지난번 포스팅에서는 PostgreSQL, Greenplum에서 EXTRACT() 함수를 사용해서 TIMESTAMP, INTERVAL 데이터 유형으로 부터 날짜, 시간 정보를 가져오기(https://rfriend.tistory.com/708) 하는 방법을 소개하였습니다.
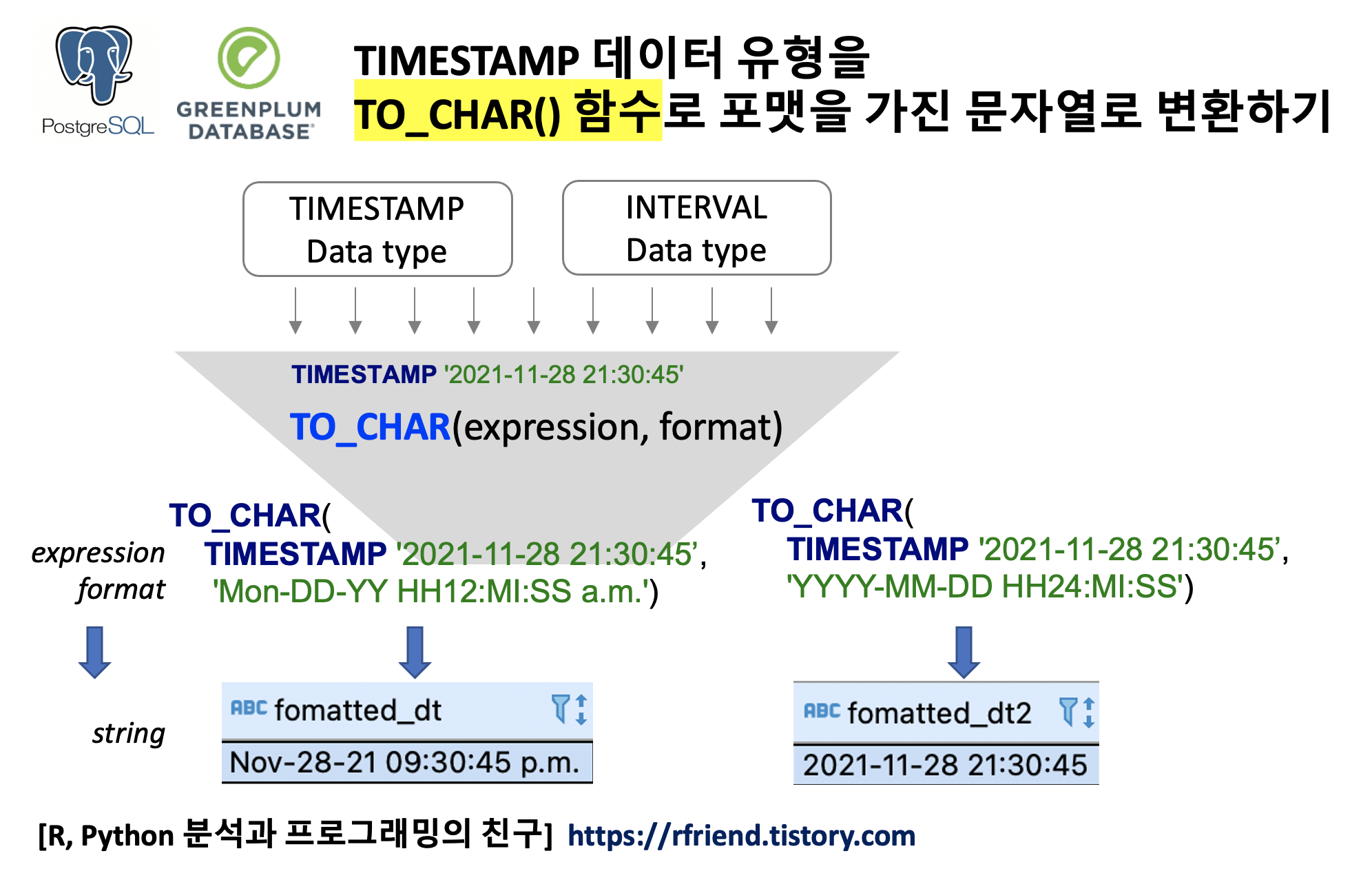
이번 포스팅에서는 PostgreSQL, Greenplum 에서 TO_CHAR(expression, format) 함수를 사용하여 TIMESTAMP 데이터를 포맷을 가진 문자열로 바꾸기 (converting a TIMESTAMP data type to a formatted string) 하는 방법을 소개하겠습니다.
TO_CHAR(expression, format) 함수에서 expression 매개변수에는 TIMESTAMP 데이터 유형 뿐만이 아니라 INTERVAL, Integer, Double Precision, Numeric 데이터 유형도 사용할 수 있습니다만, 이번 포스팅에서는 TIMESTAMP 데이터 유형에 한정해서 설명을 하겠습니다.
PostgreSQL, Greenplum, TO_CHAR(expression, format) : converting TIMESTAMP data type to a string
직관적인 이해를 돕기위한 간단한 예제로서, 아래는 TO_CHAR(expression, format) 함수에서 expression 매개변수로 TIMESTAMP '2021-11-28 21:30:45' 를 입력해주고, format 매개변수로는 'Mon-DD-YY HH12:MI:SS a.m.' (==> 축약된 형태의 첫글자 대문자의 월 이름-날짜-연도는 뒤의 두개년도만, 시간(0~12시):분:초 소문자로 점 포함해서 a.m. 또는 p.m.) 를 설정했을 때 문자열로 변환된 예입니다.
---------------------------------------------------------------------------------
-- The PostgreSQL TO_CHAR(expression, format) function
-- : converts a timestamp data type to a string.
-- [expression] a timestamp that is converted to a string according to a specific format.
-- or an interval, an integer, a double precision, or a numeric value
-- [format] The format for the result string.
-- ref: https://www.postgresqltutorial.com/postgresql-to_char/
---------------------------------------------------------------------------------
-- converting the timestamp to a string.
SELECT
TO_CHAR(
TIMESTAMP '2021-11-28 21:30:45', -- expression
'Mon-DD-YY HH12:MI:SS a.m.' -- format
) AS fomatted_dt;
--fomatted_dt |
-------------------------+
--Nov-28-21 09:30:45 p.m.|
SELECT
TO_CHAR(
TIMESTAMP '2021-11-28 21:30:45', -- expression
'YYYY-MM-DD HH24:MI:SS' -- format
) AS fomatted_dt2;
--fomatted_dt2 |
---------------------+
--2021-11-28 21:30:45|
위의 예처럼 TO_CHAR(expression, format) 의 format 매개변수에 원하는 포맷의 매개변수를 이어서 써주면 되는데요, 각 포맷 매개변수의 아웃풋을 좀더 비교하기 편리하도록 하나씩 떼어서 예를 들어보겠습니다.
먼저 날짜 년(year), 월(month), 일(day) 에 대해서 TO_CHAR(TIMESTAMP '2021-11-28 21:30:45', format) 의 날짜 format 을 아래처럼 설정했을 때의 아웃풋을 비교해보겠습니다.
- format: 'YYYY-MM-DD' ==> 2021-11-28
- format: 'dd/mm/yyyy' ==> 28/11/2021
-- converting DATE to format strings
SELECT
datum AS dt
-- YYYY: year in 4 digits
-- MM: month number from 01 to 12
-- DD: Day of month (01-31)
, TO_CHAR(datum, 'YYYY-MM-DD') AS date_yyyymmdd
-- formatted strings as 'dd/mm/yyyy'
, TO_CHAR(datum, 'dd/mm/yyyy') AS date_ddmmyyyy
FROM (
SELECT TIMESTAMP '2021-11-28 21:30:45' AS datum
) ts;
--dt |date_yyyymmdd|date_ddmmyyyy|
-------------------------+-------------+-------------+
--2021-11-28 21:30:45.000|2021-11-28 |28/11/2021 |
TIMESTAMP 데이터 유형 '2021-11-28 21:30:45'에서 월(month)을 여러가지 포맷의 문자열로 변환해 보겠습니다.
(전체 월 이름 vs. 축약형 월 이름, 전체 대문자 vs. 첫글자만 대문자 vs. 전체 소문자)
- format: 'MONTH' ==> NOVEMBER
- format: 'Month' ==> November
- format: 'month' ==> november
- format: 'MON' ==> NOV
- format: 'Mon' ==> Nov
- format: 'mon' ==> nov
-- converting Month to formatted strings
SELECT
datum AS dt
-- MONTH: English month name in uppercase
, TO_CHAR(datum, 'MONTH') AS month_upper
-- Month: Full capitalized English month name
, TO_CHAR(datum, 'Month') AS month_capital
-- month: Full lowercase English month name
, TO_CHAR(datum, 'month') AS month_lower
-- MON: Abbreviated uppercase month name e.g., JAN, FEB, etc.
, TO_CHAR(datum, 'MON') AS month_abbr_upper
-- Mon: Abbreviated capitalized month name e.g, Jan, Feb, etc.
, TO_CHAR(datum, 'Mon') AS month_abbr_capital
-- mon: Abbreviated lowercase month name e.g., jan, feb, etc.
, TO_CHAR(datum, 'mon') AS month_abbr_lower
FROM (
SELECT TIMESTAMP '2021-11-28 21:30:45' AS datum
) ts;
--dt |month_upper|month_capital|month_lower|month_abbr_upper|month_abbr_capital|month_abbr
-------------------------+-----------+-------------+-----------+----------------+------------------+----------------+
--2021-11-28 21:30:45.000|NOVEMBER |November |november |NOV |Nov |nov |
TIMESTAMP 데이터 유형 '2021-11-28 21:30:45' 에 대해서 '주(week)' 의 format 을 다르게 설정해서 문자열로 변환해보겠습니다.
- format: 'W' (Week of month, 1~5) ==> 4
- format: 'WW' (Week number of year, 1~53)==> 48
- format: 'IW' (Week number of ISO 8601, 01~53) ==> 47
-- converting number of week to formatted strings
SELECT
datum AS datetime
-- W: Week of month (1-5)
-- (the first week starts on the first day of the month)
, TO_CHAR(datum, 'W') AS week_of_month
-- WW: Week number of year (1-53)
-- (the first week starts on the first day of the year)
, TO_CHAR(datum, 'WW') AS week_of_year
-- IW: Week number of ISO 8601 week-numbering year
-- (01-53; the first Thursday of the year is in week 1)
, TO_CHAR(datum, 'IW') AS week_iso
FROM (
SELECT TIMESTAMP '2021-11-28 21:30:45' AS datum
) ts;
--datetime |week_of_month|week_of_year|week_iso|
-------------------------+-------------+------------+--------+
--2021-11-28 21:30:45.000|4 |48 |47 |
TIMESTAMP 데이터 유형의 '2021-11-28 21:30:45' 의 '일(day)'에 대해서 format 을 달리하여 문자열로 변환해 보겠습니다. (전체 vs. 축약, 대문자 vs. 첫글자만 대문자 vs. 소문자)
- format: 'DAY' ==> SUNDAY
- format: 'Day' ==> Sunday
- format: 'day' ==> sunday
- format: 'DY' ==> SUN
- format: 'Dy' ==> Sun
- format: 'dy' ==> sun
-- converting Day to formatted strings
SELECT
datum AS datetime
-- DAY: Full uppercase day name
, TO_CHAR(datum, 'DAY') AS day_upper
-- Day: Full capitalized day name
, TO_CHAR(datum, 'Day') AS day_capital
-- day: Full lowercase day name
, TO_CHAR(datum, 'day') AS day_lower
-- DY: Abbreviated uppercase day name
, TO_CHAR(datum, 'DY') AS day_abbr_upper
-- Dy: Abbreviated capitalized day name
, TO_CHAR(datum, 'Dy') AS day_abbr_capital
-- dy: Abbreviated lowercase day name
, TO_CHAR(datum, 'dy') AS day_abbr_lower
FROM (
SELECT TIMESTAMP '2021-11-28 21:30:45' AS datum
) ts;
--datetime |day_upper|day_capital|day_lower|day_abbr_upper|day_abbr_capital|day_abbr
-------------------------+---------+-----------+---------+--------------+----------------+--------------+
--2021-11-28 21:30:45.000|SUNDAY |Sunday |sunday |SUN |Sun |sun |
TIMESTAMP 데이터 유형의 '2021-11-28 21:30:45' 의 'TIME'에 대해서 format 을 달리하여 문자열로 변환해 보겠습니다. 'HH24'는 0~23시간, 'HH12'는 0~12시간의 포맷으로 시간(hour)을 문자열로 바꿔줍니다. 'HH12' 포맷을 사용할 경우 오전(a.m.)과 오후(p.m.)을 구분할 수 있도록 a.m. meridiem, p.m. meridiem 표기를 추가해줍니다.
- format: 'HH24:MI:SS' ==> 21:30:45
- format: 'HH12:MI:SS' ==> 09:30:45
- format: 'HH12:MI:SS AM' ==> 09:30:45 PM
- format: 'HH12:MI:SS a.m.' ==> 09:30:45 p.m.
