[R 지리공간 데이터 분석] 벡터 데이터의 속성 정보 가져오기 (subset attributes from vector data)
R 분석과 프로그래밍/R 지리공간데이터 분석 2021. 2. 21. 20:27Tistory 의 코드 블록에 'R' 언어도 사용할 수 있게 해달라고 며칠전에 제안 문의를 드렸었는데요, 드디어 'R' 언어가 추가되었네요. 잘 사용하겠습니다. Tistory, 감사합니다. 꾸벅~!
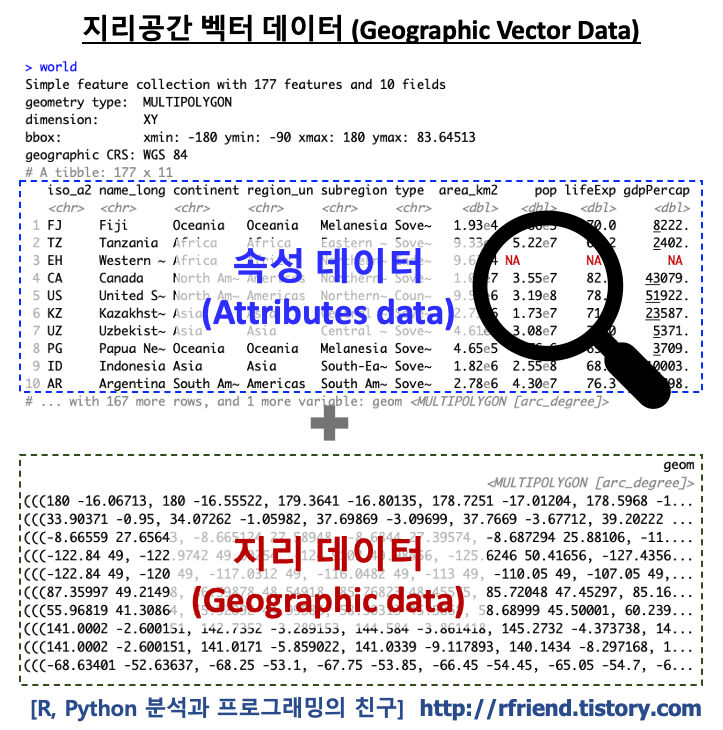
지리공간 벡터 데이터는 (a) 점(point), 선(linestring), 면(polygon) 등의 리스트로 이루어진 지리공간 데이터(geographic data)와, 지리공간 데이터를 제외한 (b) 속성 데이터(attribute data)로 구성이 됩니다. 속성 데이터(attritubes)를 사용해서 각 지리공간 별 특성 (예: 지역 이름, 면적, 인구, 예상수명 등)을 표현하게 됩니다.
이번 포스팅에서는 벡터 데이터에서 속성 정보를 가져오는 여러가지 방법을 소개하겠습니다. 'sf' 객체는 R data.frame 에서 사용하는 클래스를 지원(!!!)하므로 Base R 이나 혹은 dplyr 패키지를 사용하여 데이터 전처리하는 작업에 이미 능숙한 분이라면 이번 포스팅은 특별한 것 없이 매우 쉽게, 복습하는 기분으로 보실 수 있을 거예요.
(1) 'sf' 객체에서 속성 정보만 가져오기: st_drop_geometry()
(2) Base R 구문으로 벡터 데이터 속성 정보의 행과 열 가져오기
(subsetting attributes from geographic vector data using Base R)
(3) dplyr 로 벡터 데이터 속성 정보의 행과 열 가져오기
(subsetting attributes from geographic vector data using dplyr)
(4) 한개 칼럼만 가져온 결과를 벡터로 반환하기 (extracting a single vector)
먼저, 지리공간 데이터 객체를 다루기 위한 sf 패키지와 데이터 전처리에 사용할 dplyr 패키지를 불러오고, 예제로 사용할 세계 나라 데이터 ('world') 를 spData 패키지로 부터 가져오겠습니다.
