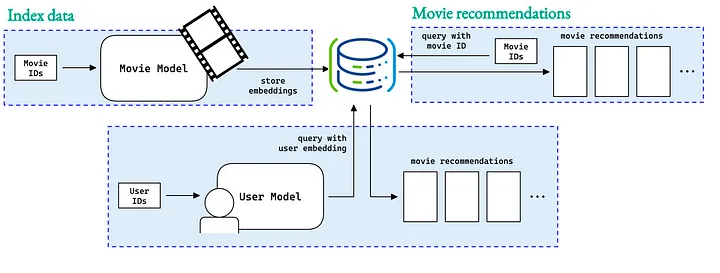
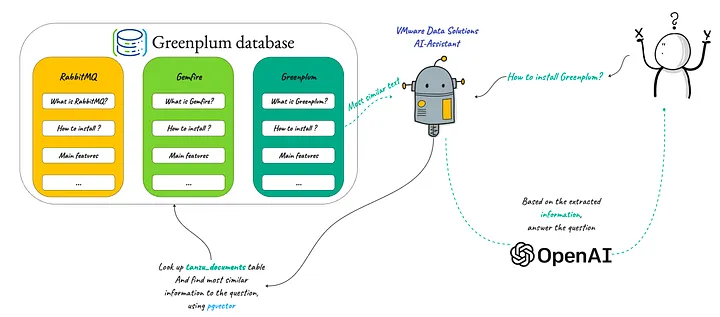
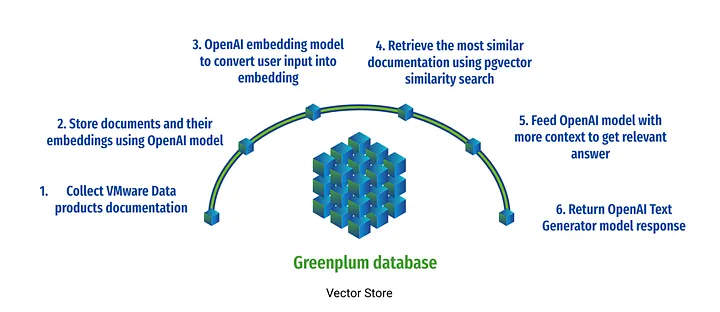
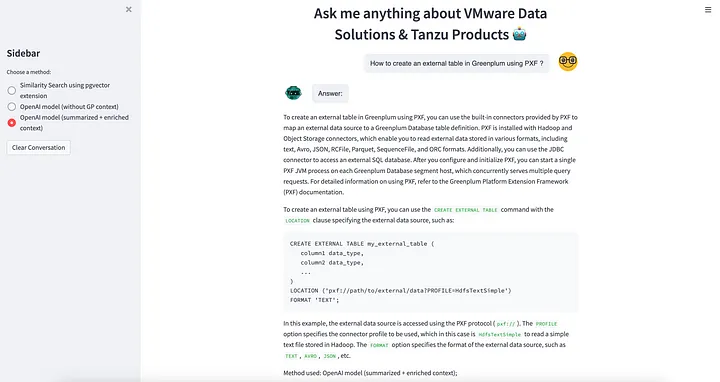
Google Colab에 PostgreSQL 과 pgvector extension 설치하는 방법 (How to install PosgreSQL and pgvector in Google Colab?)
Greenplum and PostgreSQL Database 2023. 12. 31. 23:23Google Colab에 PostgreSQL과 pgvector를 설치하면 Python 과 함께 Text, Image Embeddings 변환, 저장 및 Semantic Search 등에 사용할 수 있어서 편리합니다.
1. Google Colab 은 무엇인가?
Google Colab, 또는 Colaboratory는 Google에서 제공하는 무료 Jupyter 노트북 환경입니다. 이 서비스는 클라우드 기반으로 운영되며, 데이터 분석, 머신 러닝, 교육 및 연구를 위한 플랫폼으로 널리 사용됩니다. 주요 특징과 장점은 다음과 같습니다.