-- converting TIME to formatted strings
SELECT
datum AS dt
-- HH24: Hour of Day (0~23)
-- MI: Minute (0-59)
-- SS: Second (0-59)
, TO_CHAR(datum, 'HH24:MI:SS') AS time_h24ms
-- HH12: Hour of Day (0,12)
, TO_CHAR(datum, 'HH12:MI:SS') AS time_h12ms
-- AM, am, PM or pm Meridiem indicator (without periods, upper case)
, TO_CHAR(datum, 'HH12:MI:SS AM') AS time_h12ms_ampm
-- A.M., a.m., P.M. or p.m. Meridiem indicator (with periods, lower case)
, TO_CHAR(datum, 'HH12:MI:SS a.m.') AS time_h12ms_ampm_periods
FROM (
SELECT TIMESTAMP '2021-11-28 21:30:45' AS datum
) ts;
--dt |time_h24ms|time_h12ms|time_h12ms_ampm|time_h12ms_ampm_per
-------------------------+----------+----------+---------------+-----------------------+
--2021-11-28 21:30:45.000|21:30:45 |09:30:45 |09:30:45 PM |09:30:45 p.m. |
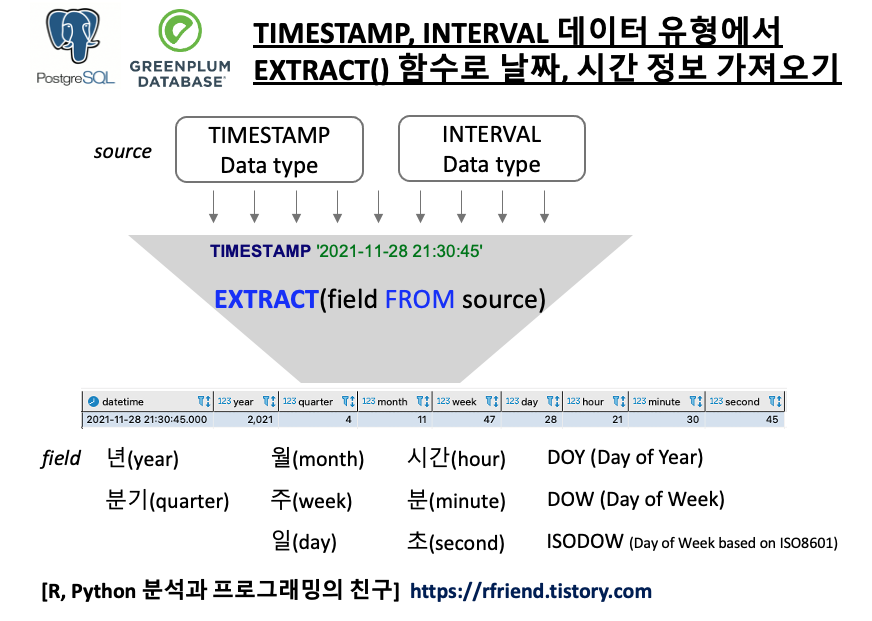
시계열 데이터를 다루다 보면 년, 분기, 월, 일, 시간, 분, 초 등의 날짜와 시간에 관한 정보를 추출해야 할 일이 있습니다.
이번 포스팅에서는 Greenplum, PostgreSQL 에서 EXTRACT() 함수로 TIMESTAMP, INTERVAL 데이터 유형에서 날짜, 시간 정보를 추출(retrive)하는 방법을 소개하겠습니다.
(1) EXTRACT() 함수로 TIMESTAMP 데이터 유형에서 날짜, 시간 정보 가져오기
(2) EXTRACT() 함수로 INTERVAL 데이터 유형에서 날짜, 시간 정보 가져오기
postgresql, greenplum, extract() function
(1) EXTRACT() 함수로 TIMESTAMP 데이터 유형에서 날짜, 시간 정보 가져오기
먼저 PostgreSQL TIMESTAMP 데이터 유형에서 년(year), 분기(quarter), 월(month), 주(week), 일(day), 시간(hour), 분(minute), 초(second), 밀리초(millisecond), 마이크로초(microsecond) 정보를 EXTRACT(field from source) 함수를 사용해서 가져와보겠습니다.
------------------------------------------------------
-- PostgreSQL EXTRACT function
-- retriveing a field such as a year, month, and day from a date/time value
-- Syntax: EXTRACT(field FROM source)
-- The field argument specifies which field to extract from the date/time value
-- The source is a value of type 'TIMESTAP' or 'INTERVAL'
-- The 'EXTRACT()' function returns a double precision value.
-- ref: https://www.postgresqltutorial.com/postgresql-extract/
------------------------------------------------------
SELECT
datum AS datetime
, EXTRACT(YEAR FROM datum)::int AS year
, EXTRACT(QUARTER FROM datum)::int AS quarter
, EXTRACT(MONTH FROM datum)::int AS month
, EXTRACT(WEEK FROM datum)::int AS week
, EXTRACT(DAY FROM datum)::Int AS day
, EXTRACT(HOUR FROM datum)::int AS hour
, EXTRACT(MINUTE FROM datum)::Int AS minute
, EXTRACT(SECOND FROM datum)::Int AS second
--, EXTRACT(MILLISECONDS FROM datum)::int AS millisecond -- =45*1000
--, EXTRACT(MICROSECONDS FROM datum)::Int AS microsecond -- = 45*1000000
FROM (
SELECT TIMESTAMP '2021-11-28 21:30:45' AS datum
) ts;
--datetime |year|quarter|month|week|day|hour|minute|second|
-------------------------+----+-------+-----+----+---+----+------+------+
--2021-11-28 21:30:45.000|2021| 4| 11| 47| 28| 21| 30| 45|
PostgreSQL의 TIMESTAMP 데이터 유형에서
- DOY (Day Of Year) : 1년 중 몇 번째 날인지에 대한 값으로, 1일~365일 범위의 값을 가짐.
- DOW (Day Of Week): 1주일 중 몇 번째 날인지에 대한 값으로, 일요일이 '0', 토요일이 '6'의 값을 가짐.
- ISODOW (Day Of Week based on ISO 8601) : ISO 8601 표준을 따라서 1주일 중 몇 번째 날인지에 대한 값으로, 월요일이 '1', 일요일이 '7'의 값을 가짐.
-- extracting the day of year, week from TIMESTAMP type
SELECT
datum AS datetime
-- the DAY OF YEAR that ranges FROM 1 TO 365
, EXTRACT(DOY FROM datum)::int AS doy
-- the DAY OF week Sunday(0) TO Saturday(6)
, EXTRACT(DOW FROM datum)::int AS dow
-- DAY OF Week based ON ISO 8601 Monday(1) to Sunday(7)
, EXTRACT(ISODOW FROM datum)::int AS isodow
FROM (
SELECT TIMESTAMP '2021-11-28 21:30:45' AS datum
) ts;
--datetime |doy|dow|isodow|
-------------------------+---+---+------+
--2021-11-28 21:30:45.000|332| 0| 7|
(2) EXTRACT() 함수로 INTERVAL 데이터 유형에서 날짜, 시간 정보 가져오기
위의 (1)번에서는 TIMESTAMP 데이터 유형에 대해서 날짜, 시간 정보를 가져왔다면, 이번에는 INTERVAL 데이터 유형에 대해서 날짜, 시간 정보를 추출해보겠습니다.
INTERVAL 데이터 유형이 익숙하지 않은 분들을 위해서, 아래에 INTERVAL 데이터 유형을 사용해서 기준일로부터 INTERVAL 기간 만큼을 뺀 날짜/시간을 계산해 보았습니다. ('2021-11-28 21:30:45' 에서 '2년 3개월 5일 2시간 10분 5초' 이전은 날짜/시간은?)
-- The INTERVAL data type allows you to store and manipulate a period of time
-- in years, months, days, hours, minutes, seconds, etc.
-- (Syntax) @ INTERVAL [ fields ] [ (p) ]
SELECT
TIMESTAMP '2021-11-28 21:30:45' AS datetme
, TIMESTAMP '2021-11-28 21:30:45'
- INTERVAL '2 years 3 months 5 days 2 hours 10 minutes 5 seconds'
AS intv_dt;
--datetme |intv_dt |
-------------------------+-----------------------+
--2021-11-28 21:30:45.000|2019-08-23 19:20:40.000|
그럼, INTERVAL 데이터 유형에서 EXTRACT(field FROM source) 함수를 사용해서 년(year), 분기(quarter), 월(month), 일(day), 시간(hour), 분(minute), 초(second) 정보를 가져와 보겠습니다.
단, 위의 (1)번에서 TIMESTAMP 데이터 유형에 대해서는 가능했던 DOW, DOY, ISODOW, ISOYEAR, WEEK 등의 정보에 대해서는 INTERVAL 데이터 유형에 대해서는 EXTRACT() 함수가 지원하지 않습니다.
-- extracting the month, day, hour from an interval.
-- DOW, DOY, ISODOW, ISOYEAR, WEEK are not supported for INTERVAL
SELECT
intv AS INTERVAL
, EXTRACT(YEAR FROM intv)::int AS intv_year
, EXTRACT(QUARTER FROM intv)::int AS intv_quarter
, EXTRACT(MONTH FROM intv)::int AS intv_month
, EXTRACT(DAY FROM intv)::int AS intv_day
, EXTRACT (HOUR FROM intv)::int AS intv_hour
, EXTRACT(MINUTES FROM intv)::int AS intv_min
, extract(SECONDS FROM intv)::int AS intv_sec
FROM (
SELECT INTERVAL '2 years 3 months 5 days 2 hours 10 minutes 5 seconds'
AS intv
) ts;
--interval |intv_year|intv_quarter|intv_month|intv_day|intv_hour|intv_min|intv_sec|
--------------------------------+---------+------------+----------+--------+---------+--------+--------+
--2 years 3 mons 5 days 02:10:05| 2| 2| 3| 5| 2| 10| 5|
이동평균(Moving Average) 는 시계열 데이터를 분석할 때 이상치(Outlier), 특이값, 잡음(Noise) 의 영향을 줄이거나 제거하는 Smoothing 의 목적이나, 또는 미래 예측에 자주 사용됩니다. 개념이 이해하기 쉽고 직관적이기 때문에 실무에서 많이 사용됩니다. 주식 투자를 하는 분이라면 아마도 이동평균에 대해서 익숙할 것입니다.
이동평균에는 가중치를 어떻게 부여하느냐에 따라서 단순이동평균(Simple Moving Average), 가중이동평균(Weighted Moving Average), 지수이동평균(Exponential Moving Average) 등이 있습니다.
이번 포스팅에서는 PostgreSQL, Greenplum DB에서 Window Function 을 사용하여 가중치를 사용하지 않는 (혹은, 모든 값에 동일한 가중치 1을 부여한다고 볼 수도 있는)
(1) 단순이동평균 계산하기 (Calculating a Simple Moving Average)
(2) 처음 이동평균 날짜 모자라는 부분은 NULL 처리하고 단순이동평균 계산하기
(3) 누적 단순이동평균 계산하기 (Calculating a Cumulative Simple Moving Average)
하는 방법을 소개하겠습니다.
PostgreSQL, Greenplum, Simple Moving Average using Window Function
먼저, 세일즈 날짜와 판매금액의 두 개 칼럼으로 구성된, 예제로 사용할 간단한 시계열 데이터(Time Series Data) 테이블을 만들어보겠습니다.
ROUND(avg(), 1) 함수를 사용해서 단순이동평균값에 대해 소수점 첫째자리 반올림을 할 수 있습니다. 그리고 필요 시 단순이동평균 계산할 대상을 조회할 때 WHERE 조건절을 추가할 수도 있습니다.
-- Calculating a Moving Average for last 3 days using Window Function
SELECT
sale_dt
, sale_amt
, ROUND(
AVG(sale_amt)
OVER(
ORDER BY sale_dt
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW), 1
) AS avg_sale_amt
FROM sales
ORDER BY sale_dt;
--sale_dt sale_amt avg_sale_amt
--2021-06-01 230 230.0
--2021-06-02 235 232.5
--2021-06-03 231 232.0
--2021-06-04 244 236.7
--2021-06-05 202 225.7
--2021-06-06 260 235.3
--2021-06-07 240 234.0
--2021-06-08 235 245.0
--2021-06-09 239 238.0
--2021-06-10 242 238.7
--2021-06-11 244 241.7
--2021-06-12 241 242.3
--2021-06-13 246 243.7
--2021-06-14 247 244.7
--2021-06-15 249 247.3
--2021-06-16 245 247.0
--2021-06-17 242 245.3
--2021-06-18 246 244.3
--2021-06-19 245 244.3
--2021-06-20 190 227.0
--2021-06-21 230 221.7
--2021-06-22 235 218.3
--2021-06-23 231 232.0
--2021-06-24 238 234.7
--2021-06-25 241 236.7
--2021-06-26 245 241.3
--2021-06-27 242 242.7
--2021-06-28 243 243.3
--2021-06-29 240 241.7
--2021-06-30 238 240.3
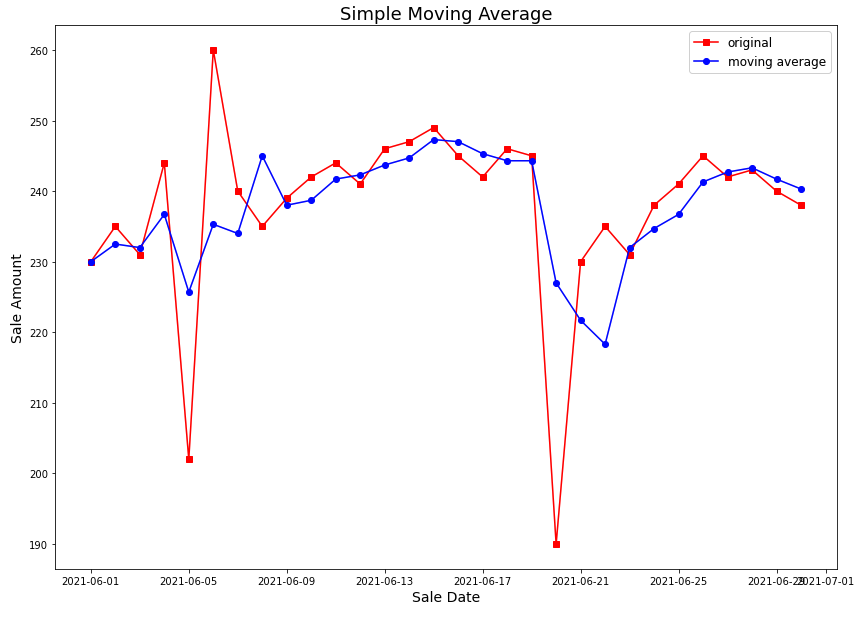
날짜를 X 축으로 놓고, Y 축에는 날짜별 (a) 세일즈 금액, (b) 3일 단순이동평균 세일즈 금액 을 시계열 그래프로 나타내서 비교해보면 아래와 같습니다. 예상했던대로 '3일 단순이동평균' 세일즈 금액이 스파이크(spike) 없이 smoothing 되어있음을 확인할 수 있습니다.
아래 코드는 Jupyter Notebook에서 Python 으로 Greenplum DB에 연결(connect)하여, SQL query 를 해온 결과를 Python pandas의 DataFrame으로 만들어서, matplotlib 으로 시계열 그래프를 그려본 것입니다.
## --- Jupyter Notebook ---
import pandas as pd
import matplotlib.pyplot as plt
## loading ipython, sqlalchemy, spycopg2
%load_ext sql
## Greenplum DB connection
%sql postgresql://dsuser:changeme@localhost:5432/demo
#'Connected: dsuser@demo'
## getting data from Greenplum by DB connection from jupyter notebook
%%sql sam << SELECT
sale_dt
, sale_amt
, ROUND(
AVG(sale_amt)
OVER(
ORDER BY sale_dt
ROWS BETWEEN 2 PRECEDING
AND CURRENT ROW)
, 1
) AS avg_sale_amt
FROM sales
ORDER BY sale_dt;
# * postgresql://dsuser:***@localhost:5432/demo
#30 rows affected.
