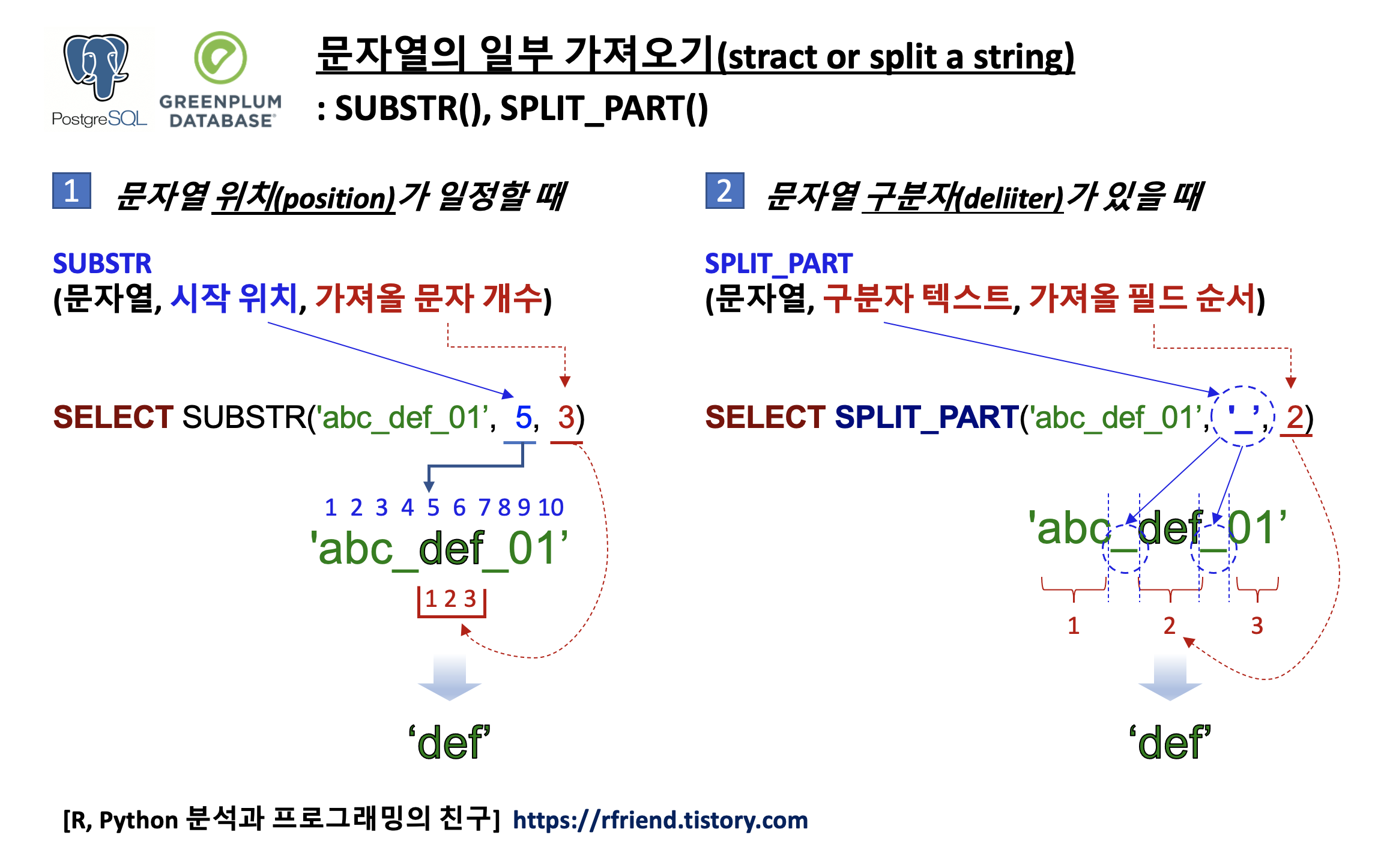
SUBSTR() 함수는 문자열의 포맷이 일정하게 정해져 있어서 위치를 기반으로 문자열의 특정한 일부분만 가져올 때 사용합니다. 반면에, SPLIT_PART() 함수는 문자열에 구분자(delimiter)가 있어서, 이 구분자를 기준으로 문자열을 구분한 후에 특정 순서에 위치한 문자열의 일부분을 가져올 때 사용합니다.
아래에 간단한 예를 들어서 설명하겠습니다.
(1) 위치 기반(position based)으로 문자열의 일부분 가져오기: SUBSTRING(), SUBSTR()
- syntax: SUBSTR(문자열, 시작 위치, 가져올 문자 개수)
substr() 함수와 substring() 함수는 동일합니다.
---------------------------------------------
-- String functions in PostgreSQL
-- substr() vs. split_part()
---------------------------------------------
-- (1) substr(string, from [, count])
-- : Extract substring
-- : when position is fixed
SELECT
SUBSTR('abc_def_01', 1, 3) AS substr_1
, SUBSTR('abc_def_01', 5, 3) AS substr_2
, SUBSTR('abc_def_01', 9, 2) AS substr_3;
--substr_1|substr_2|substr_3|
----------+--------+--------+
--abc |def |01 |
-- or equivalently (same as substring(string from from for count))
SELECT
SUBSTRING('abc_def_01', 1, 3) AS substr_1
, SUBSTRING('abc_def_01', 5, 3) AS substr_2
, SUBSTRING('abc_def_01', 9, 2) AS substr_3;
-- (2) split_part(string text, delimiter text, field int)
-- : Split string on delimiter and return the given field (counting from one)
-- : when deliiter is fixed
SELECT
SPLIT_PART('abc_def_01', '_', 1) AS split_part_1
, SPLIT_PART('abc_def_01', '_', 2) AS split_part_2
, SPLIT_PART('abc_def_01', '_', 3) AS split_part_3;
--split_part_1|split_part_2|split_part_3|
--------------+------------+------------+
--abc |def |01 |
이번 포스팅에서는 PostgreSQL, Greenplum 에서 Apahe MADlib 의 함수를 사용하여
(1) 2D array 를 1D array 로 unnest 하기
(Unnest 2D array into 1D array in PostgreSQL using madlib.array_unnest_2d_to_1d() function)
(2) 1D array 에서 순서대로 원소 값을 indexing 하기
하는 방법을 소개하겠습니다.
how to unnest 2D array into 1D array and indexing in PostgreSQL, Greenplum DB
먼저, 예제로 사용할 간단한 2D array를 포함하는 테이블을 만들어 보겠습니다.
--------------------------------------------------------------------------------
-- How to unnest a 2D array into a 1D array in PostgreSQL?
-- [reference] http://madlib.incubator.apache.org/docs/latest/array__ops_8sql__in.html#af057b589f2a2cb1095caa99feaeb3d70
--------------------------------------------------------------------------------
-- Creating a sample 2D array table
DROP TABLE IF EXISTS mat_2d_arr;
CREATE TABLE mat_2d_arr (id int, var_2d int[]);
INSERT INTO mat_2d_arr VALUES
(1, '{{1, 2, 3}, {4, 5, 6}, {7, 8, 9}}'),
(2, '{{10, 11, 12}, {13, 14, 15}, {16, 17, 18}}'),
(3, '{{19, 20, 21}, {22, 23, 24}, {25, 26, 27}}'),
(4, '{{28, 29, 30}, {31, 32, 33}, {34, 35, 36}}');
SELECT * FROM mat_2d_arr ORDER BY id;
--id|var_2d |
----+----------------------------------+
-- 1|{{1,2,3},{4,5,6},{7,8,9}} |
-- 2|{{10,11,12},{13,14,15},{16,17,18}}|
-- 3|{{19,20,21},{22,23,24},{25,26,27}}|
-- 4|{{28,29,30},{31,32,33},{34,35,36}}|
(1) 2D array 를 1D array 로 unnest 하기
(Unnest 2D array into 1D array in PostgreSQL using madlib.array_unnest_2d_to_1d() function)
Apache MADlib 의 madlib.array_unnest_2d_to_1d() 함수를 사용하면 쉽게 PostgreSQL, Greenplum의 2D array를 1D array 로 unnest 할 수 있습니다. madlib.array_unnest_2d_to_1d() 함수는 'unnest_row_id' 와 'unnest_result' 의 2개 칼럼을 반환하므로, 이들 "2개 칼럼 모두"를 반환하라는 의미로 (madlib.array_unnest_2d_to_1d(var_2d)).* 함수의 처음과 끝부분에 괄호 ()로 묶고 마지막에 아스타리스크(.*) 부호를 붙여주었습니다. ().* 를 빼먹지 않도록 주의하세요.
MADlib 함수를 사용하지 않는다면 직접 PL/SQL 사용자 정의 함수나 또는 PL/Python 이나 PL/R 사용자 정의 함수를 정의하고 실행해야 하는데요, 좀 번거롭고 어렵습니다.
-- (1) Unnest 2D array into a 1D array using madlib.array_unnest_2d_to_1d() function
SELECT
id
, (madlib.array_unnest_2d_to_1d(var_2d)).*
FROM mat_2d_arr
ORDER BY id, unnest_row_id;
--id|unnest_row_id|unnest_result|
----+-------------+-------------+
-- 1| 1|{1,2,3} |
-- 1| 2|{4,5,6} |
-- 1| 3|{7,8,9} |
-- 2| 1|{10,11,12} |
-- 2| 2|{13,14,15} |
-- 2| 3|{16,17,18} |
-- 3| 1|{19,20,21} |
-- 3| 2|{22,23,24} |
-- 3| 3|{25,26,27} |
-- 4| 1|{28,29,30} |
-- 4| 2|{31,32,33} |
-- 4| 3|{34,35,36} |
아래는 2D array를 1D array로 unnest 하는 사용자 정의함수(UDF) 를 plpgsql 로 정의해서 SQL query 로 호출해서 사용하는 방법입니다.
-- UDF for unnest 2D array into 1D array
CREATE OR REPLACE FUNCTION unnest_2d_1d(ANYARRAY, OUT a ANYARRAY)
RETURNS SETOF ANYARRAY
LANGUAGE plpgsql IMMUTABLE STRICT AS
$func$
BEGIN
FOREACH a SLICE 1 IN ARRAY $1 LOOP
RETURN NEXT;
END LOOP;
END
$func$;
-- Unnest 2D array into 1D array using the UDF above
SELECT
id
, unnest_2d_1d(var_2d) AS var_1d
FROM mat_2d_arr
ORDER BY 1, 2;
--id|var_1d |
----+----------+
-- 1|{1,2,3} |
-- 1|{4,5,6} |
-- 1|{7,8,9} |
-- 2|{10,11,12}|
-- 2|{13,14,15}|
-- 2|{16,17,18}|
-- 3|{19,20,21}|
-- 3|{22,23,24}|
-- 3|{25,26,27}|
-- 4|{28,29,30}|
-- 4|{31,32,33}|
-- 4|{34,35,36}|
(2) 1D array 에서 순서대로 원소 값을 indexing 하기
일단 2D array를 1D array 로 unnest 하고 나면, 그 다음에 1D array에서 순서대로 각 원소를 inndexing 해오는 것은 기본 SQL 구문을 사용하면 됩니다. 1D array 안에 각 3개의 원소들이 들어 있으므로, 순서대로 unnest_result[1], unnest_result[2], unnest_result[3] 으로 해서 indexing 을 해오면 아래 예제와 같습니다.
