이번 포스팅에서는 PostgreSQL, Greenplum Database에서 여러개의 테이블을 Key 값을 기준으로 JOIN 구문을 사용하여 연결하는 다양한 방법을 소개하겠습니다. 그리고 두 테이블 내 관측치 간의 모든 가능한 조합을 반환해주는 CROSS JOIN 에 대해서도 마지막에 소개하겠습니다. (DB 종류에 상관없이 join SQL query는 거의 비슷합니다.)
(1) INNER JOIN
(2) LEFT JOIN
(3) RIGHT JOIN
(4) FULL JOIN
(5) 3개 이상 복수개의 테이블을 JOIN 으로 연결하기
(6) CROSS JOIN
joining two tables in postgresql
먼저 예제로 사용한 간단한 2개의 테이블을 만들어보겠습니다. 두 테이블을 연결할 수 있는 공통의 Key값으로서 'id'라는 이름의 칼럼을 두 테이블이 모두 가지고 있습니다.
'tbl1' 과 'tbl2'는 Key 'id'를 기준으로 id = [2, 3, 4] 가 서로 동일하게 존재하며, 'tbl1'의 id = [1]은 'tbl1'에만 존재하고, 'tbl2'의 id = [5] 는 'tbl2'에만 존재합니다. 각 JOIN 방법 별로 결과가 어떻게 달라지는지 유심히 살펴보시기 바랍니다.
-- Creating two sample tables
-- sample table 1
DROP TABLE IF EXISTS tbl1;
CREATE TABLE tbl1 (
id int
, x text
) DISTRIBUTED RANDOMLY;
INSERT INTO tbl1 VALUES (1, 'a'), (2, 'b'), (3, 'c'), (4, 'd');
SELECT * FROM tbl1 ORDER BY id;
--id x
--1 a
--2 b
--3 c
--4 d
-- sample table 2
DROP TABLE IF EXISTS tbl2;
CREATE TABLE tbl2 (
id int
, y text
) DISTRIBUTED RANDOMLY;
INSERT INTO tbl2 VALUES (2, 'e'), (3, 'f'), (4, 'g'), (5, 'h');
SELECT * FROM tbl2 ORDER BY id;
--id y
--2 e
--3 f
--4 g
--5 h
(1) INNER JOIN
INNER JOIN 은 두 테이블의 Key 값을 기준으로 교집합에 해당하는 값들만 반환합니다. 두 테이블에서 Key 값이 겹치지 않는 값들은 제거되었습니다.
--------------
-- INNER JOIN
--------------
SELECT a.id, a.x, b.y
FROM tbl1 AS a
INNER JOIN tbl2 AS b
ON a.id = b.id;
--id x y
--2 b e
--3 c f
--4 d g
(2) LEFT OUTER JOIN
LEFT OUTER JOIN 은 왼쪽 테이블을 기준으로 Key값이 서로 같은 오른쪽 테이블의 값들을 왼쪽 테이블에 연결해줍니다. 아래의 예에서는 왼쪽의 'tbl1'의 값들은 100% 모두 있고, LEFT OUTER JOIN 으로 연결해준 오른쪽 'tbl2' 테이블의 경우 id = [5] 의 값이 제거된 채 id = [2, 3, 4] 에 해당하는 값들만 'tbl1'과 연결이 되었습니다. 그리고 왼쪽 'tbl1'에는 있지만 오른쪽 'tbl2'에는 없는 id = [1] 에 해당하는 값의 경우 y = [NULL] 값을 반환하였습니다.
-------------------
-- LEFT OUTER JOIN
-------------------
SELECT a.id, x, y
FROM tbl1 AS a
LEFT OUTER JOIN tbl2 AS b
ON a.id = b.id;
--id x y
--1 a [NULL]
--2 b e
--3 c f
--4 d g
(3) RIGHT OUTER JOIN
RIGHT OUTER JOIN 은 LEFT OUTER JOIN 과 정반대라고 생각하면 이해하기 쉽습니다. 이번에는 오른쪽 테이블을 기준으로 Key 값이 같은 왼쪽 테이블의 값을 오른쪽 테이블에 연결해줍니다.
아래 RIGHT OUTER JOIN 예에서는 오른쪽 테이블은 'tbl2'는 100% 모두 있고, 왼쪽 테이블 'tbl1'의 경우 'tbl2'와 Key 값이 동일한 id = [2, 3, 4] 에 해당하는 값들만 'tbl2'에 연결이 되었습니다. 'tbl2'에만 존재하고 'tbl1'에는 없는 id = [5] 의 경우 'tbl1'의 'x' 칼럼 값은 [NULL] 값이 됩니다.
