[PostgreSQL, Greenplum] 단순이동평균 (Simple Moving Average), 누적이동평균(Cumulative Moving Average)
Greenplum and PostgreSQL Database 2021. 6. 6. 23:24이동평균(Moving Average) 는 시계열 데이터를 분석할 때 이상치(Outlier), 특이값, 잡음(Noise) 의 영향을 줄이거나 제거하는 Smoothing 의 목적이나, 또는 미래 예측에 자주 사용됩니다. 개념이 이해하기 쉽고 직관적이기 때문에 실무에서 많이 사용됩니다. 주식 투자를 하는 분이라면 아마도 이동평균에 대해서 익숙할 것입니다.
이동평균에는 가중치를 어떻게 부여하느냐에 따라서 단순이동평균(Simple Moving Average), 가중이동평균(Weighted Moving Average), 지수이동평균(Exponential Moving Average) 등이 있습니다.
이번 포스팅에서는 PostgreSQL, Greenplum DB에서 Window Function 을 사용하여 가중치를 사용하지 않는 (혹은, 모든 값에 동일한 가중치 1을 부여한다고 볼 수도 있는)
(1) 단순이동평균 계산하기 (Calculating a Simple Moving Average)
(2) 처음 이동평균 날짜 모자라는 부분은 NULL 처리하고 단순이동평균 계산하기
(3) 누적 단순이동평균 계산하기 (Calculating a Cumulative Simple Moving Average)
하는 방법을 소개하겠습니다.

먼저, 세일즈 날짜와 판매금액의 두 개 칼럼으로 구성된, 예제로 사용할 간단한 시계열 데이터(Time Series Data) 테이블을 만들어보겠습니다.
-- creating a sample table
DROP TABLE IF EXISTS sales;
CREATE TABLE sales (
sale_dt date
, sale_amt int
) DISTRIBUTED RANDOMLY;
INSERT INTO sales VALUES
('2021-06-01', 230)
, ('2021-06-02', 235)
, ('2021-06-03', 231)
, ('2021-06-04', 244)
, ('2021-06-05', 202)
, ('2021-06-06', 260)
, ('2021-06-07', 240)
, ('2021-06-08', 235)
, ('2021-06-09', 239)
, ('2021-06-10', 242)
, ('2021-06-11', 244)
, ('2021-06-12', 241)
, ('2021-06-13', 246)
, ('2021-06-14', 247)
, ('2021-06-15', 249)
, ('2021-06-16', 245)
, ('2021-06-17', 242)
, ('2021-06-18', 246)
, ('2021-06-19', 245)
, ('2021-06-20', 190)
, ('2021-06-21', 230)
, ('2021-06-22', 235)
, ('2021-06-23', 231)
, ('2021-06-24', 238)
, ('2021-06-25', 241)
, ('2021-06-26', 245)
, ('2021-06-27', 242)
, ('2021-06-28', 243)
, ('2021-06-29', 240)
, ('2021-06-30', 238);
SELECT * FROM sales ORDER BY sale_dt LIMIT 5;
--sale_dt sale_amt
--2021-06-01 230
--2021-06-02 235
--2021-06-03 231
--2021-06-04 244
--2021-06-05 202
(1) 단순이동평균 계산하기 (Calculating a Simple Moving Average)
현재 날짜를 기준으로 2일전~현재날짜 까지 총 3일 기간 동안의 값을 사용하여 단순 이동평균을 구해보겠습니다.
moving average for last 3 days = (Xt + Xt-1 + Xt-2) / 3
PostgreSQL 의 9.0 이상의 버전에서는 AVG()와 OVER() 의 Window Function을 사용하여 매우 편리하게 단순이동평균 (Simple Moving Average)을 계산할 수 있습니다.
시계열 데이터는 시간의 순서가 중요하므로 OVER(ORDER BY sale_dt) 에서 먼저 날짜를 기준으로 정렬을 해주어야 합니다.
OVER(ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) 로 2일전~현재날짜 까지 총 3일 간의 Window 를 대상으로 평균을 계산하는 것을 지정해줍니다.
가령, 아래의 '2021-06-03' 일의 3일 단순이동평균값은 아래와 같이 '2021-06-01', '2021-06-02', '2021-06-03' 일의 3일치 세일즈 판매금액의 평균이 되겠습니다.
