확률과 우도(likelihood)는 통계 및 확률 이론에서 사용되는 관련된 개념으로, 각각 독특한 의미와 적용을 갖고 있습니다.
1. 확률 (Probability)
- 정의: 확률은 특정 이벤트가 발생할 가능성을 측정하며, 0에서 1 사이의 숫자로 나타납니다. 0은 불가능함을 나타내고, 1은 확실함을 나타내며, 0과 1 사이의 값은 다른 정도의 가능성을 나타냅니다.
- 해석: 예를 들어, 어떤 이벤트의 확률이 0.8이면 해당 이벤트가 발생할 확률이 80%인 것을 의미합니다.
2. 우도 (likelihood):
- 정의: 반면에 우도는 관찰된 데이터가 특정 가설이나 모델을 지원하는 정도를 측정합니다. 우도는 확률이 아니며 0에서 1의 범위에 제한되지 않습니다.
- 해석: 우도 함수는 특정 모델이나 가설이 관찰된 데이터를 얼마나 잘 설명하는지를 나타냅니다. 우도가 높을수록 데이터가 해당 가설과 일치하는 정도가 높습니다.
likelihood mathematical expression
3. 주요 차이점
(1) 중점 사항 (Focus)
- 확률 (Probability): 알려진 확률에 기반하여 미래 이벤트의 가능성을 예측하는 데 중점을 둡니다.
- 우도 (Likelihood): 관찰된 데이터와 특정 가설 또는 모델 간의 일치를 평가하는 데 중점을 둡니다.
(2) 척도 (Scale)
- 확률 (Probability): 0에서 1까지의 범위를 가지며 이벤트 발생의 가능성을 나타냅니다.
- 우도 (Likelihood) : 특정 가설을 지원하는 정도를 나타내며 특정 범위에 제한되지 않습니다.
(3) 해석 (Interpretation)
- 확률 (Probability): 미래 이벤트의 확실성 또는 가능성을 측정합니다.
- 우도 (Likelihood) : 주어진 가설이 관찰된 데이터를 얼마나 잘 설명하는지를 나타냅니다.
(4) 응용 (Applications)
- 확률 (Probability): 예측 모델링, 의사 결정, 확률 게임 등에서 널리 사용됩니다.
- 우도 (Likelihood) : 통계적 추론, 가설 검정, 모델 적합 등에서 널리 사용됩니다.
4. 예시
동전 던지기를 고려해봅시다. 앞면이 나올 확률은 0.5입니다(공정한 동전을 가정). 이제 10번의 동전 던지기에서 8번이 앞면이 나왔다면, 해당 가설에 따라 동전이 공정한지 아니면 앞면이 더 많이 나오는 편향된 동전인지를 설명하는데 우도를 계산할 수 있습니다.
요약하면, 확률은 미래 이벤트의 가능성을 예측하는 데 사용되며, 우도는 관찰된 데이터와 특정 가설 간의 적합성을 평가하는 데 사용됩니다. 확률은 0에서 1 사이의 값으로 표현되며, 우도는 가설에 대한 지지 정도를 측정하며 특정 범위에 제한되지 않습니다.
5. 최대우도 추정법 (MLE, Maximum Likelihood Estimation)
관측 결과를 바탕으로 관측되었을 가능성이 가장 큰 모수값으로 모수를 추정하는 방법을 최대가능도법(Maximum Likelihood Method) 이라고 합니다. 이를 수리적으로 정리해보면 다음과 같습니다.
Maximum Likelihood Estimation, MLE, 최대우도추정법
실제로는 우도 함수를 계산을 간소화하기 위해 로그-우도( Log-Likelihood )로 변환되는 경우가 많습니다. 로그는 단조 증가 함수이므로 로그-우도는 동일한 최대값을 갖습니다.
우도는 통계적 추론에서 중요한 역할을 합니다. 다양한 모델이나 가설을 비교할 때 연구자들은 종종 그들의 우도를 비교하며, 높은 우도를 갖는 모델이 관측된 데이터에 대한 더 나은 설명으로 간주됩니다.
6. 정규분포로 부터의 확률표본으로 평균과 분산의 최대가능도추정량 구하기
수식 입력기로 하나씩 수식 입력하는게 힘들어서 손으로 작성했습니다. ^^;
이게 대학원 중간고사 볼 때 주관식으로 다 외워서 썼던 것인데, 다시 보니 새롭네요. ㅋㅋ
7. Python을 이용한 정규분포로 부터의 확률표본으로 평균과 분산의 최대가능도추정량 구하기
Python의 scipy 모듈을 사용해서 최대가능도추정법(MLE) 으로 모수 평균과 분산의 추정량을 구해보겠습니다.
모집단의 평균이 4.5, 분산이 2.0인 정규분포로부터 표본을 1,000개 추출하여, 이 확률표본으로 부터 모집단의 분포의 모수 평균(mu), 분산(sigma^2)을 최대가능도추정(MLE) 기법을 사용해 추정해보겠습니다. 최대가능도추정량이 평균 4.48, 분산 2.0 으로서 모집단의 모수와 매우 근접하게 잘 추정되었음을 알 수 있습니다.
import numpy as np
from scipy.stats import norm
from scipy.optimize import minimize
# Generate synthetic data from a normal distribution
np.random.seed(1004)
true_mean = 4.5
true_std = 2.0
sample_size = 1000
data = np.random.normal(true_mean, true_std, sample_size)
# Define the negative log-likelihood function for a normal distribution
def neg_log_likelihood(params, data):
mean, std = params
log_likelihood = -np.sum(norm.logpdf(data, mean, std))
return log_likelihood
# Initial guess for mean and std
initial_params = [1, 1]
# Use MLE to estimate mean and std
result = minimize(neg_log_likelihood, initial_params, args=(data,), method='L-BFGS-B')
estimated_mean, estimated_std = result.x
# Display the results
print(f"True Mean: {true_mean}, True Standard Deviation: {true_std}")
print(f"Estimated Mean: {estimated_mean}, Estimated Standard Deviation: {estimated_std}")
# True Mean: 4.5, True Standard Deviation: 2.0
# Estimated Mean: 4.485386426327861, Estimated Standard Deviation: 2.0015927811977487
상관관계와 인과관계는 통계 및 연구에서 두 변수 간의 다른 유형의 관계를 설명하는 두 가지 중요한 개념입니다.
1. 상관관계 (Correlation)
- 정의: 상관관계는 두 변수가 함께 변하는 정도를 설명하는 통계적 측정입니다. 다시 말하면 한 변수의 변화가 다른 변수의 변화와 어떤 정도로 연관되어 있는지를 양적으로 표현합니다.
- 측정지표: 상관계수(correlation coefficients)는 두 변수 간의 연관 정도를 측정하는 지표입니다. 상관을 측정하는 여러 방법 중에서 가장 일반적인 것은 피어슨 상관계수입니다. 피어슨 상관계수는 -1에서 1까지의 숫자로, 변수 간의 관계의 강도와 방향을 나타냅니다.
- 상관계수 해석: - 양의 상관관계 (+1에 가까움): 한 변수가 증가하면 다른 변수도 증가하는 경향이 있습니다. - 음의 상관관계 (-1에 가까움): 한 변수가 증가하면 다른 변수는 감소하는 경향이 있습니다. - 제로 상관관계 (0에 가까움): 변수 간에 선형 관계가 없습니다.
- 예시: 아이스크림 판매와 익사 사고 수 사이에 양의 상관관계가 있다고 가정해 봅시다. 둘 다 여름 동안 증가하는 경향이 있습니다. 그러나 이는 아이스크림을 사 먹는 것이 익사를 유발한다거나 그 반대로 되는 것은 아니라는 의미입니다. 단지 상관관계일 뿐입니다.
2. 인과관계 (Causation)
- 정의: 인과관계는 두 변수 간의 원인과 결과 관계를 나타냅니다. 인과관계에서는 하나의 변수의 변화가 다른 변수에 직접적으로 영향을 주어 원인과 결과의 연결이 있습니다. 인과관계는 한 변수의 변화가 다른 변수에 변화를 일으키는 상황을 의미하며, 인과관계를 확립하려면 단순히 상관관계를 관찰하는 것 이상의 노력이 필요합니다. 이는 논리적인 연결을 입증하고 다른 가능한 설명을 배제하는 것을 포함합니다.
- 인과관계 판단 기준: 원인을 추론하기 위해 종종 고려되는 여러 기준이 있습니다. 이에는 다음이 포함됩니다:
(1) 시간적 우선순위 (Temporal precedence)
: 원인은 효과보다 앞서야 함 (2) 원인과 효과의 공변성 (Covariation of cause and effect)
: 원인의 변화가 효과의 변화와 관련이 있어야 함 (3) 대안적 설명의 제거 (Elimination of alternative explanations)
: 다른 요인들이 원인으로 제외됨
- 예시: 흡연과 폐암은 인과 관계가 있습니다. 여러 연구에서 흡연이 폐암 발생 위험을 증가시킨다는 것이 확인되었습니다. 이 관계는 단순한 통계적 연관이 아니라 흡연이 폐암 발생 가능성에 영향을 미치는 알려진 메커니즘이 있습니다.
인과관계의 종류
3. 주요 차이점
(1) 관계의 성격 (Nature of Relationship) - 상관관계: 두 변수 간의 통계적 관련성이나 관계를 나타냅니다. - 인과관계: 변화한 변수가 직접적으로 다른 변수에 영향을 미치는 인과 관계를 나타냅니다.
(2) 방향 (Direction) - 상관관계: 양의 경우 (두 변수가 함께 증가하거나 감소) 또는 음의 경우 (한 변수가 증가하면 다른 변수가 감소)가 될 수 있습니다. - 인과관계: 원인 변수의 변화가 결과 변수에 변화를 일으키는 특정한 방향성이 있습니다.
(3) 시사점 (Implications) - 상관관계: 인과관계를 의미하지 않습니다. 상관관계만으로는 인과관계의 증거를 제공하지 않습니다. - 인과관계: 직접적이고 종종 예측적인 관계를 의미합니다. 인과관계를 확립하기 위해서는 일반적으로 보다 엄격한 실험 설계와 증거가 필요합니다.
(4) 예시 - 상관관계: 아이스크림 판매와 익사 사고 수는 서로 인과관계 없이 상관관계가 있을 수 있습니다. - 인과관계: 흡연이 폐암을 유발하는 것은 인과관계의 한 예입니다.
통계적 관계를 해석할 때 주의가 필요하며, 상관관계만을 근거로 인과관계를 가정하는 것은 피해야 합니다. 보다 심층적인 연구, 실험, 대안적 설명의 고려가 종종 필요합니다.
Python의 statsmodels 모듈을 사용해서 선형회귀모형(linear regression)을 적합해보겠습니다.
선형회귀모형을 독립변수와 종속변수 간에 선형적인 관계를 가정하며, 인과관계에세는 원인이 결과보다 시간면에서 앞서서 일어나야 하므로 아래 예시에서는 설명변수 X가 목표변수 Y보다 먼저 발생한 데이터라고 가정하겠습니다. 만약 관측되지 않거나 통제되지 않은 교란 변수 (Confounding Variable) 가 있다면, 회귀 모델에서 추정된 계수는 편향될 수 있습니다. 모든 관련 변수를 통제하는 것은 인과 추론에 있어서 필수적이며, 아래 예시에 교란 변수 Z를 추가하여 선형회귀모형을 적합하였습니다.
