[Python sklearn] 숫자형과 범주형 변수가 있는 데이터 전처리 및 모델학습하는 파이프라인 만들기 (Column Transformer with Mixed Types using sklearn)
Python 분석과 프로그래밍/Python 기계학습 2022. 1. 19. 22:59데이터 유형별로 여러 단계를 거치는 데이터 전처리와 모델의 학습, 신규 데이터에 대한 예측의 전체 기계학습 워크 플로우를 파이프라인으로 관리하면 워크 플로우 관리를 간소화하고 자동화(workflow automation) 하는데 매우 큰 도움이 됩니다.
이번 포스팅에서는 Python의 scikit learn 모듈을 사용해서 숫자형과 범주형 변수가 섞여 있는 데이터셋의 데이터 전처리 및 선형회귀모형 모델을 학습하는 전체 파이프라인을 만드는 방법을 소개하겠습니다.
(1) 숫자형 변수의 결측값 처리 및 표준화하는 데이터 전처리 파이프라인 만들기
(2) 범주형 변수의 원핫인코딩하는 데이터 전처리 파이프라인 만들기
(3) ColumnTransformer 클래스로 숫자형과 범주형 변수 전처리 파이프라인 합치기
(4) 숫자형 & 범주형 데이터 전처리와 선형회귀모형 학습하는 파이프라인 만들기
(5) 모델 학습
(6) 예측 및 모델 성능 평가

먼저, 데이터 전처리 및 모델학습과 파이프라인을 구성하는데 필요한 Python modules 을 불러오겠습니다. 그리고 예제로 사용할 오픈 abalone.data 데이터셋을 가지고 pandas DataFrame을 만들어보겠습니다.
## Importing modules
import numpy as np
import pandas as pd
from sklearn.compose import ColumnTransformer
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import OneHotEncoder
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import Pipeline
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
## Making a DataFrame by reading abalone data set from URL
url = "http://archive.ics.uci.edu/ml/machine-learning-databases/abalone/abalone.data"
abalone = pd.read_csv(
url,
sep=",",
names = ['sex', 'length', 'diameter', 'height',
'whole_weight', 'shucked_weight', 'viscera_weight',
'shell_weight', 'rings'],
header = None)
abalone.head()
# sex length diameter height whole_weight shucked_weight viscera_weight shell_weight rings
# 0 M 0.455 0.365 0.095 0.5140 0.2245 0.1010 0.150 15
# 1 M 0.350 0.265 0.090 0.2255 0.0995 0.0485 0.070 7
# 2 F 0.530 0.420 0.135 0.6770 0.2565 0.1415 0.210 9
# 3 M 0.440 0.365 0.125 0.5160 0.2155 0.1140 0.155 10
# 4 I 0.330 0.255 0.080 0.2050 0.0895 0.0395 0.055 7
위의 abalone 데이터셋에서 숫자형 변수(numeric variable)인 "length", "whole_weight" 와 범주형 변수(categorical variable)인 "sex" 의 3개 칼럼을 이용해서 "rings" 를 예측하는 선형회귀모형(linear regression)을 학습시키고, 예측을 해보겠습니다.
(1) 숫자형 변수의 결측값 처리 및 표준화하는 데이터 전처리 파이프라인 만들기
숫자형 변수(numeric features)에 대해서는
(1-1) scikit learn 모듈의 SimpleImputer() 클래스를 이용해서 결측값을 "중앙값(median)"으로 대체(imputation)
(1-2) scikit learn 모듈의 StandardScaler() 클래스를 이용해서 표준화(standardization)
하는 단계를 거치는 파이프라인을 만들어보겠습니다.
콤마로 써주는 부분은 각 단계(step)의 alias 이름이 되겠습니다. 아래의 (5)번에서 전체 파이프라인을 시각화했을 때 콤마로 부연설명해준 alias 이름을 도식화한 파이프라인의 윗부분에서 볼 수 있습니다.
## (1) for numeric features
num_features = ["length", "whole_weight"]
num_transformer = Pipeline(
steps = [("imputer", SimpleImputer(strategy="median")), ("scaler", StandardScaler())]
)
(2) 범주형 변수의 원핫인코딩하는 데이터 전처리 파이프라인 만들기
범주형 변수(categorical features)에 대해서는 scikit learn 모듈의 OneHotEncoder() 클래스를 사용해서 각 범주별로 칼럼을 만들어서 해당 범주에 속하면 '1' (hot), 해당 범주에 속하지 않으면 '0' (cold) 으로 인코딩을 해서 기계가 인식할 수 있도록 해주는 단계를 정의하겠습니다.
(참고로, handle_unknown = "ignore" 옵션은 모델을 학습할 때 학습 데이터셋의 범주형 변수에는 없었던 범주가 예측에 사용하는 새로운 데이터셋에서 나타날 경우 무시하라는 의미입니다.)
