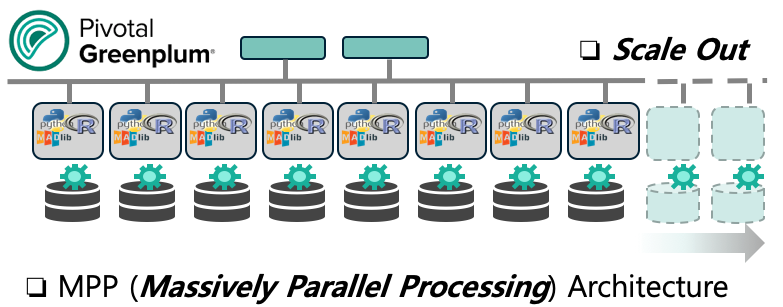
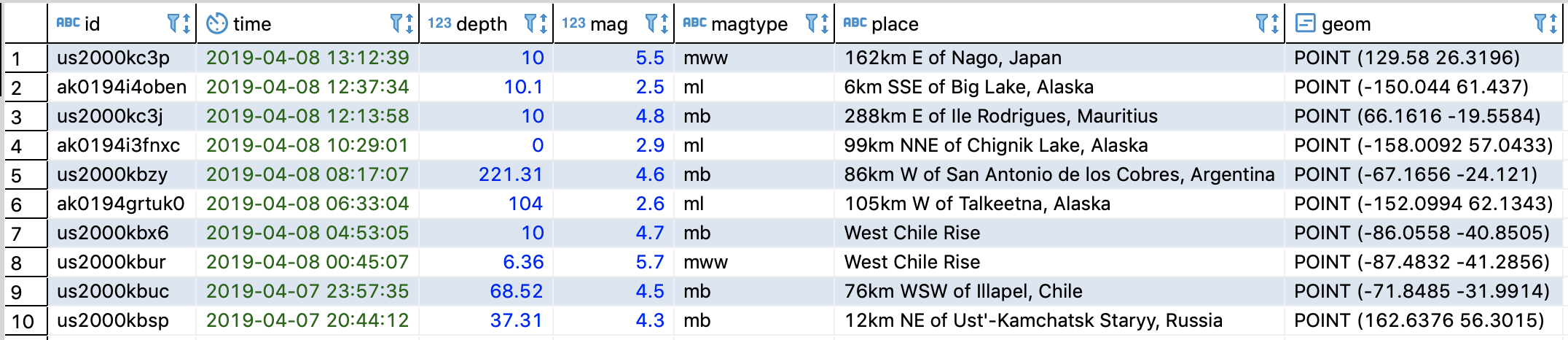
만약 한개 당 1분 걸리는 동일한 프로세스의 100개의 일을 한 명이서 한다면 100분이 걸릴텐데요, 이것을 100명에게 일을 1개씩 나누어서 동시에 분산해서 시킨다면 1분(+취합하는 시간 약간) 밖에 안걸릴 것입니다. 1명이 100명을 이길 수는 없기 때문입니다.
