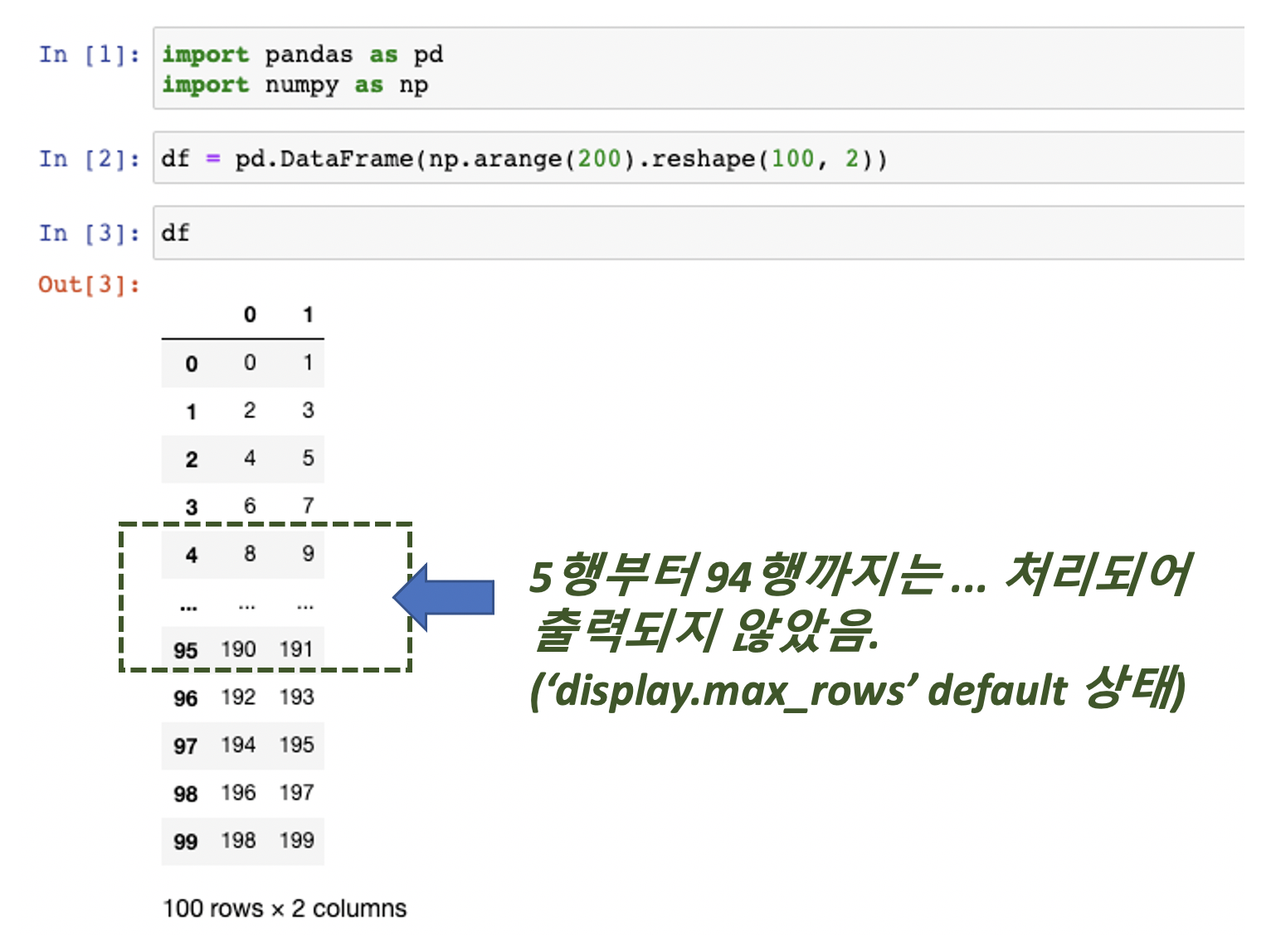
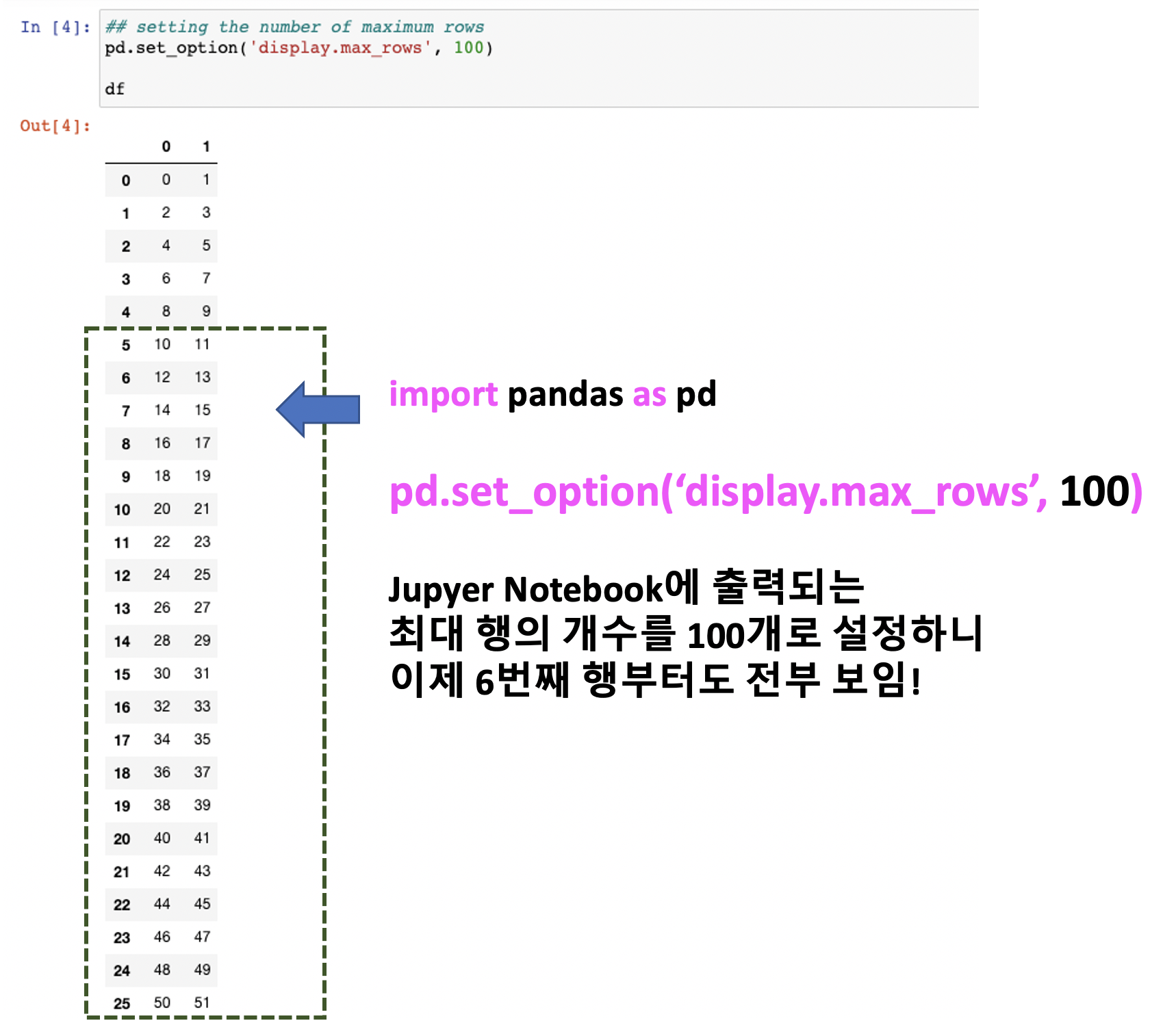
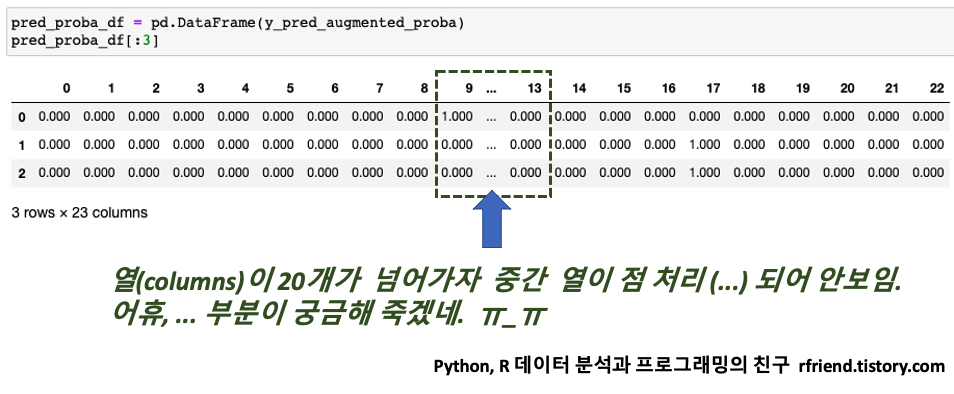
[Python pandas] resample() 메소드로 시계열 데이터를 10분 단위 구간별로 집계/요약 하기
Python 분석과 프로그래밍/Python 데이터 전처리 2019. 12. 15. 00:42이번 포스팅에서는 Python pandas library를 이용하여 시계열 데이터(time series data)를 10분, 20분, 1시간, 1일, 1달 등의 특정 시간 단위(time span) 구간별로 집계/요약 하는 방법을 소개하겠습니다. (Downsampling)
(* PostgreSQL, Greenplum database로 특정 시간 단위 구간별 시계열 데이터 집계, 요약하는 방법은 https://rfriend.tistory.com/495 참조)
이전에 소개했었던 groupby() operator를 사용해서 그룹별로 집계/요약하는 방법을 사용할 수도 있는데요, 시계열 데이터의 경우 pandas의 resample() method를 사용하면 좀더 편리하고 코드도 깔끔하게 시간 단위 구간별로 시계열 데이터를 집계/요약할 수 있습니다.

먼저 '년-월-일 시간:분:초'로 이루어진 time-stamp 를 index로 가지고, 가격(price)와 수량(amount) 의 두 개의 칼럼을 가지는 간단한 시계열 데이터를 만들어보겠습니다. pandas의 date_range(from, to, freq) 함수를 해서 '2분 간격(freq='2min')의 date range 데이터를 만들었습니다. 이 중에서 20개 행만 선택해서 예를 들어보겠습니다.
