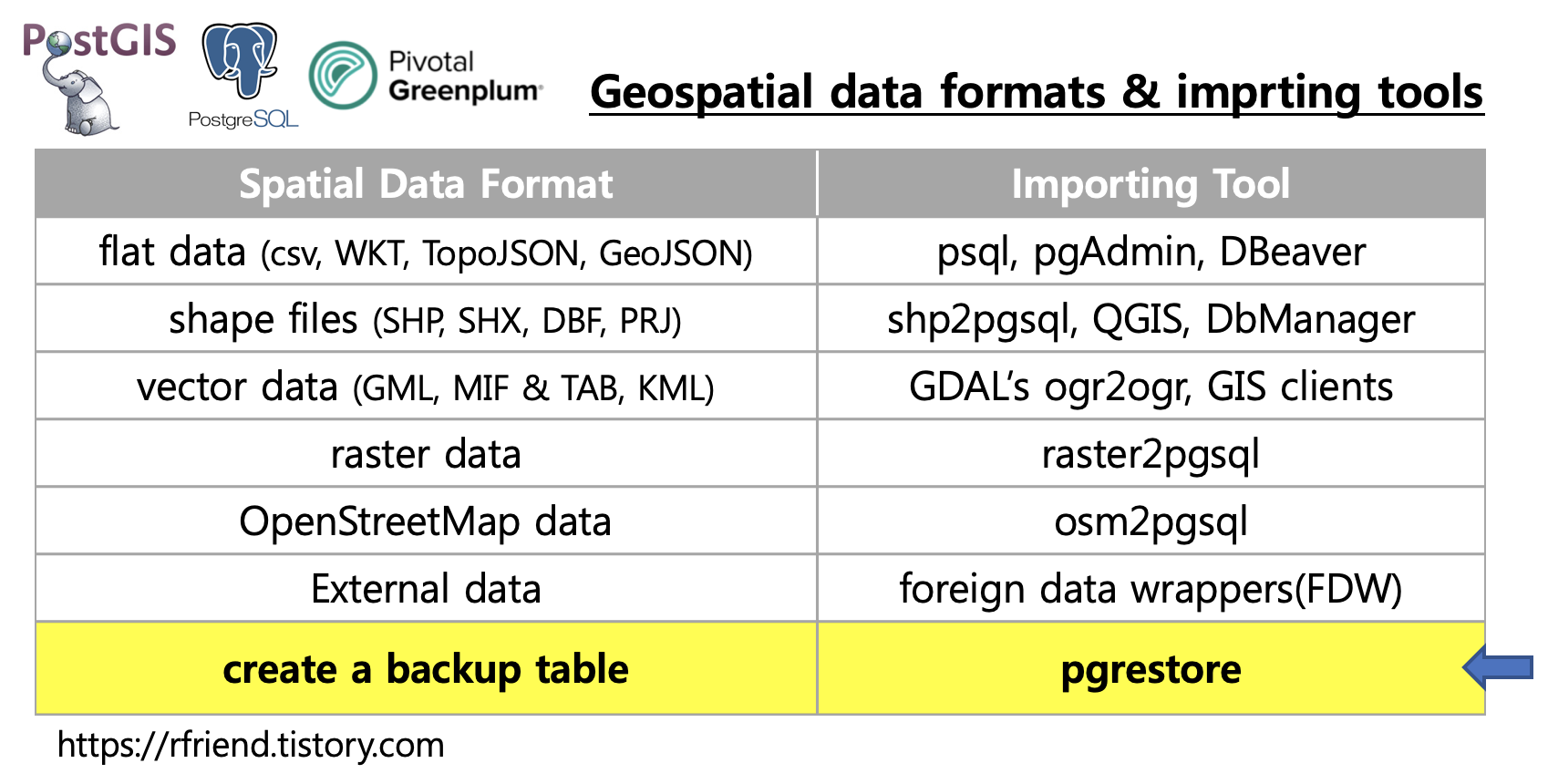
[PostgreSQL, Greenplum] 문자열 처리 연산자 및 함수 (character type operators and functions)
Greenplum and PostgreSQL Database 2020. 7. 4. 22:33이번 포스팅에서는 PostgreSQL, Greenplum Database의 문자열 데이터형 (Character Types)의 종류와, 생성, 운영자, 함수 등에 대해서 알아보겠습니다.
먼저, PostgreSQL 의 문자열형 종류는 아래처럼
- (1) 고정 길이 n 바이트 이내의 문자열 character(n), char(n)
- (2) 가변 길이 n 바이트 이내의 문자열 varchar(n)
- (3) 제한 없는 가변 길이 문자열 text, varchar
의 3가지 종류가 있습니다.
PostgreSQL은 이들 3가지 문자열 종류별로 성능 차이는 없습니다.

