽하진 않지만 조금씩 자리를 잡아가고 있다" (p263)
너무 멋있지 않나요?!
콘서트 ONLY, (c)THE PIT
저자가 이 책을 쓰기로 마음먹은 이유가, 추측컨데 아마도 뮤지컬에 대한 애정, 그리고 또 뮤지컬 무대의 보이지 않는 부분에서 제 역할을 묵묵히 해나가고 있는 동료, 선후배에 대한 애정에서 였을 것 같아요. 뮤지컬 무대의 밑에 잘 안보이는 곳에서 오케스트라가 연주하는 곳을 '피트'라고 하는데요, 저자는 "피트, 어둡고 찬란한 우주"라고 표현을 해놨어요.
"오래도록 뮤지컬 음악감독으로서 자리를 지켰던 건 이 일이 늘 새롭고 좋기 때문이었다. 이 세계에 발을 들이고 나니 도저히 헤어나올 수 없었다. 20년 가까운 시간 동안 50여 개가 넘는 작품 속에서 내 손끝으로 수많은 음악의 집을 지어왔다. (...) 한 가지 업을 오래, 깊이 해온 입장에서 보이지 않는 자리에서 고군분투하는 사람들을 세상에 알리는 것도 내 역할이라고 생각한다. 무대 위의 앙상블을 비롯해 무대 밖에서 자신의 책임을 다하는 스태프들까지, 공연을 만드는 모든 사람들이 존종받고 사랑받기를 바란다. 앞으로 동료들과 함께 뮤지컬을 만들어나가며 지금 여기에서 조금 더 전진해볼 생각이다. 어디까지 갈 수 있을지 모르겠지만 최대한 갈 수 있는 데까지 가볼 수 있도록, 할 수 있는 데까지 해볼 수 있도록, 이 발걸음이 멈춰 서지 않기를 바라면서." (본문 중에서)
저자가 '음악감독의 소양'에 대해서 얘기하는 장면 중에서 기억에 남는 말이 있어요. 바로 '체력'에 대한 얘기를 하는 부분이요. 저도 요즘 나이를 먹어서 그런지 '체력'의 중요성에 대해서 몸소 느끼고 있거든요.
"그러나 이것 하나는 분명하게 이야기할 수 있다. 가장 기본은 '체력'이라고. 매일 세 시간 동안 흔들림 없이 온몸으로 지휘하려면 체력이 뒷받침되어야 한다. 좋은 컨디션으로 평정심을 유지해야 일관된 소리를 낼 수 있다. 연주자들과 배우들은 지휘봉의 작은 떨림까지 알아채기 때문에 지휘가 조금만 달라져도 금방 눈치 챈다. 속에서부터 에너지를 채우지 않으면 할 수 없는 일이다. 그래서 나는 잘 먹고, 작은 일에도 크게 웃고, 누군가의 단점보다 장점을 찾는 일에 몰두하며 주어진 일을 성실히 해내려고 노력한다. 몹시 단순하지만 이것이 몸과 마음의 체력 모두 단련하는 나만의 방법이다." (본문 중에서)
김문정씨가 음악을 시작한 계기가 참 인상적이예요. 친구의 집에 놀러갔다가 저자가 그 집의 피아노를 치면서 재미있게 놀았었나봐요. 그런데 그 집 주인 아주머니가 매몰차게 피아노 뚜껑을 닫으면서 피아노 그만 치라고 무안을 주었나봐요. 그 모습을 안쓰럽게 보았던 저자의 어머니가 적금을 깨서 바로 다음날 피아노를 사주셨다는 거예요. 그 피아노로 저자와 동생을 물론 동네 친구들까지 모두 모여 집에서 피아노를 장난감삼아 같이 치면서 놀았다는 거예요. 저자는 그때의 그 경험이 "음악은 같이 하면 행복하고 즐거운" 경험, 추억이었다고 해요. 집의 피아노로 동네 친구들 앞에서 나름 연주회도 열고, 유희열(네, 우리가 아는 그 유희열)님과 함께 고등학교 때 밴드도 하고, 학교에서 음악 지휘도 했다고 해요.참 지혜롭고 사랑 깊은 어머니지요?! 어머니가 사주신 피아노가 전부는 아니겠지만, 어머니께서 "적금을 깨서 바로 피아노를 사주지 않으셨다면", "동네 친구들이 집에 같이 와서 피아노를 가지고 노는 것을 허락하지 않으셨다면", 그렇다면 지금의 음악감독으로서의 저자가 있을 수 있었을까 싶어요.
뮤지컬에 관심이 있는 분에게는 좋아하는 분야의 대모께서 들려주는 이야기에 쏙 빠질수밖에 없을 거구요, 뮤지컬에 관심이 없었던 분이라면 이참에 뮤지컬의 매력에 쏙 빠질거예요. 그러니 모든 분에게 추천해요. 비단 뮤지컬 주제 뿐만이 아니라 사람사는 이야기 (딸로서, 엄마로서, 선생님으로서, 선배로서, 동료로서, 후배로서...) 에 사람의 향기가 물씬 뭍어있어요. (책 읽다가 어느 부분에선 눈물 흘리기도 했어요... ㅜ_ㅜ) 그리고, 딸을 가진 부모님들에게는 "딸에게 소개해주고 싶은 여성으로서 역할 모델"로도 이 책의 저자 김문정씨의 스토리가 큰 울림이 있을 것 같아요.
"이토록 찬란한 어둠", 책도 보고, 코로나 잠잠해지면 "뮤지컬"도 보러가면 행복 만땅일 것 같습니다! :-)
이때 Series.str.contains() 메소드는 문자열 Series에 대하여 패턴 매칭(pattern matching)을 할 때 문자열 그 자체(literal itself)와 함께 정규표현식(regex=True: regular expression)까지도 사용해서 패턴 매칭을 할 수 있으며, '대/소문자 구분 (case=True: case sensitive)하며, 'NaN' 값에 대해서는 'NaN'을 반환(na=None)합니다.
아래 예에서는 문자열 Series 's1'에 대해서 문자열 'pe'가 들어있는 패턴 매칭을 해서 Boolean Series 를 반환한 예입니다. (대소문자 구분, NaN은 NaN 반환)
## returning a Series of Booleans using a literal pattern
s1.str.contains('pe')
# 0 False
# 1 False # <-- case sensitive
# 2 True
# 3 False
# 4 True
# 5 NaN # <-- returning NaN for NaN values
# 6 False
# Name: fruit, dtype: object
(2) pandas DataFrame에서 한개의 문자열 패턴 매칭이 되는 데이터 가져오기
pandas DataFrame에서 특정 문자열 칼럼에 대해서 문자열 패턴 매칭한 결과인 Boolean Series 를 이용해서 해당 행의 값만 가져올 수 있습니다. 이때 만약 문자열 패턴 매칭 결과 Boolean Seires 에 NaN 값이 포함되어 있을 경우 아래와 같은 ValueError 가 발생합니다.
