[Greenplum PostGIS] spatial_ref_sys 테이블에 신규 좌표계 등록하고 좌표 변환하기
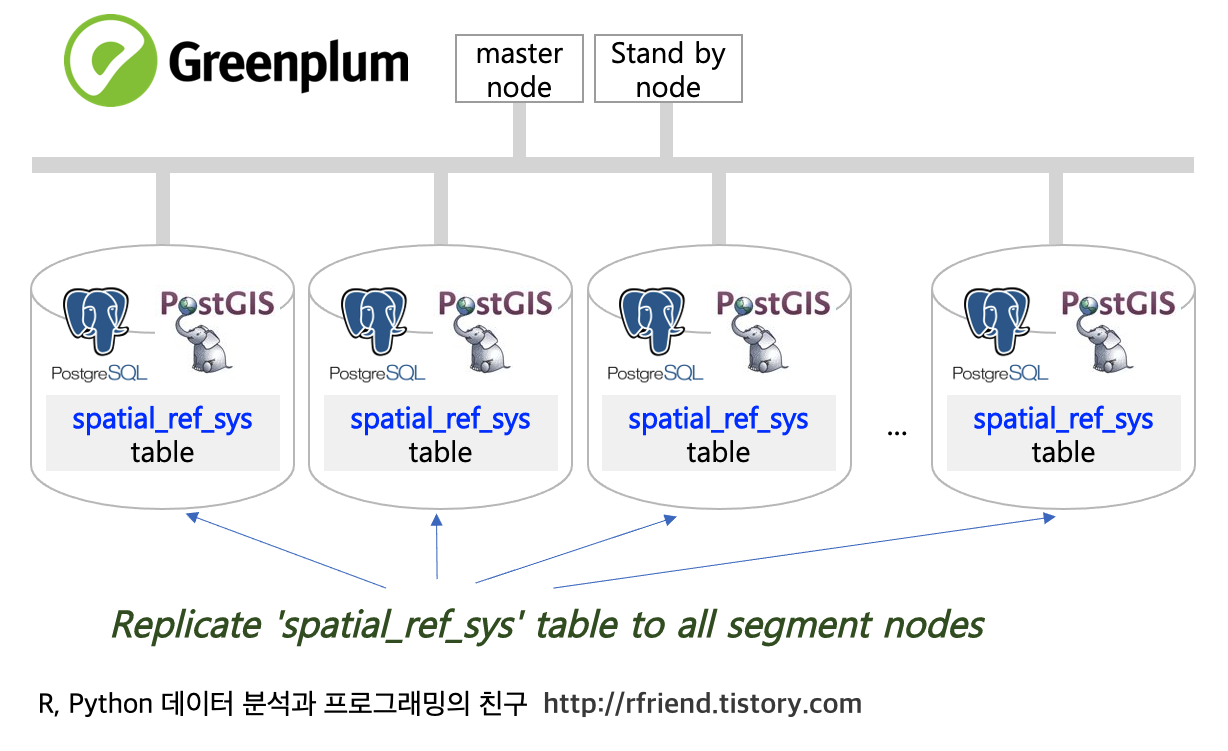
Greenplum and PostgreSQL Database 2021. 3. 14. 18:01지난번 포스팅 (rfriend.tistory.com/631) 에서는 Greenplum DB에서 PostGIS 를 사용하여 좌표 인식, 변환, 계산을 하기 위해서 필요한 좌표계 참조 테이블인 PostGIS의 spatial_ref_sys 테이블을 모든 segment nodes 에 복제하는 방법을 소개하였습니다.
이번 포스팅에서는 PostGIS의 원래의 spatial_ref_sys 테이블에는 없는 좌표계 (Coordinate Reference System) 를 사용해서 두 개의 좌표계간 변환을 하는 방법을 소개하겠습니다.
(방법 1) spatial_ref_sys 테이블에 새로운 좌표계를 등록하고 (즉, insert into spatial_ref_sys 테이블),
--> PostGIS의 ST_Transform() 함수를 사용해서 좌표계 간 변환하기
(방법 2) PostGIS_Transform_Geometry() 함수를 사용해서 직접 새로운 좌표계로 변환하기

예로서 KATECH 좌표계와 WGS84 좌표계 간 변환하는 방법을 소개하겠습니다.
참고로 KATECH 좌표계는 국내의 포털 사이트의 지도 API 서비스나 국내 네비게이션에서 사용하고 있는 비공식 좌표계로서, 원점으로 위도 38도, 경도 128도의 단일원점을 사용하기 때문에 TM128 좌표계라고도 합니다. KATECH 좌표계는 국내 CNS(자동차 항법장치)를 위해서 만들어진 것으로 3개(서부,중부,동부)의 투영원점을 위도38도, 경도127도 30분의 단일원점으로 통합한 것입니다. (* 출처: hmjkor.tistory.com/377).
(방법 1) (step 1) spatial_ref_sys 테이블에 새로운 좌표계를 등록하고 (즉, insert into spatial_ref_sys 테이블),
--> (step 2) PostGIS의 ST_Transform() 함수를 사용해서 좌표계 간 변환하기
(step 1) spatial_ref_sys 테이블에 미등록되어 있는 KATECH 좌표계를 등록하기
* 사전에 Greenplum DB 의 모든 segment nodes에 spatial_ref_sys 테이블이 복제(replication)되어 있어야 합니다.