## install statsmodels in terminal first if you don't have it
! pip install numpy pandas statsmodels
## linear regression
import numpy as np
import pandas as pd
import statsmodels.api as sm
# Generate synthetic data for demonstration
np.random.seed(42)
X = np.random.rand(100, 1) * 10 # Independent variable
epsilon = np.random.randn(100, 1) * 2 # Error term
Y = 2 * X + 1 + epsilon # Dependent variable with a causal relationship
# Create a DataFrame
df = pd.DataFrame({'X': X.flatten(), 'Y': Y.flatten()})
# Add a confounding variable
Z = np.random.randn(100, 1) # Confounding variable
df['Z'] = Z.flatten()
# Fit a linear regression model
X_with_intercept = sm.add_constant(df[['X', 'Z']])
model = sm.OLS(df['Y'], X_with_intercept).fit()
# Display regression results
print(model.summary())
# OLS Regression Results
# ==============================================================================
# Dep. Variable: Y R-squared: 0.908
# Model: OLS Adj. R-squared: 0.906
# Method: Least Squares F-statistic: 479.8
# Date: Sun, 10 Dec 2023 Prob (F-statistic): 5.01e-51
# Time: 06:30:59 Log-Likelihood: -200.44
# No. Observations: 100 AIC: 406.9
# Df Residuals: 97 BIC: 414.7
# Df Model: 2
# Covariance Type: nonrobust
# ==============================================================================
# coef std err t P>|t| [0.025 0.975]
# ------------------------------------------------------------------------------
# const 1.4314 0.342 4.182 0.000 0.752 2.111
# X 1.9081 0.062 30.976 0.000 1.786 2.030
# Z -0.0368 0.167 -0.220 0.826 -0.368 0.295
# ==============================================================================
# Omnibus: 0.975 Durbin-Watson: 2.295
# Prob(Omnibus): 0.614 Jarque-Bera (JB): 0.878
# Skew: 0.227 Prob(JB): 0.645
# Kurtosis: 2.928 Cond. No. 10.7
# ==============================================================================
# Notes:
# [1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
베이지안 통계는 확률이나 정보의 새로운 증거에 따라 확률을 갱신하는 통계학의 한 분야입니다. 이는 18세기 수학자 토마스 베이즈(Thomas Bayes)의 이름에서 따왔으며 통계적 추론에 대한 확률적인 프레임워크를 제공합니다.
베이지안 통계의 주요 개념을 하나씩 소개하고, 예제를 하나 풀어보겠습니다.
1. 베이즈 정리 (Bayes' Theorem) 및 베이지안 통계 주요 개념
베이지안 통계의 핵심은 베이즈 정리로, 사건의 확률을 사건과 관련된 조건에 대한 이전 지식을 기반으로 설명합니다. 수식은 다음과 같습니다. 여기서P(A∣B)는 사후 확률(조건 B가 주어졌을 때 A의 확률),P(B∣A)는 우도(조건 A가 주어졌을 때 B의 확률),P(A)는 사전 확률,P(B)는 B의 주변 확률입니다.
베이즈 정리 (Bayes' Theorem)
- 사전 확률 (Prior Probability): 사전 확률은 새로운 증거를 고려하기 전의 사건에 대한 초기 믿음 또는 확률을 나타냅니다. 이는 이전 지식이나 경험에 기초합니다.
- 우도(Likelihood): 우도는 특정 가설이나 모델로 관측된 데이터를 설명할 수 있는 정도를 나타냅니다. 특정 가설이나 모델이 주어졌을 때 관측된 데이터의 확률을 나타냅니다.
- 사후 확률(Posterior Probability): 사후 확률은 새로운 증거를 고려한 후의 가설이나 사건의 갱신된 확률입니다. 베이즈 정리를 사용하여 계산됩니다.
- 사후 추론(Posterior Inference): 베이지안 통계에서는 매개변수의 점 추정 대신에 사후 분포에 중점을 둡니다. 이 분포는 가능한 값의 범위와 해당 확률을 제공합니다.
- 베이지안 갱신(Bayesian Updating): 새로운 데이터가 생기면 베이지안 통계는 믿음과 확률을 계속해서 갱신할 수 있습니다. 한 번의 분석에서 얻은 사후 분포는 다음 분석의 사전 분포가 될 수 있습니다.
베이지안 통계는 데이터가 제한적인 경우나 사전 지식을 통합해야 하는 경우에 특히 유용합니다. 기계 학습, 데이터 과학, 경제학 및 의학 연구를 포함한 여러 분야에서 응용되며 불확실성을 일관되고 확률적으로 처리하는 유연성과 능력으로 알려져 있습니다.
2. 빈도론자(Frequentist) vs. 베이지안(Bayesian) 통계 추론*
통계추론은 크게 빈도론자(Frequentist), 베이지안(Bayesian)에 의한 추론으로 구분합니다. 예를 들어서 비교해보겠습니다. ( * 예시 출처: '통계학의 개념과 제문제', 이긍희, 김훈, 김재희, 박진호, 이재용 공저, KNOU출판부)
"예를 들어, 어느 학교에 학생이 입학하였습니다. 학교는 학업 능력이 낮은 학생은 탈락시키고 학업 능력이 높은 학생은 조기에 상급학교에 진학시킨다고 합니다. 두 학생의 학업능력을 평가하기 위해 여러 번의 시험과 과제물을 평가하였습니다.
빈도론자(Frequentist)의 추론은 학생의 학업능력은 고정되어 있다고 가정하고, 일정기간 동안 여러 번의 시험과 과제물 채점 결과로 그 학생의 능력을 평가합니다. 시험 회수를 늘릴수록 두 학생의 평가결과는 공정하게 비교된다고 봅니다.
반면에 베이지안(Bayesian)은 학생의 학업능력은 고정되어 있지 않다고 가정하고 시험과 과제물 채점 시마다 그 학생의 능력평가를 변경합니다. 먼저 학생의 능력은 모두 같다고 가정합니다(또는 분석자가 사전정보를 이용한다면 한 학생이 다른 학생보다 우수하다고 가정합니다). 첫 시험을 보았는데 어떤 학생이 시험을 잘 본다면 그 학생의 능력은 다른 학생보다 우수한 것으로 생각합니다. 다음 시험을 본 후 그 학생의 능력에 대한 판단을 수정합니다."
베이지안의 추론 방식이 일면 합리적이고, 또 보통 사람이 추론하는 방식과 유사함을 알 수 있습니다. 특히, 관측할 수 있는 데이터의 개수가 제한적이고 적을 때 사전적으로 알고 있는 지식이나 주관적인 믿음을 사전 확률로 이용하고, 새로 관측된 데이터로 사후 확률을 업데이트 하는 베이지안 분석법이 매우 강력합니다. 그리고 사후 확률도 단 하나의 점 추정이 아니라 확률적으로 생각하는 방식도 유효하구요.
빈도론자와 베인지안 간에 서로 논박하는 주요 내용은 아래를 참고하세요.
빈도론자(Frequentist)는 고정된 모수를 무한히 반복되는 표본에 대한 통계량의 표본분포를 바탕으로 추정하거나 검정합니다.
반면 베이지안(Bayesian)은 표본확률에 사전확률을 더하여 추정합니다(위의 Bayes' Theorem). 모수는 임의적이어서 확률분포를 가지고 있으며, 모든 추정과 검정은 주어진 데이터와 모수의 사전확률을 바탕으로 한 사후확률에 기반해서 진행됩니다.
빈도론자(Frequentist)는 베이지안의 결과가 지나치게 모수의 사전분포에 의존해서 결과가 일정하지 않고 계산시간이 많이 든다고 비판합니다.
반면 베이지안(Bayesian)은 빈도론자가 주어진 정보를 활용하지 않아 올바른 추정에 어려움이 있다고 비판합니다.
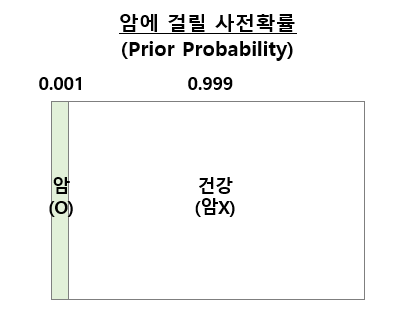
(문제) 의료 데이터에 의하면 사전에 알려진 어떤 암에 걸릴 확률이 0.1% 라고 합니다.
암에 걸렸는지를 검사하는 진단에서 실제 암이 걸린 사람은 90%의 확률로 양성이 나오고, 실제로 암에 안 걸린 건강한 사람은 5%의 확률로 양성(오진단)이 나온다고 합니다.
이럴 때 이 암 진단에서 양성이라고 판정이 나왔을 때, 실제로 암에 걸렸을 확률을 계산하세요.
이해하기 쉽도록 도식화해서 순서대로 풀어보겠습니다.
(1) 사전 확률 (Prior probability) 설정
아직은 개별 환자에 대한 정보가 없는 상태에서, 기존의 의료 데이터로 부터 얻은 사전 확률은 암에 걸릴 확률이 0.1%, 암에 걸리지 않을 확률이 99.9%라는 것을 이미 알고 있습니다.
사전확률 (prior probability)
(2) 검사 정밀도에 따른 조건부 확률 (Likelihood)
위 문제에 보면, 암에 걸렸다는 조건이 주어졌을 때 검사가 양성일 조건부 확률(P(D|H))이 90%, 암에 걸리지 않고 건강하다는 조건이 주어졌을 때 검사가 양성일 조건부 확률이 5% 라고 합니다. 이를 표로 표현하면 아래와 같습니다.
검사 정밀도에 따른 조건부 확률
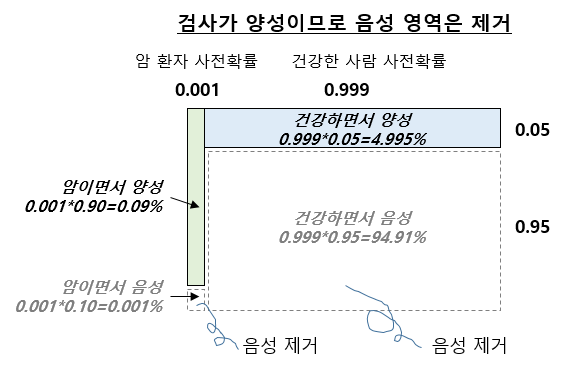
(3) 4개 유형별 각각의 확률 계산
위에 주어진 확률들로 부터 아래와 같이 4개의 유형이 존재하게 되며, 각 유형별로 확률을 계산해볼 수 있습니다.
- 암이면서 양성일 확률 = 0.001 * 0.90 = 0.09%
- 암이면서 음성일 확률 = 0.001 * 0.10 = 0.01%
- 건강하면서 양성일 확률 = 0.999 * 0.05 = 4.995%
- 건강하면서 음성일 확률 = 0.999 * 0.95 = 94.91%
4개 유형별 각각의 확률
(4) 검사가 양성이므로 음성 영역은 제거
우리가 관심있어하는 사람의 진단 결과가 양성이라고 했으므로, 위의 (3)번에서 진단 결과가 음성인 영역은 이 환자에게는 해당사항이 없으므로 제거합니다.
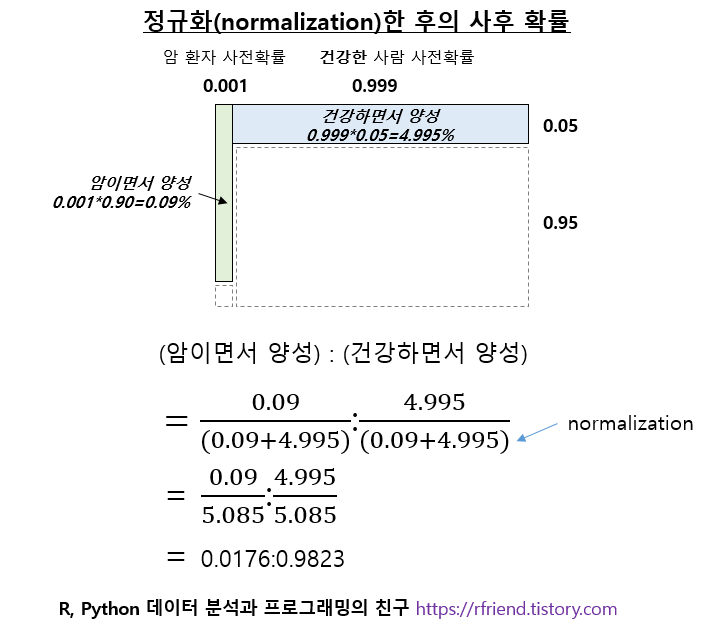
(5) 정규화(normalization)한 후의 사후 확률 (Posterior Probability) 계산
진단 결과가 양성인 영역만 남겨둔 상태에서, 암이면서 양성인 확률 (=0.001 * 0.90 = 0.09%) 과 건강하면서 양성인 확률을 (0.999 * 0.05 = 4.995%) 모두 더해서, 이 값으로 암이면서 양성인 확률과 건강하면서 양성인 확률을 나누어 주면 정규화(normalization)이 된 사후 확률을 구할 수 있습니다.