'world' 벡터 데이터셋은 10개의 속성 데이터 (10 attributes) 와 1개의 지리기하 칼럼 (1 geometry column) 으로 구성이 되어 있으며, 총 177개의 행 (즉, 국가) 에 대한 정보가 들어 있습니다.
## ==============================
## R GeoSpatial data analysis
## - Vector Attribute data operations
## - reference: https://geocompr.robinlovelace.net/attr.html
## ==============================
library(sf)
library(dplyr)
library(spData)
## vector dataset 'world': 10 attritubes and 1 geometry column
str(world)
# tibble [177 x 11] (S3: sf/tbl_df/tbl/data.frame)
# $ iso_a2 : chr [1:177] "FJ" "TZ" "EH" "CA" ...
# $ name_long: chr [1:177] "Fiji" "Tanzania" "Western Sahara" "Canada" ...
# $ continent: chr [1:177] "Oceania" "Africa" "Africa" "North America" ...
# $ region_un: chr [1:177] "Oceania" "Africa" "Africa" "Americas" ...
# $ subregion: chr [1:177] "Melanesia" "Eastern Africa" "Northern Africa" "Northern America" ...
# $ type : chr [1:177] "Sovereign country" "Sovereign country" "Indeterminate" "Sovereign country" ...
# $ area_km2 : num [1:177] 19290 932746 96271 10036043 9510744 ...
# $ pop : num [1:177] 8.86e+05 5.22e+07 NA 3.55e+07 3.19e+08 ...
# $ lifeExp : num [1:177] 70 64.2 NA 82 78.8 ...
# $ gdpPercap: num [1:177] 8222 2402 NA 43079 51922 ...
# $ geom :sfc_MULTIPOLYGON of length 177; first list element: List of 3
# ..$ :List of 1
# .. ..$ : num [1:8, 1:2] 180 180 179 179 179 ...
# ..$ :List of 1
# .. ..$ : num [1:9, 1:2] 178 178 179 179 178 ...
# ..$ :List of 1
# .. ..$ : num [1:5, 1:2] -180 -180 -180 -180 -180 ...
# ..- attr(*, "class")= chr [1:3] "XY" "MULTIPOLYGON" "sfg"
# - attr(*, "sf_column")= chr "geom"
# - attr(*, "agr")= Factor w/ 3 levels "constant","aggregate",..: NA NA NA NA NA NA NA NA NA NA
# ..- attr(*, "names")= chr [1:10] "iso_a2" "name_long" "continent" "region_un" ...
dim(world)
# [1] 177 11
(1) 'sf' 객체에서 속성 정보만 가져오기: st_drop_geometry()
지리공간 'sf' 객체에는 항상 점(points)/선(lines)/면(polygons) 등의 지리기하 데이터를 리스트로 가지고 있는 geometry 칼럼이 항상 따라 다닙니다. 만약 'sf' 객체로 부터 이 geometry 칼럼을 제거하고 나머지 속성 정보만으로 DataFrame 을 만들고 싶다면 sf 패키지의 st_drop_geometry() 메소드를 사용합니다. geometry 칼럼의 경우 지리기하 점/선/면 등의 리스트 정보를 가지고 있기 때문에 메모리 점유가 크기 때문에, 사용할 필요가 없다면 geometry 칼럼은 제거하고 속성 정보만 dataframe 으로 만들어서 분석을 진행하는게 좋겠습니다.
(아래의 (2)번 부터 소개하는 부분 가져오기(subset) 방법을 사용하면 여전히 geometry 칼럼이 그림자차럼 같이 따라와서 여전히 달라붙어 있을 것입니다.)
## Extracting the attribute data of an 'sf' object
world_df <- st_drop_geometry(world)
class(world_df)
# [1] "tbl_df" "tbl" "data.frame"
names(world_df)
# [1] "iso_a2" "name_long" "continent" "region_un" "subregion" "type" "area_km2" "pop"
# [9] "lifeExp" "gdpPercap
(2) Base R 구문으로 벡터 데이터 속성 정보의 행과 열 가져오기
(subsetting attributes from geographic vector data using Base R)
R data.frame 에서 i 행(row)과 j 열(column)을 가져올 때는 df[i, j] , subset(), $ 구문을 사용합니다. 이때 (a) i 행과 j 열에는 정수로 위치(subset rows and columns by position) 을 사용하거나, (b) j 행의 이름 (subset columns by name)을 사용할 수 있으며, (c) 논리 벡터 (logical vector)를 사용해서 i 행의 부분집합(subset rows by a logical vector) 을 가져올 수 있습니다.
