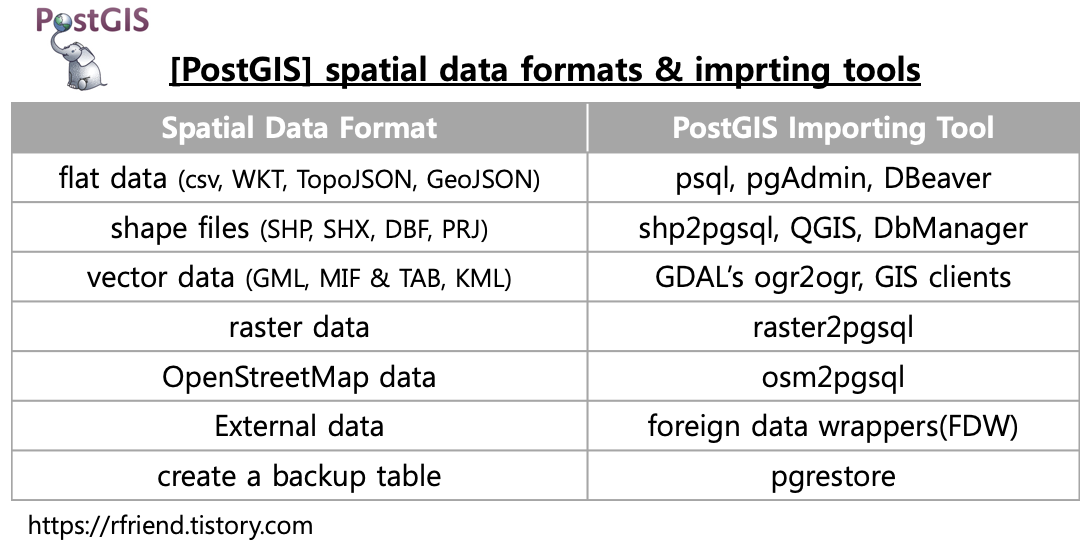
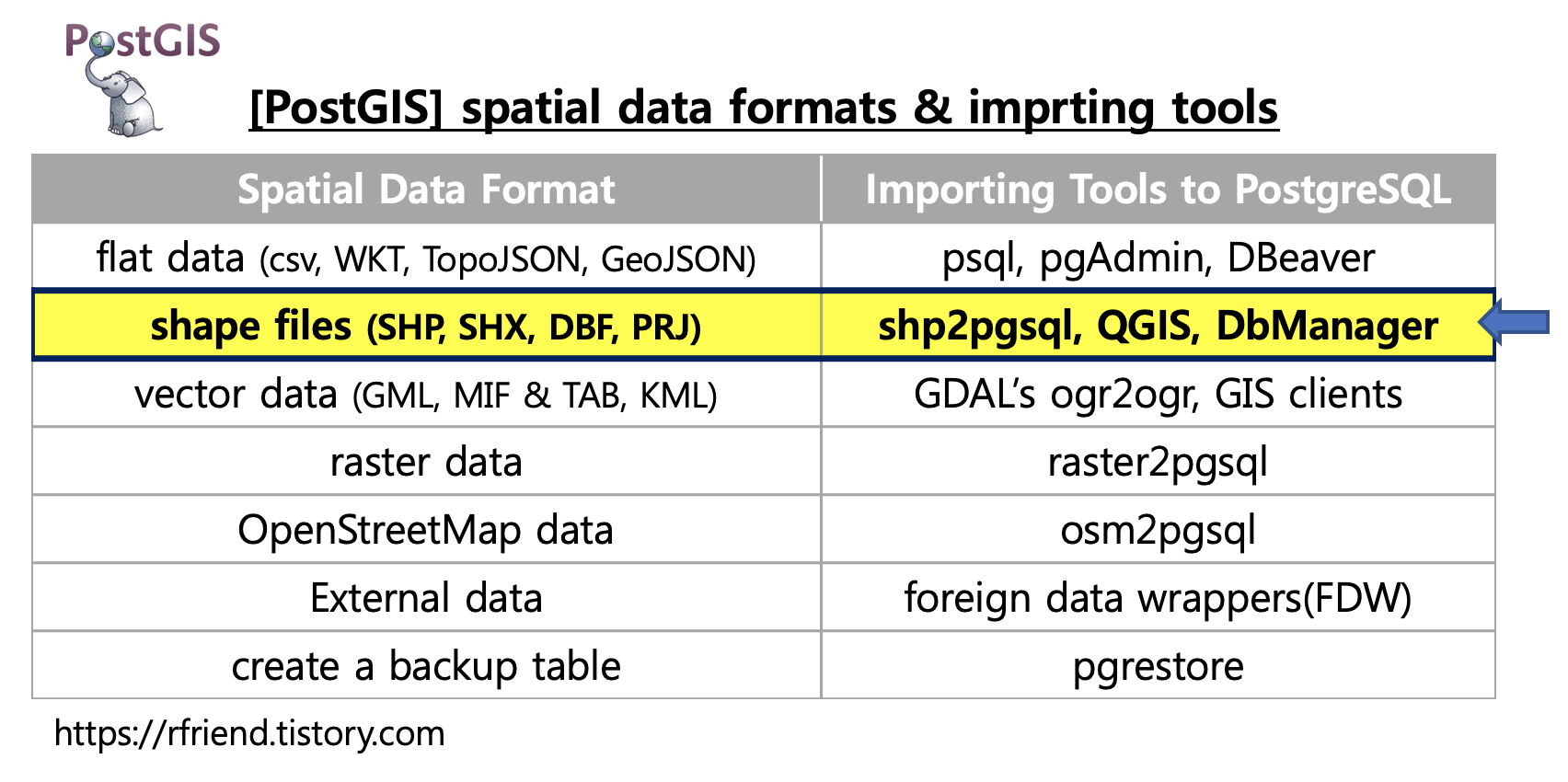
[Greenplum DB] 공간지리 shape files (SHP, SHX, DBF, PRJ)를 PostgreSQL, Greenplum DB로 import 하는 방법
Greenplum and PostgreSQL Database 2019. 4. 11. 00:41이번 포스팅에서는 공간지리 데이터 포맷 중에서 SHP, SHX, DBF, PRJ 로 이루어진 shape files 를 shp2pgsql 툴을 사용하여 PostgreSQL, Greenplum DB로 importing 하는 방법을 소개하겠습니다.
PostgreSQL을 설치하였다면 바로 shp2pgsql 툴을 사용할 수 있습니다.
예제 데이터셋은 https://github.com/PacktPublishing/Mastering-PostGIS/tree/master/Chapter01/data/ne_110m_coastline 에서 다운로드한 'ne_110m_coastline.shp', 'ne_110m_coastline.shx', 'ne_110m_coastline.dbf', 'ne_110m_coastline.prj' 의 4개 파일을 사용하였으며, 코드는 'Mastering PostGIS' (by Dominik Mikiewicz 외)를 참조하였습니다.
shp2pgsql 은 (1) shapefile data를 import하는 SQL문을 만들어주고, (2) shapefile data를 import하는 SQL문을 바로 psql로 보내서 import 해주는 command-line utility 입니다. 말이 좀 어려운데요, 아래 예제를 직접 보면 이해가 쉬울 듯 합니다.
Greenplum DB Docker 이미지에 PostGIS 설치해서 Greenplum 시작하는 방법은 https://rfriend.tistory.com/435 를 참고하세요.
