[PostgreSQL, Greenplum] Greenplum의 pgvector와 OpenAI를 이용하여 대규모 AI 기반 검색 구축하기 (Building large-scale AI-powered search in Greenplum using pgvector and OpenAI)
Greenplum and PostgreSQL Database 2023. 7. 2. 20:55[알림] * 본 포스팅 글은 Ahmed Rachid Hazourli (Greenplum Data Engineer in VMware) 가 medium.com 에 2023.5.29일에 "Building large-scale AI-powered search in Greenplum using pgvector and OpenAI"
라는 제목으로 포스팅한 글을 저자의 동의를 얻어서 한국어로 번역한 것입니다.
Greenplum의 pgvector와 OpenAI를 이용하여 대규모 AI 기반 검색 구축하기
(Building large-scale AI-powered search in Greenplum using pgvector and OpenAI)
[들어가는 글]
지난 몇 년간 ChatGPT와 같은 AI 모델의 기하급수적인 발전은 많은 조직이 생성 AI(Generative AI) 및 LLM(Large Language Model)을 출시하여 사용자 경험을 향상시키고 텍스트에서 이미지, 비디오에 이르기까지 비정형 데이터의 잠재력을 최대한 활용하도록 영감을 주었습니다.
이 블로그 글에서는 Greenplum 데이터 웨어하우스 내에서 pgvector 확장의 벡터 유사성 검색(vector similarity search) 기능을 활용하고 이를 OpenAI 모델과 결합하여 페타바이트급 대규모 텍스트 데이터에서 귀중한 통찰력을 추출하고 Greenplum의 놀라운 MPP 아키텍처(Massively Parallel Processing Architecture)를 활용하는 방법에 대해 알아보겠습니다.
도입 (Introduction):
기업들은 AI를 위해 데이터 플랫폼을 확장하고 챗봇, 추천 시스템 또는 검색 엔진에 대용량 언어 모델을 사용할 수 있는 기술과 방법을 찾기 시작했습니다.
그러나 한 가지 구체적인 과제는 이러한 AI 모델을 관리 및 배포하고 ML 생성 임베딩(ML-generated embeddings)을 규모있게 저장 및 쿼리하는 것이었습니다.
임베딩이란 무엇입니까? (What are embeddings?)
임베딩(Embeddings)은 데이터 또는 텍스트, 이미지 또는 오디오와 같은 복잡한 객체를 고차원 공간의 숫자들의 리스트로 변환하는 것을 말합니다.
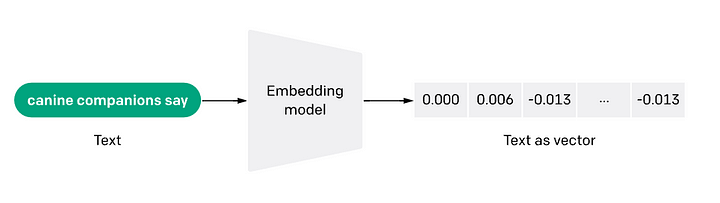
* 이미지 출처: OpenAI
이 기술은 데이터의 의미와 맥락(의미론적 관계, semantic relationships) 및 데이터 내의 복잡한 관계와 패턴(구문론적 관계, syntactic relationship)에 대한 지식을 캡처/이해할 수 있게 해주는 모든 기계학습(ML) 또는 딥러닝(DL) 알고리듬에 사용됩니다.

* 이미지 출처: https://www.pinecone.io/learn/vector-embeddings/
정보 검색, 이미지 분류, 자연어 처리 등 다양한 애플리케이션에 대해 벡터 표현(vector representations) 결과를 사용할 수 있습니다.
