이번 포스팅에서는 베타분포 (Beta Distribution)란 무엇이고, 왜 중요한가에 대해 다뤄보겠습니다.
1. 베타 분포 (Beta Distribution)는 무엇인가?
베타 분포는 구간 [0, 1] 에서 정의된 연속 확률 분포입니다. 일반적으로 Beta(α,β)로 표기되며, 여기서 α와 β는 양의 형태 매개변수입니다. 베타 분포의 확률 밀도 함수(PDF)는 다음과 같습니다:

여기서 B(α,β)는 베타 함수로, 확률 밀도 함수 아래의 면적이 1이 되도록 하는 정규화 상수 역할을 합니다.
베타 분포는 형태 매개변수의 값에 따라 다양한 모양을 가지며 다음과 같은 특징을 갖습니다:
- α=β=1인 경우, 베타 분포는 구간 [0,1]에서 균일 분포입니다.
- α와 β가 증가함에 따라 분포는 평균 주변에 더 피크한 형태를 가집니다.
2. 베이지안 통계(Bayesian Statistics)에서 베타분포(Beta Distribution)는 왜 중요한가?
베타 분포는 베이지안 통계에서 여러 이유로 중요합니다:
(1) 켤레 사전 분포 (Conjugate Prior)
베타 분포는 이항, 음이항 이항, 베르누이 및 기하 분포에 대한 켤레 사전 분포입니다(The beta distribution is the conjugate prior for the binomial, negative binomial, Bernoulli, and geometric distributions). 이는 베이지안 분석에서 베타 분포를 사전 분포로 사용하고 관측된 데이터로 업데이트하면 사후 분포도 베타 분포가 되는 특성을 의미합니다. 이러한 특성은 베이지안 추론에서 업데이팅 과정을 단순화합니다.
(2) 사전 신념 표현 (Expressing Prior Beliefs)
베타 분포는 이진 결과(성공/실패, 앞면/뒷면 등)에 대한 성공 확률에 대한 사전 신념을 모델링하는 데 자주 사용됩니다. 형태 매개변수 α와 β(shape parameters α and β)에 적절한 값을 선택함으로써 연구자는 한 방향으로의 강한 신념부터 더 불확실하거나 흩어진 신념까지 다양한 사전 신념을 표현할 수 있습니다.
(3) 베이지안 업데이팅 (Bayesian Updating)
베타 분포는 베이지안 분석에서 사전 지식을 분석에 통합하는 데 도움이 됩니다. 새로운 데이터를 관측한 후에는 사전 분포를 사후 분포로 업데이트하며, 베타 분포의 수학적 속성은 이 업데이트 과정을 분석적으로 다루기 쉽게 만듭니다.
(4) 베타-이항 모델 (Beta-Binomial Model)
베타 분포는 이항 분포와 밀접한 관련이 있습니다. 베이지안 분석에서 사전으로 사용되어진다면 베르누이 분포와 함께 사용되는 경우가 많으며, 결과적인 모델은 베타-이항 모델 (beta-binomial model)이라고 불립니다. 이 모델은 베이지안 맥락에서 이항 확률 변수의 분포를 모델링하는 데 널리 사용됩니다.
요약하면 베타 분포는 베이지안 통계에서 사전 신념을 모델링하고 이를 관측 데이터로 업데이트하는 데 유연하고 분석적으로 편리한 방법을 제공합니다. 그 켤레성(conjugate nature)은 베이지안 추론에서 수학적 계산을 간단하게 만듭니다.