정규화(normalization) 후의 사후 확률(posterior probability)
위에서 손으로 풀어본 결과 암 진단 결과가 양성으로 나온 사람이 있다고 했을 때, 실제 암에 걸렸을 사후 확률은 0.09 / (0.09 + 4.995) = 1.76% 이네요. (실제 건강한데 진단 결과 양성이 나왔을 사후 확률은 4.995 / (0.09+4.994) = 98.23% (=1-1.76%) 입니다)
90%의 정확도로 암을 진단하는 검사의 결과에서 양성이 나온다면 일반인들은 '아, 이제 나 죽나보구나. 흑.. ㅠ.ㅠ' 하고 앞이 깜깜할 거 같습니다. 그런데 베이지안(Bayesian) 통계에 대한 지식이 있는 사람이라면, '흠... 사전확률을 보니 대부분의 사람은 암이 아니고 극소수만 암이기 때문에, 진단 결과가 양성이라는 새로운 정보를 업데이트 해도... 실제로 암일 사후 확률이 그리 높지는 않겠네. 추가 검사를 기다려보도록 하지' 라고 생각할 수 있겠습니다. 베이지안 통계를 알면 쫄지 않아도 됩니다! ㅋㅋ
위의 사례를 보면 통계 지식이 부족한 일반인들이 생각하는 결과와 베이지안 통계로 추정한 확률이 차이가 많이 나고, 베이지안 통계가 일반인들의 확률에 대한 상식에 반하는거 아닌가하는 생각마저 들지도 모르겠습니다. ^^;
4. Python을 이용한 베이지안 갱신 (Bayesian Updating) 계산
베이즈 정리를 이용하여 사전확률, 조건부 확률이 주어졌을 때 사후확률을 구하는 사용자 정의 함수를 정의해보겠습니다.
## Bayesian Update using Bayes's Theorem
import numpy as np
def bayesian_update(prior_prob, likelihood, verbose=True):
# Bayes' theorem: P(H|D) = P(D|H) * P(H) / P(D)
# Posterior Probability = Likelihood * Prior Probability / Evidence
# Calculate the unnormalized posterior probability
posterior_unnormalized = likelihood * prior_prob
# Calculate the evidence (marginal likelihood) using the law of total probability
evidence = sum(posterior_unnormalized)
# Calculate the normalized posterior probability
posterior_prob = posterior_unnormalized / evidence
if verbose:
print('Likelihood:', likelihood)
print('Prior Probability:', prior_prob)
print('Posterior Unnormalized:', posterior_unnormalized)
print('Evidence(Marginal Likelihood):', evidence)
print('Posterior Probability:', posterior_prob)
return posterior_prob
어느 특정 암에 걸릴 확률이 0.1% 라고 하는 사전확률이 주어지고,
암에 걸렸을 때 암 검사에서 양성이 나올 조건부 확률이 90.0%,
암에 걸리지 않았을 때 양성이 나올 조건부 확률이 5% 라고 했을 때,
만약 어떤 사람이 암 검사에서 양성이 나왔다면 실제로 암에 걸렸을 사후 확률을 계산해 보겠습니다.
# Example values
prior_probability = np.array([0.001, 0.999]) # Prior probability for H0 and H1
likelihood_given_h0 = np.array([0.90, 0.05]) # Likelihood of the data given H0
#likelihood_given_h1 = np.array([0.10, 0.95]) # Likelihood of the data given H1
# Update the posterior probability
posterior_probability_h0 = bayesian_update(prior_probability, likelihood_given_h0)
# Print the results
print("-----" * 10)
print("Posterior Probability for H0:", posterior_probability_h0)
# Likelihood: [0.9 0.05]
# Prior Probability: [0.001 0.999]
# Posterior Unnormalized: [0.0009 0.04995]
# Evidence(Marginal Likelihood): 0.05085
# Posterior Probability: [0.01769912 0.98230088]
# --------------------------------------------------
# Posterior Probability for H0: [0.01769912 0.98230088]
중심극한정리(Central Limit Theorem, 이하 CLT)는 통계학의 기본 개념으로, 특히 표본 크기가 충분히 큰 경우 모집단의 표본 평균 분포를 설명합니다.
1. 중심극한정리(Central Limit Theorem, CLT) 개념
(1) 무작위 추출 (Random Sampling): 중심극한정리는 모양이 어떤 분포든지 상관없이 주어진 모집단에서 고정된 크기의 무작위 표본을 추출하고 각 표본의 평균을 계산한다고 가정합니다.
(2) 표본 평균 분포 (Distribution of Sample Mean): CLT는 원래 모집단 분포의 모양과 상관없이 표본 평균의 분포가 샘플 크기가 증가함에 따라 정규 분포를 근사화한다고 말합니다.
(3) 크기가 큰 표본 (Large Size of Sample): 정규 분포 근사는 표본 크기가 충분히 큰 경우에 특히 잘 적용되며 일반적으로 n ≥ 30입니다. 그러나 경우에 따라서는 적은 표본 크기에서도 CLT 근사가 가능할 수 있습니다. 특히 기본 모집단 분포가 극도로 편향되지 않은 경우입니다.
이는 표본 평균의 분포(X bar)가 평균이 모집단 평균(mu)과 같고 표준 편차(sigma/sqrt(n))가 모집단 표준 편차를 표본 크기의 제곱근으로 나눈 값인 정규 분포에 근사적으로 따른다는 것을 의미합니다.
중심극한의 정리의 중요성은 그 널리 활용성에 있습니다. 중심극한의 정리를 통계학자와 연구자들은 원래 모집단 분포의 모양을 모르더라도 표본 평균의 분포에 대해 특정 가정을 할 수 있게 됩니다. 이는 통계적 추론(statistical inference), 가설 검정(hypothesis testing) 및 신뢰 구간을 추정(estimate of confidence interval)하는 데 중요하며, 많은 통계적 방법이 정규성 가정(hypothesis of normal distribution)에 의존하기 때문에 실무에서 이러한 통계적 기법의 기초 역할을 합니다.
2. Python을 이용한 중심극한정리 시뮬레이션
다음은 Python을 사용해서 균등분포(uniform distribution)를 따르는 모집단(population)으로 부터 각 표본 크기가 30개인 표본을 1,000번 추출하는 시뮬레이션을 하여 각 표본의 평균을 계산하고, 표본 평균의 분포(distribution of sample mean)를 히스토그램으로 시각화해 본 것입니다.
import numpy as np
import matplotlib.pyplot as plt
# Parameters
population_size = 100000 # Size of the population
sample_size = 30 # Size of each sample
num_samples = 1000 # Number of samples to generate
# Generate a non-normally distributed population (e.g., uniform distribution)
population = np.random.uniform(0, 1, population_size)
# Initialize an array to store the sample means
sample_means = []
# Generate samples and calculate means
for _ in range(num_samples):
sample = np.random.choice(population, size=sample_size, replace=False)
sample_mean = np.mean(sample)
sample_means.append(sample_mean)
# Plot the population and the distribution of sample means
plt.figure(figsize=(12, 6))
# Plot the population distribution
plt.subplot(1, 2, 1)
plt.hist(population, bins=30, color='blue', alpha=0.7)
plt.title('Distribution of Uniform Distribution (Population)')
# Plot the distribution of sample means
plt.subplot(1, 2, 2)
plt.hist(sample_means, bins=30, color='green', alpha=0.7)
plt.title('Distribution of Sample Means')
plt.show()
central limit themrem simulation
왼쪽 히스토그램이 균등분포를 따르는 모집단의 것이고, 오른쪽 히스토그램은 균등분포를 따르는 모집단으로 부터 무작위 추출한 표본의 평균(sample mean)의 분포를 나타내는 것입니다. 오른쪽의 표본 평균의 분포는 평균 mu=(1+0)/2 = 0.5 를 중심으로 좌우 대칭의 종모양의 정규분포를 따름을 알 수 있습니다.
위의 Python codes 에서 모집단(population) 을 이산형, 연속형 확률분포 별로 바꿔서 시뮬레이션을 해보시면 중심극한정리를 눈으로 확인해볼 수 있습니다.
(가령, 베타분포의 경우 population = np.random.beta(0.8, 0.8, population_size) 처럼 수정하시면 됩니다)
3. 중심극한정리를 이용한 문제풀이 예시
중심극한정리를 이용하여 이항분포의 확률값을 정규분포로 근사해서 구할 수 있습니다. 이항분포는 n 이 비교적 작을 때 (통상 n <= 25) 정확한 확률값을 얻는데 유용하지만 n 이 클 때는 계산이 복잡해집니다. 이 경우 정규분포를 이용하여 이항분포의 확률의 근사값을 구할 수 있습니다. 즉, n이 클수록 또한 p값이 0.5에 가까울수록 이항분포는 정규분포화 유사해집니다. 이산형 확률변수 Y가 이항분포 B(n, p)를 따를 때, 이를 표준화(Z)한 후 표준정규분포 Z~N(0, 1)에 근사시킵니다.
연속형 변수를 사용하여 이산형 변수를 근사할 때에는 연속성 수정계수(continuity correction factor)를 사용하여 오차를 줄입니다. 부등호에 따라 0.5를 가감함으로써 이항분포의 구간을 정규분포의 구간으로 수정합니다.
[예시 문제] 한국인 성인 50%가 최소한 한 개의 신용카드를 가지고 있다고 가정하자.만일 30명의 성인을 표본추출할 때 19명에서 20명 사이의 성인이 최소한 한 개의 신용카드를 소지하고 있을 확률을 (1) 이항분포를 사용하여 구하고, (2) 정규근사를 사용하여 구하라.
(1) 이항분포를 사용한 풀이
이산형 확률변수 Y가 최소한 한 개의 신용카드를 가지고 있을 성인의 수라고 하면, Y~B(30, 0.50)이 됩니다. 이에 대한 확률은 다음과 같이 계산합니다.
이항분포를 사용한 풀이
(2) 정규근사를 사용한 풀이
Y~B(30, 0.50)일 때 E(Y)=n*p=30*0.50=15, Var(Y)=n*p*(1-p)=30(0.50)(1-0.50)=7.5 이고, 표준화의 변수를 Z라고 할 때, 이를 정규분포로 근사시킨 후 연속성 수정(+-0.5)을 하여 계산하면 다음과 같습니다.
이번 포스팅에서는 통계학에서 사용하는 p-값(p-value)이란 무엇이고, 어떻게 해석하는지 소개하겠습니다.
1. 통계학에서 p-value 는 무엇이며, 무엇에 사용하는가?
2. 독립된 두 표본 간 평균 차이 t-검정에서 p-value 해석 예시
3. Python으로 독립 두 표본 t-검정 (independent two-sample t-test)
4. 빈도론자(Frequentist)와 베이지안(Bayesian) 간 p-value 해석의 차이점은 무엇인가?
