[LangChain] RAG (Retrieval-Augmented Generation) 은 무엇이고, LangChain으로 어떻게 구현하나?
Deep Learning (TF, Keras, PyTorch)/Natural Language Processing 2023. 12. 18. 22:33LLM (Large Language Model) 을 사용하는데 있어
- Knowledge Cutoff: 모델 학습 이후에 생성된 데이터에 대해서는 학습이 안되어 답변을 못함
- No access to private data: 회사 내부 기밀정보, 신상정보, 비공개 정보에 대해서는 접근 불가
- Hallucinations: 사실에 입각하지 않은 답변을 그럴싸하고 자연스럽게 하는 환각 증상
- General Purpose: 다방면에 일정 수준 이상의 답변을 할 수 있지만, 특정 영역의 전문성이 떨어짐
등의 한계가 있을 수 있습니다.
이를 해결하는 방법으로 Fine-tuning 방법과 함께 RAG (Retrieval-Augmented Generation) 방법이 많이 사용됩니다.
이번 포스팅에서는
1. RAG (Retrieval-Augmented Generation) 이란 무엇인가?
2. RAG (Retrieval-Augmented Generation) 방법의 절차는 어떻게 되나?
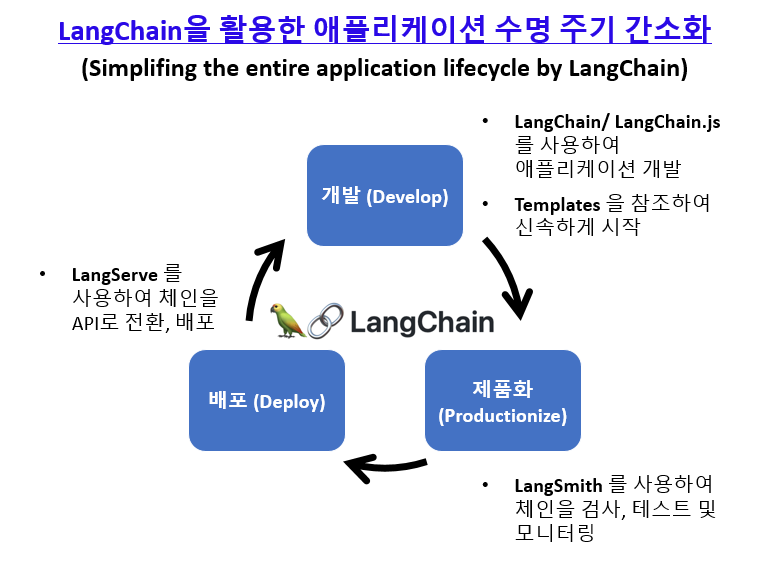
3. LangChain 으로 RAG 구현해보기
에 대해서 소개하겠습니다.
1. RAG (Retrieval-Augmented Generation) 이란 무엇인가?
RAG (Retrieval-Augmented Generation)은 자연 언어 처리 분야에서 언어 모델의 기능을 향상시키기 위해 검색 시스템과 결합하는 방법입니다. 이 접근법은 광범위한 외부 정보 소스에 의해 정보를 제공받아 응답이나 콘텐츠를 생성하는 데 특히 유용합니다.
RAG(Retrieval-Augmented Generation)에 대한 개요는 다음과 같습니다.
1. 검색 및 생성 결합 (Combining Retrieval and Generation): RAG 모델은 문서 검색 시스템과 seq2seq 언어 모델을 통합합니다. 검색 시스템은 입력 쿼리에 기반하여 대규모 코퍼스(위키피디아나 사용자 정의 데이터베이스와 같은)에서 관련 문서나 정보를 먼저 가져옵니다.
2. 정보 증강 (Information Augmentation): 검색된 문서는 언어 모델의 입력을 증강하는 데 사용되며, 이는 모델이 초기 훈련 중에 '학습'하지 못한 추가적인 맥락과 정보(additional context and information)를 제공합니다. 이를 통해 모델은 더 정확하고 맥락에 적합한 응답을 생성할 수 있게 됩니다.
3. 응용 분야 (Applications): RAG는 모델이 훈련 데이터에 포함되지 않은 구체적이고 사실적인 답변을 제공해야 하는(model needs to provide specific, factual answers) 질문 응답 시스템에서 특히 유용합니다. 또한, 정확도를 위해 외부 데이터 소스가 필요한 상세하거나 기술적인 응답이 필요한 애플리케이션에서도 사용됩니다.