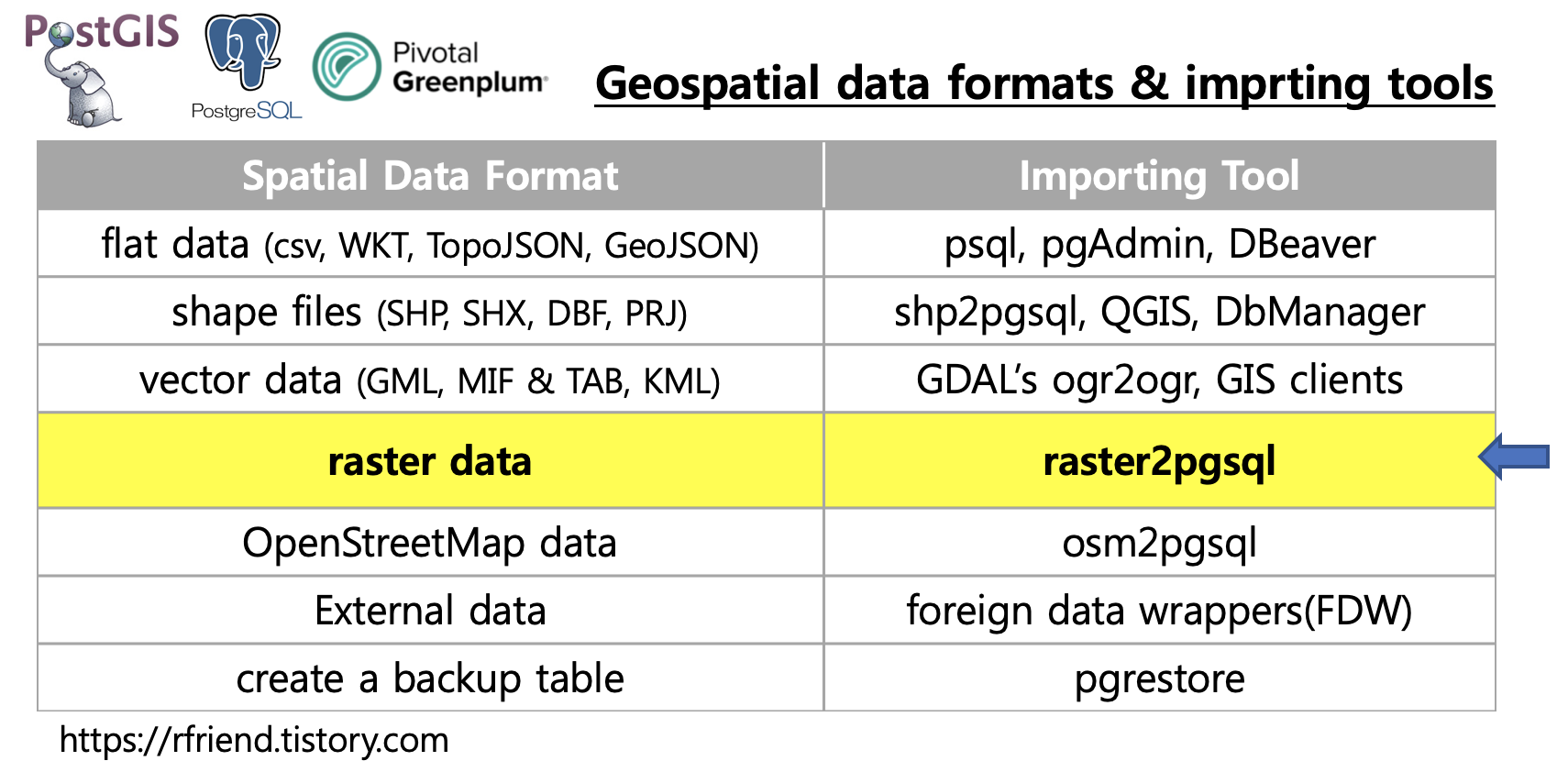
대용량 데이터에 대해서 빠른 성능으로 통계나 기계학습의 고급 분석을 처리해야 하는 경우라면 Greenplum 과 같은 MPP (Massively Parallel Processing) 아키텍처 기반의 DB에서 R 이나 Python 언어로 작성한 알고리즘을 In-DB에서 PL/R, PL/Python을 사용해서 분산 병렬 처리할 수 있습니다.
이번 포스팅에서는 Greenplum DB에서 PL/R (Procedural Language R) 을 사용해서 분산 병렬처리(distributed parallel processing하여 그룹별로 선형회귀모형을 각각 적합하고 예측하는 방법을 소개하겠습니다. 모든 연산이 In-DB 에서 일어나기 때문에 데이터 I/O 가 없으므로 I/O 시간을 절약하고 architecture 와 workflow를 간단하게 가져갈 수 있는 장점도 있습니다. (vs. DB 에서 local R 로 데이터 말아서 내리고, local R로 모형 적합 / 예측 후, 이 결과를 다시 DB에 insert 하고 하는 복잡한 절차가 필요 없음)

이번에 소개할 간단한 예제로 사용할 데이터셋은 abalone 공개 데이터셋으로서, 성 (sex) 별로 구분하여 무게(shucked_weight)와 지름(diameter) 설명변수를 input으로 하여 껍질의 고리 개수(rings)를 추정하는 선형회귀모형을 적합하고, 예측하는 문제입니다.