(참고: rfriend.tistory.com/631)
* 아래처럼 insert into 쿼리 구문으로 좌표계 정보를 spatial_ref_sys 테이블에 추가해줍니다. 이때, SRID 번호는 사용자가 알아서 지정해주면 됩니다.
* 아래 KATECH 좌표계의 정보는 다시 한번 각 사용처에서 사용하고 있는 것과 동일한 것인지 다시 한번 확인해보시기 바랍니다.(critical 한 정보이므로 반드시 아래 숫자 맞는지 다시 한번 double check 해보세요!)
-- inserting KATECH CRS into spatial_ref_sys table
INSERT into spatial_ref_sys (srid, auth_name, auth_srid, proj4text, srtext)
values (
10000,
'sr-org',
8030,
'+proj=tmerc +lat_0=38 +lon_0=128 +k=0.9999 +x_0=400000 +y_0=600000 +ellps=bessel +towgs84=-145.907,505.034,685.756,-1.162,2.347,1.592,6.342 +units=m +no_defs',
'PROJCS["Katech",GEOGCS["Bessel 1841",
DATUM["unknown",SPHEROID["bessel",6377397.155,299.1528128],
TOWGS84[-145.907,505.034,685.756,-1.162,2.347,1.592,6.342]],PRIMEM["Greenwich",0],
UNIT["degree",0.0174532925199433]],
PROJECTION["Transverse_Mercator"],
PARAMETER["latitude_of_origin",38],
PARAMETER["central_meridian",128],
PARAMETER["scale_factor",0.9999],
PARAMETER["false_easting",400000],
PARAMETER["false_northing",600000],
UNIT["Meter",1]]'
);
(step 2) PostGIS 의 ST_Transform() 함수를 사용해서 WGS 84 (SRID 4326) 좌표계를 KATECH (SRID 10000, 위에서 지정한 번호로서, SRID 번호는 지정하기 나름임) 좌표계로 변환.
-- (1st method) using ST_Transform() and CRS information from spatial_ref_sys table
SELECT ST_Transform(ST_SetSRID(ST_Point(-123.365556, 48.428611), 4326), 10000) AS katech_geom;
(방법 2) PostGIS_Transform_Geometry() 함수를 사용해서 직접 새로운 좌표계로 변환하기
두번째는 spatial_ref_sys 테이블에 새로운 좌표계를 등록할 필요없이, PostGIS_Transform_Geometry() 함수안에 (a) 기존의 변환하려는 대상 좌표계 : proj_from, (b) 앞으로 변환하려고 하는 기준 좌표계 : proj_to 를 직접 넣어주는 방식입니다.
위의 (방법 1)에서 사용한 PostGIS의 ST_Transform() 함수의 소스 코드를 까서 살펴보면 그 안에 PostGIS_Transform_Geometry() 함수를 사용하고 있습니다.
아래의 예는 table_with_geometry 라는 from 절의 테이블에서 x_axis, y_axis 의 경도, 위도 좌표를 가져와서 25를 더하고 뺀 값을 ST_MakeEnvelope() 함수로 만든 사각형 Polygon 의 좌표를 WGS 84 에서 KATECH 좌표계로 PostGIS_Transform_Geometry() 함수를 써서 변환해본 것입니다.
이렇게 수작업으로 하면 Greenplum DB의 각 segment nodes에 복제되어 있는 spatial_ref_sys 테이블에 (방법 1 - a) 처럼 KATECH 좌표계를 미리 등록 (insert into) 하지 않고 바로 사용할 수 있는 장점이 있습니다. 하지만, 이런 좌표계 변환을 여러 사용처에서, 반복적으로 해야 하는 경우라면 매번 이렇게 복잡하게 좌표계 정보를 직접 입력하는 것은 번거로고 어려운 뿐만 아니라, human error 를 유발할 위험도 다분히 있기 때문에 추천하지는 않습니다.
-- (2nd Method) using PostGIS_Transform_Geometry() function directly
SELECT
PostGIS_Transform_Geometry(
-- geom
ST_Union(ST_MakeEnvelope(x_axis::integer -25, y_axis::integer - 25, x_axis::integer + 25, y_axis::integer + 25, 6645))
-- proj_from
, ‘+proj=tmerc +lat_0=38 +lon_0=128 +k=0.9999 +x_0=400000 +y_0=600000 _ellps=bessel +units=m +no_defs +towgs84=-115.80,474.99,674.11,1.16,-2.31,-1.63,6.43’
-- proj_to
, ‘+proj=tmerc +lat_0=38 +lon_0=128 +k=0.9999 +x_0=400000 +y_0=600000 +ellps=bessel +towgs84=-145.907,505.034,685.756,-1.162,2.347,1.592,6.342 +units=m +no_defs’
-- SRID
, 5179)
FROM table_with_geometry …;
이번 포스팅이 많은 도움이 되었기를 바랍니다.
행복한 데이터 과학자 되세요! :-)