[R 지리공간 데이터 분석] 지리공간 벡터의 속성 데이터를 그룹별로 집계하기 (vector attribute aggregation by group)
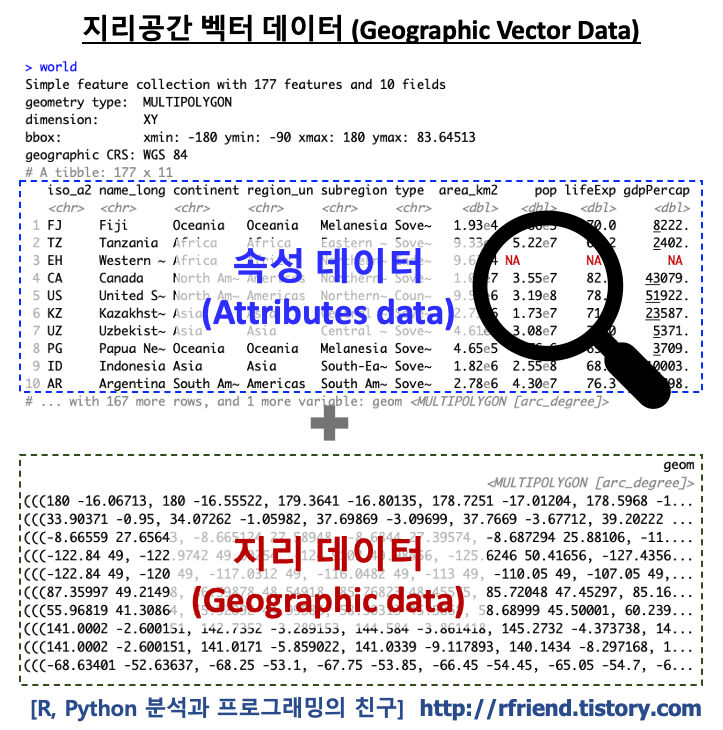
R 분석과 프로그래밍/R 지리공간데이터 분석 2021. 3. 1. 17:24지난번 포스팅에서는 지리공간 벡터 데이터의속성 정보의 행과 열을 가져오기 (rfriend.tistory.com/622) 에 대해서 알아보았습니다. 그리고 지리공간 벡터 데이터는 지리 정보(geometry column) + 속성 정보(attributes)로 이루어지며, 속성 정보의 일부를 subset 하여 가져오면 지리정보(geometry column)가 같이 따라 온다는 것도 소개하였습니다.
이번 포스팅에서는 지리공간 벡터 데이터의 속성 정보의 요약 정보를 그룹별로 집계하는 방법(aggregating geographic vector attritubes by group)을 R 패키지별로 나누어서 소개하겠습니다.
(1) Base R의 aggregate() 함수를 사용해서 지리 벡터 데이터의 속성 정보를 그룹별로 집계하기
(2) dplyr 의 summarise() 함수를 사용해서 지리 벡터 데이터의 속성 정보를 그룹별로 집계하기
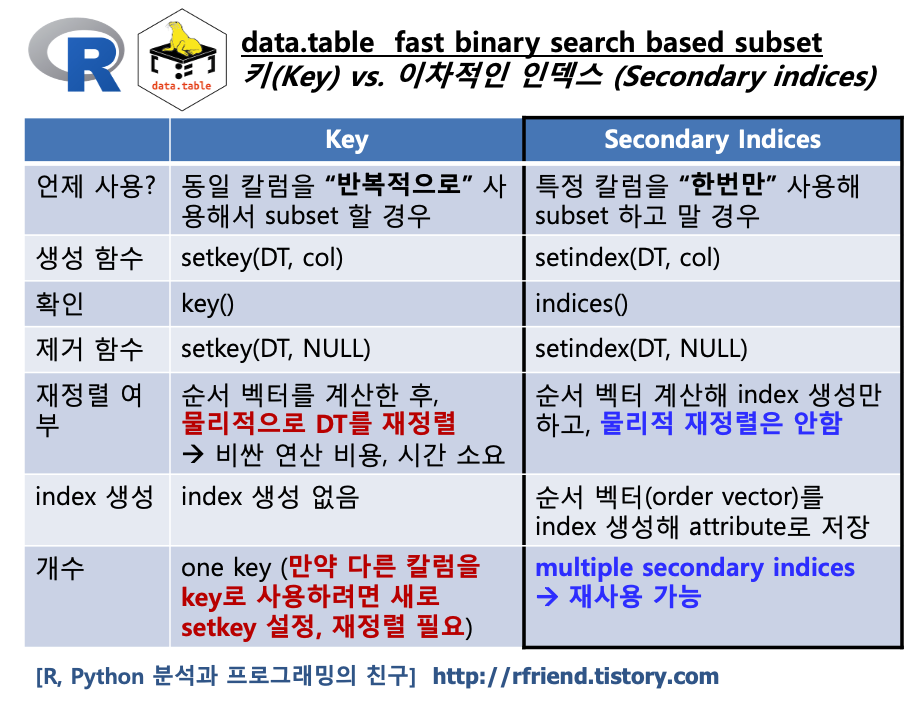
(3) data.table 로 지리 벡터 데이터의 속성 정보를 그룹별로 집계하기

(1) Base R의 aggregate() 함수를 사용해서 지리 벡터 데이터의 속성 정보를 그룹별로 집계하기
그리고, Base R, dplyr, data.table 의 3개 패키지 내 함수를 사용해서 아래 문제의 그룹별 속성 정보 집계를 해보겠습니다.
대륙(continent) 그룹 별로 인구(pop) 속성 데이터의 합(summation)을 구하고, 국가의 수 (number of countries) 를 집계한 후, --> 인구 합이 가장 큰 상위 3개(top 3) 대륙을 선별하시오.