import pandas as pd import numpy as np # generate time series index range = pd.date_range('2019-12-19', '2019-12-20', freq='2min') df = pd.DataFrame(index = range)[:20] # add 'price' columm using random number np.random.seed(seed=1004) # for reproducibility df['price'] = np.random.randint(low=10, high=100, size=20) # add 'amount' column unsing random number df['amount'] = np.random.randint(low=1, high=5, size=20) print('Shape of df DataFrame:', df.shape) [Out]:Shape of df DataFrame: (20, 2)df [Out]:
|
(1) 10분 단위 구간별로 각 칼럼의 첫번째 값(first value), 마지막 값(last value) 구하기 (select the first and last value by 10 minutes time span using pandas resample method) |
resample('10T') 는 '년-월-일 시간:분:초' 의 시계열 index를 10분 단위의 동일 간격별로 데이터를 뽑으라는 뜻입니다. pandas의 groupby() 에서 split-apply-combine에서 동일 시간대 간격으로 split 의 역할을 한다고 생각할 수 있습니다.
[ resample() 메소드의 시간 단위 구간 설정 ]
- 5분 단위 구간 : resample('5T')
- 10분 단위 구간 : resample('10T')
- 20분 단위 구간 : resample('20T')
- 1시간 단위 구간 : resample('1H')
- 1일 단위 구간 : resample('1D')
- 1주일 단위 구각 : resample('1W')
- 1달 단위 구간 : resample('1M')
- 1년 단위 구간 : resample('1Y')