-- (2) Indexing an unnested 1D array
SELECT
a.id
, unnest_row_id
, unnest_result[1] AS x1
, unnest_result[2] AS x2
, unnest_result[3] AS x3
FROM (
SELECT
id
, (madlib.array_unnest_2d_to_1d(var_2d)).*
FROM mat_2d_arr
) AS a
ORDER BY id, unnest_row_id;
--id|unnest_row_id|x1|x2|x3|
----+-------------+--+--+--+
-- 1| 1| 1| 2| 3|
-- 1| 2| 4| 5| 6|
-- 1| 3| 7| 8| 9|
-- 2| 1|10|11|12|
-- 2| 2|13|14|15|
-- 2| 3|16|17|18|
-- 3| 1|19|20|21|
-- 3| 2|22|23|24|
-- 3| 3|25|26|27|
-- 4| 1|28|29|30|
-- 4| 2|31|32|33|
-- 4| 3|34|35|36|
데이터셋에 이상치가 있으면 모델을 훈련시킬 때 적합된 모수에 큰 영향을 줍니다. 따라서 탐색적 데이터 분석을 할 때 이상치(outlier)를 찾고 제거하는 작업이 필요합니다.
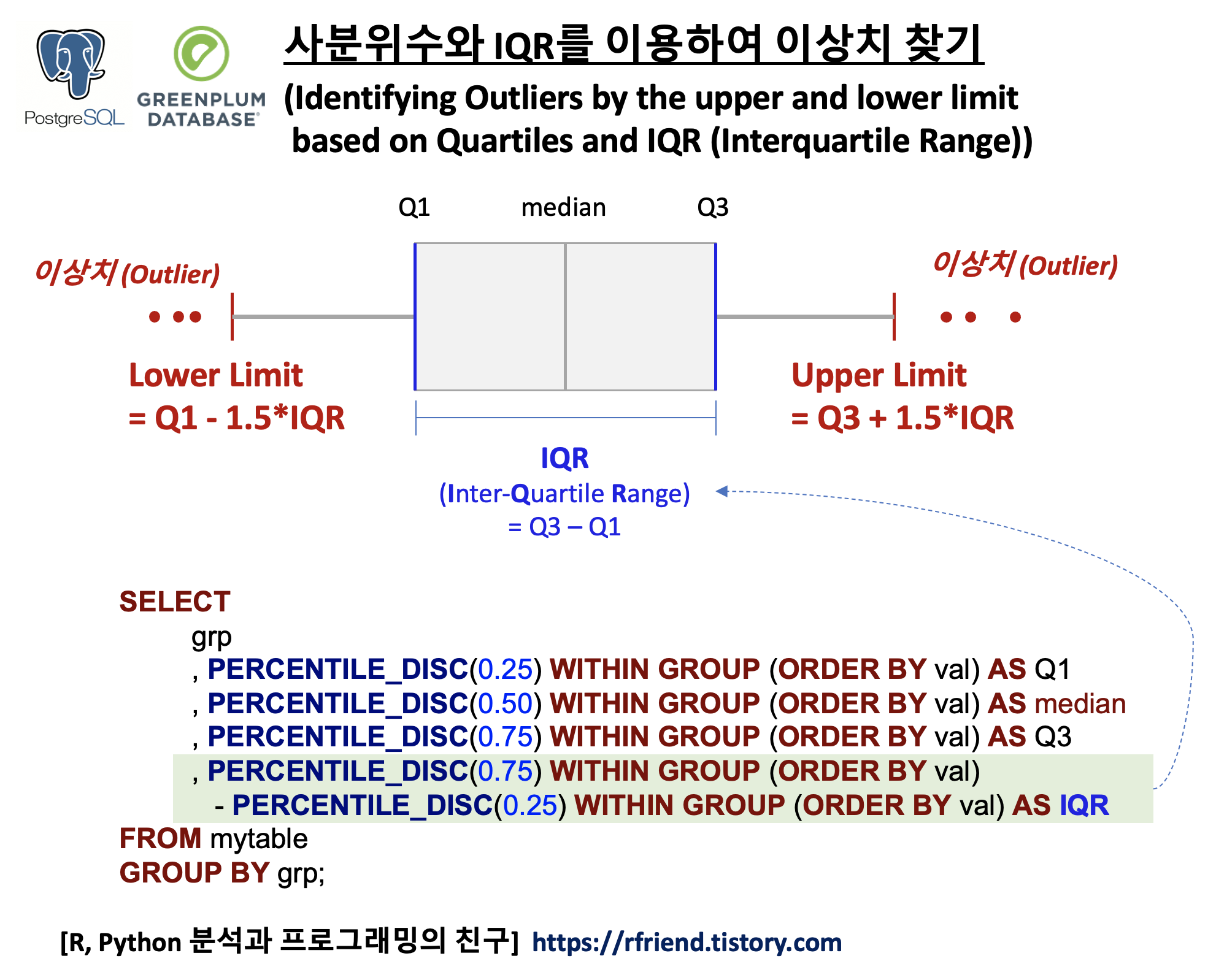
이번 포스팅에서는 PostgreSQL, Greenplum DB에서 SQL의 PERCENTILE_DISC() WITHIN GROUP (ORDER BY) 함수를 사용해서, 사분위수와 IQR 에 기반하여 이상치를 찾고 제거하는 방법(Identifying and removing Outliers by the upper and lower limit based on Quartiles and IQR(Interquartile Range))을 소개하겠습니다.
요약통계량의 평균과 표준편차는 이상치에 매우 민감합니다. 따라서 정규분포가 아니라 이상치가 존재하여 한쪽으로 치우친 분포에서는 (average +-3 * standard deviation) 범위 밖의 값을 이상치로 간주하는 방법은 적합하지 않을 수 있습니다. 반면, 이상치에 덜 민감한 사분위수와 IQR 를 이용하여 이상치를 찾고 제거하는 방법은 간단하게 구현하여 사용할 수 있습니다.
identifying outliers by upper and lower limit based on quartiles and IQR using SQL
먼저, 예제로 사용할 데이터셋 테이블을 만들어보겠습니다. 부산과 서울의 지역(region) 그룹별로 seller_id 별 판매금액(amt) 을 칼럼으로 가지며, 판매금액에 이상치(outliler)를 포함시켰습니다.
PostgreSQL, Greenplum 에서 PERCENTILE_DISC() 함수를 사용하여 사분위수(quartiles)와 IQR(Interquartile Range)를 구할 수 있습니다. 아래 예에서는 지역(region) 별로 1사분위수(Q1), 중앙값(median), 3사분위수(Q3), IQR (Interquartile Range) 를 구해보았습니다.
IQR (Interquartile Range) = Q3 - Q1
-- Quartiles by region groups
-- Interquartile Range (IQR) = Q3-Q1
-- : relatively robust statistic compared to range and std dev for the measure of spread.
SELECT
region
, PERCENTILE_DISC(0.25) WITHIN GROUP (ORDER BY amt) AS q1
, PERCENTILE_DISC(0.50) WITHIN GROUP (ORDER BY amt) AS median
, PERCENTILE_DISC(0.75) WITHIN GROUP (ORDER BY amt) AS q3
, PERCENTILE_DISC(0.75) WITHIN GROUP (ORDER BY amt) -
PERCENTILE_DISC(0.25) WITHIN GROUP (ORDER BY amt) AS iqr
FROM reg_sales
GROUP BY region
ORDER BY region;
--region|q1 |median|q3 |iqr|
--------+---+------+---+---+
--Busan |350| 390|450|100|
--Seoul |350| 380|440| 90|
사분위수와 IQR 를 이용하여 이상치를 찾는 방식(identifying outliers by upper and lower limit based on quartiles and IQR using SQL in PostgreSQL)은 아래와 같습니다. (포스팅 상단의 도식 참조)
* Upper Limit = Q1 - 1.5 * IQR
* Lower Limit = Q3 + 1.5 * IQR
if value > Upper Limit then 'Outlier'
or if value < Lower Limit then 'Outlier'
-- Identifying outliers by the upper and lower limit based on Quartiles and IQR as:
-- : Lower Limit = Q1 – 1.5 * IQR
-- : Upper Limit = Q3 + 1.5 * IQR
WITH stats AS (
SELECT
region
, PERCENTILE_DISC(0.25) WITHIN GROUP (ORDER BY amt) AS q1
, PERCENTILE_DISC(0.75) WITHIN GROUP (ORDER BY amt) AS q3
, PERCENTILE_DISC(0.75) WITHIN GROUP (ORDER BY amt) -
PERCENTILE_DISC(0.25) WITHIN GROUP (ORDER BY amt) AS iqr
FROM reg_sales
GROUP BY region
)
SELECT
r.*
FROM reg_sales AS r
LEFT JOIN stats AS s ON r.region = s.region
WHERE r.amt < (s.q1 - 1.5 * s.iqr) OR r.amt > (s.q3 + 1.5 * s.iqr) -- identifying outliers
ORDER BY region, amt;
--region|seller_id|amt |
--------+---------+----+
--Busan | 1| 10|
--Busan | 9|3200|
--Busan | 10|4600|
--Seoul | 1| 20|
--Seoul | 10|2500|
아래의 예에서는 사분위수와 IQR에 기반하여 이상치를 제거 (Removing outliers by upper and lower limit based on quartiles and IQR using SQL in PostgreSQL) 하여 보겠습니다.
-- Removing outliers by the upper and lower limit based on Quartiles and IQR as:
-- : Lower Limit = Q1 – 1.5 * IQR
-- : Upper Limit = Q3 + 1.5 * IQR
WITH stats AS (
SELECT
region
, PERCENTILE_DISC(0.25) WITHIN GROUP (ORDER BY amt) AS q1
, PERCENTILE_DISC(0.75) WITHIN GROUP (ORDER BY amt) AS q3
, PERCENTILE_DISC(0.75) WITHIN GROUP (ORDER BY amt) -
PERCENTILE_DISC(0.25) WITHIN GROUP (ORDER BY amt) AS iqr
FROM reg_sales
GROUP BY region
)
SELECT
r.*
FROM reg_sales AS r
LEFT JOIN stats AS s ON r.region = s.region
WHERE r.amt > (s.q1 - 1.5 * s.iqr) AND r.amt < (s.q3 + 1.5 * s.iqr) -- removing outliers
ORDER BY region, amt;
--region|seller_id|amt|
--------+---------+---+
--Busan | 2|310|
--Busan | 3|350|
--Busan | 4|380|
--Busan | 5|390|
--Busan | 6|430|
--Busan | 7|450|
--Busan | 8|450|
--Seoul | 2|300|
--Seoul | 3|350|
--Seoul | 4|370|
--Seoul | 5|380|
--Seoul | 6|400|
--Seoul | 7|410|
--Seoul | 8|440|
--Seoul | 9|460|
데이터 분석을 하다보면 데이터 전처리 단계에서 '결측값 확인 및 처리(handling missing values) '가 필요합니다.