이러한 일을 성별 F, M, I 별로 순차적으로 하는 것이 아니라, Greenplum DB 에서 성별 F, M, I 별로 PL/R로 분산 병렬처리하여 동시에 수행하는 방법입니다.
(1) abalone 데이터셋으로 테이블 만들기 |
먼저, abalone 데이터셋을 공개 데이터셋 웹사이트에서 가져와서 External table을 만들고, 이로부터 abalone table 을 생성해보겠습니다.
--------------------------------- -- Linear Regression in Parallel -- using PL/R --------------------------------- -- Dataset for example: abalone dataset from the UC Irvine Machine Learning Repository -- url: http://archive.ics.uci.edu/ml/machine-learning-databases/abalone/abalone.data -- Create an external web table DROP EXTERNAL TABLE IF EXISTS abalone_external; CREATE EXTERNAL WEB TABLE abalone_external( sex text , length float8 , diameter float8 , height float8 , whole_weight float8 , shucked_weight float8 , viscera_weight float8 , shell_weight float8 , rings integer -- target variable to predict ) LOCATION('http://archive.ics.uci.edu/ml/machine-learning-databases/abalone/abalone.data') FORMAT 'CSV' (null as '?'); -- Create a table of abalone DROP TABLE IF EXISTS abalone; CREATE TABLE abalone AS SELECT * FROM abalone_external DISTRIBUTED BY (sex); -- Viewing data distribution SELECT gp_segment_id, COUNT(*) AS row_cnt FROM abalone GROUP BY gp_segment_id; -- Check data SELECT * FROM abalone LIMIT 5; |


(2) Train, Test set 테이블 분할 (train, test set split) |
다음으로 MADlib(https://madlib.apache.org/) 의 madlib.train_test_split() 함수를 사용해서 abalone 원 테이블을 train set, test set 테이블로 분할(split into train and test set) 해보겠습니다.
--------------------------- -- Train, Test set split --------------------------- -- Check the number of observations per sex group(F, I, M) -- Train, Test set split DROP TABLE IF EXISTS out_train, out_test; SELECT madlib.train_test_split( 'abalone', -- Source table 'out', -- Output table 0.8, -- train_proportion NULL, -- Default = 1 - train_proportion = 0.5 'sex', -- Strata definition 'rings, shucked_weight, diameter', -- Columns to output FALSE, -- Sample with replacement TRUE); -- Separate output tables SELECT * FROM out_train LIMIT 5; SELECT sex, count(*) FROM out_train GROUP BY sex; SELECT sex, count(*) FROM out_test GROUP BY sex; |




(3) array aggregation 하여 PL/R에서 사용할 데이터셋 준비하기 |
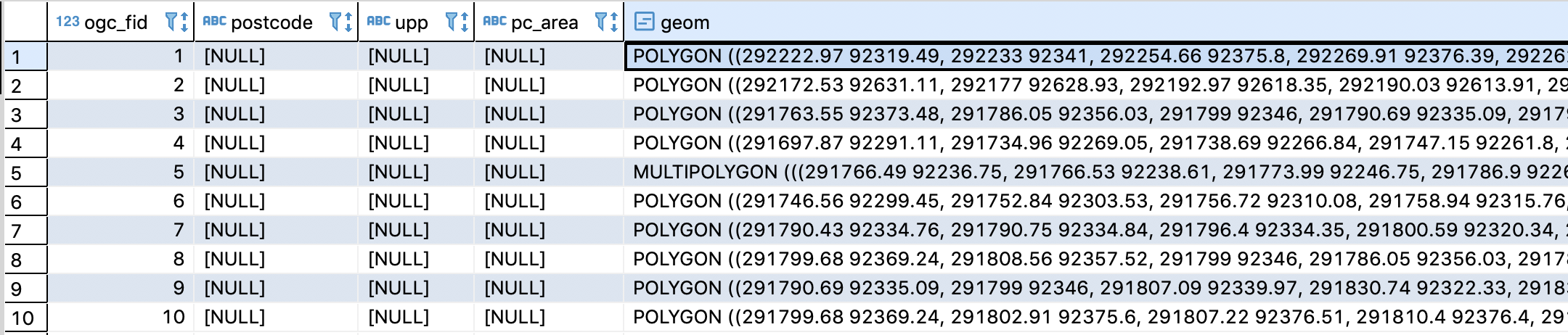
좀 낯설을 수도 있는데요, PL/R 에서는 array 를 input으로 받으므로 array_agg() 함수를 사용해서 설명변수를 칼럼별로 array aggregation 해줍니다. 이때 성별(sex) 로 모형을 각각 병렬로 적합할 것이므로 group by sex 로 해서 성별로 따로 따로 array aggregation 을 해줍니다. 이렇게 해주면 long format으로 여러개의 열(row)에 들어있던 값들이 성별로 구분이 되어서 하나의 array( { } )에 모두 들어가게 됩니다. (아래 이미지 참조)