#Returning data to local variable sam
## converting to pandas DataFrame
sam_df = sam.DataFrame()
sam_df.head()
#sale_dt sale_amt avg_sale_amt
#0 2021-06-01 230 230.0
#1 2021-06-02 235 232.5
#2 2021-06-03 231 232.0
#3 2021-06-04 244 236.7
#4 2021-06-05 202 225.7
## plotting time-series plot
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = [14, 10]
plt.plot(sam_df.sale_dt, sam_df.sale_amt, marker='s', color='r', label='original')
plt.plot(sam_df.sale_dt, sam_df.avg_sale_amt, marker='o', color='b', label='moving average')
plt.title('Simple Moving Average', fontsize=18)
plt.xlabel('Sale Date', fontsize=14)
plt.ylabel('Sale Amount', fontsize=14)
plt.legend(fontsize=12, loc='best')
plt.show()
original data vs. simple moving average
(2) 처음 이동평균 날짜 모자라는 부분은 NULL 처리하고 단순이동평균 계산하기
위의 (1)번에서 '3일 단순이동평균' 값을 계산할 때 시계열 데이터가 시작하는 첫번째와 두번째 날짜에 대해서는 이전 데이터가 존재하지 않기 때문에 '3일치' 데이터가 부족하게 됩니다. (만약 '10일 단순이동평균'을 계산한다고 하면 처음 시작하는 9일치 데이터의 경우 '10일치' 데이터에는 모자라게 되겠지요.)
위의 (1)번에서는 이처럼 '3일치' 데이터가 모자라는 '2021-06-01', '2021-06-02' 일의 경우 '3일치'가 아니라 '1일치', '2일치' 단순이동평균으로 대체 계산해서 값을 채워넣었습니다.
하지만, 필요에 따라서는 '3일치 단순이동평균'이라고 했을 때 이전 데이터가 '3일치'가 안되는 경우에는 단순이동평균을 계산하지 말고 그냥 'NULL' 값으로 처리하고 싶은 경우도 있을 것입니다. 이때 (2-1) CASE WHEH 과 AVG(), OVER() window function을 사용하는 방법, (2-2) LAG(), OVER() window function 을 이용하는 방법의 두 가지를 소개하겠습니다.
(2-1) CASE WHEH 과 AVG(), OVER() window function을 사용하여 단순이동평균 계산하고, 이동평균계산 날짜 모자라면 NULL 처리하는 방법
SELECT
sale_dt
, sale_amt
, CASE WHEN
row_number() OVER(ORDER BY sale_dt) >= 3
THEN
ROUND(
AVG(sale_amt)
OVER(
ORDER BY sale_dt
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW)
, 1)
ELSE NULL END
AS avg_sale_amt
FROM sales
ORDER BY sale_dt;
--sale_dt sale_amt avg_sale_amt
--2021-06-01 230 NULL
--2021-06-02 235 NULL
--2021-06-03 231 232.0
--2021-06-04 244 236.7
--2021-06-05 202 225.7
--2021-06-06 260 235.3
--2021-06-07 240 234.0
--2021-06-08 235 245.0
--2021-06-09 239 238.0
--2021-06-10 242 238.7
--2021-06-11 244 241.7
--2021-06-12 241 242.3
--2021-06-13 246 243.7
--2021-06-14 247 244.7
--2021-06-15 249 247.3
--2021-06-16 245 247.0
--2021-06-17 242 245.3
--2021-06-18 246 244.3
--2021-06-19 245 244.3
--2021-06-20 190 227.0
--2021-06-21 230 221.7
--2021-06-22 235 218.3
--2021-06-23 231 232.0
--2021-06-24 238 234.7
--2021-06-25 241 236.7
--2021-06-26 245 241.3
--2021-06-27 242 242.7
--2021-06-28 243 243.3
--2021-06-29 240 241.7
--2021-06-30 238 240.3
(2-2) LAG(), OVER() window function을 사용하여 단순이동평균 계산하고, 이동평균계산 날짜 모자라면 NULL 처리하는 방법
아래 LAG() 함수를 사용한 방법은 이렇게도 가능하다는 예시를 보여준 것이구요, 위의 (2-1) 과 비교했을 때 'x일 단순이동평균'에서 'x일'이 숫자가 커질 경우 수작업으로 LAG() 함수를 'x일' 날짜만큼 모두 써줘야 하는 수고를 해줘야 하고, 그 와중에 휴먼 에러가 개입될 여지도 있어서 아무래도 위의 (2-1) 방법이 더 나아보입니다.
(3) 누적 단순이동평균 계산하기 (Calculating a Cumulative Simpe Moving Average)
처음 시작하는 날짜부터 해서 누적으로 단순이동 평균 (Cumulative Moving Average) 을 계산하고 싶을 때는 아래처럼 AVG(sale_amt) OVER(ORDER BY sale_dt ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) 처럼 window 범위를 처음부터 현재까지로 설정해주면 됩니다.
아래 예에서 '2021-06-05'일까지의 누적 단순이동평균 값은 아래와 같이 계산되었습니다.
지난번 포스팅에서는 PostgreSQL, Greenplum에서 두 개의 SELECT 문 결과에 대한 합집합(UNION, UNION ALL), 교집합(INTERSECT), 차집합(EXCEPT) 에 대해서 알아보았습니다. (참고 ==> https://rfriend.tistory.com/659 )
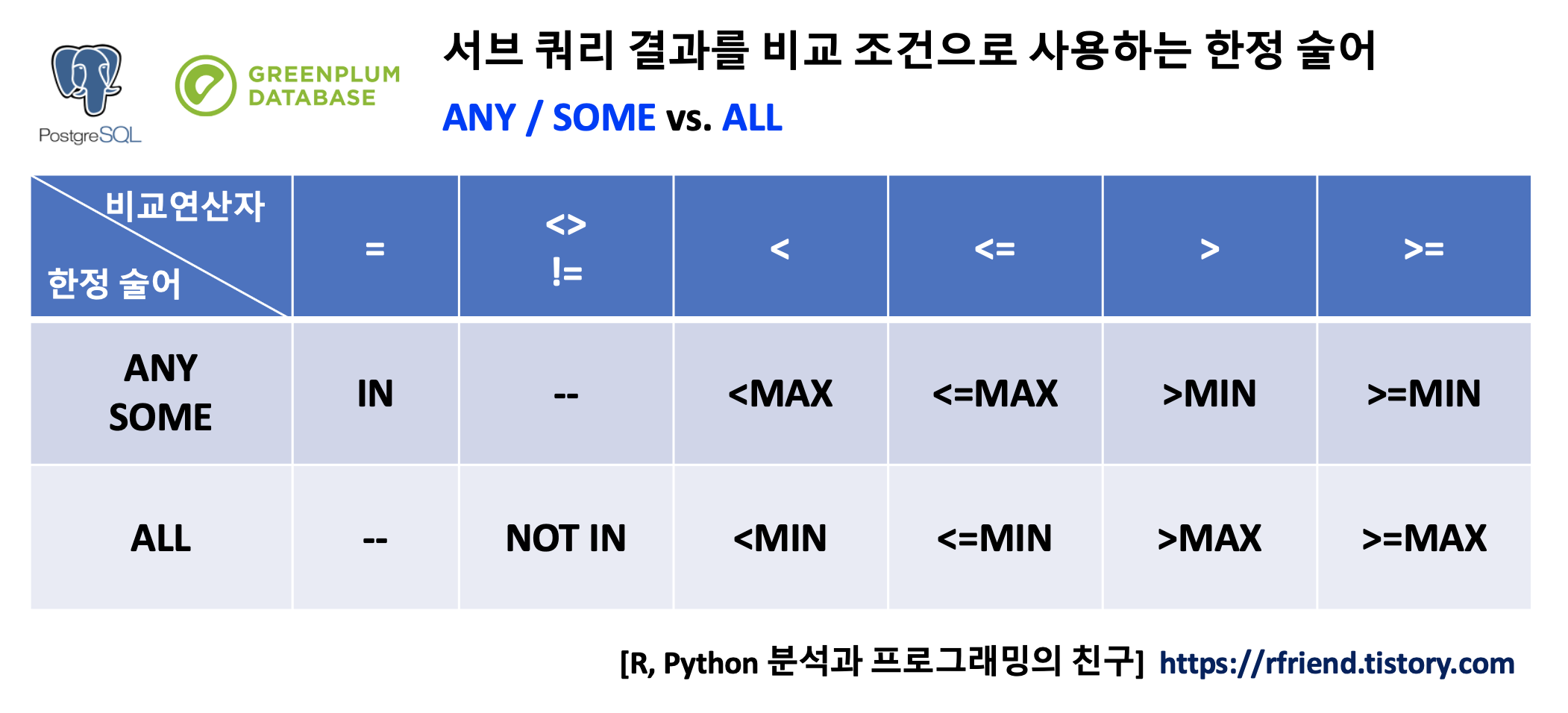
이번 포스팅에서는 Sub-Query의 결과를 WHERE 문에서 비교 조건으로 하여 사용할 수 있는 한정 술어 연산자로서 ANY, SOME, ALL, EXISTS 연산자(operator)에 대해서 알아보겠습니다.
1. ANY, SOME 연산자
2. ALL 연산자
3. EXISTS, NOT EXISTS 연산자
[ Sub-Query 결과를 비교 조건으로 사용하는 한정 술어 ANY/ SOME vs. ALL 비교 ]
PostgreSQL, Greenplum, 한정술어, any, some, all
먼저, 예제로 사용할 간단한 테이블 두 개를 만들어보겠습니다. 'cust_master' 테이블은 id, age, gender 의 세 개 칼럼으로 구성되어 있고, cust_amt 테이블은 id, amt 의 두 개 칼럼으로 구성되어 있으며, 두 테이블은 id 를 공통으로 가지고 있어 서로 연결이 가능합니다. (** 이번 포스팅에서는 JOIN 은 사용하지 않고, 대신 한정 술어를 사용해서 JOIN 결과와 유사한 결과를 얻어보겠습니다.)
-----------------------------------------------------------------------------------
-- 한정술어: ANY/ SOME, ALL, EXISTS, NOT EXISTS operators
-----------------------------------------------------------------------------------
-- creating sample tables
DROP TABLE IF EXISTS cust_master;
CREATE TABLE cust_master (
id int
, age int
, gender text
) DISTRIBUTED RANDOMLY;
INSERT INTO cust_master VALUES
(1, 45, 'M')
, (2, 34, 'F')
, (3, 30, 'F')
, (4, 28, 'M')
, (5, 59, 'M')
;
DROP TABLE IF EXISTS cust_amt;
CREATE TABLE cust_amt (
id int
, amt int
) DISTRIBUTED RANDOMLY;
INSERT INTO cust_amt VALUES
(1, 500)
, (2, 200)
, (3, 750)
, (8, 900)
, (9, 350)
;
(1) ANY, SOME 연산자
ANY 한정술어 연산자는 Sub-Query 의 결과 값들 중에서 어떤 값이라도 =, <>, !=, <, <=, >, >= 등의 비교 연산자의 조건을 만족하면 TRUE 를 반환하며, 그렇지 않은 경우 FALSE 를 반환합니다. SOME 한정 술어 연산자는 ANY 연산자와 동일한 기능을 수행합니다.
Sub-Query 는 반드시 1개의 칼럼만 반환해야 합니다.
아래의 예에서는 cust_amt 테이블에서 amt > 300 인 조건을 만족하는 id 와 동일한('=') id 를 가진 값을 cust_master 테이블에서 SELECT 해본 것입니다. (JOIN 문을 사용해도 됩니다만, ANY 연산자를 사용해서 아래처럼도 가능합니다. PostgreSQL이 내부적으로 query optimization을 해서 JOIN 문을 쓰던 ANY/ SOME 연산자를 쓰던 성능은 비슷합니다.)
WHERE 조건문에 IN 연산자를 사용할 경우에는 ANY/SOME 연산자에서 같이 사용했던 비교 연산자 ('=') 가 없는 차이점이 있습니다.
WHERE 조건절에서 ANY, SOME 연산자에 비교연산자(=, <>, !=, <, <=, >, >=) 가 같이 사용되었을 경우의 의미는 포스팅 초반의 표를 참고하세요.
--------------------------------
-- ANY, SOME operator
--------------------------------
-- ANY operator compares a value to a set of values returned by a subquery.
--The ANY operator must be preceded by one of the following comparison operator =, <=, >, <, > and <>
--The ANY operator returns true if any value of the subquery meets the condition, otherwise, it returns false.
SELECT id
FROM cust_amt
WHERE amt > 300
ORDER BY id;
--id
--1
--3
--8
--9
-- ANY OPERATOR
SELECT *
FROM cust_master
WHERE id = ANY (
SELECT id
FROM cust_amt
WHERE amt > 300
);
--id age gender
--1 45 M
--3 30 F
-- SOME OPERATOR
SELECT *
FROM cust_master
WHERE id = SOME (
SELECT id
FROM cust_amt
WHERE amt > 300
);
-- IN
SELECT *
FROM cust_master
WHERE id IN (
SELECT id
FROM cust_amt
WHERE amt > 300
);
(2) ALL 연산자
ALL 한정술어 연산자는 Sub-Query의 결과의 '모든 값과 비교' 하여 '모든 값이 조건을 만족하면 TRUE, 그렇지 않으면 FALSE'를 반환합니다.
WHERE 조건절에서 ALL 연산자에 비교연산자(=, <>, !=, <, <=, >, >=) 가 같이 사용되었을 경우의 의미는 포스팅 초반의 표를 참고하세요. 가령 아래의 예에서 "WHERE age > ALL (sub-query)" 는 "WHERE age > sub-query의 MAX" 값과 같은 의미입니다. 아래의 예에서는 Sub-Query의 avg_age 가 32, 44 이므로 이중에서 MAX 값인 44보다 age가 큰 값을 cust_master 테이블에서 조회를 하겠군요.
---------------------------
-- the ALL operator
---------------------------
-- the PostgreSQL ALL operator compares a value with a list of values returned by a subquery.
SELECT gender, avg(age) AS avg_age
FROM cust_master
GROUP BY gender;
--gender avg_age
--F 32.0000000000000000
--M 44.0000000000000000
SELECT *
FROM cust_master
WHERE age > ALL (
SELECT avg(age) AS avg_age
FROM cust_master
GROUP BY gender
);
--id age gender
--1 45 M
--5 59 M
(3) EXISTS, NOT EXISTS 연산자
EXISTS 연산자는 Sub-Query의 결과에서 값이 존재하는지를 평가하는 블리언 연산자입니다. 만약 Sub-Query의 결과에 단 1개의 행이라도 값이 존재하다면 EXISTS 연산자의 결과는 TRUE 가 되며, Sub-Query의 결과가 한 개의 행도 존재하지 않는다면 FALSE 가 됩니다.