# Resampling by a given time span (group) # : first, last df_summary = pd.DataFrame() df_summary['price_10m_first'] = df.price.resample('10T').first() df_summary['price_10m_last'] = df.price.resample('10T').last() df_summary['amount_10m_first'] = df.amount.resample('10T').first() df_summary['amount_10m_last'] = df.amount.resample('10T').last() df_summary
|
(2) 10분 단위 구간별로 숫자형 데이터의 합계, 누적 합계 구하기 (sum, cumulative sum by 10 minutes time span using pandas resample method) |
# Resampling by a given time span (group) # sum, cumulative sum df_summary = pd.DataFrame() df_summary['price_10m_sum'] = df.price.resample('10T').sum() df_summary['price_10m_cumsum'] = df.price.resample('10T').sum().cumsum() df_summary['amount_10m_sum'] = df.amount.resample('10T').sum() df_summary['amount_10m_cumsum'] = df.amount.resample('10T').sum().cumsum() df_summary
|
(3) 10분 단위 구간별로 최소값, 최대값, 평균, 중앙값, 범위 구하기 (summary statistics by 10 minutes time span using pandas resample method) |
최소값(min), 최대값(max), 평균(mean), 중앙값(median) 요약통계량은 min(), max(), mean(), median() 메소드를 이용하여 구할 수 있으며, 범위(range)는 해당 메소드가 없어서 범위(range) = 최대값(max) - 최소값(min) 의 계산을 해서 구하였습니다.