여기서 다시 한번 짚고 넘어갈 점은, 특정 행과 열의 부분집합을 가져오면 제일 끝에 geometry 칼럼이 꼭 껌딱지처럼 달라붙어서 같이 따라온다는 점입니다.
(2-a-1) 위치를 지정해서 지리공간 벡터 데이터로 부터 부분 행 가져오기 (subset rows by position)
## -- Vecter arrtibute subsetting
## subsetting columns returns results with geometry column as well.
## -- subset rows by position
world[1:3, ]
# Simple feature collection with 6 features and 10 fields
# geometry type: MULTIPOLYGON
# dimension: XY
# bbox: xmin: -180 ymin: -18.28799 xmax: 180 ymax: 83.23324
# geographic CRS: WGS 84
# # A tibble: 6 x 11
# iso_a2 name_long continent region_un subregion type area_km2 pop lifeExp gdpPercap geom
# <chr> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <MULTIPOLYGON [arc_degree]>
# 1 FJ Fiji Oceania Oceania Melanesia Sover~ 1.93e4 8.86e5 70.0 8222. (((180 -16.06713, 180 -16.555~
# 2 TZ Tanzania Africa Africa Eastern ~ Sover~ 9.33e5 5.22e7 64.2 2402. (((33.90371 -0.95, 34.07262 -~
# 3 EH Western S~ Africa Africa Northern~ Indet~ 9.63e4 NA NA NA (((-8.66559 27.65643, -8.6651~
(2-a-2) 위치를 지정해서 지리공간 벡터 데이터로 부터 부분 열 가져오기 (subset columns by position)
## -- subset columns by position
world[, 1:3]
# Simple feature collection with 177 features and 3 fields
# geometry type: MULTIPOLYGON
# dimension: XY
# bbox: xmin: -180 ymin: -90 xmax: 180 ymax: 83.64513
# geographic CRS: WGS 84
# # A tibble: 177 x 4
# iso_a2 name_long continent geom
# <chr> <chr> <chr> <MULTIPOLYGON [arc_degree]>
# 1 FJ Fiji Oceania (((180 -16.06713, 180 -16.55522, 179.3641 -16.80135, 178.7251 -17.01204, 178.5968~
# 2 TZ Tanzania Africa (((33.90371 -0.95, 34.07262 -1.05982, 37.69869 -3.09699, 37.7669 -3.67712, 39.202~
# 3 EH Western Sahara Africa (((-8.66559 27.65643, -8.665124 27.58948, -8.6844 27.39574, -8.687294 25.88106, -~
# 4 CA Canada North America (((-122.84 49, -122.9742 49.00254, -124.9102 49.98456, -125.6246 50.41656, -127.4~
# 5 US United States North America (((-122.84 49, -120 49, -117.0312 49, -116.0482 49, -113 49, -110.05 49, -107.05 ~
# 6 KZ Kazakhstan Asia (((87.35997 49.21498, 86.59878 48.54918, 85.76823 48.45575, 85.72048 47.45297, 85~
# 7 UZ Uzbekistan Asia (((55.96819 41.30864, 55.92892 44.99586, 58.50313 45.5868, 58.68999 45.50001, 60.~
# 8 PG Papua New Guinea Oceania (((141.0002 -2.600151, 142.7352 -3.289153, 144.584 -3.861418, 145.2732 -4.373738,~
# 9 ID Indonesia Asia (((141.0002 -2.600151, 141.0171 -5.859022, 141.0339 -9.117893, 140.1434 -8.297168~
# 10 AR Argentina South America (((-68.63401 -52.63637, -68.25 -53.1, -67.75 -53.85, -66.45 -54.45, -65.05 -54.7,~
# # ... with 167 more rows
(2-b) 칼럼 이름을 사용해서 지리공간 벡터 데이터로 부터 부분 열 가져오기 (subset columns by name)
## -- subset columns by name
world[, c("name_long", "area_km2")]