--------------------
-- RIGHT OUTER JOIN
--------------------
SELECT a.id, x, y
FROM tbl1 AS a
RIGHT OUTER JOIN tbl2 AS b
ON a.id = b.id;
--id x y
--2 b e
--3 c f
--4 d g
--5 [NULL] h
(4) FULL JOIN
FULL JOIN은 양쪽 테이블 모두를 기준으로 Key 값이 같은 값들을 연결시켜 줍니다. 이때 한쪽 테이블에만 Key 값이 존재할 경우 다른쪽 테이블의 칼럼 값에는 [NULL] 값을 반환합니다.
제일 위에 있는 도식화 그림을 참고하시면 위의 INNER JOIN, LEFT OUTER JOIN, RIGHT OUTER JOIN, FULL JOIN에 대해서 좀더 이해하기 쉬울 거예요.
---------------
-- FULL JOIN
---------------
SELECT a.id, x, y
FROM tbl1 AS a
FULL JOIN tbl2 AS b
ON a.id = b.id;
--id x y
--1 a [NULL]
--2 b e
--3 c f
--4 d g
--5 [NULL] h
(5) 3개 이상의 복수개의 테이블을 JOIN 으로 연결하기
위의 (1)~(4) 는 2개의 테이블을 Key 값을 기준으로 JOIN 문으로 연결한 것이었습니다. 만약 3개 이상의 복수개의 테이블을 JOIN 으로 연결하고자 한다면 아래의 예처럼 JOIN 문과 연결 Key 값을 ON 으로 이어서 써주면 됩니다.
아래의 예는 'tbl1' 테이블을 기준으로 'tbl2', 'tbl3'를 'id' Key를 기준으로 LEFT OUTER JOIN 한 것입니다.
--------------------------------------------------------
-- LEFT OUTER JOIN with Multiple Tables
--------------------------------------------------------
-- creating the 3rd table
DROP TABLE IF EXISTS tbl3;
CREATE TABLE tbl3 (
id int
, z text
) DISTRIBUTED RANDOMLY;
INSERT INTO tbl2 VALUES (2, 'i'), (4, 'j'), (6, 'k'), (8, 'l');
SELECT * FROM tbl3 ORDER BY id;
--id z
--2 i
--4 j
--6 k
--7 l
-- LEFT OUTER JOIN with 3 tables
SELECT a.id, x, y
FROM tbl1 AS a
LEFT OUTER JOIN tbl2 AS b
ON a.id = b.id
LEFT OUTER JOIN tbl3 AS c
ON a.id = c.id
ORDER BY a.id;
--id x y z
--1 a [NULL] [NULL]
--2 b e i
--3 c f [NULL]
--4 d g j
(6) CROSS JOIN
위의 (1)~(5)까지의 JOIN은 두 테이블에 동일하게 존재하는 Key값을 기준으로 두 테이블을 연결하여 주었다면, 이제 CROSS JOIN 은 두 테이블의 모든 값들 간의 조합을 반환하며, 이때 Key 값은 필요없습니다. 가령 왼쪽 테이블에 m 개의 행이 있고, 오른쪽 테이블에 n 개의 행이 있다면 두 테이블의 CROSS JOIN은 m * n 개의 조합(combination)을 반환합니다.
실수로 행의 개수가 엄청나게 많은 두 테이블을 CROSS JOIN 하게 될 경우 시간도 오래 걸리고 자칫 memory full 나서 DB가 다운되는 경우도 있습니다. 따라서 CROSS JOIN 을 할 때는 지금 하려는 작업이 CROSS JOIN 요건이 맞는 것인지 꼭 한번 더 확인이 필요하며, 소요 시간이나 메모리가 여력이 되는지에 대해서도 먼저 가늠해볼 필요가 있습니다.
----------------
-- CROSS JOIN
----------------
SELECT a.id AS id_a, a.x, b.id AS id_b, b.y
FROM tbl1 AS a
CROSS JOIN tbl2 AS b
ORDER BY a.id, b.id;
--id_a x id_b y
--1 a 2 e
--1 a 3 f
--1 a 4 g
--1 a 5 h
--2 b 2 e
--2 b 3 f
--2 b 4 g
--2 b 5 h
--3 c 2 e
--3 c 3 f
--3 c 4 g
--3 c 5 h
--4 d 2 e
--4 d 3 f
--4 d 4 g
--4 d 5 h
지난번 포스팅에서는 R 지리공간 벡터 데이터의 속성 정보에 대해서 Base R, dplyr, data.table 패키지를 사용하여 그룹별로 집계하는 방법(rfriend.tistory.com/624)을 소개하였습니다.
이번 포스팅에서는 dplyr 패키지를 사용하여 두 개의 지리공간 벡터 데이터 테이블을 Join 하는 여러가지 방법을 소개하겠습니다. [1] Database SQL에 이미 익숙한 분이라면 이번 포스팅은 매우 쉽습니다. 왜냐하면 dplyr 의 두 테이블 간 Join 이 SQL의 Join 을 차용해서 만들어졌기 때문입니다.