4. 사용 예시: RAG의 일반적인 응용은 복잡한 질문에 대해 독립적인 언어 모델보다 정확하게 답변할 수 있는 관련 정보를 수집하는 AI 챗봇과 가상 비서입니다.
5. RAG 방법의 장점 (Advantages of RAG)
- 더 풍부한 응답 (Richer Responses): 광범위한 정보에 접근함으로써 RAG는 더 상세하고 정확한 응답을 제공할 수 있습니다.
- 동적 지식 (Dynamic Knowledge): 모델이 최신 정보에 접근할 수 있게 해주며, 특히 최근 이벤트나 특정 데이터에 관한 질문에 유용합니다.
6. 기술 구현 (Technical Implementation): RAG 시스템을 구현하는 것은 일반적으로 Elasticsearch나 밀집 벡터 검색 시스템(Dense Vector Search System)과 같은 검색 모델과 GPT나 BART와 같은 seq2seq 언어 모델을 결합하는 것을 포함합니다.
RAG는 AI와 NLP 분야에서 중요한 발전을 나타내며, 광범위한 외부 정보에 기반한 보다 동적이고 최신의 내부 정보에 입각한 정확한 언어 생성을 가능하게 합니다.
2. RAG (Retrieval-Augmented Generation) 방법의 절차는 어떻게 되나?
검색-증강 생성(Retrieval-Augmented Generation, RAG) 방법은 정보 검색과 언어 생성의 힘을 결합한 자연 언어 처리에서의 정교한 접근법입니다. RAG 작동 방식을 단계별로 설명하면 다음과 같습니다:


* 출처: https://python.langchain.com/docs/use_cases/question_answering/
1. 문서를 텍스트 임베딩으로 변환하여 Vector DB에 저장하기
- 문서를 읽어와서(Load) 분할(Split)하고 파싱(Parsing)하기
- Dense Vector 형태의 Sentence Embedding 변환하기
- 나중에 Retrieval 단계에서 빠르게 검색해서 사용할 수 있도록 Indexing하여 Vector DB에 저장(Store)하기
2. 입력 수신 (Input Reception)
프로세스는 입력 쿼리 또는 프롬프트를 받는 것으로 시작됩니다. 이 쿼리가 RAG 프로세스를 활성화합니다.
3. 문서 검색 (Document Retrieval)
- 검색 시스템 활성화 (Retrieval System Activation): 첫 번째 주요 단계는 검색 시스템을 활성화하는 것입니다. 이 시스템은 대규모 문서 코퍼스나 데이터베이스(위키피디아나 전문화된 데이터셋과 같은)를 검색하도록 설계되었습니다.
- 쿼리 처리 (Retrieval System Activation): 입력 쿼리는 검색 시스템이 이해할 수 있는 검색 쿼리를 형성하기 위해 처리됩니다.
- 문서 가져오기 (Document Fetching): 검색 시스템은 처리된 쿼리를 기반으로 코퍼스를 검색하고 관련 문서나 정보 스니펫을 검색합니다.
4. 정보 증강 (Information Augmentation)
- 맥락 통합 (Context Integration): 검색된 문서는 입력 쿼리를 증강하는 데 사용됩니다. 이 단계는 원래 입력과 문서에서 추출된 관련 정보를 결합하는 것을 포함합니다.
- 증강된 입력 형성 (Context Integration): 증강된 입력이 형성되며, 이제 원래 쿼리와 검색된 문서의 추가 맥락을 모두 포함하게 됩니다.
5. 언어 모델이 답변 생성 (Language Model Generation)
- 증강된 입력 공급 (Feeding Augmented Input): 이 증강된 입력은 일반적으로 GPT나 BART와 같은 시퀀스-투-시퀀스 모델인 언어 모델에 공급됩니다.
- 응답 생성 (Response Generation): 언어 모델은 증강된 입력을 처리하고 응답을 생성합니다. 이 응답은 모델의 사전 훈련된 지식뿐만 아니라 검색 단계에서 가져온 외부 정보에 의해 정보를 제공받습니다.
6. 출력 생성 (Output Production)
- 정제 및 형식화 (Refinement and Formatting): 생성된 응답은 필요에 따라 애플리케이션의 요구 사항에 맞게 정제되거나 형식화될 수 있습니다.
- 아웃풋 전달 (Output Delivery): 최종 응답은 RAG 프로세스의 출력으로 전달됩니다. 이 출력은 일반적으로 독립적인 언어 모델에 의해 생성된 응답보다 더 정보에 근거하고 정확하며 맥락적으로 관련성이 높습니다.