1. 통계학에서 p-value 는 무엇이며, 무엇에 사용하는가?
통계학에서 p-값(확률 값)은 귀무가설(null hypothesis, H0)에 대한 증거를 평가하는 데 도움이 되는 지표입니다. 귀무가설은 차이나 효과가 없다는 것을 나타내는 명제로, 연구자들은 이 귀무가설을 기각할 충분한 증거가 있는지를 판단하기 위해 통계 검정을 사용합니다.
p-값은 귀무가설이 참일 때 관측 결과나 그보다 더 극단적인 결과가 나올 확률을 나타냅니다. 다시 말해, 이는 귀무가설에 대한 증거의 강도를 측정하는 것입니다.
주로 다음과 같은 방식으로 사용합니다.
(1) 만약 p-값이 작다면(일반적으로 미리 정의된 유의수준, 예를 들어 0.05보다 낮다면), 이는 관측 결과가 무작위로 발생할 가능성이 적다는 것을 나타내며, 이는 귀무가설(null hypothesis, H0)을 기각하고 대립가설(alternative hypothesis, H1)을 채택합니다.
(2) 만약 p-값이 크다면, 이는 관측 결과가 귀무가설과 상당히 일치한다는 것을 나타내며, 귀무가설을 기각할 충분한 증거가 없다는 것을 의미합니다.
p-값이 작다고 해서 특정 가설이 참임을 증명하는 것은 아닙니다. 이는 단순히 데이터가 귀무가설과 일치하지 않는다는 것을 나타냅니다. 또한, 유의수준(예: 0.05)의 선택은 어느 정도 임의적이며 연구자의 판단이나 해당 분야의 관례에 따라 달라집니다.
연구자들은 p-값을 신중하게 해석하고 귀무가설 검정에 관한 결정을 내릴 때 다른 관련 정보와 함께 고려해야 합니다. p-값은 효과의 크기나 실제적인 중요성에 대한 정보를 제공하지 않으며, 단지 귀무가설에 대한 증거의 강도(the evidence against a null hypothesis)를 나타냅니다.
2. 독립된 두 표본 간 평균 차이 t-검정에서 p-value 해석 예시
예를 들어 혈압을 낮추는 새로운 약물에 대한 임상시험을 다루는 예를 살펴보겠습니다. 연구자들은 새로운 약물이 플라시보에 비해 혈압을 낮추는 데 효과적인지를 테스트하고자 합니다. 이 맥락에서 p-값의 사용과 해석은 다음과 같을 수 있습니다.
시나리오:
- 귀무가설 (H0): 새로운 약물은 혈압에 아무런 영향을 미치지 않으며, 관측된 차이는 무작위로 발생한 것이다. - 대립가설 (H1): 새로운 약물은 플라시보에 비해 혈압을 낮추는 데 효과적이다. 즉, 플라시보 그룹보다 신약 그룹의 혈압이 더 낮다.
실험 설계:
- 연구자들은 참가자들을 새로운 약물을 받는 그룹과 플라시보를 받는 그룹으로 무작위로 배정합니다. - 특정한 치료 기간 이후 각 참가자의 혈압 변화를 측정합니다.
데이터 분석:
- 각 10개의 샘플 데이터를 수집하고 분석한 후, 연구자들은 두 그룹 간의 혈압 변화의 평균을 비교하기 위해 통계적 검정(예: t-검정)을 수행합니다. - 예를 들어, 검정 결과로 얻은 t-통계량이 3.372, p-값이 0.0017인 경우를 가정해 봅시다.
해석:
- 얻은 p-값(0.0034)이 선택된 유의수준(예: alpah=0.05)보다 작습니다. - 빈도주의적 해석: 이는 만약 귀무가설이 사실이라면(즉, 새로운 약물이 효과가 없다면), 실제로 관측된 데이터보다 더 극단적인 데이터를 관측할 확률이 0.17%밖에 되지 않는다는 것을 나타냅니다. 0.0017이 유의수준 0.05 보다 작으므로 연구자들은 귀무가설을 기각하기로 결정할 수 있습니다. - 결정: 연구자들은 귀무가설을 기각하고 새로운 약물이 플라시보에 비해 혈압을 낮추는 데 효과적임을 시사하는 충분한 증거가 있다고 결론지을 수 있습니다.
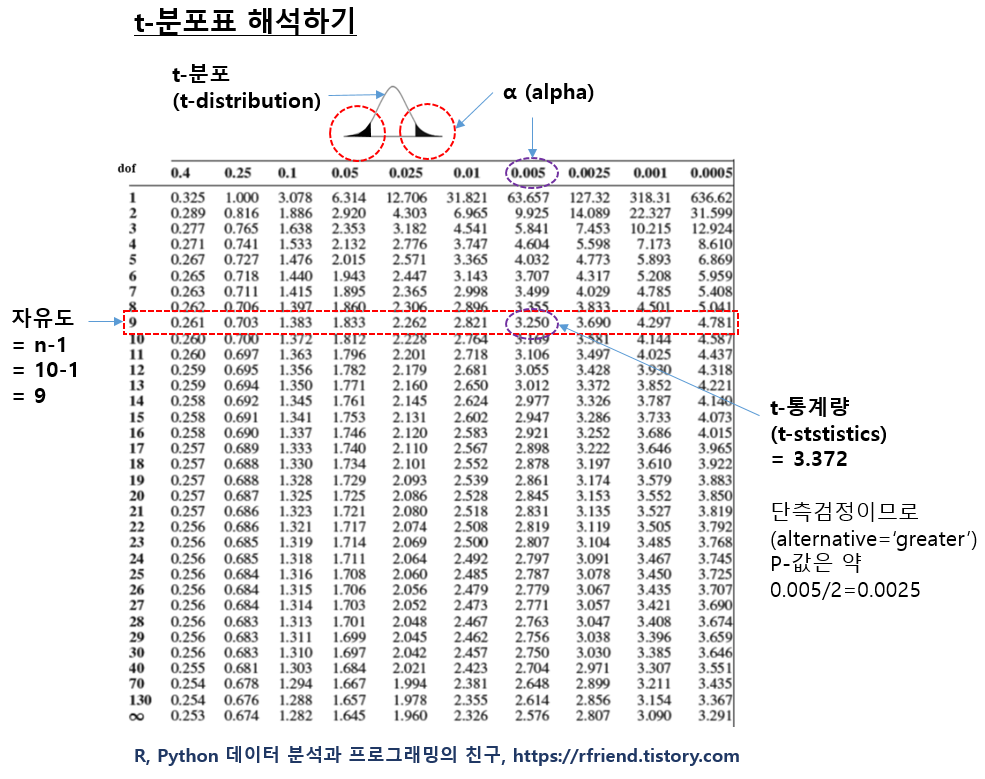
아래에는 t-분포표를 수작업으로 해석하는 방법입니다.
t-분포표의 행은 자유도(degree of freedom) 으로서, 만약 샘플의 관측치 개수가 주어지면 (자유도 = n-1) 로 계산해줍니다. t-분포표의 열은 유의수준 알파(alpha)이고, 표의 안에 있는 숫자는 가설 검정에 사용하는 t-통계량입니다. (정규분포표에서는 행과 열이 z-통계량이고, 표의 가운데 값이 p-value인데요, t-분포표는 이와 달라서 좀 헷갈리는 면이 있습니다.) 샘플로 부터 자유도와 t-통계량를 계산하면, 아래의 t-분포표를 보고 상단 열에서 p-값을 찾으면 됩니다.
이번 예에서는 가령, 관측치가 각 그룹별로 10개라고 하면, 자유도 = n-1 = 9 가 됩니다.
그리고 t-통계량을 계산했더니 3.372가 나왔다고 했을 때, 아래 표에서 t-통계량 3.372 는 자유도 9인 행에서 보면 3.250보다는 크고, 3.690보다는 작은 값입니다. 따라서 상단의 알파(alpha) 값은 0.005와 0.0025 사이의 값이라고 추정할 수 있습니다. 그런데 대립가설이 "H1: 새로운 약물은 플라시보에 비해 혈압을 낮추는 데 효과적이다. 즉, 플라시보 그룹보다 신약 그룹의 혈압이 더 낮다." 이므로 단측검정 (alternative = 'greater') 을 사용하므로, p-value=0.005/2=0.0025 보다 작고 ~ p-value=0.0025/2=0.00125 보다는 큰 값으로 볼 수 있습니다.
유의수준 0.05보다는 훨씬 작은 값이므로, 귀무가설을 기각하고 대립가설을 채택합니다. 즉, 신약이 혈압을 낮추는데 효과가 있다고 판단할 수 있습니다.
t-분포표 해석하기
p-값 자체만으로는 효과의 크기나 임상적 중요성에 대한 정보를 제공하지 않습니다. 연구자들은 통계 검정을 기반으로 의사결정을 내릴 때 효과 크기, 신뢰구간 및 실제적인 중요성도 고려해야 합니다. 또한 베이지안 프레임워크에서는 관측된 데이터를 기반으로 사전 신념을 업데이트하는 것이 포함될 수 있습니다.
3. Python으로 독립 두 표본 t-검정 (independent two-sample t-test)
scipy 모듈의 scipy.stats.stats.ttest_ind() 메소드를 사용해서 독립된 두 표본의 평균에 차이가 있는지를 t-검정해 보겠습니다.
- 귀무가설(H0): Group 1과 Group 2의 평균에는 차이가 없다. (mu_g1 = mu_g2)
- 대립가설(H1): Group 1가 Group 2의 평균보다 크다. (mu_g1 > mu_g2)
t 통계량이 3.37이고 p-값(p-value)이 0.0034 로서, 유의수준(alpha) 0.05보다 p-값이 더 작으므로 귀무가설을 기각(reject null hypothesis)하고, 대립가설을 채택(accept alternative hypothesis)합니다.
## independent two-sample t-test
import numpy as np
import scipy.stats as stats
# Example data for two independent samples
group1 = [25, 30, 32, 28, 34, 26, 30, 29, 31, 27]
group2 = [21, 24, 28, 25, 30, 22, 26, 23, 27, 24]
print('Mean of Group 1:', np.mean(group1))
print('Mean of Group 2:', np.mean(group2))
# Perform independent two-sample t-test
t_statistic, p_value = stats.ttest_ind(
group1, group2,
equal_var=True,
alternative='greater', # alternative hypothesis: mu_1 is greater than mu_2
)
# Print the results
print(f'T-statistic: {t_statistic}')
print(f'P-value: {p_value}')
# Check the significance level (e.g., 0.05)
alpha = 0.05
if p_value < alpha:
print('Reject the null hypothesis. \
There is a significant difference between the groups.')
else:
print('Fail to reject the null hypothesis. \
There is no significant difference between the groups.')
# Mean of Group 1: 29.2
# Mean of Group 2: 25.0
# T-statistic: 3.3723126837047914
# P-value: 0.0016966232763530164
# Reject the null hypothesis. There is a significant difference between the groups.
4. 빈도론자(Frequentist)와 베이지안(Bayesian) 간 p-value 해석의 차이점은 무엇인가?
빈도론자(Frequentist)와 베이지안(Bayesian) 간의 통계학적 접근 방식에서 p-값의 해석은 다릅니다. 각 접근 방식이 p-값을 어떻게 해석하는지 간략하게 살펴보겠습니다.
(1) 빈도주의적 해석 (Frequentist Interpretation):
- 빈도주의 통계학에서 p-값은 귀무가설이 참일 때 관측된 데이터나 그보다 더 극단적인 데이터가 나올 확률로 간주됩니다. - 의사결정 과정은 일반적으로 특정한 유의수준(alpha), 보통 0.05,을 기준으로 귀무가설을 기각하거나 기각하지 않는 것으로 구성됩니다. - 만약 p-값이 선택된 유의수준보다 작거나 같으면 귀무가설이 기각됩니다. p-값이 유의수준보다 크면 귀무가설이 기각되지 않습니다. - 빈도주의 통계학에서는 확률을 가설에 할당하지 않으며 대신 특정 가설 하에서 데이터의 확률에 중점을 둡니다.