R의 sf 클래스 객체인 지리공간 벡터 데이터를 dplyr 의 함수를 사용해서 두 테이블을 join 하면 속성(attributes)과 함께 지리공간 geometry 칼럼과 정보도 join 된 후의 테이블에 자동으로 그대로 따라가게 됩니다.
(1) Mutating Joins : 두 테이블을 합쳐서 새로운 테이블을 생성하기
- (1-1) inner join
- (1-2) left join
- (1-3) right join
- (1-4) full join
(2) Filtering Joins : 두 테이블의 매칭되는 부분을 기준으로 한쪽 테이블을 걸러내기
- (2-1) semi join
- (2-2) anti join
(3) Nesting joins : 한 테이블의 모든 칼럼을 리스트로 중첩되게 묶어서 다른 테이블에 합치기
- (3-1) nest join
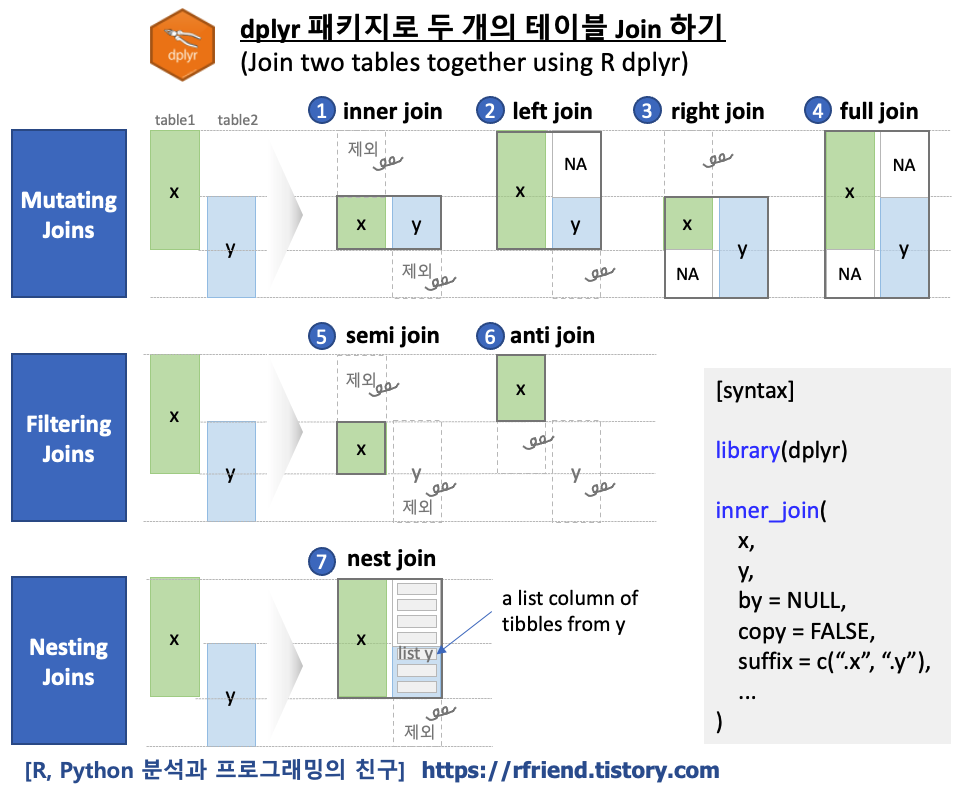
R dplyr 패키지가 두 테이블 Join 을 하는데 제공하는 함수는 inner_join(), left_join(), right_join(), full_join(), semi_join(), anti_join(), nest_join() 의 총 7개가 있으며, 이는 크게 (a) Mutating Joins, (b) Filtering Joins, (3) Nesting Joins의 3개의 범주로 분류할 수 있습니다.
[ R dplyr 패키지로 두 개의 테이블 Join 하기 (Joining two tables together using R dplyr) ]
joining two tables using R dplyr
(1) Mutating Joins
Mutation Joins 는 두 개의 테이블을 Key를 기준으로 Join 하여 두 개 테이블로 부터 가져온 (전체 또는 일부) 행과 모든 열로 Join 하여 새로운 테이블을 만들 때 사용합니다. 위의 그림에서 보는 바와 같이 왼쪽(Left Hand Side, LHS)의 테이블과 오른쪽(Right Hand Side, RHD)의 테이블로 부터 모두 행과 열을 가져와서 Join 된 테이블을 반환하며, 이때 왼쪽(LHS)와 오른쪽(RHS) 중에서 어느쪽 테이블이 기준이 되느냐에 따라 사용하는 함수가 달라집니다.
