이번 포스팅에서는 Python의 SciPy 모듈을 사용해서 각 원소 간 짝을 이루어서 유클리디언 거리를 계산(calculating pair-wise distances)하는 방법을 소개하겠습니다. 본문에서 scipy 의 거리 계산함수로서 pdist()와 cdist()를 소개할건데요, 반환하는 결과물의 형태에 따라 적절한 것을 선택해서 사용하면 되겠습니다. 마지막으로 scipy 에서 제공하는 거리를 계산하는 기준(distance metric)에 대해서 알아보겠습니다.
(Scikit-Learn 모듈에도 거리 계산 함수가 있는데요, SciPy 모듈에 거리 측정 기준이 더 많아서 SciPy 모듈로 소개합니다.)
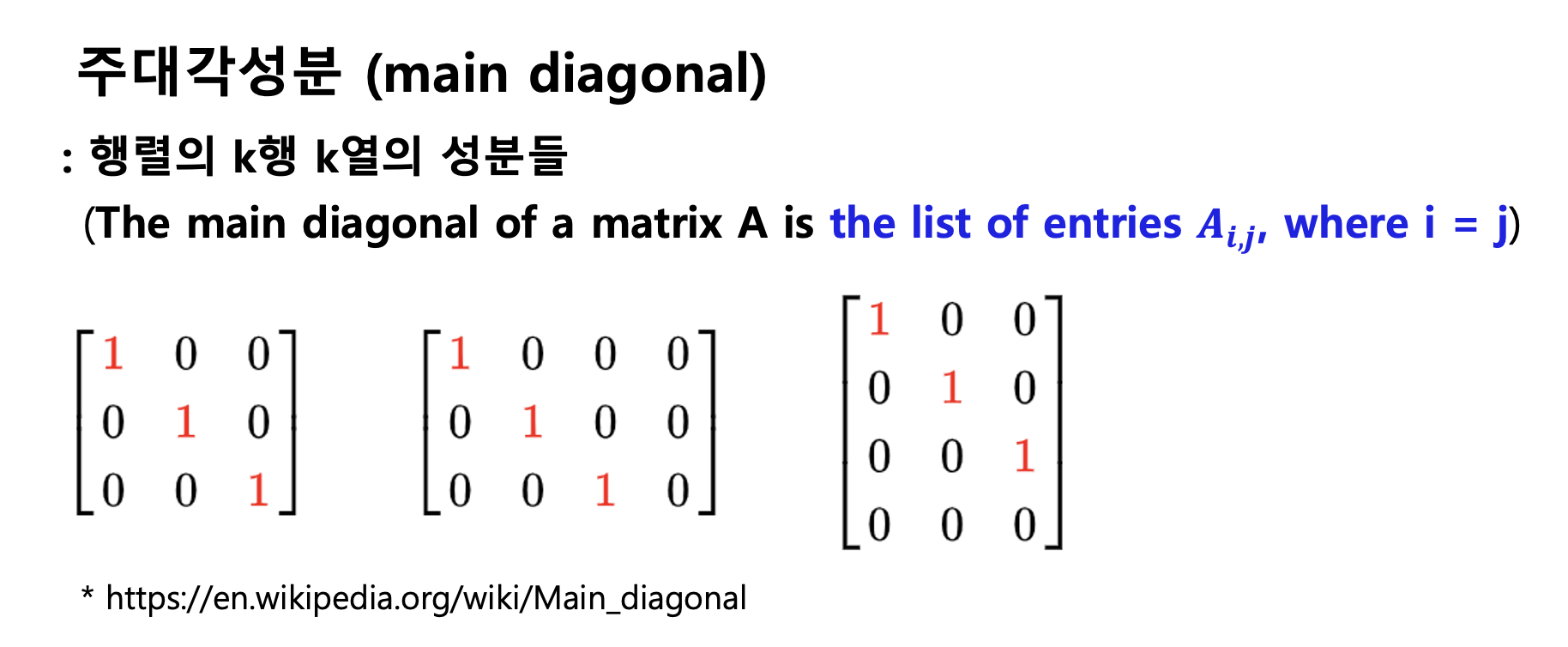
(1) scipy.spatial.distance.pdist(): returns condensed distance matrix Y.
(2) scipy.spatial.distance.cdist(): returns M by N distance matrix.