(2) 베이지안 해석 (Bayesian Interpretation):
- 베이지안 통계학에서는 관측된 데이터를 기반으로 가설에 대한 사전 신념(prior beliefs)을 업데이트하는 것에 중점을 둡니다. - 베이지안 분석은 가설에 대한 사전 신념과 관측된 데이터 모두를 고려하여 가설에 대한 사후 확률 분포(posterior probability distribution for the hypothesis)를 제공합니다. - 베이지안은 의사결정을 위해 일반적으로 p-값 만을 고려하지 않습니다. 대신 전체 사후 분포를 고려하며 이전 정보를 통합합니다. - 베이지안 분석은 데이터가 주어졌을 때 가설이 참일 확률을 직접 계산합니다. 이는 빈도주의적 접근과 달리 가설이 주어진 데이터에 대한 확률만을 고려하는 것이 아닙니다. - 가설 검정을 위해 때로는 베이지안 분석에서는 가설 간의 가능도 비율(ratio of the likehoods under different hypotheses)인 베이즈 팩터(Bayes factor)를 사용하기도 합니다.
요약하면 핵심적인 차이점은 확률 해석에 있습니다. 빈도주의자들은 확률을 사건의 장기적 빈도로 간주하며, 베이지안은 확률을 신념이나 불확실성의 척도로 해석합니다. 빈도주의자들은 p-값을 가설에 대한 의사결정에 사용하며, 베이지안안은 베이지안 추론을 사용하여 직접적으로 신념을 업데이트하고 표현합니다.
먼저 my_dict 내 원소의 value 가 각각 0, 1, 2 인 sub Dictionary 를 만들어보겠습니다.
my_dict.items() 로 Dictionary 내 원소 값을 불러오고, 조건절이 있는 list comprehension 을 이용하였으며, for loop 순환문을 사용해도 됩니다.
# (1) Split a Dictionary by each value categories of 0, 1, 2
dict_0 = {k: v for k, v in my_dict.items() if v == 0}
dict_1 = {k: v for k, v in my_dict.items() if v == 1}
dict_2 = {k: v for k, v in my_dict.items() if v == 2}
print('Dict 0:', dict_0)
print('Dict 1:', dict_1)
print('Dict 2:', dict_2)
# Dict 0: {'d': 0, 'i': 0, 'j': 0, 'k': 0, 'l': 0, 'm': 0, 'p': 0, 'r': 0, 'u': 0, 'w': 0, 'y': 0}
# Dict 1: {'b': 1, 'e': 1, 'g': 1, 'h': 1, 't': 1, 'v': 1}
# Dict 2: {'a': 2, 'c': 2, 'f': 2, 'n': 2, 'o': 2, 'q': 2, 's': 2, 'x': 2, 'z': 2}
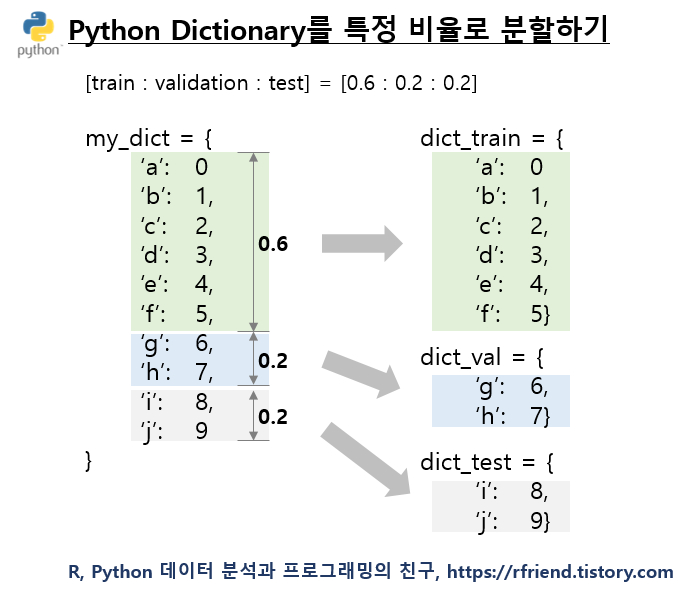
(2) Dictionary 를 특정 비율로 분할하기
Split a Dictionary by proportions
이제 위에서 생성한 sub Dictionary를 먼저 무작위로 순서를 재정렬한 후에, [training : validation : test] = [0.6 : 0.2 : 0.2] 의 비율로 분할을 해보겠습니다.
list(dict_k.keys()) 로 각 sub Dictionary 의 key 값을 리스트로 만든 후에, random.shuffle(keys_list) 로 key 값을 무작위로 순서를 재정렬해주었습니다.
그 후에 [train:validation:test] = [0.6:0.2:0.2] 의 비율에 해당하는 각 sub Dictionary의 원소값의 개수를 계산한 후에, 이 원소 개수만큼 keys_list 에서 key 값 리스트를 indexing 해 옵니다.
그리고 마지막으로 list comprehension을 이용해서 train, validation, test set 별 key 해당하는 value 를 가져와서 {key: value} 쌍으로 train/validation/test set의 각 Dictionary를 만들어주면 됩니다.
# (2) Split each Dictionary into training set 60%, validation 20%, test set 20% randomly
def split_dict(dict_k, train_r=0.6, val_r=0.2, verbose=False):
import random
random.seed(1004)
keys_list = list(dict_k.keys())
# randomize the order of the keys
random.shuffle(keys_list)
# numbers per train, validation, and test set
num_train = int(len(keys_list) * train_r)
num_val = int(len(keys_list) * val_r)
# split kyes
keys_train = keys_list[:num_train] # 60%
keys_val = keys_list[num_train:(num_train+num_val)] # 20%
keys_test = keys_list[(num_train+num_val):] # 20% = 1 - train_ratio - val_ratio
# split a Dictionary
dict_k_train = {k: dict_k[k] for k in keys_train}
dict_k_val = {k: dict_k[k] for k in keys_val}
dict_k_test = {k: dict_k[k] for k in keys_test}
if verbose:
print('Keys List:', keys_list)
print('---' * 20)
print('Training set:', dict_k_train)
print('Validation set:', dict_k_val)
print('Test set:', dict_k_test)
return dict_k_train, dict_k_val, dict_k_test
실제로 dict_0, dict_1, dict_2 의 각 sub Dictionary에 위에서 정의한 사용자 정의 함수 split_dict() 함수를 적용해보겠습니다.
토큰화, 단어 임베딩, 텍스트 임베딩은 자연어 처리(NLP) 및 기계 학습에서 텍스트 데이터를 표현하고 처리하는 데 사용되는 개념입니다. 이러한 개념들은 감정 분석, 기계 번역, 텍스트 분류와 같은 NLP 작업에서 중요하며, 기계 학습 모델이 이해하고 학습할 수 있는 형태로 텍스트 정보를 표현하고 처리하는 데 사용됩니다.
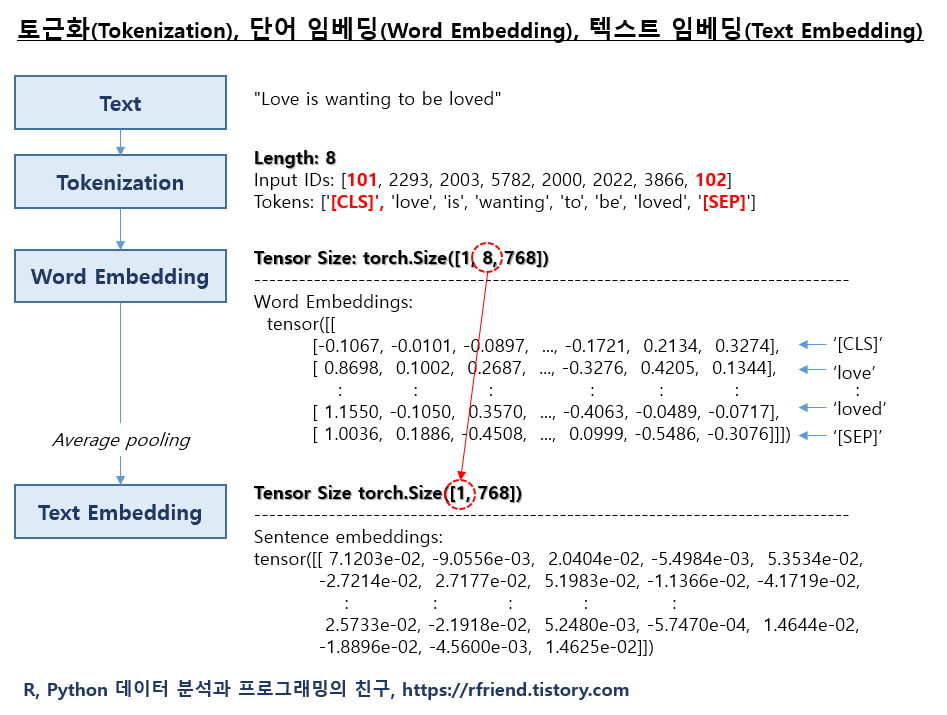
이번 포스팅에서는 토근화(Tokenization), 단어 임베딩 (Word Embedding), 텍스트 임베딩 (Text Embedding)에 대해서 소개하겠습니다. 그리고 transformers 와 PyTorch 를 이용하여 실습을 해보겠습니다.
tokenization, word embedding, text embedding
1. 토큰화 (Tokenization)
- 정의: 토큰화는 텍스트를 토큰이라 불리는 더 작은 단위로 분해하는 과정입니다. 이러한 토큰은 단어, 서브워드 또는 문자일 수 있으며 원하는 정밀도 수준에 따라 다릅니다.
- 목적: 토큰화는 NLP에서 중요한 전처리 단계로, 기계가 텍스트의 개별 요소를 이해하고 처리할 수 있게 합니다. 토큰은 후속 분석을 위한 구성 요소로 작용합니다.
-- Install transformers, torch, sentence-transformers at terminal at first
pip install -q transformers
pip install -q torch
pip install -q -U sentence-transformers
# 1. Tokenization
# : Tokenization is the process of breaking down a text into smaller units called tokens.
# : These tokens can be words, subwords, or characters, depending on the level of granularity desired.
from transformers import AutoTokenizer
# Load pre-trained DistilBERT tokenizer
tokenizer = AutoTokenizer.from_pretrained('distilbert-base-uncased')
# Example text
text = "Love is wanting to be loved"
# Tokenize the text
input_ids = tokenizer.encode(text)
tokens = tokenizer.tokenize(tokenizer.decode(input_ids))
print("Input IDs:", input_ids)
print("-------" * 10)
print("Tokens:", tokens)
# Input IDs: [101, 2293, 2003, 5782, 2000, 2022, 3866, 102]
# ----------------------------------------------------------------------
# Tokens: ['[CLS]', 'love', 'is', 'wanting', 'to', 'be', 'loved', '[SEP]']
2. 단어 임베딩 (Word Embedding)
- 정의: 단어 임베딩은 단어를 연속적인 벡터 공간의 실수로 이루어진 밀도 있는 벡터로 나타내는 기술입니다. 각 단어는 벡터로 매핑되며 이러한 벡터 간의 거리와 방향이 의미를 가집니다.
- 목적: 단어 임베딩은 단어 간의 의미적 관계를 포착하여 기계가 주어진 텍스트의 맥락과 의미를 이해할 수 있게 합니다. 단어가 맥락과 의미가 유사한 경우 단어 임베딩 벡터가 서로 가깝게 위치하는 특성이 있어 semantic search에 유용하게 활용됩니다. 유명한 단어 임베딩 모델로는 Word2Vec, GloVe, FastText가 있습니다.