(1-1) inner join
먼저, 예제로 사용할 sf 클래스 객체로서, spData 패키지에서 세계 국가별 속성정보와 지리기하 정보를 가지고 있는 'world' 데이터셋, 그리고 2016년과 2017년도 국가별 커피 생산량을 집계한 coffee_data 데이터셋을 가져오겠습니다. "world" 데이터셋은 177개의 관측치, 11개의 칼럼을 가지고 있고, "coffee_data" 데이터셋은 47개의 관측치, 3개의 칼럼을 가지고 있습니다. 그리고 두 데이터셋은 공통적으로 'name_long' 이라는 국가이름 칼럼을 가지고 있으며, 이는 두 테이블을 Join 할 때 기준 Key 로 사용이 됩니다.
테이블 Join 을 위해 dplyr 패키지를 불러오겠습니다.
## ==================================
## GeoSpatial Data Analysis using R
## : Vector attribute joining
## : reference: https://geocompr.robinlovelace.net/attr.html
## ==================================
library(sf)
library(spData) # for sf data
library(dplyr)
## -- (a) world: World country pologons in spData
names(world)
# [1] "iso_a2" "name_long" "continent" "region_un" "subregion" "type" "area_km2" "pop" "lifeExp" "gdpPercap"
# [11] "geom"
dim(world)
# [1] 177 11
## -- (b) coffee_data: World coffee productiond data in spData
## : estimated values for coffee production in units of 60-kg bags in each year
names(coffee_data)
# [1] "name_long" "coffee_production_2016" "coffee_production_2017"
dim(coffee_data)
# [1] 47 3
dplyr 패키지의 테이블 Join 에 사용하는 함수들의 기본 구문은 아래와 같이 왼쪽(x, LHS), 오른쪽(y, RHS) 테이블, 두 테이블을 매칭하는 기준 칼럼(by), 데이터 source가 다를 경우 복사(copy) 여부, 접미사(suffix) 등의 매개변수로 구성되어 서로 비슷합니다.
## dplyr join syntax library(dplyr)
## -- (a) Mutating Joins inner_join(x, y, by = NULL, copy = FALSE, suffix = c(".x", ".y"), ...) left_join(x, y, by = NULL, copy = FALSE, suffix = c(".x", ".y"), ...) right_join(x, y, by = NULL, copy = FALSE, suffix = c(".x", ".y"), ...) full_join(x, y, by = NULL, copy = FALSE, suffix = c(".x", ".y"), ...)
## -- (b) Filtering Joins semi_join(x, y, by = NULL, copy = FALSE, ...) anti_join(x, y, by = NULL, copy = FALSE, ...)
## -- (c) Nesting Joins nest_join(x, y, by = NULL, copy = FALSE, keep = FALSE, name = NULL, ...)
inner join 은 두 테이블에서 Key 칼럼을 기준으로 서로 매칭이 되는 행에 대해서만, 두 테이블의 모든 칼럼을 반환합니다. 그럼, "world"와 "coffee_data" 두 데이터셋 테이블을 공통의 칼럼인 "name_long" 을 기준으로 inner join 해보겠습니다. 두 테이블에 공통으로 "name_long"이 존재하는 관측치가 45개가 있네요.
만약 두 테이블 x, y 에 다수의 매칭되는 값이 있을 경우에는, 모든 가능한 조합의 값을 반환하므로, 주의가 필요합니다.
dplyr 의 Join 함수들은 두 테이블 Join 의 기준이 되는 Key 칼럼 이름을 by 매개변수에 안써주면 두 테이블에 공통으로 존재하는 칼럼을 Key 로 삼아서 Join 을 수행하고, 콘솔 창에 'Joining, by = "name_long"' 과 같이 Key 를 출력해줍니다.
left join 은 왼쪽의 테이블(LHS, x)을 모두 반환하고 (기준이 됨), 오른쪽 테이블(RHS, y)은 왼쪽 테이블과 Key 값이 매칭되는 관측치에 대해서만 모든 칼럼을 왼쪽 테이블에 Join 하여 반환합니다. 만약 오른쪽 테이블(RHS, y)에 매칭되는 값이 없는 경우 x 테이블의 y에 해당하는 행은 NA 로 채워집니다.