- 웹 기반 인터페이스: 설치가 필요 없으며, 웹 브라우저를 통해 접근하고 사용할 수 있습니다. 이는 사용자가 어디에서나 쉽게 작업을 시작할 수 있게 해줍니다.
- 무료 접근: 기본적인 사용은 무료이며, 누구나 Google 계정을 통해 접근할 수 있습니다.
- GPU 및 TPU 지원: 데이터 과학과 머신 러닝 작업을 위해 고성능 컴퓨팅 자원인 GPU와 TPU를 무료로 사용할 수 있습니다.
- Python 지원: Python 프로그래밍 언어와 다양한 라이브러리(NumPy, Pandas, Matplotlib 등)를 지원합니다. 또한 TensorFlow, PyTorch 같은 머신 러닝 라이브러리를 사용할 수 있습니다.
- 협업: Google 드라이브와의 통합을 통해 쉽게 공유하고, 다른 사용자와 협업할 수 있습니다. 문서 형식의 노트북에서 직접 코드를 작성하고 실행할 수 있어 팀워크에 유용합니다.
- 교육 및 연구 목적: 교육과 연구를 위한 훌륭한 도구로, 대학 강의, 워크샵, 개인 프로젝트 등 다양한 목적으로 활용됩니다.
Google Colab은 특히 하드웨어 리소스에 제한이 있는 사용자나 빠른 프로토타이핑을 원하는 데이터 과학자 및 연구자들에게 매우 유용합니다.
2. PostgreSQL 은 무엇인가?
PostgreSQL은 고급 오픈 소스 관계형 데이터베이스 관리 시스템(RDBMS)입니다. PostgreSQL은 강건함, 확장성, 그리고 SQL 표준 준수로 잘 알려져 있습니다. PostgreSQL은 복잡한 쿼리, 외래 키, 트리거, 뷰, 트랜잭션의 무결성, 다중 버전 동시성 제어 등 다양한 기능을 제공합니다. 간단한 웹 애플리케이션부터 복잡한 데이터 웨어하우징 및 지리공간 데이터 분석에 이르기까지 다양한 애플리케이션에 적합한 선택입니다.
3. pgvector extension은 무엇인가?
pgvector는 고차원 벡터 공간에서의 효율적인 유사성 검색을 위해 설계된 PostgreSQL 확장 기능(an extension for Pogres for efficient similarity search in high-dimensional vector spaces)입니다. 이미지, 텍스트, 오디오 등에 대한 임베딩과 같은 벡터가 일반적인 머신 러닝 애플리케이션에 특히 유용합니다. pgvector는 추천 시스템, 이미지 검색, 자연어 처리 애플리케이션과 같은 작업에 필수적인 빠른 최근접 이웃 검색을 지원합니다.
pgvector의 주요 측면은 다음과 같습니다.
- 벡터 데이터 타입 (Vector Data Type): 벡터를 저장하기 위한 새로운 데이터 타입을 도입합니다.
- 벡터용 인덱싱 (Indexing for Vectors): 고차원 데이터에서 검색 성능을 향상시키는 벡터에 최적화된 인덱싱 방법을 제공합니다.
: IVFFlat (Inverted File with Flat Compression), HNSW (Hierarchical Navigable Small World)
- PostgreSQL과의 통합 (Integration with PostreSQL): 강력한 데이터베이스 기능을 활용하여 PostgreSQL과 원활하게 작동합니다.
- 머신 러닝 파이프라인에서의 사용 (Use in Machine Learning Pipelines): 임베딩과 같은 머신 러닝 모델 출력의 저장 및 쿼리에 이상적입니다.
PostgreSQL과 pgvector가 오픈소스이고 확장성(Scalability) 이 뛰어나다는 점은 다른 전용 Vector DB 대비 큰 강점입니다. (아래 블로그 포스팅 참고)
* Why did we replace Pinecone with PGVecotr?:
https://medium.com/@jeffreyip54/why-we-replaced-pinecone-with-pgvector-2f679d253eba
PostgreSQL과 pgvector의 결합은 특히 머신 러닝 모델을 포함하는 복잡한 데이터 집약적 애플리케이션을 친숙하고 강력한 데이터베이스 환경 내에서 처리할 수 있게 합니다.