시계열 데이터의 결측값을 처리하는 방법에는 보간(interpolation), 이전/이후 값으로 대체, 이동평균(moving average)으로 대체 등 여러가지 방법(https://rfriend.tistory.com/682)이 있습니다.
이번 포스팅에서는 가장 간단한 방법으로서 PostgreSQL, Greenplum DB에서 SQL로 first_value() window function을 사용해서 할 수 있는 '결측값을 이전 값으로 채우기' 또는 '결측값을 이후 값으로 채이기' 하는 방법을 소개하겠습니다.
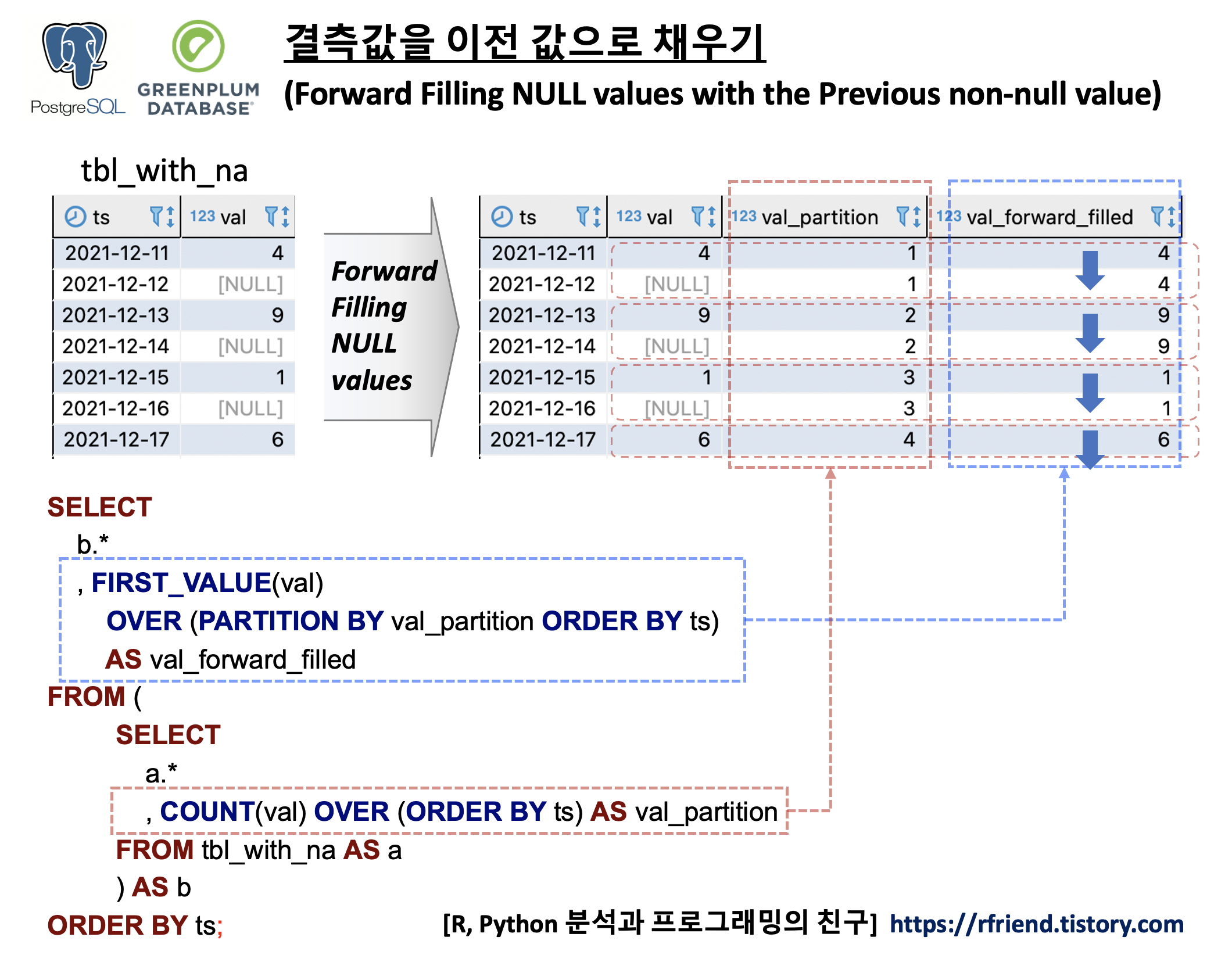
(1) 결측값을 이전 값으로 채우기
(Forward filling NULL values with the previous non-null value)
(2) 여러개 칼럼의 결측값을 이전 값으로 채우기
(Forward filling NULL values in Multiple Columns with the previous non-null value)
(3) 그룹별로 결측값을 이전 값으로 채우기
(Forward filling NULL values by Group with the previous non-null value)
(4) 결측값을 이후 값으로 채우기
(Backward filling NULL values with the next non-null value)
PostgreSQL, Greenplum, forward filling NULL values with the previous non-null value
결측값을 시계열데이터의 TimeStamp 를 기준으로 정렬한 상태에서 SQL로 결측값을 이전의 실측값으로 채우는 방법의 핵심은 FIRST_VALUE() Window Function 을 사용하는 것입니다. FIRST_VALUE() 의 구문은 아래와 같으며, OVER(PARTITION BY column_name ORDER BY TimeStamp_column_name) 의 기능은 위의 예제에 대한 도식의 빨강, 파랑 박스와 화살표를 참고하시기 바랍니다.
-- PostgreSQL FIRST_VALUE() Window Function syntax
FIRST_VALUE ( expression )
OVER (
[PARTITION BY partition_expression, ... ]
ORDER BY sort_expression [ASC | DESC], ...
)
(1) 결측값을 이전 값으로 채우기
(Forward filling NULL values with the previous non-null value)
먼저, 날짜를 나타내는 'ts' 칼럼과 결측값을 가지는 'val' 칼럼으로 구성된 예제 테이블을 만들어보겠습니다.
-- creating a sample dataset with NULL values
DROP TABLE IF EXISTS tbl_with_na;
CREATE TABLE tbl_with_na (
ts DATE NOT NULL
, val int
);
INSERT INTO tbl_with_na VALUES
('2021-12-11', 4)
, ('2021-12-12',NULL)
, ('2021-12-13', 9)
, ('2021-12-14', NULL)
, ('2021-12-15', 1)
, ('2021-12-16', NULL)
, ('2021-12-17', 6)
;
SELECT * FROM tbl_with_na ORDER BY ts;
--ts |val|
------------+---+
--2021-12-11| 4|
--2021-12-12| |
--2021-12-13| 9|
--2021-12-14| |
--2021-12-15| 1|
--2021-12-16| |
--2021-12-17| 6|
이제 FIRST_VALUE() OVER(), COUNT() OVER() 의 window function 을 사용해서 결측값을 이전 실측값으로 채워보겠습니다.
-----------------------------------------------------
-- (1) Forward Filling NULL values
-----------------------------------------------------
SELECT
b.*
, FIRST_VALUE(val)
OVER (PARTITION BY val_partition ORDER BY ts)
AS val_forward_filled
FROM (
SELECT
a.*
, count(val) OVER (ORDER BY ts) AS val_partition
FROM tbl_with_na AS a
) AS b
ORDER BY ts;
--ts |val|val_partition|val_forward_filled|
------------+---+-------------+------------------+
--2021-12-11| 4| 1| 4|
--2021-12-12| | 1| 4|
--2021-12-13| 9| 2| 9|
--2021-12-14| | 2| 9|
--2021-12-15| 1| 3| 1|
--2021-12-16| | 3| 1|
--2021-12-17| 6| 4| 6|
(2) 여러개 칼럼의 결측값을 이전 값으로 채우기
(Forward filling NULL values in Multiple Columns with the previous non-null value)
먼저, 날짜를 나타내는 칼럼 'ts'와 측정값을 가지는 2개의 칼럼 'val_1', 'val_2'로 구성된 예제 테이블을 만들어 보겠습니다.
-- creating a sample table with NULL values in multiple columns
DROP TABLE IF EXISTS tbl_with_na_mult_cols;
CREATE TABLE tbl_with_na_mult_cols (
ts DATE NOT NULL
, val_1 int
, val_2 int
);
INSERT INTO tbl_with_na_mult_cols VALUES
('2021-12-11', 1, 5)
, ('2021-12-12',NULL, NULL)
, ('2021-12-13', 2, 6)
, ('2021-12-14', NULL, 7)
, ('2021-12-15', 3, NULL)
, ('2021-12-16', NULL, NULL)
, ('2021-12-17', 4, 8)
;
SELECT * FROM tbl_with_na_mult_cols ORDER BY ts;
--ts |val_1|val_2|
------------+-----+-----+
--2021-12-11| 1| 5|
--2021-12-12| | |
--2021-12-13| 2| 6|
--2021-12-14| | 7|
--2021-12-15| 3| |
--2021-12-16| | |
--2021-12-17| 4| 8|
다음으로 결측값을 채우려는 여러개의 각 칼럼마다 FIRST_VALUE() OVER(), COUNT() OVER() 의 window function 을 사용해서 결측값을 이전 값으로 채워보겠습니다.
------------------------------------------------------------------
-- (2) Forward Filling NULL values in Multiple Columns
------------------------------------------------------------------
SELECT
b.ts
, b.val_1
, b.val_1_partition
, FIRST_VALUE(val_1)
OVER (PARTITION BY val_1_partition ORDER BY ts)
AS val_1_fw_filled
, b.val_2
, b.val_2_partition
, FIRST_VALUE(val_2)
OVER (PARTITION BY val_2_partition ORDER BY ts)
AS val_2_fw_filled
FROM (
SELECT
a.*
, count(val_1) OVER (ORDER BY ts) AS val_1_partition
, count(val_2) OVER (ORDER BY ts) AS val_2_partition
FROM tbl_with_na_mult_cols AS a
) AS b
ORDER BY ts;
--ts |val_1|val_1_partition|val_1_fw_filled|val_2|val_2_partition|val_2_fw_filled|
------------+-----+---------------+---------------+-----+---------------+---------------+
--2021-12-11| 1| 1| 1| 5| 1| 5|
--2021-12-12| | 1| 1| | 1| 5|
--2021-12-13| 2| 2| 2| 6| 2| 6|
--2021-12-14| | 2| 2| 7| 3| 7|
--2021-12-15| 3| 3| 3| | 3| 7|
--2021-12-16| | 3| 3| | 3| 7|
--2021-12-17| 4| 4| 4| 8| 4| 8|
(3) 그룹별로 결측값을 이전 값으로 채우기
(Forward filling NULL values by Group with the previous non-null value)
이번에는 2개의 그룹('a', 'b')이 있고, 'val' 칼럼에 결측값이 있는 예제 데이터 테이블을 만들어보겠습니다.