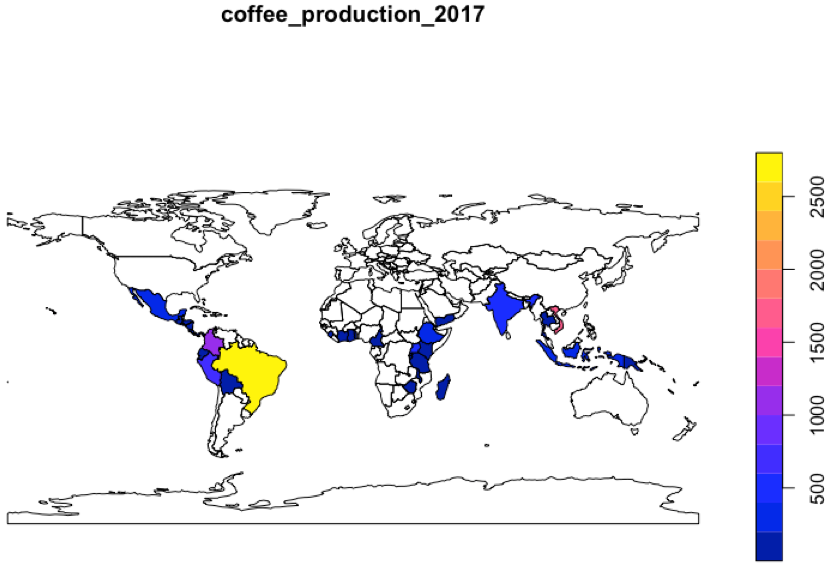
아래 예에서는 왼쪽에 있는 "world" 테이블을 기준으로 오른쪽의 "coffee_data"를 공통으로 존재하는 'name_long' 칼럼을 Key로 해서 left join 을 한 것입니다. 12번째와 13번째 칼럼에 오른쪽 테이블인 "coffee_data" 에서 Join 해서 가져온 "coffee_production_2016", "coffee_production_2017"의 칼럼이 왼쪽 "world" 테이블에 Join 이 되었습니다.
plot() 함수로 다면(multi-polygons) 기하도형으로 구성된 세계 국가별 지도에 2017년도 커피 생산량을 시각화해보았습니다. 지리기학 벡터 데이터를 Join 했을 때 누릴 수 있는 geometry 칼럼을 사용할 수 있는 혜택이 되겠습니다.
두 테이블을 Join 할 때 기준이 되는 Key 칼럼의 이름이 서로 다른 경우 by 매개변수에 서로 다른 변수 이름을 구체적으로 명시해주면 됩니다. 아래 예에서는 오른쪽 "coffee_data" 테이블의 'name_long' 칼럼 이름을 'nm'으로 바꿔준 후에, by = c(name_long = "nm") 처럼 Join하려는 두 테이블의 서로 다른 이름의 Key 변수들을 명시해주었습니다.
## -- Using the 'by' argument to specify the joining variables
coffee_renamed = rename(coffee_data, nm = name_long)
world_coffee2 = left_join(world, coffee_renamed,
by = c(name_long = "nm")) # specify the joining variables
names(world_coffee2)
# [1] "iso_a2" "name_long" "continent" "region_un"
# [5] "subregion" "type" "area_km2" "pop"
# [9] "lifeExp" "gdpPercap" "geom" "coffee_production_2016"
# [13] "coffee_production_2017"
(1-3) right join
right join 은 오른쪽 테이블(RHS, y) 을 전부 반환하고, 왼쪽 테이블 (LHS, x) 은 오른쪽(y) 테이블과 매칭이 되는 값에 대해서만 모든 칼럼을 Join 해서 반환합니다. Key 칼럼을 기준으로 왼쪽 테이블에 없는 값은 NA 처리가 되어 오른쪽 테이블에 Join 됩니다. (위의 그림 도식을 참고하세요).
만약 왼쪽과 오른쪽 테이블에 다수의 매칭되는 값들이 있을 경우 매칭되는 값들의 모든 조합으로 Join 됩니다. 아래 예에서 Join 의 기준이 되는 Key 를 명기해주는 매개변수 by = 'name_long' 는 두 테이블에 공통으로 존재하므로 생략 가능합니다.
## -- (1-3) right join: return all rows from y, and all columns from x.
world_coffee_right = right_join(x = world,
y = coffee_data,
by = 'name_long')
dim(world) # -- left
# [1] 177 11
dim(coffee_data) # -- right
# [1] 47 3
dim(world_coffee_right) # -- right join
# [1] 47 13
(1-4) full join
full Join 은 왼쪽 (LHS, x)과 오른쪽(RHS, y)의 모든 행과 열을 반환합니다.
## -- (1-4) full join: return all rows and all columns from both x and y.
world_coffee_full = full_join(x = world,
y = coffee_data,
by = 'name_long')
dim(world_coffee_full)
# [1] 179 13
names(world_coffee_full)
# [1] "iso_a2" "name_long" "continent" "region_un"
# [5] "subregion" "type" "area_km2" "pop"
# [9] "lifeExp" "gdpPercap" "geom" "coffee_production_2016"
# [13] "coffee_production_2017"
어느 한쪽 테이블에서 버려지는 값이 없으며, 만약 왼쪽이나 오른쪽 테이블에 없는 값이면 "NA" 처리됩니다. 아래의 왼쪽 "world" 테이블과 오른쪽의 "coffee_data" 테이블 간에 서로 매칭되지 않는 부분은 "NA"가 들어가 있음을 알 수 있습니다.