## (2) Categorical features
cat_features = ["sex"]
cat_transformer = OneHotEncoder(handle_unknown="ignore")
(3) ColumnTransformer 클래스로 숫자형과 범주형 변수 전처리 파이프라인 합치기
위의 (1) 숫자형 데이터 전처리 단계와 (2) 범주형 데이터 전처리 단계를 정의하는 클래스와 파이프라인을 scikit learn 모듈의 ColumnTransformer() 클래스를 사용해서 숫자형 변수(num_features)와 범주형 변수(cat_features) 별로 매핑하여 하나의 데이터 전처리 파이프라인으로 합쳐보겠습니다.
## (3) Use ColumnTransformer by selecting column by names
preprocessor = ColumnTransformer(
transformers = [
("num", num_transformer, num_features),
("cat", cat_transformer, cat_features)
]
)
(4) 숫자형 & 범주형 데이터 전처리와 선형회귀모형 학습하는 파이프라인 만들기
이번에는 위의 (3)번에서 숫자형과 범주형 데이터 전처리를 하나로 묶은 데이터 전처리 파이프라인에 (4) 선형회귀모형을 적합하는 클래스를 추가해서 파이프라인을 만들어보겠습니다.
## (4) Append regressor to preprocessing pipeline.
lin_reg = Pipeline(
steps = [("preporcessor", preprocessor), ("regressor", LinearRegression())]
)
(5) 모델 학습
모델을 학습할 때 사용할 training set (0.8) 과 모델의 성능을 평가할 때 사용할 test set (0.2) 를 0.8:0.2의 비율로 무작위 추출해서 분할해보겠습니다.
## Split training(0.8) and test set(0.2) randomly
X = abalone[["length", "whole_weight", "sex"]]
y = abalone["rings"]
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.2,
random_state=1004)
sklean 의 set_config(display="diagram") 을 설정해주면 위의 (1) ~ (4) 에서 정의해준 숫자형 & 범주형 변수 데이터 전처리와 선형회귀모형 적합의 전체 기계학습 워크플로우 파이프라인을 다이어그램으로 시각화해서 볼 수 있습니다.
참고로, 파이프라인의 각 단계의 박스를 커서로 클릭하면 상세 옵션 설정 내용(예: SimpleImputer 클래스의 경우 strategy='median', OneHotEncoder 클래스의 handle_unknown='ignore' 등) 을 펼쳐서 볼 수 있습니다. 그리고 "num"과 "cat" 부분을 클릭하면 숫자형 변수와 범주형 변수 이름을 확인할 수 있습니다.
이제 드디어 준비가 다 되었군요. lin_reg.fit(X_train, y_train) 을 실행하면 (1)~(4)의 전체 워크플로우가 파이프라인을 따라서 순차적으로 실행이 됩니다. 코드가 참 깔끔해졌지요!
## Display a diagram of Pipelines in Jupyter Notebook
from sklearn import set_config
set_config(display="diagram")
## Fit a Linear Regression model using pipelines
lin_reg.fit(X_train, y_train)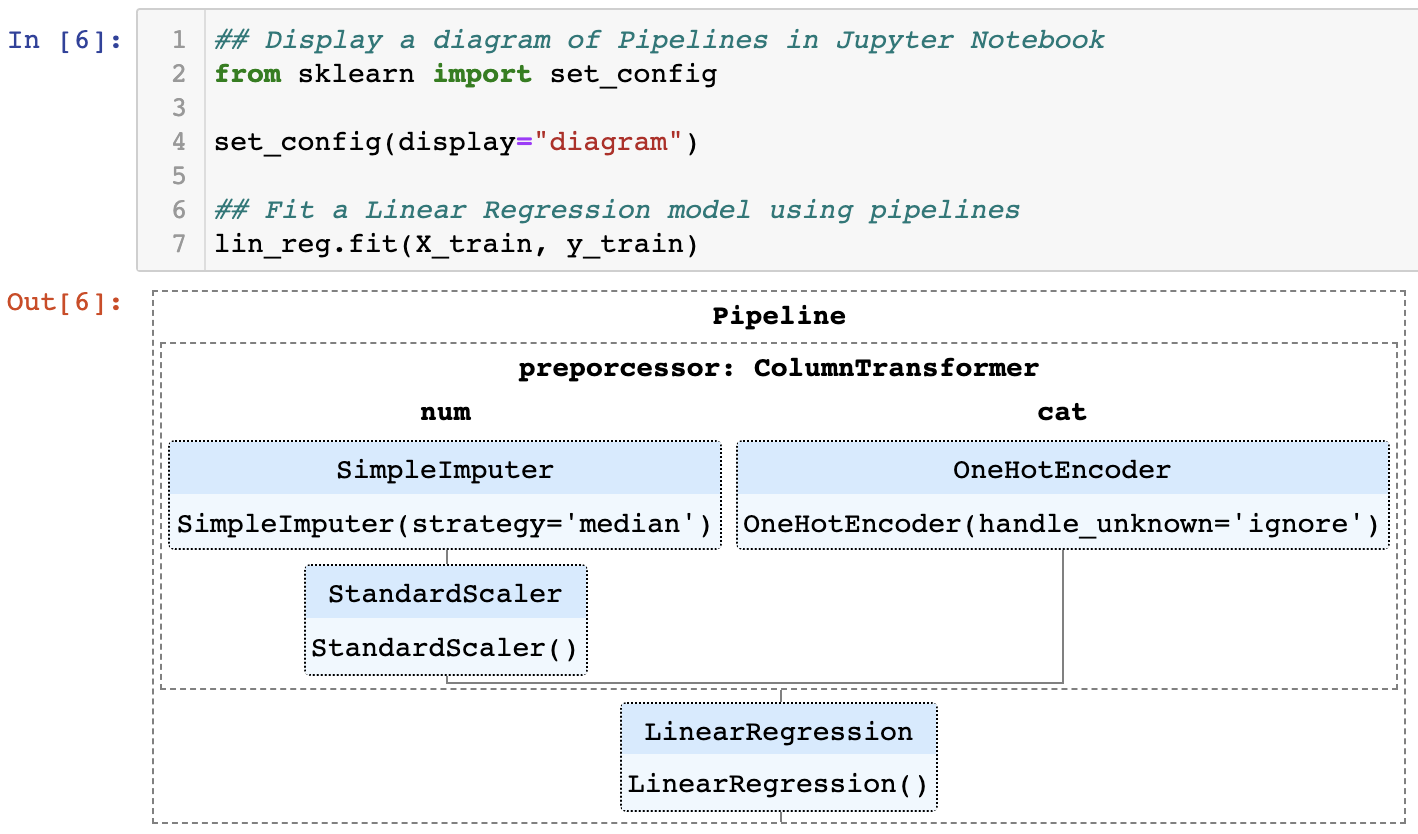
(6) 예측 및 모델 성능 평가
이제 따로 떼어놓았던 test set (0.2) 를 가지고 MAPE (Mean Absolute Percentage Error) 지표를 사용해서 모델의 성능을 평가해보겠습니다.