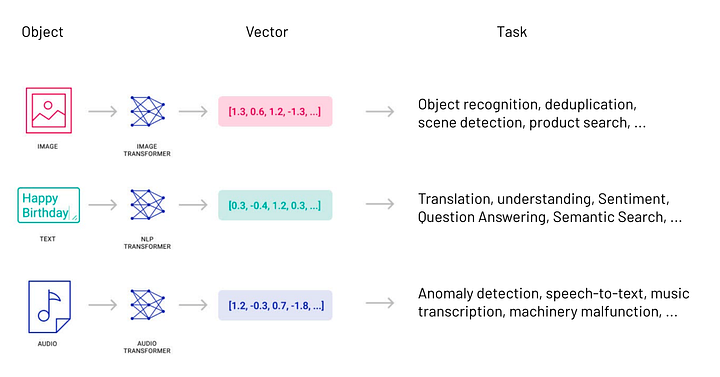
* 이미지 출처: https://dev.to/josethz00/vector-databases-5df1
다음 다이어그램은 2D 공간에서 단어 임베딩(woed embeddings in 2D space)이 어떻게 보여지는지를 시각적으로 나타냅니다.
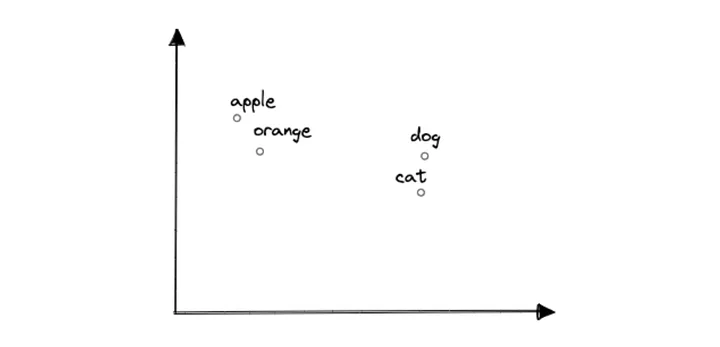
* 이미지 출처: https://neon.tech/blog/building-an-ai-powered-chatbot-using-vercel-openai-and-postgres
의미론적으로 유사한 단어들이 임베딩에서 서로 가까이 있다는 것을 알 수 있습니다. 예를 들어, "사과"라는 단어는 "개"나 "고양이"보다 "오렌지"에 더 가깝습니다.
임베딩을 생성한 후, 회사는 벡터 공간 내에서 유사성 검색(similarity searches)을 수행하고 제품 추천 시스템과 같은 AI 애플리케이션을 구축할 수 있습니다.
pgvector를 사용하여 Greenplum에 임베딩 저장하기
(Storing embeddings in Greeplum using pgvector)
Greenplum 7은 pgvector 확장(pgvector extension) 덕분에 벡터 임베딩을 대규모로 저장하고 쿼리할 준비가 잘 되어 있습니다. 이를 통해 Greenplum 데이터 웨어하우스에 벡터 데이터베이스(vector database) 기능을 제공하여 사용자가 빠른 검색과 효율적인 유사성 검색을 수행할 수 있습니다.
Greenplum의 pgvector 를 사용하여 ML 지원 응용프로그램에 대한 데이터베이스를 설정, 운영 및 확장할 수 있습니다.
예를 들어, 스트리밍 서비스는 pgvector를 사용하여 방금 본 것과 유사한 영화 추천 목록을 제공할 수 있습니다.
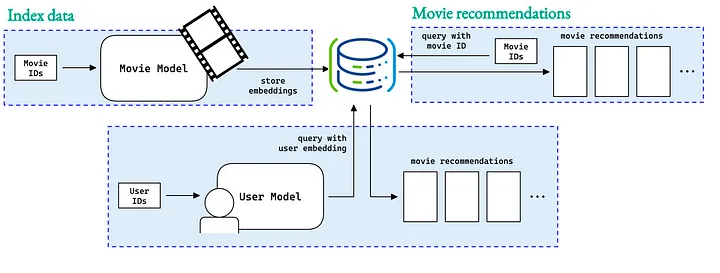
왜 Greenplum 이고 pgvector 인가?
많은 기업이 다른 벡터 데이터베이스를 관리하지 않고도 엔터프라이즈 데이터 웨어하우스 내에서 벡터 의미 검색(vector semantic searches)을 저장, 쿼리 및 수행하려고 합니다.