(1) shp2pgsql로 shapefile data를 import하는 SQL문 만들기 |
먼저, 명령 프롬프트 창에서 'ne_110m_coastline.shp', 'ne_110m_coastline.shx', 'ne_110m_coastline.dbf', 'ne_110m_coastline.prj'의 4개 shape files 를 docker cp 명령문을 사용하여 Greenplum docker의 gpdb-ds:/tmp 폴더로 복사하겠습니다. (만약 VMware를 이용해서 Greenplum DB를 설치해서 사용 중이라면 scp 명령문으로 GPDB 안으로 파일 복사)
|
-- (1) 명령 프롬프트 창에서 shape files 를 docker gpdb-ds:/tmp 경로로 복사 ihongdon-ui-MacBook-Pro:~ ihongdon$ ihongdon-ui-MacBook-Pro:~ ihongdon$ cd /Users/ihongdon/Documents/PostGIS/data/ne_110m_coastline/ ihongdon-ui-MacBook-Pro:ne_110m_coastline ihongdon$ ls ne_110m_coastline.dbf ne_110m_coastline.prj ne_110m_coastline.shp ne_110m_coastline.shx ihongdon-ui-MacBook-Pro:ne_110m_coastline ihongdon$ ihongdon-ui-MacBook-Pro:ne_110m_coastline ihongdon$ ihongdon-ui-MacBook-Pro:ne_110m_coastline ihongdon$ docker cp ihongdon-ui-MacBook-Pro:ne_110m_coastline ihongdon$ docker cp ihongdon-ui-MacBook-Pro:ne_110m_coastline ihongdon$ docker cp ihongdon-ui-MacBook-Pro:ne_110m_coastline ihongdon$ docker cp |
다른 명령 프롬프트 창에서 GPDB에 4개의 shape files 이 잘 들어갔는지 확인해보겠습니다.
|
[gpadmin@mdw /]$ [gpadmin@mdw /]$ cd tmp [gpadmin@mdw tmp]$ ls -la total 123532 drwxrwxrwt 1 root root 4096 Apr 10 13:13 . drwxr-xr-x 1 root root 4096 Apr 9 07:11 .. drwxrwxrwt 2 root root 4096 Sep 11 2017 .ICE-unix drwxrwxrwt 2 root root 4096 Sep 11 2017 .Test-unix drwxrwxrwt 2 root root 4096 Sep 11 2017 .X11-unix drwxrwxrwt 2 root root 4096 Sep 11 2017 .XIM-unix drwxrwxrwt 2 root root 4096 Sep 11 2017 .font-unix -rw-r--r-- 1 501 games 3179 Apr 8 06:02 ne_110m_coastline.dbf -rw-r--r-- 1 501 games 147 Apr 8 06:03 ne_110m_coastline.prj -rw-r--r-- 1 501 games 89652 Apr 8 06:03 ne_110m_coastline.shp -rw-r--r-- 1 501 games 1172 Apr 8 06:04 ne_110m_coastline.shx [gpadmin@mdw tmp]$ |
이제 shp2pgsql 유틸리티를 이용해서 data_import.ne_110m_coastline.sql 라는 이름의 ne_coastline shape files 를 import 하는 SQL 문을 만들어보겠습니다.
|
-- (2) 명령 프롬프트 창 docker gpdb-ds의 gpadmin@mdw 에서 shp2pgsql 실행하여 sql 생성 [gpadmin@mdw tmp]$ shp2pgsql -s 4326 ne_110m_coastline data_import.ne_coastline > data_import.ne_coastline.sql Shapefile type: Arc Postgis type: MULTILINESTRING[2] [gpadmin@mdw tmp]$ [gpadmin@mdw tmp]$ ls -la |
다른 명령 프롬프트 창에서 docker GPDB에 만들어진 data_import.ne_coastline.sql 파일을 로컬로 복사해서 SQL 문이 어떻게 생겼는지 눈으로 확인을 해보겠습니다. 아래에 보는 바와 같이 CREATE TABLE "data_import"."ne_coastline" (gid serial, scalerank numeric(10,0), featurecla varchar(12)); ALTER TABLE data_import.ne_coastline ADD PRIMARY KEY (gid); SELECT AddGeometryColumn(data_import.ne_coastline, geom, 4326, MULTILINESTRING, 2); INSERT INTO data_import.ne_coastline VALUES (); 와 같이 우리가 이미 알고 있는 테이블 생성과 데이터 삽입 표준 SQL query 문이 자동으로 만들어졌음을 확인할 수 있습니다. 이 SQL 문을 실행하면 테이블 생성부터 데이터 importing까지 일괄로 수행이 됩니다.