# Simple feature collection with 177 features and 2 fields
# geometry type: MULTIPOLYGON
# dimension: XY
# bbox: xmin: -180 ymin: -90 xmax: 180 ymax: 83.64513
# geographic CRS: WGS 84
# # A tibble: 177 x 3
# name_long area_km2 geom
# <chr> <dbl> <MULTIPOLYGON [arc_degree]>
# 1 Fiji 19290. (((180 -16.06713, 180 -16.55522, 179.3641 -16.80135, 178.7251 -17.01204, 178.5968 -1...
# 2 Tanzania 932746. (((33.90371 -0.95, 34.07262 -1.05982, 37.69869 -3.09699, 37.7669 -3.67712, 39.20222 ...
# 3 Western Sahara 96271. (((-8.66559 27.65643, -8.665124 27.58948, -8.6844 27.39574, -8.687294 25.88106, -11....
# 4 Canada 10036043. (((-122.84 49, -122.9742 49.00254, -124.9102 49.98456, -125.6246 50.41656, -127.4356...
# 5 United States 9510744. (((-122.84 49, -120 49, -117.0312 49, -116.0482 49, -113 49, -110.05 49, -107.05 49,...
# 6 Kazakhstan 2729811. (((87.35997 49.21498, 86.59878 48.54918, 85.76823 48.45575, 85.72048 47.45297, 85.16...
# 7 Uzbekistan 461410. (((55.96819 41.30864, 55.92892 44.99586, 58.50313 45.5868, 58.68999 45.50001, 60.239...
# 8 Papua New Guinea 464520. (((141.0002 -2.600151, 142.7352 -3.289153, 144.584 -3.861418, 145.2732 -4.373738, 14...
# 9 Indonesia 1819251. (((141.0002 -2.600151, 141.0171 -5.859022, 141.0339 -9.117893, 140.1434 -8.297168, 1...
# 10 Argentina 2784469. (((-68.63401 -52.63637, -68.25 -53.1, -67.75 -53.85, -66.45 -54.45, -65.05 -54.7, -6...
# # ... with 167 more rows
(2-c) 논리 벡터를 사용해서 지리공간 벡터 데이터로 부터 부분 행 가져오기 (subset rows by a logical vectors)
## -- subset using 'logical vectors'
small_area_bool <- world$area_km2 < 10000
summary(small_area_bool)
# Mode FALSE TRUE
# logical 170 7
small_countries <- world[small_area_bool, ]
nrow(small_countries)
# [1] 7
## or equivalently above
small_countries <- world[world$area_km2 < 10000, ]
## -- using base R subset() function
small_countries <- subset(world, area_km2 < 10000)
(3) dplyr 로 벡터 데이터 속성 정보의 행과 열 가져오기
(subsetting attributes from geographic vector data using dplyr)
R의 dplyr 패키지를 사용해서 지리공간 벡터 데이터의 속성 정보를 처리하면 Base R 대비 코드의 가독성이 좋고, 속도가 빠르다는 장점이 있습니다. dplyr 패키지에서 체인('%>%')으로 파이프 연산자 (pipe operator) 를 사용하면 작업 흐름 (work flow) 를 자연스럽게 따라가면서 코딩을 할 수 있어서 코드의 가독성이 상당히 좋습니다. 그리고 dplyr 은 소스코드가 C++로 되어 있어 속도도 상당히 빠른 편입니다.
dplyr 의 select(), slice(), filter(), pull() 함수를 사용해서 지리공간 벡터 데이터의 속성 정보의 부분 행과 열을 가져와 보겠습니다.
