지난번 포스팅에서는 레스터 데이터의 유형으로 (a) 셀 ID (Cell IDs), (b) 셀 값 (Cell Values) 에 대해서 알아보고, RasterLayer 예제 데이터를 R raster 패키지의 raster() 함수로 불러와서 여러 속성 정보를 살펴보았습니다. (rfriend.tistory.com/605)
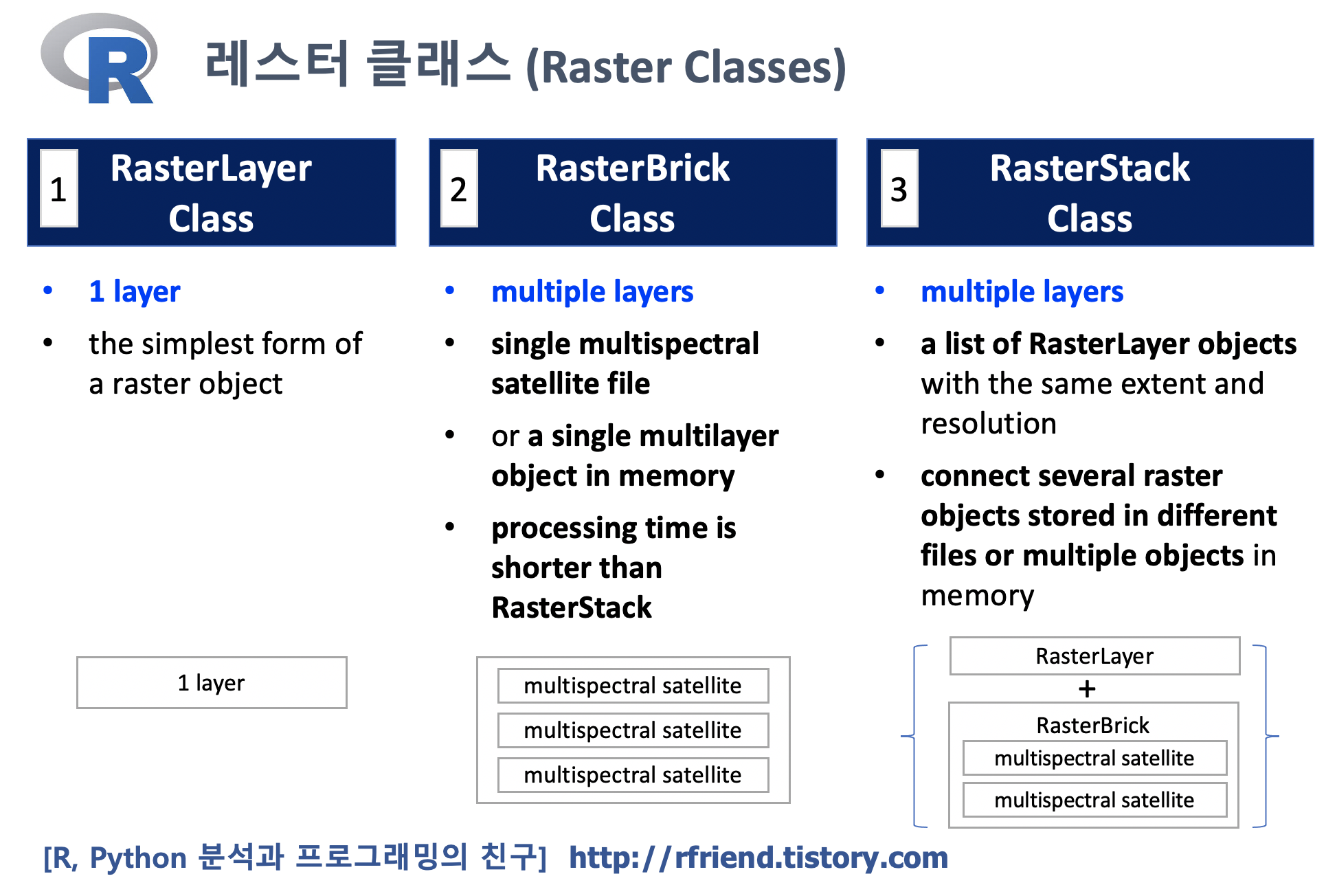
이번 포스팅에서는 3가지의 레스터 클래스 (Raster Classes) 의 특장점과 언제 사용하면 좋을지에 대해서 소개하겠습니다.
(1) RasterLayer class
(2) RasterBrick class
(3) RasterStack class
(4) 언제 어떤 레스터 클래스를 사용하는 것이 좋은가?
[ 3가지의 레스터 클래스 (Raster Classes) ]
(1) RasterLayer Class
RasterLayer Class는 레스터 객체 중에서 가장 간단한 형태의 클래스로서, 단 한 개의 층으로 구성되어 있습니다.
지난번 포스팅에서 소개했던 것처럼, RasterLayer Class 객체를 만드는 가장 쉬운 방법은 기존의 RasterLayer Class 객체 파일을 읽어오는 것입니다. 아래 예에서는 raster 패키지의 raster() 함수를 사용해서 spDataLarge 패키지에 내장되어 있는 srtm.tif 레스터 층 클래스 객체를 읽어와서 raster_layer 라는 이름의 단 한개의 층만을 가진 RasterLayer Class 객체를 만들어보겠습내다 . nlayers() 함수로 층의 개수를 살펴보면 '1'개 인 것을 확인할 수 있습니다.