다행히 Greenplum과 pgvector를 결합하면 AI 모델의 임베딩을 사용하여 빠르고 확장 가능한 애플리케이션을 구축하고 더 빨리 운영에 들어갈 수 있습니다.
pgvector와 OpenAI를 사용하여 Greenplum에서 제품 설명서에 사용할 AI-Assistant를 구축하기.
문맥:
우리 모두는 이전에 ChatGPT와 같은 챗봇을 사용한 적이 있으며 캐주얼하고 범용적인 질문에 적합하다는 것을 알았습니다. 하지만, 깊고 도메인별 지식이 필요할 때 ChatGPT는 부족하다는 것을 알아차렸을 수도 있습니다. 또한, 그것은 지식의 격차를 메우기 위해 답을 만들고 결코 출처를 언급하지 않습니다.
하지만 어떻게 이것을 개선할 수 있을까요? 적합한 데이터 소스를 정확하게 검색하고 질문에 답변하는 ChatGPT를 구축하려면 어떻게 해야 할까요?
답변:
이 질문에 대한 대답은 제품 설명서를 검색 가능하게 만들고 작업별 프롬프트를 OpenAI에 제공하면 결과가 더 신뢰할 수 있다는 것입니다. 즉, 사용자가 질문할 때 Greenplum 테이블에서 적합한 데이터 세트를 검색하도록 pgvector에게 요청합니다. 그런 다음 사용자의 질문에 답변하기 위한 참조 문서(reference document)로 OpenAI에 제공합니다.
실제 임베딩 적용하기:
이 섹션에서는 임베딩을 실제 적용한 모습을 살펴보고, 임베딩 저장을 용이하게 하고 벡터의 가장 가까운 이웃에 대한 쿼리를 가능하게 하는 Greenplum에 대한 오픈 소스 pgvector 확장을 사용하는 방법을 배울 것입니다.
다음 그림과 같이 OpenAI를 사용하여 지능형 챗봇을 구축하고 시맨틱 텍스트 검색을 통해 Greenplum, RabbitMQ, Gemfire, VMware SQL 및 VMware Data Service Manager에 대한 자세한 기술적 질문에 답변할 수 있는 VMware 데이터 솔루션에 대한 도메인별 지식을 얻을 수 있도록 지원함으로써 이 기능을 시연합니다:
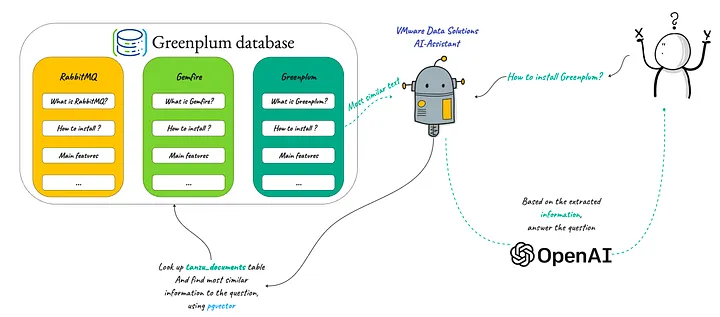
주요 절차는 다음과 같습니다.
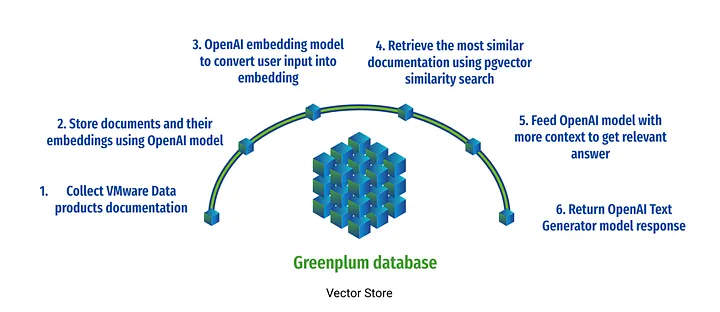
1. pgvector extension 을 설치하고 활성화합니다.
