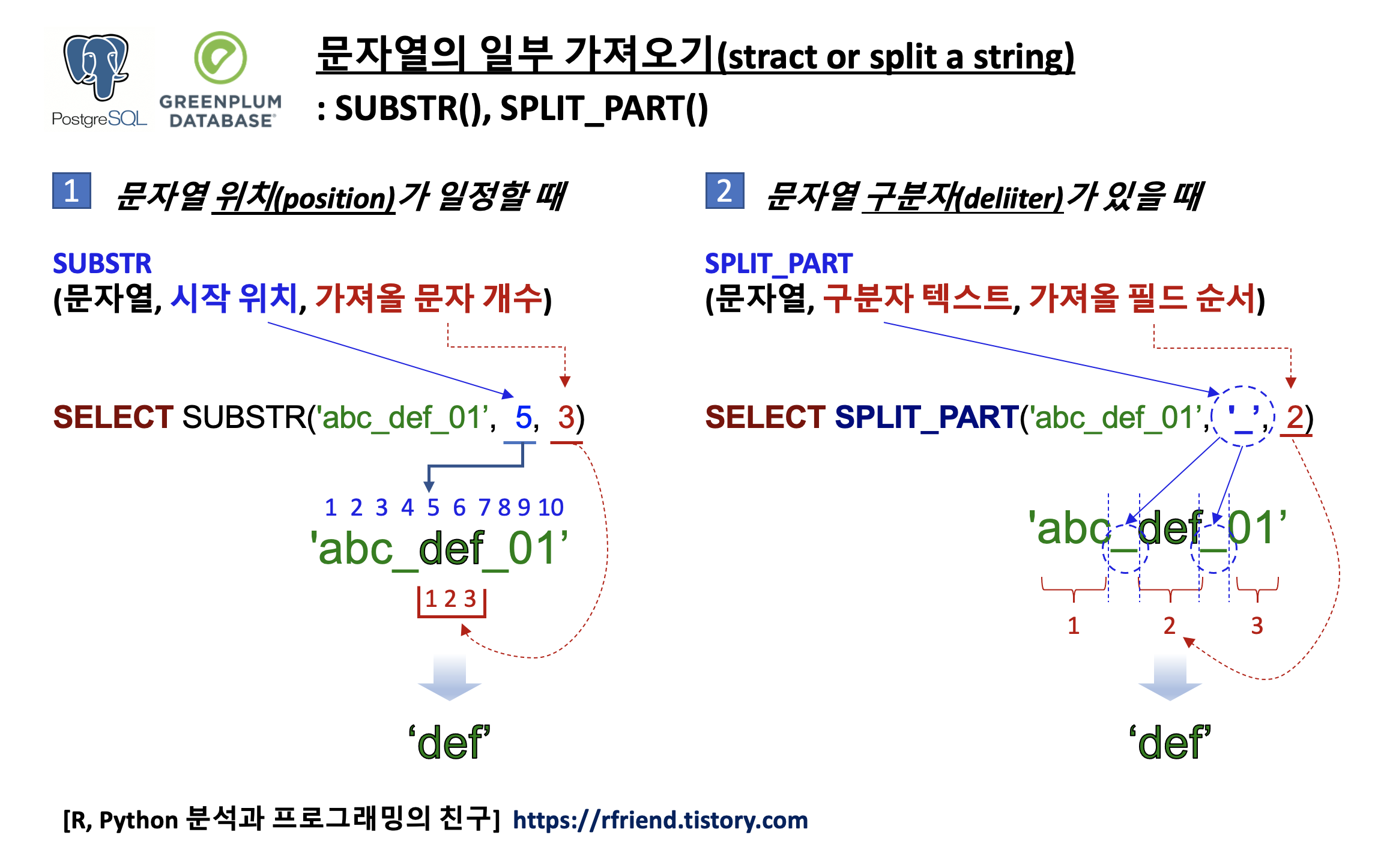
이번 포스팅에서는 정답 레이블 Y는 없고 오직 설명변수 X 만을 사용해서 데이터 내 관계, 패턴, 구조를 탐색하는데 사용하는 비지도학습 중에서 차원 축소 (Dimensionality Reduction) 에 대한 이론적인 부분을 알아보겠습니다. (Python 코딩은 다음번 포스팅부터 해볼께요.)
1. 차원 축소란 무엇인가? (What is Dimensionality Reduction?)
2. 왜 차원 축소가 필요한가? (Why is Dimensionality Reduction?)
3. 차원 축소의 단점은? (Pitfall of Dimensionality Reduction)
4. 차원 축소하는 방법은? (How to do Dimensionality Reduction?)
1. 차원 축소란 무엇인가? (What is Dimensionality Reduction?)
차원 축소 (Dimensionality Reduction, 또는 Dimension Reduction) 는 저차원 표현(low-dimensional representation)이 고차원 원본 데이터의 의미 있는 특성을 이상적으로 원래의 차원에 가깝게 유지할 수 있도록 고차원 공간에서 저차원 공간으로 데이터를 변환(the transformation of data from a high-dimensional space into a low-dimensional space)하는 것을 말합니다.[wikipedia, 1]
차원 축소를 하게 되면 원본 데이터로부터 일부 정보 손실 (information loss)이 발생하는데요, 원본 데이터로부터의 정보 손실을 최소화하면서 저차원으로 얼마나 잘 재표현(representation)할 수 있느냐가 관건이 되겠습니다.
[ 차원 축소 (Dimensionality Reduction) vs. 군집 분석 (Clustering) ]

차원 축소 (Dimensionality Reduction)와 군집분석 (Clustering) 모두 정답 Label Y 가 필요없이 특성 변수(features) 만을 가지고 데이터의 구조와 특성을 파악하는 비지도학습(Unsupervised Learning) 에 속합니다.