* SQL 파일 첨부 :
|
-- (3) (optional) 다른 명령 프롬프트 창에서 gpdb-ds:/tmp/data_import.ne_coastline.sql 를 docker gpdb에서 밖으로 복사하여 sql query 확인해 보기 ihongdon-ui-MacBook-Pro:ne_110m_coastline ihongdon$ docker cp gpdb-ds:/tmp/data_import.ne_coastline.sql /Users/ihongdon/Documents/PostGIS/data/ne_110m_coastline/ ihongdon-ui-MacBook-Pro:ne_110m_coastline ihongdon$
-- sql query문을 열어서 확인해보면 아래와 같음 SET CLIENT_ENCODING TO UTF8; SET STANDARD_CONFORMING_STRINGS TO ON; BEGIN; CREATE TABLE "data_import"."ne_coastline" (gid serial, "scalerank" numeric(10,0), "featurecla" varchar(12)); ALTER TABLE "data_import"."ne_coastline" ADD PRIMARY KEY (gid); SELECT AddGeometryColumn('data_import','ne_coastline','geom','4326','MULTILINESTRING',2); INSERT INTO "data_import"."ne_coastline" ("scalerank","featurecla",geom) VALUES ('1','Coastline','0105000020E61000000100000001020000000B000000BFA9980AD07664C095CA366A1FA653C04B24ADB8626364C0700E7B2E4B8E53C03EE93FF8D72764C0BF309DD0549853C02960B7EFE00764C02CDFE4B164AC53C07CB8A9DB6FEF63C08FDFE431F7C253C0A4D39170A9E663C089F492F9CEDF53C09E264A4F152464C0165BF9DF96E853C0FB978739134E64C026353A8703D253C01A655486E06064C0C3343A0771BB53C0B2C4809F216264C0974C8585ADB753C0BFA9980AD07664C095CA366A1FA653C0'); INSERT INTO "data_import"."ne_coastline" ("scalerank","featurecla",geom) VALUES ('0','Coastline','0105000020E61000000100000001020000000C000000D0347456A2CA18C05BC1C65E0CEF4A403FFBA3ECC62118C08AB5EFBA9B934A4010BA8804CA271BC09650268B4B214A40D09F77358C1F21C036A1DEA9ABD5494040720A9544F423C08AA1DEA904E9494088D170FB225522C0BCBB2928AC6E4A40088BF249866023C04F137F7DD0F04A40F0F906F8EDA720C07E8CF6F40E554B40D08D1B64E6491EC028FE33FFD8904B4040B24E9775EF1AC0BA12E24620964B40B0E392DBD5A516C0BAA0A43CFD464B40D0347456A2CA18C05BC1C65E0CEF4A40');
.... 너무 길어서 중간 생략함 .....
INSERT INTO "data_import"."ne_coastline" ("scalerank","featurecla",geom) VALUES ('0','Coastline','0105000020E6100000010000000102000000840000008881E7DEC36147C090CC237F30A85440A4E4D53906B445C084177D0569CE5440E0965643E2F243C02AD9B11188CB544044C49448A24F43C09E779CA223E354405026FC523F8B41C0C8EA56CF49E95440608E1EBFB7193BC08842041C42E15440905DA27A6BD834C02615C61682AE5440F8B7921D1BB136C06C2BF697DD955440E0B298D87C843AC0E2E995B20C9354405866666666E63FC0CCCCCCCCCC8C5440102C0E677E653FC094E34EE96081544098CADB114EDB3BC0149161156F88544050205ED72FD838C0B83B6BB75D7254408821AB5B3DE736C0F8BD4D7FF6855440E87C3F355E1236C04C4F58E2016F544020139B8F6B2B37C06CF12900C6495440F8CD3637A69F34C0FAB4C35F9361544000E292E34E892FC00C4FAF94657A544010117008558A29C0B22E6EA3016E54404029CB10C76A28C0765