pgvector 를 설치한 후에 Greenplum에서 벡터 임베딩의 저장을 시작하고 다음과 같이 pgvector 실행을 활성화하여 의미 검색(semantic searches)을 수행할 수 있습니다:
CREATE EXTENSION vector;
2. VECTOR 데이터 유형으로 제품 설명서 테이블 만들기
다음 SQL 쿼리로 제품 설명서와 임베딩을 저장할 테이블을 만들어 보겠습니다:
CREATE TABLE tanzu_documents (
id bigserial primary key,
content text,
embedding vector(1536)
)
DISTRIBUTED BY (id)
;
pgvector는 벡터(VECTOR data-type)라고 불리는 새로운 데이터 유형을 도입합니다. 우리는 위의 쿼리 코드에서 벡터 데이터 유형으로 임베딩 열을 만들었습니다. 벡터의 크기는 벡터가 얼마나 많은 차원을 보유하는지 정의합니다. OpenAI의 text—embedding-ada-002 모델은 1,536개의 차원을 출력하므로 벡터 크기에 사용할 것입니다.
이 게시물에서 OpenAI API를 사용하고 있으므로 다음을 실행하는 모든 Greenplum 호스트에 openai 패키지를 설치합니다:
gpssh -f gphostsfile -e 'pip3 install -y openai'
또한 이 임베딩을 생성한 원본 제품 설명서 텍스트를 저장하기 위해 content 라는 text 열을 만듭니다.
참고: 위의 table은 Greenplum 세그먼트에 걸쳐 "id" 열을 기준으로 분산 저장(distributed by the “id”)되며, pgvector extension은 Greenplum 기능과 완벽하게 작동합니다. 따라서 분산저장에서 파티셔닝에 이르기까지 Greenplum의 MPP(Massiviely Parallel Processing) 기능에 대량의 데이터를 관리하고 검색하는 pgvector의 효율성을 추가하면 Greenplum 사용자는 확장 가능한 규모있는 AI 애플리케이션을 구축할 수 있습니다.
3. OpenAI 임베딩 가져오기 위한 Greenplum PL/Python 함수
이제 문서에 대한 임베딩을 생성해야 합니다. 여기서는 OpenAI의 text-message-ada-002 모델 API를 사용하여 텍스트에서 임베딩을 생성합니다.
가장 좋은 방법은 Greenplum 데이터베이스 내에 PL/Python3u 절차적 언어(Procedural Language)를 사용하여 Python 함수를 생성하는 것입니다. 다음 Greenplum Python 함수는 각 입력 문서에 대한 벡터 임베딩(vector embeddings)을 반환합니다.
CREATE OR REPLACE FUNCTION get_embeddings(content text)
RETURNS VECTOR
AS
$$
import openai
import os
text = content
openai.api_key = os.getenv("OPENAI_API_KEY")
response = openai.Embedding.create(
model="text-embedding-ada-002",
input = text.replace("\n"," ")
)
embedding = response['data'][0]['embedding']
return embedding
$$ LANGUAGE PLPYTHON3U;* 참고: OpenAI API key 생성하는 방법은 https://rfriend.tistory.com/794 를 참고하세요.
4. Greenplum 테이블에 데이터 넣기
원본 텍스트를 tanzu_documents 테이블, 특히 content 열에 로딩한 다음, embedding 열을 업데이트하고 이전에 생성된 get_messages Python 함수를 사용하여 모든 컨텐츠에 대해 OpenAI 임베딩을 생성합니다:
UPDATE tanzu_documents SET embedding = get_embeddings(content);
5. 첫 번째 의미론적 검색 (Semantic Search) 질의
pgvector의 코사인 거리를 사용하여 (<=> 연산자를 사용하여) 첫 번째 의미 검색 쿼리를 만들고, 질문과 가장 유사한 텍스트(즉, 최소 거리를 가진 텍스트)를 찾아보겠습니다: Greenplum 설치 방법? (How to install Greenplum? )
WITH cte_question_embedding AS
(
SELECT
get_embeddings(
'How to create an external table in Greenplum
using PXF to read from an Oracle database ?'