아래의 예에서는 cust_master 테이블과 cust_amt 의 두 개 테이블을 같이 사용해서, cust_amt 테이블의 amt > 400 인 조건을 만족하고 cust_master 와 cust_amt 테이블에서 id 가 서로 같은 값이 존재(EXISTS) 하는 cust_master 의 모든 칼럼 값을 가져온 것입니다. (JOIN 문을 사용하지 않고도 EXISTS 문을 사용해서 아래처럼 쓸 수도 있답니다. 성능은 비슷.)
NOT EXISTS 연산자는 EXISTS 연산자를 사용했을 때와 정반대의 값을 반환합니다.(TRUE, FALSE 가 서로 정반대임).
---------------------------
-- EXISTS operator
---------------------------
-- The EXISTS operator is a boolean operator that tests for existence of rows in a subquery.
-- If the subquery returns at least one row, the result of EXISTS is TRUE.
-- In case the subquery returns no row, the result is of EXISTS is FALSE.
SELECT *
FROM cust_master AS m
WHERE EXISTS (
SELECT 1
FROM cust_amt AS a
WHERE m.id = a.id
AND a.amt > 400
)
ORDER BY id;
--id age gender
--1 45 M
--3 30 F
----------------------------------
-- NOT EXISTS operator
----------------------------------
-- in case the subquery returns no row, the result is of NOT EXISTS is TRUE
SELECT *
FROM cust_master AS m
WHERE NOT EXISTS (
SELECT 1
FROM cust_amt AS a
WHERE m.id = a.id
AND a.amt > 400
)
ORDER BY id;
--id age gender
--2 34 F
--4 28 M
--5 59 M
지난번 포스팅에서는 여러개 테이블에서 SELECT 문으로 가져온 결과들의 합집합을 구할 때 UNION 은 중복 확인 및 처리를 하고 UNION ALL 은 중복확인 없이 여러 테이블의 모든 값을 합친다는 차이점을 소개하였습니다. (참고 => https://rfriend.tistory.com/658 )
이번 포스팅에서는 PostgreSQL, Greenplum DB에서 SELECT 문의 결과끼리 합치고 빼는 집합 연산자로서
(1) 합집합 UNION
(2) 교집합 INTERSECT
(3) 차집합 EXCEPT
(4) 필요조건: 칼럼의 개수가 같아야 하고, 모든 칼럼의 데이터 유형이 동일해야 함.
에 대해서 알아보겠습니다.
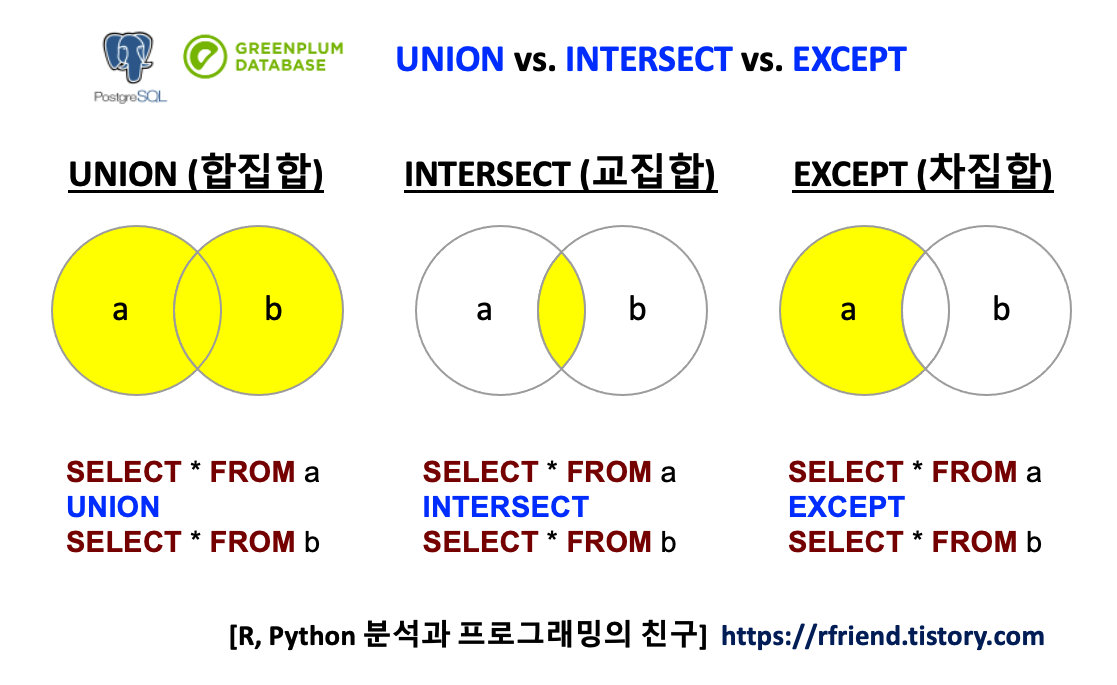
벤다이어 그램으로 PostgreSQL, Greenplum DB에서 SELECT 문 결과에 대한 합집합 UNION, 교집합 INTERSECT, 차집합 EXCEPT 했을 때의 결과를 도식화하면 아래와 같습니다.
예제로 사용할 간단한 테이블 두 개를 만들어보겠습니다. 'x1', 'x2' 의 두 개 칼럼이 있고, 두 개 모두 동일하게 'integer' 데이터 유형이어서 테이블 집합연산자인 합집합, 교집합, 차집합의 예제로 사용할 수 있습니다.
-- creating sample tables
-- Sample Table 1
DROP TABLE IF EXISTS sample_1;
CREATE TABLE sample_1 (x1 int, x2 int)
DISTRIBUTED randomly;
INSERT INTO sample_1 VALUES (1, 11), (2, 12), (3, 13), (4, 14), (5, 15);
SELECT * FROM sample_1 ORDER BY x1;
--x1 x2
--1 11
--2 12
--3 13
--4 14
--5 15
-- Sample Table 2
DROP TABLE IF EXISTS sample_2;
CREATE TABLE sample_2 (x1 int, x2 int)
DISTRIBUTED randomly;
INSERT INTO sample_2 VALUES (4, 14), (5, 15), (6, 16), (7, 17), (8, 18);
SELECT * FROM sample_2 ORDER BY x1;
--x1 x2
--4 14
--5 15
--6 16
--7 17
--8 18
아래의SELECT 문 결과에 대한 UNION, INTERSECT, EXCEPT query 구문은 별도의 추가 설명이 필요 없을 정도로 쉬운 내용이므로 예제 집합연산자의 결과만 제시하는 것으로 설명을 갈음하겠습니다.
(1) 합집합 UNION
-- UNION
SELECT * FROM sample_1
UNION
SELECT * FROM sample_2
ORDER BY x1;
--x1 x2
--1 11
--2 12
--3 13
--4 14
--5 15
--6 16
--7 17
--8 18
(2) 교집합 INTERSECT
-- INTERSECT
SELECT * FROM sample_1
INTERSECT
SELECT * FROM sample_2
ORDER BY x1;
--x1 x2
--4 14
--5 15
(3) 차집합 EXCEPT
두 테이블의 차집합 EXCEPT 는 먼저 SELECT 한 결과에서 나중에 SELECT 한 결과 중 중복되는 부분을 제외한 후의 나머지 결과를 반환합니다.
참고로, Oracle, MySQL DB에서는 SELECT 문 결과에 대한 차집합은 MINUS 함수를 사용해서 구할 수 있습니다.
-- EXCEPT
SELECT * FROM sample_1
EXCEPT
SELECT * FROM sample_2
ORDER BY x1;
--x1 x2
--1 11
--2 12
--3 13
(4) 필요조건: 칼럼의 개수가 같아야 하고, 모든 칼럼의 데이터 유형이 동일해야 함.
UNION, UNION ALL, INTERSECT, EXCEPT 의 집합연산자를 사용하려면 SELECT 문으로 불러온 두 테이블의 결과에서 칼럼의 개수가 서로 같아야 하고 또 모든 칼럼의 데이터 유형(Data Type)이 서로 동일해야만 합니다. 만약 칼럼의 데이터 유형이 서로 다르다면 아래와 같은 에러가 발생합니다. (아래 예에서는 'x2' 칼럼이 하나는 'integer', 또 하나는 'text' 로서 서로 다르기때문에 에러가 발생한 경우임)/
SQL Error [42804]: ERROR: UNION types integer and text cannot be matched
-- The data types of all corresponding columns must be compatible.
-- Sample Table 3
DROP TABLE IF EXISTS sample_3;
CREATE TABLE sample_3 (x1 int, x2 text)
DISTRIBUTED randomly;
INSERT INTO sample_3 VALUES (10, 'a'), (20, 'b'), (30, 'c'), (40, 'd'), (50, 'f');
SELECT * FROM sample_3 ORDER BY x1;
--x1 y
--10 a
--20 b
--30 c
--40 d
--50 f
-- ERROR
SELECT * FROM sample_1
INTERSECT
SELECT * FROM sample_3;
--SQL Error [42804]: ERROR: UNION types integer and text cannot be matched
지난번 포스팅에서는 PostgreSQL, Greenplum DB에서 JOIN 문을 사용하여 여러개의 테이블을 Key 값을 기준으로 왼쪽+오른쪽으로 연결하는 다양한 방법(INNER JOIN, LEFT OUTER JOIN, RIGHT OUTER JOIN, FULL JOIN)을 소개하였습니다. (참고 ==> https://rfriend.tistory.com/657)
이번 포스팅에서는 PostgreSQL, Greenplum DB에서 UNION, UNION ALL 함수를 사용해서 여러개의 테이블을 위+아래로 합치는 방법을 소개하겠습니다. 이전의 JOIN 이 Key값 기준 연결/매칭의 개념이었다면 이번 포스팅의 UNION, UNION ALL은 합집합(union of sets) 의 개념이라고 볼 수 있습니다.
(1) UNION : 중복값 제거 후 테이블을 위+아래로 합치기
(2) UNION ALL : 중복값 제거하지 않은 채 테이블을 위+아래로 합치기
(3) 전제조건: 합치려는 테이블 칼럼의 데이터 유형(data type)이 서로 같아야 함.
UNION 은 두 테이블의 중복값을 제거한 후에 두 테이블을 위+아래로 합친 결과를 반환하는 반면에, UNION ALL 은 중복값 여부를 확인하지 않고 두 테이블의 모든 값을 위+아래로 합친 결과를 반환합니다.
POSTGRESQL, GREENPLUM UNION, UNION ALL
UNION 의 경우 두 테이블의 값을 스캔 해서 두 테이블 간의 중복값 여부를 확인하는 중간 단계가 존재하기 때문에 두 테이블의 각 크기가 매우 큰 경우 UNION ALL 대비 상대적으로 연산 시간이 오래 걸립니다. 만약 위+아래로 합치려는 두 테이블의 값 간에 중복값이 없다거나 혹은 중복값 여부를 확인할 필요 없이 모두 합치기만 필요한 요건의 경우에는 UNION ALL 을 사용하는 것이 속도 면에서 유리합니다.
간단한 예제 테이블들을 만들어서 예를 들어보겠습니다.
-------------------------------------
-- UNION vs. UNION ALL
-------------------------------------
-- Sample Table 1
DROP TABLE IF EXISTS sample_1;
CREATE TABLE sample_1 (x1 int, x2 int)
DISTRIBUTED randomly;
INSERT INTO sample_1 VALUES (1, 11), (2, 12), (3, 13), (4, 14), (5, 15);
SELECT * FROM sample_1 ORDER BY x1;
--x1 x2
--1 11
--2 12
--3 13
--4 14
--5 15
-- Sample Table 2
DROP TABLE IF EXISTS sample_2;
CREATE TABLE sample_2 (x1 int, x2 int)
DISTRIBUTED randomly;
INSERT INTO sample_2 VALUES (4, 14), (5, 15), (6, 16), (7, 17), (8, 18);
SELECT * FROM sample_2 ORDER BY x1;
--x1 x2
--4 14
--5 15
--6 16
--7 17
--8 18
(1)UNION : 중복값 제거 후 테이블을 위+아래로 합치기
SELECT column1, column2, ... FROM table1
UNION
SELECT column1, column2, ... FROM table2
와 같은 형식의 구문으로 두 테이블에서 중복값을 제거한 후에 위+아래로 합칠 수 있습니다.
--------------------
-- (1) UNION
--------------------
SELECT * FROM sample_1
UNION
SELECT * FROM sample_2
ORDER BY x1;
--x1 x2
--1 11
--2 12
--3 13
--4 14
--5 15
--6 16
--7 17
--8 18
(2) UNION ALL : 중복값 제거하지 않은 채 테이블을 위+아래로 합치기
SELECT column1, column2, ... FROM table1
UNION ALL
SELECT column1, column2, ... FROM table2
와 같은 형식의 구문으로 두 테이블에서 중복값을 제거하지 않은 상태에서 (중복값 체크 없음) 위+아래로 합칠 수 있습니다.
-------------------------
-- (2) UNION ALL
-------------------------
SELECT * FROM sample_1
UNION ALL
SELECT * FROM sample_2
ORDER BY x1;
--x1 x2
--1 11
--2 12
--3 13
--4 14
--4 14 -- 중복
--5 15
--5 15 -- 중복
--6 16
--7 17
--8 18
(3) 전제조건: 합치려는 테이블 칼럼의 데이터 유형(data type)이 서로 같아야 함.
만약 UNION, UNION ALL 로 합치려는 두 테이블의 칼럼의 데이터 유형(data type)이 서로 같지 않다면, (아래의 예에서는 sample_1 테이블의 x2 칼럼은 integer, sample_3 테이블의 x2 칼럼은 text로서 서로 다름), "ERROR: UNION types integer and text cannot be matched" 라는 에러 메시지가 발생합니다.
-- (3) The data types of all corresponding columns must be compatible.
-- Sample Table 3
DROP TABLE IF EXISTS sample_3;
CREATE TABLE sample_3 (x1 int, x2 text)
DISTRIBUTED randomly;
INSERT INTO sample_3 VALUES (10, 'a'), (20, 'b'), (30, 'c'), (40, 'd'), (50, 'f');
SELECT * FROM sample_3 ORDER BY x1;
--x1 y
--10 a
--20 b
--30 c
--40 d
--50 f
-- ERROR
SELECT * FROM sample_1
UNION
SELECT * FROM sample_3;
--SQL Error [42804]: ERROR: UNION types integer and text cannot be matched
-- Position: 38
이번 포스팅에서는 PostgreSQL, Greenplum Database에서 여러개의 테이블을 Key 값을 기준으로 JOIN 구문을 사용하여 연결하는 다양한 방법을 소개하겠습니다. 그리고 두 테이블 내 관측치 간의 모든 가능한 조합을 반환해주는 CROSS JOIN 에 대해서도 마지막에 소개하겠습니다. (DB 종류에 상관없이 join SQL query는 거의 비슷합니다.)