## ==========================================
## R Raster Classes
## : RasterLayer, RasterBrick and RasterStack
## ==========================================
library(raster)
library(spDataLarge)
## -- (1) RasterLayer
## : The RasterLayer class represents the simplest form of a raster object,
## and consists of only one layer.
## read-in a raster file from disk or from a server
raster_filepath = system.file("raster/srtm.tif", package = "spDataLarge")
raster_filepath
# [1] "/Library/Frameworks/R.framework/Versions/4.0/Resources/library/spDataLarge/raster/srtm.tif"
raster_layer = raster(raster_filepath)
raster_layer
# class : RasterLayer
# dimensions : 457, 465, 212505 (nrow, ncol, ncell)
# resolution : 0.0008333333, 0.0008333333 (x, y)
# extent : -113.2396, -112.8521, 37.13208, 37.51292 (xmin, xmax, ymin, ymax)
# crs : +proj=longlat +datum=WGS84 +no_defs
# source : /Library/Frameworks/R.framework/Versions/4.0/Resources/library/spDataLarge/raster/srtm.tif
# names : srtm
# values : 1024, 2892 (min, max)
## number of layers
nlayers(raster_layer)
# [1] 1
raster 패키지는 rgdal 패키지의 도움을 받아 수많은 드라이버를 지원합니다.
아래는 raster::writeFormats() 로 확인해 본, raster 패키지가 지원하는 "쓰기 포맷 (Write Formats)" 들 입니다.
## write Formats
raster::writeFormats()
# name long_name
# [1,] "raster" "R-raster"
# [2,] "SAGA" "SAGA GIS"
# [3,] "IDRISI" "IDRISI"
# [4,] "IDRISIold" "IDRISI (img/doc)"
# [5,] "BIL" "Band by Line"
# [6,] "BSQ" "Band Sequential"
# [7,] "BIP" "Band by Pixel"
# [8,] "ascii" "Arc ASCII"
# [9,] "CDF" "NetCDF"
# [10,] "ADRG" "ARC Digitized Raster Graphics"
# [11,] "BMP" "MS Windows Device Independent Bitmap"
# [12,] "BT" "VTP .bt (Binary Terrain) 1.3 Format"
# [13,] "BYN" "Natural Resources Canada's Geoid"
# [14,] "CTable2" "CTable2 Datum Grid Shift"
# [15,] "EHdr" "ESRI .hdr Labelled"
# [16,] "ELAS" "ELAS"
# [17,] "ENVI" "ENVI .hdr Labelled"
# [18,] "ERS" "ERMapper .ers Labelled"
# [19,] "GPKG" "GeoPackage"
# [20,] "GS7BG" "Golden Software 7 Binary Grid (.grd)"
# [21,] "GSBG" "Golden Software Binary Grid (.grd)"
# [22,] "GTX" "NOAA Vertical Datum .GTX"
# [23,] "GTiff" "GeoTIFF"
# [24,] "HDF4Image" "HDF4 Dataset"
# [25,] "HFA" "Erdas Imagine Images (.img)"
# [26,] "IDA" "Image Data and Analysis"
# [27,] "ILWIS" "ILWIS Raster Map"
# [28,] "INGR" "Intergraph Raster"
# [29,] "ISCE" "ISCE raster"
# [30,] "ISIS2" "USGS Astrogeology ISIS cube (Version 2)"
# [31,] "ISIS3" "USGS Astrogeology ISIS cube (Version 3)"
# [32,] "KRO" "KOLOR Raw"
# [33,] "LAN" "Erdas .LAN/.GIS"
# [34,] "Leveller" "Leveller heightfield"
# [35,] "MBTiles" "MBTiles"
# [36,] "MRF" "Meta Raster Format"
# [37,] "NGW" "NextGIS Web"
# [38,] "NITF" "National Imagery Transmission Format"
# [39,] "NTv2" "NTv2 Datum Grid Shift"
# [40,] "NWT_GRD" "Northwood Numeric Grid Format .grd/.tab"
# [41,] "PAux" "PCI .aux Labelled"
# [42,] "PCIDSK" "PCIDSK Database File"
# [43,] "PCRaster" "PCRaster Raster File"
# [44,] "PDF" "Geospatial PDF"
# [45,] "PDS4" "NASA Planetary Data System 4"
# [46,] "PNM" "Portable Pixmap Format (netpbm)"
# [47,] "RMF" "Raster Matrix Format"
# [48,] "ROI_PAC" "ROI_PAC raster"
# [49,] "RRASTER" "R Raster"
# [50,] "RST" "Idrisi Raster A.1"
# [51,] "SAGA" "SAGA GIS Binary Grid (.sdat, .sg-grd-z)"
# [52,] "SGI" "SGI Image File Format 1.0"
# [53,] "Terragen" "Terragen heightfield"
# [54,] "VICAR" "MIPL VICAR file"
# [55,] "netCDF" "Network Common Data Format"
그리고 아래는 rgdal::gdalDrivers() 로 확인해 본, rgdal 패키지에서 지원하는 140 여개의 드라이버들입니다. 드라이버별로 생성(create), 복사(copy) 가능 여부는 아래에서 확인이 가능합니다.