E6397A852544048910A630B4930C0CA9717601F2554408899999999D930C06A6666666616544058C47762D60B34C0AA315A47550B544040A2B437F8BA31C09E508880430854406066666666E632C09C99999999D95340D00182397AB433C0E288B5F814B05340F8DF4A766CAC33C05E6397A8DE685340E0E995B20C7932C05CD3BCE3143F5340F860E0B9F70834C07E130A11703C53402098A3C7EFAD35C07E6132553028534018938C9C85D533C0141956F146065340A89C4B71559933C0C03E3A75E5CF524058D72FD80DAB34C03C454772F9C95240309FE579705F33C0BA973446EB92524018A14ACD1E9835C0340C1F11538E5240C8CD70033E6F34C028A5A0DB4B745240B86ED8B628C334C084640113B85D5240480B5EF4152C36C0849ECDAACF53524040D3D9C9E09037C0427E6FD39F535240E00C1AFA275036C0BA019F1F4628524008D847A7AE4C36C052616C21C80B5240302B4D4A414738C0ACBB79AA432652403809336DFFCA38C0EA482EFF21155240A86F99D3657137C0A49C685721055240E8940ED6FF2136C09A9EB0C403DE5140E892E34EE9C035C0AC2B9FE579AA5140B8AC1743398937C0A21A2FDD249E5140C037DBDC984E38C07CD66EBBD0B65140C851F2EA1C8B39C074A25D8594DB5140B00C71AC8B3339C0B685200725B05140084CE0D6DD5C3AC08C7615527E8E5140C874763238BA37C0C408E1D1C68B514068A6ED5F595936C0FC88981249885140F8C01C3D7E0739C01E0DE02D90505140E802ECA353BF3BC0DE8442041C1E5140F8FC304278AC3EC03641D47D000851403870CE88D2C63FC0B28009DCBA075140DCB5847CD06740C01C4CC3F011EF5040D48C45D3D91941C01C7233DC80AB5040385C72DC292D42C07A832F4CA67E5040041C42959A8542C04287F9F2027C5040B42E6EA3013043C028A5A0DB4B6C50401C9430D3F6E743C0B0777FBC575D5040E8ACDD76A15544C0C4E78711C2355040DCB06D51665744C05A5F24B4E5085040A8605452279844C064D0D03FC1BD4F40887F9F71E16845C03C8AE59656574F4094C6681D553545C01CFE9AAC51F34E40A00F5D50DF6E45C0444C89247A894E40386744696FB045C02015C616820C4E40C4CCCCCCCC6446C088E63A8DB4044E406CF59CF4BE2147C0642A6F47386D4E40B8679604A82148C0E4F3C308E16D4E4004ADC090D59D48C0D0D79E5912B44E4098D2C1FA3FF348C01C4CC3F011314F408C1804560ED149C08CC43D963ED04F40446E861BF0114AC05AA31EA2D11150404C33164D67234AC0024D840D4F4B504024895E46B1D44AC0686AD95A5F865040C0120F289BA64AC0AAC64B3789B55040F81CE6CB0BFC4AC05851836918CC5040CC7F48BF7D7D4AC01AD82AC1E2165140C4E9B298D8BC49C034F44F70B12E5140C022F8DF4A8A49C0660113B87549514078CF0F23846F49C0AEADD85F767B5140A85B3D27BD014AC0CA293A92CB64514064E42CEC69474AC046B79734465B5140F0BEF1B567BA4AC0FCD478E92652514080B2295778574BC00EE544BB0A67514028D6E25300604BC00A850838849251408C3F1878EE2D4BC0BA2DCA6C90B4514018A3755435B74AC0FE1D8A027DB55140406E861BF0B149C08E7A884677A45140F0940ED6FF8D4AC078A52C431CCD51409CFEEC478A004BC0B4AC342905E35140F8FFFFFFFF7F4BC040C3A0B304DA5140045053CBD6EA4BC06E4C4F58E2E95140342861A6ED5B4BC0F051B81E852552402CB05582C5A94BC09AE7C1DD593D5