-- creating a sample dataset with groups
DROP TABLE IF EXISTS tbl_with_na_grp;
CREATE TABLE tbl_with_na_grp (
ts DATE NOT NULL
, grp TEXT NOT NULL
, val int
);
INSERT INTO tbl_with_na_grp VALUES
('2021-12-11', 'a',1) -- GROUP 'a'
, ('2021-12-12','a', NULL)
, ('2021-12-13', 'a', 2)
, ('2021-12-14', 'a', NULL)
, ('2021-12-15', 'a', 3)
, ('2021-12-16', 'a', NULL)
, ('2021-12-17', 'a', 4)
, ('2021-12-11', 'b', 11) -- GROUP 'b'
, ('2021-12-12', 'b', NULL)
, ('2021-12-13', 'b', 13)
, ('2021-12-14', 'b', NULL)
, ('2021-12-15', 'b', 15)
, ('2021-12-16', 'b', NULL)
, ('2021-12-17', 'b', 17)
;
SELECT * FROM tbl_with_na_grp ORDER BY grp, ts;
--ts |grp|val|
------------+---+---+
--2021-12-11|a | 1|
--2021-12-12|a | |
--2021-12-13|a | 2|
--2021-12-14|a | |
--2021-12-15|a | 3|
--2021-12-16|a | |
--2021-12-17|a | 4|
--2021-12-11|b | 11|
--2021-12-12|b | |
--2021-12-13|b | 13|
--2021-12-14|b | |
--2021-12-15|b | 15|
--2021-12-16|b | |
--2021-12-17|b | 17|
이제 그룹 별로(OVER (PARTITION BY grp, val_partition ORDER BY ts)) 이전 값으로 채우기(FIRST_VALUE(val))를 해보겠습니다.
----------------------------------------------------------
-- (3) Forward Filling NULL values by Group
----------------------------------------------------------
SELECT
b.*
, FIRST_VALUE(val)
OVER (PARTITION BY grp, val_partition ORDER BY ts)
AS val_filled
FROM (
SELECT
a.*
, count(val)
OVER (PARTITION BY grp ORDER BY ts)
AS val_partition
FROM tbl_with_na_grp AS a
) AS b
ORDER BY grp, ts;
--ts |grp|val|val_partition|val_filled|
------------+---+---+-------------+----------+
--2021-12-11|a | 1| 1| 1|
--2021-12-12|a | | 1| 1|
--2021-12-13|a | 2| 2| 2|
--2021-12-14|a | | 2| 2|
--2021-12-15|a | 3| 3| 3|
--2021-12-16|a | | 3| 3|
--2021-12-17|a | 4| 4| 4|
--2021-12-11|b | 11| 1| 11|
--2021-12-12|b | | 1| 11|
--2021-12-13|b | 13| 2| 13|
--2021-12-14|b | | 2| 13|
--2021-12-15|b | 15| 3| 15|
--2021-12-16|b | | 3| 15|
--2021-12-17|b | 17| 4| 17|
(4) 결측값을 이후 값으로 채우기
(Backward filling NULL values with the next non-null value)
결측값을 이전 값(previous non-null value)이 아니라 이후 값(next non-null value) 으로 채우려면 (1)번의 SQL 코드에서 OVER (ORDER BY ts DESC)) 처럼 내림차순으로 정렬(sorting in DESCENDING order) 해준 후에 FIRST_VALUE() 를 사용하면 됩니다.
-----------------------------------------------------
-- (4) Backward Filling NULL values
-----------------------------------------------------
SELECT
b.*
, FIRST_VALUE(val)
OVER (PARTITION BY grp, val_partition ORDER BY ts DESC)
AS val_filled
FROM (
SELECT
a.*
, count(val)
OVER (PARTITION BY grp ORDER BY ts DESC)
AS val_partition
FROM tbl_with_na_grp AS a
) AS b
ORDER BY grp, ts;
--ts |grp|val|val_partition|val_filled|
------------+---+---+-------------+----------+
--2021-12-11|a | 1| 4| 1|
--2021-12-12|a | | 3| 2|
--2021-12-13|a | 2| 3| 2|
--2021-12-14|a | | 2| 3|
--2021-12-15|a | 3| 2| 3|
--2021-12-16|a | | 1| 4|
--2021-12-17|a | 4| 1| 4|
--2021-12-11|b | 11| 4| 11|
--2021-12-12|b | | 3| 13|
--2021-12-13|b | 13| 3| 13|
--2021-12-14|b | | 2| 15|
--2021-12-15|b | 15| 2| 15|
--2021-12-16|b | | 1| 17|
--2021-12-17|b | 17| 1| 17|
지난번 포스팅에서는 PostgreSQL, Greenplum DB에서 옆으로 넓은 테이블(horizontally wide-format table)을 세로로 긴 테이블(vertically long-format table)로 변환(transpose)하는 2가지 방법을 소개하였습니다. (https://rfriend.tistory.com/713)
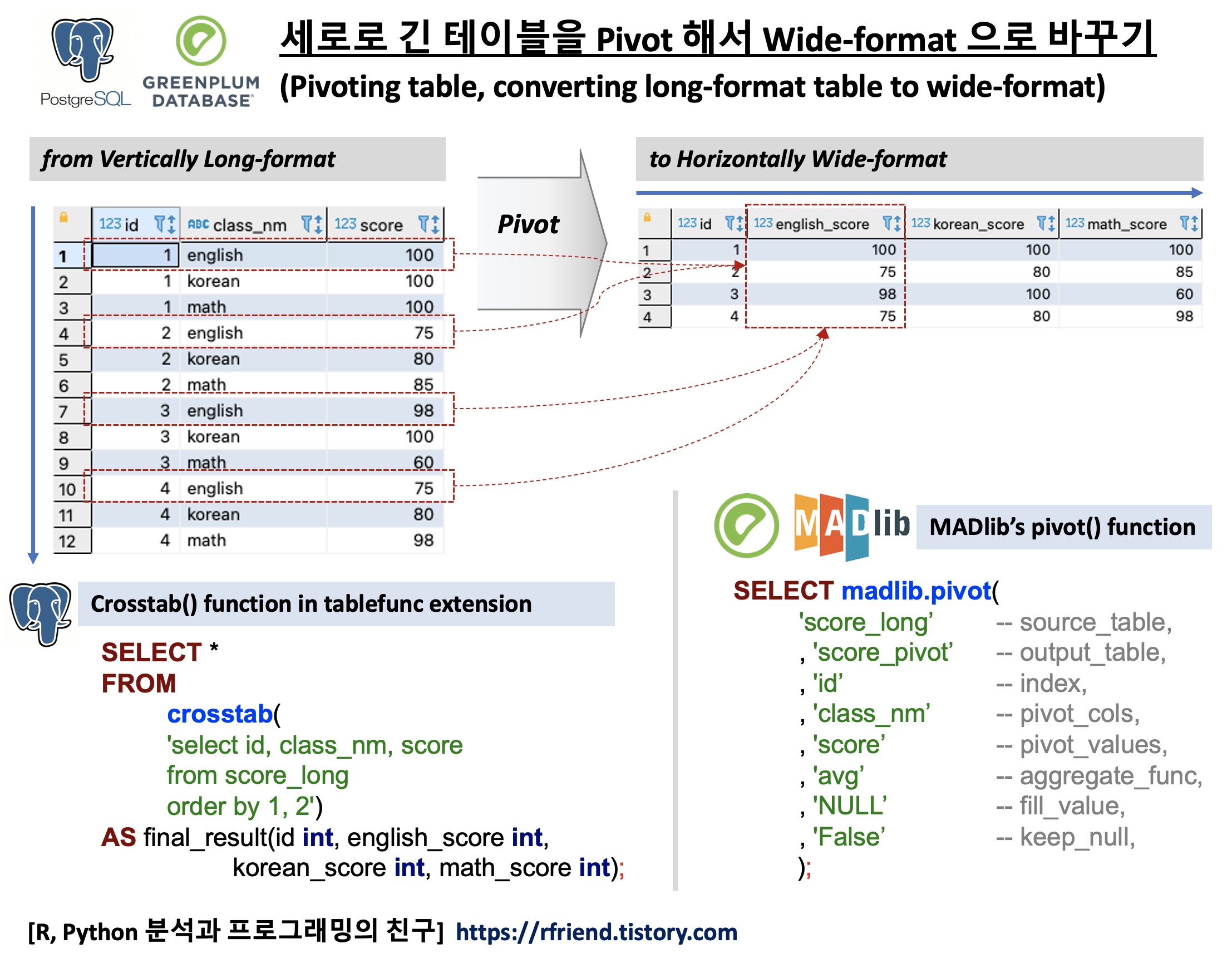
이번 포스팅에서는 반대로, PostgreSQL, Greenplum DB에서 세로로 긴 테이블을 가로로 넓은 테이블로 Pivot 하는 방법(Pivoting table, converting long-format table to wide-format table)을 소개하겠습니다. 보통 탐색적 데이터 분석, 통계 분석, 기계학습 등의 분석을 할 때는 pivot table 한 후의 각 ID별로 여러개의 칼럼이 옆으로 넓게 붙은 형태의 테이블을 사용합니다.
* PostgreSQL과 Greenplum 에서 각각 다른 함수를 사용하는 것에 유의하세요.
(1) PostgreSQL에서 tablefunc extension의 crosstab() 함수를 이용해 테이블 피봇하기
(Pivoting table using crosstab() function in PostgreSQL)
(2) Greenplum 에서 Apache MADlib의 pivot() 함수를 이용해 테이블 피봇하기
(Pivoting table using Apache MADlib's pivot() function in Greenplum)
(3) Manual 하게 Select 후 Join 해서 테이블 피봇하기
(Pivoting table by select and join manually)
PostgreSQL, Greenplum, pivoting table, reshaping from long-format to wide-format
먼저, 예제로 사용할 간단한 예제 테이블을 만들어보겠습니다. 학생 ID별로 과목(class_nm) 별 점수(score) 를 저장해놓은 테이블입니다.
--------------------------------------------------------------------------------
-- Pivoting table using crosstab() function in PostgreSql 9.4+
-- [ref] https://www.postgresql.org/docs/9.4/tablefunc.html
-- [ref] https://learnsql.com/blog/creating-pivot-tables-in-postgresql-using-the-crosstab-function/
--------------------------------------------------------------------------------
DROP TABLE IF EXISTS score_long;
CREATE TABLE score_long (
id int NOT null
, class_nm TEXT
, score int
);
INSERT INTO score_long VALUES
(1,'english' , 100)
, (1,'korean' , 100)
, (1,'math', 100)
, (2,'english', 75)
, (2,'korean', 80)
, (2,'math', 85)
, (3,'english', 98)
, (3,'korean' , 100)
, (3,'math', 60)
, (4,'english', 75)
, (4,'korean', 80)
, (4,'math', 98)
;
SELECT * FROM score_long ORDER BY id, class_nm;
--id|class_nm|score
----+--------+-----+
-- 1|english | 100|
-- 1|korean | 100|
-- 1|math | 100|
-- 2|english | 75|
-- 2|korean | 80|
-- 2|math | 85|
-- 3|english | 98|
-- 3|korean | 100|
-- 3|math | 60|
-- 4|english | 75|
-- 4|korean | 80|
-- 4|math | 98|
(1) PostgreSQL에서 tablefunc extension의 crosstab() 함수를 이용해 테이블 피봇하기
(Pivoting table using crosstab() function in PostgreSQL)
세로로 긴 테이블을 가로로 넓은 테이블로 pivot 할 때 사용되는 crosstab() 함수는 PostgreSQL 버전 8.3 이 배포되었을 때 처음 소개되었던 tablefunc extension 에 포함되었습니다. 따라서 tablefunc extension 을 처음 사용하는 경우라면
CREATE EXTENSION tablefunc; 로 활성화시켜준 후에 crosstab() 함수를 호출해서 사용할 수 있습니다.
crosstab() 함수는 SELECT 문의 FROM 절에 사용이 되므로 처음 사용하는 분이라면 좀 낯설게 여길 수도 있겠습니다. crosstab() 함수에서 SELECT 문은 3개의 칼럼을 반환합니다.