(3) 거리 측정 기준(distance metric)

먼저, 예제로 사용할 간단한 샘플 데이터셋으로서 x와 y의 두 개의 칼럼에 대해 4개의 원소를 가지는 numpy array 로 만들어보겠습니다. 그리고 matplotlib 으로 산점도를 그려서 4개의 원소에 대해 x와 y의 좌표에 산점도를 그려서 확인해보겠습니다.
| ID | x | y |
| 1 | 3 | 2 |
| 2 | 3 | 3 |
| 3 | 5 | 5 |
| 4 | 6 | 7 |
import numpy as np
import matplotlib.pyplot as plt
X = np.array([
# x, y
[3, 2], # ID 1
[3, 3], # ID 2
[5, 5], # ID 3
[6, 7], # ID 4
])
plt.plot(X[:, 0], X[:, 1], 'o')
plt.show()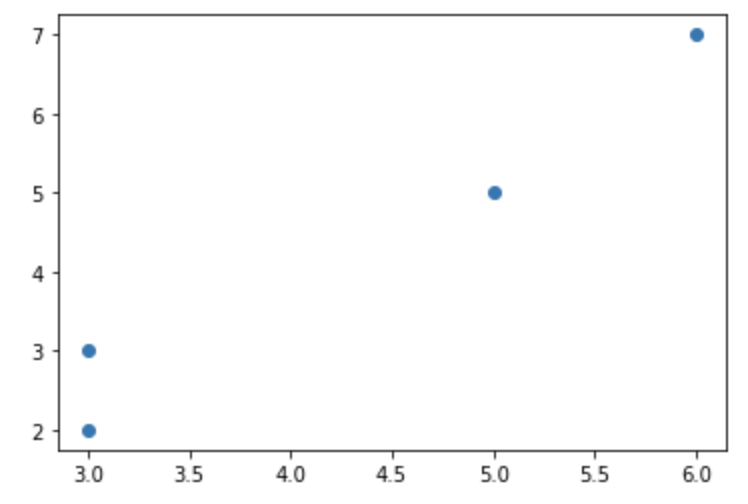
(1) scipy.spatial.distance.pdist(X, metric='euclidean'): returns condensed distance matrix Y.
scipy.spatial.distance.pdist(X, metric='euclidean') 함수는 X 벡터 또는 행렬에서 각 원소(관측치) 간 짝을 이루어서 유클리디언 거리를 계산해줍니다. 그리고 응축된 형태의 거리 행렬(condensed distance matrix)을 반환합니다. 아래의 (1)번 pdist() 계산 결과가 반환된 형태를 (2) cdist() 로 계산 결과가 반환된 형태와 비교해보면 이해가 쉬울 거예요.
pdist(X, metric='eudlidean') 계산 결과는 각 관측치 간 짝을 이룬 거리 계산이므로 아래 값들의 계산 결과입니다. 거리 계산 결과는 자기 자신과의 거리인 대각행렬 부분은 제외하고, 각 원소 간 쌍을 이룬 부분에 대해서만 관측치의 순서에 따라서 반환되었습니다. (예: ID1 : ID2, ID1 : ID3, ID1 : ID4, ID2 : ID3, ID2 : ID4, ID3 : ID4)
* DISTANCE_euclidean(ID 1, ID 2) = sqrt((3-3)^2 + (2-3)^2) = 1.00
* DISTANCE_euclidean(ID 1, ID 3) = sqrt((3-5)^2 + (2-5)^2) = 3.60
* DISTANCE_euclidean(ID 1, ID 4) = sqrt((3-6)^2 - (2-7)^2) = 5.83
* DISTANCE_euclidean(ID 2, ID 3) = sqrt((3-5)^2 - (3-5)^2) = 2.82
* DISTANCE_euclidean(ID 2, ID 4) = sqrt((3-6)^2 - (3-7)^2) = 5.00
* DISTANCE_euclidean(ID 3, ID 4) = sqrt((5-6)^2 - (5-7)^2) = 2.23
# scipy.spatial.distance.pdist(X, metric='euclidean', *, out=None, **kwargs)
# : Pairwise distances between observations in n-dimensional space.
# : Returns a condensed distance matrix Y.
from scipy.spatial import distance
X_pdist = distance.pdist(X, metric='euclidean')
X_pdist
# array([1. , 3.60555128, 5.83095189, 2.82842712, 5. ,
# 2.23606798])
(2) scipy.spatial.distance.cdist(): returns M by N distance matrix.
scipy.spatial.distance.cdist(XA, XB, metric='euclidean') 함수는 원소(관측치) 간 쌍을 이루어 유클리디언 거리를 계산합니다만, 위의 (1) pdist() 함수와는 달리,
- (a) input 으로 XA, XB 의 두 개의 행렬 (혹은 벡터)를 받으며, (vs. pdist() 는 X 행렬 한 개만 받음)
- (b) output 으로 M by N 거리 행렬을 반환합니다. (vs. pdist() 는 condensed distance matrix 를 반환)
하는 차이점이 있습니다. 위의 (1)번 scipy.spatial.distance.pdist() 함수와 (2) scipy.spatial.distance.cdist() 함수의 input, output을 비교해보면 이해가 쉬울 거예요.