-- Data Preparation -- : array aggregation using array_agg() DROP TABLE IF EXISTS abalone_array; CREATE TABLE abalone_array AS SELECT sex::text -- group , array_agg(rings::float8) as rings -- y , array_agg(shucked_weight::float8) as s_weight -- x1 , array_agg(diameter::float8) as diameter -- x2 FROM out_train GROUP BY sex DISTRIBUTED BY (sex); SELECT * FROM abalone_array; |


(4) 선형회귀모형 적합하는 PL/R 사용자 정의 함수 정의하기 (Define PL/R UDF) |
선형회귀모형 PL/R 의 반환받는 값을 두가지 유형으로 나누어서 각각 소개하겠습니다.
(4-1) 적합된 회귀모형의 회귀계수 (coefficients) 를 반환하기
(4-2) 적합된 회귀모형 자체(fitted model itself)를 반환하기
먼저, (4-1) 적합된 회귀모형의 회귀계수를 반환하는 PL/R 함수를 정의하는 방법을 소개하겠습니다.
R의 lm() 함수를 사용하여 다중 선형회귀모형을 적합(fit a model)하면, summary(fitted_model)$coef 는 추정된 회귀계수(coef_est), 표준오차(std_error), T통계량(t_stat), P-값 (p_value) 를 반환합니다.
CREATE OR REPLAE FUNCTION pl_r_funtion_name(column_name data_type[], ...) 으로 PL/R 함수 이름과 인자로 받는 칼럼 이름, 데이터 유형을 정의해주고,
이들 모형 적합 후의 추정된 회귀계수와 통계량을 Greenplum DB에 반환하려면 데이터 유형이 여러개이므로 composit type 을 별도로 정의('lm_abalone_type')해주어고, PL/R 사용자 정의함수에서 returns setof lm_abalone_type 처럼 써주면 됩니다.
그 다음에, $$ pure R codes block $$ LANGUAGE 'plr' 형식으로 R codes 를 통째로 $$ ~~~~ $$ 안에 넣어주면 됩니다.
---------------------------------------------------------------- -- (4-1) PL/R : Linear Regression Model's Coefficients --> Predict ---------------------------------------------------------------- -- Return Types DROP TYPE IF EXISTS lm_abalone_type CASCADE; CREATE TYPE lm_abalone_type AS ( variable text , coef_est float , std_error float , t_stat float , p_value float ); -- PL/R User Defined Function DROP FUNCTION IF EXISTS plr_lm_train(float8[], float8[], float8[]); CREATE OR REPLACE FUNCTION plr_lm_train( rings float8[] , s_weight float8[] , diameter float8[] ) RETURNS SETOF lm_abalone_type AS $$ m1 <- lm(rings ~ s_weight + diameter) m1_s <- summary(m1)$coef temp_m1 <- data.frame(rownames(m1_s), m1_s) return(temp_m1) $$ LANGUAGE 'plr';
|
(5) PL/R 실행하기 (execute PL/R UDF in Greenplum DB) |
위의 (4)에서 정의한 성별(per sex) 선형회귀모형을 적합하여 회귀계수와 통계량을 반환하는 PL/R 사용자 정의함수를 Greenplum DB 안에서 병렬처리하여 실행해보겠습니다.
select sex, (plr_lm_train(rings, s_weight, diameter)).* from abalone_array 처럼 위의 (4)번에서 정의한 PL/R 함수에 (3)번에서 준비한 array 가 들어있는 테이블의 칼럼을 써주고, from 절에 array 테이블 이름을 써주면 됩니다.