ValueError: Cannot mask with non-boolean array containing NA / NaN valu
## ValueError: Cannot mask with non-boolean array containing NA / NaN values
df[df['fruit'].str.contains('pe')]
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-5-ee5e3bc73f2f> in <module>
1 ## ValueError: Cannot mask with non-boolean array containing NA / NaN values
----> 2 df[s1.str.contains('pe')]
~/opt/anaconda3/lib/python3.8/site-packages/pandas/core/frame.py in __getitem__(self, key)
2890
2891 # Do we have a (boolean) 1d indexer?
-> 2892 if com.is_bool_indexer(key):
2893 return self._getitem_bool_array(key)
2894
~/opt/anaconda3/lib/python3.8/site-packages/pandas/core/common.py in is_bool_indexer(key)
132 na_msg = "Cannot mask with non-boolean array containing NA / NaN values"
133 if isna(key).any():
--> 134 raise ValueError(na_msg)
135 return False
136 return True
ValueError: Cannot mask with non-boolean array containing NA / NaN values
이 'ValueError: Cannot mask with non-boolean array containing NA/NaN values' 를 해결하기 위해서는 Series.str.contains(pattern, na=False) 처럼 NaN 값을 Boolean의 'False'로 설정해주면 됩니다.
## Specifying na to be False instead of NaN replaces NaN values with False.
df[df['fruit'].str.contains('pe'
, na=False) # specifying NA to be False
]
# id fruit
# 2 3 grapes
# 4 5 peach and perl
만약 문자열 매칭을 할 때 '대/소문자 구분없이 (case insensitive)' 하려면 'case=False' 옵션을 설정해주면 됩니다.
아래 예에서는 case=False 로 설정한 상태에서 'pe' 문자열 매칭을 했더니 'PERSIMON' 대문자도 매칭이 되어서 가져오기가 되었습니다.
## Specifying case sensitivity using case.
df[df['fruit'].str.contains('pe'
, na=False
, case=False) # case = False
]
# id fruit
# 1 2 PERSIMON # <-- case insensitive
# 2 3 grapes
# 4 5 peach and perl
Series.str.contains() 함수에는 정규표현식(regex=True: Regular Expression)을 사용해서 문자열 매칭을 할 수 있습니다. 아래의 예에서는 정규표현식을 이용해서 '숫자가 포함된 ('\\d' : returning any digits)' 문자열을 가져와보겠습니다.
## returning any digit using regular expression
df[df['fruit'].str.contains(
'\\d' # returning any digit
, regex=True # using regular expression
, na=False
)
]
# id fruit
# 6 7 1004
(3) pandas DataFrame에서 여러개의 문자열 패턴 매팅이 되는 데이터 가져오기
이번에는 문자열 매칭을 할 때 '여러개의 문자열 패턴 (multiple strings of pattern)' 과 매칭되는 문자열을 확인하고, pandas DataFrame으로 부터 해당 행의 데이터를 가져와보겠습니다.
여러개의 문자열 패턴을 표현할 때 '|' 가 'or' 를 나타냅니다. 아래의 예의 경우, ['ap' or 'ma' or 'gr'] 이 포함된 문자열을 매칭해서 Boolean String을 반환하고 싶을 때 ['ap'|'ma'|'gr'] 을 패턴으로 입력해주면 됩니다. Python의 내장함수(built-in function) 중에서 join() 메소드를 이용하면 여러개의 문자열을 '|' 구분자(separator)를 넣어서 하나의 문자열로 묶어줄 수 있습니다. ('|'.join(['ap', 'ma', 'gr']) 은 ==> 'ap|ma|gr' 을 반환하며, ==> ['ap' or 'ma' or 'gr'] 을 의미함)
## join() method joins all itmes in a tuple into a string with a separartor
'|'.join(['ap', 'ma', 'gr'])
# 'ap|ma|gr'
## Returning ‘apple’ or ‘mango’ or 'grapes'
## when either expression occurs in a string.
s1.str.contains(
'|'.join(['ap', 'ma', 'gr']) # 'ap|ma|gr', ie. 'ap' or 'ma' or 'gr'
, na=False
, case=False
)
# 0 True
# 1 False
# 2 True
# 3 True
# 4 False
# 5 False
# 6 False
# Name: fruit, dtype: bool
이제 pandas DataFrame 에서 'fruit' 칼럼에서 'ap' or 'ma' or 'gr' 문자열이 포함되어 있는 모든 행을 가져와보겠습니다.
## indexing data using a Series of Booleans
df[df['fruit'].str.contains(
'|'.join(['ap', 'ma', 'gr'])
, na=False
, case=False
)
]
# id fruit
# 0 1 apple
# 2 3 grapes
# 3 4 mango
아래의 도식은 Sowmya Vajjala, et.al, "Practical Natural Language Processing", O'REILLY (2020) 에서 인용한 'Building Blocks of Language Structure'와 언어의 각 구성요소별 NLP 응용분야를 정리한 것입니다. 음소, 형태소 & 어휘항목, 구문, 문맥 순서대로 하나씩 소개해보겠습니다. (영어 단어가 생소해서 원서로 처음 읽을 때 뭔 소리인가 했어요..)