7. 피드백 루프 (선택적)
일부 구현에서는 검색된 문서의 효과성과 최종 출력의 품질을 평가하는 피드백 메커니즘이 있을 수 있습니다. 이 피드백은 프로세스의 미래 반복을 개선하는 데 사용될 수 있습니다.
RAG 방법은 광범위한 정적 지식베이스와 현대 언어 모델의 동적 생성 능력 사이의 격차를 효과적으로 연결하여 맥락적으로 풍부하고 매우 관련성이 높은 답변을 생성합니다.
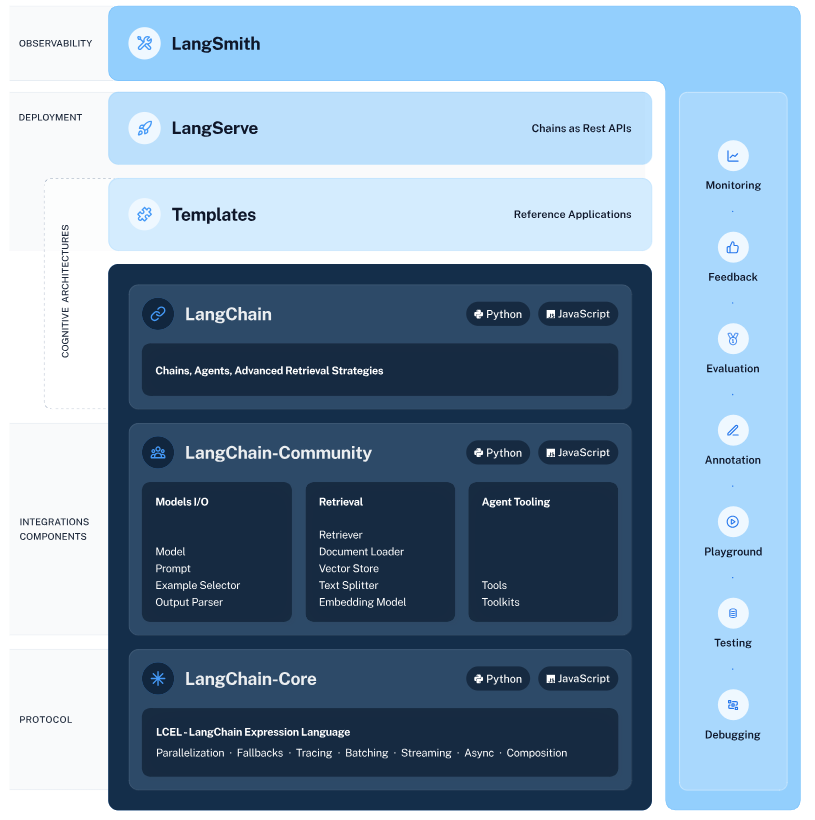
3. LangChain 으로 RAG 구현해보기
흐름은 다음과 같습니다.

1. 첫 번째 단계에서는 두 개의 항목이 있는 RunnableParallel 객체를 생성합니다. 첫 번째 항목인 context는 검색기에 의해 가져온 문서 결과를 포함할 것입니다. 두 번째 항목인 question은 사용자의 원래 질문을 담을 것입니다. 질문을 전달하기 위해 RunnablePassthrough를 사용하여 이 항목을 복사합니다.
2. 위 단계에서의 Dictionary를 프롬프트 구성요소에 공급합니다. 그런 다음 사용자 입력인 question과 검색된 문서인 context를 사용하여 프롬프트를 구성하고 PromptValue를 출력합니다.
3. 모델 구성요소는 생성된 프롬프트를 가져와 OpenAI LLM 모델(ChatModel)에 평가를 위해 전달합니다. 모델에서 생성된 출력은 ChatMessage 객체입니다.
4. 마지막으로, output_parser 구성요소는 ChatMessage를 가져와 이를 Python 문자열로 변환(StrOutputParser)하며, 이는 chain.invoke() 메소드에서 반환됩니다.
LangChain 코드를 하나씩 살펴보겠습니다.
먼저, 필요한 모듈로서 langchain, openai, docarray, tiktoken 이 미리 설치가 안되었다면, 먼저 터미널에서 pip install 을 사용해서 모듈을 설치해야 합니다. (Jupyter Notebook에서 사용 중이라면 셀 안에서 '!' 를 앞에 붙임)
-- Prerequisite: install modules of langchain, openai, docarray, tiktoken
! pip install -q langchain openai docarray tiktoken
DocArrayInMomorySerch 클래스를 사용해서 In-memory Vector DB에 OpenAI의 Embeddings model을 사용해서 임베딩 변환한 문장들을 저장합니다.