* 3일 단순이동평균('2021-06-03') = (230 + 235 + 231) / 3 = 232.0
ROUND(avg(), 1) 함수를 사용해서 단순이동평균값에 대해 소수점 첫째자리 반올림을 할 수 있습니다. 그리고 필요 시 단순이동평균 계산할 대상을 조회할 때 WHERE 조건절을 추가할 수도 있습니다.
-- Calculating a Moving Average for last 3 days using Window Function
SELECT
sale_dt
, sale_amt
, ROUND(
AVG(sale_amt)
OVER(
ORDER BY sale_dt
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW), 1
) AS avg_sale_amt
FROM sales
ORDER BY sale_dt;
--sale_dt sale_amt avg_sale_amt
--2021-06-01 230 230.0
--2021-06-02 235 232.5
--2021-06-03 231 232.0
--2021-06-04 244 236.7
--2021-06-05 202 225.7
--2021-06-06 260 235.3
--2021-06-07 240 234.0
--2021-06-08 235 245.0
--2021-06-09 239 238.0
--2021-06-10 242 238.7
--2021-06-11 244 241.7
--2021-06-12 241 242.3
--2021-06-13 246 243.7
--2021-06-14 247 244.7
--2021-06-15 249 247.3
--2021-06-16 245 247.0
--2021-06-17 242 245.3
--2021-06-18 246 244.3
--2021-06-19 245 244.3
--2021-06-20 190 227.0
--2021-06-21 230 221.7
--2021-06-22 235 218.3
--2021-06-23 231 232.0
--2021-06-24 238 234.7
--2021-06-25 241 236.7
--2021-06-26 245 241.3
--2021-06-27 242 242.7
--2021-06-28 243 243.3
--2021-06-29 240 241.7
--2021-06-30 238 240.3
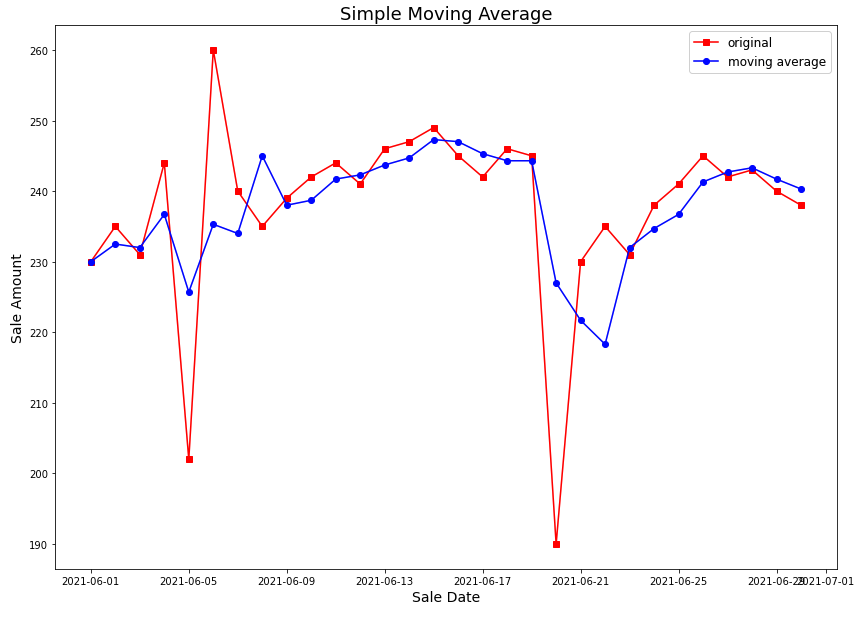
날짜를 X 축으로 놓고, Y 축에는 날짜별 (a) 세일즈 금액, (b) 3일 단순이동평균 세일즈 금액 을 시계열 그래프로 나타내서 비교해보면 아래와 같습니다. 예상했던대로 '3일 단순이동평균' 세일즈 금액이 스파이크(spike) 없이 smoothing 되어있음을 확인할 수 있습니다.
아래 코드는 Jupyter Notebook에서 Python 으로 Greenplum DB에 연결(connect)하여, SQL query 를 해온 결과를 Python pandas의 DataFrame으로 만들어서, matplotlib 으로 시계열 그래프를 그려본 것입니다.