Building blocks of language structure
(2-1) 음소 (Phonemes) : 말과 소리 (Speech & Sounds)
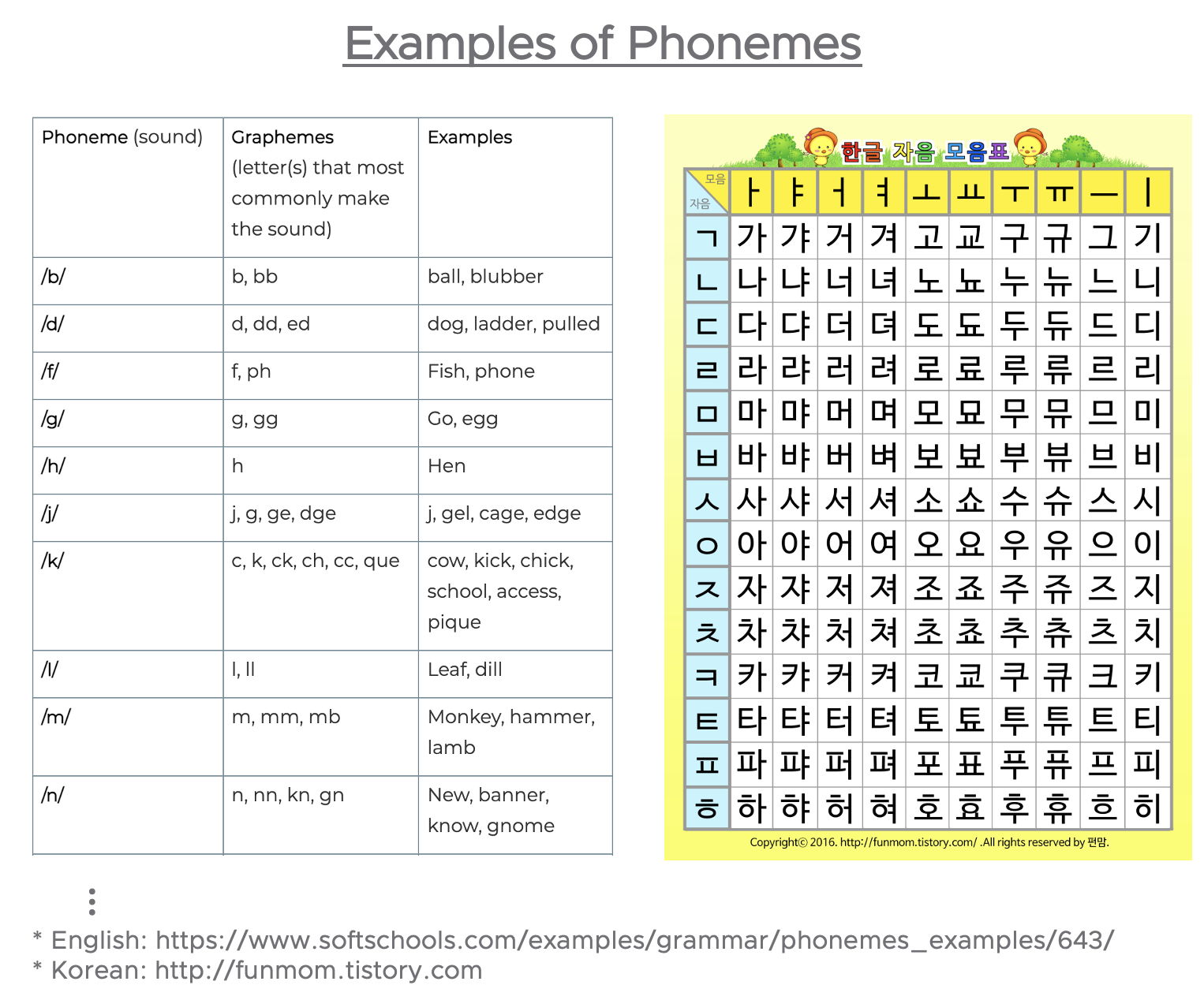
음소(Phonemes)는 언어에서 말과 소리의 가장 작은 단위(the smallest units of sound in a language)입니다. 음소는 그 자체로는 아무런 의미도 없지만, 다른 음소들과 함께 사용이 되면 의미를 가지게 될 수 있습니다.[1] 음운론(Phonology)과 언어학(Linguistics)에서 음소는 특정 언어에서 한 단어와 다른 단어를 구별할 수 있는 소리의 단위입니다.[2]
아래는 영어와 한글의 음소 예시예요. 영어에는 44개의 다른 소리의 음소가 있고, 한글에는 14개의 자음과 10개의 모음 소리의 음소가 있습니다.
음소 (phonemes)
음소(Phonemes)는 말을 글로 변환하기(Speech to Text), 글을 말로 변환하기(Text to Speech), 화자 파악하기 (Speaker Identification) 등의 영역에 활용이 됩니다.
형태소(Morphemes) 는 의미를 가지는 언어의 가장 작은 단위(the smallest unit of language) 이며, 음소(phonemes)의 조합을 통해서 만들어집니다.[1] 형태소는 단어(Words)처럼 보이기는 하지만, 그렇다고 행태소가 곧 단어는 아닙니다. 형태소와 단어의 차이점은, 형태소는 홀로 사용될 수 없지만, 단어는 그 정의상 항상 홀로 자기완결적으로 사용될 수 있다는 점입니다.[3]
아래 예에서는 영어 단어를 형태소로 분리해본 것인데요, 아무래도 예를 보는 것이 형태소를 이해하는데 직관적으로 와 닿을것 같습니다. (예: running => run + nning, books => book + s, unreadable => un+read+able, readability => read+able+ity) unreadable 에서 접두사 'un'이나 접미사 'able'은 모두 형태소로서, 단어의 뜻을 바꾸어줍니다.
[ 단어에서 형태소 분리 예시 (examples of morphemes in words) ]
형태소 (morphemes)
어휘항목(Lexemes) 또는 어휘소는 의미에 의해서 서로 관련되어 있는 형태소의 구조적인 변형(the structural variations of morphemes related to one another by meaning)입니다.[1] 어휘항목(어휘소)는 변형을 통해 관련되는 단어들의 기초가 되는 어휘적 의미의 단위입니다. 어근 단어(root word)에 의해 대략적으로 일치하는 형태소 분석의 단위인 기본 추상적 의미 단위입니다.[4] (위키피디아 번역하려니 쉽지가 않네요. -,-;) 예를 들어, 영어에서 Run, Runs, Ran, Running은 "RUN"으로 표현될 수 있는 동일한 어휘소의 형태입니다. 예를 보면 금방 이해가 될 것 같습니다.
[ 어휘항목(어휘소, Lemexmes) 예시 ]
어휘항목, 어휘소 (lexemes)
형태소와 어휘소는 토큰화(Tokenization), 단어 임베팅(Word Embedding), 형태소(품사) 분석(POS Tagging: Part-Of-Speech Tagging) 등의 영역에 사용됩니다.