## Where there are not matching values, returns 'NA' for the one missing.
head(world_coffee_full[, c(2:3, 9:13)], 10)
# Simple feature collection with 10 features and 6 fields
# geometry type: MULTIPOLYGON
# dimension: XY
# bbox: xmin: -180 ymin: -55.25 xmax: 180 ymax: 83.23324
# geographic CRS: WGS 84
# # A tibble: 10 x 7
# name_long continent lifeExp gdpPercap geom coffee_productio~ coffee_productio~
# <chr> <chr> <dbl> <dbl> <MULTIPOLYGON [arc_degree]> <int> <int>
# 1 Fiji Oceania 70.0 8222. (((180 -16.06713, 180 -16.55522, 179.3641 ~ NA NA
# 2 Tanzania Africa 64.2 2402. (((33.90371 -0.95, 34.07262 -1.05982, 37.6~ 81 66
# 3 Western Sa~ Africa NA NA (((-8.66559 27.65643, -8.665124 27.58948, ~ NA NA
# 4 Canada North Amer~ 82.0 43079. (((-122.84 49, -122.9742 49.00254, -124.91~ NA NA
# 5 United Sta~ North Amer~ 78.8 51922. (((-122.84 49, -120 49, -117.0312 49, -116~ NA NA
# 6 Kazakhstan Asia 71.6 23587. (((87.35997 49.21498, 86.59878 48.54918, 8~ NA NA
# 7 Uzbekistan Asia 71.0 5371. (((55.96819 41.30864, 55.92892 44.99586, 5~ NA NA
# 8 Papua New ~ Oceania 65.2 3709. (((141.0002 -2.600151, 142.7352 -3.289153,~ 114 74
# 9 Indonesia Asia 68.9 10003. (((141.0002 -2.600151, 141.0171 -5.859022,~ 742 360
# 10 Argentina South Amer~ 76.3 18798. (((-68.63401 -52.63637, -68.25 -53.1, -67.~ NA N
(2) Filtering Joins
Filtering Joins 은 두 테이블의 매칭되는 값을 기준으로 한쪽 테이블의 값을 걸러내는데 사용합니다.
(2-1) semi join
semi join 은 왼쪽(LHS, x)과 오른쪽(RHS, y) 테이블의 서로 매칭되는 값에 대해 왼쪽(LHS, x)의 모든 칼럼을 반환합니다. 이때 매칭 여부를 평가하는데 사용되었던 오른쪽 테이블(RHS, y)의 값은 하나도 가져오지 않으며, 단지 왼쪽 테이블(x)을 걸러내느데(filtering)만 사용하였다는 점이 위의 (1-2) Left Join 과 다른 점입니다. (위의 도식을 참고하세요)
## -- (2) Filtering joins
## -- (2-1) semi join
## : return all rows from x where there are matching values in y,
## : keeping just columns form x.
world_coffee_semi = semi_join(world, coffee_data)
# Joining, by = "name_long"
dim(world_coffee_semi)
# [1] 45 11
names(world_coffee_semi)
# [1] "iso_a2" "name_long" "continent" "region_un" "subregion" "type" "area_km2" "pop"
# [9] "lifeExp" "gdpPercap" "geom"
(2-2) anti join
anti join 은 왼쪽 테이블(LHS, x)과 오른쪽 테이블(RHS, y)의 매칭되는 부분을 왼쪽 테이블(LHS, x)에서 걸러낸 x의 모든 칼럼을 반환합니다. 이때 매칭 여부를 평가하는데 사용되었던 오른쪽(RHS, y) 테이블의 값은 하나도 가져오지 않으며, 단지 왼쪽 테이블(x)을 걸러내는데(filtering)만 사용합니다.
위의 (2-1)의 semi join 은 x와 y의 매칭되는 부분의 x값만을 반환하였다면, 이번 (2-2)의 anti join 은 반대로 x와 j의 매칭이 안되는 부분의 x값만을 반환하는게 다릅니다. (y 값은 안가져오는 것은 semi join 과 anti join 이 동일함.)
## -- (6) anti join
## : return all rows from x where there are not matching values in y,
## : keeping just columns from x.
world_coffee_anti = anti_join(world, coffee_data)
# Joining, by = "name_long"
dim(world_coffee_anti)
# [1] 132 11
names(world_coffee_anti)
# [1] "iso_a2" "name_long" "continent" "region_un" "subregion" "type" "area_km2" "pop"
# [9] "lifeExp" "gdpPercap" "geom"
(3) Nesting Joins
(3-1) nest join
nest join 은 왼쪽 테이블(LHS, x)의 모든 행과 열을 반환하며, 이때 오른쪽(RHS, y)의 매칭되는 부분의 모든 칼럼의 값들을 list 형태로 중첩되게 묶어서 왼쪽 x 테이블에 join 해줍니다. 즉, 오른쪽 y 테이블의 매칭되는 값들의 칼럼이 여러개 이더라도 왼쪽 x 테이블에 join 이 될 때는 1개의 칼럼에 list 형태로 오른쪽 y 테이블의 여러개 칼럼의 값들이 묶여서 join 됩니다.