lin_reg.predict(X_test) 를 실행하면 앞서 정의했던 (1) ~ (4) 의 숫자형 & 문자형 변수별 데이터 전처리와 모델 예측의 전체 워크 플로우의 파이프라인이 물 흐르듯이 자동으로 알아서 진행이 됩니다. 너무나 신기하고 편리하지요?!
(파이프라인이 있으면 lin_reg.predict(X_test) 라는 코드 단 한줄이면 되는데요, 만약 위의 (1) ~ (4) 의 과정을 수작업으로 Test set 에 대해서 데이터 전처리해주는 코드를 다시 짠다고 생각을 해보세요. -_-;)
## Define UDF of MAPE(Mean Absolute Percentage Error)
## or sklearn.metrics.mean_absolute_percentage_error() class, which is new in version 0.24.
## : https://scikit-learn.org/stable/modules/generated/sklearn.metrics.mean_absolute_percentage_error.html#sklearn.metrics.mean_absolute_percentage_error
def MAPE(y_test, y_pred):
y_test, y_pred = np.array(y_test), np.array(y_pred)
return np.mean(np.abs((y_test - y_pred) / y_test)) * 100
## Evaluate performance of a model
y_pred = lin_reg.predict(X_test)
print("MSE: %.2f" % MAPE(y_test, y_pred))
#[out] MSE: 18.68
[ Reference ]
- Column Transformer with Mixed Types
: https://scikit-learn.org/stable/auto_examples/compose/plot_column_transformer_mixed_types.html
- sklearn SimpleImputer
: https://scikit-learn.org/stable/modules/generated/sklearn.impute.SimpleImputer.html
- sklearn StandardScaler
: https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.StandardScaler.html
- sklearn OneHotEncoder
: https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.OneHotEncoder.html
- sklearn Linear Regression
: https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LinearRegression.html
- sklearn Pipeline
: https://scikit-learn.org/stable/modules/generated/sklearn.pipeline.Pipeline.html
- sklearn train_test_split
: https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.html
- sklearn mean_squared_error
: https://scikit-learn.org/stable/modules/generated/sklearn.metrics.mean_squared_error.html
이번 포스팅이 많은 도움이 되었기를 바랍니다.
행복한 데이터 과학자 되세요! :-)

'Python 분석과 프로그래밍 > Python 기계학습' 카테고리의 다른 글
Rfriend님의
글이 좋았다면 응원을 보내주세요!