(2-3) 구문 (Syntax) : 문장 (Phrases & Sentences)
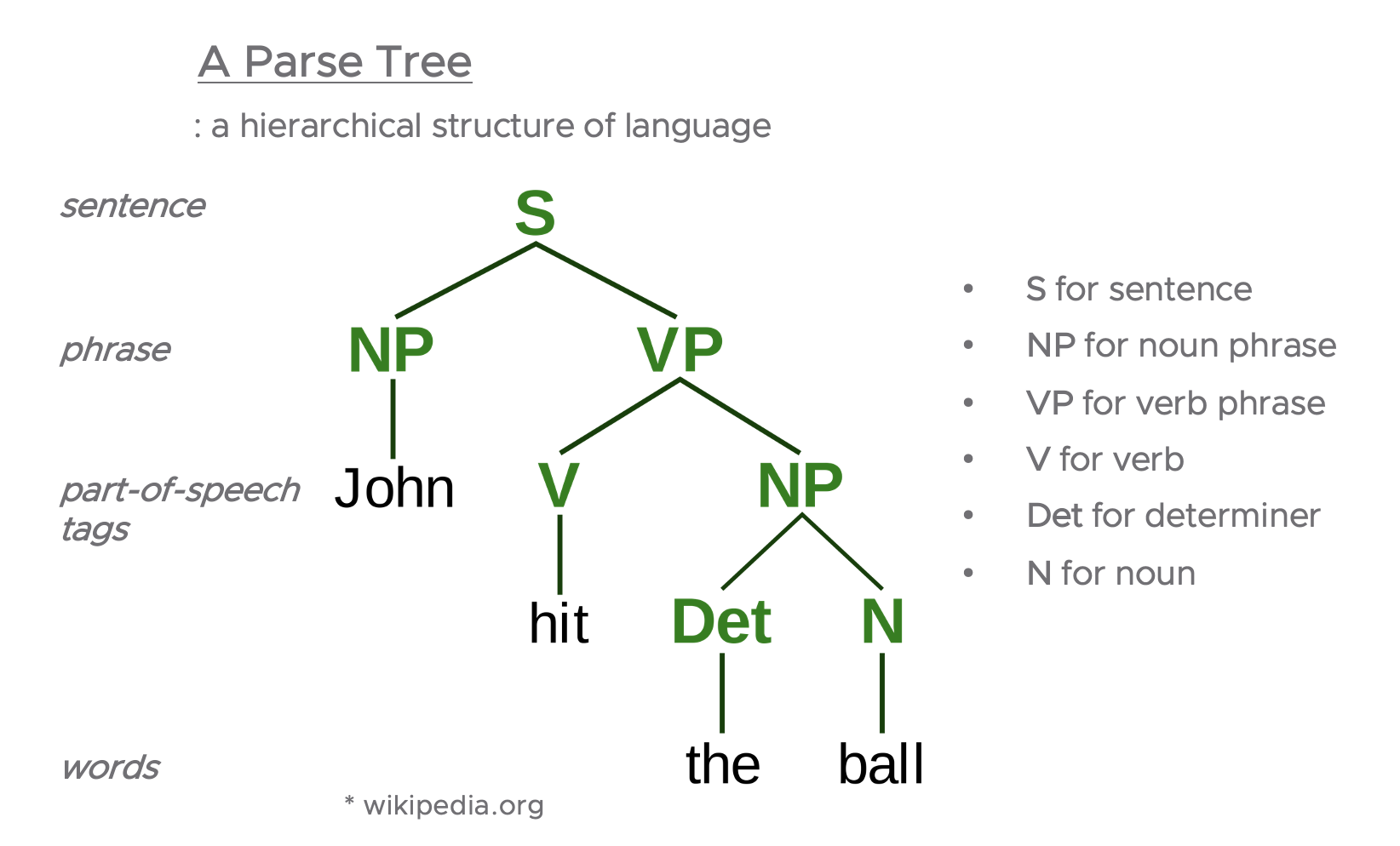
언어학에서 구문론(Syntax)은 단어(Words)와 형태소(Morphemes)가 어떻게 결합되어 구(Phrases)나 문장(Sentences)과 같은 더 큰 단위를 형성하는지 연구하는 학문입니다. 구문론의 중심 관심사는 어순(Word Order), 문법적 관계(Grammatical Relations), 계층적 문장 구조(구성)(Hierarchical Sentence Structure, Constituency), 교차 언어적 변형의 특성(the nature of crosslinguistic variation), 형태와 의미 사이의 관계(the relationship between form and meaning)를 포함합니다. 구문론에는 중심 가정과 목표가 다른 수많은 접근법이 있습니다.[5]
언어학에서 구문론적인 구조는 많은 다양한 형태로 제시될 수 있습니다. 그중에서 문장을 표현하는 일반적인 방법으로 'a Parse Tree' 이 있습니다. Parse Tree는 언어의 계층적 구조(a hierarchical structure of language)를 가지고 있으며, 아래의 예시에서 보는 바와 같이, 제일 밑에는 단어(words), 그 위에는 형태소(품사) 태깅(POS tagging, Part-Of-Speech Tagging), 그 위에는 구(phrase), 제일 위에는 문장(sentence)으로 하여 계층적 구조를 시각화해서 나타내줍니다.[1]
[ A Parse Tree 예시 ]
Syntax: a parse tree
* image: wikipedia.org
언어학의 구문론(Syntax)은 파싱(Parsing), 객체 추출(Entity Extraction), 관계 추출(Relation Extraction)에 사용됩니다.
(2-4) 문맥 (Context) : 의미 (Meaning)
문맥(Context)은 언어의 사용, 언어의 변화, 대화/문장의 요약에 영향을 미치는 의사소통 상황과 관련된 제약을 말합니다.[6] 문맥은 언어의 각 요소들이 합쳐져서 특정 의미(meaning)를 가지고 만드는 것과 관련이 있습니다. 문맥은 단어와 구문의 문자 그대로의 의미(literal meaning of words and phrases)와 함께 장기간의 참조(long-term references), 세계 지식(world knowledge), 상식(common sense)을 포함한다. 문장의 의미는 문맥에 따라 달라질 수 있는데, 이는 단어와 구절이 때로는 여러 의미를 가질 수 있기 때문입니다.[1].
바로 언어의 이런 문맥이 가지는 특성 때문에 상식을 배우지 못하는 기계 번역이 굉장히 어려운 과제인 것입니다. 사람도 문맥을 잘 파악하지 못하면 엉뚱하게 해석해서 곤란한 경우가 자주 있는데, 인공지능이라고 예외는 아니겠죠.
example of sentiment analysis
문맥은 문서 요약(Summarization), 토픽 모델링(Topic Modeling), 감성분석(Sentiment Analysis), 냉소적인 표현 탐지(Sarcasm Detection) 등의 분야에 활용됩니다.
이상으로 언어 구조의 구성요소로서 음소(Phonemes), 형태소와 어휘소(Morphemes & Lexemes), 구문(Syntax), 문맥(Context) 에 대한 소개를 마치겠습니다. (저는 언어학 전공이 아닌지라 공부하면서 번역하는데 용어가 좀 어려웠습니다. ㅋ)
[ Reference ]
[1] Sowmya Vajjala el.al., "Practical Natural Language Processing: A Comprehensive Guide to Building Real-World NLP Systems", O'REILLY (2020)
빅데이터의 시대에 매 순간 엄청난 양의 텍스트 비정형 데이터가 생성/ 저장/ 분석이 되고 있습니다. 그리고 특히 최근에는 딥러닝을 자연어 처리에 적극 활용함으로써 기존에는 할 수 없었던 놀라운 성과가 속속 나오고 있습니다.
이번 포스팅에서는 자연어 처리(NLP: Natural Language Processing)에 대한 첫발을 떼는 개요로서,
(1) 자연어 처리 이란 무엇인가? (What is NLP?)
(2) 자연어 처리의 응용분야 (NLP Tasks)에는 무엇이 있나?
에 대해서 소개하겠습니다.
(1) 자연어 처리 (NLP: Natural Language Processing) 이란 무엇인가?
자연어 처리(NLP, Natural Language Processing)는 컴퓨터와 인간 언어, 특히 대량의 자연어 데이터를 처리하고 분석하도록 컴퓨터를 프로그래밍하는 방법과 관련된 언어학, 컴퓨터 과학, 인공지능의 하위 분야입니다. [1]
(Natural language processing (NLP) is a subfield of linguistics, computer science, and artificial intelligence concerned with the interactions between computers and human language, in particular how to program computers to process and analyze large amounts of natural language data.)