## gdal Drivers
rgdal::gdalDrivers()
# name long_name create copy isRaster
# 1 AAIGrid Arc/Info ASCII Grid FALSE TRUE TRUE
# 2 ACE2 ACE2 FALSE FALSE TRUE
# 3 ADRG ARC Digitized Raster Graphics TRUE FALSE TRUE
# 4 AIG Arc/Info Binary Grid FALSE FALSE TRUE
# 5 ARG Azavea Raster Grid format FALSE TRUE TRUE
# 6 AirSAR AirSAR Polarimetric Image FALSE FALSE TRUE
# 7 BAG Bathymetry Attributed Grid FALSE TRUE TRUE
# 8 BIGGIF Graphics Interchange Format (.gif) FALSE FALSE TRUE
# 9 BLX Magellan topo (.blx) FALSE TRUE TRUE
# 10 BMP MS Windows Device Independent Bitmap TRUE FALSE TRUE
# 11 BSB Maptech BSB Nautical Charts FALSE FALSE TRUE
# 12 BT VTP .bt (Binary Terrain) 1.3 Format TRUE FALSE TRUE
# 13 BYN Natural Resources Canada's Geoid TRUE FALSE TRUE
# 14 CAD AutoCAD Driver FALSE FALSE TRUE
# 15 CALS CALS (Type 1) FALSE TRUE TRUE
# 16 CEOS CEOS Image FALSE FALSE TRUE
# 17 COASP DRDC COASP SAR Processor Raster FALSE FALSE TRUE
# 18 COG Cloud optimized GeoTIFF generator FALSE TRUE TRUE
# 19 COSAR COSAR Annotated Binary Matrix (TerraSAR-X) FALSE FALSE TRUE
# 20 CPG Convair PolGASP FALSE FALSE TRUE
# 21 CTG USGS LULC Composite Theme Grid FALSE FALSE TRUE
# 22 CTable2 CTable2 Datum Grid Shift TRUE FALSE TRUE
# 23 DAAS Airbus DS Intelligence Data As A Service driver FALSE FALSE TRUE
# 24 DERIVED Derived datasets using VRT pixel functions FALSE FALSE TRUE
# 25 DIMAP SPOT DIMAP FALSE FALSE TRUE
# 26 DIPEx DIPEx FALSE FALSE TRUE
# 27 DOQ1 USGS DOQ (Old Style) FALSE FALSE TRUE
# 28 DOQ2 USGS DOQ (New Style) FALSE FALSE TRUE
# 29 DTED DTED Elevation Raster FALSE TRUE TRUE
# 30 E00GRID Arc/Info Export E00 GRID FALSE FALSE TRUE
# 31 ECRGTOC ECRG TOC format FALSE FALSE TRUE
# 32 EEDAI Earth Engine Data API Image FALSE FALSE TRUE
# 33 EHdr ESRI .hdr Labelled TRUE TRUE TRUE
# 34 EIR Erdas Imagine Raw FALSE FALSE TRUE
# 35 ELAS ELAS TRUE FALSE TRUE
# 36 ENVI ENVI .hdr Labelled TRUE FALSE TRUE
# 37 ERS ERMapper .ers Labelled TRUE FALSE TRUE
# 38 ESAT Envisat Image Format FALSE FALSE TRUE
# 39 FAST EOSAT FAST Format FALSE FALSE TRUE
# 40 FIT FIT Image FALSE TRUE TRUE
# 41 FujiBAS Fuji BAS Scanner Image FALSE FALSE TRUE
# 42 GFF Ground-based SAR Applications Testbed File Format (.gff) FALSE FALSE TRUE
# 43 GIF Graphics Interchange Format (.gif) FALSE TRUE TRUE
# 44 GMT GMT NetCDF Grid Format FALSE TRUE TRUE
# 45 GPKG GeoPackage TRUE TRUE TRUE
# 46 GRASSASCIIGrid GRASS ASCII Grid FALSE FALSE TRUE
# 47 GRIB GRIdded Binary (.grb, .grb2) FALSE TRUE TRUE
# 48 GS7BG Golden Software 7 Binary Grid (.grd) TRUE TRUE TRUE
# 49 GSAG Golden Software ASCII Grid (.grd) FALSE TRUE TRUE
# 50 GSBG Golden Software Binary Grid (.grd) TRUE TRUE TRUE
# 51 GSC GSC Geogrid FALSE FALSE TRUE
# 52 GTX NOAA Vertical Datum .GTX TRUE FALSE TRUE
# 53 GTiff GeoTIFF TRUE TRUE TRUE
# 54 GXF GeoSoft Grid Exchange Format FALSE FALSE TRUE
# 55 GenBin Generic Binary (.hdr Labelled) FALSE FALSE TRUE
# 56 HDF4 Hierarchical Data Format Release 4 FALSE FALSE TRUE
# 57 HDF4Image HDF4 Dataset TRUE FALSE TRUE
# 58 HDF5 Hierarchical Data Format Release 5 FALSE FALSE TRUE
# 59 HDF5Image HDF5 Dataset FALSE FALSE TRUE
# 60 HF2 HF2/HFZ heightfield raster FALSE TRUE TRUE
# 61 HFA Erdas Imagine Images (.img) TRUE TRUE TRUE
# 62 HTTP HTTP Fetching Wrapper FALSE FALSE TRUE
# 63 IDA Image Data and Analysis TRUE FALSE TRUE
# 64 IGNFHeightASCIIGrid IGN France height correction ASCII Grid FALSE FALSE TRUE
# 65 ILWIS ILWIS Raster Map TRUE TRUE TRUE
# 66 INGR Intergraph Raster TRUE TRUE TRUE
# 67 IRIS IRIS data (.PPI, .CAPPi etc) FALSE FALSE TRUE
# 68 ISCE ISCE raster TRUE FALSE TRUE
# 69 ISG International Service for the Geoid FALSE FALSE TRUE
# 70 ISIS2 USGS Astrogeology ISIS cube (Version 2) TRUE FALSE TRUE
# 71 ISIS3 USGS Astrogeology ISIS cube (Version 3) TRUE TRUE TRUE
# 72 