(1) INNER JOIN
(2) LEFT JOIN
(3) RIGHT JOIN
(4) FULL JOIN
(5) 3개 이상 복수개의 테이블을 JOIN 으로 연결하기
(6) CROSS JOIN
joining two tables in postgresql
먼저 예제로 사용한 간단한 2개의 테이블을 만들어보겠습니다. 두 테이블을 연결할 수 있는 공통의 Key값으로서 'id'라는 이름의 칼럼을 두 테이블이 모두 가지고 있습니다.
'tbl1' 과 'tbl2'는 Key 'id'를 기준으로 id = [2, 3, 4] 가 서로 동일하게 존재하며, 'tbl1'의 id = [1]은 'tbl1'에만 존재하고, 'tbl2'의 id = [5] 는 'tbl2'에만 존재합니다. 각 JOIN 방법 별로 결과가 어떻게 달라지는지 유심히 살펴보시기 바랍니다.
-- Creating two sample tables
-- sample table 1
DROP TABLE IF EXISTS tbl1;
CREATE TABLE tbl1 (
id int
, x text
) DISTRIBUTED RANDOMLY;
INSERT INTO tbl1 VALUES (1, 'a'), (2, 'b'), (3, 'c'), (4, 'd');
SELECT * FROM tbl1 ORDER BY id;
--id x
--1 a
--2 b
--3 c
--4 d
-- sample table 2
DROP TABLE IF EXISTS tbl2;
CREATE TABLE tbl2 (
id int
, y text
) DISTRIBUTED RANDOMLY;
INSERT INTO tbl2 VALUES (2, 'e'), (3, 'f'), (4, 'g'), (5, 'h');
SELECT * FROM tbl2 ORDER BY id;
--id y
--2 e
--3 f
--4 g
--5 h
(1) INNER JOIN
INNER JOIN 은 두 테이블의 Key 값을 기준으로 교집합에 해당하는 값들만 반환합니다. 두 테이블에서 Key 값이 겹치지 않는 값들은 제거되었습니다.
--------------
-- INNER JOIN
--------------
SELECT a.id, a.x, b.y
FROM tbl1 AS a
INNER JOIN tbl2 AS b
ON a.id = b.id;
--id x y
--2 b e
--3 c f
--4 d g
(2) LEFT OUTER JOIN
LEFT OUTER JOIN 은 왼쪽 테이블을 기준으로 Key값이 서로 같은 오른쪽 테이블의 값들을 왼쪽 테이블에 연결해줍니다. 아래의 예에서는 왼쪽의 'tbl1'의 값들은 100% 모두 있고, LEFT OUTER JOIN 으로 연결해준 오른쪽 'tbl2' 테이블의 경우 id = [5] 의 값이 제거된 채 id = [2, 3, 4] 에 해당하는 값들만 'tbl1'과 연결이 되었습니다. 그리고 왼쪽 'tbl1'에는 있지만 오른쪽 'tbl2'에는 없는 id = [1] 에 해당하는 값의 경우 y = [NULL] 값을 반환하였습니다.
-------------------
-- LEFT OUTER JOIN
-------------------
SELECT a.id, x, y
FROM tbl1 AS a
LEFT OUTER JOIN tbl2 AS b
ON a.id = b.id;
--id x y
--1 a [NULL]
--2 b e
--3 c f
--4 d g
(3) RIGHT OUTER JOIN
RIGHT OUTER JOIN 은 LEFT OUTER JOIN 과 정반대라고 생각하면 이해하기 쉽습니다. 이번에는 오른쪽 테이블을 기준으로 Key 값이 같은 왼쪽 테이블의 값을 오른쪽 테이블에 연결해줍니다.
아래 RIGHT OUTER JOIN 예에서는 오른쪽 테이블은 'tbl2'는 100% 모두 있고, 왼쪽 테이블 'tbl1'의 경우 'tbl2'와 Key 값이 동일한 id = [2, 3, 4] 에 해당하는 값들만 'tbl2'에 연결이 되었습니다. 'tbl2'에만 존재하고 'tbl1'에는 없는 id = [5] 의 경우 'tbl1'의 'x' 칼럼 값은 [NULL] 값이 됩니다.
--------------------
-- RIGHT OUTER JOIN
--------------------
SELECT a.id, x, y
FROM tbl1 AS a
RIGHT OUTER JOIN tbl2 AS b
ON a.id = b.id;
--id x y
--2 b e
--3 c f
--4 d g
--5 [NULL] h
(4) FULL JOIN
FULL JOIN은 양쪽 테이블 모두를 기준으로 Key 값이 같은 값들을 연결시켜 줍니다. 이때 한쪽 테이블에만 Key 값이 존재할 경우 다른쪽 테이블의 칼럼 값에는 [NULL] 값을 반환합니다.
제일 위에 있는 도식화 그림을 참고하시면 위의 INNER JOIN, LEFT OUTER JOIN, RIGHT OUTER JOIN, FULL JOIN에 대해서 좀더 이해하기 쉬울 거예요.
---------------
-- FULL JOIN
---------------
SELECT a.id, x, y
FROM tbl1 AS a
FULL JOIN tbl2 AS b
ON a.id = b.id;
--id x y
--1 a [NULL]
--2 b e
--3 c f
--4 d g
--5 [NULL] h
(5) 3개 이상의 복수개의 테이블을 JOIN 으로 연결하기
위의 (1)~(4) 는 2개의 테이블을 Key 값을 기준으로 JOIN 문으로 연결한 것이었습니다. 만약 3개 이상의 복수개의 테이블을 JOIN 으로 연결하고자 한다면 아래의 예처럼 JOIN 문과 연결 Key 값을 ON 으로 이어서 써주면 됩니다.
아래의 예는 'tbl1' 테이블을 기준으로 'tbl2', 'tbl3'를 'id' Key를 기준으로 LEFT OUTER JOIN 한 것입니다.
--------------------------------------------------------
-- LEFT OUTER JOIN with Multiple Tables
--------------------------------------------------------
-- creating the 3rd table
DROP TABLE IF EXISTS tbl3;
CREATE TABLE tbl3 (
id int
, z text
) DISTRIBUTED RANDOMLY;
INSERT INTO tbl2 VALUES (2, 'i'), (4, 'j'), (6, 'k'), (8, 'l');
SELECT * FROM tbl3 ORDER BY id;
--id z
--2 i
--4 j
--6 k
--7 l
-- LEFT OUTER JOIN with 3 tables
SELECT a.id, x, y
FROM tbl1 AS a
LEFT OUTER JOIN tbl2 AS b
ON a.id = b.id
LEFT OUTER JOIN tbl3 AS c
ON a.id = c.id
ORDER BY a.id;
--id x y z
--1 a [NULL] [NULL]
--2 b e i
--3 c f [NULL]
--4 d g j
(6) CROSS JOIN
위의 (1)~(5)까지의 JOIN은 두 테이블에 동일하게 존재하는 Key값을 기준으로 두 테이블을 연결하여 주었다면, 이제 CROSS JOIN 은 두 테이블의 모든 값들 간의 조합을 반환하며, 이때 Key 값은 필요없습니다. 가령 왼쪽 테이블에 m 개의 행이 있고, 오른쪽 테이블에 n 개의 행이 있다면 두 테이블의 CROSS JOIN은 m * n 개의 조합(combination)을 반환합니다.
실수로 행의 개수가 엄청나게 많은 두 테이블을 CROSS JOIN 하게 될 경우 시간도 오래 걸리고 자칫 memory full 나서 DB가 다운되는 경우도 있습니다. 따라서 CROSS JOIN 을 할 때는 지금 하려는 작업이 CROSS JOIN 요건이 맞는 것인지 꼭 한번 더 확인이 필요하며, 소요 시간이나 메모리가 여력이 되는지에 대해서도 먼저 가늠해볼 필요가 있습니다.
----------------
-- CROSS JOIN
----------------
SELECT a.id AS id_a, a.x, b.id AS id_b, b.y
FROM tbl1 AS a
CROSS JOIN tbl2 AS b
ORDER BY a.id, b.id;
--id_a x id_b y
--1 a 2 e
--1 a 3 f
--1 a 4 g
--1 a 5 h
--2 b 2 e
--2 b 3 f
--2 b 4 g
--2 b 5 h
--3 c 2 e
--3 c 3 f
--3 c 4 g
--3 c 5 h
--4 d 2 e
--4 d 3 f
--4 d 4 g
--4 d 5 h
저는 주로 PostgreSQL, Greenplum database를 사용해서 작업을 할 때 DBeaver SQL IDE 를 사용하곤 합니다. 전에는 PGAdmin도 많이 썼는데요, 요즘에는 DBeaver를 주로 사용하네요.
고객사에 가서 프로젝트를 하게 되면 노트북에 분석에 사용하는 툴들을 설치해서 들어가게 되고, 프로젝트 종료 후에는 고객사의 보안 규정에 따라 노트북을 반출할 때는 포맷을 하게 됩니다. 이렇다 보니 포맷 후에 다시 처음부터 분석에 필요한 툴들을 새로 설치하고, 설정도 매번 새로 해줘야합니다.
이럴 때마다 매번 DBeaver 에서 설정 확인하고 조정해주는 것들에 대한 소소한 팁들 정리해보았습니다.
1. DBeaver 테마 설정
2. DBeaver 폰트 유형 및 폰트 크기 설정
3. DBeaver 대문자로 자동 바꿔주기 설정
4. DBeaver 행번호 표시 설정
1. DBeaver 테마 설정
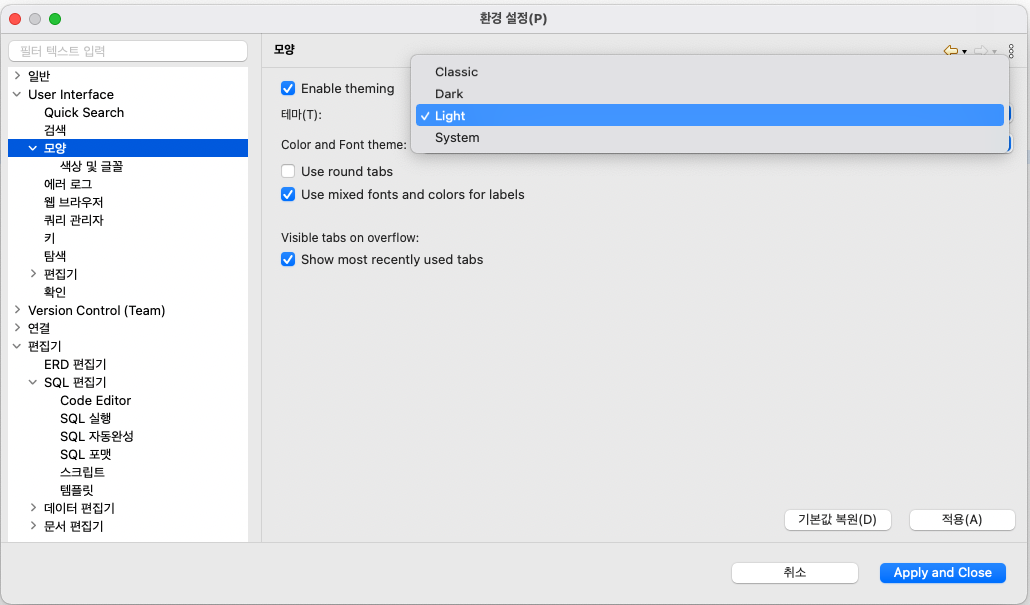
DBeaver 는 편집기의 전체 Theme으로 Classic, Dark, Light, System 의 4가지를 제공합니다. 아래의 경로대로 찾아가서 각각 클릭해서 '적용'해본 후에, 본인이 가장 좋아하는 Theme으로 설정하면 됩니다. (저는 'Light' (default) Theme이 가장 깔끔해서 기본 설정 그대로 사용하곤 합니다.)