그리고 retriever 를 설정 (retriever = vectorstore.as_retriever()) 합니다.
retriever 는 나중에 chaining 해서 쓸 수도 있고, 아니면 retriever.invoke() 해서 바로 검색(Retrieval)하는데 사용할 수도 있습니다. 검색을 할 때는 Vector DB에 저장된 임베딩과 User query로 들어온 문서의 임베딩 간에 코사인 유사도 (cosine similarity)를 계산해서 유사도 내림차순 기준으로 검색 결과를 반환합니다.
## import modules required
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.prompts import ChatPromptTemplate
from langchain.vectorstores import DocArrayInMemorySearch
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
## Sentence Embedding, Vector Store
vectorstore = DocArrayInMemorySearch.from_texts(
["There are 4 seasons in Korea",
"Harry Potter is an outstanding wizard",
"The dog likes to walk"],
embedding=OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY), # set with yours
)
## Setup the Retriever using an In-memory store
## , which can retrieve documents based on a query
retriever = vectorstore.as_retriever()
## This is a runnable component that can be chained together with other component as below,
## , but you can also try to run it separately.
retriever.invoke("Who is Harry Potter?")
# [Document(page_content='Harry Potter is an outstanding wizard'),
# Document(page_content='The dog likes to walk'),
# Document(page_content='There are 4 seasons in Korea')]
ChatPromptTemplate.from_template() 를 사용해서 Prompt Template 를 생성해줍니다. 아래의 template 를 보면 알 수 있는 것처럼 LLM 모델에게 "오직 주어진 context 에 기반해서 질문에 답변을 해라" 라고 지시를 합니다.
template = """Answer the question based only on the following context: {context} Question: {question}"""
그리고 {context} 에는 문서 검색(Retrieval)의 결과를 넣어주고, {question}에는 사용자 질문을 넣어줍니다. 그러면 위에서 정의한 retriever 가 문서의 임베딩된 문장들과 사용자 질문 임베딩 간의 코사인 유사도를 계산해서 가장 유사한 k 개의 문장을 {context}로 넣어주게 됩니다.
## Chat Prompt Template
# : the prompt template below takes in context and question as values
# : to be substituted in the prompt.
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
## ChatModel
model = ChatOpenAI(openai_api_key=OPENAI_API_KEY) # set with yours
## Output Parser
output_parser = StrOutputParser()
RunnableParallel 메소드는 (a) "context"로서 retriever와 (b) "question"으로서 RunnablePassthrough() 를 병렬로 처리할 수 있게 해줍니다. (위의 RAG pipeline 그림 참조하세요. 두 갈래로 나뉘어서 동시 처리됩니다.)
'|' 를 사용해서 setpu_and_retrieval (사용자 질문을 받아서 저장된 문서 중에서 가장 관련있는 텍스트를 검색해오기) + Prompt (오직 {context}를 참조해서만 {question}에 답변하라는 지시) + model (OpenAI의 ChatModel LLM을 사용해서 답변) + output_parser (ChatModel이 생성한 ChatMessage를 string으로 파싱) 연결(chaining) 합니다.
chain.invoke() 로 위에서 생성한 chian을 실행해줍니다.
## Before building the prompt template,
## we want to retrieve relevant documents to the search and include them as part of the context.
setup_and_retrieval = RunnableParallel(
{"context": retriever, # the retriever for document search
"question": RunnablePassthrough() # to pass the user's question
}
)
## Chaining setup_and_retrieval + Prompt + ChatModel + OutputParser
chain = setup_and_retrieval | prompt | model | output_parser
## Run a chain pipeline
chain.invoke("Who is Harry Potter?")
# Harry Potter is an outstanding wizard.
[ Reference ]
1. RangChain Tutorial - RAG Search Example
: https://python.langchain.com/docs/expression_language/get_started#basic-example-prompt-model-output-parser
2. LangChain Tutorial - Retrieval-Augmented Generation (RAG)
: https://python.langchain.com/docs/use_cases/question_answering/
3. transformer를 이용한 토큰화(Tokenization), 단어 임베딩(Word Embedding), 텍스트 임베딩 (Text Embedding)
: https://rfriend.tistory.com/m/807
이번 포스팅이 많은 도움이 되었기를 바랍니다.
행복한 데이터 과학자 되세요!