이때 테이블에 return 받는 값들이 composit type의 여러개 칼럼들이므로 (plr_udf(column, ...)).* 처럼 PL/R 함수를 괄호 ( ) 로 싸주고 끝에 '*' (asterisk) 를 붙여줍니다. ( * 를 빼먹으면 여러개의 칼럼별로 나누어지지 않고 한개의 칼럼에 튜플로 모든 칼럼이 뭉쳐서 들어갑니다)
-- Execution of Linear Regression PL/R DROP TABLE IF EXISTS lm_abalone_model_coef; CREATE TABLE lm_abalone_model_coef AS ( SELECT sex, (plr_lm_train(rings, s_weight, diameter)).* FROM abalone_array ) DISTRIBUTED BY (sex); SELECT * FROM lm_abalone_model_coef; |

(6) 적합한 선형회귀모형을 사용해 test set에 대해 예측하기 (prediction on test set) |
위의 (5)번에서 적합한 성별 선형회귀모형들의 회귀계수 (coefficients per sex groups) 를 사용해서 test set 의 데이터셋에 대해 PL/R 함수로 분산 병렬처리하여 rings 값을 예측해보겠습니다. (training 도 분산병렬처리, prediction/ scoring 도 역시 분산병렬처리!)
먼저, 예측하는 PL/R 함수에 넣어줄 test set을 array aggregation 해줍니다.
다음으로, ID별로 실제값(actual rings)과 예측한 값(predicted rings)을 반환받을 수 있도록 composite type 을 정의해줍니다.
그 다음엔 추정된 회귀계수를 사용해서 예측할 수 있도록 행렬 곱 연산을 하는 PL/R 함수(plr_lm_coef_predict())를 정의해줍니다.
마지막으로 예측하는 PL/R 함수를 실행해줍니다.
------------------------------------------------ -- Prediction and Model Evaluation for Test set ------------------------------------------------ -- Preparation of test set in aggregated array DROP TABLE IF EXISTS test_array; CREATE TABLE test_array AS SELECT sex::text , array_agg(rings::float8) as rings -- y , array_agg(shucked_weight::float8) as s_weight -- x1 , array_agg(diameter::float8) as diameter --x2 FROM out_test GROUP BY sex DISTRIBUTED BY (sex); SELECT * FROM test_array; -- Define composite data type for predicted return values DROP TYPE IF EXISTS lm_predicted_type CASCADE; CREATE TYPE lm_predicted_type AS ( id int , actual float , pred float ); -- Define PL/R UDF of prediction per groups using linear regression coefficients DROP FUNCTION IF EXISTS plr_lm_coef_predict(float8[], float8[], float8[], float8[]); CREATE OR REPLACE FUNCTION plr_lm_coef_predict( rings float8[] , s_weight float8[] , diameter float8[] , coef_est float8[] ) RETURNS SETOF lm_predicted_type AS $$ actual <- rings # y intercept <- 1 X <- cbind(intercept, s_weight, diameter) # X matrix coef_est <- matrix(coef_est) # coefficients matrix predicted <- X %*% coef_est # matrix multiplication df_actual_pred <- data.frame(actual, predicted) id <- as.numeric(rownames(df_actual_pred)) return(data.frame(id, df_actual_pred)) $$ LANGUAGE 'plr'; -- Execute PL/R Prediction UDF DROP TABLE IF EXISTS out_coef_predict; CREATE TABLE out_coef_predict AS ( SELECT sex, (plr_lm_coef_predict(c.rings, c.s_weight, c.diameter, c.coef_est)).* FROM ( SELECT a.*, b.coef_est FROM test_array a, (SELECT sex, array_agg(coef_est) AS coef_est FROM lm_abalone_model_coef GROUP BY sex) b WHERE a.sex = b.sex ) c ) DISTRIBUTED BY (sex); -- Compare 'actual' vs. 'predicted' SELECT * FROM out_coef_predict WHERE sex = 'F' ORDER BY sex, id LIMIT 10; |


(7) 회귀모형 자체를 Serialize 해서 DB에 저장하고, Unserialize 해서 예측하기 |
위의 (4)번~(6번) 까지는 적합된 회귀모형의 회귀계수와 통계량을 반환하고, 이를 이용해 예측을 해보았다면, 이번에는
- (4-2) 적합된 회귀모형 자체(model itself)를 Serialize 하여 DB에 저장하고 (인코딩),
- 이를 DB에서 읽어와서 Unserialize 한 후 (디코딩), 예측하기
- 단, 이때 예측값의 95% 신뢰구간 (95% confidence interval) 도 같이 반환하기
를 해보겠습니다.