(3-1) dplyr::select(sf, name) 함수를 사용하여 이름으로 특정 열 선택하기 (selects columns by name)
이때, select() 함수는 dplyr 패키지 뿐만 아니라 raster 패키지에도 존재하므로 dplyr::select() 처럼 select() 함수 이름 앞에 패키지 이름을 명시적으로 같이 표기해 줌으로써 불명확성을 없앨 수 있습니다. dplyr::select(data.frame 이름, 칼럼1, 칼럼2, ...) 의 구문으로 원하는 열의 속성 정보만 가져올 수 있습니다. (지리공간 벡터 데이터라고 해서 select() 구문에는 특별한 것이 없으며, subset 결과의 끝에 geometry 칼럼이 달라 붙어서 따라와 있다는 점이 다릅니다.)
## -- using 'dplyr' package
## : select(), slice(), filter(), pull()
## select(): selects columns by name
## : "geom" column remains.
world1 = dplyr::select(world, name_long, area_km2)
names(world1)
# [1] "name_long" "area_km2" "geom"
(3-2) dplyr::select(sf, position) 함수를 사용하여 위치로 특정 열 선택하기 (select columns by position)
## select() columns by position
world1 = dplyr::select(world, 2, 7)
names(world1)
# [1] "name_long" "area_km2" "geom"
(3-3) dplyr::select(sf, name1:name2) 함수를 사용하여 범위 내의 모든 열 선택하기 (a range of columns by ':')
':' 연산자를 사용하여 두개의 위치(position1:position2)나 칼럼 이름(name1:name2)들의 범위 사이에 들어있는 모든 열을 한꺼번에 가져올 수 있습니다. 선택해서 가져오고 싶은 열이 많고 범위로 표현할 수 있을 경우 유용합니다.
## select() also allows subsetting of a range of columns with the help of the : operator
world2 = dplyr::select(world, name_long:area_km2)
names(world2)
# [1] "name_long" "continent" "region_un" "subregion" "type" "area_km2" "geom"
(3-4) dplyr::select(sf, -name) 으로 특정 열을 제거하기 (omit specific columns with the - operator)
## Omit specific columns with the - operator
# all columns except subregion and area_km2 (inclusive)
world3 = dplyr::select(world, -region_un, -subregion, -area_km2, -gdpPercap)
names(world3)
# [1] "iso_a2" "name_long" "continent" "type" "pop" "lifeExp" "geom"
(3-5) dplyr::select(sf, name_new = name_old) 로 선택해서 가져온 열 이름을 바꾸기 (subset & rename columns)
## select() lets you subset and rename columns at the same time
world4 = dplyr::select(world, name_long, population = pop)
names(world4)
# [1] "name_long" "population" "geom"
(3-6) dplyr::select(sf, contains(string)) 로 특정 문자열을 포함한 칼럼을 선택하기
dplyr 의 select() 함수는 contains(), starts_with(), ends_with(), num_range() 와 같은 도우미 함수 (helper functions) 를 사용해서 매우 강력하고 편리하게 특정 칼럼을 선택해서 가져올 수 있습니다.
## select() works with ‘helper functions’ for advanced subsetting operations,
## including contains(), starts_with() and num_range()
## contains(): Contains a literal string
world5 = dplyr::select(world, contains('Ex'))
names(world5)
# [1] "lifeExp" "geom"
(3-7) dplyr::select(sf, starts_with(string)) 로 특정 문자열로 시작하는 칼럼을 선택하기
## starts_with(): Starts with a prefix
world6 = dplyr::select(world, starts_with('life'))
names(world6)
# [1] "lifeExp" "geom"
(3-8) dplyr::select(sf, ends_with(string)) 로 특정 문자열로 끝나는 칼럼을 선택하기
## ends_with(): Ends with a suffix
world7 = dplyr::select(world, ends_with('Exp'))
names(world7)
# [1] "lifeExp" "geom"
(3-9) dplyr::select(df, matches(regular_expression)) 으로 정규 표현식을 만족하는 특정 칼럼을 선택하기
아래 예는 정규 표현식(regular expression) "[p]" 를 matches() 도움미 함수 안에 사용해서, 칼럼 이름에 대/소문자 'p' 문자열이 들어있는 칼럼을 선택해서 가져온 것입니다.