(칼럼 1) 첫번째 칼럼은 각 관측치를 구분하는 ID (identifier) 칼럼입니다. 위의 예에서는 학생들의 ID가 이에 해당합니다.
(칼럼 2) 두번째 칼럼은 pivot table 에서의 범주(categories)에 해당하는 칼럼입니다. pivot을 하게 되면 각 칼럼으로 변환이 됩니다. 위의 예에서는 과목명(class_nm) 칼럼이 이에 해당합니다.
(칼럼 3) 세번째 칼럼은 pivot table 의 각 셀에 할당이 될 값(value)에 해당하는 칼럼입니다. 위의 예에서는 점수(score) 칼럼이 이에 해당합니다.
crosstab() 함수안에 SQL query로 위의 3개 칼럼을 select 한 결과를, AS final_result() 에서 pivot table 에서 재표현할 칼럼 이름과 데이터 유형을 정의해주면 됩니다.
-- (1) Pivoting table using PostgreSQL's crosstab() function
-- Enabling the Crosstab Function
-- : The crosstab() function is part of a PostgreSQL extension called tablefunc.
CREATE EXTENSION tablefunc;
-- Pivoting table
--: The crosstab() function receives an SQL SELECT command as a parameter.
SELECT *
FROM
crosstab(
'select id, class_nm, score
from score_long
order by 1, 2')
AS final_result(id int, english_score int, korean_score int, math_score int);
--id|english_score|korean_score|math_score|
----+-------------+------------+----------+
-- 1| 100| 100| 100|
-- 2| 75| 80| 85|
-- 3| 98| 100| 60|
-- 4| 75| 80| 98|
(2) Greenplum 에서 Apache MADlib의 pivot() 함수를 이용해 테이블 피봇하기
(Pivoting table using Apache MADlib's pivot() function in Greenplum)
Greenplum 에서는 PostgreSQL에서 사용했던 crosstab() 함수를 사용할 수 없습니다 대신 Greenplum 에서는 테이블을 pivot 하려고 할 때 Apache MADlib의 pivot() 함수를 사용합니다. 아래의 madlib.pivot() 함수 안의 구문(syntax)을 참고해서 각 매개변수 항목에 순서대로 입력을 해주면 됩니다.
--------------------------------------------------------------------------------
-- Pivoting table using crosstab() function in Greenplum
-- [ref] https://madlib.apache.org/docs/latest/group__grp__pivot.html
--------------------------------------------------------------------------------
-- Pivoting table using Apache MADlib's pivot() function
DROP TABLE IF EXISTS score_pivot;
SELECT madlib.pivot(
'score_long' -- source_table,
, 'score_pivot' -- output_table,
, 'id' -- index,
, 'class_nm' -- pivot_cols,
, 'score' -- pivot_values,
, 'avg' -- aggregate_func,
, 'NULL' -- fill_value,
, 'False' -- keep_null,
);
SELECT * FROM score_pivot ORDER BY id;
--id|score_avg_class_nm_english|score_avg_class_nm_korean|score_avg_class_nm_math|
--+--------------------------+-------------------------+-----------------------+
-- 1| 100.0000000000000000| 100.0000000000000000| 100.0000000000000000|
-- 2| 75.0000000000000000| 80.0000000000000000| 85.0000000000000000|
-- 3| 98.0000000000000000| 100.0000000000000000| 60.0000000000000000|
-- 4| 75.0000000000000000| 80.0000000000000000| 98.0000000000000000|
칼럼 이름이 자동으로 설정('피봇값_집계함수_카테고리 칼럼이름' 형식)이 되는데요, 만약 칼럼 이름을 사용자의 입맛에 맞게 새로 바꿔주고 싶으면 ALTER TABLE table_name RENAME COLUMN old_column TO new_column; 을 사용해서 바꿔주세요.
-- Renaming the column names
ALTER TABLE score_pivot
RENAME COLUMN score_avg_class_nm_english TO english_score;
ALTER TABLE score_pivot
RENAME COLUMN score_avg_class_nm_korean TO korean_score;
ALTER TABLE score_pivot
RENAME COLUMN score_avg_class_nm_math TO math_score;
SELECT * FROM score_pivot ORDER BY id;
--id|english_score |korean_score |math_score |
----+--------------------+--------------------+--------------------+
-- 1|100.0000000000000000|100.0000000000000000|100.0000000000000000|
-- 2| 75.0000000000000000| 80.0000000000000000| 85.0000000000000000|
-- 3| 98.0000000000000000|100.0000000000000000| 60.0000000000000000|
-- 4| 75.0000000000000000| 80.0000000000000000| 98.0000000000000000|
(3) Manual 하게 Select 후 Join 해서 테이블 피봇하기
(Pivoting table by select and join manually)
물론, 피봇한 후의 테이블에서 칼럼 개수가 몇 개 안된다면 수작업으로 조건절로 SELECT 하여 JOIN 을 해서 새로운 테이블을 만들어 주는 방법도 가능합니다. 다만, pivot table 의 칼럼 개수가 수십, 수백개 된다면 이처럼 수작업으로 일일이 하나씩 SELECT 한 후에 JOIN 을 하는게 매우 번거롭고, 시간이 오래걸리고, 자칫 human error 를 만들 수도 있으니 위의 함수를 사용하는 것이 보다 나아보입니다.
-- (3) Piovting table using join manually
WITH english AS (
SELECT id, score AS english_score
FROM score_long
WHERE class_nm = 'english'
), korean AS (
SELECT id, score AS korean_score
FROM score_long
WHERE class_nm = 'korean'
), math AS (
SELECT id, score AS math_score
FROM score_long
WHERE class_nm = 'math'
)
SELECT * FROM english
LEFT JOIN korean USING(id)
LEFT JOIN math USING(id);
--id|english_score|korean_score|math_score|
----+-------------+------------+----------+
-- 1| 100| 100| 100|
-- 2| 75| 80| 85|
-- 3| 98| 100| 60|
-- 4| 75| 80| 98|
탐색적 데이터분석, 통계나 기계학습 모델링을 할 때의 데이터 형태를 보면 관측치의 식별자 ID(identifier) 별로 하나의 행(row)에 여러개의 특성정보(features)를 여러개의 칼럼(columns)으로 해서 옆으로 넓게 (horizontally wide format) 만든 데이터셋을 사용합니다.
그런데 Database의 Table 은 이와는 다르게, 보통 식별자 ID 별로 칼럼 이름(column name)과 측정값(measured value)을 여러개의 행(rows)으로 해서 세로로 길게 (vertically long format) 만든 테이블로 데이터를 관리합니다. Vertically Long Format 의 테이블이 새로 생성되는 데이터를 추가(insert into)하거나 삭제(delete from) 하기도 쉽고, 그룹별로 연산 (group by operation) 을 하기에도 쉽습니다. 그리고 API 서비스와 DB를 연계할 때도 세로로 긴 형태의 테이블이 사용됩니다.
(통계/기계학습을 하려고 할때는 DB로 부터 Query를 해서 Cross-tab 을 하여 horizontally wide format 의 DataFrame이나 Array 로 바꾸어서 이후 분석을 진행합니다.)
그럼, PostgreSQL, Greenplum DB에서 옆으로 넓은 형태의 테이블을 세로로 긴 형태의 테이블로 변형하는 2가지 방법을 소개하겠습니다. (Transposing columns into rows in PostgreSQL, Greenplum) (Reshaping horizontally wide-format into verticaly long-format table in PostgreSQL, Greenplum)
(1) UNION ALL 함수를 이용하여 여러개의 칼럼을 행으로 변환하기
(2) UNNEST() 함수를 이용하여 여러개의 칼럼을 행으로 변환하기
PostgreSQL, Greenplum, Transposing columns into rows, Reshaping wide to long format table
먼저, 예제로 사용한 간단한 테이블을 생성해 보겠습니다. 학생 ID 별로 국어, 영어, 수학, 과학, 역사, 체육 점수를 옆으로 넓은 형태(horizontally wide-format)로 저장해놓은 테이블입니다.
----------------------------------------------
-- Transposing columns into rows
-- (1) UNION ALL
-- (2) UNNEST()
----------------------------------------------
-- creating a sample table
DROP TABLE IF EXISTS score_wide;
CREATE TABLE score_wide (
id int NOT NULL
, korean_score int
, english_score int
, math_score int
, physics_score int
, history_score int
, athletics_score int
);
INSERT INTO score_wide VALUES
(1, 100, 100, 100, 100, 100, 90)
, (2, 80, 75, 85, 80, 60, 100)
, (3, 100, 98, 60, 55, 95, 85)
, (4, 80, 75, 98, 100, 85, 95);
SELECT * FROM score_wide ORDER BY id;
--id|korean_score|english_score|math_score|physics_score|history_score|athletics_score|
----+------------+-------------+----------+-------------+-------------+---------------+
-- 1| 100| 100| 100| 100| 100| 90|
-- 2| 80| 75| 85| 80| 60| 100|
-- 3| 100| 98| 60| 55| 95| 85|
-- 4| 80| 75| 98| 100| 85| 95|
(1) UNION ALL 함수를 이용하여 여러개의 칼럼을 행으로 변환하기
일반적으로 많이 알려져 있고, 또 실행 성능도 다음에 소개할 UNNEST() 보다 상대적으로 조금 더 좋습니다.
하지만 아래의 예제 코드를 보면 알 수 있는 것처럼, 칼럼의 개수가 여러개일 경우 코드가 길어지고 동일한 코드 항목 항목이 반복되어서 복잡해보이는 단점이 있습니다.
-- (1) using UNION ALL
DROP TABLE IF EXISTS score_long_union;
CREATE TABLE score_long_union AS (
SELECT id, 'korean' AS class_nm, korean_score AS score FROM score_wide
UNION ALL
SELECT id, 'english' AS class_nm, english_score AS score FROM score_wide
UNION ALL
SELECT id, 'math' AS class_nm, math_score AS score FROM score_wide
UNION ALL
SELECT id, 'physics' AS class_nm, physics_score AS score FROM score_wide
UNION ALL
SELECT id, 'history' AS class_nm, history_score AS score FROM score_wide
UNION ALL
SELECT id, 'athletics' AS class_nm, athletics_score AS score FROM score_wide
);
SELECT * FROM score_long_union ORDER BY id, class_nm;
--id|class_nm |score|
----+---------+-----+
-- 1|athletics| 90|
-- 1|english | 100|
-- 1|history | 100|
-- 1|korean | 100|
-- 1|math | 100|
-- 1|physics | 100|
-- 2|athletics| 100|
-- 2|english | 75|
-- 2|history | 60|
-- 2|korean | 80|
-- 2|math | 85|
-- 2|physics | 80|
-- 3|athletics| 85|
-- 3|english | 98|
-- 3|history | 95|
-- 3|korean | 100|
-- 3|math | 60|
-- 3|physics | 55|
-- 4|athletics| 95|
-- 4|english | 75|
-- 4|history | 85|
-- 4|korean | 80|
-- 4|math | 98|
-- 4|physics | 100|
(2) UNNEST() 함수를 이용하여 여러개의 칼럼을 행으로 변환하기
다음으로, UNNEST() 함수를 사용하는 방법은 위의 UNION ALL 대비 코드가 한결 간결해서 가독성이 좋습니다.
