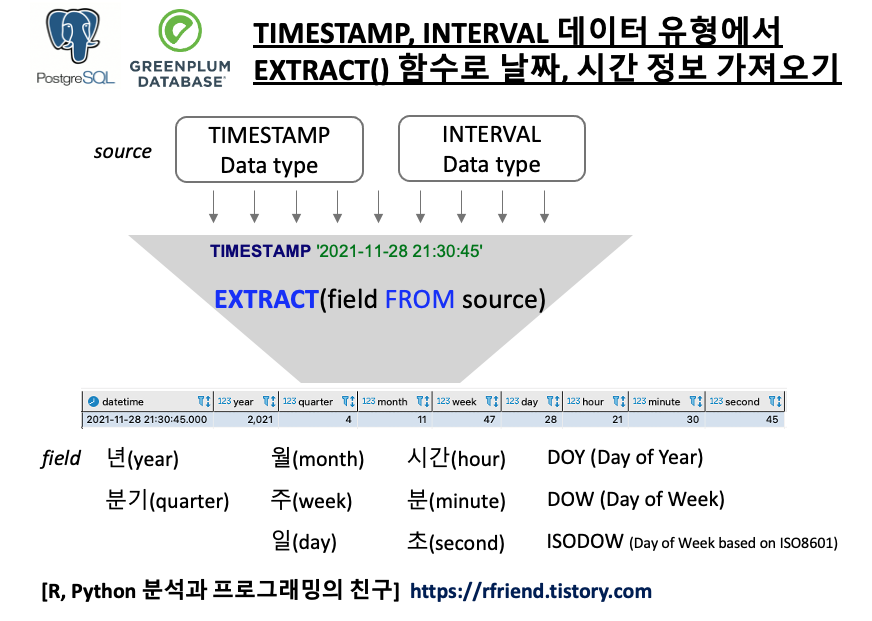
[PostgreSQL, Greenplum] 결측값을 이전 값으로 채우기 (Forward filling NULL values with the previous non-null value)
Greenplum and PostgreSQL Database 2021. 12. 11. 17:27데이터 분석을 하다보면 데이터 전처리 단계에서 '결측값 확인 및 처리(handling missing values) '가 필요합니다.
시계열 데이터의 결측값을 처리하는 방법에는 보간(interpolation), 이전/이후 값으로 대체, 이동평균(moving average)으로 대체 등 여러가지 방법(https://rfriend.tistory.com/682)이 있습니다.
이번 포스팅에서는 가장 간단한 방법으로서 PostgreSQL, Greenplum DB에서 SQL로 first_value() window function을 사용해서 할 수 있는 '결측값을 이전 값으로 채우기' 또는 '결측값을 이후 값으로 채이기' 하는 방법을 소개하겠습니다.
(1) 결측값을 이전 값으로 채우기
(Forward filling NULL values with the previous non-null value)
(2) 여러개 칼럼의 결측값을 이전 값으로 채우기
(Forward filling NULL values in Multiple Columns with the previous non-null value)