## matches(): Matches a regular expression.
world8 = dplyr::select(world, matches("[p]"))
names(world8)
# [1] "type" "pop" "lifeExp" "gdpPercap" "geom"
(3-10) dplyr::select(df, num_range("x", num1:num2)) 으로 숫자 범위 안의 모든 칼럼 선택하기
만약 칼럼 이름이 "x1", "x2", "x3", "x4", "x5" 처럼 접두사(prefix)가 동일하고 뒤에 순차적인 정수가 붙어있는 형태라면 특정 정수 범위의 칼럼들을 선택해서 가져올 때 num_range() 도우미 함수를 select() 함수 안에 사용할 수 있습니다. "world" sf 객체의 데이터셋은 칼럼 이름이 특정 접두사로 동일하게 시작하지 않으므로, 아래에는 간단한 data.frame 을 만들어서 예를 들어보였습니다.
## -- num_range(): Matches a numerical range like x01, x02, x03.
x1 = c(1:5)
x2 = c(6:10)
x3 = c(11:15)
x4 = c(16:20)
x5 = c(21:25)
df = data.frame(x1, x2, x3, x4, x5)
df
# x1 x2 x3 x4 x5
# 1 1 6 11 16 21
# 2 2 7 12 17 22
# 3 3 8 13 18 23
# 4 4 9 14 19 24
# 5 5 10 15 20 25
## subset using num_range()
df2 = dplyr::select(df, num_range("x", 1:3))
df2
# x1 x2 x3
# 1 1 6 11
# 2 2 7 12
# 3 3 8 13
# 4 4 9 14
# 5 5 10 15
(3-11) dplyr::slice(sf, position1:position2) 으로 특정 행 잘라서 가져오기 (slice rows by position)
## -- slice(): is the row-equivalent of select()
dplyr::slice(world, 3:5)
# Simple feature collection with 3 features and 10 fields
# geometry type: MULTIPOLYGON
# dimension: XY
# bbox: xmin: -171.7911 ymin: 18.91619 xmax: -8.665124 ymax: 83.23324
# geographic CRS: WGS 84
# # A tibble: 3 x 11
# iso_a2 name_long continent region_un subregion type area_km2 pop lifeExp gdpPercap
# <chr> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
# 1 EH Western ~ Africa Africa Northern~ Inde~ 9.63e4 NA NA NA
# 2 CA Canada North Am~ Americas Northern~ Sove~ 1.00e7 3.55e7 82.0 43079.
# 3 US United S~ North Am~ Americas Northern~ Coun~ 9.51e6 3.19e8 78.8 51922.
# # ... with 1 more variable: geom <MULTIPOLYGON [arc_degree]>
(3-12) dplyr::filter(sf, logical_vector) 로 조건을 만족하는 특정 행 걸러내기 (filter rows with conditions)
## -- filter()
# Countries with a population longer than 1 B.
world9 = filter(world, pop > 1000000000)
# world9
# Simple feature collection with 2 features and 10 fields
# geometry type: MULTIPOLYGON
# dimension: XY
# bbox: xmin: 68.17665 ymin: 7.965535 xmax: 135.0263 ymax: 53.4588
# geographic CRS: WGS 84
# # A tibble: 2 x 11
# iso_a2 name_long continent region_un subregion type area_km2 pop lifeExp gdpPercap
# * <chr> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
# 1 IN India Asia Asia Southern~ Sove~ 3142892. 1.29e9 68.0 5385.
# 2 CN China Asia Asia Eastern ~ Coun~ 9409830. 1.36e9 75.9 12759.
# # ... with 1 more variable: geom <MULTIPOLYGON [arc_degree]>
(3-13) dplyr 의 체인('%>%')을 사용한 파이프 연산자로 filter(), select(), slice() 의 작업 흐름 만들기 (workflow by pipe operator)
아래에는 'world' 의 sf 객체 데이터셋으로 부터 먼저 대륙이 아시아인 국가를 걸러내고 (world %>% filter(continent == "Asia"), 이 결과를 받아서 긴 이름과 인구 칼럼을 선택하고 (%>% dplyr::select(name_long, pop)), 이 결과를 받아서 1행에서 3행까지 잘라서 가져오기(%>% slice(1:3)) 를 체인(chain %>%)으로 연결해서 파이프 연산자(pipe operator)로 작업 흐름에 따라 코딩을 한 것입니다.
