[LangChain] 웹 검색 툴로 최신 정보를 검색해 컨텍스트 정보로 참고하여 답변 생성하기 (Adding web search tool and generate answer using LangChain, ChatGPT)
Deep Learning (TF, Keras, PyTorch)/Natural Language Processing 2024. 1. 2. 11:41ChatGPT와 같은 LLM 모델을 이용한 질의응답 시에 제약조건으로 지식단절(Knowledge Cutoff)이 있습니다.
지식단절 (Knowledge Cutoff)이란 LLM 모델이 학습에 사용한 데이터가 생성된 시점 이후의 새로운 사건, 정보에 대해서는 학습이 안되어서 답변 생성이 불가능한 것을 말합니다.
지식단절의 한계를 극복하는 방법으로 최신의 데이터를 계속 수집해서 자주 LLM 모델을 Fine-tuning 해주는 방법이 있습니다. 하지만 이는 비용과 시간이 많이 듭니다.
지식단절의 한계를 극복하는 또 다른 방법으로는 웹 검색 툴을 추가하여, 사용자의 질문에 해당하는 최신의 공개된 정보를 웹 검색을 통해 가져와서, 이 최신 공개 정보를 컨텍스트 정보로 하여 LLM 모델이 답변을 생성하도록 할 수 있습니다. 이는 앞서 말한 Fine-tuning 기법 대비 상대적으로 비용과 시간이 적게 들고 바로 적용해볼 수 있는 장점이 있습니다.
이번 포스팅에서는 LangChain 을 이용하여 DuckDuckGo Web Search Tool을 추가해 사용자 질의에 해당하는 최신 정보를 검색하고, ChatGPT LLM 모델이 이를 컨텍스트 정보로 삼아 답변을 생성하는 방법을 소개하겠습니다.
LangChain에서는 Google Search, Bing Search, DuckDuckGo Search 웹 검색 툴을 제공합니다. Google 과 Bing search를 사용하려면 API 서비스 등록을 하고 API Key를 받아서 사용해야 합니다.
[ 웹 검색 툴로 최신 정보를 검색하여 컨텍스트 정보로 참고하여 답변 생성하기 ]

먼저 터미널에서 pip install 을 사용해 langchain, openai, black, python-lsp-black, duckduckgo-search 모듈을 설치합니다.
! pip install -q langchain openai black>=22.3 python-lsp-black duckduckgo-search
실습에 필요한 모듈을 importing 합니다.
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
OpenAI API Key를 환경변수로 등록해줍니다.
import os
os.environ["OPENAI_API_KEY"] = "sk-xxxx..." # set with yours
(1) Web Search Tool을 사용하지 않았을 때의 지식 단절 (Knowledge Cutoff)
먼저, Web Search Tool을 사용하지 않고 ChatGPT LLM 모델만을 가지고 최신 정보가 필요한 질문을 했을 때 지식 단절로 인해 적절한 답변을 못하는 현상을 살펴보겠습니다.
template = """You are an AI assistant. Answer the question.
If you don't know the answer, just say you don't know.
Question: {question}
Answer:"""
prompt = ChatPromptTemplate.from_template(template)
model = ChatOpenAI(model="gpt-4")
parser = StrOutputParser()
chain = prompt | model | parser
아래처럼 "누가 BTS 멤버 중에 가장 늦게 군대에 갔나요?" 라고 질문을 했을 때 ChatGPT-4 모델이 최신의 실시간 데이터를 제공할 수 없다고 답변합니다. (가상의 그럴싸한 거짓말을 하는 환각(Hallucinations) 현상을 일으키지 않아서 그나마 다행이예요.)
## -- 지식 단절 (Knowledge Cutoff)
chain.invoke({"question": "Which BTS member was the last to go to the military?"})
# "As an AI developed up to October 2021, I can't provide real-time data.
# As of my last update, none of the BTS members have begun their military service yet.
# In South Korea, all able-bodied men are required to serve in the military
# for approximately two years. Please check the most recent sources for this information."
(2) Web Search Tool을 사용하여 최신 정보를 검색해 지식 단절 (Knowledge Cutoff) 극복하기
이번에는 DuckDuckGo Search Tool을 추가해서 최신 정보를 웹에서 검색해 가지고 와서, 이를 컨텍스트 정보로 하여 답변을 생성해보도록 하겠습니다.
## Adding Web Search Tools
from langchain.tools import DuckDuckGoSearchRun
search = DuckDuckGoSearchRun()
## Provide "the latest context information" from web search
template = """Answer the question based on context.
Question: {question}
Context: {context}
Answer:"""
prompt = ChatPromptTemplate.from_template(template)
model = ChatOpenAI(model="gpt-4")
parser = StrOutputParser()
chain = (
{"question": RunnablePassthrough(), "context": RunnablePassthrough()}
| prompt
| model
| parser
)
먼저, DuckDuckGo Search tool 이 잘 작동하나 살펴보겠습니다.
search_result = search.run("Which BTS member was the last to go to the military?")
print(search_result)
# The last two members, Jimin and Jungkook, began their 18-month military duty
# in South Korea on Tuesday. Some fans say they should have been exempt. 24 BTS in 2019.
# Any potential reunion... South Korea Final Members of K-Pop Band BTS Begin Mandatory
# South Korean Military Service This video cannot be played because of a technical error.
# (Error Code: 102006) By Kim Tong-hyung / AP... Updated Dec 15, 2023, 11:01 AM
# SGT SEOUL - South Korean singers Jimin and Jungkook of K-pop boy band BTS
# began their mandatory military service on Dec 12. They are the last of the...
# Last October, BTS's agency BigHit Music owned by HYBE, confirmed that all seven members
# of the band would fulfil their country's military obligation, starting with the eldest,
# Jin, who... BTS formed in 2013 with seven members: RM, Jin, V, J-Hope, Suga,
# Jimin and Jungkook. The band went on to achieve global fame,
# with number one singles in more than 100 countries around the...
다음으로, DuckDuckGo 웹 검색 결과를 컨텍스트로 하여 답변을 생성해보겠습니다.
