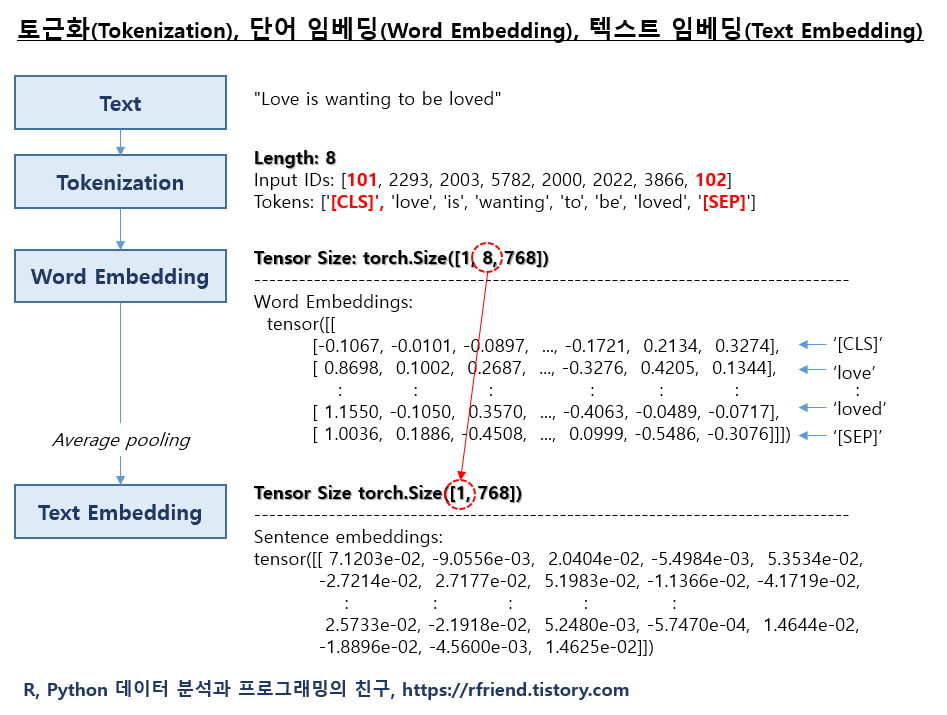
transformer 를 이용한 토큰화 (Tokenization), 단어 임베딩 (Word Embedding), 텍스트 임베팅 (Text Embedding)
Deep Learning (TF, Keras, PyTorch)/Natural Language Processing 2023. 8. 15. 21:31토큰화, 단어 임베딩, 텍스트 임베딩은 자연어 처리(NLP) 및 기계 학습에서 텍스트 데이터를 표현하고 처리하는 데 사용되는 개념입니다. 이러한 개념들은 감정 분석, 기계 번역, 텍스트 분류와 같은 NLP 작업에서 중요하며, 기계 학습 모델이 이해하고 학습할 수 있는 형태로 텍스트 정보를 표현하고 처리하는 데 사용됩니다.
이번 포스팅에서는 토근화(Tokenization), 단어 임베딩 (Word Embedding), 텍스트 임베딩 (Text Embedding)에 대해서 소개하겠습니다. 그리고 transformers 와 PyTorch 를 이용하여 실습을 해보겠습니다.
1. 토큰화 (Tokenization)
- 정의: 토큰화는 텍스트를 토큰이라 불리는 더 작은 단위로 분해하는 과정입니다. 이러한 토큰은 단어, 서브워드 또는 문자일 수 있으며 원하는 정밀도 수준에 따라 다릅니다.
- 목적: 토큰화는 NLP에서 중요한 전처리 단계로, 기계가 텍스트의 개별 요소를 이해하고 처리할 수 있게 합니다. 토큰은 후속 분석을 위한 구성 요소로 작용합니다.