이번 포스팅에서는
(1) Google Colab에 PostgreSQL 설치하기
(2) Google Colab에 설치된 PostgreSQL에 pgvector extension 설치하기
에 대해서 소개하겠습니다.

(1) Google Colab에 PostgreSQL 설치하기
(How to install PostgreSQL in Google Colab?)
- PostgreSQL 설치
!sudo apt-get -y -qq update
!sudo apt-get -y -qq install postgresql
- PostgreSQL 서버 서비스 시작하기
!sudo service postgresql start
- User와 Password 설정하기
# Setup a password 'postgres' for username 'postgres'
!sudo -u postgres psql -U postgres -c "ALTER USER postgres PASSWORD 'postgres';"
- 'dev' 데이터베이스 만들기
# Setup a database with name 'dev' to be used
!sudo -u postgres psql -U postgres -c "DROP DATABASE IF EXISTS dev;"
!sudo -u postgres psql -U postgres -c "CREATE DATABASE dev;"
- 'dev' 데이터베이스에 연결하기
# set connection
%env DATABASE_URL=postgresql://postgres:postgres@localhost:5432/dev
- %load_ext sql 로 SQL 확장 모듈 로드하기
%load_ext는 Jupyter Notebook과 같은 IPython 환경에서 사용하는 매직 명령어 중 하나입니다. 이 명령어는 확장(extension) 모듈을 로드하고 활성화하는 데 사용됩니다. 확장 모듈은 추가 기능을 제공하며, %load_ext sql을 사용하여 SQL 쿼리를 실행할 수 있습니다.
# To load the sql extention to start using %%sql
%load_ext sql
- SQL query 테스트
# You can start executing postgres sql commands
%%sql
select version();
-- version
-- PostgreSQL 14.9 (Ubuntu 14.9-0ubuntu0.22.04.1) on x86_64-pc-linux-gnu, compiled by gcc (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0, 64-bit
(2) Google Colab의 PostgreSQL에 pgvector extension 설치하기
(How to install pgvector extension in Google Colab?)
- git clone 해서 pgvector extension 설치 파일 다운로드하기
!git clone --branch v0.5.1 https://github.com/pgvector/pgvector.git
- pgvector 설치 파일이 다운로드 되어있는 폴더로 경로 변경
(Google Colab의 마운트 한 후, content 폴더에 저장됨)
%cd /content/pgvector
- pgvector 설치
!make
!make install
- pgvector 확장 실행: CREATE EXTENSION vector;
- PostgreSQL 서버에 로그인
- PostgreSQL의 확장 벡터를 생성하려는 데이터베이스로 연결
- 확장 벡터를 생성하려는 데이터베이스에서 다음 명령어를 실행
(데이터베이스 별로 최초 1회만 실행해주면 됩니다)
%%sql
CREATE EXTENSION IF NOT EXISTS vector;
참고로, pgvector 에서 제공하는 연산자는 아래의 6개가 있습니다. 사용자 질문과 문서 간 텍스트 임베딩에 대한 Semantic Search 에 코사인 유사도 (1 - Cosine Distance) 가 많이 사용됩니다.
| 연산자 (operator) | 설명 (description) |
| + | 요소 별 더하기 (Element-wise Addition) |
| - | 요소 별 빼기 (Element-wise Subtraction) |
| * | 요소 별 곱하기 (Element-wise Multiplication) |
| <-> | 유클리드 거리 (Euclidean Distance) |
| <#> | 음의 내적 (Negative Inner Product) |
| <=> | 코사인 거리 (Cosine Distance) |
[ Reference ]
* Postres pgvector: https://github.com/pgvector/pgvector
* Vector Indexes in Postgres using pgvector: IVFFlat vs. HNSW:
https://tembo.io/blog/vector-indexes-in-pgvector/
이번 포스팅이 많은 도움이 되었기를 바랍니다.
행복한 데이터 과학자 되세요! :-)

'Greenplum and PostgreSQL Database' 카테고리의 다른 글
Rfriend님의
글이 좋았다면 응원을 보내주세요!