# 2. Word Embedding
# : Word embedding is a technique that represents words
# as dense vectors of real numbers in a continuous vector space.
# : Each word is mapped to a vector, and the distances and directions
# between these vectors carry semantic meaning.
from transformers import AutoTokenizer, AutoModel
import torch
# Load pre-trained DistilBERT model
tokenizer = AutoTokenizer.from_pretrained('distilbert-base-uncased')
model = AutoModel.from_pretrained('distilbert-base-uncased')
# Encode the tokens to obtain word embeddings
input_ids = tokenizer.encode(text, return_tensors='pt')
with torch.no_grad():
word_embeddings = model(input_ids)[0]
print("Tensor Size:", word_embeddings.size())
print("------" * 10)
print("Word Embeddings:")
print(word_embeddings)
# Tensor Size: torch.Size([1, 8, 768])
# ------------------------------------------------------------
# Word Embeddings:
# tensor([[
# [-0.1067, -0.0101, -0.0897, ..., -0.1721, 0.2134, 0.3274],
# [ 0.8698, 0.1002, 0.2687, ..., -0.3276, 0.4205, 0.1344],
# [-0.1877, -0.0777, 0.1905, ..., -0.0220, 0.0024, 0.5138],
# ...,
# [ 0.5998, -0.2141, 0.3774, ..., -0.3945, -0.1149, 0.1245],
# [ 1.1550, -0.1050, 0.3570, ..., -0.4063, -0.0489, -0.0717],
# [ 1.0036, 0.1886, -0.4508, ..., 0.0999, -0.5486, -0.3076]]])
3. 텍스트 임베딩 (Text Embedding)
- 정의: 텍스트 임베딩은 문장(sentences)이나 문서(documents) 전체를 밀도 있는 벡터로 나타내어 전체 텍스트의 전반적인 의미를 캡처하는 기술입니다. 단어 임베딩을 집계하거나 요약하여 전체 텍스트의 표현을 만듭니다.
- 목적: 텍스트 임베딩은 전체 문서나 문장을 의미적 공간에서 비교하고 분석할 수 있게 합니다. 텍스트 임베딩을 생성하는 방법에는 단어 임베딩의 평균(averaging word embeddings)을 사용하거나 순환 신경망(RNN), 장·단기 기억 네트워크(LSTM), 트랜스포머(Transformers)를 사용하는 방법 등이 있습니다.
텍스트 임베딩은
- 텍스트 분류 (Text Classification),
- 감성분석 (Sentiment Analysis),
- 검색 엔진 랭킹 (Search Engine Ranking),
- 군집 및 유사도 분석 (Clustering and Similarity Analysis),
- 질의 응답 (Question Answering, 질문과 답변을 임베딩으로 표현함으로써 시스템은 쿼리의 의미 콘텐츠와 데이터셋의 관련 정보를 정확하게 검색할 수 있음)
등에 활용할 수 있습니다.
text embedding 을 하는 방법에는 (1) transformers 를 이용한 방법과, (2) sentence-transfomers 모델을 이용하는 방법이 있습니다. sentence-transformers 모델을 이용하는 방법이 코드가 간결합니다.
3-1. transformers 를 이용한 text embedding
# 3. Text Embedding
# : Text embedding represents entire sentences or documents as dense vectors,
# capturing the overall meaning of the text.
# : It involves aggregating or summarizing word embeddings
# to create a representation for the entire text.
from transformers import AutoTokenizer, AutoModel
import torch
import torch.nn.functional as F
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
# Example sentence
text = "Love is wanting to be loved"
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('distilbert-base-uncased')
model = AutoModel.from_pretrained('distilbert-base-uncased')
# Tokenize sentences
encoded_input = tokenizer(text, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
# Normalize embeddings
sentence_embeddings = F.normalize(sentence_embeddings, p=2, dim=1)
print("Tensor Size", sentence_embeddings.size())
print("--------" * 10)
print("Sentence embeddings:")
print(sentence_embeddings)
# Tensor Size torch.Size([1, 768])
# --------------------------------------------------------------------------------
# Sentence embeddings:
# tensor([[ 7.1203e-02, -9.0556e-03, 2.0404e-02, -5.4984e-03, 5.3534e-02,
# -2.7214e-02, 2.7177e-02, 5.1983e-02, -1.1366e-02, -4.1719e-02,
# : : : : :
# 2.5733e-02, -2.1918e-02, 5.2480e-03, -5.7470e-04, 1.4644e-02,
# -1.8896e-02, -4.5600e-03, 1.4625e-02]])
3-2. sentence-transformers 모델을 이용한 text embedding
: 'all-mpnet-base-v2' 모델을 HuggingFace에서 다운로드 하여 사용
위의 (1)번에서 소개했던 pandas.Series.explode() 메소드를 apply() 함수를 사용해서 위에서 만든 DataFrame df 의 모든 열에 적용해줍니다. 옆으로 길게 리스트 형태로 있던 DataFrame 내 원소가 각 행(row)의 개별 원소로 풀어져서 세로로 긴 DataFrame 형태로 변형되었습니다.
## unpacking the lists in DataFrame
df_unpacked = df.apply(pd.Series.explode)
print(df_unpacked)
# grp id value
# 0 a 1 0.0
# 0 a 2 0.421948
# 0 a 3 0.9422
# 0 b 4 0.582
# 0 b 5 0.0
# 0 b 6 0.28574
# 0 c 7 0.55382
# 0 c 8 0.2801
# 0 c 9 0.87
(3) DataFrame의 float 자리수를 지정해주기
세번째 칼럼인 'value'의 float 값들의 자리수가 서로 달라서 보기에 좋지 않습니다. 이럴 경우 astype(float).round(2) 메소드를 사용해서 소수점 2째 자리로 반올일해서 자리수를 일치시켜주면 보기에 깔끔하고 좋습니다.
## Output to two decimal places
df_unpacked['value'] = df_unpacked['value'].astype(float).round(2)
print(df_unpacked)
# grp id value
# 0 a 1 0.00
# 0 a 2 0.42
# 0 a 3 0.94
# 0 b 4 0.58
# 0 b 5 0.00
# 0 b 6 0.29
# 0 c 7 0.55
# 0 c 8 0.28
# 0 c 9 0.87
이번 포스팅에서는 리스트와 사전 자료형을 이용해서 문자열과 숫자를 서로 매핑하고 변환하는 방법을 소개하겠습니다.
(예전에 이와 비슷한 포스팅을 한적이 있는데요, 예전 거에서 한 발자국씩만 더 나가봤습니다.)
(1) 리스트 내 문자열을 숫자로 변환하기
(2) 리스트 내 숫자를 문자열로 변환하기
(3) 고유한 문자열에 정수를 매핑하기
(4) 고유한 정수에 문자열을 매핑하기
(1) 리스트 내 문자열 을 숫자로 변환하기
* 방법 1: Python의 List Comprehension 과 int(str) 메소드를 같이 사용하는 방법입니다.
## Converting string list to integer list
str_list = ['5', '12', '8', '19', '34']
## way 1: list comprehension
int_list = [int(x) for x in str_list]
print(int_list)
# [5, 12, 8, 19, 34]
* 방법 2: map() 메소드를 사용해서 list(map(int, string_list)) 형태로 사용하는 방법입니다.
## way 2: map(int, str) function
int_list2 = list(map(int, str_list))
print(int_list2)
# [5, 12, 8, 19, 34]
(2) 리스트 내 문자열을 숫자로 변환하기
리스트 안의 문자열을 숫자로 바꾸는 방법은 위의 (1)번에서 소개한 2가지 방법과 동일하며, int() 대신 str()을 사용해주면 됩니다.
## converting integer to string
## way 1: list comprehension
[str(i) for i in int_list]
# ['5', '12', '8', '19', '34']
## way 2: map(str, int_list)
list(map(str, int_list))
# ['5', '12', '8', '19', '34']
(3) 고유한 문자열에 정수를 매핑하기
(3-1) sorted(set(label_list)) : 먼저 문자열 리스트 에서 유일한(unique) 문자열 집합을 추출해서 정렬한 후에
--> {k: v+1 for v, k in enumerate(sorted(set(label_list)))} : 유일한 문자열 별로 1부터 순차적으로 정수를 부여한 사전 자료형을 만듭니다 (향후 매핑 참조에 사용됨)
## original label list
label_list = ['cat', 'dog', 'cat', 'car', 'tree', 'tree', 'dog']
sorted(set(label_list))
# ['car', 'cat', 'dog', 'tree']
## mapping index dictionary(label key: integer value)
label_int_dict = {
k: v+1 for v, k in enumerate(
sorted(set(label_list))
)
}
print(label_int_dict)
# {'car': 1, 'cat': 2, 'dog': 3, 'tree': 4}
(3-2) for x in label_list : label_list 에서 순서대로 문자열 원소값을 for loop 순환문을 통해 하나씩 가져와서
--> [label_int_dict[x]] : 위의 (3-1)에서 생성한 매핑 사전에서 문자열에 해당하는 정수를 매핑해주고 리스트로 만들어줍니다.
## mapping label to integer index using list comprehension
mapped_int_list = [label_int_dict[x] for x in label_list]
print(mapped_int_list)
# [2, 3, 2, 1, 4, 4, 3]
(4) 고유한 정수에 문자열을 매핑하기
(4-1) for k, v in label_int_dict.items() : 위의 (3-1)에서 생성한 문자열-정수 매핑 사전에서 Key, Value 를 불러와서
--> {v: k} : {Value: Key} 로 서로 키와 값의 위치를 바꾸어서 새로 사전 자료형을 만들어줍니다.
(아래 (4-2)에서 매핑 사전으로 사용됨)
## converting integer to label string
int_label_dict = {
v: k for k, v in label_int_dict.items()
}
print(int_label_dict)
# {1: 'car', 2: 'cat', 3: 'dog', 4: 'tree'}
(4-2) for x in mapped_int_list : 위의 (3-2)에서 변환했던 mapped_int_list 리스트에서 정수를 하나씩 불러와서
--> [int_label_dict[x]] : (4-1)에서 생성한 {정수: 문자열} 매핑 사전을 이용해서 정수에 해당하는 문자열을 매핑하고 리스트로 만들어줍니다.
## mapping integer to label using list comprehension
mapped_label_list = [int_label_dict[x] for x in mapped_int_list]
print(mapped_label_list)
# ['cat', 'dog', 'cat', 'car', 'tree', 'tree', 'dog']
Greenplum의 pgvector와 OpenAI를 이용하여 대규모 AI 기반 검색 구축하기 (Building large-scale AI-powered search in Greenplum using pgvector and OpenAI)
[들어가는 글]
지난 몇 년간 ChatGPT와 같은 AI 모델의 기하급수적인 발전은 많은 조직이 생성 AI(Generative AI) 및 LLM(Large Language Model)을 출시하여 사용자 경험을 향상시키고 텍스트에서 이미지, 비디오에 이르기까지 비정형 데이터의 잠재력을 최대한 활용하도록 영감을 주었습니다.