예제로 spData 패키지에 들어있는 'world' 라는 이름의, 10개 속성(attributes)과 1개 지리기하 칼럼(geometry column)을 가지고 있는 세계 국가에 대한 지리 벡터 데이터를 사용하겠습니다. 그리고 속성 정보 집계를 하는데 사용할 dplyr, data.table 패키지도 불러오겠습니다.
## =================================
## GeoSpatial Data Analysis using R
## : Vector attribute aggregation
## =================================
library(sf)
library(spData) # for dataset
library(dplyr) # for data aggregation
library(data.table) # for data aggregation
names(world)
# [1] "iso_a2" "name_long" "continent" "region_un" "subregion" "type" "area_km2" "pop" "lifeExp" "gdpPercap"
# [11] "geom"
Base R 패키지에 기본으로 내장되어 있는 aggregate(x ~ group, FUN, data, ...) 함수를 사용해서 '대륙(continent)' 그룹별로 속성 정보인 '인구(pop)' 의 합(sum) 을 집계해보겠습니다. 이렇게 합계를 집계하면 data.frame 을 반환하였으며, 집계된 결과에 지리 기하(geometry) 정보는 없습니다.
## aggregation operations summarize dataset by a 'grouping variable'.
## (1) aggregation using aggregate() function from Base R
## : returns a non-spatial data.frame
world_agg_pop = aggregate(pop ~ continent,
FUN = sum,
data = world,
na.rm = TRUE)
str(world_agg_pop)