자연어 처리와 유사한 의미로 많이 사용되는 용어인 텍스트 마이닝(text mining)은 텍스트 분석(text analytics, text analysis), 텍스트 데이터 마이닝 (text data mining)이라고도 하며, 텍스트에서 고품질 정보를 얻는 과정을 말합니다. 텍스트 마이닝은 컴퓨터를 사용해서 텍스트로부터 정보를 자동으로 추출함으로써, 이전에 알려지지 않았던 새로운 정보를 발견을하는 것을 포함합니다. [2] (Text mining, also referred to as text data mining, similar to text analytics, is the process of deriving high-quality information from text. It involves "the discovery by computer of new, previously unknown information, by automatically extracting information from different written resources)
(2) 자연어 처리의 응용분야 (NLP Tasks)에는 무엇이 있나?
아래의 도식은 상대적인 난이도에 따라서 자연어 처리의 응용분야 (NLP Tasks) 를 나열해 본 것입니다. [3]
아래 도식에 소개된 자연어처리(NLP)의 쉬운 과업부터 어려운 과업까지 순서대로 간략하게 설명을 해보겠습니다.
NLP Tasks
* 출처: Sowmya Vajjala et.al,"Practical Natural Language Process: A Comprehensive Guide to Building Real-World NLP Systems", O'REILLY, 2020
* 맞춤법 검사 (Spell Checking)
맞춤법 검사기 (또는 맞춤법 검사기)는 소프트웨어에서 텍스트의 오타를 검사하는 소프트웨어 기능입니다. 워드 프로세서 사용하다 보면 오타에 빨간줄 밑줄 그어진거 보셨을 거예요. 철자 검사 기능은 워드 프로세서, 전자 메일 클라이언트, 전자 사전 또는 검색 엔진과 같은 소프트웨어나 서비스에 내장되어 있는 경우가 많습니다. Grammarly 와 같은 맞춤법 검사 및 문법 검사 서비스 광고를 요즘 많이 보게 되네요.
* 키워드 기반 정보 검색 (Keyword-Based Information Retrieval)
정보 검색은 대규모의 문서를 모아놓은 곳에서 사용자 쿼리와 관련된 문서를 찾는 작업입니다. 구글 검색(Google Search)과 같은 애플리케이션은 정보 검색의 대표적인 사례입니다.
* 토픽 모델링 (Topic Modeling)
토픽 모델링은 문서들에 대한 비지도 분류 학습 방법(a method for unsupervised classification of documents)으로, 우리가 무엇을 찾아야 하는지 확실하지 않은 경우에도 자연스러운 항목 그룹을 찾는 숫자 데이터에 대한 클러스터링과 유사합니다. 토픽 모델링은 거대한 문서들의 집합에서 토픽 구조를 발견하는데 사용합니다. 잠재 디리클레 할당(LDA: Latent Dirichlet Allocation) 은 주제 모델을 적합시키기 위해 특히 인기 있는 기법입니다.
* 텍스트 분류 (Text Classification)
텍스트 분류는 텍스트를 내용에 따라 알려진 범주 집합으로 분류하는 작업입니다. 텍스트 분류는 자연어 처리(NLP)에서 단연코 가장 인기 있는 작업이며, 전자 메일 스팸 식별에서 감성 분석(sentiment analysis)에 이르기까지 다양한 도구에 사용됩니다.
* 정보 추출 (Information Extraction)
정보 추출은 이메일이나 소셜 미디어 게시물에서 언급된 사람의 이름과 같은 관련 정보를 텍스트에서 추출하는 작업입니다.
* 텍스트 요약 (Text Summarization)
자동 텍스트 요약(Automatic Text Summary)은 원본 내용 내에서 가장 중요하거나 관련 있는 정보를 나타내는 부분 집합(요약)을 만들기 위해 계산적으로 데이터 집합을 요약, 단축하는 과정을 말합니다.
* 질의 응답 (Question Answering)
질의 응답(QA)은 정보 검색 및 자연어 처리(NLP) 분야의 컴퓨터 과학 분야로, 자연 언어로 인간이 제기하는 질문에 자동으로 답변하는 시스템을 구축하는 것과 관련이 있습니다.
* 기계 번역 (Machine Translation)
기계 번역은 텍스트나 음성을 한 언어에서 다른 언어로 번역하는 소프트웨어의 사용을 연구하는 컴퓨터 언어학의 하위 분야입니다. Google Translator, Papago 번역기 등이 대표적인 예가 되겠습니다.
* 열린 주제의 대화 에이전트 (Open Domain Conversational Agent)
대화 시스템 또는 대화 에이전트(CA)는 인간과 대화하기 위한 컴퓨터 시스템입니다. 대화 시스템은 입력 채널과 출력 채널 모두에서 통신을 위해 하나 이상의 텍스트, 음성, 그래픽, 촉감, 제스처 및 기타 모드를 사용합니다. (위 도식의 오른쪽 부분 워크 플로우별 과업 참조). 애플의 Siri, Kakao Mini 등의 인공지능 스피커가 대화 에이전트(CA)의 대표적인 예가 되겠네요.
이번 포스팅에서는 PostgreSQL, Greenplum DB의 Window Function 의 함수 특징, 함수별 구문 사용법에 대해서 알아보겠습니다. Window Function을 알아두면 편리하고 또 강력한 SQL query 를 사용할 수 있습니다. 특히 MPP (Massively Parallel Processing) Architecture 의 Greenplum DB 에서는 Window Function 실행 시 분산병렬처리가 되기 때문에 성능 면에서 매우 우수합니다.