-------------------------------------------------------------------- -- (2) PL/R : Linear Model --> Serialize --> Deserialize --> Predict -------------------------------------------------------------------- -- PL/R User Defined Function Definition DROP FUNCTION IF EXISTS plr_lm_model(float8[], float8[], float8[]); CREATE OR REPLACE FUNCTION plr_lm_model( rings float8[] , s_weight float8[] , diameter float8[] ) RETURNS bytea -- serialized model as a byte array AS $$ lr_model <- lm(rings ~ s_weight + diameter) return (serialize(lr_model, NULL)) $$ LANGUAGE 'plr'; -- Execution of Linear Regression PL/R DROP TABLE IF EXISTS lm_abalone_model; CREATE TABLE lm_abalone_model AS ( SELECT sex, plr_lm_model(rings, s_weight, diameter) AS serialized_model FROM abalone_array ) DISTRIBUTED BY (sex); -- We can not read serialized model SELECT * FROM lm_abalone_model; DROP TYPE IF EXISTS lm_predicted_interval_type CASCADE; CREATE TYPE lm_predicted_interval_type AS ( id int , actual float , pred float , lwr float , upr float ); -- PL/R function to read a serialized PL/R model DROP FUNCTION IF EXISTS plr_lm_model_predict(float8[], float8[], float8[], bytea); CREATE OR REPLACE FUNCTION plr_lm_model_predict( rings float8[] , s_weight float8[] , diameter float8[] , serialized_model bytea ) RETURNS SETOF lm_predicted_interval_type AS $$ model <- unserialize(serialized_model) actual <- rings # y X <- data.frame(s_weight, diameter) # new data X predicted <- predict(model, newdata = X, interval = "confidence") df_actual_pred <- data.frame(actual, predicted) id <- as.numeric(rownames(df_actual_pred)) return (data.frame(id, df_actual_pred)) $$ LANGUAGE 'plr'; -- Predict DROP TABLE IF EXISTS out_model_predict; CREATE TABLE out_model_predict AS ( SELECT sex, (plr_lm_model_predict(c.rings, c.s_weight, c.diameter, c.serialized_model)).* FROM ( SELECT a.*, b.serialized_model FROM test_array a, lm_abalone_model b WHERE a.sex = b.sex ) c ) DISTRIBUTED BY (sex); SELECT * FROM out_model_predict WHERE sex = 'F' ORDER BY sex, id LIMIT 10; |


[Greenplum & PostgreSQL] MADlib 을 활용한 그룹별 선형회귀모형 분산병렬 적합 및 예측은 https://rfriend.tistory.com/533 를 참고하세요.
[References]
Reference of PL/R on Greenplum: https://pivotalsoftware.github.io/gp-r/
PL/R - R PROCEDURAL LANGUAGE FOR POSTGRESQL by Joseph E Conway : http://joeconway.com/plr.html
Pivotal Greenplum PL/R Language Extension 설치 : https://gpdb.docs.pivotal.io/530/ref_guide/extensions/pl_r.html
Greenplum 5에 PL/R 설치 및 R 패키지 수동 설치
: https://rfriend.tistory.com/442Greenplum 6에 PL/R 설치 및 R 버전 업그레이트 : http://gpdbkr.blogspot.com/2019/12/greenplum-6-plr-r.html
Apache MADlib 설치 및 사용 매뉴얼: https://madlib.apache.org/
많은 도움이 되었기를 바랍니다.
이번 포스팅이 도움이 되었다면 아래의 '공감~ '를 꾹 눌러주세요.
'를 꾹 눌러주세요.


















 Pivotal_Graph_Analytics_w_MADlib_GPDB_20190130.pdf
Pivotal_Graph_Analytics_w_MADlib_GPDB_20190130.pdf






 graph_pagerank_madlib.sql
graph_pagerank_madlib.sql