반면에, UNNEST() 함수를 사용하면 연산이 된 후의 ARRAY 에 대해서는 INDEX가 지원이 안되다보니 위의 UNION ALL 대비 상대적으로 실행 성능이 떨어지는 단점이 있습니다.(UNION ALL 방법이 UNNEST() 방법보다 약 2배 정도 성능이 빠름.)
이번 포스팅에서는 psql 과 SQL Query 를 이용해서 PostgreSQL, Greenplum DB로부터
(1) 모든 Databases 조회하기 (list all databases in PostgreSQL, Greenplum)
(2) 모든 Schemas 조회하기 (list all schemas in PostgreSQL, Greenplum)
(3) 모든 Tables 조회하기 (list all tables in PostgreSQL, Greenplum)
(4) 모든 Views 조회하기 (list all views in PostgreSQL, Greenplum)
(5) 모든 Columns 조회하기 (list all columns in PostgreSQL, Greenplum)
하는 방법을 소개하겠습니다.
Database의 메타 정보를 가지고 있는 information_schema 나 pg_catalog 테이블을 조회해서 원하는 정보를 얻는 방법인데요, 보통 데이터 전처리와 분석을 시작할 때 종종 사용하는 편이어서 알아두면 편리합니다.
PpostgreSQL list all database, schema, table, view, columns
(1) 모든 Databases 조회하기 (list all databases in PostgreSQL, Greenplum)
----------------------------------------------------------------------
-- List all DBs, Schemas, Tables, Views, Columns
----------------------------------------------------------------------
-- (1) List all Databases
-- (1-1) using psql
$ \l
-- or alternatively
$ \list
-- (1-2) SQL query
SELECT datname
FROM pg_database;
(2) 모든 Schemas 조회하기 (list all schemas in PostgreSQL, Greenplum)
-- (2) List all Schemas
-- (2-1) using psql
$ \dn
-- (2-2) using SQL query
SELECT schema_name
FROM information_schema.schemata;
--schema_name |
--------------------+
--madlib |
--gp_toolkit |
--information_schema
--public |
--pg_catalog |
--pg_bitmapindex |
--pg_aoseg |
--pg_toast |
-- or alternatively
SELECT nspname
FROM pg_catalog.pg_namespace;
(3) 모든 Tables 조회하기 (list all tables in PostgreSQL, Greenplum)
-- (3) Tables
-- (3-1) using psql
-- listing all tables
$ \dt
-- listing tables using pattern matching
$ \dt pubic.ab*
-- (3-2) using SQL query
-- listing all tables
SELECT
table_schema
, table_name
FROM information_schema.tables
WHERE table_schema NOT IN ('pg_catalog', 'information_schema');
-- or alternatively
SELECT
schemaname
, tablename
FROM pg_catalog.pg_tables
WHERE schemaname NOT IN ('pg_catalog', 'information_schema');
-- listing tables using pattern matching
SELECT
schemaname
, tablename
FROM pg_catalog.pg_tables
WHERE schemaname='public'
AND tablename LIKE 'ab%'
;
--schemaname|tablename |
------------+----------------+
--public |abalone_array |
--public |abalone_predict |
--public |abalone_external|
--public |abalone |
--public |abalone_split |
(4) 모든 Views 조회하기 (list all views in PostgreSQL, Greenplum)
-- (4) List all Views
-- (4-1) using psql
-- $ \dv
-- (4-2) using SQL query
SELECT
table_schema
, table_name AS view_name
FROM information_schema.VIEWS
WHERE table_schema NOT IN ('pg_catalog', 'information_schema')
ORDER BY table_schema, table_name;
--table_schema|view_name |
--------------+--------------------------------------+
--public |geography_columns |
--public |geometry_columns |
--public |plcontainer_refresh_config |
--public |plcontainer_show_config |
--public |raster_columns |
--public |raster_overviews |
-- or alternatively
SELECT
schemaname
, viewname
FROM pg_catalog.pg_views
WHERE schemaname NOT IN ('pg_catalog', 'information_schema')
ORDER BY schemaname, viewname;
(5) 모든 Columns 조회하기 (list all columns in PostgreSQL, Greenplum)
-- (5) List all Columns
-- (5-1) using psql
$ \d+ table_name
-- (5-2) using SQL query
SELECT
table_schema
, table_name
, column_name
, data_type
FROM information_schema.columns
WHERE table_schema = 'public'
AND table_name = 'abalone'
ORDER BY ordinal_position
;
--table_schema|table_name|column_name |data_type
--------------+----------+--------------+----------------+
--public |abalone |id |bigint |
--public |abalone |sex |text |
--public |abalone |length |double precision|
--public |abalone |diameter |double precision|
--public |abalone |height |double precision|
--public |abalone |whole_weight |double precision|
--public |abalone |shucked_weight|double precision|
--public |abalone |viscera_weight|double precision|
--public |abalone |shell_weight |double precision|
--public |abalone |rings |integer |
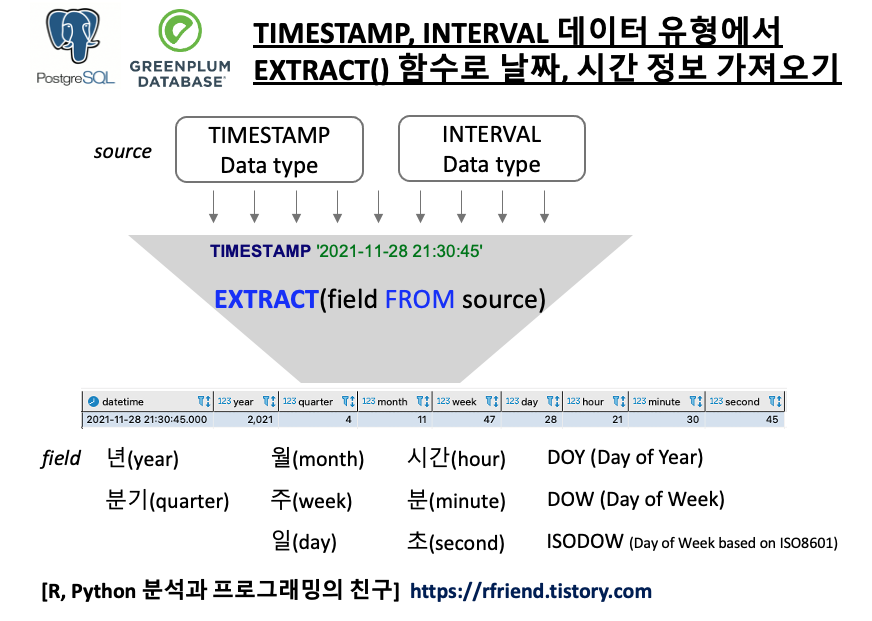
시계열 데이터를 다루다 보면 년, 분기, 월, 일, 시간, 분, 초 등의 날짜와 시간에 관한 정보를 추출해야 할 일이 있습니다.
이번 포스팅에서는 Greenplum, PostgreSQL 에서 EXTRACT() 함수로 TIMESTAMP, INTERVAL 데이터 유형에서 날짜, 시간 정보를 추출(retrive)하는 방법을 소개하겠습니다.
(1) EXTRACT() 함수로 TIMESTAMP 데이터 유형에서 날짜, 시간 정보 가져오기
(2) EXTRACT() 함수로 INTERVAL 데이터 유형에서 날짜, 시간 정보 가져오기
postgresql, greenplum, extract() function
(1) EXTRACT() 함수로 TIMESTAMP 데이터 유형에서 날짜, 시간 정보 가져오기
먼저 PostgreSQL TIMESTAMP 데이터 유형에서 년(year), 분기(quarter), 월(month), 주(week), 일(day), 시간(hour), 분(minute), 초(second), 밀리초(millisecond), 마이크로초(microsecond) 정보를 EXTRACT(field from source) 함수를 사용해서 가져와보겠습니다.
------------------------------------------------------
-- PostgreSQL EXTRACT function
-- retriveing a field such as a year, month, and day from a date/time value
-- Syntax: EXTRACT(field FROM source)
-- The field argument specifies which field to extract from the date/time value
-- The source is a value of type 'TIMESTAP' or 'INTERVAL'
-- The 'EXTRACT()' function returns a double precision value.
-- ref: https://www.postgresqltutorial.com/postgresql-extract/
------------------------------------------------------
SELECT
datum AS datetime
, EXTRACT(YEAR FROM datum)::int AS year
, EXTRACT(QUARTER FROM datum)::int AS quarter
, EXTRACT(MONTH FROM datum)::int AS month
, EXTRACT(WEEK FROM datum)::int AS week
, EXTRACT(DAY FROM datum)::Int AS day
, EXTRACT(HOUR FROM datum)::int AS hour
, EXTRACT(MINUTE FROM datum)::Int AS minute
, EXTRACT(SECOND FROM datum)::Int AS second
--, EXTRACT(MILLISECONDS FROM datum)::int AS millisecond -- =45*1000
--, EXTRACT(MICROSECONDS FROM datum)::Int AS microsecond -- = 45*1000000
FROM (
SELECT TIMESTAMP '2021-11-28 21:30:45' AS datum
) ts;
--datetime |year|quarter|month|week|day|hour|minute|second|
-------------------------+----+-------+-----+----+---+----+------+------+
--2021-11-28 21:30:45.000|2021| 4| 11| 47| 28| 21| 30| 45|
PostgreSQL의 TIMESTAMP 데이터 유형에서
- DOY (Day Of Year) : 1년 중 몇 번째 날인지에 대한 값으로, 1일~365일 범위의 값을 가짐.
- DOW (Day Of Week): 1주일 중 몇 번째 날인지에 대한 값으로, 일요일이 '0', 토요일이 '6'의 값을 가짐.
- ISODOW (Day Of Week based on ISO 8601) : ISO 8601 표준을 따라서 1주일 중 몇 번째 날인지에 대한 값으로, 월요일이 '1', 일요일이 '7'의 값을 가짐.