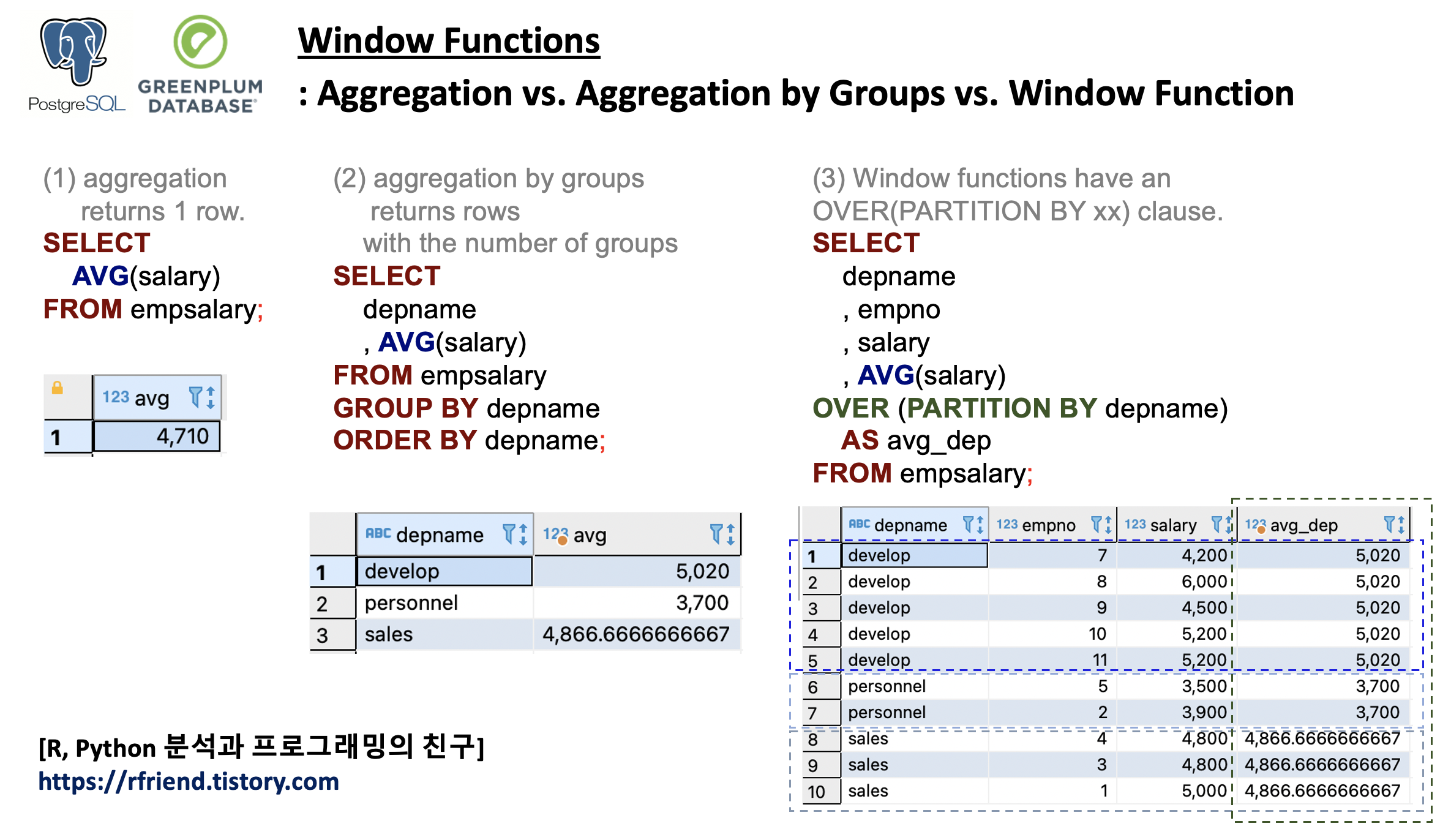
Window Function 은 현재 행과 관련된 테이블 행 집합(a set of table rows)에 대해 계산을 수행합니다. 이는 집계 함수(aggregate function)로 수행할 수 있는 계산 유형과 비슷합니다. 그러나 일반적인 집계 함수와 달리 Window Function을 사용하면 행이 단일 출력 행으로 그룹화되지 않으며 행은 별도의 ID를 유지합니다.
아래 화면의 예시는 AVG() 함수로 평균을 구하는데 있어,
(a) 전체 평균 집계: AVG() --> 한 개의 행 반환
(b) 그룹별 평균 집계: AVG() ... GROUP BY --> 그룹의 개수만큼 행 반환
[ PostgreSQL, Greenplum: Aggregation vs. Aggregation by Groups vs. Window Function ]
PostgreSQL, Greenplum: Aggregation vs. Aggregation by Groups vs. Window Function
먼저, 부서(depname), 직원번호(empno), 급여(salary) 의 칼럼을 가지는 간단한 예제 테이블 empsalary 을 만들고 데이터를 입력해보겠습니다.
-- (0) making a sample table as an example
DROP TABLE IF EXISTS empsalary;
CREATE TABLE empsalary (
depname TEXT
, empno INT
, salary INT
);
INSERT INTO empsalary (depname, empno, salary)
VALUES
('sales', 1, 5000)
, ('personnel', 2, 3900)
, ('sales', 3, 4800)
, ('sales', 4, 4800)
, ('personnel', 5, 3500)
, ('develop', 7, 4200)
, ('develop', 8, 6000)
, ('develop', 9, 4500)
, ('develop', 10, 5200)
, ('develop' , 11, 5200);
SELECT * FROM empsalary ORDER BY empno LIMIT 2;
--depname |empno|salary|
-----------+-----+------+
--sales | 1| 5000|
--personnel| 2| 3900|
(1) AVG() vs. AVG() GROUP BY vs. AVG() OVER (PARTITION BY ORDER BY)
아래는 (a) AVG() 로 전체 급여의 전체 평균 집계, (b) AVG() GROUP BY depname 로 부서 그룹별 평균 집계, (c) AVG() OVER (PARTITION BY depname) 의 Window Function을 사용해서 부서 집합 별 평균을 계산해서 직원번호 ID의 행별로 결과를 반환하는 것을 비교해 본 것입니다. 반환하는 행의 개수, 결과를 유심히 비교해보시면 aggregate function 과 window function 의 차이를 이해하는데 도움이 될거예요.
-- (0) aggregation returns 1 row.
SELECT
AVG(salary)
FROM empsalary;
--avg |
-----------------------+
--4710.0000000000000000|
-- (0) aggregation by groups returns rows with the number of groups
SELECT
depname
, AVG(salary)
FROM empsalary
GROUP BY depname
ORDER BY depname;
--depname |avg |
-----------+---------------------+
--develop |5020.000000000000000
--personnel|3700.000000000000000
--sales |4866.6666666666666667|
-- (1) Window functions have an OVER(PARTITION BY xx) clause.
-- any function without an OVER clause is not a window function, but rather an aggregate or single-row (scalar) function.
SELECT
depname
, empno
, salary
, AVG(salary)
OVER (PARTITION BY depname)
AS avg_dep
FROM empsalary;
--depname |empno|salary|avg_dep |
-----------+-----+------+---------------------+
--develop | 7| 4200|5020.0000000000000000|
--develop | 8| 6000|5020.0000000000000000|
--develop | 9| 4500|5020.0000000000000000|
--develop | 10| 5200|5020.0000000000000000|
--develop | 11| 5200|5020.0000000000000000|
--personnel| 5| 3500|3700.0000000000000000|
--personnel| 2| 3900|3700.0000000000000000|
--sales | 4| 4800|4866.6666666666666667|
--sales | 3| 4800|4866.6666666666666667|
--sales | 1| 5000|4866.6666666666666667|
아래는 PostgreSQL, Greenplum 의 Window Function Syntax 구문입니다.
- window_function(매개변수) 바로 다음에 OVER() 가 있으며,
- OVER() 안에 PARTITION BY 로 연산이 실행될 집단(set) 기준을 지정해주고
- OVER() 안에 ORDER BY 로 시간(time), 순서(sequence)가 중요할 경우 정렬 기준을 지정해줍니다.
