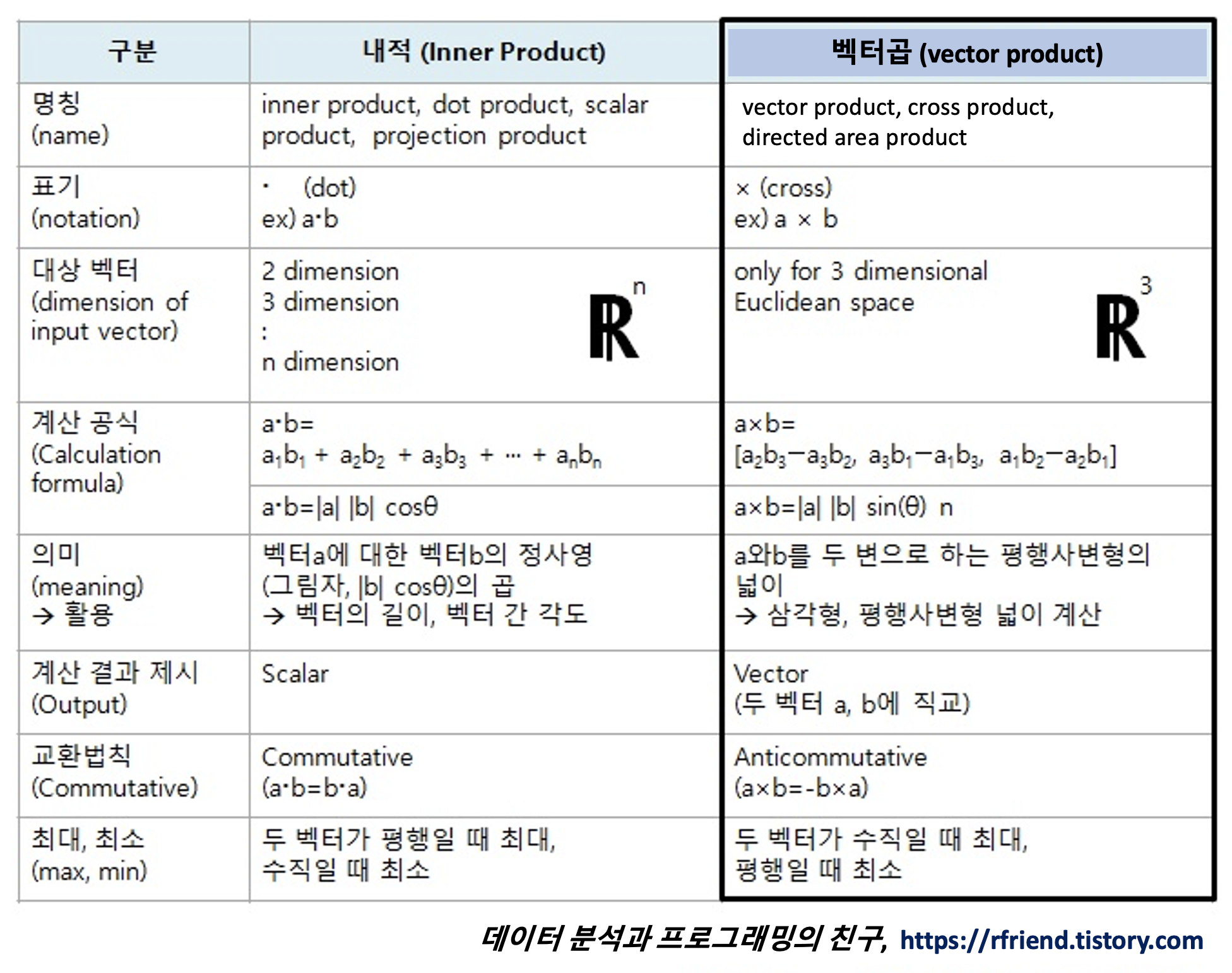
R 그래프 Base Graphics plotting system : hist() boxplot(), stem(), barplot(), dotchart(), pie(), plot()
R 분석과 프로그래밍/R 그래프_시각화 2015. 12. 24. 01:20R의 plotting system에는 크게 (1) Base Graphics, (2) Lattice, (3) ggplot2 의 3가지가 있습니다. 이전 포스팅에서 ggplot2 plotting system을 활용한 그래프 그리기를 소개하였다면, 이제부터는 쉽고 빠르게, 대화형으로 직관적으로 그래프를 단계적으로 그려나갈 수 있는 Base Graphics plotting system에 대해서 알아보겠습니다.

아래에 산점도(scatter plot)을 가지고 위에서 소개한 용어들이 의미하는 바를 예를 들어 설명해보도록 하겠습니다.
> library(MASS) > attach(Cars93) > > # high level graphics facility : plot() > # graphics parameters : type, pch, col, etc. > plot(MPG.highway ~ Weight, type = "p", pch = 19, col = "black") > > # low level graphics facility : abline(), title(), text() > # graphics parameters : labels, cex, pos, col, etc. > abline(lm(MPG.highway ~ Weight)) > text(Weight, MPG.highway, labels = abbreviate(Manufacturer, minlength = 5), + cex = 0.6, pos = 2, col = "blue")
|