# 'data.frame': 6 obs. of 2 variables:
# $ continent: chr "Africa" "Asia" "Europe" "North America" ...
# $ pop : num 1.15e+09 4.31e+09 6.69e+08 5.65e+08 3.78e+07 ...
class(world_agg_pop)
# [1] "data.frame"
world_agg_pop
# continent pop
# 1 Africa 1154946633
# 2 Asia 4311408059
# 3 Europe 669036256
# 4 North America 565028684
# 5 Oceania 37757833
# 6 South America 412060811
'sf' 객체에 대해 aggregate() 함수를 적용하면 'sf' 클래스에 있는 aggregate.sf() 함수가 자동으로 활성화되어 적용이 됩니다. world['pop'] 의 'sf' 클래스를 x 로 하여 aggregate(x = sf_object, by = list(), FUN, ...) 구문으로 아래와 같이 대륙 그룹별로 인구의 합계를 집계하면 "data.frame"을 확장한 "sf" 클래스의 집계된 객체를 반환하며, "data.frame"의 제일 끝에 "geometry" 칼럼이 리스트로 같이 집계(aggregation)가 됩니다. (즉, 각 대륙별로 국가들의 다각형 면(polygon)을 모아놓은 리스트가 "geometry"에 생김).
## aggregate.sf() is activated automatically when 'x' is an sf object and a 'by' argument is provided.
## : returns a spatial 'sf' class and data.frame
world_agg_pop2 = aggregate(
x = world['pop'],
by = list(world$continent), # a lost of grouping elements
FUN = sum,
na.rm = TRUE)
str(world_agg_pop2)
# Classes 'sf' and 'data.frame': 8 obs. of 3 variables:
# $ Group.1 : chr "Africa" "Antarctica" "Asia" "Europe" ...
# $ pop : num 1.15e+09 0.00 4.31e+09 6.69e+08 5.65e+08 ...
# $ geometry:sfc_GEOMETRY of length 8; first list element: List of 2
# ..$ :List of 1
# .. ..$ : num [1:356, 1:2] 32.8 32.6 32.5 32.2 31.5 ...
# ..$ :List of 1
# .. ..$ : num [1:49, 1:2] 49.5 49.8 50.1 50.2 50.5 ...
# ..- attr(*, "class")= chr [1:3] "XY" "MULTIPOLYGON" "sfg"
# - attr(*, "sf_column")= chr "geometry"
# - attr(*, "agr")= Factor w/ 3 levels "constant","aggregate",..: 3 2
# ..- attr(*, "names")= chr [1:2] "Group.1" "pop"
class(world_agg_pop2)
# [1] "sf" "data.frame"
names(world_agg_pop2)
# [1] "Group.1" "pop" "geometry"
world_agg_pop2
# Simple feature collection with 8 features and 2 fields
# Attribute-geometry relationship: 0 constant, 1 aggregate, 1 identity
# geometry type: GEOMETRY
# dimension: XY
# bbox: xmin: -180 ymin: -90 xmax: 180 ymax: 83.64513
# geographic CRS: WGS 84
# Group.1 pop geometry
# 1 Africa 1154946633 MULTIPOLYGON (((32.83012 -2...
# 2 Antarctica 0 MULTIPOLYGON (((-163.7129 -...
# 3 Asia 4311408059 MULTIPOLYGON (((120.295 -10...
# 4 Europe 669036256 MULTIPOLYGON (((-51.6578 4....
# 5 North America 565028684 MULTIPOLYGON (((-61.68 10.7...
# 6 Oceania 37757833 MULTIPOLYGON (((169.6678 -4...
# 7 Seven seas (open ocean) 0 POLYGON ((68.935 -48.625, 6...
# 8 South America 412060811 MULTIPOLYGON (((-66.95992 -...
참고로, world['pop'] 는 "sf" 객체이기 때문에 aggregate() 함수 적용 시 자동으로 ''sf" 클래스의 aggregate.sf() 함수가 자동으로 활성화되어 적용되고 집계 결과가 "sf" 객체로 반환되는 반면에, world$pop 는 숫자형 벡터(numeric vector) 이므로 aggregate() 함수를 적용하면 "data.frame" 으로 집계 결과를 반환하게 됩니다.