(1) PostgreSQL 문자열형 포함한 테이블 생성 및 문자열 입력 |
위에서 소개한 3개의 문자열형 종류인 CHAR(2), VARCHAR(10), TEXT 를 포함하고 있는 예제 테이블을 만들어보겠습니다. 괄호안의 숫자는 Bytes 길이를 의미합니다.
-- Create a table for an example DROP TABLE IF EXISTS char_type_test; CREATE TABLE char_type_test ( id SERIAL PRIMARY KEY , col_1 CHAR(2) , col_2 VARCHAR(10) , col_3 TEXT ); |
아래의 두가지 경우는 CHAR(2), VARCHAR(10) 처럼 바이트 길이 제약이 있는데 이를 만족하지 않는 경우 SQL ERROR가 발생한 예입니다.
(1-1) col_1 의 바이트 길이가 CHAR(2) 와 정확하게 맞지 않아서 에러가 나는 경우
-- PostgreSQL issued an error -- SQL Error [22001]: ERROR: value too long for type character(2) INSERT INTO char_type_test (col_1, col_2, col_3) VALUES ( 'Hollo' , 'PostgreSQL WORLD' , 'I love PostgreSQL all the time' ); |

(1-2) col_2 의 바이트 길이가 VARCHAR(10) 보다 길어서 에러가 나는 경우
-- PostgreSQL issued an error -- SQL Error [22001]: ERROR: value too long for type character varying(10) INSERT INTO char_type_test (col_1, col_2, col_3) VALUES ( 'Hi' , 'PostgreSQL WORLD' , 'I love PostgreSQL all the time' ); |

(1-3) col_1, col_2, col_3 가 모두 문자열형 조건을 만족하여 정상 입력된 경우
-- No error INSERT INTO char_type_test (col_1, col_2, col_3) VALUES ( 'Hi' , 'PostgreSQL' , 'I love PostgreSQL all the time') , ( 'Hi' , 'Greenplum' , 'I love Greenplum too' ); SELECT * FROM char_type_test ORDER BY id; |

(2) PostgreSQL 문자열 연산자 (Operator)와 함수 (Functions) |
(2-1) 문자열 합치기 (String Concatenation)
- 문자열 합치기: '||' 연산자
- 문자열 합치기: CONCAT() 함수
- 구분자를 포함하여 문자열 합치기: CONCAT_WS() 함수
(2-1-1) 문자열 합치기 연산자: '||'
지난번 포스팅에서는 PostgreSQL의 4가지 유형의 연산자로서 산술 연산자, 비교 연산자, 논리 연산자, 비트 연산자에 대해서 소개하였는데요, 문자열에 특화된 연산자 중에서 두 문자열을 합칠 때 사용하는 '||' 연산자를 소개하겠습니다.
string || string
string || non-string or non-string || string
SELECT * , col_1 || ', ' || col_2 AS db_name , id || ' : ' || col_2 AS db_id FROM char_type_test; |

(2-1-2) 두 문자열 합치기 함수: CONCAT()
위의 (2-1-1)과 동일한 결과를 concat() 함수를 사용하여 얻을 수 있습니다.
SELECT * , CONCAT(col_1, ', ', col_2) AS db_name_2 , CONCAT(id, ' : ', col_2) AS db_id_2 FROM char_type_test; |