윈도우(W) > User Interface > 모양 > Enable theming > 테마(T) > [Classic, Dark, Light, System] > Apply and Close
DBeaver : 윈도우(W) > 설정
DBeaver : User Interface > 모양 > 테마(T)
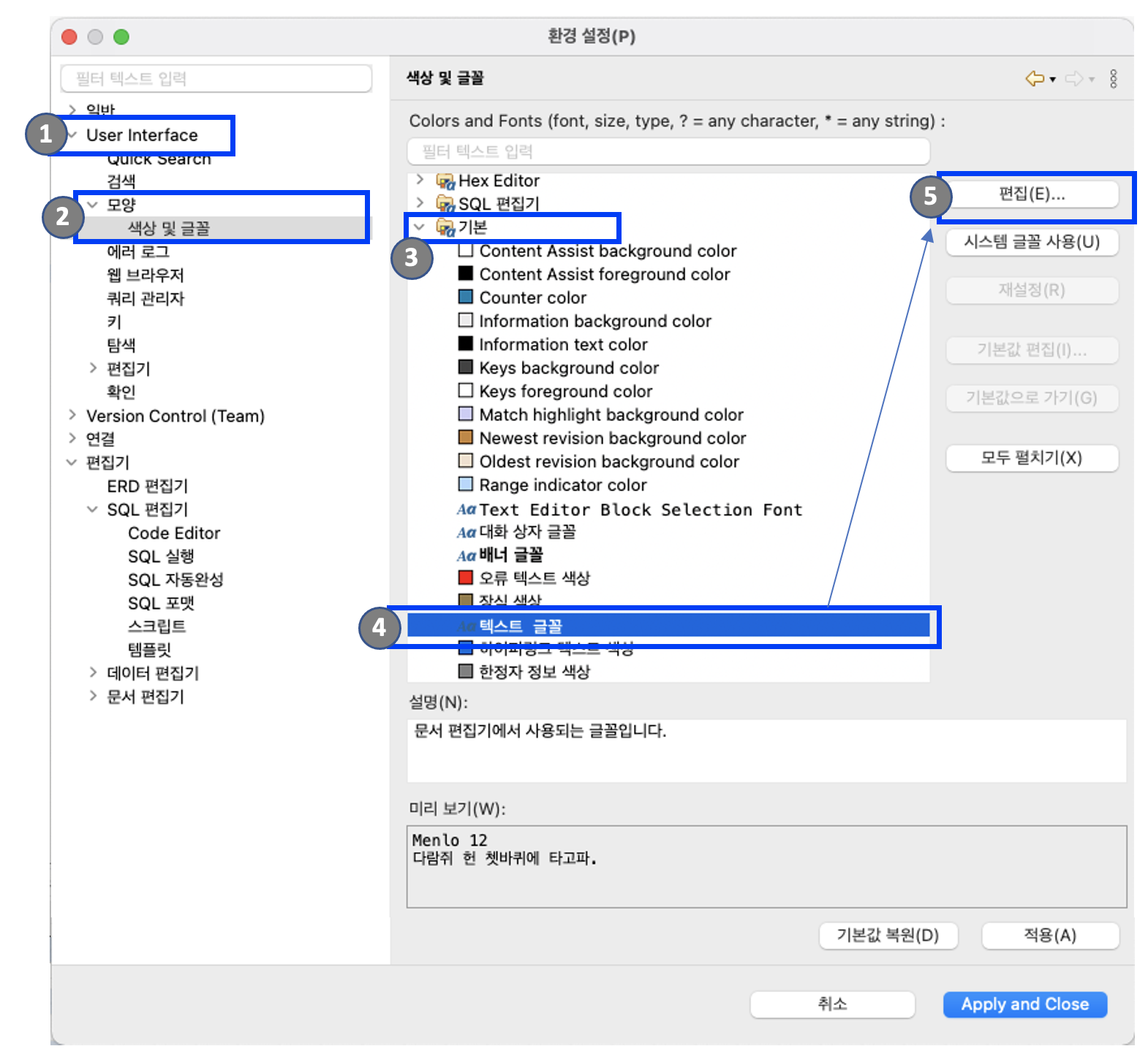
2. DBeaver 글꼴 유형(폰트 타입) 및 글꼴 크기(폰트 사이즈) 설정
DBeaver 새로 설치하고 나면, 매번 폰트 유형은 Arial로, 폰트 크기를 14로 키워서 사용하는 편입니다. 그런데 텍스트 글꼴 설정하는 메뉴 위치 찾기가 쉽지 않습니다. 그래서 자주 구글링을 하는 편이지요. 나중에 제가 폰트 설정하는 메뉴가 어디에 숨어있는지 참고하려고 이번 포스팅 쓰는 거랍니다. ^^;
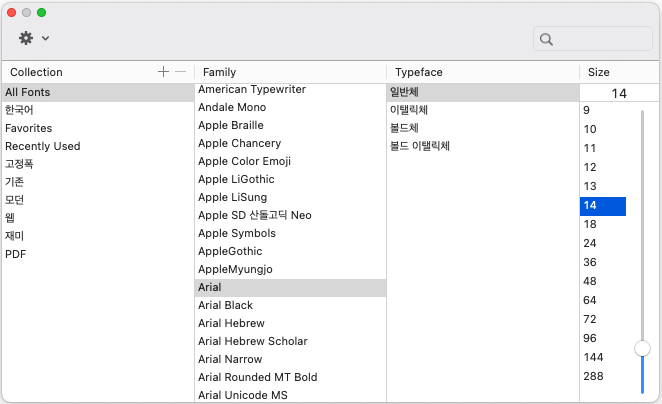
윈도우(W) > User Interface > 모양 > 색상 및 글꼴 > 기본 > 텍스트 글꼴 > 편집 > Collection, Family, Typeface, Size 설정 > Apply and Close
DBeaver: User Interface > Font setting > Edit
Collection 에서 "All Fonts" 선택하고, Family에서 원하는 글꼴(폰트)를 선택합니다. 저는 무난하게 "Arial"을 선택했습니다. Typeface 에서 [일반체, 이탤릭체, 볼드체, 볼드 이탤릭체] 중에서 선택을 하고, 글꼴 크기 (폰트 사이즈)를 설정해주면 됩니다. 이렇게 설정을 다 해주고 나면 앞의 화면의 제일 밑에 있는 "Apply and Close"를 클릭해주면 설정이 적용됩니다.
3. DBeaver SQL Keyword 를 대문자로 자동으로 바꿔주기 설정
개인마다 각자 취향이 있겠습니다만, 저는 SQL Query 구문의 가독성을 좋게 하는데 도움이 되기 때문에 SQL Keyword 문을 대문자로 하고, 그 외 테이블이나 칼럼 이름은 소문자로 구분해서 사용하곤 합니다. 그런데 이렇게 대문자와 소문자를 매번 SQL query문을 쓸 때마다 수동으로 키보드에서 CapsLock 키를 눌러가면서 바꿔줘야 한다면 상당히 번거롭습니다. 이때 SQL Keyword 구문을 자동으로 대문자로 바꿔주는 설정이 있다면 정말 편하겠지요?!
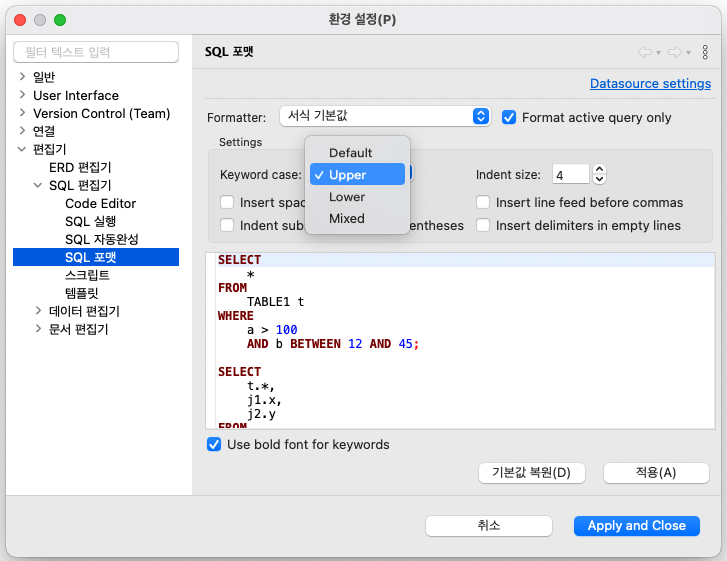
윈도우(W) > 편집기 > SQL 편집기 > SQL 포맷 > Keyword case > [Default, Upper, Lower, Mixed] > Apply and Close
DBeaver: Editor > SQL Editor > SQL format > Keyword case > Upper
4. DBeaver 행번호 표시 설정
DBeaver 의 SQL 편집기에서 행 번호를 표시하면 SQL Query가 길어졌을 때 디버깅하기에 편리하기 때문에 행번호 표시를 활성화해서 사용하곤 합니다.
윈도우(W) > 편집기 > 문서 편집기 > 행 번호 표시(B) check > Apply and Close
DBeaver : Editor > Document Editor > Line Number
"행 번호 표시"를 활성화하면 아래처럼 SQL 편집기의 Script 창의 왼쪽에 "행 번호 (line nubmer)"가 표시됩니다.
지난번 포스팅에서는 Python의 statsmodels 모듈을 이용하여 여러개의 숫자형 변수에 대해 집단 간 평균의 차이가 있는지를 for loop 순환문을 사용하여 검정하는 방법(rfriend.tistory.com/639)을 소개하였습니다.
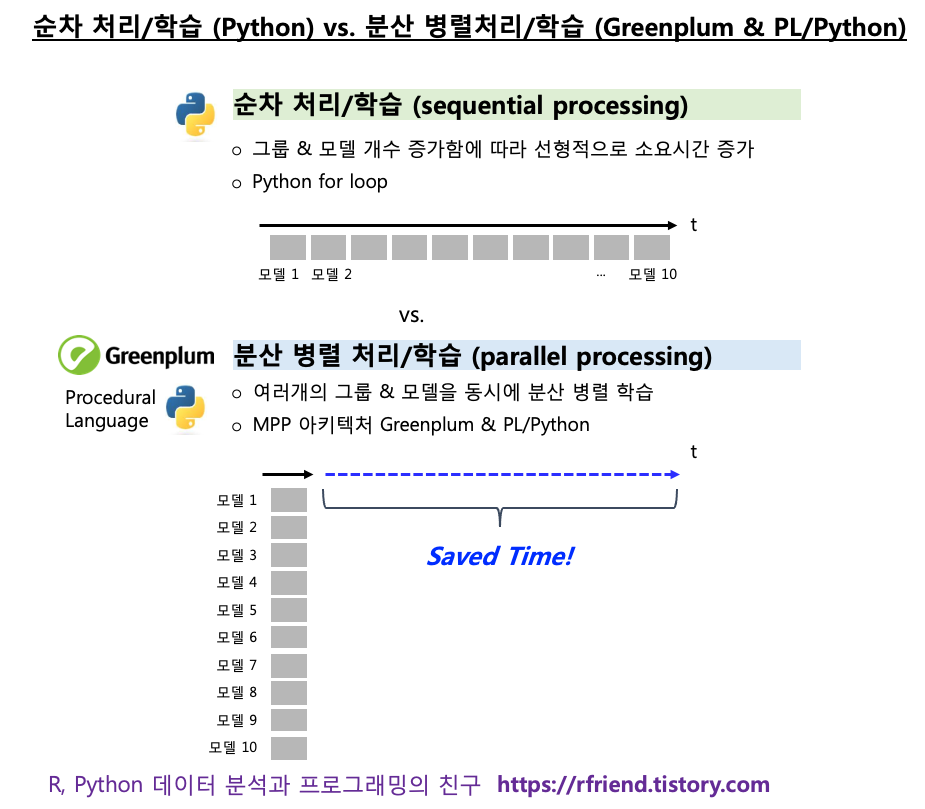
Python에서 for loop 문을 사용하면 순차적으로 처리 (sequential processing) 를 하게 되므로, 일원분산분석을 해야 하는 숫자형 변수의 개수가 많아질 수록 선형적으로 처리 시간이 증가하게 됩니다.
Greenplum에서 PL/Python (또는 PL/R) 을 사용하면 일원분산분석의 대상의 되는 숫자형 변수가 매우 많고 데이터 크기가 크더라도 분산병렬처리 (distributed parallel processing) 하여 ANOVA test 를 처리할 수 있으므로 신속하게 분석을 할 수 있는 장점이 있습니다.
더불어서, 데이터가 저장되어 있는 DB에서 데이터의 이동 없이(no data I/O, no data movement), In-DB 처리/분석이 되므로 work-flow 가 간소화되고 batch scheduling 하기에도 편리한 장점이 있습니다.
만약 데이터는 DB에 있고, 애플리케이션도 DB를 바라보고 있고, 분석은 Python 서버 (또는 R 서버)에서 하는 경우라면, 분석을 위해 DB에서 데이터를 samfile 로 떨구고, 이를 Python에서 pd.read_csv()로 읽어들여서 분석하고, 다시 결과를 text file로 떨구고, 이 text file을 ftp로 DB 서버로 이동하고, psql로 COPY 문으로 테이블에 insert 하는 workflow ... 관리 포인트가 많아서 정신 사납고 복잡하지요?!
자, 이제 Greenplum database에서 PL/Python으로 일원분산분석을 병렬처리해서 집단 간 여러개의 개별 변수별 평균 차이가 있는지 검정을 해보겠습니다.
(1) 여러 개의 변수를 가지는 샘플 데이터 만들기
정규분포로 부터 난수를 발생시켜서 3개 그룹별로 각 30개 씩의 샘플 데이터를 생성하였습니다. 숫자형 변수로는 'x1', 'x2', 'x3', 'x4'의 네 개의 변수를 생성하였습니다. 이중에서 'x1', 'x2'는 3개 집단이 모두 동일한 평균과 분산을 가지는 정규분포로 부터 샘플을 추출하였고, 반면에 'x3', 'x4'는 3개 집단 중 2개는 동일한 평균과 분산의 정규분포로 부터 샘플을 추출하고 나머지 1개 집단은 다른 평균을 가지는 정규분포로 부터 샘플을 추출하였습니다. (뒤에 one-way ANOVA 검정을 해보면 'x3', 'x4'에 대한 집단 간 평균 차이가 있는 것으로 결과가 나오겠지요?!)
import numpy as np
import pandas as pd
# generate 90 IDs
id = np.arange(90) + 1
# Create 3 groups with 30 observations in each group.
from itertools import chain, repeat
grp = list(chain.from_iterable((repeat(number, 30) for number in [1, 2, 3])))
# generate random numbers per each groups from normal distribution
np.random.seed(1004)
# for 'x1' from group 1, 2 and 3
x1_g1 = np.random.normal(0, 1, 30)
x1_g2 = np.random.normal(0, 1, 30)
x1_g3 = np.random.normal(0, 1, 30)
# for 'x2' from group 1, 2 and 3
x2_g1 = np.random.normal(10, 1, 30)
x2_g2 = np.random.normal(10, 1, 30)
x2_g3 = np.random.normal(10, 1, 30)
# for 'x3' from group 1, 2 and 3
x3_g1 = np.random.normal(30, 1, 30)
x3_g2 = np.random.normal(30, 1, 30)
x3_g3 = np.random.normal(50, 1, 30)
# different mean
x4_g1 = np.random.normal(50, 1, 30)
x4_g2 = np.random.normal(50, 1, 30)
x4_g3 = np.random.normal(20, 1, 30)
# different mean # make a DataFrame with all together
df = pd.DataFrame({
'id': id, 'grp': grp,
'x1': np.concatenate([x1_g1, x1_g2, x1_g3]),
'x2': np.concatenate([x2_g1, x2_g2, x2_g3]),
'x3': np.concatenate([x3_g1, x3_g2, x3_g3]),
'x4': np.concatenate([x4_g1, x4_g2, x4_g3])})
df.head()
id
grp
x1
x2
x3
x4
1
1
0.594403
10.910982
29.431739
49.232193
2
1
0.402609
9.145831
28.548873
50.434544
3
1
-0.805162
9.714561
30.505179
49.459769
4
1
0.115126
8.885289
29.218484
50.040593
5
1
-0.753065
10.230208
30.072990
49.601211
위에서 만든 가상의 샘플 데이터를 Greenplum DB에 'sample_tbl' 이라는 이름의 테이블로 생성해보겠습니다. Python pandas의 to_sql() 메소드를 사용하면 pandas DataFrame을 쉽게 Greenplum DB (또는 PostgreSQL DB)에 uploading 할 수 있습니다.
# creating a table in Greenplum by importing pandas DataFrame
conn = "postgresql://gpadmin:changeme@localhost:5432/demo"
df.to_sql('sample_tbl',
conn,
schema = 'public',
if_exists = 'replace',
index = False)
Jupyter Notebook에서 Greenplum DB에 접속해서 SQL로 이후 작업을 진행하겠습니다.
