[LangChain] Fallback 을 사용해서 LLM API 에러 처리 (Handling LLM API errors using Fallbacks)
Deep Learning (TF, Keras, PyTorch)/Natural Language Processing 2023. 12. 23. 18:09LLM 애플리케이션에서는 LLM API의 문제, 모델의 부적절한 출력, 다른 통합과 관련된 문제 등 다양한 실패 지점이 있을 수 있습니다. Fallbacks 방법은 이러한 문제를 우아하게 처리하고 격리하는 데 도움이 됩니다.
LangChain의 invoke 메소드를 사용할 때는 언어 모델과 외부 API를 다루는 복잡성으로 인해 다양한 오류가 발생할 수 있습니다. 일반적인 오류 유형은 다음과 같습니다.
(1) 네트워크 오류 (Network Errors): 외부 언어 모델이나 API에 연결할 때 발생하는 타임아웃이나 연결 실패와 같은 네트워크 관련 문제입니다.
(2) API 오류 (API Errors): 언어 모델이나 다른 서비스의 API에서 반환되는 오류로, 속도 제한, 인증 문제 또는 예기치 않은 응답을 포함할 수 있습니다.
(3) 모델 오류 (Model Errors): 토큰 한도(Token Limits Per Minute, TPM)를 초과하는 응답을 생성하거나 지원되지 않는 입력 형식을 만나는 등, 언어 모델 자체와 관련된 문제입니다.
(4) 내부 LangChain 오류 (Internal LangChain Errors): LangChain 프레임워크 내의 오류로, 구성 문제, 프롬프트 구성 문제 또는 LangChain에서 정의된 작업 체인의 오류 등을 포함할 수 있습니다.
이러한 오류를 무난하게 처리하기 위해 코드에 오류 처리 메커니즘 또는 fallback 전략을 구현할 수 있습니다. 중요한 것은, Fallbacks 방법이 LLM 수준뿐만 아니라 전체 Runnable 수준에서도 적용될 수 있다는 것입니다.
먼저 openai, langchain 가 설치되어 있지 않다면, 터미널에서 pip install 을 사용해서 설치합니다.
! pip install -q openai langchain
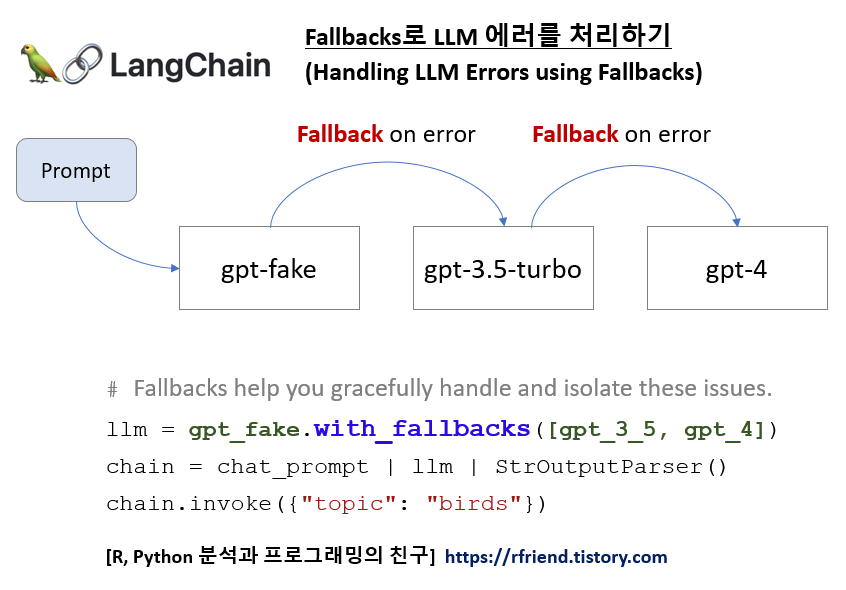
아래 예제에서는 존재하지 않는 LLM 모델을 사용하여 에러가 발생한 상황에서, ChatGPT-3.5-Turbo, ChatGPT-4 모델을 대신 사용하도록 하는 Fallbacks을 설정하여 에러를 처리하여 보겠습니다.
이때 다수의 LLM wrapper 들이 LLM API 에러를 감지하면 재시도(retry)를 하도록 디폴트 세팅이 되어있습니다. 그래서 max_retries=0 으로 설정을 해주어서 에러가 나면 바로 Fallbacks 로 넘어가도록 하였습니다.
먼저, ChatOpenAI(model_name="gpt-fake") 라고 하는 존재하지 않는 모델을 사용해서 억지로 에러(NotFoundError)를 유발해보겠습니다.
import os
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
os.environ["OPENAI_API_KEY"] = "sk-xxxxx..."
chat_prompt = ChatPromptTemplate.from_template("""Write a short joke about {topic}""")
bad_model = ChatOpenAI(model_name="gpt-fake", max_retries=0, openai_api_key=OPENAI_API_KEY)
bad_chain = chat_prompt | bad_model | StrOutputParser()
bad_chain.invoke({"topic": "birds"})
# NotFoundError Traceback (most recent call last)
# <ipython-input-15-7c48d4ea1ee5> in <cell line: 9>()
# 7 bad_chain = chat_prompt | bad_model | StrOutputParser()
# 8
# ----> 9 bad_chain.invoke({"topic": "birds"})
#
# NotFoundError: Error code: 404 - {'error':
# {'message': 'The model `gpt-fake` does not exist',
# 'type': 'invalid_request_error',
# 'param': None,
# 'code': 'model_not_found'}
# }
이제 Fallbacks 을 추가해서 "gpt-fake" LLM 모델에 에러가 발생 시 대체 방안인 "gpt-3.5-turbo" 모델을 사용하고, 이마저도 에러가 발생하면 "gpt-4" 모델로 넘어가서 응답을 생성하도록 해보겠습니다.
llm = gpt_fake.with_fallbacks([gpt_3_5, gpt_4])
import os
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
os.environ["OPENAI_API_KEY"] = "sk-xxxx..."
template = """Write a short jork about {topic}"""
chat_prompt = ChatPromptTemplate.from_template(template)
gpt_fake = ChatOpenAI(
model_name="gpt-fake",
max_retries=0, # Note that we set max_retries = 0 to avoid retrying on RateLimits, etc
)
gpt_3_5 = ChatOpenAI(model_name="gpt-3.5-turbo")
gpt_4 = ChatOpenAI(model_name="gpt-4")
# This is where the magic happens, using Fallbacks
llm = gpt_fake.with_fallbacks([gpt_3_5, gpt_4])
chain = chat_prompt | llm | StrOutputParser()
chain.invoke({"topic": "birds"})
# Why did the bird bring a ladder to the party?
# Because it heard the drinks were on the house!
이번에는 에러 없이 답변을 잘 하네요! ^^b
[ Reference ]
* LangChain Tutorial - Add Fallbacks:
https://python.langchain.com/docs/expression_language/how_to/fallbacks
이번 포스팅이 많은 도움이 되었기를 바랍니다.
행복한 데이터 과학자 되세요! :-)