JAXAPALSAR JAXA PALSAR Product Reader (Level 1.1/1.5) FALSE FALSE TRUE
# 73 JDEM Japanese DEM (.mem) FALSE FALSE TRUE
# 74 JP2OpenJPEG JPEG-2000 driver based on OpenJPEG library FALSE TRUE TRUE
# 75 JPEG JPEG JFIF FALSE TRUE TRUE
# 76 KMLSUPEROVERLAY Kml Super Overlay FALSE TRUE TRUE
# 77 KRO KOLOR Raw TRUE FALSE TRUE
# 78 L1B NOAA Polar Orbiter Level 1b Data Set FALSE FALSE TRUE
# 79 LAN Erdas .LAN/.GIS TRUE FALSE TRUE
# 80 LCP FARSITE v.4 Landscape File (.lcp) FALSE TRUE TRUE
# 81 LOSLAS NADCON .los/.las Datum Grid Shift FALSE FALSE TRUE
# 82 Leveller Leveller heightfield TRUE FALSE TRUE
# 83 MAP OziExplorer .MAP FALSE FALSE TRUE
# 84 MBTiles MBTiles TRUE TRUE TRUE
# 85 MEM In Memory Raster TRUE FALSE TRUE
# 86 MFF Vexcel MFF Raster TRUE TRUE TRUE
# 87 MFF2 Vexcel MFF2 (HKV) Raster TRUE TRUE TRUE
# 88 MRF Meta Raster Format TRUE TRUE TRUE
# 89 MSGN EUMETSAT Archive native (.nat) FALSE FALSE TRUE
# 90 NDF NLAPS Data Format FALSE FALSE TRUE
# 91 NGSGEOID NOAA NGS Geoid Height Grids FALSE FALSE TRUE
# 92 NGW NextGIS Web TRUE TRUE TRUE
# 93 NITF National Imagery Transmission Format TRUE TRUE TRUE
# 94 NTv1 NTv1 Datum Grid Shift FALSE FALSE TRUE
# 95 NTv2 NTv2 Datum Grid Shift TRUE FALSE TRUE
# 96 NWT_GRC Northwood Classified Grid Format .grc/.tab FALSE FALSE TRUE
# 97 NWT_GRD Northwood Numeric Grid Format .grd/.tab TRUE TRUE TRUE
# 98 OZI OziExplorer Image File FALSE FALSE TRUE
# 99 PAux PCI .aux Labelled TRUE FALSE TRUE
# 100 PCIDSK PCIDSK Database File TRUE FALSE TRUE
# 101 PCRaster PCRaster Raster File TRUE TRUE TRUE
# 102 PDF Geospatial PDF TRUE TRUE TRUE
# 103 PDS NASA Planetary Data System FALSE FALSE TRUE
# 104 PDS4 NASA Planetary Data System 4 TRUE TRUE TRUE
# 105 PLMOSAIC Planet Labs Mosaics API FALSE FALSE TRUE
# 106 PLSCENES Planet Labs Scenes API FALSE FALSE TRUE
# 107 PNG Portable Network Graphics FALSE TRUE TRUE
# 108 PNM Portable Pixmap Format (netpbm) TRUE FALSE TRUE
# 109 PRF Racurs PHOTOMOD PRF FALSE FALSE TRUE
# 110 PostGISRaster PostGIS Raster driver FALSE TRUE TRUE
# 111 R R Object Data Store FALSE TRUE TRUE
# 112 RDA DigitalGlobe Raster Data Access driver FALSE FALSE TRUE
# 113 RIK Swedish Grid RIK (.rik) FALSE FALSE TRUE
# 114 RMF Raster Matrix Format TRUE FALSE TRUE
# 115 ROI_PAC ROI_PAC raster TRUE FALSE TRUE
# 116 RPFTOC Raster Product Format TOC format FALSE FALSE TRUE
# 117 RRASTER R Raster TRUE TRUE TRUE
# 118 RS2 RadarSat 2 XML Product FALSE FALSE TRUE
# 119 RST Idrisi Raster A.1 TRUE TRUE TRUE
# 120 Rasterlite Rasterlite FALSE TRUE TRUE
# 121 SAFE Sentinel-1 SAR SAFE Product FALSE FALSE TRUE
# 122 SAGA SAGA GIS Binary Grid (.sdat, .sg-grd-z) TRUE TRUE TRUE
# 123 SAR_CEOS CEOS SAR Image FALSE FALSE TRUE
# 124 SDTS SDTS Raster FALSE FALSE TRUE
# 125 SENTINEL2 Sentinel 2 FALSE FALSE TRUE
# 126 SGI SGI Image File Format 1.0 TRUE FALSE TRUE
# 127 SIGDEM Scaled Integer Gridded DEM .sigdem FALSE TRUE TRUE
# 128 SNODAS Snow Data Assimilation System FALSE FALSE TRUE
# 129 SRP Standard Raster Product (ASRP/USRP) FALSE FALSE TRUE
# 130 SRTMHGT SRTMHGT File Format FALSE TRUE TRUE
# 131 TIL EarthWatch .TIL FALSE FALSE TRUE
# 132 TSX TerraSAR-X Product FALSE FALSE TRUE
# 133 Terragen Terragen heightfield TRUE FALSE TRUE
# 134 USGSDEM USGS Optional ASCII DEM (and CDED) FALSE TRUE TRUE
# 135 VICAR MIPL VICAR file TRUE TRUE TRUE
# 136 VRT Virtual Raster TRUE TRUE TRUE
# 137 WCS OGC Web Coverage Service FALSE FALSE TRUE
# 138 WEBP WEBP FALSE TRUE TRUE
# 139 WMS OGC Web Map Service FALSE TRUE TRUE
# 140 WMTS OGC Web Map Tile Service FALSE TRUE TRUE
# 141 XPM X11 PixMap Format FALSE TRUE TRUE
# 142 XYZ ASCII Gridded XYZ FALSE TRUE TRUE
# 143 ZMap ZMap Plus Grid FALSE TRUE TRUE
# 144 netCDF Network Common Data Format TRUE TRUE TRUE
RasterLayer 클래스 객체를 raster() 함수를 사용해서 처음부터 직접 만들 수도 있습니다.