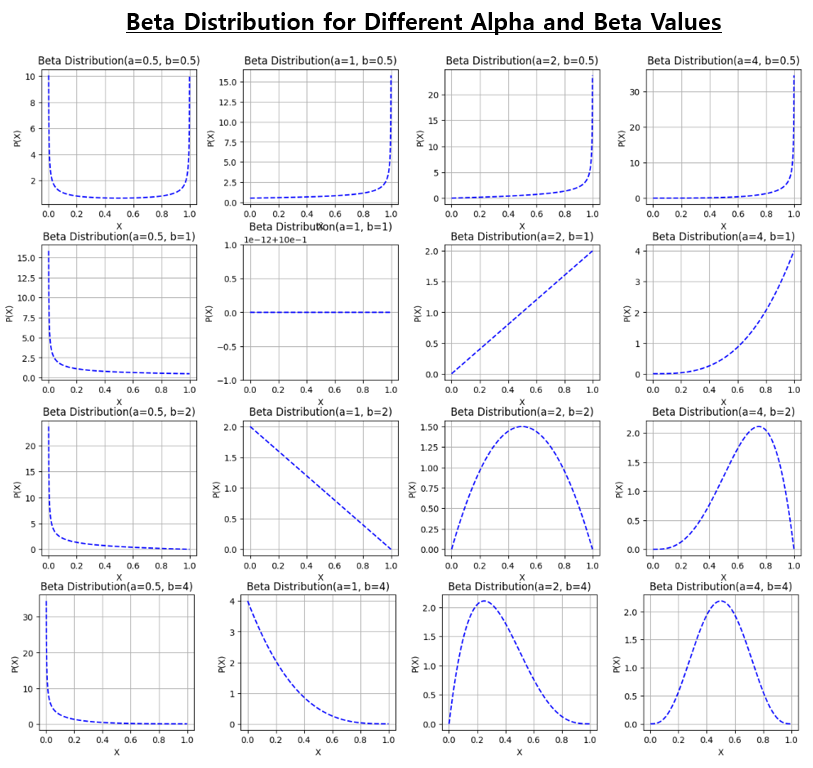
3. Python을 이용해서 베타 분포의 파라미터별 그래프 그려보기
X 축 값의 구간은 [0, 1] 사이의 실수로 하고, 형태 매개변수 α와 β(shape parameters α and β) 를 변화시켜가면서 베타 분포를 그래프로 그려보겠습니다. 가령, 아래 그래프에서 보는 바와 같이, α와 β의 값이 각각 1인 경우 확률값이 모두 0으로 동일합니다. (즉, 사전 정보가 없다는 의미입니다)
α와 β의 값에 따라 매우 다양한 형태의 확률 분포를 표현할 수 있어서 유용합니다.
# Plot the beta distribution for each set of alpha and beta values
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import beta
# Define a range of x values
x = np.linspace(0, 1, 1000)
# Define different alpha and beta values
d = [.5, 1, 2, 4]
fig = plt.figure(figsize=(16, 12))
for i in np.arange(16):
a = d[i % 4]
b = d[i // 4]
ax = fig.add_subplot(4, 4, 1 + i)
ax.set_title('Beta Distribution(a=' + str(a) + ', b=' + str(b) + ')')
ax.set_xlabel('X')
ax.set_ylabel('P(X)')
ax.grid()
ax.plot(x, beta(a, b).pdf(x), 'b--')
plt.subplots_adjust(top=.95, bottom=.05, hspace=.3, wspace=.3)
plt.show()
이번 포스팅이 많은 도움이 되었기를 바랍니다.
행보한 데이터 과학자 되세요! :-)

'Python 분석과 프로그래밍 > Python 통계분석' 카테고리의 다른 글
| [시계열 분석] Drift, Shift 는 무엇이고, 어떻게 분석하는가? (0) | 2024.01.20 |
|---|---|
| 확률 (Probability) vs. 우도 (Likelihood) (0) | 2023.12.10 |
| 상관관계(Correlation) vs. 인과관계(Causation) (0) | 2023.12.10 |
| 베이지안 통계(Bayesian Statistics)와 베이즈 정리(Bayes's Theorem) (1) | 2023.12.09 |
| 중심극한의 정리 (Central Limit Theorem) 이란 무엇이고, 왜 중요한가? (0) | 2023.12.09 |