-- PostgreSQL Window Function Syntax
WINDOW_FUNCTION(arg1, arg2,..) OVER (
[PARTITION BY partition_expression]
[ORDER BY sort_expression [ASC | DESC]
[NULLS {FIRST | LAST }]
)
PostgreSQL, Greenplum Window Function Syntax
PostgreSQL의 Window Functions 중에서 제가 그래도 자주 쓰는 함수로 AVG() OVER(), SUM() OVER(), RANK() OVER(), LAG() OVER(), LEAD() OVER(), FIRST_VALUE() OVER(), LAST_VALUE() OVER(), NTILE() OVER(), ROW_NUMBER() OVER() 등의 일부 함수 (제 맘대로... ㅎㅎ)에 대해서 아래에 예시를 들어보겠습니다.
(2) RANK() OVER ([PARTITION BY] ORDER BY) : 순위
아래 예는 PARTITION BY depname 로 '부서' 집단별로 구분해서, ORDER BY salary DESC로 급여 내림차순으로 정렬한 후의 직원별 순위(rank)를 계산해서 직원 ID 행별로 순위를 반환해줍니다.
PARTITION BY 집단 내에서 ORDER BY 정렬 기준칼럼의 값이 동일할 경우 순위는 동일한 값을 가지며, 동일한 순위의 개수만큼 감안해서 그 다음 순위의 값은 순위가 바뀝니다. (가령, develop 부서의 경우 순위가 1, 2, 2, 4, 5, 로서 동일 순위 '2'가 두명 있고, 급여가 네번째인 사람의 순위는 '4'가 되었음.)
-- (2) You can control the order
-- in which rows are processed by window functions using ORDER BY within OVER.
SELECT
depname
, empno
, salary
, RANK() OVER (PARTITION BY depname ORDER BY salary DESC)
FROM empsalary;
--depname |empno|salary|rank|
-----------+-----+------+----+
--personnel| 2| 3900| 1|
--personnel| 5| 3500| 2|
------------------------------------- set 1 (personnel)
--sales | 1| 5000| 1|
--sales | 3| 4800| 2|
--sales | 4| 4800| 2|
------------------------------------- set 2 (sales)
--develop | 8| 6000| 1|
--develop | 11| 5200| 2|
--develop | 10| 5200| 2|
--develop | 9| 4500| 4|
--develop | 7| 4200| 5|
------------------------------------- set 3 (develop)
(3) SUM() OVER () : PARTITION BY, ORDER BY 는 생략 가능
만약 집단별로 구분해서 연산할 필요가 없다면 OVER() 구문 안에서 PARTITON BY 는 생략할 수 있습니다.
만약 시간이나 순서가 중요하지 않다면 OVER() 구문 안에서 ORDER BY 는 생략할 수 있습니다.
아래 예에서는 SUM(salary) OVER () 를 사용해서 전체 직원의 급여 평균을 계산해서 각 직원 ID의 개수 만큼 행을 반환했습니다.
-- (3) ORDER BY can be omitted if the ordering of rows is not important.
-- It is also possible to omit PARTITION BY,
-- in which case there is just one partition containing all the rows.
SELECT
salary
, SUM(salary) OVER () -- same result
FROM empsalary;
--salary|sum |
--------+-----+
-- 5000|47100|
-- 3900|47100|
-- 4800|47100|
-- 4800|47100|
-- 3500|47100|
-- 4200|47100|
-- 6000|47100|
-- 4500|47100|
-- 5200|47100|
-- 5200|47100|
(4) SUM() OVER (ORDER BY) : ORDER BY 구문이 추가되면 누적 합으로 결과가 달라짐
만약 PARTITION BY 가 없어서 집단별 구분없이 전체 데이터셋을 대상으로 연산을 하게 될 때, SUM(salary) OVER (ORDER BY salary) 처럼 OVER () 절 안에 ORDER BY 를 추가하게 되면 salary 를 기준으로 정렬이 된 상태에서 누적 합이 계산되므로 위의 (3)번과 차이점을 알아두기 바랍니다.
-- (4) But if we add an ORDER BY clause, we get very different results:
SELECT
salary
, SUM(salary) OVER (ORDER BY salary)
FROM empsalary;
--salary|sum |
--------+-----+
-- 3500| 3500|
-- 3900| 7400|
-- 4200|11600|
-- 4500|16100|
-- 4800|25700|
-- 4800|25700|
-- 5000|30700|
-- 5200|41100|
-- 5200|41100|
-- 6000|47100|
(5) LAG(expression, offset) OVER (ORDER BY), LEAD(expression, offset) OVER (ORDER BY)
이번에는 시간(time), 순서(sequence)가 중요한 시계열 데이터(Time Series data) 로 예제 테이블을 만들어보겠습니다. 시계열 데이터에 대해 Window Function 을 사용하게 되면 OVER (ORDER BY timestamp) 처럼 ORDER BY 를 꼭 포함시켜줘야 겠습니다.
-- (5) LAG() over (), LEAD() over ()
-- making a sample TimeSeries table
DROP TABLE IF EXISTS ts;
CREATE TABLE ts (
dt DATE
, id INT
, val INT
);
INSERT INTO ts (dt, id, val) VALUES
('2022-02-10', 1, 25)
, ('2022-02-11', 1, 28)
, ('2022-02-12', 1, 35)
, ('2022-02-13', 1, 34)
, ('2022-02-14', 1, 39)
, ('2022-02-10', 2, 40)
, ('2022-02-11', 2, 35)
, ('2022-02-12', 2, 30)
, ('2022-02-13', 2, 25)
, ('2022-02-14', 2, 15);
SELECT * FROM ts ORDER BY id, dt;
--dt |id|val|
------------+--+---+
--2022-02-10| 1| 25|
--2022-02-11| 1| 28|
--2022-02-12| 1| 35|
--2022-02-13| 1| 34|
--2022-02-14| 1| 39|
--2022-02-10| 2| 40|
--2022-02-11| 2| 35|
--2022-02-12| 2| 30|
--2022-02-13| 2| 25|
--2022-02-14| 2| 15|
LAG(expression, offset) OVER (PARTITION BY id ORDER BY timestamp) 윈도우 함수는 ORDER BY timestamp 기준으로 정렬을 한 상태에서, id 집합 내에서 현재 행에서 offset 만큼 앞에 있는 행의 값(a row which comes before the current row)을 가져옵니다. 아래의 예를 살펴보는 것이 이해하기 빠르고 쉬울거예요.
-- (5-1) LAG() function to access a row which comes before the current row
-- at a specific physical offset.