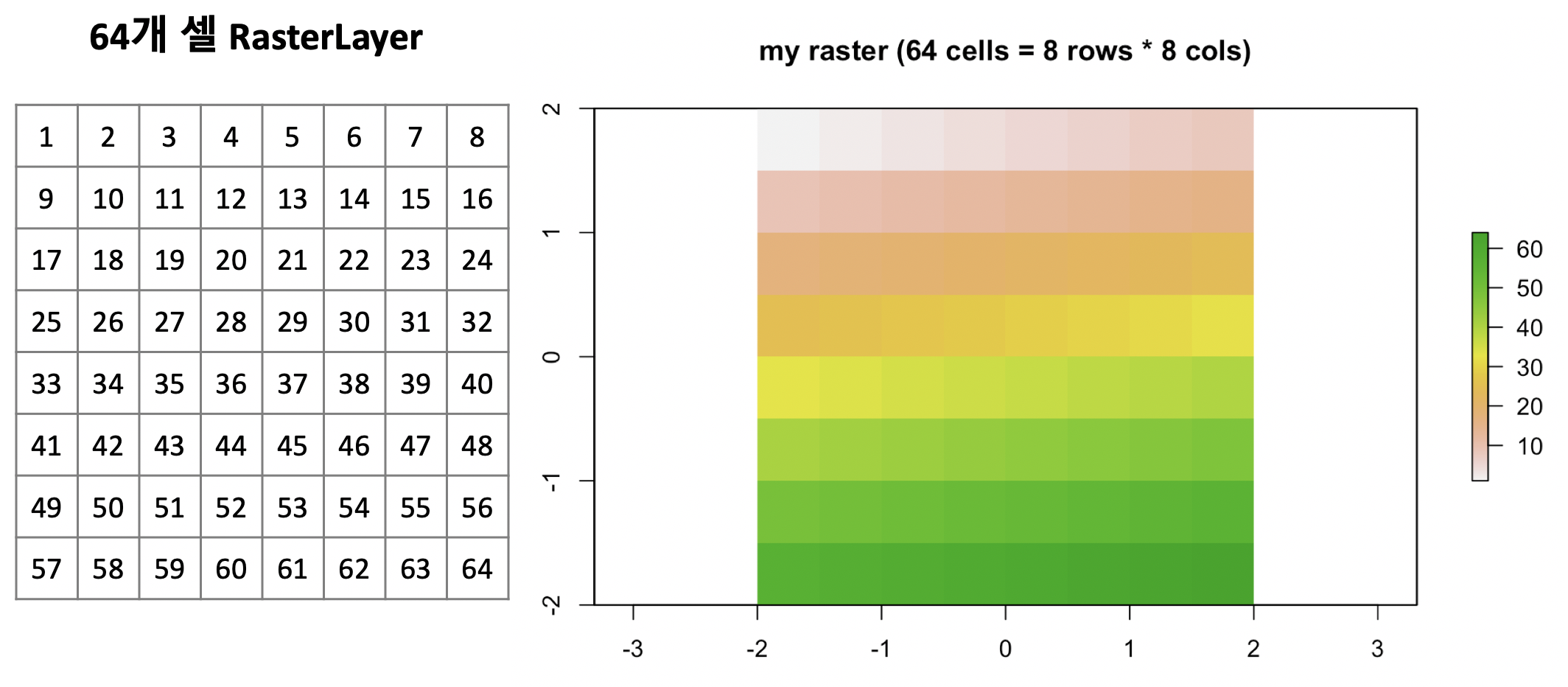
아래의 예는 8개의 행과 8개의 열을 가진, 총 64 개의 셀(or 픽셀)을 가진 RasterLayer 클래스를 직접 만들어본 것입니다. 이때 레스터 객체의 좌표 참조 시스템(CRS, Coordinates Reference System)은 WGS84 가 기본 설정값이며, 이는 해상도(resolution)의 단위가 도 (in degrees) 라는 의미입니다. 아래 예에서는 res = 0.5 로서 해상도를 0.5도로 설정해주었습니다. 각 셀의 값은 왼쪽 상단부터 시작하여, 행 방향(row-wise)으로 왼쪽에서 오른쪽으로 채워나가게 됩니다. 아래 예는 총 64개 셀의 각 셀의 값을 1~64 의 정수값을 좌측 상단에서 시작하여 우측으로 한 줄씩 채워나가도록 했으며, 제일 아래에 8*8 셀들의 값과 오른쪽에 plot()으로 시각화한 결과를 확인해보시기 바랍니다.