-- extracting the day of year, week from TIMESTAMP type
SELECT
datum AS datetime
-- the DAY OF YEAR that ranges FROM 1 TO 365
, EXTRACT(DOY FROM datum)::int AS doy
-- the DAY OF week Sunday(0) TO Saturday(6)
, EXTRACT(DOW FROM datum)::int AS dow
-- DAY OF Week based ON ISO 8601 Monday(1) to Sunday(7)
, EXTRACT(ISODOW FROM datum)::int AS isodow
FROM (
SELECT TIMESTAMP '2021-11-28 21:30:45' AS datum
) ts;
--datetime |doy|dow|isodow|
-------------------------+---+---+------+
--2021-11-28 21:30:45.000|332| 0| 7|
(2) EXTRACT() 함수로 INTERVAL 데이터 유형에서 날짜, 시간 정보 가져오기
위의 (1)번에서는 TIMESTAMP 데이터 유형에 대해서 날짜, 시간 정보를 가져왔다면, 이번에는 INTERVAL 데이터 유형에 대해서 날짜, 시간 정보를 추출해보겠습니다.
INTERVAL 데이터 유형이 익숙하지 않은 분들을 위해서, 아래에 INTERVAL 데이터 유형을 사용해서 기준일로부터 INTERVAL 기간 만큼을 뺀 날짜/시간을 계산해 보았습니다. ('2021-11-28 21:30:45' 에서 '2년 3개월 5일 2시간 10분 5초' 이전은 날짜/시간은?)
-- The INTERVAL data type allows you to store and manipulate a period of time
-- in years, months, days, hours, minutes, seconds, etc.
-- (Syntax) @ INTERVAL [ fields ] [ (p) ]
SELECT
TIMESTAMP '2021-11-28 21:30:45' AS datetme
, TIMESTAMP '2021-11-28 21:30:45'
- INTERVAL '2 years 3 months 5 days 2 hours 10 minutes 5 seconds'
AS intv_dt;
--datetme |intv_dt |
-------------------------+-----------------------+
--2021-11-28 21:30:45.000|2019-08-23 19:20:40.000|
그럼, INTERVAL 데이터 유형에서 EXTRACT(field FROM source) 함수를 사용해서 년(year), 분기(quarter), 월(month), 일(day), 시간(hour), 분(minute), 초(second) 정보를 가져와 보겠습니다.
단, 위의 (1)번에서 TIMESTAMP 데이터 유형에 대해서는 가능했던 DOW, DOY, ISODOW, ISOYEAR, WEEK 등의 정보에 대해서는 INTERVAL 데이터 유형에 대해서는 EXTRACT() 함수가 지원하지 않습니다.
-- extracting the month, day, hour from an interval.
-- DOW, DOY, ISODOW, ISOYEAR, WEEK are not supported for INTERVAL
SELECT
intv AS INTERVAL
, EXTRACT(YEAR FROM intv)::int AS intv_year
, EXTRACT(QUARTER FROM intv)::int AS intv_quarter
, EXTRACT(MONTH FROM intv)::int AS intv_month
, EXTRACT(DAY FROM intv)::int AS intv_day
, EXTRACT (HOUR FROM intv)::int AS intv_hour
, EXTRACT(MINUTES FROM intv)::int AS intv_min
, extract(SECONDS FROM intv)::int AS intv_sec
FROM (
SELECT INTERVAL '2 years 3 months 5 days 2 hours 10 minutes 5 seconds'
AS intv
) ts;
--interval |intv_year|intv_quarter|intv_month|intv_day|intv_hour|intv_min|intv_sec|
--------------------------------+---------+------------+----------+--------+---------+--------+--------+
--2 years 3 mons 5 days 02:10:05| 2| 2| 3| 5| 2| 10| 5|
지난번 포스팅에서는 PostgreSQL, Greenplum에서 두 개의 SELECT 문 결과에 대한 합집합(UNION, UNION ALL), 교집합(INTERSECT), 차집합(EXCEPT) 에 대해서 알아보았습니다. (참고 ==> https://rfriend.tistory.com/659 )
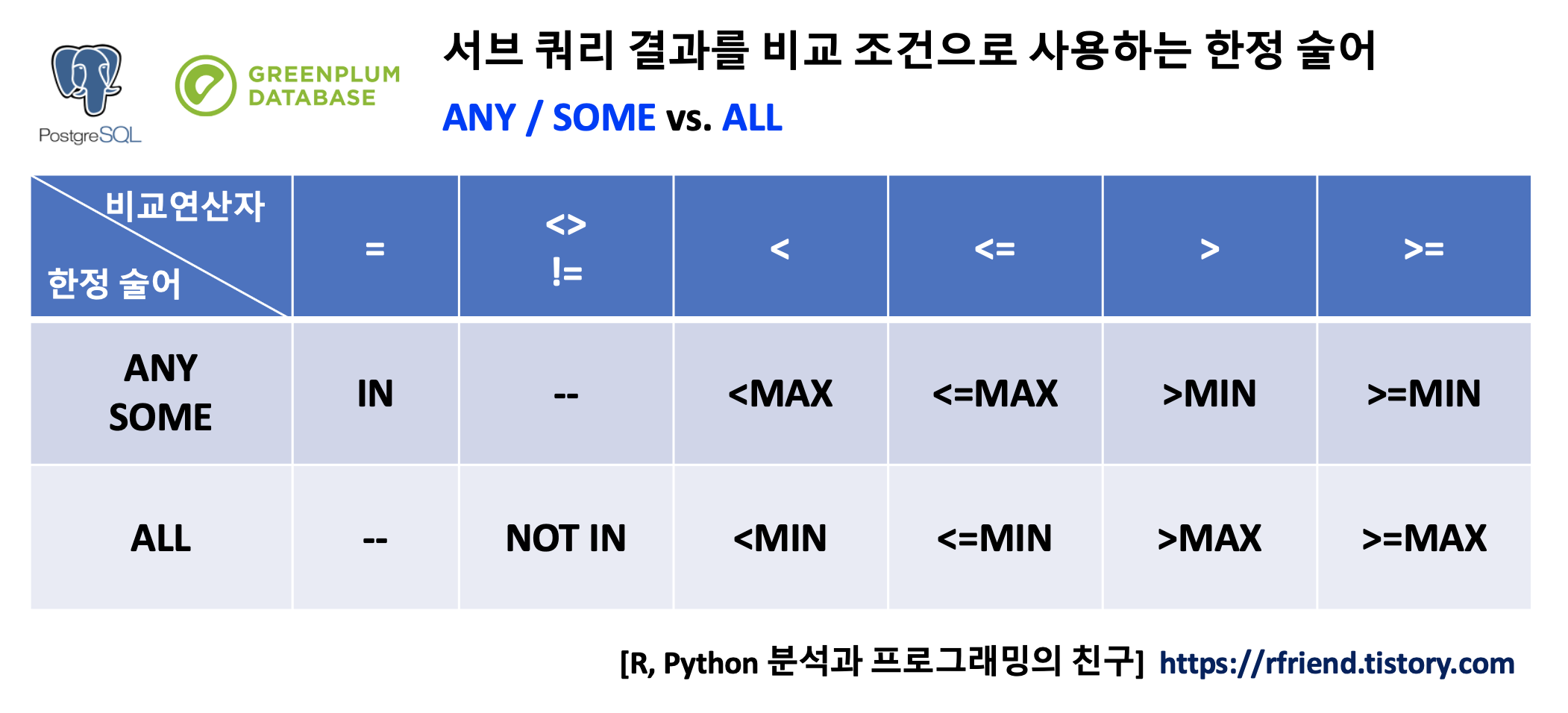
이번 포스팅에서는 Sub-Query의 결과를 WHERE 문에서 비교 조건으로 하여 사용할 수 있는 한정 술어 연산자로서 ANY, SOME, ALL, EXISTS 연산자(operator)에 대해서 알아보겠습니다.
1. ANY, SOME 연산자
2. ALL 연산자
3. EXISTS, NOT EXISTS 연산자
[ Sub-Query 결과를 비교 조건으로 사용하는 한정 술어 ANY/ SOME vs. ALL 비교 ]
PostgreSQL, Greenplum, 한정술어, any, some, all
먼저, 예제로 사용할 간단한 테이블 두 개를 만들어보겠습니다. 'cust_master' 테이블은 id, age, gender 의 세 개 칼럼으로 구성되어 있고, cust_amt 테이블은 id, amt 의 두 개 칼럼으로 구성되어 있으며, 두 테이블은 id 를 공통으로 가지고 있어 서로 연결이 가능합니다. (** 이번 포스팅에서는 JOIN 은 사용하지 않고, 대신 한정 술어를 사용해서 JOIN 결과와 유사한 결과를 얻어보겠습니다.)
-----------------------------------------------------------------------------------
-- 한정술어: ANY/ SOME, ALL, EXISTS, NOT EXISTS operators
-----------------------------------------------------------------------------------
-- creating sample tables
DROP TABLE IF EXISTS cust_master;
CREATE TABLE cust_master (
id int
, age int
, gender text
) DISTRIBUTED RANDOMLY;
INSERT INTO cust_master VALUES
(1, 45, 'M')
, (2, 34, 'F')
, (3, 30, 'F')
, (4, 28, 'M')
, (5, 59, 'M')
;
DROP TABLE IF EXISTS cust_amt;
CREATE TABLE cust_amt (
id int
, amt int
) DISTRIBUTED RANDOMLY;
INSERT INTO cust_amt VALUES
(1, 500)
, (2, 200)
, (3, 750)
, (8, 900)
, (9, 350)
;
(1) ANY, SOME 연산자
ANY 한정술어 연산자는 Sub-Query 의 결과 값들 중에서 어떤 값이라도 =, <>, !=, <, <=, >, >= 등의 비교 연산자의 조건을 만족하면 TRUE 를 반환하며, 그렇지 않은 경우 FALSE 를 반환합니다. SOME 한정 술어 연산자는 ANY 연산자와 동일한 기능을 수행합니다.
Sub-Query 는 반드시 1개의 칼럼만 반환해야 합니다.
아래의 예에서는 cust_amt 테이블에서 amt > 300 인 조건을 만족하는 id 와 동일한('=') id 를 가진 값을 cust_master 테이블에서 SELECT 해본 것입니다. (JOIN 문을 사용해도 됩니다만, ANY 연산자를 사용해서 아래처럼도 가능합니다. PostgreSQL이 내부적으로 query optimization을 해서 JOIN 문을 쓰던 ANY/ SOME 연산자를 쓰던 성능은 비슷합니다.)
WHERE 조건문에 IN 연산자를 사용할 경우에는 ANY/SOME 연산자에서 같이 사용했던 비교 연산자 ('=') 가 없는 차이점이 있습니다.
WHERE 조건절에서 ANY, SOME 연산자에 비교연산자(=, <>, !=, <, <=, >, >=) 가 같이 사용되었을 경우의 의미는 포스팅 초반의 표를 참고하세요.
--------------------------------
-- ANY, SOME operator
--------------------------------
-- ANY operator compares a value to a set of values returned by a subquery.
--The ANY operator must be preceded by one of the following comparison operator =, <=, >, <, > and <>
--The ANY operator returns true if any value of the subquery meets the condition, otherwise, it returns false.