## 'sf' object
class(world['pop'])
# [1] "sf" "tbl_df" "tbl" "data.frame"
world['pop']
# Simple feature collection with 177 features and 1 field
# geometry type: MULTIPOLYGON
# dimension: XY
# bbox: xmin: -180 ymin: -90 xmax: 180 ymax: 83.64513
# geographic CRS: WGS 84
# # A tibble: 177 x 2
# pop geom
# <dbl> <MULTIPOLYGON [arc_degree]>
# 1 885806 (((180 -16.06713, 180 -16.55522, 179.3641 -16.80135, 178.7251 -17.01204, 178.5968 -1...
# 2 52234869 (((33.90371 -0.95, 34.07262 -1.05982, 37.69869 -3.09699, 37.7669 -3.67712, 39.20222 ...
# 3 NA (((-8.66559 27.65643, -8.665124 27.58948, -8.6844 27.39574, -8.687294 25.88106, -11....
# 4 35535348 (((-122.84 49, -122.9742 49.00254, -124.9102 49.98456, -125.6246 50.41656, -127.4356...
# 5 318622525 (((-122.84 49, -120 49, -117.0312 49, -116.0482 49, -113 49, -110.05 49, -107.05 49,...
# 6 17288285 (((87.35997 49.21498, 86.59878 48.54918, 85.76823 48.45575, 85.72048 47.45297, 85.16...
# 7 30757700 (((55.96819 41.30864, 55.92892 44.99586, 58.50313 45.5868, 58.68999 45.50001, 60.239...
# 8 7755785 (((141.0002 -2.600151, 142.7352 -3.289153, 144.584 -3.861418, 145.2732 -4.373738, 14...
# 9 255131116 (((141.0002 -2.600151, 141.0171 -5.859022, 141.0339 -9.117893, 140.1434 -8.297168, 1...
# 10 42981515 (((-68.63401 -52.63637, -68.25 -53.1, -67.75 -53.85, -66.45 -54.45, -65.05 -54.7, -6...
# # ... with 167 more rows
## -- vs. numeric
class(world$pop)
# [1] "numeric"
world$pop[1:20]
# [1] 885806 52234869 NA 35535348 318622525 17288285 30757700 7755785 255131116 42981515 17613798 73722860
# [13] 13513125 46024250 37737913 13569438 10572466 10405844 143819666 382169
이제 우리가 풀고자 하는 요구사항에 답해보겠습니다. 요구사항은 "대륙 그룹별로 속성정보인 인구(pop)의 합과 국가의 수를 집계하고, 인구 합을 기준으로 상위 3개의 대륙을 찾으라"는 것이었습니다. aggregate(x ~ group, data, FUN) 구문으로 그룹별 집계를 하되, 집계해야 할 것이 (a) 인구의 "합(sum)"과, & (b) 국가의 "개수(number of rows)" 의 2개 이므로 FUN = function(x) c(pop = sum(x), n = length(x)) 의 함수를 사용해서 합과 개수를 구하도록 했습니다. 그리고 do.call(data.frame, ...) 을 사용해서 리스트로 반환된 집계 결과를 data.frame으로 변환을 해주었습니다.
그리고 "인구 합을 기준으로 상위 3개 대륙"을 찾기 위해서 order(-world_pop$pop.pop) 로 내림차순 정렬('-' 부호가 내림차순 정렬을 의미함. order 는 정렬 후의 위치 인덱스를 반환함.)을 한 인덱스를 사용해서 정렬을 한 후에 [1:3, ] 으로 상위 3개 행만을 가져왔습니다.
## group by aggregation: sum of pop, number of rows
world_pop = do.call(data.frame, aggregate(pop ~ continent,
data = world,
FUN = function(x) c(pop = sum(x), n = length(x))))
## sorting by pop.pop in descending order and select top 3
world_pop[order(-world_pop$pop.pop),][1:3,]
# continent pop.pop pop.n
# 2 Asia 4311408059 45
# 1 Africa 1154946633 48
# 3 Europe 669036256 37
(2) dplyr 의 summarise() 함수를 사용해서 지리 벡터 데이터의 속성 정보를 그룹별로 집계하기
위의 (1)번에서는 Base R의 aggregate() 함수를 사용하였는데요, dplyr 패키지의 group_by() 로 기준이 되는 그룹을 지정해주고 summarise() (또는 summarize()) 함수를 사용해서 다양한 집계 함수를 사용하여 Base R 보다 가독성이 좋고 속도가 빠른 코드를 짤 수 있습니다.