SELECT
dt
, id
, val
, LAG(val, 1) OVER (PARTITION BY id ORDER BY dt) AS lag_val_1
, LAG(val, 2) OVER (PARTITION BY id ORDER BY dt) AS lag_val_2
FROM ts
;
--dt |id|val|lag_val_1|lag_val_2|
------------+--+---+---------+---------+
--2022-02-10| 1| 25| | |
--2022-02-11| 1| 28| 25| |
--2022-02-12| 1| 35| 28| 25|
--2022-02-13| 1| 34| 35| 28|
--2022-02-14| 1| 39| 34| 35|
--2022-02-10| 2| 40| | |
--2022-02-11| 2| 35| 40| |
--2022-02-12| 2| 30| 35| 40|
--2022-02-13| 2| 25| 30| 35|
--2022-02-14| 2| 15| 25| 30|
LEAD(expression, offset) OVER (PARTITION BY id ORDER BY timestamp) 윈도우 함수는 ORDER BY timestamp 기준으로 정렬을 한 후에, id 집합 내에서 현재 행에서 offset 만큼 뒤에 있는 행의 값(a row which follows the current row)을 가져옵니다. 아래의 예를 살펴보는 것이 이해하기 빠르고 쉬울거예요.
-- (5-2) LEAD() function to access a row that follows the current row,
-- at a specific physical offset.
SELECT
dt
, id
, val
, LEAD(val, 1) OVER (PARTITION BY id ORDER BY dt) AS lead_val_1
, LEAD(val, 2) OVER (PARTITION BY id ORDER BY dt) AS lead_val_2
FROM ts
;
--dt |id|val|lead_val_1|lead_val_2|
------------+--+---+----------+----------+
--2022-02-10| 1| 25| 28| 35|
--2022-02-11| 1| 28| 35| 34|
--2022-02-12| 1| 35| 34| 39|
--2022-02-13| 1| 34| 39| |
--2022-02-14| 1| 39| | |
--2022-02-10| 2| 40| 35| 30|
--2022-02-11| 2| 35| 30| 25|
--2022-02-12| 2| 30| 25| 15|
--2022-02-13| 2| 25| 15| |
--2022-02-14| 2| 15| | |
(6) FIRST_VALUE() OVER (), LAST_VALUE() OVER ()
OVER (PARTITION BY id ORDER BY dt) 로 id 집합 내에서 dt 순서를 기준으로 정렬한 상태에서, FIRST_VALUE() 는 첫번째 값을 반환하며, LAST_VALUE() 는 마지막 값을 반환합니다.
OVER() 절 안에 RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING 은 partion by 집합 내의 처음과 끝의 모든 행의 범위를 다 고려하라는 의미입니다.
-- (6) FIRST_VALUE() OVER (), LAST_VALUE() OVER ()
-- The FIRST_VALUE() function returns a value evaluated
-- against the first row in a sorted partition of a result set.
-- The LAST_VALUE() function returns a value evaluated
-- against the last row in a sorted partition of a result set.
-- The RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING clause defined
-- the frame starting from the first row and ending at the last row of each partition.
SELECT
dt
, id
, val
, FIRST_VALUE(val)
OVER (
PARTITION BY id
ORDER BY dt
RANGE BETWEEN UNBOUNDED PRECEDING
AND UNBOUNDED FOLLOWING) AS first_val
, LAST_VALUE(val)
OVER (
PARTITION BY id
ORDER BY dt
RANGE BETWEEN UNBOUNDED PRECEDING
AND UNBOUNDED FOLLOWING) AS last_val
FROM ts
;
--dt |id|val|first_val|last_val|
------------+--+---+---------+--------+
--2022-02-10| 1| 25| 25| 39|
--2022-02-11| 1| 28| 25| 39|
--2022-02-12| 1| 35| 25| 39|
--2022-02-13| 1| 34| 25| 39|
--2022-02-14| 1| 39| 25| 39|
--2022-02-10| 2| 40| 40| 15|
--2022-02-11| 2| 35| 40| 15|
--2022-02-12| 2| 30| 40| 15|
--2022-02-13| 2| 25| 40| 15|
--2022-02-14| 2| 15| 40| 15|
(7) NTILE(buckets) OVER (PARTITION BY ORDER BY)
NTINE(buckets) 의 buckets 개수 만큼 가능한 동일한 크기(equal size)를 가지는 집단으로 나누어줍니다.
아래 예 NTILE(2) OVER (PARTITION BY id ORDER BY val) 는 id 집합 내에서 val 을 기준으로 정렬을 한 상태에서 NTILE(2) 의 buckets = 2 개 만큼의 동일한 크기를 가지는 집단으로 나누어주었습니다.
짝수개면 정확하게 동일한 크기로 나누었을텐데요, id 집단 내 행의 개수가 5개로 홀수개인데 2개의 집단으로 나누려다 보니 가능한 동일한 크기인 3개, 2개로 나뉘었네요.
-- (7) NTILE() function allows you to divide ordered rows in the partition
-- into a specified number of ranked groups as EQUAL SIZE as possible.
SELECT
dt
, id
, val
, NTILE(2) OVER (PARTITION BY id ORDER BY val) AS ntile_val
FROM ts
ORDER BY id, val
;
--dt |id|val|ntile_val|
------------+--+---+---------+
--2022-02-10| 1| 25| 1|
--2022-02-11| 1| 28| 1|
--2022-02-13| 1| 34| 1|
--2022-02-12| 1| 35| 2|
--2022-02-14| 1| 39| 2|
--2022-02-14| 2| 15| 1|
--2022-02-13| 2| 25| 1|
--2022-02-12| 2| 30| 1|
--2022-02-11| 2| 35| 2|
--2022-02-10| 2| 40| 2|
(8) ROW_NUMBER() OVER (ORDER BY)
아래의 예 ROW_NUMBER() OVER (PARTITION BY id ORDER BY dt) 는 id 집합 내에서 dt 를 기준으로 올림차순 정렬 (sort in ascending order) 한 상태에서, 1 부터 시작해서 하나씩 증가시켜가면서 행 번호 (row number) 를 부여한 것입니다. 집합 내에서 특정 기준으로 정렬한 상태에서 특정 순서/위치의 값을 가져오기 한다거나, 집합 내에서 unique 한 ID 를 생성하고 싶을 때 종종 사용합니다.
-- (8) ROW_NUMBER() : Number the current row within its partition starting from 1.
SELECT
dt
, id
, val
, ROW_NUMBER() OVER (PARTITION BY id ORDER BY dt) AS seq_no
FROM ts
;
--dt |id|val|seq_no|
------------+--+---+------+
--2022-02-10| 1| 25| 1|
--2022-02-11| 1| 28| 2|
--2022-02-12| 1| 35| 3|
--2022-02-13| 1| 34| 4|
--2022-02-14| 1| 39| 5|
--2022-02-10| 2| 40| 1|
--2022-02-11| 2| 35| 2|
--2022-02-12| 2| 30| 3|
--2022-02-13| 2| 25| 4|
--2022-02-14| 2| 15| 5|