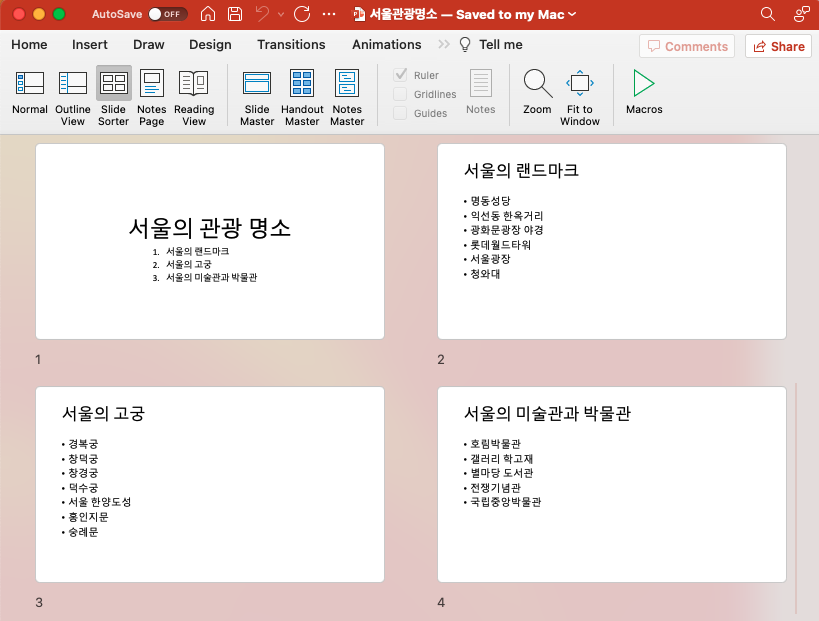
이번 포스팅에서는
(1) pandas.Series.explode() 메소드를 사용해서 Series 안의 리스트를 행으로 변환하기
(2) pandas.Series.explode() 메소드를 사용해서 DataFrame 안의 리스트를 행으로 변환하기
(3) DataFrame의 float 자리수를 지정해주기
방법을 소개하겠습니다.

(1) pandas.Series.explode() 메소드를 사용해서 Series 안의 리스트(list)를 행으로 변환하기
ignore_index=False 가 디폴트 모드이며, 같은 리스트 내 원소들에 대해서는 같은 인덱스 번호가 부여됩니다.
import pandas as pd
# Series.explode(ignore_index=False)
# Transform each element of a list-like to a row.
s = pd.Series([[4, 9, 6, 1, 8], 'love', [], [3, 0, 1]])
## # by default: ignore_index=False
s.explode(ignore_index=False)
# 0 4
# 0 9
# 0 6
# 0 1
# 0 8
# 1 love
# 2 NaN
# 3 3
# 3 0
# 3 1
# dtype: object
ignore_index=True 로 설정을 해주면 0, 1, ..., n-1 의 순서대로 인덱스 번호가 부여됩니다.
## If 'ignore_index=True', the resulting index will be labeled 0, 1, …, n - 1.
s.explode(ignore_index=True)
# 0 4
# 1 9
# 2 6
# 3 1
# 4 8
# 5 love
# 6 NaN
# 7 3
# 8 0
# 9 1
# dtype: object
(2) pandas.Series.explode() 메소드를 사용해서 DataFrame 안의 리스트를 행으로 변환하기
먼저, 리스트를 원소로 가지는 pandas DataFrame을 예시로 만들어보겠습니다. 바로 이어서 리스트를 풀어서 각 행으로 변환할 것이므로 각 열별 리스트 내 원소의 개수가 서로 같아야 합니다.
## DataFrame with lists
df = pd.DataFrame({
'grp': [['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c', 'c']],
'id': [[1, 2, 3, 4, 5, 6, 7, 8, 9]],
'value': [[0.0, 0.421948, 0.9422, 0.582, 0.0, 0.28574, 0.55382, 0.2801, 0.87]]
})
print(df)
# grp \
# [a, a, a, b, b, b, c, c, c]
#
# id \
# [1, 2, 3, 4, 5, 6, 7, 8, 9]
# value
# [0.0, 0.421948, 0.9422, 0.582, 0.0, 0.28574, 0.55382, 0.2801, 0.87]]
위의 (1)번에서 소개했던 pandas.Series.explode() 메소드를 apply() 함수를 사용해서 위에서 만든 DataFrame df 의 모든 열에 적용해줍니다. 옆으로 길게 리스트 형태로 있던 DataFrame 내 원소가 각 행(row)의 개별 원소로 풀어져서 세로로 긴 DataFrame 형태로 변형되었습니다.
## unpacking the lists in DataFrame
df_unpacked = df.apply(pd.Series.explode)
print(df_unpacked)
# grp id value
# 0 a 1 0.0
# 0 a 2 0.421948
# 0 a 3 0.9422
# 0 b 4 0.582
# 0 b 5 0.0
# 0 b 6 0.28574
# 0 c 7 0.55382
# 0 c 8 0.2801
# 0 c 9 0.87
(3) DataFrame의 float 자리수를 지정해주기
세번째 칼럼인 'value'의 float 값들의 자리수가 서로 달라서 보기에 좋지 않습니다. 이럴 경우 astype(float).round(2) 메소드를 사용해서 소수점 2째 자리로 반올일해서 자리수를 일치시켜주면 보기에 깔끔하고 좋습니다.
## Output to two decimal places
df_unpacked['value'] = df_unpacked['value'].astype(float).round(2)
print(df_unpacked)
# grp id value
# 0 a 1 0.00
# 0 a 2 0.42
# 0 a 3 0.94
# 0 b 4 0.58
# 0 b 5 0.00
# 0 b 6 0.29
# 0 c 7 0.55
# 0 c 8 0.28
# 0 c 9 0.87
[ Reference ]
* pandas.Series.explode() 메소드
: https://pandas.pydata.org/docs/reference/api/pandas.Series.explode.html
이번 포스팅이 많은 도움이 되었기를 바랍니다.
행복한 데이터 과학자 되세요! :-)

'Python 분석과 프로그래밍 > Python 데이터 전처리' 카테고리의 다른 글
| [Python] Dictionary를 특정 값, 특정 비율로 분할하기 (0) | 2023.12.08 |
|---|---|
| [Python] 리스트와 사전 자료형을 이용해서 문자열과 숫자 매핑하기 (0) | 2023.07.16 |
| [Python] Pandas 함수 적용: map(), applymap(), apply() (0) | 2023.06.06 |
| [Python] 파워포인트와 PDF 파일에서 텍스트 추출하기 (0) | 2023.03.19 |
| [Python Numpy] 반복자 enumerate() vs. 다차원 반복자np.ndenumerate() (0) | 2023.03.05 |
Rfriend님의
글이 좋았다면 응원을 보내주세요!