## -- Rasters can also be created from scratch using the raster() function.
## RasterLayer object, The CRS is the default of raster objects: WGS84.
## raster of 64 cells (pixels) = 8 rows * 8 cols (row-wise)
my_raster = raster(nrows = 8, ncols = 8, res = 0.5,
xmn = -2.0, xmx = 2.0, ymn = -2.0, ymx = 2.0,
vals = 1:64)
my_raster
# class : RasterLayer
# dimensions : 8, 8, 64 (nrow, ncol, ncell)
# resolution : 0.5, 0.5 (x, y)
# extent : -2, 2, -2, 2 (xmin, xmax, ymin, ymax)
# crs : +proj=longlat +datum=WGS84 +no_defs
# source : memory
# names : layer
# values : 1, 64 (min, max)
## plotting
plot(my_raster, main = "my raster (64 cells = 8 rows * 8 cols)")
(2) RasterBrick Class
위 (1) 의 RasterLayer 클래스가 단지 1개 층 (only 1 layer) 으로만 구성되는 가장 간단한 형태의 레스터 클래스라고 소개했는데요, (2) RasterBrick 클래스와 (3) RasterStack 클래스는 여러개의 층(multiple layers)을 가질 수 있습니다.
특히, RasterBrick 클래스는 단일 다중 스펙트럼 위성 파일 (a single multispectral satellite file) 이나 또는 메모리의 단일 다층 객체 (a single multilayer object in memory) 의 형태로 다층의 레스터 객체를 구성합니다.
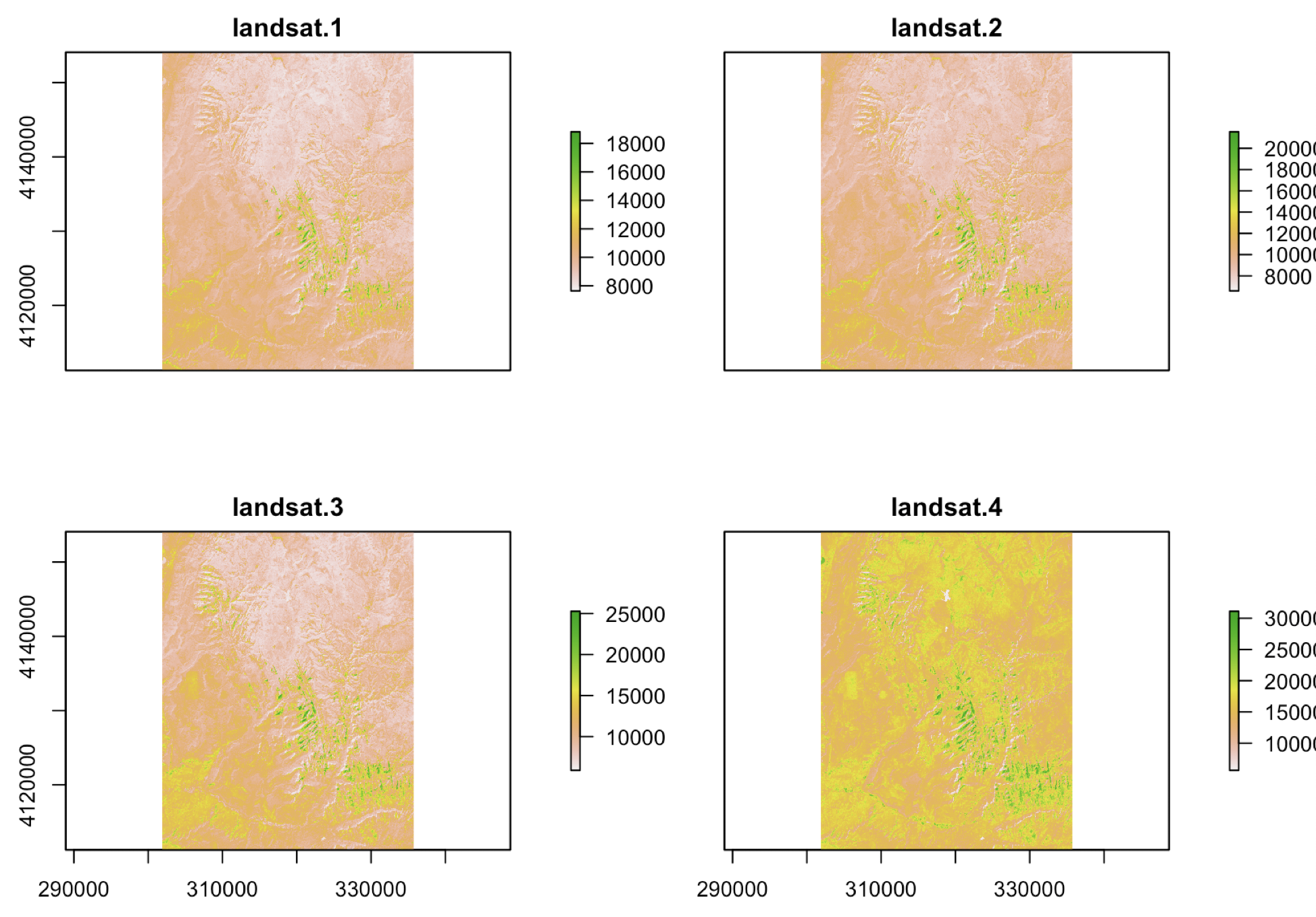
아래의 예는 raster 패키지의 brick() 함수를 사용해서 spDataLarge 패키지에 들어있는 landsat.tif 의 다층 레스터 파일을 RasterBrick 클래스 객체로 불러온 것입니다.
nlayers() 함수로 총 몇 개의 층이 있는지 확인해 보니 4개의 층이 하나의 파일에 들어있네요.
plot() 함수로 RasterBrick 클래스 객체의 4개 층을 모두 시각화보면 아래와 같습니다.