SELECT id
FROM cust_amt
WHERE amt > 300
ORDER BY id;
--id
--1
--3
--8
--9
-- ANY OPERATOR
SELECT *
FROM cust_master
WHERE id = ANY (
SELECT id
FROM cust_amt
WHERE amt > 300
);
--id age gender
--1 45 M
--3 30 F
-- SOME OPERATOR
SELECT *
FROM cust_master
WHERE id = SOME (
SELECT id
FROM cust_amt
WHERE amt > 300
);
-- IN
SELECT *
FROM cust_master
WHERE id IN (
SELECT id
FROM cust_amt
WHERE amt > 300
);
(2) ALL 연산자
ALL 한정술어 연산자는 Sub-Query의 결과의 '모든 값과 비교' 하여 '모든 값이 조건을 만족하면 TRUE, 그렇지 않으면 FALSE'를 반환합니다.
WHERE 조건절에서 ALL 연산자에 비교연산자(=, <>, !=, <, <=, >, >=) 가 같이 사용되었을 경우의 의미는 포스팅 초반의 표를 참고하세요. 가령 아래의 예에서 "WHERE age > ALL (sub-query)" 는 "WHERE age > sub-query의 MAX" 값과 같은 의미입니다. 아래의 예에서는 Sub-Query의 avg_age 가 32, 44 이므로 이중에서 MAX 값인 44보다 age가 큰 값을 cust_master 테이블에서 조회를 하겠군요.
---------------------------
-- the ALL operator
---------------------------
-- the PostgreSQL ALL operator compares a value with a list of values returned by a subquery.
SELECT gender, avg(age) AS avg_age
FROM cust_master
GROUP BY gender;
--gender avg_age
--F 32.0000000000000000
--M 44.0000000000000000
SELECT *
FROM cust_master
WHERE age > ALL (
SELECT avg(age) AS avg_age
FROM cust_master
GROUP BY gender
);
--id age gender
--1 45 M
--5 59 M
(3) EXISTS, NOT EXISTS 연산자
EXISTS 연산자는 Sub-Query의 결과에서 값이 존재하는지를 평가하는 블리언 연산자입니다. 만약 Sub-Query의 결과에 단 1개의 행이라도 값이 존재하다면 EXISTS 연산자의 결과는 TRUE 가 되며, Sub-Query의 결과가 한 개의 행도 존재하지 않는다면 FALSE 가 됩니다.
아래의 예에서는 cust_master 테이블과 cust_amt 의 두 개 테이블을 같이 사용해서, cust_amt 테이블의 amt > 400 인 조건을 만족하고 cust_master 와 cust_amt 테이블에서 id 가 서로 같은 값이 존재(EXISTS) 하는 cust_master 의 모든 칼럼 값을 가져온 것입니다. (JOIN 문을 사용하지 않고도 EXISTS 문을 사용해서 아래처럼 쓸 수도 있답니다. 성능은 비슷.)
NOT EXISTS 연산자는 EXISTS 연산자를 사용했을 때와 정반대의 값을 반환합니다.(TRUE, FALSE 가 서로 정반대임).
---------------------------
-- EXISTS operator
---------------------------
-- The EXISTS operator is a boolean operator that tests for existence of rows in a subquery.
-- If the subquery returns at least one row, the result of EXISTS is TRUE.
-- In case the subquery returns no row, the result is of EXISTS is FALSE.
SELECT *
FROM cust_master AS m
WHERE EXISTS (
SELECT 1
FROM cust_amt AS a
WHERE m.id = a.id
AND a.amt > 400
)
ORDER BY id;
--id age gender
--1 45 M
--3 30 F
----------------------------------
-- NOT EXISTS operator
----------------------------------
-- in case the subquery returns no row, the result is of NOT EXISTS is TRUE
SELECT *
FROM cust_master AS m
WHERE NOT EXISTS (
SELECT 1
FROM cust_amt AS a
WHERE m.id = a.id
AND a.amt > 400
)
ORDER BY id;
--id age gender
--2 34 F
--4 28 M
--5 59 M
지난번 포스팅에서는 여러개 테이블에서 SELECT 문으로 가져온 결과들의 합집합을 구할 때 UNION 은 중복 확인 및 처리를 하고 UNION ALL 은 중복확인 없이 여러 테이블의 모든 값을 합친다는 차이점을 소개하였습니다. (참고 => https://rfriend.tistory.com/658 )
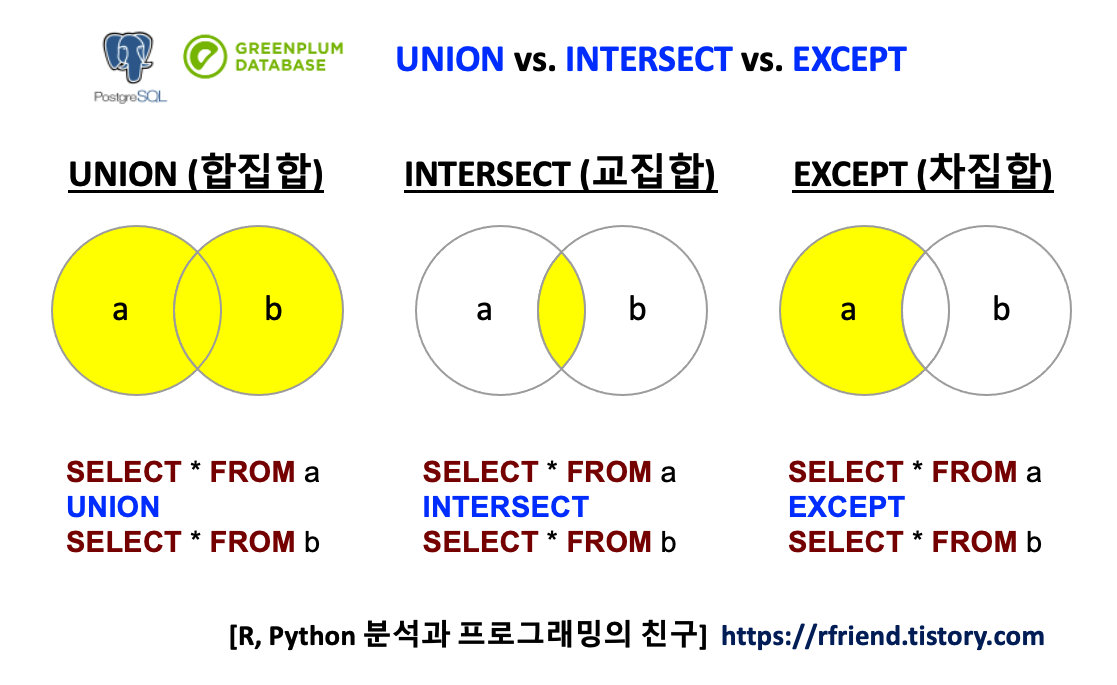
이번 포스팅에서는 PostgreSQL, Greenplum DB에서 SELECT 문의 결과끼리 합치고 빼는 집합 연산자로서
(1) 합집합 UNION
(2) 교집합 INTERSECT
(3) 차집합 EXCEPT
(4) 필요조건: 칼럼의 개수가 같아야 하고, 모든 칼럼의 데이터 유형이 동일해야 함.
에 대해서 알아보겠습니다.
벤다이어 그램으로 PostgreSQL, Greenplum DB에서 SELECT 문 결과에 대한 합집합 UNION, 교집합 INTERSECT, 차집합 EXCEPT 했을 때의 결과를 도식화하면 아래와 같습니다.
예제로 사용할 간단한 테이블 두 개를 만들어보겠습니다. 'x1', 'x2' 의 두 개 칼럼이 있고, 두 개 모두 동일하게 'integer' 데이터 유형이어서 테이블 집합연산자인 합집합, 교집합, 차집합의 예제로 사용할 수 있습니다.
-- creating sample tables
-- Sample Table 1
DROP TABLE IF EXISTS sample_1;
CREATE TABLE sample_1 (x1 int, x2 int)
DISTRIBUTED randomly;
INSERT INTO sample_1 VALUES (1, 11), (2, 12), (3, 13), (4, 14), (5, 15);
SELECT * FROM sample_1 ORDER BY x1;
--x1 x2
--1 11
--2 12
--3 13
--4 14
--5 15
-- Sample Table 2
DROP TABLE IF EXISTS sample_2;
CREATE TABLE sample_2 (x1 int, x2 int)
DISTRIBUTED randomly;
INSERT INTO sample_2 VALUES (4, 14), (5, 15), (6, 16), (7, 17), (8, 18);
SELECT * FROM sample_2 ORDER BY x1;
--x1 x2
--4 14
--5 15
--6 16
--7 17
--8 18
아래의SELECT 문 결과에 대한 UNION, INTERSECT, EXCEPT query 구문은 별도의 추가 설명이 필요 없을 정도로 쉬운 내용이므로 예제 집합연산자의 결과만 제시하는 것으로 설명을 갈음하겠습니다.
(1) 합집합 UNION
-- UNION
SELECT * FROM sample_1
UNION
SELECT * FROM sample_2
ORDER BY x1;
--x1 x2
--1 11
--2 12
--3 13
--4 14
--5 15
--6 16
--7 17
--8 18
(2) 교집합 INTERSECT
-- INTERSECT
SELECT * FROM sample_1
INTERSECT
SELECT * FROM sample_2
ORDER BY x1;
--x1 x2
--4 14
--5 15
(3) 차집합 EXCEPT
두 테이블의 차집합 EXCEPT 는 먼저 SELECT 한 결과에서 나중에 SELECT 한 결과 중 중복되는 부분을 제외한 후의 나머지 결과를 반환합니다.
참고로, Oracle, MySQL DB에서는 SELECT 문 결과에 대한 차집합은 MINUS 함수를 사용해서 구할 수 있습니다.
-- EXCEPT
SELECT * FROM sample_1
EXCEPT
SELECT * FROM sample_2
ORDER BY x1;
--x1 x2
--1 11
--2 12
--3 13
(4) 필요조건: 칼럼의 개수가 같아야 하고, 모든 칼럼의 데이터 유형이 동일해야 함.
UNION, UNION ALL, INTERSECT, EXCEPT 의 집합연산자를 사용하려면 SELECT 문으로 불러온 두 테이블의 결과에서 칼럼의 개수가 서로 같아야 하고 또 모든 칼럼의 데이터 유형(Data Type)이 서로 동일해야만 합니다. 만약 칼럼의 데이터 유형이 서로 다르다면 아래와 같은 에러가 발생합니다. (아래 예에서는 'x2' 칼럼이 하나는 'integer', 또 하나는 'text' 로서 서로 다르기때문에 에러가 발생한 경우임)/
SQL Error [42804]: ERROR: UNION types integer and text cannot be matched
-- The data types of all corresponding columns must be compatible.
-- Sample Table 3
DROP TABLE IF EXISTS sample_3;
CREATE TABLE sample_3 (x1 int, x2 text)
DISTRIBUTED randomly;
INSERT INTO sample_3 VALUES (10, 'a'), (20, 'b'), (30, 'c'), (40, 'd'), (50, 'f');
SELECT * FROM sample_3 ORDER BY x1;
--x1 y
--10 a
--20 b
--30 c
--40 d
--50 f
-- ERROR
SELECT * FROM sample_1
INTERSECT
SELECT * FROM sample_3;
--SQL Error [42804]: ERROR: UNION types integer and text cannot be matched