)
AS question_embeddings
)
SELECT
id
, content
, embedding <=> cte_question_embedding.question_embeddings AS distance
FROM tanzu_documents, cte_question_embedding
ORDER BY embedding <=> cte_question_embedding.question_embeddings ASC
LIMIT 1;
pgvector는 유사성을 계산하는 데 사용할 수 있는 세 가지 새로운 연산자를 소개합니다:
- (1) 유클리드 거리 (Euclidean distance)(L2 거리): <->,
- (2) 음의 내적 (Negative inner product): <#>,
- (3) 코사인 거리 (Cosine distance): <=>
* 참고: 유클리드 거리 (Euclidean distance)는 https://rfriend.tistory.com/199 를 참고하세요.
코사인 거리 (Cosine distance)는 https://rfriend.tistory.com/319 를 참고하세요.
SELECT 문은 다음 출력을 반환해야 합니다:
id | 640
content | title: Accessing External Data with PXF
-- Data managed by your organisation may already reside in external sources
-- such as Hadoop, object stores, and other SQL databases.
-- The Greenplum Platform Extension Framework \(PXF\) provides access
-- to this external data via built-in connectors that map an external
-- data source to a Greenplum Database table definition.
-- PXF is installed with Hadoop and Object Storage connectors.
-- These connectors enable you to read external data stored in text,
-- Avro, JSON, RCFile, Parquet, SequenceFile, and ORC formats.
-- You can use the JDBC connector to access an external SQL database.
-- > **Note** In previous versions of the Greenplum Database,
-- you may have used the `gphdfs` external table protocol to access
-- data stored in Hadoop. Greenplum Database version 6.0.0
-- removes the `gphdfs` protocol. Use PXF and the `pxf` external table
-- protocol to access Hadoop in Greenplum Database version 6.x.
-- The Greenplum Platform Extension Framework includes
-- a C-language extension and a Java service.
-- After configuring and initialising PXF, you start a single
-- PXF JVM process on each Greenplum Database segment host.
-- This long-running process concurrently serves multiple query requests.
-- For detailed information about the architecture of and using PXF,
-- refer to the [Greenplum Platform Extension Framework \(PXF\)]
-- (https://docs.vmware.com/en/VMware-Greenplum-Platform-Extension-Framework
-- /6.6/greenplum-platform-extension-framework/overview_pxf.html) documentation.
-- **Parent topic:** [Working with External Data]
-- (../external/g-working-with-file-based-ext-tables.html) **Parent topic:**
-- [Loading and Unloading Data](../load/topics/g-loading-and-unloading-data.html)
distance | 0.12006528354516588
6. 유사성 검색 SQL 함수:
많은 임베딩에 대해 유사성 검색을 수행할 예정이기 때문에, 이를 위한 SQL 사용자 정의 함수를 생성합니다:
CREATE OR REPLACE FUNCTION match_documents (
query_embedding VECTOR(1536),
match_threshold FLOAT,
match_count INT
)
RETURNS TABLE (
id BIGINT,
content TEXT,
similarity FLOAT
)
AS $$
SELECT
documents.id,
documents.content,
1 - (documents.embedding <=> query_embedding) AS similarity
FROM tanzu_documents documents
WHERE 1 - (documents.embedding <=> query_embedding) > match_threshold
ORDER BY similarity DESC
LIMIT match_count;
$$ LANGUAGE SQL STABLE;
위에서 정의한 match_documents 함수를 사용하여 다음과 같이 가장 유사한 텍스트를 OpenAI 모델에 제공합니다:
SELECT t.id, t.content, t.similarity
FROM match_documents(
(select get_embeddings(
'How to create an external table in Greenplum using PXF
to read from an Oracle database ?'))
, 0.8
, 1) t
;id | 640
content | title: Accessing External Data with PXF
-- Data managed by your organisation may already reside in external sources
-- such as Hadoop, object stores, and other SQL databases.
-- The Greenplum Platform Extension Framework \(PXF\) provides access
-- to this external data via built-in connectors
-- that map an external data source to a Greenplum Database table definition.
-- PXF is installed with Hadoop and Object Storage connectors.
-- These connectors enable you to read external data stored in text, Avro,
-- JSON, RCFile, Parquet, SequenceFile, and ORC formats.