아래는 dplyr 패키지의 체인(%>%) 으로 파이프 연산자(pipe operator)를 사용해서 대륙 그룹별로 인구의 합계를 구해본 것입니다. 이때, 'sf' 객체에 대해 summarise() 함수를 적용하면 집계 결과는 자동으로 "data.frame"을 확장한 "sf" 클래스의 객체로 반환을 하고, 제일 마지막 칼럼에 "geom" 지리기하 리스트를 포함하게 됩니다.
## (2) aggregation using summarise() function from dplyr
library(dplyr)
world_agg_pop3 = world %>%
group_by(continent) %>%
summarise(sum(pop, na.rm = TRUE))
class(world_agg_pop3)
# [1] "sf" "tbl_df" "tbl" "data.frame"
names(world_agg_pop3)
# [1] "continent" "pop" "geom"
dplyr 의 summarise() 함수를 쓰면 (a) 집계한 결과의 칼럼 이름을 새로 부여할 수 있고, (b) 여러개의 집계 함수(예: 합, 개수, 평균, 표준편차, 최대, 최소 등)를 동시에 사용할 수 있다는 편리한 장점이 있습니다.
아래 예에서는 대륙별로 인구에 대한 합(sum(pop, na.rm=TRUE))과 국가의 개수(n()) 를 구하고, 집계된 후 결과의 칼럼 이름도 "pop_sum", "n_countries" 로 새로 부여해 본 것입니다.
## summarise(sum(), n()) {dplyr}
world %>%
group_by(continent) %>%
summarise(pop_sum = sum(pop, na.rm = TRUE),
n_countries = n())
# `summarise()` ungrouping output (override with `.groups` argument)
# Simple feature collection with 8 features and 3 fields
# geometry type: MULTIPOLYGON
# dimension: XY
# bbox: xmin: -180 ymin: -90 xmax: 180 ymax: 83.64513
# geographic CRS: WGS 84
# # A tibble: 8 x 4
# continent pop_sum n_countries geom
# <chr> <dbl> <int> <MULTIPOLYGON [arc_degree]>
# 1 Africa 1154946633 51 (((32.83012 -26.74219, 32.58026 -27.47016, 32.46213 -28.30101, 32.20339 -28.~
# 2 Antarctica 0 1 (((-48.66062 -78.04702, -48.1514 -78.04707, -46.66286 -77.83148, -45.15476 -~
# 3 Asia 4311408059 47 (((120.295 -10.25865, 118.9678 -9.557969, 119.9003 -9.36134, 120.4258 -9.665~
# 4 Europe 669036256 39 (((-51.6578 4.156232, -52.24934 3.241094, -52.55642 2.504705, -52.93966 2.12~
# 5 North America 565028684 18 (((-61.68 10.76, -61.105 10.89, -60.895 10.855, -60.935 10.11, -61.77 10, -6~
# 6 Oceania 37757833 7 (((169.6678 -43.55533, 170.5249 -43.03169, 171.1251 -42.51275, 171.5697 -41.~
# 7 Seven seas (open oce~ 0 1 (((68.935 -48.625, 69.58 -48.94, 70.525 -49.065, 70.56 -49.255, 70.28 -49.71~
# 8 South America 412060811 13 (((-66.95992 -54.89681, -67.29103 -55.30124, -68.14863 -55.61183, -68.63999 ~
이제 위에서 주어진 요구사항인 "대륙 그룹별로 인구의 합계와 국가 수를 집계하고, 인구합을 기준으로 상위 3개 대륙을 찾으라"는 문제를 dplyr 의 체인 파이프 연산자를 써서 풀어보겠습니다. top_n(n = 3, wt = pop) 함수로 인구합을 기준으로 상위 3개를 구하였고, arrange(desc(pop)) 로 인구합을 기준으로 내림차순 정렬하였습니다. 이때 지리기하 칼럼은 생략하고 속성(attritubes)에 대한 집계 결과만 얻고자 하므로 제일 마지막에 st_drop_geometry() 함수로 "geometry" 칼럼을 제거하였습니다.
