[Python pandas] DataFrame.filter(): 특정 조건에 맞는 칼럼이나 행을 선택해 가져오기
Python 분석과 프로그래밍/Python 데이터 전처리 2023. 1. 17. 08:22이번 포스팅에서는 Python pandas DataFrmae에서 filter() 함수를 사용하여 특정 조건에 맞는 칼럼이나 행을 선택해서 가져오는 방법을 소개하겠습니다.
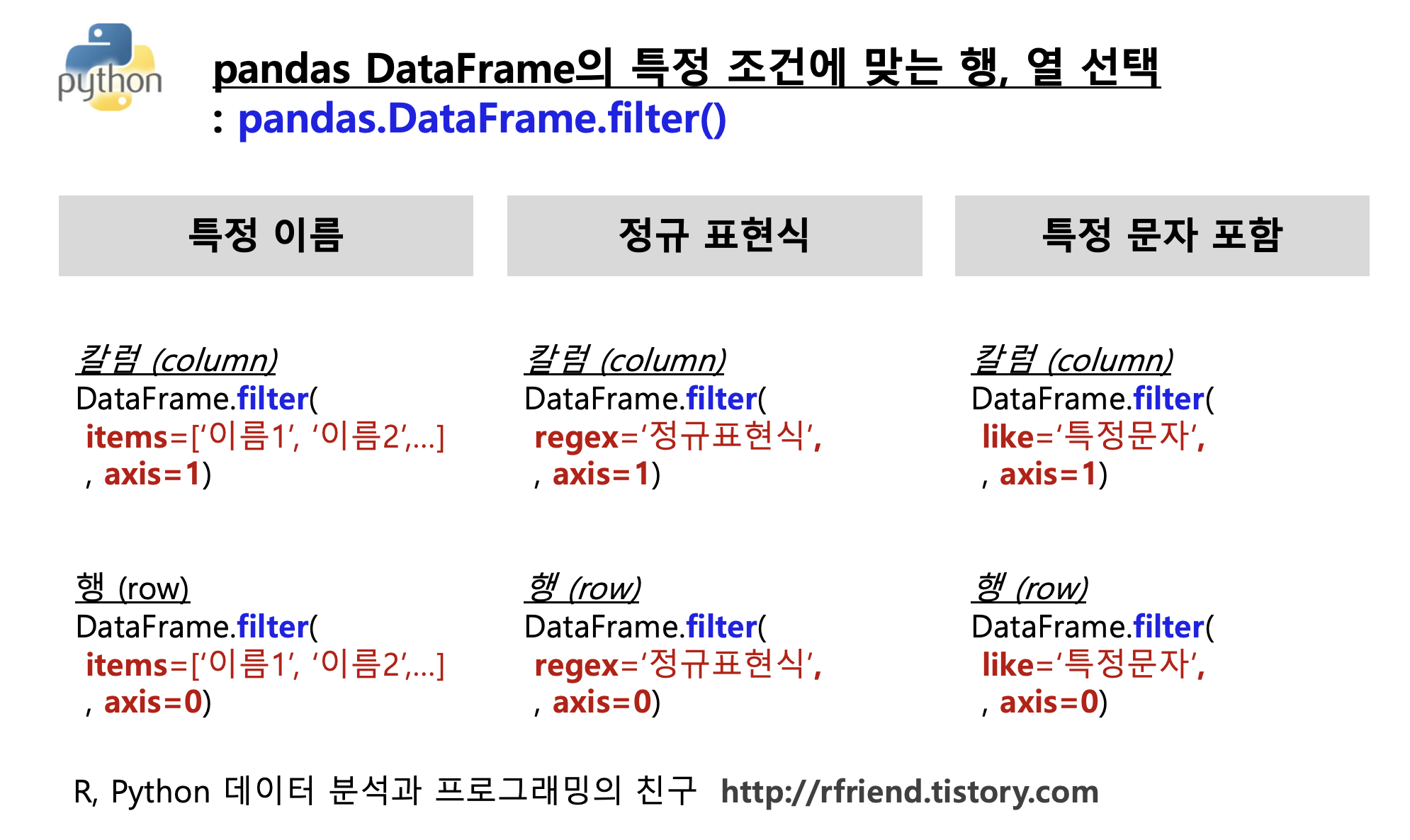
(1) pd.DataFrame.filter() 함수의 items 옵션을 사용하여 '이름'으로 행이나 열을 선택해서 가져오기
(2) pd.DataFrame.filter() 함수의 regex 옵션을 사용하여 '정규 표현식'으로 행이나 열을 선택해서 가져오기
(3) pd.DataFrame.filter() 함수의 like 옵션을 사용하여 '특정 문자를 포함'하는 행이나 열을 선택해서 가져오기
먼저 예제로 사용할 간단한 DataFrame을 만들어보겠습니다.
## sample pandas DataFrame
import numpy as np
import pandas as pd
df = pd.DataFrame(
np.arange(12).reshape(3, 4),
index=['abc', 'bbb', 'ccc'],
columns=['x_1', 'x_2', 'var1', 'var2'])
df
# x_1 x_2 var1 var2
# abc 0 1 2 3
# bbb 4 5 6 7
# ccc 8 9 10 11
(1) pd.DataFrame.filter() 함수의 items 옵션을 사용하여 '이름'으로 행이나 열을 선택해서 가져오기
(1-1) pd.DataFrame.filter(items = ['칼럼 이름 1', '칼럼 이름 2', ...], axis=1) 옵션을 사용해서 '특정 칼럼 이름'의 데이터를 선택해서 가져올 수 있습니다. 칼럼 이름은 리스트 형태 (list-like) 로 나열해줍니다. axis 의 디폴트 옵션은 axis = 1 로서 칼럼 기준입니다.
참고로, 일상적으로 많이 사용하는 df[['칼럼 이름 1', '칼럼 이름 2', ...]] 와 같습니다.
## pd.DataFrame.filter()
## : Subset the dataframe rows or columns according to the specified index labels.
## reference: https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.filter.html
## (1-1) items: select columns by name
## equivalently: df[['x_1', 'var2']]
df.filter(items=['x_1', 'var2'], axis=1)
# x_1 var2
# abc 0 3
# bbb 4 7
# ccc 8 11
(1-2) pd.DataFrame.filter(items = ['열 이름 1', '열 이름 2', ...], axis=0) 옵션을 사용해서 '특정 열 이름'의 데이터를 선택해서 가져올 수 있습니다.
참고로, 자주 사용하는 df.loc[['열 이름 1', '열 이름 2', ...]] 와 같습니다.
## (1-2) items: select rows by name
## equivalently: df.loc[['bbb', 'abc']]
df.filter(items=['bbb', 'abc'], axis=0)
# x_1 x_2 var1 var2
# bbb 4 5 6 7
# abc 0 1 2 3
(2) pd.DataFrame.filter() 함수의 regex 옵션을 사용하여 '정규 표현식'으로 행이나 열을 선택해서 가져오기
DataFrame.filter() 함수의 힘은 정규 표현식(regular expression)을 사용해서 행이나 열을 선택할 수 있다는 점입니다. 정규 표현식은 너무 광범위해서 이 포스팅에서 세부적으로 다루기에는 무리구요, 아래에는 정규 표현식의 강력함에 대한 맛보기로 세 개의 예시를 준비해봤습니다.