## -- (2) RasterBrick
## : A RasterBrick consists of multiple layers,
## which typically correspond to a single multispectral satellite file
## or a single multilayer object in memory.
multi_raster_file = system.file("raster/landsat.tif", package = "spDataLarge")
raster_brick = brick(multi_raster_file)
## 4 layers
raster_brick
# class : RasterBrick
# dimensions : 1428, 1128, 1610784, 4 (nrow, ncol, ncell, nlayers)
# resolution : 30, 30 (x, y)
# extent : 301905, 335745, 4111245, 4154085 (xmin, xmax, ymin, ymax)
# crs : +proj=utm +zone=12 +datum=WGS84 +units=m +no_defs
# source : /Library/Frameworks/R.framework/Versions/4.0/Resources/library/spDataLarge/raster/landsat.tif
# names : landsat.1, landsat.2, landsat.3, landsat.4
# min values : 7550, 6404, 5678, 5252
# max values : 19071, 22051, 25780, 31961
## nlayers() : number of layers in a Raster* object
nlayers(raster_brick)
# [1] 4
## plotting RasterBrick object with 4 layers
plot(raster_brick)
(3) RasterStack Class
세번째 레스터 클래스인 RasterStack 클래스도 다 층 (multi-layers) 레스터 객체로 구성이 됩니다. 같은 범위와 해상도를 가진 여러개의 RasterLayer 클래스 객체들을 리스트로 묶어서 RasterStack 클래스 객체를 만들 수 있습니다.
이때, 위 (2)번의 RasterBrick 클래스가 동일한 복수개의 RasterLayer 층으로 구성되는 반면에, 이번 (3)번의 RasterStack 클래스는 여러개의 RasterLayer와 RasterBrick 클래스 객체가 혼합되어서 구성할 수 있다는 점입니다. 연산 속도면에서 보면 일반적으로 RasterBrick 클래스가 RasterStack 클래스보다 빠릅니다.
RasterBrick 클래스와 RasterStack 객체에 대한 연산은 보통은 RasterBrack 클래스 객체를 반환합니다.
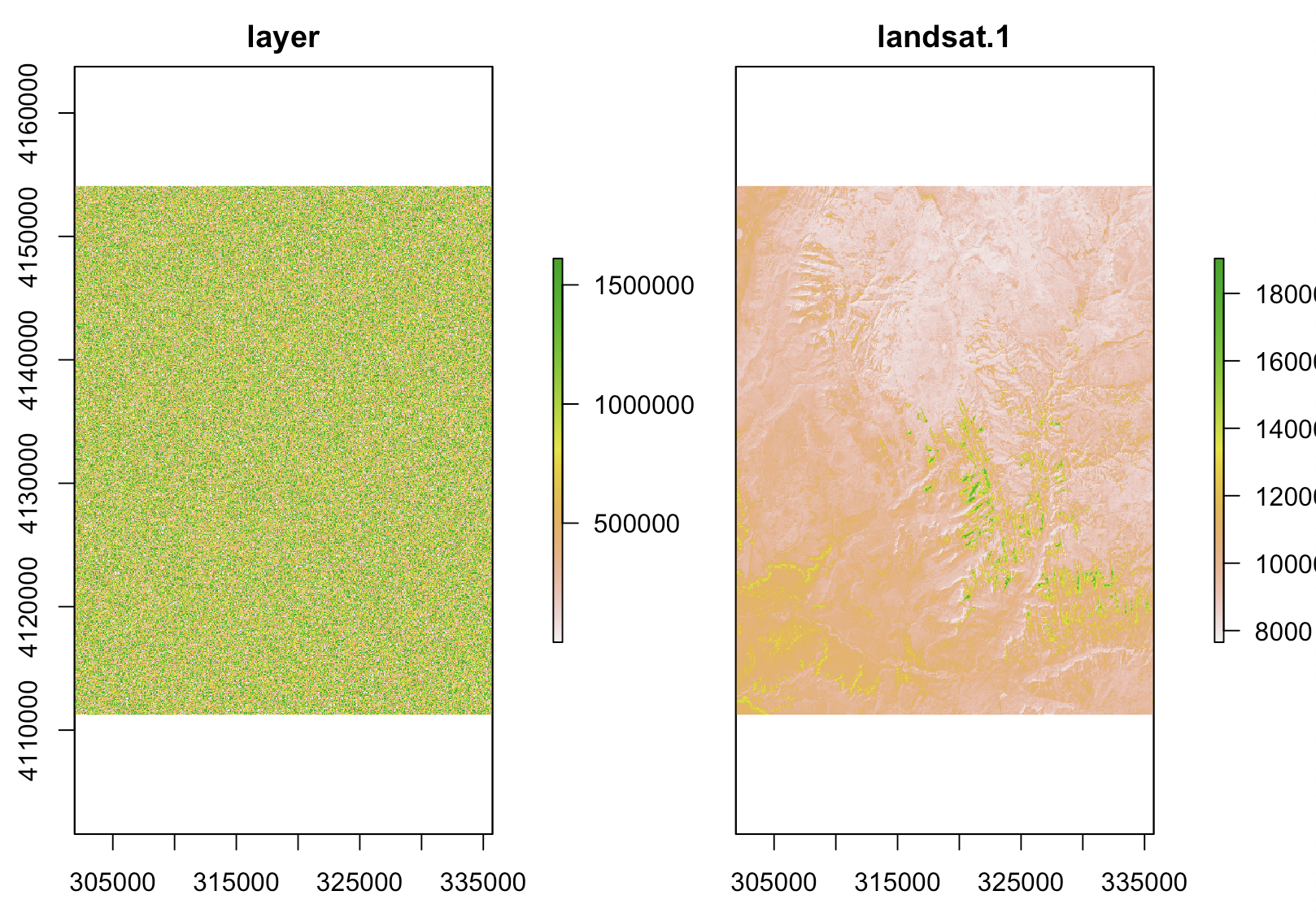
아래 예에서는 (a) raster(raster_brick, layer = 1) 함수를 사용해서 위의 (2)번에서 불러왔던 RasterBrick 클래스 객체의 1번째 층만 가져다가 raster_on_disk 라는 이름으로 레스터 객체를 하나 만들고, (b) raster() 함수로 동일한 범위와 해상도, 좌표 참조 시스템(CRS)를 가지고 난수로 셀의 값을 채운 raster_in_memory 라는 이름의 메모리에 있는 RasterLayer 클래스 객체를 만들었습니다. 다음에 stac() 함수로 raster_stack = stack(raster_in_memory, raster_on_disk) 처럼 (a) + (b) 하여 쌓아서 raster_stack 라는 이름의 RasterStack 클래스 객체를 만들었습니다.
마지막으로 plot() 함수로 RasterStack 클래스 객체에 쌓여 있는 2개의 객체를 시각화해보았습니다. (raster_in_memory 는 난수를 발생시켜 셀 값을 채웠기 때문에 시각화했을 때 아무런 패턴이 없습니다.)
