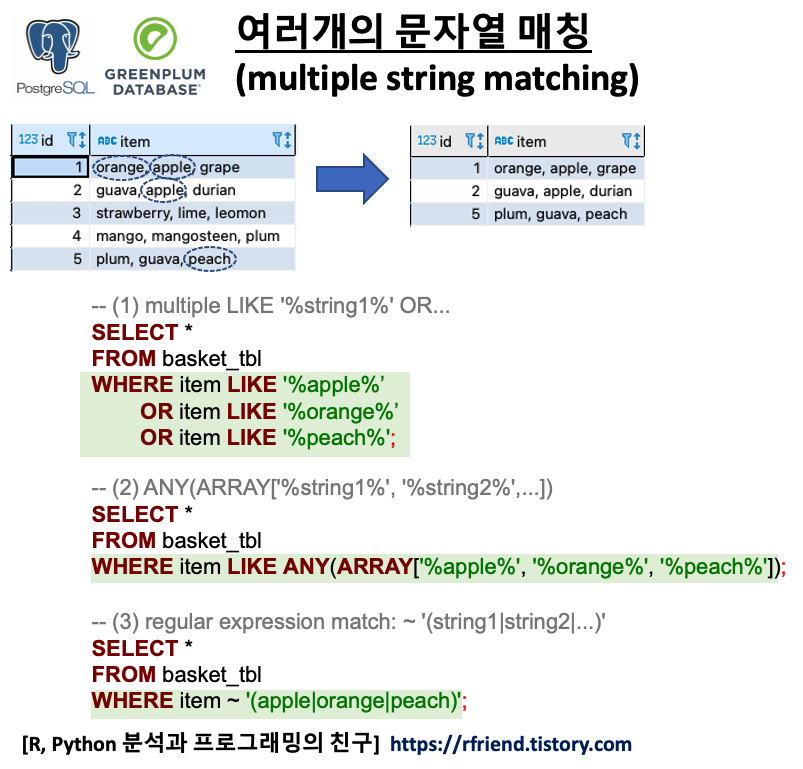
이번 포스팅에서는 PostgreSQL, Greenplum DB에서 여러개의 문자열을 'OR' 조건으로 매칭하는 3가지 SQL 방법을 소개하겠습니다.
(1) LIKE '%string1%' OR LIKE '%string2%' ...
(2) ANY(ARRAY['%string1%', '%string2%', ...])
(3) regular expression matching: ~ '(string1|string2|...)'
먼저 예제로 사용할 샘플 테이블을 만들어보겠습니다. 과일가게에서 장바구니 ID별로 구매한 과일 품목이 문자열로 들어있는 테이블입니다.
-- create a sample table
DROP TABLE IF EXISTS basket_tbl;
CREATE TABLE basket_tbl (
id int
, item text
);
INSERT INTO basket_tbl VALUES
(1, 'orange, apple, grape')
, (2, 'guava, apple, durian')
, (3, 'strawberry, lime, leomon')
, (4, 'mango, mangosteen, plum')
, (5, 'plum, guava, peach');
SELECT * FROM basket_tbl ORDER BY id;
--id|item |
----+------------------------+
-- 1|orange, apple, grape |
-- 2|guava, apple, durian |
-- 3|strawberry, lime, leomon|
-- 4|mango, mangosteen, plum |
-- 5|plum, guava, peach |
위의 샘플 테이블의 item 칼럼의 문자열에서 'apple', 'orange', 'peach' 중에 하나라도(OR) 문자열이 매칭(string matching)이 되면 SELECT 문으로 조회를 해오는 SQL query 를 3가지 방법으로 작성해보겠습니다.
(1) LIKE '%string1%' OR LIKE '%string2%' ...
가장 단순한 반면에, 조건절 항목이 많아질 경우 SQL query 가 굉장히 길어지고 비효율적인 단점이 있습니다.
-- (1) multiple LIKE '%string1%' OR LIKE '%string2%' OR...
SELECT *
FROM basket_tbl
WHERE item LIKE '%apple%'
OR item LIKE '%orange%'
OR item LIKE '%peach%'
ORDER BY id;
--id|item |
----+--------------------+
-- 1|orange, apple, grape|
-- 2|guava, apple, durian|
-- 5|plum, guava, peach |
(2) ANY(ARRAY['%string1%', '%string2%', ...])
문자열 매칭 조건절의 각 문자열 항목을 ARRAY[] 에 나열을 해주고, any() 연산자를 사용해서 이들 문자열 조건 중에서 하나라도 매칭이 되면 반환을 하도록 하는 방법입니다. 위의 (1)번 보다는 SQL query 가 짧고 깔끔해졌습니다.
-- (2) ANY(ARRAY['%string1%', '%string2%',...])
SELECT *
FROM basket_tbl
WHERE item LIKE ANY(ARRAY['%apple%', '%orange%', '%peach%'])
ORDER BY id;
--id|item |
----+--------------------+
-- 1|orange, apple, grape|
-- 2|guava, apple, durian|
-- 5|plum, guava, peach |
(3) regular expression matching: ~ '(string1|string2|...)'
마지막으로, 정규표현식(regular expression) '~'을 이용해서 복수의 문자열을 OR 조건(수직바 '|')으로 매칭하는 방법입니다. '%'를 사용하지 않아도 되므로 (1), (2) 와 비교했을 때 가장 SQL query 가 간단한 방법입니다.
-- (3) regular expression match: ~ '(string1|string2|...)'
SELECT *
FROM basket_tbl
WHERE item ~ '(apple|orange|peach)'
ORDER BY id;
--id|item |
----+--------------------+
-- 1|orange, apple, grape|
-- 2|guava, apple, durian|
-- 5|plum, guava, peach |
이번 포스팅이 많은 도움이 되었기를 바랍니다.
행복한 데이터 과학자 되세요~! :-)