## finding the world's 3 most populous continents by chaining functions using dplyr
world %>%
dplyr::select(pop, continent) %>%
group_by(continent) %>%
summarise(pop = sum(pop, na.rm = TRUE), n_countries = n()) %>%
top_n(n = 3, wt = pop) %>% # select top 3 rows by 'pop' varialbe
arrange(desc(pop)) %>% # sorting in a descending order
st_drop_geometry() # drop geometry column
# `summarise()` ungrouping output (override with `.groups` argument)
# # A tibble: 3 x 3
# continent pop n_countries
# * <chr> <dbl> <int>
# 1 Asia 4311408059 47
# 2 Africa 1154946633 51
# 3 Europe 669036256 39
(3) data.table 로 지리 벡터 데이터의 속성 정보를 그룹별로 집계하기
마지막으로 data.table 패키지를 사용해서 "대륙 그룹별로 인구 합계와 국가 수를 집계하고, 인구 합계 기준 상위 3개 대륙을 찾으라"는 문제를 풀어보겠습니다.
먼저, world_dt = data.table(world) 로 'world' sf 객체를 data.table 객체로 변환하였습니다. 그리고 data.table 의 체인 파이프를 사용해서 필요한 작업 흐름을 이어서 작성해보았는데요, 역시 data.table 이 코드가 가장 간결하고, 또 속도도 가장 빠릅니다. 아래 코드에서 .(pop = sum(pop, na.rm = T), n = .N) 은 인구 합계(sum(pop, na.rm=T)와 행의 개수(.N) 를 대륙 그룹별로(by = list(continent)) 집계한 후에, [order(-pop)] 로 인구 합계를 기준으로 내림차순 정렬('-' 부호는 내림차순을 의미함)을 하고, [1:3]으로 상위 3개 대륙의 집계 결과만 가져온 것입니다. 코드가 '간결함' 그 자체입니다!
단, 이때 최종 집계 결과는 data.table 로 반환이 되며, 지리기하 정보는 없습니다.
## (3) aggregating vector attributes using data.table package
library(data.table)
world_dt = data.table(world)
world_dt[, .(pop = sum(pop, na.rm = TRUE), n = .N),
by = list(continent)][order(-pop)][1:3]
## or equivalently above, using chaining
world_dt[,
.(pop = sum(pop, na.rm = TRUE), n = .N), # aggregate
by = list(continent)][ # by groups
order(-pop)][ # sorting in descending order
1:3] # subset rows (1:3)
# continent pop n
# 1: Asia 4311408059 47
# 2: Africa 1154946633 51
# 3: Europe 669036256 39
만약, 그룹별 지리기하 벡터 데이터를 집계한 결과에 지리기하 칼럼(geometry column)을 같이 리스트로 묶어서 속성정보와 함께 집계하고 싶으면 data.table 객체에서 칼럼을 가져올 때 world_dt[, .(pop = sum(pop, na.rm = T), n = .N, geom = geom) 처럼 "geom" 칼럼도 같이 가져오고, 이후의 집계 및 정렬, 인덱싱은 동일합니다.
## with geometry column (lists)
world_dt[, .(pop = sum(pop, na.rm = TRUE), n = .N, geom = geom),
by = list(continent)][order(-pop)][1:3]
# continent pop n geom
# 1: Asia 4311408059 47 <XY[1]>
# 2: Asia 4311408059 47 <XY[1]>
# 3: Asia 4311408059 47 <XY[13]>
[Reference]
* Geocompuation with R - 'Attribute data operations': geocompr.robinlovelace.net/attr.html
이번 포스팅이 많은 도움이 되었기를 바랍니다.
행복한 데이터 과학자 되세요! :-)