(3) 그룹별로 결측값을 이전 값으로 채우기
(Forward filling NULL values by Group with the previous non-null value)
(4) 결측값을 이후 값으로 채우기
(Backward filling NULL values with the next non-null value)
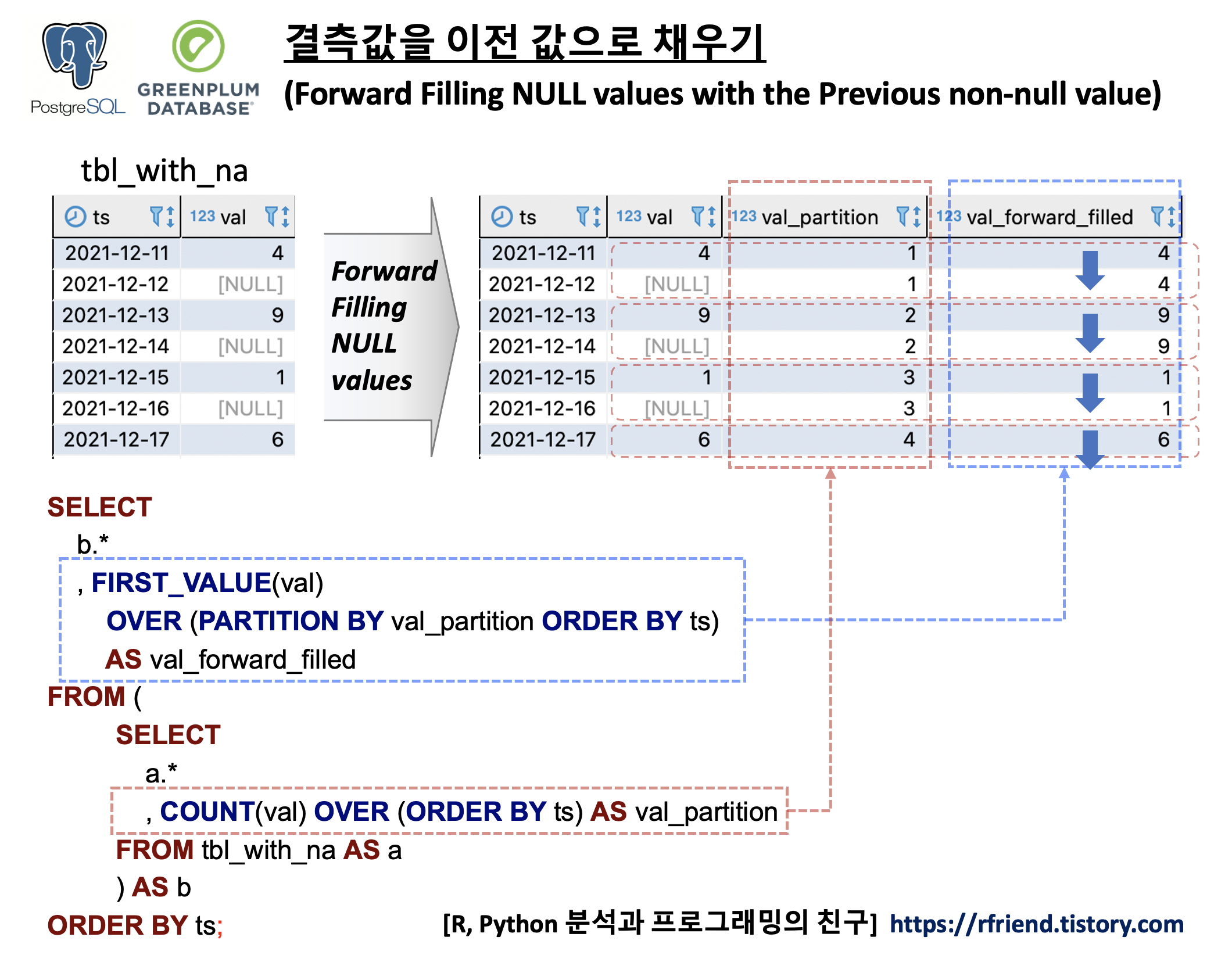
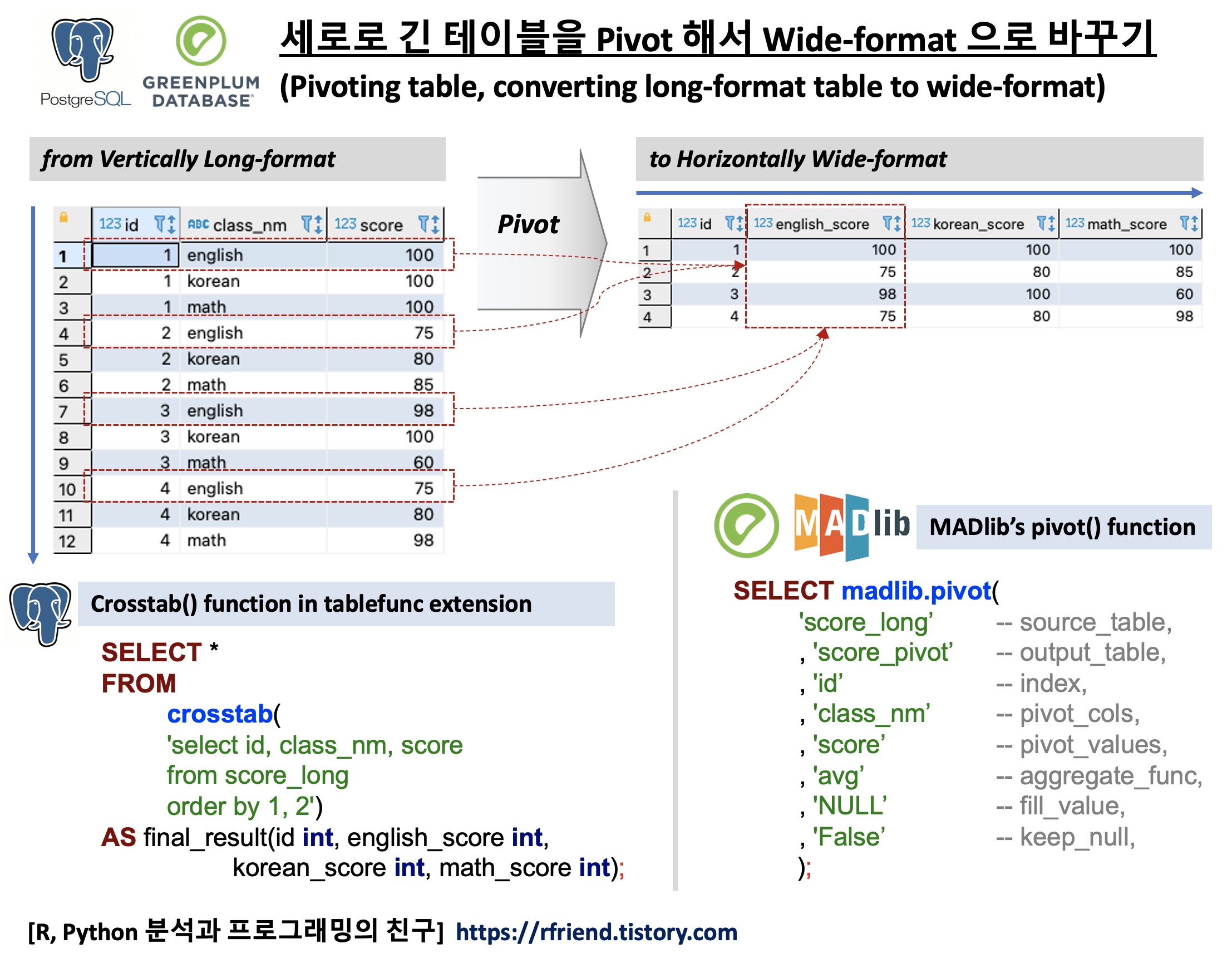
결측값을 시계열데이터의 TimeStamp 를 기준으로 정렬한 상태에서 SQL로 결측값을 이전의 실측값으로 채우는 방법의 핵심은 FIRST_VALUE() Window Function 을 사용하는 것입니다. FIRST_VALUE() 의 구문은 아래와 같으며, OVER(PARTITION BY column_name ORDER BY TimeStamp_column_name) 의 기능은 위의 예제에 대한 도식의 빨강, 파랑 박스와 화살표를 참고하시기 바랍니다.
-- PostgreSQL FIRST_VALUE() Window Function syntax
FIRST_VALUE ( expression )
OVER (
[PARTITION BY partition_expression, ... ]
ORDER BY sort_expression [ASC | DESC], ...
)
(1) 결측값을 이전 값으로 채우기
(Forward filling NULL values with the previous non-null value)
먼저, 날짜를 나타내는 'ts' 칼럼과 결측값을 가지는 'val' 칼럼으로 구성된 예제 테이블을 만들어보겠습니다.
-- creating a sample dataset with NULL values
DROP TABLE IF EXISTS tbl_with_na;
CREATE TABLE tbl_with_na (
ts DATE NOT NULL
, val int
);
INSERT INTO tbl_with_na VALUES
('2021-12-11', 4)
, ('2021-12-12',NULL)
, ('2021-12-13', 9)
, ('2021-12-14', NULL)
, ('2021-12-15', 1)
, ('2021-12-16', NULL)
, ('2021-12-17', 6)
;
SELECT * FROM tbl_with_na ORDER BY ts;
--ts |val|
------------+---+
--2021-12-11| 4|
--2021-12-12| |
--2021-12-13| 9|
--2021-12-14| |
--2021-12-15| 1|
--2021-12-16| |
--2021-12-17| 6|
이제 FIRST_VALUE() OVER(), COUNT() OVER() 의 window function 을 사용해서 결측값을 이전 실측값으로 채워보겠습니다.