# scipy.spatial.distance.cdist(XA, XB, metric='euclidean', *, out=None, **kwargs)
# : Compute distance between each pair of the two collections of inputs.
# : A M by N distance matrix is returned.(M for X, N for Y)
from scipy.spatial import distance
X_cdist = distance.cdist(X, X, metric='euclidean')
X_cdist
# array([[0. , 1. , 5.83095189, 3.60555128],
# [1. , 0. , 5. , 2.82842712],
# [5.83095189, 5. , 0. , 2.23606798],
# [3.60555128, 2.82842712, 2.23606798, 0. ]])
(3) 거리 측정 기준(distance metric)
위의 (1), (2)번에서는 거리 측정 기준으로 디폴트 옵션인 '유클리디언 거리(metric='euclidean distance') 를 사용해서 원소 간 쌍을 이룬 거리를 계산하였습니다.
scipy 모듈은 유클리디어 거리 외에도 다양한 거리 측정 기준을 제공합니다. (맨하탄 거리, 표준화 거리, 마할라노비스 거리, 자카드 거리, 코사인 거리, 편집 거리에 대해서는 아래의 Reference 의 링크를 참고하세요.)
[ scipy.spatial.distance.pdist(), cdist() 함수의 metric options (알파벳 순서) ]
‘braycurtis’, ‘canberra’, ‘chebyshev’, ‘cityblock’, ‘correlation’, ‘cosine’, ‘dice’, ‘euclidean’, ‘hamming’, ‘jaccard’, ‘jensenshannon’, ‘kulsinski’, ‘kulczynski1’, ‘mahalanobis’, ‘matching’, ‘minkowski’, ‘rogerstanimoto’, ‘russellrao’, ‘seuclidean’, ‘sokalmichener’, ‘sokalsneath’, ‘sqeuclidean’, ‘yule’.
아래에는 metric='cityblcok' 매개변수 설정을 통해서 '맨하탄 거리(Manhattan distance)'를 계산하여 보았습니다. cdist() 함수를 사용하였으므로 4 by 4 행렬의 형태로 관측치 간 쌍을 이룬 거리 계산 결과를 반환합니다.
* DISTANCE_manhattan(ID 1, ID 2) = |3-3|+|2-3| = 1
* DISTANCE_manhattan(ID 1, ID 3) = |3-5|+|2-5| = 5
* DISTANCE_manhattan(ID 1, ID 4) = |3-6|+|2-7| = 8
* DISTANCE_manhattan(ID 2, ID 3) = |3-5|+|3-5| = 4
* DISTANCE_manhattan(ID 2, ID 4) = |3-6|+|3-7| = 7
* DISTANCE_manhattan(ID 3, ID 4) = |5-6|+|5-7| = 3
X
# array([[3, 2],
# [3, 3],
# [5, 5],
# [6, 7]])
## Manhattan Distance
from scipy.spatial import distance
X_cdist_cityblock = distance.cdist(X, X, metric='cityblock')
X_cdist_cityblock
# array([[0., 1., 5., 8.],
# [1., 0., 4., 7.],
# [5., 4., 0., 3.],
# [8., 7., 3., 0.]])
[ Reference ]
[1] scipy.spatial.distance.pdist
: https://docs.scipy.org/doc/scipy/reference/generated/scipy.spatial.distance.pdist.html#scipy.spatial.distance.pdist
[2] scipy.spatial.distance.cdist
: https://docs.scipy.org/doc/scipy/reference/generated/scipy.spatial.distance.cdist.html#scipy.spatial.distance.cdist
[3] 맨하탄 거리(Manhattan distance), 유클리드 거리(Euclidean distance), 표준화 거리(), 마할라노비스 거리
: https://rfriend.tistory.com/199
[4] 자카드 거리 (Jaccard distance): https://rfriend.tistory.com/318
[5] 코사인 거리 (cosine distance): https://rfriend.tistory.com/319
[6] 편집거리 (edit distance, Levenshtein metric): https://rfriend.tistory.com/320
이번 포스팅이 많은 도움이 되었기를 바랍니다.
행복한 데이터 과학자 되세요! :-)