-- You can use the JDBC connector to access an external SQL database.
-- > **Note** In previous versions of the Greenplum Database,
-- you may have used the `gphdfs` external table protocol to access data
-- stored in Hadoop. Greenplum Database version 6.0.0 removes the `gphdfs` protocol.
-- Use PXF and the `pxf` external table protocol to access Hadoop in
-- Greenplum Database version 6.x.
-- The Greenplum Platform Extension Framework includes a C-language extension
-- and a Java service. After configuring and initialising PXF,
-- you start a single PXF JVM process on each Greenplum Database segment host.
-- This long-running process concurrently serves multiple query requests.
-- For detailed information about the architecture of and using PXF,
-- refer to the [Greenplum Platform Extension Framework \(PXF\)]
-- (https://docs.vmware.com/en/VMware-Greenplum-Platform-Extension-Framework/6.6/
-- greenplum-platform-extension-framework/overview_pxf.html) documentation.
-- **Parent topic:** [Working with External Data](../external/g-working-with-file-based-ext-tables.html)
-- **Parent topic:** [Loading and Unloading Data](../load/topics/g-loading-and-unloading-data.html)
similarity | 0.8775289173395486
7. 벡터 인덱싱 (Vectors Indexing):
우리의 테이블은 임베딩과 함께 시간이 지남에 따라 커질 수 있으며, 수십억 개의 벡터에 걸쳐 의미 검색을 수행하기를 원할 것입니다.
pgvector의 뛰어난 점은 쿼리 속도를 높이고 검색 속도를 높일 수 있는 인덱싱(Indexing) 기능입니다.
벡터 인덱스는 정확한 최근접이웃 검색(ANN/KNN, Nearest Neighbour)을 수행합니다. 벡터는 유사성에 따라 그룹화되지 않으므로 순차적 검색(sequential scan)을 통해 가장 가까운 이웃을 찾는 작업은 느리며, 유사성에 따라 정렬을 빠르게 하는 것이 중요합니다(ORDER BY 절).
각 거리 연산자에는 서로 다른 유형의 인덱스가 필요합니다. 시작할 때 적절한 수의 lists 는 1백만개 행까지는 1,000개, 1백만개 이상의 경우 sqrt(행) 개입니다. 코사인 거리로 정렬하기 때문에 vector_cosine_ops 인덱스를 사용합니다.
-- Create a Vector Index
CREATE INDEX ON tanzu_documents
USING ivfflat (embedding vector_cosine_ops)
WITH
(lists = 300);
-- Analyze table
ANALYZE tanzu_documents;
pgvector 인덱싱에 대한 자세한 내용은 여기에서 확인하십시오.
https://github.com/pgvector/pgvector#indexing
8. 관련 답변에 적합한 데이터 세트를 OpenAI 모델에 제공합니다.
사용자의 인풋과 사용자 인풋에 가장 유사한 텍스트 둘 다를 인풋으로 사용해서 OPenAI 모델에게 답하도록 질문하는 PL/Python 함수를 정의합니다.
CREATE FUNCTION ask_openai(user_input text, document text)
RETURNS TEXT
AS
$$
import openai
import os
openai.api_key = os.getenv("OPENAI_API_KEY")
search_string = user_input
docs_text = document
messages = [
{"role": "system",
"content": "You concisely answer questions based on text provided to you."}
]
prompt = """Answer the user's prompt or question:
{search_string}
by summarising the following text:
{docs_text}
Keep your answer direct and concise. Provide code snippets where applicable.
The question is about a Greenplum / PostgreSQL database.
You can enrich the answer with other Greenplum or PostgreSQL-relevant details
if applicable.""".format(
search_string=search_string,
docs_text=docs_text
)
messages.append({"role": "user", "content": prompt})
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=messages
)
return response.choices[0]["message"]["content"]
$$ LANGUAGE PLPYTHON3U;
9. 더 똑똑한 검색 기능 만들기
앞서 언급했듯이, ChatGPT는 기존의 문서만 반환하지 않습니다. ChatGPT는 다양한 정보를 이해해서 하나의 응집력있는 대답으로 만들 수 있습니다. 이를 위해 GPT에 관련 문서와 이 답변을 생성하는 데 사용할 수 있는 프롬프트를 제공해야 합니다.