군집분석 (Clustering) 은 관측치, 객체 간의 유사성(similarity)을 측정해서 유사한 관측치, 객체끼리 그룹을 만드는 분석 기법을 말합니다. 반면에 차원 축소 (Dimensionality Reduction) 는 특성 변수(features, variables)를 대상으로 변수 간 상관성에 기초해서 고차원에서 저차원 공간으로 재표현하는 변수 변환을 말합니다.
2. 왜 차원 축소가 필요한가? (Why is Dimensionality Reduction?)
차원 축소를 하는 이유, 활용 목적에는 여러가지가 있는데요, 먼저 기계학습 측면에서는 차원 축소가 차원의 저주 (Curse of Dimensionality)를 피하고, 과적합 (Overfitting) 을 방지하는데 효과적입니다.
차원의 저주(Curse of Dimensionality) 는 일상적 경험의 3차원 물리적 공간 등 저차원적 환경에서 일어나지 않는 고차원적 공간에서 데이터를 분석하고 정리할 때 발생하는 다양한 현상을 말합니다. 이 표현은 Richard E. Bellman 이 동적 프로그래밍의 문제를 고려할 때 처음 사용하였습니다. 차원 저주 현상은 수치 분석, 샘플링, 조합론, 기계 학습, 데이터 마이닝 및 데이터베이스와 같은 영역에서 발생합니다. 이러한 문제의 공통 주제는 차원성이 증가하면 공간의 부피가 너무 빠르게 증가하여 사용 가능한 데이터가 희박해진다는 것입니다. 신뢰할 수 있는 결과를 얻기 위해 필요한 데이터의 양은 차원성에 따라 기하급수적으로 증가하는 경우가 많습니다. 또한 데이터를 구성하고 검색하는 것은 종종 객체가 유사한 속성을 가진 그룹을 형성하는 영역을 감지하는 데 의존합니다. 그러나 고차원 데이터에서는 모든 객체가 여러 면에서 희박하고 유사하지 않아 일반적인 데이터 구성 전략이 효율적이지 못하게 됩니다. [wikipedia, 2]
통계학의 선형회귀모형에는 독립변수(independent variable, 혹은 설명변수 explanatory variable, 혹은 예측변수 predictor variable) 들 간의 독립을 가정합니다. (독립변수라는 이름 자체에 변수 간 독립을 명시함. ㅎㅎ) 그런데 모델링에 인풋으로 사용하는 설명변수 간 다중공선성(multicolleniarity)이 존재할 경우 추정된 회귀계수의 분산이 커져서 모델이 불안정하고 과적합에 빠지는 위험이 있습니다. 독립변수간 다중공선성(multicolleniarity)을 해결하는 몇가지 방법 중의 하나가 독립변수간 상관성에 기반해서 차원을 축소한 후에 회귀모형을 적합하는 방법입니다.
탐색적 데이터 분석을 하는 단계에서 변수 간 관계를 파악하기 위해서 산점도(scatter plot)으로 시각화(visualization) 해서 보면 효과적인데요, 만약 특성변수(features)의 개수가 여러개일 경우에는 2개 특성변수 간 조합의 개수가 기하급수적으로 늘어나기 때문에 모든 조합을 시각화해서 살펴보는 것에 어려움이 있습니다. 이럴 경우, 차원축소를 해서 소수의 차원에 대해서 시각화를 하면 많은 양의 정보를 효과적으로 시각화해서 데이터 특성을 탐색해볼 수 있습니다.
이밖에도 차원 축소를 하면 이후의 데이터 처리, 분석 시에 연산 속도를 향상(performance incease)시킬 수 있습니다. 그리고 데이터를 압축(data compression)하여 데이터 저장이나 전송 효율을 높이는데도 차원 축소를 사용할 수 있습니다.
3. 차원 축소의 단점은? (Pitfall of Dimensionality Reduction)
차원 축소를 하게 되면 원본 데이터 대비 정도의 차이일 뿐 필연적으로 정보 손실 (Information Loss) 이 발생합니다. 그리고 원본 데이터 대비 차원 축소한 데이터를 해석하는데도 어려움이 (hard to interprete) 생깁니다. 또한 차원 축소를 위한 데이터 변환 절차가 추가되므로 데이터 파이프 라인 (data pipeline) 이 복잡해지는 단점도 있습니다.
4. 차원 축소하는 방법은? (How to do Dimensionality Reduction?)
차원 축소하는 방법은 크게 (Linear) Projection 과 (Non-linear) Manifold Learning 의 2가지로 나눌 수 있습니다.
(4-1) Projection-based Dimensionality Reduction: 주성분분석 (PCA, Principal Component Analysis), 특이값 분해 (Singular Value Decomposition), 요인분석 (Factor Analysis)
(4-2) Manifold Learning: LLE (Locally-Linear Embedding), Isomap, Kernel Principal Component Analysis, Autoencoders, SOM(Self-Organizing Map)

다음번 포스팅에서는 linear projection 방법 중에서 Python 의 Sklearn 모듈을 활용하여 주성분분석 (PCA, Principal Component Analysis)을 하는 방법을 소개하겠습니다.
[ Reference ]
[1] Wikipedia - Dimensionality Reduction: https://en.wikipedia.org/wiki/Dimensionality_reduction
[2] Wikipedia - Curse of Dimensionality: https://en.wikipedia.org/wiki/Curse_of_dimensionality
[3] Wikipedia - Nonlinear Dimensionality Reduction: https://en.wikipedia.org/wiki/Nonlinear_dimensionality_reduction
이번 포스팅이 많은 도움이 되었기를 바랍니다.
행복한 데이터 과학자 되세요! :-)