-----------------------------------------------------
-- (1) Forward Filling NULL values
-----------------------------------------------------
SELECT
b.*
, FIRST_VALUE(val)
OVER (PARTITION BY val_partition ORDER BY ts)
AS val_forward_filled
FROM (
SELECT
a.*
, count(val) OVER (ORDER BY ts) AS val_partition
FROM tbl_with_na AS a
) AS b
ORDER BY ts;
--ts |val|val_partition|val_forward_filled|
------------+---+-------------+------------------+
--2021-12-11| 4| 1| 4|
--2021-12-12| | 1| 4|
--2021-12-13| 9| 2| 9|
--2021-12-14| | 2| 9|
--2021-12-15| 1| 3| 1|
--2021-12-16| | 3| 1|
--2021-12-17| 6| 4| 6|
(2) 여러개 칼럼의 결측값을 이전 값으로 채우기
(Forward filling NULL values in Multiple Columns with the previous non-null value)
먼저, 날짜를 나타내는 칼럼 'ts'와 측정값을 가지는 2개의 칼럼 'val_1', 'val_2'로 구성된 예제 테이블을 만들어 보겠습니다.
-- creating a sample table with NULL values in multiple columns
DROP TABLE IF EXISTS tbl_with_na_mult_cols;
CREATE TABLE tbl_with_na_mult_cols (
ts DATE NOT NULL
, val_1 int
, val_2 int
);
INSERT INTO tbl_with_na_mult_cols VALUES
('2021-12-11', 1, 5)
, ('2021-12-12',NULL, NULL)
, ('2021-12-13', 2, 6)
, ('2021-12-14', NULL, 7)
, ('2021-12-15', 3, NULL)
, ('2021-12-16', NULL, NULL)
, ('2021-12-17', 4, 8)
;
SELECT * FROM tbl_with_na_mult_cols ORDER BY ts;
--ts |val_1|val_2|
------------+-----+-----+
--2021-12-11| 1| 5|
--2021-12-12| | |
--2021-12-13| 2| 6|
--2021-12-14| | 7|
--2021-12-15| 3| |
--2021-12-16| | |
--2021-12-17| 4| 8|
다음으로 결측값을 채우려는 여러개의 각 칼럼마다 FIRST_VALUE() OVER(), COUNT() OVER() 의 window function 을 사용해서 결측값을 이전 값으로 채워보겠습니다.
------------------------------------------------------------------
-- (2) Forward Filling NULL values in Multiple Columns
------------------------------------------------------------------
SELECT
b.ts
, b.val_1
, b.val_1_partition
, FIRST_VALUE(val_1)
OVER (PARTITION BY val_1_partition ORDER BY ts)
AS val_1_fw_filled
, b.val_2
, b.val_2_partition
, FIRST_VALUE(val_2)
OVER (PARTITION BY val_2_partition ORDER BY ts)
AS val_2_fw_filled
FROM (
SELECT
a.*
, count(val_1) OVER (ORDER BY ts) AS val_1_partition
, count(val_2) OVER (ORDER BY ts) AS val_2_partition
FROM tbl_with_na_mult_cols AS a
) AS b
ORDER BY ts;
--ts |val_1|val_1_partition|val_1_fw_filled|val_2|val_2_partition|val_2_fw_filled|
------------+-----+---------------+---------------+-----+---------------+---------------+
--2021-12-11| 1| 1| 1| 5| 1| 5|
--2021-12-12| | 1| 1| | 1| 5|
--2021-12-13| 2| 2| 2| 6| 2| 6|
--2021-12-14| | 2| 2| 7| 3| 7|
--2021-12-15| 3| 3| 3| | 3| 7|
--2021-12-16| | 3| 3| | 3| 7|
--2021-12-17| 4| 4| 4| 8| 4| 8|
(3) 그룹별로 결측값을 이전 값으로 채우기
(Forward filling NULL values by Group with the previous non-null value)
이번에는 2개의 그룹('a', 'b')이 있고, 'val' 칼럼에 결측값이 있는 예제 데이터 테이블을 만들어보겠습니다.