-- Install transformers, torch, sentence-transformers at terminal at first
pip install -q transformers
pip install -q torch
pip install -q -U sentence-transformers# 1. Tokenization
# : Tokenization is the process of breaking down a text into smaller units called tokens.
# : These tokens can be words, subwords, or characters, depending on the level of granularity desired.
from transformers import AutoTokenizer
# Load pre-trained DistilBERT tokenizer
tokenizer = AutoTokenizer.from_pretrained('distilbert-base-uncased')
# Example text
text = "Love is wanting to be loved"
# Tokenize the text
input_ids = tokenizer.encode(text)
tokens = tokenizer.tokenize(tokenizer.decode(input_ids))
print("Input IDs:", input_ids)
print("-------" * 10)
print("Tokens:", tokens)
# Input IDs: [101, 2293, 2003, 5782, 2000, 2022, 3866, 102]
# ----------------------------------------------------------------------
# Tokens: ['[CLS]', 'love', 'is', 'wanting', 'to', 'be', 'loved', '[SEP]']
2. 단어 임베딩 (Word Embedding)
- 정의: 단어 임베딩은 단어를 연속적인 벡터 공간의 실수로 이루어진 밀도 있는 벡터로 나타내는 기술입니다. 각 단어는 벡터로 매핑되며 이러한 벡터 간의 거리와 방향이 의미를 가집니다.
- 목적: 단어 임베딩은 단어 간의 의미적 관계를 포착하여 기계가 주어진 텍스트의 맥락과 의미를 이해할 수 있게 합니다. 단어가 맥락과 의미가 유사한 경우 단어 임베딩 벡터가 서로 가깝게 위치하는 특성이 있어 semantic search에 유용하게 활용됩니다. 유명한 단어 임베딩 모델로는 Word2Vec, GloVe, FastText가 있습니다.
# 2. Word Embedding
# : Word embedding is a technique that represents words
# as dense vectors of real numbers in a continuous vector space.
# : Each word is mapped to a vector, and the distances and directions
# between these vectors carry semantic meaning.
from transformers import AutoTokenizer, AutoModel
import torch
# Load pre-trained DistilBERT model
tokenizer = AutoTokenizer.from_pretrained('distilbert-base-uncased')
model = AutoModel.from_pretrained('distilbert-base-uncased')
# Encode the tokens to obtain word embeddings
input_ids = tokenizer.encode(text, return_tensors='pt')
with torch.no_grad():
word_embeddings = model(input_ids)[0]
print("Tensor Size:", word_embeddings.size())
print("------" * 10)
print("Word Embeddings:")
print(word_embeddings)
# Tensor Size: torch.Size([1, 8, 768])
# ------------------------------------------------------------
# Word Embeddings:
# tensor([[
# [-0.1067, -0.0101, -0.0897, ..., -0.1721, 0.2134, 0.3274],
# [ 0.8698, 0.1002, 0.2687, ..., -0.3276, 0.4205, 0.1344],
# [-0.1877, -0.0777, 0.1905, ..., -0.0220, 0.0024, 0.5138],
# ...,
# [ 0.5998, -0.2141, 0.3774, ..., -0.3945, -0.1149, 0.1245],
# [ 1.1550, -0.1050, 0.3570, ..., -0.4063, -0.0489, -0.0717],
# [ 1.0036, 0.1886, -0.4508, ..., 0.0999, -0.5486, -0.3076]]])
3. 텍스트 임베딩 (Text Embedding)
- 정의: 텍스트 임베딩은 문장(sentences)이나 문서(documents) 전체를 밀도 있는 벡터로 나타내어 전체 텍스트의 전반적인 의미를 캡처하는 기술입니다. 단어 임베딩을 집계하거나 요약하여 전체 텍스트의 표현을 만듭니다.
- 목적: 텍스트 임베딩은 전체 문서나 문장을 의미적 공간에서 비교하고 분석할 수 있게 합니다. 텍스트 임베딩을 생성하는 방법에는 단어 임베딩의 평균(averaging word embeddings)을 사용하거나 순환 신경망(RNN), 장·단기 기억 네트워크(LSTM), 트랜스포머(Transformers)를 사용하는 방법 등이 있습니다.