2024년 1월을 기준으로 했을 때, BTS 멤버 중에 가장 늦게 군대에 간 멤버가 "지민과 정국 (Jimin and Jungkook)" 이라고 이번에는 정확하게 답변을 해주네요!
question = "Which BTS member was the last to go to the military?"
chain.invoke({"question": question, "context": search.run(question)})
# 'Jimin and Jungkook'
[ Reference ]
- LangChain - Using Tools: https://python.langchain.com/docs/expression_language/cookbook/tools
- Google Search: https://python.langchain.com/docs/integrations/tools/google_search
- Bing Search: https://python.langchain.com/docs/integrations/tools/bing_search
- DuckDuckGoSearch: https://python.langchain.com/docs/integrations/tools/ddg
이번 포스팅이 많은 도움이 되었기를 바랍니다.
행복한 데이터 과학자 되세요! :-)

'Deep Learning (TF, Keras, PyTorch) > Natural Language Processing' 카테고리의 다른 글
| [LangChain] Chat Model로 Few-shot Prompting 하기 (0) | 2024.01.03 |
|---|---|
| [LangChain] LLM Model로 Few-shot Prompting 하기 (2) | 2024.01.02 |
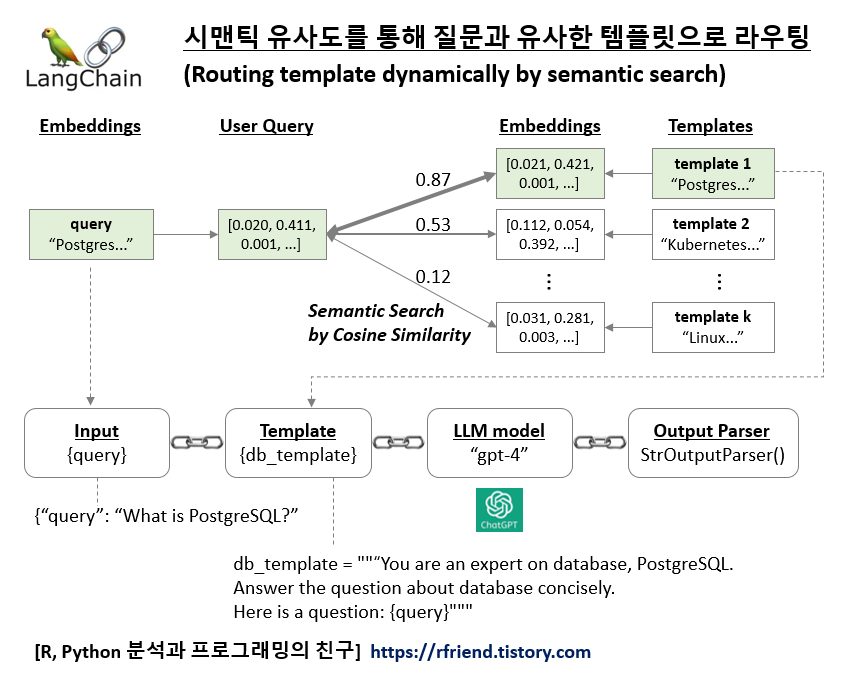
| [LangChain] 시맨틱 유사도를 통해 질문과 유사한 템플릿으로 라우팅하기 (0) | 2023.12.31 |
| [LangChain] 자연어로 Python code 쓰고 실행하기 (0) | 2023.12.27 |
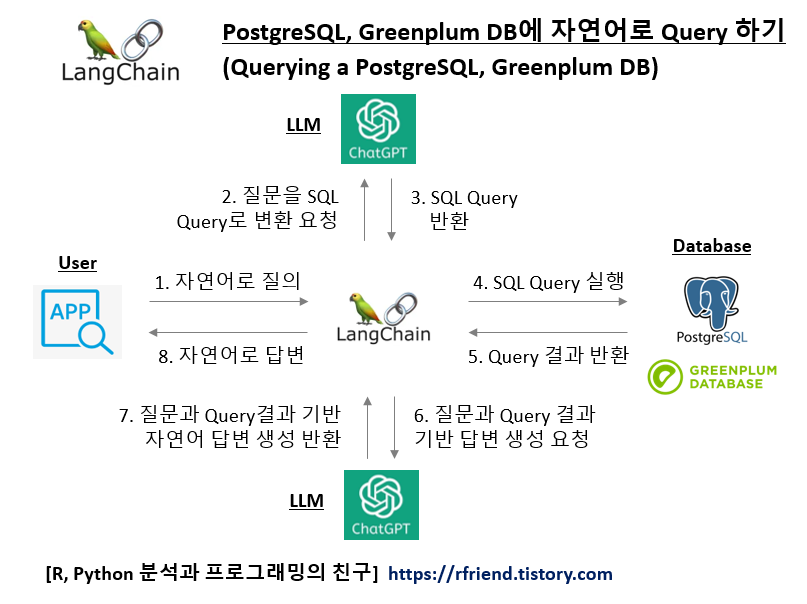
| [LangChain] 자연어로 질의해서 PostgreSQL, Greenplum DB에 SQL Query하여 답변하기 (Querying a PostgreSQL, Greenplum DB in natural language) (0) | 2023.12.27 |
Rfriend님의
글이 좋았다면 응원을 보내주세요!