-- creating a sample dataset with groups
DROP TABLE IF EXISTS tbl_with_na_grp;
CREATE TABLE tbl_with_na_grp (
ts DATE NOT NULL
, grp TEXT NOT NULL
, val int
);
INSERT INTO tbl_with_na_grp VALUES
('2021-12-11', 'a',1) -- GROUP 'a'
, ('2021-12-12','a', NULL)
, ('2021-12-13', 'a', 2)
, ('2021-12-14', 'a', NULL)
, ('2021-12-15', 'a', 3)
, ('2021-12-16', 'a', NULL)
, ('2021-12-17', 'a', 4)
, ('2021-12-11', 'b', 11) -- GROUP 'b'
, ('2021-12-12', 'b', NULL)
, ('2021-12-13', 'b', 13)
, ('2021-12-14', 'b', NULL)
, ('2021-12-15', 'b', 15)
, ('2021-12-16', 'b', NULL)
, ('2021-12-17', 'b', 17)
;
SELECT * FROM tbl_with_na_grp ORDER BY grp, ts;
--ts |grp|val|
------------+---+---+
--2021-12-11|a | 1|
--2021-12-12|a | |
--2021-12-13|a | 2|
--2021-12-14|a | |
--2021-12-15|a | 3|
--2021-12-16|a | |
--2021-12-17|a | 4|
--2021-12-11|b | 11|
--2021-12-12|b | |
--2021-12-13|b | 13|
--2021-12-14|b | |
--2021-12-15|b | 15|
--2021-12-16|b | |
--2021-12-17|b | 17|
이제 그룹 별로(OVER (PARTITION BY grp, val_partition ORDER BY ts)) 이전 값으로 채우기(FIRST_VALUE(val))를 해보겠습니다.
----------------------------------------------------------
-- (3) Forward Filling NULL values by Group
----------------------------------------------------------
SELECT
b.*
, FIRST_VALUE(val)
OVER (PARTITION BY grp, val_partition ORDER BY ts)
AS val_filled
FROM (
SELECT
a.*
, count(val)
OVER (PARTITION BY grp ORDER BY ts)
AS val_partition
FROM tbl_with_na_grp AS a
) AS b
ORDER BY grp, ts;
--ts |grp|val|val_partition|val_filled|
------------+---+---+-------------+----------+
--2021-12-11|a | 1| 1| 1|
--2021-12-12|a | | 1| 1|
--2021-12-13|a | 2| 2| 2|
--2021-12-14|a | | 2| 2|
--2021-12-15|a | 3| 3| 3|
--2021-12-16|a | | 3| 3|
--2021-12-17|a | 4| 4| 4|
--2021-12-11|b | 11| 1| 11|
--2021-12-12|b | | 1| 11|
--2021-12-13|b | 13| 2| 13|
--2021-12-14|b | | 2| 13|
--2021-12-15|b | 15| 3| 15|
--2021-12-16|b | | 3| 15|
--2021-12-17|b | 17| 4| 17|
(4) 결측값을 이후 값으로 채우기
(Backward filling NULL values with the next non-null value)
결측값을 이전 값(previous non-null value)이 아니라 이후 값(next non-null value) 으로 채우려면 (1)번의 SQL 코드에서 OVER (ORDER BY ts DESC)) 처럼 내림차순으로 정렬(sorting in DESCENDING order) 해준 후에 FIRST_VALUE() 를 사용하면 됩니다.
-----------------------------------------------------
-- (4) Backward Filling NULL values
-----------------------------------------------------
SELECT
b.*
, FIRST_VALUE(val)
OVER (PARTITION BY grp, val_partition ORDER BY ts DESC)
AS val_filled
FROM (
SELECT
a.*
, count(val)
OVER (PARTITION BY grp ORDER BY ts DESC)
AS val_partition
FROM tbl_with_na_grp AS a
) AS b
ORDER BY grp, ts;
--ts |grp|val|val_partition|val_filled|
------------+---+---+-------------+----------+
--2021-12-11|a | 1| 4| 1|
--2021-12-12|a | | 3| 2|
--2021-12-13|a | 2| 3| 2|
--2021-12-14|a | | 2| 3|
--2021-12-15|a | 3| 2| 3|
--2021-12-16|a | | 1| 4|
--2021-12-17|a | 4| 1| 4|
--2021-12-11|b | 11| 4| 11|
--2021-12-12|b | | 3| 13|
--2021-12-13|b | 13| 3| 13|
--2021-12-14|b | | 2| 15|
--2021-12-15|b | 15| 2| 15|
--2021-12-16|b | | 1| 17|
--2021-12-17|b | 17| 1| 17|
[ Reference ]
* PostgreSQL window function first_value()
: https://www.postgresqltutorial.com/postgresql-first_value-function/
* PostgreSQL window functions
: https://www.postgresql.org/docs/9.4/functions-window.html
이번 포스팅이 많은 도움이 되었기를 바랍니다.
행복한 데이터 과학자 되세요! :-)