# Resampling by a given time span (group) # min, max, mean, median, range df_summary = pd.DataFrame() df_summary['price_10m_min'] = df.price.resample('10T').min() df_summary['price_10m_max'] = df.price.resample('10T').max() df_summary['price_10m_mean'] = df.price.resample('10T').mean() df_summary['price_10m_median'] = df.price.resample('10T').median() df_summary['price_10m_range'] = \ df.price.resample('10T').max() - df.price.resample('10T').min() df_summary
|
(4) 10분 단위 구간별로 분산(variance), 표준편차(standard deviation) 구하기 (variance, standard deviation by 10 minutes time span using pandas resample(() method) |
resample('10T') 로 10분 단위 구간별로 데이터를 그룹으로 뽑고, var() 메소드로 표본 분산(sample variance)을 구합니다. (* 참고: 모집단 분산(population variance)이 편차 제곱의 합을 원소의 개수 N으로 나누어주는 반면에, 표본 분산(sample variance)는 편차 제곱의 합을 원소의 개수에서 1개를 뺀 N-1로 나누어준다는 차이점이 있습니다)
표본 표분편차(sample standard deviation)을 직접 구할 수 있는 메소드가 없어서 표본 분산에 제곱근(square root)을 취하여 표본 표준편차를 구하였습니다.
# Resampling by a given time span (group) # variance, standard deviation df_summary = pd.DataFrame() # sample variance 1/(N-1)*sigma(X-X_bar)^2 df_summary['price_10m_var'] = df.price.resample('10T').var() # sample standard deviation using sqrt(var) formula df_summary['price_10m_stddev'] = np.sqrt(df.price.resample('10T').var())
|
(5) 특정 시간 단위 구간별로 요약 통계량 구하는 사용자 정의 함수 (User Defined Function for aggregating summary statistics by specific time span) |
위의 (1) ~ (4)번에서 pandas의 resample() 메소드를 사용하여 시계열 데이터를 특정 시간 단위 구간별로 샘플링하고, 첫번째 값(first), 마지막 값(last), 합(sum), 누적합(cumsum), 최소값(min), 최대값(max), 평균(mean), 중앙값(median), 구간(range), 분산(variance), 표준편차(standard deviation) 을 구하는 방법을 소개하였습니다.
이를 좀더 사용하기 편리하도록 아래의 매개변수를 인자로 가지는 사용자 정의 함수를 정의해보겠습니다.
[ resample_summary() 사용자 정의 함수 매개변수 ]
(a) ts_data : '년-월-일 시간:분:초'의 시계열 범위 데이터를 index로 가지는 시계열 데이터 DataFrame
(b) col_nm : 집계/요약의 대상이 되는 칼럼 이름
(c) time_span : 특정 시간 단위 구간 (예: 10분 단위 '10T', 1시간 단위 '1H', 1일 단위 '1D' 등)
(d) func_list : 집계/요약할 함수 (예: 첫번째 값 'first', 마지막 값 'last', 합 'sum', 누적합 'cumsum', 최소값 'min', 최대값 'max', 평균 'mean', 중앙값 'median', 범위 'range', 표본 분산 'var', 표본 표준편차 'stddev' 등)
공통으로 사용되는 부분인 resampler = ts_data[col_nm].resample(time_span) 를 resampler 객체로 만들어서 반복해서 사용하였습니다.
그리고 사용자가 입력(선택)한 집계/요약 함수만 집계/요약하여 반환하도록 if [function name] in func_list 조건문을 추가해주었습니다.