PL/Python에서 작업하기 쉽도록 테이블 구조를 wide format에서 long format 으로 변경하겠습니다. union all 로 해서 칼럼 갯수 만큼 위/아래로 append 해나가면 되는데요, DB 에서 이런 형식의 데이터를 관리하고 있다면 아마도 이미 long format 으로 관리하고 있을 가능성이 높습니다. (새로운 데이터가 수집되면 계속 insert into 하면서 행을 밑으로 계속 쌓아갈 것이므로...)
%%sql
-- reshaping a table from wide to long
drop table if exists sample_tbl_long;
create table sample_tbl_long as (
select id, grp, 'x1' as col, x1 as val from sample_tbl
union all
select id, grp, 'x2' as col, x2 as val from sample_tbl
union all
select id, grp, 'x3' as col, x3 as val from sample_tbl
union all
select id, grp, 'x4' as col, x4 as val from sample_tbl
) distributed randomly;
* postgresql://gpadmin:***@localhost:5432/demo
Done.
360 rows affected.
%sql select * from sample_tbl_long order by id, grp, col limit 8;
[Out]
* postgresql://gpadmin:***@localhost:5432/demo
8 rows affected.
id grp col val
1 1 x1 0.594403067344276
1 1 x2 10.9109819091195
1 1 x3 29.4317394311833
1 1 x4 49.2321928075563
2 1 x1 0.402608708677309
2 1 x2 9.14583073327387
2 1 x3 28.54887315985
2 1 x4 50.4345438286737
(3) 분석 결과 반환 composite type 정의
일원분산분석 결과를 반환받을 때 각 분석 대상 변수 별로 (a) F-통계량, (b) p-value 의 두 개 값을 float8 데이터 형태로 반환받는 composite type 을 미리 정의해놓겠습니다.
%%sql
-- Creating a coposite return type
drop type if exists plpy_anova_type cascade;
create type plpy_anova_type as (
f_stat float8
, p_val float8
);
* postgresql://gpadmin:***@localhost:5432/demo
Done.
Done.
(4) 일원분산분석(one-way ANOVA) PL/Python 사용자 정의함수 정의
집단('grp')과 측정값('val')을 input 으로 받고, statsmodels 모듈의 sm.stats.anova_lm() 메소드로 일원분산분석을 하여 결과 테이블에서 'F-통계량'과 'p-value'만 인덱싱해서 반환하는 PL/Python 사용자 정의 함수를 정의해보겠습니다.
%%sql
-- Creating the PL/Python UDF of ANOVA
drop function if exists plpy_anova_func(text[], float8[]);
create or replace function plpy_anova_func(grp text[], val float8[])
returns plpy_anova_type
as $$
import pandas as pd
import statsmodels.api as sm
from statsmodels.formula.api import ols
df = pd.DataFrame({'grp': grp, 'val': val})
model = ols('val ~ grp', data=df).fit()
anova_result = sm.stats.anova_lm(model, typ=1)
return {'f_stat': anova_result.loc['grp', 'F'],
'p_val': anova_result.loc['grp', 'PR(>F)']}
$$ language 'plpythonu';
* postgresql://gpadmin:***@localhost:5432/demo
Done.
Done.
(5) 일원분산분석(one-way ANOVA) PL/Python 함수 분산병렬처리 실행
PL/Python 사용자 정의함수는 SQL query 문으로 실행합니다. 이때 PL/Python 이 'F-통계량'과 'p-value'를 반환하도록 UDF를 정의했으므로 아래처럼 (plpy_anova_func(grp_arr, val_arr)).* 처럼 ().* 으로 해서 모든 결과('F-통계량' & 'p-value')를 반환하도록 해줘야 합니다. (빼먹고 실수하기 쉬우므로 ().*를 빼먹지 않도록 주의가 필요합니다)
이렇게 하면 변수별로 segment nodes 에서 분산병렬로 각각 처리가 되므로, 변수가 수백~수천개가 있더라도 (segment nodes가 많이 있다는 가정하에) 분산병렬처리되어 신속하게 분석을 할 수 있습니다. 그리고 결과는 바로 Greenplum DB table에 적재가 되므로 이후의 application이나 API service에서 가져다 쓰기에도 무척 편리합니다.
%%sql
-- Executing the PL/Python UDF of ANOVA
drop table if exists plpy_anova_table;
create table plpy_anova_table as (
select
col
, (plpy_anova_func(grp_arr, val_arr)).*
from (
select
col
, array_agg(grp::text order by id) as grp_arr
, array_agg(val::float8 order by id) as val_arr
from sample_tbl_long
group by col
) a
) distributed randomly;
* postgresql://gpadmin:***@localhost:5432/demo
Done.
4 rows affected.
총 4개의 각 변수별 일원분산분석 결과를 조회해보면 아래와 같습니다.
%%sql
select * from plpy_anova_table order by col;
[Out]
* postgresql://gpadmin:***@localhost:5432/demo
4 rows affected.
col f_stat p_val
x1 0.773700830155438 0.46445029458511966
x2 0.20615939957339052 0.8140997216173114
x3 4520.512608893724 1.2379278415456727e-88
x4 9080.286130418674 1.015467388498996e-101
Greenplum DB는 여려개의 PostgreSQL DB를 합쳐놓은 shared-nothing architecture 의 MPP (Massively Parallel Processing) Database 입니다. 손과 발이 되는 여러개의 cluster nodes에 머리가 되는 Master host 가 조율/조정/지시해가면서 분산하여 병렬로 일을 시키고, 각 cluster nodes의 연산처리 결과를 master host 가 모아서 취합하여 최종 결과를 반환하는 방식으로 일을 하기 때문에 (1) 대용량 데이터도 (2) 매우 빠르게 처리할 수 있습니다.
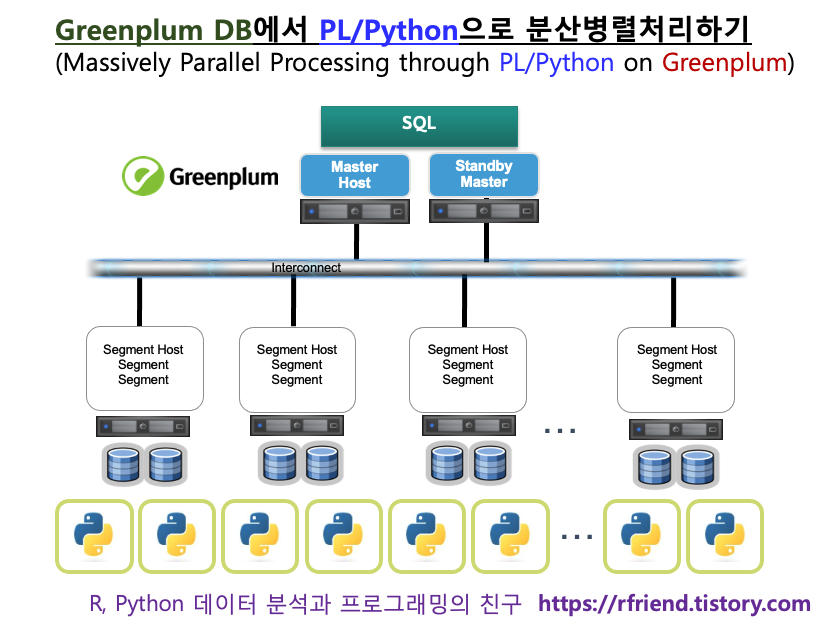
이번 포스팅에서는 여기에서 한발 더 나아가서, Procedural Language Extension (PL/X) 을 사용하여 Python, R, Java, C, Perl, SQL 등의 프로그래밍 언어를 Greenplum DB 내에서 사용하여 데이터의 이동 없이 분산 병렬처리하는 방법을 소개하겠습니다.
Massively Parallel Processing through PL/Python on Greenplum DB
난수를 발생시켜서 만든 가상의 데이터셋을 사용하여 PL/Python으로 Random Forest의 Feature Importance를 숫자형 목표변수('y1_num') 그룹과 범주형 목표변수('y2_cat') 그룹 별로 분산병렬처리하는 간단한 예를 들어보겠습니다.
(b) y2_cat = case when (x4*7.0 + x5*6.0 - x6*4.0 + x4*5.0 + 0.001*random()) >= 9 then 1 else 0 의 함수로 부터 만듦.
(2) PL/Python 함수 정의하기 : (a) 숫자형 목표변수('y1_num') 그룹은 Random Forest Regressor를, (b) 범주형 목표변수('y2_cat') 그룹은 Random Forest Classifier 를 각 그룹별로 분산병렬로 훈련시킨 후, : 각 그룹별 Random Forest Regressor 모델별 200개의 숫자형 변수별 Feature Importance를 반환
(3) PL/Python 함수 실행하기
(4) 각 그룹별 변수별 Random Forest 의 Feature Importance 를 조회하기
를 해 보겠습니다.
(1) 가상의 예제 데이터셋 만들기
- group: 2개의 그룹
(목표변수로 하나는 숫자형, 하나는 범주형 값을 가지는 2개의 X&y 데이터셋 그룹을 생성함.)
(b) y2_cat = case when (x4*7.0 + x5*6.0 - x6*4.0 + x4*5.0 + 0.001*random()) >= 9 then 1 else 0
(y1_num, y2_cat 값을 만들때 x 변수에 곱하는데 사용한 *7.0, *6.0, *5.0 은 아무런 의미 없습니다.
그냥 가상의 예제 샘플 데이터를 만들려고 임의로 선택해서 곱해준 값입니다.)
아래의 예제는 In-DB 처리를 염두에 두고, 200개의 숫자형 X 변수들과 한개의 숫자형 y 변수를 DB의 테이블에 "col_nm"이라는 칼럼에는 변수 이름을, "col_val"에는 변수 값을 long form 으로 생성해서 저장해 놓은 것입니다.
나중에 PL/Python의 함수 안에서 pandas 의 pivot_table() 함수를 사용해서 wide form 으로 DataFrame의 형태를 재구조화해서 random forest 를 분석하게 됩니다.
제 맥북에서 도커로 만든 Greenplum 에는 1개의 master node와 2개의 segment nodes 가 있는데요, 편의상 cross join 으로 똑같은 칼럼과 값을 가지는 설명변수 X 데이터셋을 2의 segment nodes에 replication 해서 그룹1('grp=1'), 그룹2('grp=2')를 만들었습니다.
그리고 여기에 목표변수 y 값으로는 숫자형 목표변수 'y1_num' 칼럼의 값에 대해서는 그룹1('grp=1'), 범주형 목표변수 'y2_cat' 칼럼의 값에 대해서는 그룹2('grp=2')를 부여한 후에, 앞서 만든 설명변수 X 데이터셋에 union all 로 'y1_num'과 'y2_cat' 데이터를 합쳐서 최종으로 하나의 long format의 테이블을 만들었습니다.
첫번째 그룹은 200개의 숫자형 X 변수 중에서 'x1', 'x2', 'x3'의 3개 변수만 숫자형 목표변수(numeric target variable) 인 'y1_num'과 관련이 있고, 나머지 194개의 설명변수와는 관련이 없게끔 y1_num = x1*7.0 + x2*6.0 + x3*5.0 + 0.001*random() 함수를 사용해서 'y1_num' 을 만들었습니다 (*7.0, *6.0, *5.0 은 가상의 예제 데이터를 만들기 위해 임의로 선택한 값으로서, 아무 이유 없습니다). 뒤에서 PL/Python으로 Random Forest Regressor 의 feature importance 결과에서 'x1', 'x2', 'x3' 변수의 Feature Importance 값이 높게 나오는지 살펴보겠습니다.
두번째 그룹은 200개의 숫자형 X변수 중에서 'x4', 'x5', 'x6'의 3개 변수만 범주형 목표변수(categorical target variable) 인 'y2_cat'과 관련이 있고, 나머지 194개의 설명변수와는 연관이 없게끔 y2_cat = case when (x4*7.0 + x5*6.0 - x6*4.0 + x4*5.0 + 0.001*random()) >= 9 then 1 else 0 함수로 부터 가상으로 생성하였습니다. 뒤에서 PL/Python으로 Random Forest Classifier 의 feature importance 결과에서 'x4', 'x5', 'x6' 변수의 Feature Importance 값이 높게 나오는지 살펴보겠습니다.