## -- (3) Nesting joins
## -- (3-1) nest join
## : eturn all rows and all columns from x. Adds a list column of tibbles.
## : Each tibble contains all the rows from y that match that row of x.
world_coffee_nest = nest_join(world, coffee_data)
# Joining, by = "name_long"
dim(world_coffee_nest)
# [1] 177 12
names(world_coffee_nest)
# [1] "iso_a2" "name_long" "continent" "region_un" "subregion" "type" "area_km2"
# [8] "pop" "lifeExp" "gdpPercap" "geom" "coffee_data"
head(world_coffee_nest[, 10:12], 3)
# Simple feature collection with 3 features and 2 fields
# geometry type: MULTIPOLYGON
# dimension: XY
# bbox: xmin: -180 ymin: -18.28799 xmax: 180 ymax: 27.65643
# geographic CRS: WGS 84
# # A tibble: 3 x 3
# gdpPercap geom coffee_data
# <dbl> <MULTIPOLYGON [arc_degree]> <list>
# 1 8222. (((180 -16.06713, 180 -16.55522, 179.3641 -16.80135, 178.7251 -17.01204, 178.5968 ~ <tibble [0 x 2~
# 2 2402. (((33.90371 -0.95, 34.07262 -1.05982, 37.69869 -3.09699, 37.7669 -3.67712, 39.2022~ <tibble [1 x 2~
# 3 NA (((-8.66559 27.65643, -8.665124 27.58948, -8.6844 27.39574, -8.687294 25.88106, -1~ <tibble [0 x 2~
말로만 설명하면 잘 이해가 안될 듯 하여 아래에 nest_join(world, coffee_data) 된 테이블의 아웃풋을 화면 캡쳐하였습니다. nest join 된 후의 테이블에서 오른쪽의 "coffee_data" 라는 1개의 칼럼에 보면 list(coffee_proeuction_2016 = 81, coffee_proeuction_2017 = xx) 라고 해서 "coffee_data" 에 들어있는 2개의 칼럼이 1개의 리스트 형태의 칼럼에 중첩이 되어서 들어가 있음을 알 수 있습니다.
다음번 포스팅에서는 Join 했을 때 Join 의 기준이 되는 Key 값이 일부 표준화가 안되어서 제대로 Join 이 안될 경우에 정규 표현식(Regular expression)을 사용해서 Join 하는 방법(rfriend.tistory.com/626)을 소개하겠습니다.
이번 포스팅에서는 SQL을 사용해서 Database의 Table 들을 Join/Merge 하는 것과 유사하게 Python pandas의 pd.merge() 함수를 사용해서 DataFrame을 Key 기준으로 inner, outer, left, outer join 하여 합치는 방법을 소개하도록 하겠습니다.
SQL을 사용하는데 익숙한 분석가라면 매우 쉽고 빠르게 이해하실 수 있을 것입니다. 그리고 Python의 merge() 기능은 메모리 상에서 매우 빠르게 작동함으로 사용하는데 있어 불편함이 덜할 것 같습니다.
pandas merge 함수 설정값들은 아래와 같이 여러개가 있는데요, 이중에서 'how'와 'on'은 꼭 기억해두셔야 합니다.
pd.merge(left, right, # merge할 DataFrame 객체 이름 how='inner', # left, rigth, inner (default), outer on=None, # merge의 기준이 되는 Key 변수 left_on=None, # 왼쪽 DataFrame의 변수를 Key로 사용 right_on=None, # 오른쪽 DataFrame의 변수를 Key로 사용 left_index=False, # 만약 True 라면, 왼쪽 DataFrame의 index를 merge Key로 사용 right_index=False, # 만약 True 라면, 오른쪽 DataFrame의 index를 merge Key로 사용 sort=True, # merge 된 후의 DataFrame을 join Key 기준으로 정렬 suffixes=('_x', '_y'), # 중복되는 변수 이름에 대해 접두사 부여 (defaults to '_x', '_y' copy=True, # merge할 DataFrame을 복사 indicator=False) # 병합된 이후의 DataFrame에 left_only, right_only, both 등의 출처를 알 수 있는 부가 정보 변수 추가
먼저, pandas, DataFrame library를 importing 한 후에, 2개의 DataFrame을 만들어보겠습니다.
In [1]:import pandas as pd
In [2]:from pandas import DataFrame
In [3]: df_left = DataFrame({'KEY': ['K0', 'K1', 'K2', 'K3'],
...: 'A': ['A0', 'A1', 'A2', 'A3'],
...: 'B': ['B0', 'B1', 'B2', 'B3']})
...:
In [4]: df_right = DataFrame({'KEY': ['K2', 'K3', 'K4', 'K5'],
...: 'C': ['C2', 'C3', 'C4', 'C5'],
...: 'D': ['D2', 'D3', 'D4', 'D5']})
...:
In [5]: df_left
Out[5]:
A B KEY 0 A0 B0 K0 1 A1 B1 K1 2 A2 B2 K2 3 A3 B3 K3
In [6]: df_right
Out[6]:
C D KEY 0 C2 D2 K2 1 C3 D3 K3 2 C4 D4 K4 3 C5 D5 K5
'how' 의 left, right, inner, outer 별로 위에서 만든 'df_left'와 'df_right' 두 개의 DataFrame을 'KEY' 변수를 기준으로 merge 해보겠습니다. SQL join에 익숙하신 분이라면 쉽게 이해할 수 있을 것입니다.