문자열을 합치는데 사용하는 '||' 연산자와 CONCAT() 함수 사이에는 NULL 값을 처리하는데 있어 차이가 존재합니다. '||' 연산자는 NULL 값이 있으면 NULL 값을 반환하는 반면에, CONCAT() 함수는 NULL 값을 무시하고 나머지 값을 반환합니다.
-- Concatenate using || with a NULL value returns NULL SELECT col_1 || NULL AS result_string FROM char_type_test; -- Concat function ignores NULL arguments. SELECT CONCAT(col_1, NULL) AS result_string_2 FROM char_type_test; |


(2-1-3) 구분자를 포함하여 문자열을 합치기 (CONCAT With Separator): CONCAT_WS()
-- (3) CONCAT_WS : CONCAT With Separator -- : CONCAT_WS(separator, str_1, str_2, ...); SELECT * , CONCAT_WS(', ', col_1, col_2) AS db_name_3 , CONCAT_WS(' : ', id, col_2) AS db_id_3 FROM char_type_test; |

합치려는 문자열의 개수가 여러개이고 구분자를 포함시키고 싶을 경우, CATCAT_WS() 함수는 구분자를 한번만 써줘도 되므로, 구분자를 매번 써줘어야 하는 CATCAT() 함수보다 편리합니다.
-- Useful when there are lots of values to concatenate SELECT CONCAT('a', ': ', 'b', ': ', 'c', ': ', 'd', ': ', 'e', ': ', 'f') AS concat_result_1; SELECT CONCAT_WS(': ', 'a', 'b', 'c', 'd', 'e', 'f') AS concat_ws_result_2; |

(2-2) 문자열 길이 (String Length)
- 문자열 내 비트의 길이: BIT_LENGTH(string)
- 문자열 내 바이트의 길이: OCTET_LENGTH(string)
- 문자열 내 문자 길이: LENGTH(string)
SELECT col_3 , BIT_LENGTH(col_3) AS bit_len_col_3 , OCTET_LENGTH(col_3) AS cotet_len_col_3 , LENGTH(col_3) AS char_len_col_3 FROM char_type_test; |

문자열 내 바이트의 길이를 재는 OCTET_LENGTH()와 문자 길이를 재는 LENGTH() 함수가 알파벳과 숫자에서는 차이가 없는데요, 한글처럼 문자열 내 바이트와 문자 길이가 다른 경우도 있습니다. 따라서 한글의 바이트를 재고 싶다면 LENGTH()가 아니라 OCTET_LENGTH() 함수를 사용해야 겠습니다.
SELECT OCTET_LENGTH('abc123'); --------- result 6 |
SELECT LENGTH('abc123'); ---------- result 6 |
SELECT OCTET_LENGTH('안녕하세요'); ---------- result 15 |
SELECT LENGTH('안녕하세요'); ---------- result 5 |
(2-3) 문자열 대/소문자 변환 (String Case Conversion)
- 문자열 내 문자를 소문자로 바꾸기: LOWER(string)
- 문자열 내 문자를 대문자로 바꾸기: UPPER(string)
- 문자열 내 첫번째 문자를 대문자로, 나머지 문자는 소문자로 바꾸기: INITCAP(string)
-- lower(string): convert a string to lower case -- upper(string): convert a string to upper case -- initcap(string): convert words in a string to title case SELECT col_2 , LOWER(col_2) AS lower_col_2 , UPPER(col_2) AS upper_col_2 , INITCAP(col_2) AS initcap_col_2 FROM char_type_test; |

(2-4) 문자열 겹쳐쓰기, 바꾸기, 뒤집기, 반복하기
- 문자열 겹쳐쓰기: OVERLAY(string PLACING string FROM int [FOR int])
- 문자열 바꾸기: REPLACE(string, FROM, TO)
-- overlay(string placing string from int [for int]) -- replace(string, from, to) SELECT col_3 , OVERLAY(col_3 PLACING 'Opensource DB ' FROM 8 FOR 10) AS overlayed_col_3 , REPLACE(col_3, 'I', 'You') AS replaced_col_3 FROM char_type_test;
|

- 문자열 순서 뒤집기: REVERSE(string)
- 문자열 n번 반복하기: REPEAT(string, int)
-- reverse(string) -- repeat(string, int) SELECT col_2 , REVERSE(col_2) AS reversed_col_2 , REPEAT(col_2, 3) AS repeated_col_2 FROM char_type_test;
|