마지막 단계로, 우리는 지능형 AI-Assistant 애플리케이션을 서비스하기 위해 이전 기능을 단일 프로세스로 결합해야 합니다.
이전 기능과 임베딩은 프롬프트를 2단계 프로세스로 분할하여 이 문제를 해결할 수 있습니다:
1. 임베딩 데이터베이스에 질문과 가장 관련성이 높은 문서를 조회합니다.
2. 이러한 문서를 OpenAI 모델이 답변에서 참조할 컨텍스트로 삽입합니다.
CREATE OR REPLACE FUNCTION intelligent_ai_assistant(
user_input TEXT
)
RETURNS TABLE (
content TEXT
)
LANGUAGE SQL STABLE
AS $$
SELECT
ask_openai(user_input,
(SELECT t.content
FROM match_documents(
(SELECT get_embeddings(user_input)) ,
0.8,
1) t
)
);
$$;
위의 SQL 함수는 사용자 입력을 가져다가 임베딩으로 변환하고, tanzu_documents 테이블에 대해 pgvector를 사용하여 의미론적 텍스트 검색을 수행하여 가장 관련성이 높은 문서를 찾고, 마지막으로 이를 OpenAI API 호출에 대한 참조 텍스트로 제공하여 최종 답변을 반환합니다.
10. OpenAI 및 Streamlit 🎈를 활용한 시맨틱 텍스트 검색 기능으로 강화된 자체 챗봇 구축 🤖
마지막으로, 우리는 문서를 이해하고 pgvector 시맨틱 텍스트 검색과 함께 Greenplum 데이터 웨어하우스를 사용하는 Streamlit 🎈 챗봇 🤖를 개발했습니다.
챗봇 스트림릿 애플리케이션은 https://greenplum-pgvector-chatbot.streamlit.app/에서 이용할 수 있습니다.
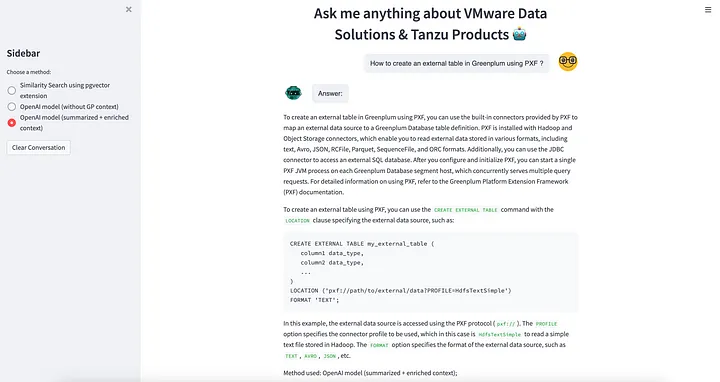
소스 코드는 https://github.com/ahmedrachid/streamlit-chatbot-greenplum 에서 확인할 수 있습니다
🚀 결론
결론적으로, 확장 가능한 AI 애플리케이션을 구축하고자 하는 기업은 Greenplum 의 대규모 병렬 처리 기능 및 성능을 pgvector 연산과 결합함으로써, 방대한 양의 벡터 임베딩 및 비정형 데이터에 대해 빠른 검색, 유사성 및 의미 검색을 수행할 수 있습니다.
참조 (References):
1. Open-source Greenplum data warehouse
: https://greenplum.org/
2. VMware Greenplum data warehouse
: https://docs.vmware.com/en/VMware-Tanzu-Greenplum/index.html
3. pgvector extension - Open-source vector similarity search for Postgres
: https://github.com/pgvector/pgvector
읽어주셔서 감사합니다! 어떠한 의견이나 제안도 환영합니다!
여기에서 다른 Greenplum 기사를 확인하십시오.
이번 포스팅이 많은 도움이 되었기를 바랍니다.
행복한 데이터 과학자 되세요! :-)