(1) Merge method : left (SQL join name : LEFT OUTER JOIN)
In [7]: df_merge_how_left = pd.merge(df_left, df_right,
...:how='left',
...:on='KEY')
...:
In [8]: df_merge_how_left
Out[8]:
A B KEY C D 0 A0 B0 K0 NaN NaN 1 A1 B1 K1 NaN NaN 2 A2 B2 K2 C2 D2 3 A3 B3 K3 C3 D3
(2) Merge method : right (SQL join name : RIGHT OUTER JOIN)
In [9]: df_merge_how_right = pd.merge(df_left, df_right,
...:how='right',
...:on='KEY')
In [10]: df_merge_how_right
Out[10]:
A B KEY C D 0 A2 B2 K2 C2 D2 1 A3 B3 K3 C3 D3 2 NaN NaN K4 C4 D4 3 NaN NaN K5 C5 D5
In [11]: df_merge_how_inner = pd.merge(df_left, df_right,
...:how='inner', # default
...:on='KEY')
...:
In [12]: df_merge_how_inner
Out[12]:
A B KEY C D 0 A2 B2 K2 C2 D2 1 A3 B3 K3 C3 D3
(4) Merge method : outer (SQL join name : FULL OUTER JOIN)
In [13]: df_merge_how_outer = pd.merge(df_left, df_right,
...:how='outer',
...:on='KEY')
...:
In [14]: df_merge_how_outer
Out[14]:
A B KEY C D 0 A0 B0 K0 NaN NaN 1 A1 B1 K1 NaN NaN 2 A2 B2 K2 C2 D2 3 A3 B3 K3 C3 D3 4 NaN NaN K4 C4 D4 5 NaN NaN K5 C5 D5
[참고] Hive 조인 문 : INNER JOIN, LEFT OUTER JOIN, RIGHT OUTER JOIN, FULL JOIN, CARTESIAN PRODUCT JOIN, MAP-SIDE JOIN, UNION ALL :http://rfriend.tistory.com/216
(5) indicator = True : 병합된 이후의 DataFrame에 left_only, right_only, both 등의
출처를 알 수 있는 부가정보 변수 추가
In [15]: pd.merge(df_left, df_right, how='outer', on='KEY',
...:indicator=True)
Out[15]:
A B KEY C D _merge 0 A0 B0 K0 NaN NaN left_only 1 A1 B1 K1 NaN NaN left_only 2 A2 B2 K2 C2 D2 both 3 A3 B3 K3 C3 D3 both 4 NaN NaN K4 C4 D4 right_only 5 NaN NaN K5 C5 D5 right_only
위에서는 indicator=True로 했더니 '_merge'라는 새로운 변수가 생겼습니다.
이 방법 외에도, 아래처럼 indicator='변수 이름(예: indicator_info)'을 설정해주면, 새로운 변수 이름에 indicator 정보가 반환됩니다.
In [16]: pd.merge(df_left, df_right, how='outer', on='KEY',
...:indicator='indicator_info')
Out[16]:
A B KEY C D indicator_info 0 A0 B0 K0 NaN NaN left_only 1 A1 B1 K1 NaN NaN left_only 2 A2 B2 K2 C2 D2 both 3 A3 B3 K3 C3 D3 both 4 NaN NaN K4 C4 D4 right_only 5 NaN NaN K5 C5 D5 right_only
(6) 변수 이름이 중복될 경우 접미사 붙이기 : suffixes = ('_x', '_y')
'B'와 'C' 의 변수 이름이 동일하게 있는 두 개의 DataFrame을 만든 후에, KEY를 기준으로 합치기(merge)를 해보겠습니다. 변수 이름이 중복되므로 Data Source를 구분할 수 있도록 suffixes = ('string', 'string') 을 사용해서 중복되는 변수의 뒷 부분에 접미사를 추가해보겠습니다. default는 suffixes = ('_x', '_y') 입니다.
# making DataFrames with overlapping columns
In [17]: df_left_2 = DataFrame({'KEY': ['K0', 'K1', 'K2', 'K3'],
...: 'A': ['A0', 'A1', 'A2', 'A3'],
...:'B': ['B0', 'B1', 'B2', 'B3'],
...:'C': ['C0', 'C1', 'C2', 'C3']})
In [18]: df_right_2 = DataFrame({'KEY': ['K0', 'K1', 'K2', 'K3'],