집계/요약된 값의 칼럼 이름은 이해하기 쉽도록 접미사(suffix)를 붙어서 [ 기존 칼럼 이름 + '_' + 시간 단위 구간 + '_' + 집계/요약함수 ] 를 이어붙여서 새로 만들어주었습니다. (예: price_10T_first)
# UDF of Resampling by column name, time span and summary functions def resample_summary(ts_data, col_nm, time_span, func_list):
import numpy as np import pandas as pd
df_summary = pd.DataFrame() # blank DataFrame to store results
# resampler with column name by time span (group by) resampler = ts_data[col_nm].resample(time_span)
# aggregation functions with suffix name if 'first' in func_list: df_summary[col_nm + '_' + time_span + '_first'] = resampler.first()
if 'last' in func_list: df_summary[col_nm + '_' + time_span + '_last'] = resampler.last()
if 'sum' in func_list: df_summary[col_nm + '_' + time_span + '_sum'] = resampler.sum()
if 'cumsum' in func_list: df_summary[col_nm + '_' + time_span + '_cumsum'] = resampler.sum().cumsum()
if 'min' in func_list: df_summary[col_nm + '_' + time_span + '_min'] = resampler.min()
if 'max' in func_list: df_summary[col_nm + '_' + time_span + '_max'] = resampler.max()
if 'mean' in func_list: df_summary[col_nm + '_' + time_span + '_mean'] = resampler.mean()
if 'median' in func_list: df_summary[col_nm + '_' + time_span + '_median'] = resampler.median()
if 'range' in func_list: df_summary[col_nm + '_' + time_span + '_range'] = resampler.max() - resampler.min()
if 'var' in func_list: df_summary[col_nm + '_' + time_span + '_var'] = resampler.var() # sample variance
if 'stddev' in func_list: df_summary[col_nm + '_' + time_span + '_stddev'] = np.sqrt(resampler.var())
return df_summary
|
위의 (5)번에서 정의한 resample_summary() 사용자 정의 함수를 이용하여, df 데이터셋의 'price' 칼럼에 대해 '10분 단위 구간별로(time_span = '10T') 첫번째 값('first'), 마지막 값('last'), 합('sum'), 누적합('cumsum'), 최소값('min'), 최대값('max') 을 구해보겠습니다.
func_list = ['first', 'last', 'sum', 'cumsum', 'min', 'max'] resample_summary(df, 'price', '10T', func_list)
|
이번에는 시간 단위 구간을 '20분 ('20T')'으로 늘려서 resample_summary() 사용자 정의 함수를 사용해 보겠습니다.
func_list = ['mean', 'median', 'range', 'var', 'stddev'] resample_summary(df, 'price', '20T', func_list)
|
이번에는 집계/요약의 대상이 되는 칼럼을 '수량(amount)' 으로 바꾸어서 resample_summary() 사용자 정의 함수를 사용해 보겠습니다.
func_list = ['mean', 'median', 'range', 'var', 'stddev'] resample_summary(df, 'amount', '20T', func_list) # with 'amount' column
|
집계/요약할 함수를 평균('mean'), 중앙값('median'), 범위('range'), 분산('var'), 표준편차('stddev')로 바꾸어서 resample_summary() 사용자 정의 함수를 사용해 보겠습니다.
func_list = ['mean', 'median', 'range', 'var', 'stddev'] resample_summary(df, 'price', '10T', func_list)
|
이번에는 데이터를 2019-12-19 일에서 2020-01-18일 까지 약 한달 간의 시계열 데이터를 난수로 생성해서 ==> 시간 단위 구간을 1시간('1H'), 1일('1D'), 1주('1W'), 1달('1M') 로 바꾸어가면서 집계/요약을 해보겠습니다.