위 그래프의 R함수에서 높은 수준의 그래프 함수, 낮은 수준의 그래프 함수, 그래프 모수에 해당하는 부분을 각 각 표기하면 아래와 같습니다. 높은 수준의 그래프 함수 plot()으로 먼저 뼈대를 잡아놓고, 낮은 수준의 그래프 함수 abline()로 차의 무게(Weight)와 고속도로연비(MPG.highway) 간 회귀선을 적합시킨 선을 추가하고 text()로 차 제조사 이름을 명기하였습니다. 이때 그래프 모수(parameters)로 그래프의 형태(type), 점의 형태(pch), 색깔(col), 레이블(labels), default 대비 확대 배수(cex), 다른 축과 교차되는 좌표(pos) 등을 옵션으로 설정하게 됩니다.
|
|

높은 수준의 그래프 함수 (High Level Graphics facilities) 들을 표로 정리해보면 아래와 같습니다.
|
Graph |
High Level Graphics Functions of Base Graphics system |
|
histogram |
hist() |
|
Box-and-Whiskers Plot |
boxplot() |
|
Stem and Leaf Plot |
stem() |
|
Bar Plot |
barplot() |
|
Cleveland Dot Plot |
dotchart() |
|
Pie Plot |
pie() |
|
Scatter Plot |
plot(x, y) |
|
Scatter Plot Matrix |
plot(dataframe) cf) other package: scatterplotMatrx() |
|
Line Plot |
plot(x, y, type=“l”) |
|
High Density Needle Plot |
plot(x, y, type=“h”) |
|
Both Dot and Line Plot |
plot(x, y, type=“b”) |
|
Overlapped Dot and Line Plot |
plot(x, y, type=“o”) |
|
Step Plot |
plot(x, y, type=“s”) |
|
Empty Plot |
plot(x, y, type=“n”) |
디폴트 모수로 해서 간단하게 그래프를 예로 들어보겠습니다.
일변량 연속형 데이터 그래프 (plot for 1 variable, continuous data)
- Histogram : hist()
> # histogram : hist() > hist(Cars93$MPG.highway, main = "histogram : hist()")
|

- box-and-whisker plot : boxplot()
> # box-and-whisker plot : boxplot() > boxplot(Cars93$MPG.highway, main = "box-and-whisker plot : boxplot()")
|

- stem and leaf plot : stem()
|
> # stem and leaf plot : stem() > stem(Cars93$MPG.highway) The decimal point is 1 digit(s) to the right of the | 2 | 00112233334444 2 | 55555555666666666667777778888888888999999 3 | 000000000111111123333333444 3 | 6667778 4 | 13 4 | 6 5 | 0 |
- bar plot : barplot()
|
> ##-------- plot for one variable, categorical data > # bar plot : barplot() > table_cyl <- table(Cars93$Cylinders) > barplot(table_cyl, main = "bar plot : barplot()") |

- Cleveland dot plot : dotchart()
> # cleveland dot plot : dotchart() > table_cyl <- table(Cars93$Cylinders) # frequency table > Cylinders <- names(table_cyl) # names for label > > dotchart(as.numeric(table_cyl), labels = Cylinders, main = "cleveland dot plot")
|

- pie chart : pie()
> # pie chart : pie() > table_cyl <- table(Cars93$Cylinders) # frequency table > Cylinders <- names(table_cyl) # names for label > > pie(table_cyl, labels = Cylinders, main = "pie chart")
|

- 산점도 (scatter plot)
> ##----- plot for 2 variables, continuous data > # scatter plot : plot(x, y) > with(Cars93, plot(Weight, MPG.highway, main = "scatter plot : plot(x, y)")) |

- scatter plot matrix : plot(dataframe), pairs(), scatterplotMatrix(dataframe)
> Cars93_subset <- Cars93[,c("Weight", "Horsepower", "MPG.highway", "MPG.city")] > plot(Cars93_subset, main = "scatter plot matrix : plot(dataframe)") >
|


- plot by various types : plot(x, y, type = "l, h, b, o, s, n")
> ##-------- > # plot by various type : l, h, b, o, s, n > # order by Weight > Cars93_1 <- Cars93[order(Cars93$Weight),] > > # dividing window frame > par(mfrow = c(3, 2)) > > # plots by type > attach(Cars93_1) > # line plot > plot(MPG.highway ~ Weight, type = "l", main = "type = l") > > # high density needle plot > plot(MPG.highway ~ Weight, type = "h", main = "type = h") > > # both dot and line plot > plot(MPG.highway ~ Weight, type = "b", main = "type = b") > > # overlapped dot and line plot > plot(MPG.highway ~ Weight, type = "o", main = "type = o") > > # step plot > plot(MPG.highway ~ Weight, type = "s", main = "type = s") > > # empty plot > plot(MPG.highway ~ Weight, type = "n", main = "type = n") > > detach(Cars93_1) |

많은 도움 되었기를 바랍니다.
이번 포스팅이 도움이 되었다면 아래의 '공감 ~♡' 단추를 꾸욱 눌러주세요.^^

'R 분석과 프로그래밍 > R 그래프_시각화' 카테고리의 다른 글
| R 그래프 모수(Graphical Parameters) : 기호 모양 pch, 크기 cex, 선 유형 lty, 선 두께 lwd (0) | 2015.12.26 |
|---|---|
| R 그래프 모수 (Graphical Parameters) : 그래프 모수 설정하는 2가지 방법 (0) | 2015.12.24 |
| R 동적 그래프 (Interactive Plotting in R) : with manipulate package in Rstudio (0) | 2015.09.12 |
| R ggplot2 연속확률분포 곡선, stat_function() (0) | 2015.09.07 |
| R ggplot2 히트맵(Heat map) 그리기 : geom_tile(), geom_raster() (12) | 2015.09.06 |