------------------------------------------------------------------
-- Random Forest's Feature Importance using PL/Python on Greenplum
------------------------------------------------------------------
-- (1) Generate sample data
-- 2 groups
-- 100 observations(ID) per group
-- X: 200 numeric input variables per observation(ID)
-- y : a numeric target variable by a function of y = x1*5.0 + x2*4.5 - x3*4.0 + x4*3.5 + 0.001*random()
-- distributed by 'grp' (group)
-- (1-1) 100 IDs of observations
drop table if exists id_tmp;
create table id_tmp (
id integer
) distributed randomly;
insert into id_tmp (select * from generate_series(1, 100, 1));
select * from id_tmp order by id limit 3;
--id
--1
--2
--3
-- (1-2) 200 X variables
drop table if exists x_tmp;
create table x_tmp (
x integer
) distributed randomly;
insert into x_tmp (select * from generate_series(1, 200, 1));
select * from x_tmp order by x limit 3;
--x
--1
--2
--3
-- (1-3) Cross join of ID and Xs
drop table if exists id_x_tmp;
create table id_x_tmp as (
select * from id_tmp
cross join x_tmp
) distributed randomly;
select count(1) from id_x_tmp;
-- 20,000 -- (id 100 * x 200 = 20,000)
select * from id_x_tmp order by id, x limit 3;
--id x
--1 1
--1 2
--1 3
-- (1-4) Generate X values randomly
drop table if exists x_long_tmp;
create table x_long_tmp as (
select
a.id as id
, x
, 'x'||a.x::text as x_col
, round(random()::numeric, 3) as x_val
from id_x_tmp a
) distributed randomly;
select count(1) from x_long_tmp;
-- 20,000
select * from x_long_tmp order by id, x limit 3;
--id x x_col x_val
--1 1 x1 0.956
--1 2 x2 0.123
--1 3 x3 0.716
select min(x_val) as x_min_val, max(x_val) as x_max_val from x_long_tmp;
--x_min_val x_max_val
--0.000 1.000
-- (1-5) create y values
drop table if exists y_tmp;
create table y_tmp as (
select
s.id
, (s.x1*7.0 + s.x2*6.0 + s.x3*5.0 + 0.001*random()) as y1_num -- numeric
, case when (s.x4*7.0 + s.x5*6.0 + s.x6*5.0 + 0.001*random()) >= 9
then 1
else 0
end as y2_cat -- categorical
from (
select distinct(a.id) as id, x1, x2, x3, x4, x5, x6 from x_long_tmp as a
left join (select id, x_val as x1 from x_long_tmp where x_col = 'x1') b
on a.id = b.id
left join (select id, x_val as x2 from x_long_tmp where x_col = 'x2') c
on a.id = c.id
left join (select id, x_val as x3 from x_long_tmp where x_col = 'x3') d
on a.id = d.id
left join (select id, x_val as x4 from x_long_tmp where x_col = 'x4') e
on a.id = e.id
left join (select id, x_val as x5 from x_long_tmp where x_col = 'x5') f
on a.id = f.id
left join (select id, x_val as x6 from x_long_tmp where x_col = 'x6') g
on a.id = g.id
) s
) distributed randomly;
select count(1) from y_tmp;
--100
select * from y_tmp order by id limit 5;
--id y1_num y2_cat
--1 11.0104868695838 1
--2 10.2772997177048 0
--3 7.81790575686749 0
--4 8.89387259676540 1
--5 2.47530914815422 1
-- (1-6) replicate X table to all clusters
-- by the number of 'y' varialbes. (in this case, there are 2 y variables, 'y1_num' and 'y2_cat'
drop table if exists long_x_grp_tmp;
create table long_x_grp_tmp as (
select
b.grp as grp
, a.id as id
, a.x_col as col_nm
, a.x_val as col_val
from x_long_tmp as a
cross join (
select generate_series(1, c.y_col_cnt) as grp
from (
select (count(distinct column_name) - 1) as y_col_cnt
from information_schema.columns
where table_name = 'y_tmp' and table_schema = 'public') c
) as b -- number of clusters
) distributed randomly;
select count(1) from long_x_grp_tmp;
-- 40,000 -- 2 (y_col_cnt) * 20,000 (x_col_cnt)
select * from long_x_grp_tmp order by id limit 5;
--grp id col_nm col_val
--1 1 x161 0.499
--2 1 x114 0.087
--1 1 x170 0.683
--2 1 x4 0.037
--2 1 x45 0.995
-- (1-7) create table in long format with x and y
drop table if exists long_x_y;
create table long_x_y as (
select x.*
from long_x_grp_tmp as x
union all
select 1::int as grp, y1.id as id, 'y1_num'::text as col_nm, y1.y1_num as col_val
from y_tmp as y1
union all
select 2::int as grp, y2.id as id, 'y2_cat'::text as col_nm, y2.y2_cat as col_val
from y_tmp as y2
) distributed randomly;
select count(1) from long_x_y;
-- 40,200 (x 40,000 + y1_num 100 + y2_cat 100)
select grp, count(1) from long_x_y group by 1 order by 1;
--grp count
--1 20100
--2 20100
select * from long_x_y where grp=1 order by id, col_nm desc limit 5;
--grp id col_nm col_val
--1 1 y1_num 11.010
--1 1 x99 0.737
--1 1 x98 0.071
--1 1 x97 0.223
--1 1 x96 0.289
select * from long_x_y where grp=2 order by id, col_nm desc limit 5;
--grp id col_nm col_val
--2 1 y2_cat 1.0
--2 1 x99 0.737
--2 1 x98 0.071
--2 1 x97 0.223
--2 1 x96 0.289
-- drop temparary tables
drop table if exists id_tmp;
drop table if exists x_tmp;
drop table if exists id_x_tmp;
drop table if exists x_long_tmp;
drop table if exists y_tmp;
drop table if exists long_x_grp_tmp;
(2) PL/Python 사용자 정의함수 정의하기
- (2-1) composite return type 정의하기
PL/Python로 분산병렬로 연산한 Random Forest의 feature importance (또는 variable importance) 결과를 반환할 때 텍스트 데이터 유형의 '목표변수 이름(y_col_nm)', '설명변수 이름(x_col_nm)'과 '변수 중요도(feat_impo)' 의 array 형태로 반환하게 됩니다. 반환하는 데이터가 '텍스트'와 'float8' 로 서로 다른 데이터 유형이 섞여 있으므로 composite type 의 return type 을 만들어줍니다. 그리고 PL/Python은 array 형태로 반환하므로 text[], text[] 과 같이 '[]' 로서 array 형태로 반환함을 명시합니다.
-- define composite return type
drop type if exists plpy_rf_feat_impo_type cascade;
create type plpy_rf_feat_impo_type as (
y_col_nm text[]
, x_col_nm text[]
, feat_impo float8[]
);
- (2-2) Random Forest feature importance 결과를 반환하는 PL/Python 함수 정의하기
PL/Python 사용자 정의 함수를 정의할 때는 아래와 같이 PostgreSQL의 Procedural Language 함수 정의하는 표준 SQL 문을 사용합니다.
input data 는 array 형태이므로 칼럼 이름 뒤에 데이터 유형에는 '[]'를 붙여줍니다.
중간의 $$ ... python code block ... $$ 부분에 pure python code 를 넣어줍니다.
제일 마지막에 PL/X 언어로서 language 'plpythonu' 으로 PL/Python 임을 명시적으로 지정해줍니다.
create or replace function function_name(column1 data_type1[], column2 data_type2[], ...) returns return_type as $$ ... python code block ... $$ language 'plpythonu';
만약 PL/Container 를 사용한다면 명령 프롬프트 창에서 아래처럼 $ plcontainer runtime-show 로 Runtime ID를 확인 한 후에,
PL/Python 코드블록의 시작 부분에 $$ # container: container_Runtime_ID 로서 사용하고자 하는 docker container 의 runtime ID를 지정해주고, 제일 마지막 부분에 $$ language 'plcontainer'; 로 확장 언어를 'plcontainer'로 지정해주면 됩니다. PL/Container를 사용하면 최신의 Python 3.x 버전을 사용할 수 있는 장점이 있습니다.
create or replace function function_name(column1 data_type1[], column2 data_type2[], ...) returns return_type as $$ # container: plc_python3_shared ... python code block ... $$ LANGUAGE 'plcontainer';
아래 코드에서는 array 형태의 'id', 'col_nm', 'col_val'의 3개 칼럼을 input 으로 받아서 먼저 pandas DataFrame으로 만들어 준 후에, 이를 pandas pivot_table() 함수를 사용해서 long form --> wide form 으로 데이터를 재구조화 해주었습니다.
다음으로, 숫자형의 목표변수('y1_num')를 가지는 그룹1 데이터셋에 대해서는 sklearn 패키지의 RandomForestRegressor 클래스를 사용해서 Random Forest 모델을 훈련하고, 범주형의 목표변수('y2_cat')를 가지는 그룹2의 데이터셋에 대해서는 sklearn 패키지의 RandomForestClassifier 클래스를 사용하여 모델을 훈련하였습니다. 그리고 'rf_regr_fitted.feature_importances_' , 'rf_clas_fitted.feature_importances_'를 사용해서 200개의 각 변수별 feature importance 속성을 리스트로 가져왔습니다.
마지막에 return {'y_col_nm': y_col_nm, 'x_col_nm': x_col_nm_list, 'feat_impo': feat_impo} 에서 전체 변수 리스트와 변수 중요도 연산 결과를 array 형태로 반환하게 했습니다.
----------------------------------
-- PL/Python UDF for Random Forest
----------------------------------
-- define PL/Python function
drop function if exists plpy_rf_feat_impo_func(text[], text[], text[]);
create or replace function plpy_rf_feat_impo_func(
id_arr text[]
, col_nm_arr text[]
, col_val_arr text[]
) returns plpy_rf_feat_impo_type as
$$
#import numpy as np
import pandas as pd
# making a DataFrame
xy_df = pd.DataFrame({
'id': id_arr
, 'col_nm': col_nm_arr
, 'col_val': col_val_arr
})
# pivoting a table
xy_pvt = pd.pivot_table(xy_df
, index = ['id']
, columns = 'col_nm'
, values = 'col_val'
, aggfunc = 'first'
, fill_value = 0)
X = xy_pvt[xy_pvt.columns.difference(['y1_num', 'y2_cat'])]
X = X.astype(float)
x_col_nm_list = X.columns
# UDF for Feature Importance by RandomForestRegressor
def rf_regr_feat_impo(X, y):
# training RandomForestRegressor
from sklearn.ensemble import RandomForestRegressor
rf_regr = RandomForestRegressor(n_estimators=200)
rf_regr_fitted = rf_regr.fit(X, y)
# The impurity-based feature importances.
rf_regr_feat_impo = rf_regr_fitted.feature_importances_
return rf_regr_feat_impo
# UDF for Feature Importance by RandomForestClassifier
def rf_clas_feat_impo(X, y):
# training RandomForestClassifier with balanced class_weight
from sklearn.ensemble import RandomForestClassifier
rf_clas = RandomForestClassifier(n_estimators=200, class_weight='balanced')
rf_clas_fitted = rf_clas.fit(X, y)
# The impurity-based feature importances.
rf_clas_feat_impo = rf_clas_fitted.feature_importances_
return rf_clas_feat_impo
# training RandomForest and getting variable(feature) importance
if 'y1_num' in xy_pvt.columns:
y_target = 'y1_num'
y = xy_pvt[y_target]
feat_impo = rf_regr_feat_impo(X, y)
if 'y2_cat' in xy_pvt.columns:
y_target = 'y2_cat'
y = xy_pvt[y_target]
y = y.astype(int)
feat_impo = rf_clas_feat_impo(X, y)
feat_impo_df = pd.DataFrame({
'y_col_nm': y_target
, 'x_col_nm': x_col_nm_list
, 'feat_impo': feat_impo
})
# returning the results of feature importances
return {
'y_col_nm': feat_impo_df['y_col_nm']
, 'x_col_nm': feat_impo_df['x_col_nm']
, 'feat_impo': feat_impo_df['feat_impo']
}
$$ language 'plpythonu';
(3) PL/Python 함수 실행하기
PL/Python 함수를 실행할 때는 표준 SQL Query 문의 "SELECT group_name, pl_python_function() FROM table_name" 처럼 함수를 SELECT 문으로 직접 호출해서 사용합니다.
PL/Python의 input 으로 array 형태의 데이터를 넣어주므로, 아래처럼 FROM 절의 sub query 에 array_agg() 함수로 먼저 데이터를 'grp' 그룹 별로 array aggregation 하였습니다.
PL/Python 함수의 전체 결과를 모두 반환할 것이므로(plpy_rf_var_impo_func()).* 처럼 함수를 모두 감싼 후에 ().* 를 사용하였습니다. (실수해서 빼먹기 쉬우므로 유의하시기 바랍니다.)
목표변수가 숫자형('y1_num')과 범주형('y2_cat')'별로 그룹1과 그룹2로 나누어서, 'grp' 그룹별로 분산병렬로 Random Forest 분석이 진행되며, Variable importance 결과를 'grp' 그룹 ID를 기준으로 분산해서 저장(distributed by (grp);)하게끔 해주었습니다.
-- execute PL/Python function
drop table if exists rf_feat_impo_result;
create table rf_feat_impo_result as (
select
a.grp
, (plpy_rf_feat_impo_func(
a.id_arr
, a.col_nm_arr
, a.col_val_arr
)).*
from (
select
c.grp
, array_agg(c.id::text order by id) as id_arr
, array_agg(c.col_nm::text order by id) as col_nm_arr
, array_agg(c.col_val::text order by id) as col_val_arr
from long_x_y as c
group by grp
) a
) distributed by (grp);
(4) 각 그룹별 변수별 Random Forest 의 Feature Importance 조회하기
위의 (3)번을 실행해서 나온 결과를 조회하면 아래와 같이 'grp=1', 'grp=2' 별로 각 칼럼별로 Random Forest에 의해 계산된 변수 중요도(variable importance) 가 array 형태로 저장되어 있음을 알 수 있습니다.
select count(1) from rf_feat_impo_result;
-- 2
-- results in array-format
select * from rf_feat_impo_result order by grp;
plpython_random_forest_feature_importance_array
위의 array 형태의 결과는 사람이 눈으로 보기에 불편하므로, unnest() 함수를 써서 long form 으로 길게 풀어서 결과를 조회해 보겠습니다.
이번 예제에서는 난수로 생성한 X설명변수에 임의로 함수를 사용해서 숫자형 목표변수('y1_num')를 가지는 그룹1에 대해서는 'x1', 'x2', 'x3' 의 순서대로 변수가 중요하고, 범주형 목표변수('y2_cat')를 가지는 그룹2에서는 'x4', 'x5', 'x6'의 순서대로 변수가 중요하게 가상의 예제 데이터셋을 만들어주었습니다. (random() 함수로 난수를 생성해서 예제 데이터셋을 만들었으므로, 매번 실행할 때마다 숫자는 달라집니다).
아래 feature importance 결과를 보니, 역시 그룹1의 데이터셋에 대해서는 'x1', 'x2', 'x3' 변수가 중요하게 나왔고, 그룹2의 데이터셋에 대해서는 'x4', 'x5', 'x6' 변수가 중요하다고 나왔네요.
-- display the results using unnest()
select
grp
, unnest(y_col_nm) as y_col_nm
, unnest(x_col_nm) as x_col_nm
, unnest(feat_impo) as feat_impo
from rf_feat_impo_result
where grp = 1
order by feat_impo desc
limit 10;
--grp y_col_nm x_col_nm feat_impo
--1 y1_num x1 0.4538784064497847
--1 y1_num x2 0.1328532144509229
--1 y1_num x3 0.10484121806286809
--1 y1_num x34 0.006843343319633915
--1 y1_num x42 0.006804819286213849
--1 y1_num x182 0.005771113354638556
--1 y1_num x143 0.005220090515711377
--1 y1_num x154 0.005101366229848041
--1 y1_num x46 0.004571420249598611
--1 y1_num x57 0.004375780774099066
select
grp
, unnest(y_col_nm) as y_col_nm
, unnest(x_col_nm) as x_col_nm
, unnest(feat_impo) as feat_impo
from rf_feat_impo_result
where grp = 2
order by feat_impo desc
limit 10;
--grp y_col_nm x_col_nm feat_impo
--2 y2_cat x4 0.07490484681851341
--2 y2_cat x5 0.04099924609654107
--2 y2_cat x6 0.03431643243509608
--2 y2_cat x12 0.01474464870781392
--2 y2_cat x40 0.013865405628514437
--2 y2_cat x37 0.013435535581862938
--2 y2_cat x167 0.013236591006394367
--2 y2_cat x133 0.012570295279560963
--2 y2_cat x142 0.012177597741973058
--2 y2_cat x116 0.011713289042962961
-- The end.