# generate time series index range = pd.date_range('2019-12-19', '2020-01-18', freq='2min') # one month period df_1m = pd.DataFrame(index = range) # add 'price' columm using random number np.random.seed(seed=1004) # for reproducibility df_1m['price'] = np.random.randint(low=10, high=100, size=len(df)) # add 'amount' column unsing random number df_1m['amount'] = np.random.randint(low=1, high=5, size=len(df)) print('Shape of df_1m DataFrame:', df_1m.shape) Shape of df_1m DataFrame: (21601, 2)
func_list = ['first', 'sum', 'mean', 'stddev']
resample_summary(df_1m, 'price', '1H', func_list).head() # by 1 Hour
func_list = ['first', 'sum', 'mean', 'stddev']
resample_summary(df_1m, 'price', '1D', func_list).head() # by 1 Day
# by 1 Weekfunc_list = ['first', 'sum', 'mean', 'stddev']
resample_summary(df_1m, 'price', '1W', func_list) # by 1 Week
func_list = ['first', 'sum', 'mean', 'stddev']
resample_summary(df_1m, 'price', '2W', func_list) # by 2 Week
# by 1 Monthfunc_list = ['first', 'sum', 'mean', 'stddev']
resample_summary(df_1m, 'price', '1M', func_list) # by 1 Month
|
(6) 10분 단위 구간별 수량 가중 평균 가격 구하기 (amount-weighted average of price by 10 minutes time span using pandas resample method) |
가격('price')과 수량('amount')을 곱해서 만든 새로운 칼럼 'price_mult_amt' 를 만들어주고, resample('10T') 메소드를 사용해서 10분 단위 구간별로 수량 가중 평균 가격(10분 단위 구간별 구입가격*구입수량 합 / 전체 구입수량 합)을 구해주었습니다.
참고로, 아래 코드에서 역 슬래쉬('\')는 코드를 한줄에 다 쓰기에 너무 길 경우에 '다음 줄로 넘겨서 쓴 코드를 앞코드와 이어진 코드'로 인식하게 만들어 줄 때 사용합니다.
# function: weighted average # 각 시간대의 수량가중평균가격(sum(price*amount)/sum(amount)) # (*가중평균은 특정 시간대에 발생한 모든 구입건의 구입가격*구입수량 합/전체 구입수량 합) df_summary = pd.DataFrame() df['price_mult_amt'] = df['price']*df['amount'] df_summary['price_10m_amount_weighted_avg'] = \ df.price_mult_amt.resample('10T').sum() / df.amount.resample('10T').sum() df_summary
|
(7) 10분 단위 구간별 집계/요약 통계량 결과를 csv 파일로 내보내기 (exporting summary results by 10 minutes time span into 'csv file' using pandas to_csv() method) |
위의 (5)번에서 정의한 resample_summary() 사용자 정의 함수(UDF)를 사용하여 10분 단위('10T') 구간별로 가격('price') 칼럼에 대해 'first', 'last', 'sum', 'cumsum', 'min', 'max', 'mean', 'median', 'range', 'var', 'stddev'를 모두 집계/요약한 데이터 프레임을 만들고,
이어서, 10단위 구간별로 수량 가중 평균 가격(amount-weighted average of price)을 구한 후에,
이를 취합한 결과 데이터프레임을 pandas의 to_csv() 메소드를 사용하여 'df_summary.csv' 라는 이름의 csv 파일로 내보내보겠습니다. '년-월-일 시간:분:초'의 시간 정보가 들어있는 index도 같이 내보내야 하므로 to_csv() 메소드 내 index=True 옵션으로 설정해주었으며, 결측값이 존재할 경우 na_rep='NaN' 으로 표기하도록 설정해주었고, 요약통계량 값이 부동소수형(float) 일 경우 소수점 2번째 자리까지만 표기하도록 float_format='%.2f' 옵션을 설정해주었습니다.
# summary statistics using resample_summary() User Defiened Function, refer to (5) func_list = ['first', 'last', 'sum', 'cumsum', 'min', 'max', 'mean', 'median', 'range', 'var', 'stddev'] df_summary = resample_summary(df, 'price', '10T', func_list) # amount-weighted average of price, refer to (6) df['price_mult_amt'] = df['price']*df['amount'] df_summary['price_10m_amount_weighted_avg'] = \ df.price_mult_amt.resample('10T').sum()/ df.amount.resample('10T').sum() # export df_summary DataFrame into csv file import os work_dir = os.getcwd() # current working directory file_path = os.path.join(work_dir, 'df_summary.csv') df_summary.to_csv(file_path , index=True # include index , na_rep='NaN' # representation of missing value , float_format = '%.2f') # 2 decimal places
|
많은 도움이 되었기를 바랍니다.
이번 포스팅이 도움이 되었다면 아래의 '공감~ '를 꾹 눌러주세요. :-)
'를 꾹 눌러주세요. :-)