(2-5) 문자열의 위치 인덱스: POSITION(substring IN string)
POSITION() 함수이 첫번째 인자로 받는 substring 은 대/소문자를 구분합니다.
---------------------------------- -- Location of specified substring ---------------------------------- SELECT col_3 , POSITION('g' in col_3) AS g_position , POSITION('G' in col_3) AS "G_position" , POSITION('love' in col_3) AS love_position FROM char_type_test; |

(2-6) 문자열의 부분 문자열을 잘라오기: SUBSTR(string [from int] [for int])
-- substring(string [from int] [for int]) SELECT * , SUBSTR(col_2, 1, 3) AS substr_col_2_3 , SUBSTR(col_2, 1, 5) AS substr_col_2_5 FROM char_type_test;
|

(2-7) 문자열을 구분자(Delimeter)를 기준으로 분할 후 일부분 가져오기
: SPLIT_PART(string, delimiter, part_position)
-------------- -- Split a string on a specified delimeter -------------- SELECT '2020-07-04' AS yyyymmdd , SPLIT_PART('2020-07-04', '-', 1) AS year , SPLIT_PART('2020-07-04', '-', 2) AS month , SPLIT_PART('2020-07-04', '-', 3) AS day;
|

(2-8) 문자열 내 특정 하위 문자열을 잘라내기: TRIM()
- 문자열 내 특정 문자로 시작하는 부분 잘라내기: TRIM(leadnig characters from string)
- 문자열 내 특정 문자로 끝나는 부분 잘라내기: TRIM(trailing characters from string)
- 문자열 내 특정 문자로 시작하거나 끝나는 부분 잘라내기: TRIM(both characters from string)
- 문자열의 왼쪽 시작부분에 특정 문자가 있으면 잘라내기: LTRIM(string, characters)
- 문자열의 오른쪽 끝부분에 특정 문자가 있으면 잘라내기: RTRIM(string, characters)
TRIM()과 LTRIM(), RTRIM() 간에 인자의 위치가 조금 다른 것에 주의하세요.
-- trim([leading | trailing | both] [character] from string) SELECT 'xTomxx' AS original_str , TRIM(LEADING 'x' FROM 'xTomxx') AS trim_leading , TRIM(TRAILING 'x' FROM 'xTomxx') AS trim_trailing , TRIM(BOTH 'x' FROM 'xTomxx') AS trim_both , LTRIM('xTomxx', 'x') AS l_trim , RTRIM('xTomxx', 'x') AS r_trim; |

(2-9) 문자열의 처음 n개 문자 가져오기
- 문자열의 왼쪽으로(시작) 부터 처음 n개 문자 가져오기: LEFT(string, int n)
- 문자열의 오른쪽으로(끝) 부터 처음 n개 문자 가져오기: RIGHT(string, int n)
-------------------------------- -- First n character in a string -------------------------------- SELECT col_2 , LEFT(col_2, 3) AS first_n_from_left , RIGHT(col_2, 3) AS first_n_from_right FROM char_type_test;
|

(2-10) 문자열의 길이가 n개보다 모자라는 개수만큼 채우기(Padding)
- 문자열의 길이가 n 개보다 모자라는 개수만큼 character로 왼쪽부터 채우기
: LPAD(string, int n, character) - 문자열의 길이가 n 개보다 모자라는 개수만큼 character로 오른쪽부터 채우기
: RPAD(string, int n, character)
----------------------------------- -- PAD on the left or rght a string ----------------------------------- SELECT id , LPAD(id::char, 5, '0') AS lpad_id , RPAD(id::char, 5, '0') AS rpad_id FROM char_type_test;
|

문자열형의 패턴 매칭(pattern matching)까지 다루기에는 포스팅이 너무 길어지므로 다음번에 별도로 소개하겠습니다.
많은 도움이 되었기를 바랍니다.
이번 포스팅이 도움이 되었다면 아래의 '공감~ '를 꾹 눌러주세요. :-)
'를 꾹 눌러주세요. :-)