두번째 코드는 위와 똑같은 결과를 얻기 위해 함수 안의 함수인 중첩 함수 (nested functions) 로 표현해 본 것입니다. 앞서의 dplyr 의 chain(%>%)을 사용한 파이프 연산자(pipe operator)로 쓴 코드에 비해서 중첩 함수로 쓴 코드는 상대적으로 가독성이 떨어집니다.
##-- pipe operator %>%: It enables expressive code: the output of a previous function
## becomes the first argument of the next function, enabling chaining.
world10 = world %>%
filter(continent == "Asia") %>%
dplyr::select(name_long, pop) %>%
slice(1:3)
world10
# Simple feature collection with 3 features and 2 fields
# geometry type: MULTIPOLYGON
# dimension: XY
# bbox: xmin: 46.46645 ymin: -10.35999 xmax: 141.0339 ymax: 55.38525
# geographic CRS: WGS 84
# # A tibble: 3 x 3
# name_long pop geom
# <chr> <dbl> <MULTIPOLYGON [arc_degree]>
# 1 Kazakhstan 17288285 (((87.35997 49.21498, 86.59878 48.54918, 85.76823 48.45575, 85.72048 47.452~
# 2 Uzbekistan 30757700 (((55.96819 41.30864, 55.92892 44.99586, 58.50313 45.5868, 58.68999 45.5000~
# 3 Indonesia 255131116 (((141.0002 -2.600151, 141.0171 -5.859022, 141.0339 -9.117893, 140.1434 -8.~
## -- The alternative to %>% is nested function calls, which is harder to read:
world11 = slice(
dplyr::select(
filter(world, continent == "Asia"),
name_long, pop),
1:3)
(4) dplyr::pull(sf, column_name) 으로 한개 칼럼만 가져온 결과를 벡터로 반환하기 (extracting a single vector)
일반적으로 dplyr 에서 특정 칼럼을 선택(select)해서 가져오면 data.frame 으로 결과를 반환합니다. 만약, 한개의 특정 칼럼만을 벡터(a single vector)로 가져오고 싶다면 명시적으로 pull() 함수를 사용해줘야 합니다. (혹은 df[ , "column_name"] 도 벡터 반환)
## Most dplyr verbs return a data frame.
## To extract a single vector, one has to explicitly use the pull() command
# create throw-away data frame
d = data.frame(pop = 1:10, area = 1:10)
# (a) -- return data frame object when selecting a single column
d[, "pop", drop = FALSE] # equivalent to d["pop"]
select(d, pop)
# pop
# 1 1
# 2 2
# 3 3
# 4 4
# 5 5
# 6 6
# 7 7
# 8 8
# 9 9
# 10 10
# (b) -- return a vector when selecting a single column
d[, "pop"]
pull(d, pop)
# [1] 1 2 3 4 5 6 7 8 9 10
아래의 예는 pull() 함수를 명시적으로 사용해서 인구("pop") 한개 열의 1행~5행의 관측치를 가져와서 벡터(vetor objects)로 반환한 것입니다.
## -- vector objects
world$pop[1:5]
# [1] 885806 52234869 NA 35535348 318622525
pull(world, pop)[1:5]
# [1] 885806 52234869 NA 35535348 318622525
다음번 포스팅에서는 지리기하 벡터 데이터에서 속성 정보에 대해 그룹별로 집계(aggregating geographic vector attributes by group)하는 방법을 소개하겠습니다. (rfriend.tistory.com/624)
[Reference]
* Geo-computation with R - 'Attribute data operations'
: geocompr.robinlovelace.net/attr.html
이번 포스팅이 많은 도움이 되었기를 바랍니다.
행복한 데이터 과학자 되세요! :-)