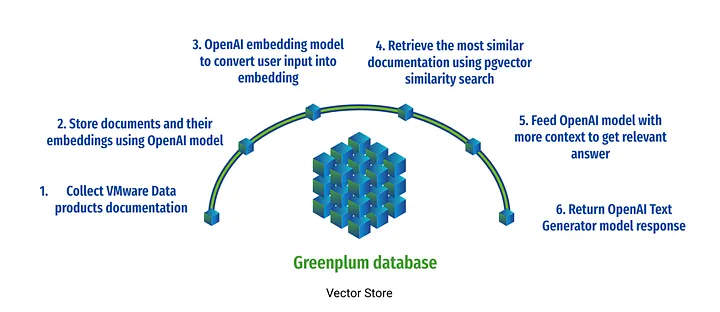
이 블로그 글에서는 Greenplum 데이터 웨어하우스 내에서 pgvector 확장의 벡터 유사성 검색(vector similarity search) 기능을 활용하고 이를 OpenAI 모델과 결합하여 페타바이트급 대규모 텍스트 데이터에서 귀중한 통찰력을 추출하고 Greenplum의 놀라운 MPP 아키텍처(Massively Parallel Processing Architecture)를 활용하는 방법에 대해 알아보겠습니다.
large-scale AI-powered search using Greenplum pgvector and OpenAI
도입 (Introduction):
기업들은 AI를 위해 데이터 플랫폼을 확장하고 챗봇, 추천 시스템 또는 검색 엔진에 대용량 언어 모델을 사용할 수 있는 기술과 방법을 찾기 시작했습니다.
그러나 한 가지 구체적인 과제는 이러한 AI 모델을 관리 및 배포하고 ML 생성 임베딩(ML-generated embeddings)을 규모있게 저장 및 쿼리하는 것이었습니다.
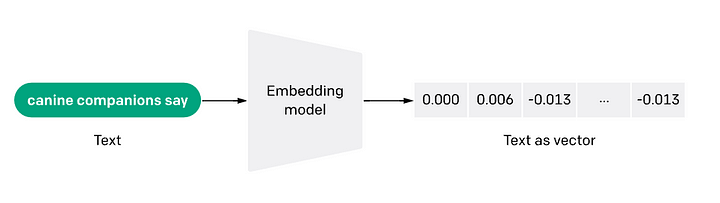
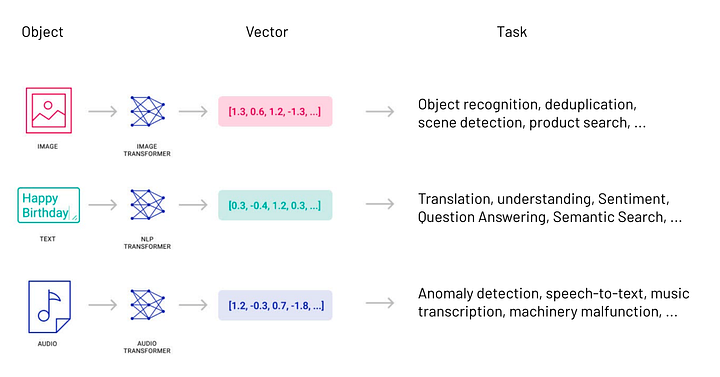
임베딩이란 무엇입니까? (What are embeddings?)
임베딩(Embeddings)은 데이터 또는 텍스트, 이미지 또는 오디오와 같은 복잡한 객체를 고차원 공간의 숫자들의 리스트로 변환하는 것을 말합니다.
이 기술은 데이터의 의미와 맥락(의미론적 관계, semantic relationships) 및 데이터 내의 복잡한 관계와 패턴(구문론적 관계, syntactic relationship)에 대한 지식을 캡처/이해할 수 있게 해주는 모든 기계학습(ML) 또는 딥러닝(DL) 알고리듬에 사용됩니다.
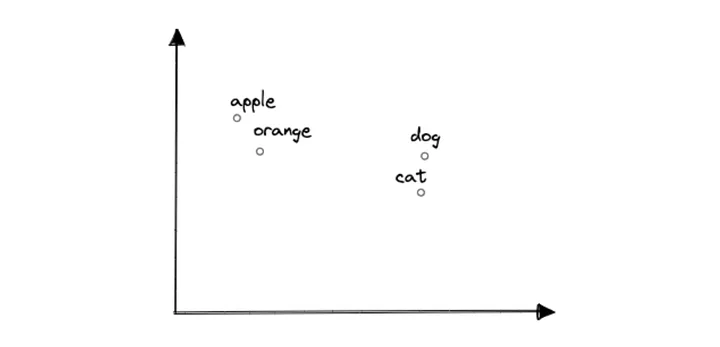
의미론적으로 유사한 단어들이 임베딩에서 서로 가까이 있다는 것을 알 수 있습니다. 예를 들어, "사과"라는 단어는 "개"나 "고양이"보다 "오렌지"에 더 가깝습니다.
임베딩을 생성한 후, 회사는 벡터 공간 내에서 유사성 검색(similarity searches)을 수행하고 제품 추천 시스템과 같은 AI 애플리케이션을 구축할 수 있습니다.
pgvector를 사용하여 Greenplum에 임베딩 저장하기 (Storing embeddings in Greeplum using pgvector)
Greenplum 7은 pgvector 확장(pgvector extension) 덕분에 벡터 임베딩을 대규모로 저장하고 쿼리할 준비가 잘 되어 있습니다. 이를 통해 Greenplum 데이터 웨어하우스에 벡터 데이터베이스(vector database) 기능을 제공하여 사용자가 빠른 검색과 효율적인 유사성 검색을 수행할 수 있습니다.
Greenplum의 pgvector 를 사용하여 ML 지원 응용프로그램에 대한 데이터베이스를 설정, 운영 및 확장할 수 있습니다.
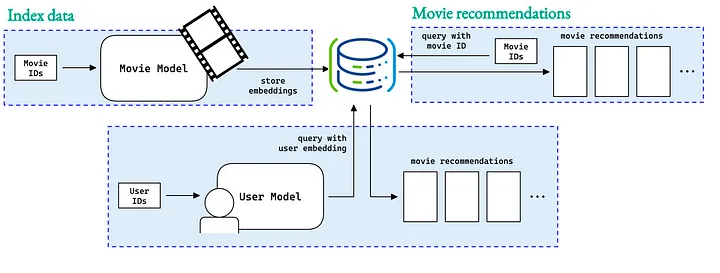
예를 들어, 스트리밍 서비스는 pgvector를 사용하여 방금 본 것과 유사한 영화 추천 목록을 제공할 수 있습니다.
movie recommendations using embeddings
왜 Greenplum 이고 pgvector 인가?
많은 기업이 다른 벡터 데이터베이스를 관리하지 않고도 엔터프라이즈 데이터 웨어하우스 내에서 벡터 의미 검색(vector semantic searches)을 저장, 쿼리 및 수행하려고 합니다.
다행히 Greenplum과 pgvector를 결합하면 AI 모델의 임베딩을 사용하여 빠르고 확장 가능한 애플리케이션을 구축하고 더 빨리 운영에 들어갈 수 있습니다.
pgvector와 OpenAI를 사용하여 Greenplum에서 제품 설명서에 사용할 AI-Assistant를 구축하기.
문맥:
우리 모두는 이전에 ChatGPT와 같은 챗봇을 사용한 적이 있으며 캐주얼하고 범용적인 질문에 적합하다는 것을 알았습니다. 하지만, 깊고 도메인별 지식이 필요할 때 ChatGPT는 부족하다는 것을 알아차렸을 수도 있습니다. 또한, 그것은 지식의 격차를 메우기 위해 답을 만들고 결코 출처를 언급하지 않습니다.
하지만 어떻게 이것을 개선할 수 있을까요? 적합한 데이터 소스를 정확하게 검색하고 질문에 답변하는 ChatGPT를 구축하려면 어떻게 해야 할까요?
답변:
이 질문에 대한 대답은 제품 설명서를 검색 가능하게 만들고 작업별 프롬프트를 OpenAI에 제공하면 결과가 더 신뢰할 수 있다는 것입니다. 즉, 사용자가 질문할 때 Greenplum 테이블에서 적합한 데이터 세트를 검색하도록 pgvector에게 요청합니다. 그런 다음 사용자의 질문에 답변하기 위한 참조 문서(reference document)로 OpenAI에 제공합니다.
실제 임베딩 적용하기:
이 섹션에서는 임베딩을 실제 적용한 모습을 살펴보고, 임베딩 저장을 용이하게 하고 벡터의 가장 가까운 이웃에 대한 쿼리를 가능하게 하는 Greenplum에 대한 오픈 소스 pgvector 확장을 사용하는 방법을 배울 것입니다.
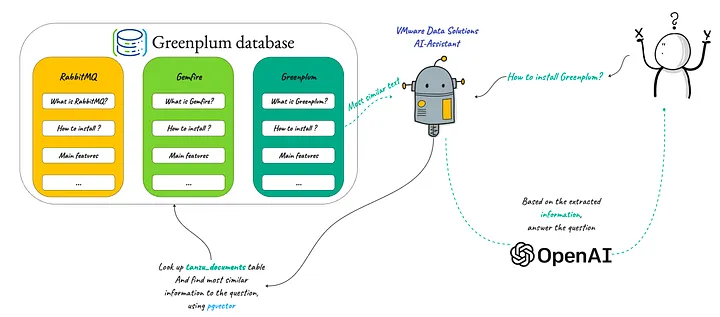
다음 그림과 같이 OpenAI를 사용하여 지능형 챗봇을 구축하고 시맨틱 텍스트 검색을 통해 Greenplum, RabbitMQ, Gemfire, VMware SQL 및 VMware Data Service Manager에 대한 자세한 기술적 질문에 답변할 수 있는 VMware 데이터 솔루션에 대한 도메인별 지식을 얻을 수 있도록 지원함으로써 이 기능을 시연합니다:
pgvector 를 설치한 후에 Greenplum에서 벡터 임베딩의 저장을 시작하고 다음과 같이 pgvector 실행을 활성화하여 의미 검색(semantic searches)을 수행할 수 있습니다:
CREATE EXTENSION vector;
2. VECTOR 데이터 유형으로 제품 설명서 테이블 만들기
다음 SQL 쿼리로 제품 설명서와 임베딩을 저장할 테이블을 만들어 보겠습니다:
CREATE TABLE tanzu_documents (
id bigserial primary key,
content text,
embedding vector(1536)
)
DISTRIBUTED BY (id)
;
pgvector는 벡터(VECTOR data-type)라고 불리는 새로운 데이터 유형을 도입합니다. 우리는 위의 쿼리 코드에서 벡터 데이터 유형으로 임베딩 열을 만들었습니다. 벡터의 크기는 벡터가 얼마나 많은 차원을 보유하는지 정의합니다. OpenAI의 text—embedding-ada-002 모델은 1,536개의 차원을 출력하므로 벡터 크기에 사용할 것입니다.
이 게시물에서 OpenAI API를 사용하고 있으므로 다음을 실행하는 모든 Greenplum 호스트에 openai 패키지를 설치합니다:
gpssh -f gphostsfile -e 'pip3 install -y openai'
또한 이 임베딩을 생성한 원본 제품 설명서 텍스트를 저장하기 위해 content 라는 text 열을 만듭니다.
참고: 위의 table은 Greenplum 세그먼트에 걸쳐 "id" 열을 기준으로 분산 저장(distributed by the “id”)되며, pgvector extension은 Greenplum 기능과 완벽하게 작동합니다. 따라서 분산저장에서 파티셔닝에 이르기까지 Greenplum의 MPP(Massiviely Parallel Processing) 기능에 대량의 데이터를 관리하고 검색하는 pgvector의 효율성을 추가하면 Greenplum 사용자는 확장 가능한 규모있는 AI 애플리케이션을 구축할 수 있습니다.
3. OpenAI 임베딩 가져오기 위한 Greenplum PL/Python 함수
이제 문서에 대한 임베딩을 생성해야 합니다. 여기서는 OpenAI의 text-message-ada-002 모델 API를 사용하여 텍스트에서 임베딩을 생성합니다.
가장 좋은 방법은 Greenplum 데이터베이스 내에 PL/Python3u 절차적 언어(Procedural Language)를 사용하여 Python 함수를 생성하는 것입니다. 다음 Greenplum Python 함수는 각 입력 문서에 대한 벡터 임베딩(vector embeddings)을 반환합니다.