텍스트 임베딩은
- 텍스트 분류 (Text Classification),
- 감성분석 (Sentiment Analysis),
- 검색 엔진 랭킹 (Search Engine Ranking),
- 군집 및 유사도 분석 (Clustering and Similarity Analysis),
- 질의 응답 (Question Answering, 질문과 답변을 임베딩으로 표현함으로써 시스템은 쿼리의 의미 콘텐츠와 데이터셋의 관련 정보를 정확하게 검색할 수 있음)
등에 활용할 수 있습니다.
text embedding 을 하는 방법에는 (1) transformers 를 이용한 방법과, (2) sentence-transfomers 모델을 이용하는 방법이 있습니다. sentence-transformers 모델을 이용하는 방법이 코드가 간결합니다.
3-1. transformers 를 이용한 text embedding
# 3. Text Embedding
# : Text embedding represents entire sentences or documents as dense vectors,
# capturing the overall meaning of the text.
# : It involves aggregating or summarizing word embeddings
# to create a representation for the entire text.
from transformers import AutoTokenizer, AutoModel
import torch
import torch.nn.functional as F
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
# Example sentence
text = "Love is wanting to be loved"
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('distilbert-base-uncased')
model = AutoModel.from_pretrained('distilbert-base-uncased')
# Tokenize sentences
encoded_input = tokenizer(text, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
# Normalize embeddings
sentence_embeddings = F.normalize(sentence_embeddings, p=2, dim=1)
print("Tensor Size", sentence_embeddings.size())
print("--------" * 10)
print("Sentence embeddings:")
print(sentence_embeddings)
# Tensor Size torch.Size([1, 768])
# --------------------------------------------------------------------------------
# Sentence embeddings:
# tensor([[ 7.1203e-02, -9.0556e-03, 2.0404e-02, -5.4984e-03, 5.3534e-02,
# -2.7214e-02, 2.7177e-02, 5.1983e-02, -1.1366e-02, -4.1719e-02,
# : : : : :
# 2.5733e-02, -2.1918e-02, 5.2480e-03, -5.7470e-04, 1.4644e-02,
# -1.8896e-02, -4.5600e-03, 1.4625e-02]])
3-2. sentence-transformers 모델을 이용한 text embedding
: 'all-mpnet-base-v2' 모델을 HuggingFace에서 다운로드 하여 사용
sentence-transformers 모델에 대한 설명은 https://huggingface.co/sentence-transformers 를 참고하세요.
# ! pip install -q -U sentence-transformers
# Text embedding by sentence-transformers model
# reference: https://huggingface.co/sentence-transformers/all-mpnet-base-v2
from sentence_transformers import SentenceTransformer
text = "Love is wanting to be loved"
model = SentenceTransformer('sentence-transformers/all-mpnet-base-v2')
text_embedding = model.encode(text)
print("Tensor Shape:", text_embedding.shape)
print("------" * 10)
print("Text Embedding:")
print(text_embedding)
# Tensor Shape: (768,)
# ------------------------------------------------------------
# Text Embedding:
# [ 7.25340098e-02 -3.43943425e-02 3.50002125e-02 -1.46801360e-02
# 1.79491900e-02 5.70273288e-02 -9.77409929e-02 2.65225749e-02
# : : : :
# -6.68407883e-03 1.09006204e-02 -1.37606068e-02 -4.93713543e-02
# 3.27182375e-02 5.77081088e-03 4.32791896e-02 -1.55460704e-02]
이번 포스팅이 많은 도움이 되었기를 바랍니다.
행복한 데이터 과학자 되세요! :-)

'Deep Learning (TF, Keras, PyTorch) > Natural Language Processing' 카테고리의 다른 글
| [LangChain] 프롬프트, 모델, 아웃풋 파서 연결하기 (Chaining a prompt template, a model, and output parser using LangChain Expression Language) (0) | 2023.12.18 |
|---|---|
| [LangChain] 언어 모델 기반 애플리케이션 개발 프레임워크 LangChain, Sematic Kernel 의 구성요소와 특성, 관계 (0) | 2023.12.17 |
| ChatGPT를 사용하기 위한 OpenAI API Key 발급하는 방법 (0) | 2023.04.09 |
| OpenAI ChatGPT API 사용하는 방법 (0) | 2023.03.19 |
| [Python] 텍스트 데이터 전처리 및 토큰화 (Tokenization) (0) | 2022.08.01 |