240FC449E245D0F4CC000FBE8D495695240940035B56CA94CC010EA5BE674AD5240344A5E9D634C4DC0C24351A04FC65240AC76DB85E64A4DC0EC4CA1F31AE1524074B0FECF61A24EC0EEF0D7648D06534034BD529621B24FC098900F7A360B53404C07EBFF1C8450C07C62D68BA108534068300DC3472051C072693524EE035340B8AF03E78C6A51C0FAA9F1D24D1853407416F6B4C3D951C0826E2F698C4053407A1EDC9DB53151C0C22B82FFAD54534004486DE2E4B050C09CBB96900F5853401C81785DBFC251C00EF9A067B36853405CBA490C025352C0DE334B02D4825340B8E82B48334A52C0C0A94885B19B53403E2CD49AE65751C0FA1D8A027DBA53401851DA1B7C6D50C072B6B9313DD9534028CB10C7BA5450C08872A25D85F05340921D1B81780151C0EA305F5E800754408C8D40BCAEC950C0DAA7E331032154404C62105839D84FC0BCA94885B14D5440E86F4221021E4FC0B6AF03E78C545440543BFC3559534FC0CE0BB08F4E71544034B9DFA128244EC0868A71FE26825440E8F0D7648D9A4CC082828B15358C5440D0F6AFAC34114BC028E8F692C68C54401849F4328A854AC092831266DA785440C8BE2B82FF3149C03AA06CCA159C54409CE1067C7E0048C00E9DD7D825845440906A9F8EC74C47C0E6A90EB9197F544070E7FBA9F14246C0E81DA7E8486A5440ECC039234A7347C05A04FF5BC98C54408881E7DEC36147C090CC237F30A85440'); INSERT INTO "data_import"."ne_coastline" ("scalerank","featurecla",geom) VALUES ('3','Country','0105000020E6100000010000000102000000060000006666666666A65AC06766666666665240713D0AD7A3505AC0295C8FC2F56852400000000000205AC07B14AE47E15A5240B91E85EB51585AC0713D0AD7A33052405C8FC2F528BC5AC03E0AD7A3705D52406666666666A65AC06766666666665240'); COMMIT; |
(2) shp2pgsql로 shapefile data를 import하는 SQL문을 psql로 보내서 import하기 |
Greenplum docker 명령 프롬프트 창에서 shp2pgsql 유틸리티를 사용해서 (1)번에서 만든 SQL문을 psql로 보내서 실행시켜 보겠습니다. (아래에서 각자 자신의 Greenplum DB 혹은 PostgreSQL DB의 host(-h), port(-p), user(-U), database(-d) 이름을 설정해 줌)
|
[gpadmin@mdw tmp]$ shp2pgsql -s 4326 ne_110m_coastline data_import.ne_coastline .... 중간 생략함 .... INSERT 0 1 |
마지막으로, DBeaver db tool로 가서 SELECT 문으로 데이터가 잘 들어갔는지 조회를 해보겠습니다. 해안선(coastline)을 MULTILINESTRING 공간지리 데이터 포맷으로 저장해놓은 데이터셋이군요.
|
SELECT * FROM data_import.ne_coastline ORDER BY gid LIMIT 10; |
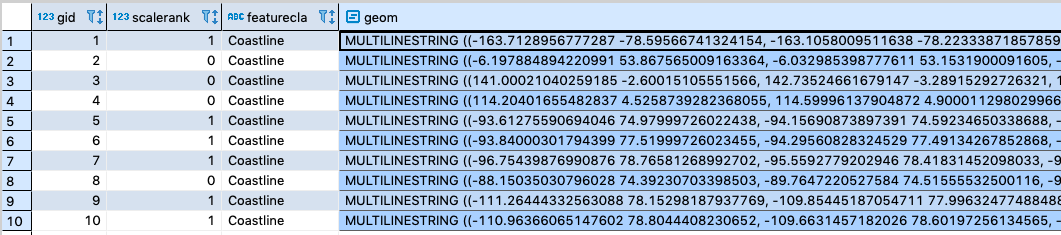
이중에서 첫번째 gid의 geom만 가져다 살펴보면 아래에서 보는 것처럼 22개의 값으로 이루어져 있습니다.
|
MULTILINESTRING ((-163.7128956777287 -78.59566741324154, -163.1058009511638 -78.22333871857859, -161.24511349184644 -78.38017669058443, -160.24620805564453 -78.69364592886694, -159.48240454815448 -79.04633757925897, -159.20818356019765 -79.4970077452764, -161.12760128481472 -79.63420867301133, -162.43984676821842 -79.28146534618699, -163.027407803377 -78.92877369579496, -163.06660437727038 -78.8699659158468, -163.7128956777287 -78.59566741324154)) |
많은 도움이 되었기를 바랍니다.