(2-1) 정규 표현식을 이용해서 특정 문자로 시작(^)하는 모든 칼럼 선택해서 가져오기: regex='^(특정문자).+'
## (2) select columns by regular expression
## (2-1) 'x_' 로 시작하는 모든 칼럼 선택
## 캐럿 기호 ^는 텍스트의 시작,
df.filter(regex='^(x_).+', axis=1)
# x_1 x_2
# abc 0 1
# bbb 4 5
# ccc 8 9
(2-2) 정규 표현식을 이용해서 특정 문자로 끝나는($) 모든 칼럼 선택해서 가져오기: regex='특정문자$'
## (2-2) '2' 루 끝나는 모든 칼럼 선택
## 달러 기호 $는 텍스트의 끝
df.filter(regex='2$', axis=1)
# x_2 var2
# abc 1 3
# bbb 5 7
# ccc 9 11
(2-3) 정규 표현식을 이용해서 특정 문자로 시작하지 않는 모든 칼럼 선택해서 가져오기: regex='^(?!특정문자).+'
## (2-3) 'x_' 로 시작하지 않는 모든 칼럼 선택
df.filter(regex='^(?!x_).+', axis=1)
# var1 var2
# abc 2 3
# bbb 6 7
# ccc 10 11
(2-4) 정규 표현식을 이용해서 행 이름의 끝에 특정 문자를 포함하는 행(row)을 선택하기
: DataFrame.filter(regex='특정문자$', axis=0)
## select rows(axis=0) containing 'c' at the end using regular expression.
df.filter(regex='c$', axis=0)
# x_1 x_2 var1 var2
# abc 0 1 2 3
# ccc 8 9 10 11
(3) pd.DataFrame.filter() 함수의 like 옵션을 사용하여 '특정 문자를 포함'하는 행이나 열을 선택해서 가져오기
(3-1) 특정 문자를 포함하는 칼럼(column)을 선택해서 가져오기: df.filter(like='특정 문자', axis=1)
## (3) filter(like)
## select columns(axis=1) containing 'x_'
df.filter(like='x_', axis=1)
# x_1 x_2
# abc 0 1
# bbb 4 5
# ccc 8 9
(3-2) 특정 문자를 포함하는 행(row)을 선택해서 가져오기: df.filter(like='문정 문자', axis=0)
## select rows(axis=0) containing 'b' in a string
df.filter(like='b', axis=0)
# x_1 x_2 var1 var2
# abc 0 1 2 3
# bbb 4 5 6 7
[Reference]
pandas.DataFrame.filter(): https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.filter.html
이번 포스팅이 많은 도움이 되었기를 바랍니다.
행복한 데이터 과학자 되세요! :-)

'Python 분석과 프로그래밍 > Python 데이터 전처리' 카테고리의 다른 글
| [Python] 파워포인트와 PDF 파일에서 텍스트 추출하기 (0) | 2023.03.19 |
|---|---|
| [Python Numpy] 반복자 enumerate() vs. 다차원 반복자np.ndenumerate() (0) | 2023.03.05 |
| [Python pandas] pandas DataFrame의 데이터 유형별 칼럼 선택, 배제 (0) | 2023.01.03 |
| [Python] 리스트 원소 데이터 유형 변환, 원소 값 변환, 빼기, 정렬 (0) | 2023.01.02 |
| [Python] Dictionary (Key: Value 매핑) 를 이용하여 여러개의 문자열 변경하기 (replace multiple strings using Dictionary and replace() method) (0) | 2022.12.18 |


 date_sample
date_sample



 test_text_file.txt
test_text_file.txt