CREATE OR REPLACE FUNCTION get_embeddings(content text)
RETURNS VECTOR
AS
$$
import openai
import os
text = content
openai.api_key = os.getenv("OPENAI_API_KEY")
response = openai.Embedding.create(
model="text-embedding-ada-002",
input = text.replace("\n"," ")
)
embedding = response['data'][0]['embedding']
return embedding
$$ LANGUAGE PLPYTHON3U;
원본 텍스트를 tanzu_documents 테이블, 특히 content 열에 로딩한 다음, embedding 열을 업데이트하고 이전에 생성된 get_messages Python 함수를 사용하여 모든 컨텐츠에 대해 OpenAI 임베딩을 생성합니다:
UPDATE tanzu_documents SET embedding = get_embeddings(content);
5. 첫 번째 의미론적 검색 (Semantic Search) 질의
pgvector의 코사인 거리를 사용하여 (<=> 연산자를 사용하여) 첫 번째 의미 검색 쿼리를 만들고, 질문과 가장 유사한 텍스트(즉, 최소 거리를 가진 텍스트)를 찾아보겠습니다: Greenplum 설치 방법? (How to install Greenplum? )
WITH cte_question_embedding AS
(
SELECT
get_embeddings(
'How to create an external table in Greenplum
using PXF to read from an Oracle database ?'
)
AS question_embeddings
)
SELECT
id
, content
, embedding <=> cte_question_embedding.question_embeddings AS distance
FROM tanzu_documents, cte_question_embedding
ORDER BY embedding <=> cte_question_embedding.question_embeddings ASC
LIMIT 1;
pgvector는 유사성을 계산하는 데 사용할 수 있는 세 가지 새로운 연산자를 소개합니다: - (1) 유클리드 거리 (Euclidean distance)(L2 거리): <->, - (2) 음의 내적 (Negative inner product): <#>, - (3) 코사인 거리 (Cosine distance): <=>
id | 640
content | title: Accessing External Data with PXF
-- Data managed by your organisation may already reside in external sources
-- such as Hadoop, object stores, and other SQL databases.
-- The Greenplum Platform Extension Framework \(PXF\) provides access
-- to this external data via built-in connectors that map an external
-- data source to a Greenplum Database table definition.
-- PXF is installed with Hadoop and Object Storage connectors.
-- These connectors enable you to read external data stored in text,
-- Avro, JSON, RCFile, Parquet, SequenceFile, and ORC formats.
-- You can use the JDBC connector to access an external SQL database.
-- > **Note** In previous versions of the Greenplum Database,
-- you may have used the `gphdfs` external table protocol to access
-- data stored in Hadoop. Greenplum Database version 6.0.0
-- removes the `gphdfs` protocol. Use PXF and the `pxf` external table
-- protocol to access Hadoop in Greenplum Database version 6.x.
-- The Greenplum Platform Extension Framework includes
-- a C-language extension and a Java service.
-- After configuring and initialising PXF, you start a single
-- PXF JVM process on each Greenplum Database segment host.
-- This long-running process concurrently serves multiple query requests.
-- For detailed information about the architecture of and using PXF,
-- refer to the [Greenplum Platform Extension Framework \(PXF\)]
-- (https://docs.vmware.com/en/VMware-Greenplum-Platform-Extension-Framework
-- /6.6/greenplum-platform-extension-framework/overview_pxf.html) documentation.
-- **Parent topic:** [Working with External Data]
-- (../external/g-working-with-file-based-ext-tables.html) **Parent topic:**
-- [Loading and Unloading Data](../load/topics/g-loading-and-unloading-data.html)
distance | 0.12006528354516588
6. 유사성 검색 SQL 함수:
많은 임베딩에 대해 유사성 검색을 수행할 예정이기 때문에, 이를 위한 SQL 사용자 정의 함수를 생성합니다:
CREATE OR REPLACE FUNCTION match_documents (
query_embedding VECTOR(1536),
match_threshold FLOAT,
match_count INT
)
RETURNS TABLE (
id BIGINT,
content TEXT,
similarity FLOAT
)
AS $$
SELECT
documents.id,
documents.content,
1 - (documents.embedding <=> query_embedding) AS similarity
FROM tanzu_documents documents
WHERE 1 - (documents.embedding <=> query_embedding) > match_threshold
ORDER BY similarity DESC
LIMIT match_count;
$$ LANGUAGE SQL STABLE;
위에서 정의한 match_documents 함수를 사용하여 다음과 같이 가장 유사한 텍스트를 OpenAI 모델에 제공합니다:
SELECT t.id, t.content, t.similarity
FROM match_documents(
(select get_embeddings(
'How to create an external table in Greenplum using PXF
to read from an Oracle database ?'))
, 0.8
, 1) t
;
id | 640
content | title: Accessing External Data with PXF
-- Data managed by your organisation may already reside in external sources
-- such as Hadoop, object stores, and other SQL databases.
-- The Greenplum Platform Extension Framework \(PXF\) provides access
-- to this external data via built-in connectors
-- that map an external data source to a Greenplum Database table definition.
-- PXF is installed with Hadoop and Object Storage connectors.
-- These connectors enable you to read external data stored in text, Avro,
-- JSON, RCFile, Parquet, SequenceFile, and ORC formats.
-- You can use the JDBC connector to access an external SQL database.
-- > **Note** In previous versions of the Greenplum Database,
-- you may have used the `gphdfs` external table protocol to access data
-- stored in Hadoop. Greenplum Database version 6.0.0 removes the `gphdfs` protocol.
-- Use PXF and the `pxf` external table protocol to access Hadoop in
-- Greenplum Database version 6.x.
-- The Greenplum Platform Extension Framework includes a C-language extension
-- and a Java service. After configuring and initialising PXF,
-- you start a single PXF JVM process on each Greenplum Database segment host.
-- This long-running process concurrently serves multiple query requests.
-- For detailed information about the architecture of and using PXF,
-- refer to the [Greenplum Platform Extension Framework \(PXF\)]
-- (https://docs.vmware.com/en/VMware-Greenplum-Platform-Extension-Framework/6.6/
-- greenplum-platform-extension-framework/overview_pxf.html) documentation.
-- **Parent topic:** [Working with External Data](../external/g-working-with-file-based-ext-tables.html)
-- **Parent topic:** [Loading and Unloading Data](../load/topics/g-loading-and-unloading-data.html)
similarity | 0.8775289173395486
7. 벡터 인덱싱 (Vectors Indexing):
우리의 테이블은 임베딩과 함께 시간이 지남에 따라 커질 수 있으며, 수십억 개의 벡터에 걸쳐 의미 검색을 수행하기를 원할 것입니다.
pgvector의 뛰어난 점은 쿼리 속도를 높이고 검색 속도를 높일 수 있는 인덱싱(Indexing) 기능입니다.
벡터 인덱스는 정확한 최근접이웃 검색(ANN/KNN, Nearest Neighbour)을 수행합니다. 벡터는 유사성에 따라 그룹화되지 않으므로 순차적 검색(sequential scan)을 통해 가장 가까운 이웃을 찾는 작업은 느리며, 유사성에 따라 정렬을 빠르게 하는 것이 중요합니다(ORDER BY 절).
각 거리 연산자에는 서로 다른 유형의 인덱스가 필요합니다. 시작할 때 적절한 수의 lists 는 1백만개 행까지는 1,000개, 1백만개 이상의 경우 sqrt(행) 개입니다. 코사인 거리로 정렬하기 때문에 vector_cosine_ops 인덱스를 사용합니다.
-- Create a Vector Index
CREATE INDEX ON tanzu_documents
USING ivfflat (embedding vector_cosine_ops)
WITH
(lists = 300);
-- Analyze table
ANALYZE tanzu_documents;
pgvector 인덱싱에 대한 자세한 내용은 여기에서 확인하십시오. https://github.com/pgvector/pgvector#indexing
8. 관련 답변에 적합한 데이터 세트를 OpenAI 모델에 제공합니다.
사용자의 인풋과 사용자 인풋에 가장 유사한 텍스트 둘 다를 인풋으로 사용해서 OPenAI 모델에게 답하도록 질문하는 PL/Python 함수를 정의합니다.
CREATE FUNCTION ask_openai(user_input text, document text)
RETURNS TEXT
AS
$$
import openai
import os
openai.api_key = os.getenv("OPENAI_API_KEY")
search_string = user_input
docs_text = document
messages = [
{"role": "system",
"content": "You concisely answer questions based on text provided to you."}
]
prompt = """Answer the user's prompt or question:
{search_string}
by summarising the following text:
{docs_text}
Keep your answer direct and concise. Provide code snippets where applicable.
The question is about a Greenplum / PostgreSQL database.
You can enrich the answer with other Greenplum or PostgreSQL-relevant details
if applicable.""".format(
search_string=search_string,
docs_text=docs_text
)
messages.append({"role": "user", "content": prompt})
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=messages
)
return response.choices[0]["message"]["content"]
$$ LANGUAGE PLPYTHON3U;
9. 더 똑똑한 검색 기능 만들기
앞서 언급했듯이, ChatGPT는 기존의 문서만 반환하지 않습니다. ChatGPT는 다양한 정보를 이해해서 하나의 응집력있는 대답으로 만들 수 있습니다. 이를 위해 GPT에 관련 문서와 이 답변을 생성하는 데 사용할 수 있는 프롬프트를 제공해야 합니다.
마지막 단계로, 우리는 지능형 AI-Assistant 애플리케이션을 서비스하기 위해 이전 기능을 단일 프로세스로 결합해야 합니다.
이전 기능과 임베딩은 프롬프트를 2단계 프로세스로 분할하여 이 문제를 해결할 수 있습니다:
1. 임베딩 데이터베이스에 질문과 가장 관련성이 높은 문서를 조회합니다. 2. 이러한 문서를 OpenAI 모델이 답변에서 참조할 컨텍스트로 삽입합니다.
CREATE OR REPLACE FUNCTION intelligent_ai_assistant(
user_input TEXT
)
RETURNS TABLE (
content TEXT
)
LANGUAGE SQL STABLE
AS $$
SELECT
ask_openai(user_input,
(SELECT t.content
FROM match_documents(
(SELECT get_embeddings(user_input)) ,
0.8,
1) t
)
);
$$;
위의 SQL 함수는 사용자 입력을 가져다가 임베딩으로 변환하고, tanzu_documents 테이블에 대해 pgvector를 사용하여 의미론적 텍스트 검색을 수행하여 가장 관련성이 높은 문서를 찾고, 마지막으로 이를 OpenAI API 호출에 대한 참조 텍스트로 제공하여 최종 답변을 반환합니다.
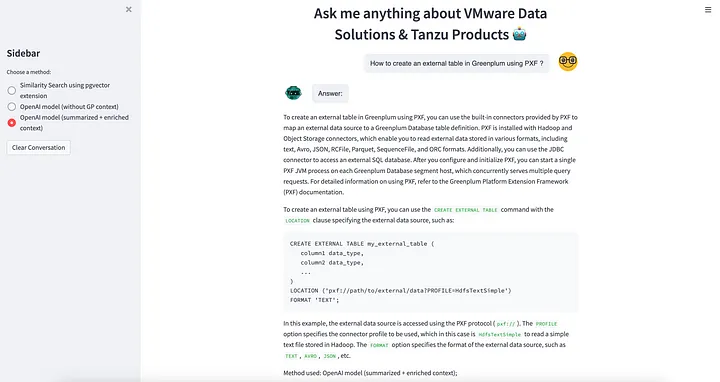
10. OpenAI 및 Streamlit 🎈를 활용한 시맨틱 텍스트 검색 기능으로 강화된 자체 챗봇 구축 🤖
마지막으로, 우리는 문서를 이해하고 pgvector 시맨틱 텍스트 검색과 함께 Greenplum 데이터 웨어하우스를 사용하는 Streamlit 🎈 챗봇 🤖를 개발했습니다.