## -- (3) RasterStack
## : RasterStack allows you to connect several raster objects
## stored in different files or multiple objects in memory.
raster_on_disk = raster(raster_brick, layer = 1)
raster_in_memory = raster(xmn = 301905, xmx = 335745,
ymn = 4111245, ymx = 4154085,
res = 30)
values(raster_in_memory) = sample(seq_len(ncell(raster_in_memory)))
crs(raster_in_memory) = crs(raster_on_disk)
## RasterStack is a list of RasterLayer objects with the same extent and resolution.
raster_stack = stack(raster_in_memory, raster_on_disk)
raster_stack
# dimensions : 1428, 1128, 1610784, 2 (nrow, ncol, ncell, nlayers)
# resolution : 30, 30 (x, y)
# extent : 301905, 335745, 4111245, 4154085 (xmin, xmax, ymin, ymax)
# crs : +proj=utm +zone=12 +datum=WGS84 +units=m +no_defs
# names : layer, landsat.1
# min values : 1, 7550
# max values : 1610784, 19071
## plotting RasterStack (raster_in_memory + raster_on_disk)
plot(raster_stack)
(4) 언제 어떤 레스터 클래스를 사용하는 것이 좋은가?
위의 (1), (2), (3)에서 소개한 RasterLayer 클래스, RasterBrick 클래스, RasterStack 클래스의 특징과 서로 간의 차이점을 보면 알겠지만 다시 한번 정리하자면요, Raster* 클래스 중에서 무엇을 사용할 지는 투입 데이터 (input data)의 특징이 무엇이냐에 따라 달라집니다.
하나의 다층 레스터 파일이나 객체(a single multilayer file or object)를 처리하는 것이라면 RasterBrick 이 적합합니다.
반면에, 여러개의 레스터 파일들(many files)이나 여러 종류의 레스터 클래스 (many Raster*) 를 한꺼번에 연결해서 연산하고 처리해야 하는 경우라면 RasterStack Class 가 적합하겠습니다.
[ Reference ]
* Geographic data in R : geocompr.robinlovelace.net/spatial-class.html
이번 포스팅이 많은 도움이 되었기를 바랍니다.
행복한 데이터 과학자 되세요! :-)

728x90
반응형
'R 분석과 프로그래밍 > R 지리공간데이터 분석' 카테고리의 다른 글
| [R 지리공간 데이터 분석] 공간의 단위 (Spatial Units) (2) | 2021.02.14 |
|---|---|
| [R 지리공간 데이터 분석] R에서의 좌표계, 좌표 참조 시스템 (CRS, Coordinate Reference Systems in R) (0) | 2021.02.13 |
| [R 지리공간 데이터 분석] 레스터 데이터 (Raster Data) (0) | 2021.01.24 |
| [R 지리공간 데이터 분석] sf 패키지와 sp 패키지 간 클래스 변환 (conversion b/w R sf and sp classes) (0) | 2021.01.04 |
| [R 지리공간 데이터 분석] sf 클래스 = sfg 객체 (Geometry) + data.frame 속성 (Non-geometric attributes) (0) | 2021.01.03 |








