(* 참고: Jupyter Notebook에서 PostgreSQL, Greenplum DB connect 하여 데이터 가져오는 방법은 https://rfriend.tistory.com/577, https://rfriend.tistory.com/579 참조)
## --- Jupyter Notebook ---
import pandas as pd
import matplotlib.pyplot as plt
## loading ipython, sqlalchemy, spycopg2
%load_ext sql
## Greenplum DB connection
%sql postgresql://dsuser:changeme@localhost:5432/demo
#'Connected: dsuser@demo'
## getting data from Greenplum by DB connection from jupyter notebook
%%sql sam << SELECT
sale_dt
, sale_amt
, ROUND(
AVG(sale_amt)
OVER(
ORDER BY sale_dt
ROWS BETWEEN 2 PRECEDING
AND CURRENT ROW)
, 1
) AS avg_sale_amt
FROM sales
ORDER BY sale_dt;
# * postgresql://dsuser:***@localhost:5432/demo
#30 rows affected.
#Returning data to local variable sam
## converting to pandas DataFrame
sam_df = sam.DataFrame()
sam_df.head()
#sale_dt sale_amt avg_sale_amt
#0 2021-06-01 230 230.0
#1 2021-06-02 235 232.5
#2 2021-06-03 231 232.0
#3 2021-06-04 244 236.7
#4 2021-06-05 202 225.7
## plotting time-series plot
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = [14, 10]
plt.plot(sam_df.sale_dt, sam_df.sale_amt, marker='s', color='r', label='original')
plt.plot(sam_df.sale_dt, sam_df.avg_sale_amt, marker='o', color='b', label='moving average')
plt.title('Simple Moving Average', fontsize=18)
plt.xlabel('Sale Date', fontsize=14)
plt.ylabel('Sale Amount', fontsize=14)
plt.legend(fontsize=12, loc='best')
plt.show()
(2) 처음 이동평균 날짜 모자라는 부분은 NULL 처리하고 단순이동평균 계산하기
위의 (1)번에서 '3일 단순이동평균' 값을 계산할 때 시계열 데이터가 시작하는 첫번째와 두번째 날짜에 대해서는 이전 데이터가 존재하지 않기 때문에 '3일치' 데이터가 부족하게 됩니다. (만약 '10일 단순이동평균'을 계산한다고 하면 처음 시작하는 9일치 데이터의 경우 '10일치' 데이터에는 모자라게 되겠지요.)
위의 (1)번에서는 이처럼 '3일치' 데이터가 모자라는 '2021-06-01', '2021-06-02' 일의 경우 '3일치'가 아니라 '1일치', '2일치' 단순이동평균으로 대체 계산해서 값을 채워넣었습니다.
하지만, 필요에 따라서는 '3일치 단순이동평균'이라고 했을 때 이전 데이터가 '3일치'가 안되는 경우에는 단순이동평균을 계산하지 말고 그냥 'NULL' 값으로 처리하고 싶은 경우도 있을 것입니다. 이때 (2-1) CASE WHEH 과 AVG(), OVER() window function을 사용하는 방법, (2-2) LAG(), OVER() window function 을 이용하는 방법의 두 가지를 소개하겠습니다.
(2-1) CASE WHEH 과 AVG(), OVER() window function을 사용하여 단순이동평균 계산하고, 이동평균계산 날짜 모자라면 NULL 처리하는 방법
SELECT
sale_dt
, sale_amt
, CASE WHEN
row_number() OVER(ORDER BY sale_dt) >= 3
THEN
ROUND(
AVG(sale_amt)
OVER(
ORDER BY sale_dt
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW)
, 1)
ELSE NULL END
AS avg_sale_amt
FROM sales
ORDER BY sale_dt;
--sale_dt sale_amt avg_sale_amt
--2021-06-01 230 NULL
--2021-06-02 235 NULL
--2021-06-03 231 232.0
--2021-06-04 244 236.7
--2021-06-05 202 225.7
--2021-06-06 260 235.3
--2021-06-07 240 234.0
--2021-06-08 235 245.0
--2021-06-09 239 238.0
--2021-06-10 242 238.7
--2021-06-11 244 241.7
--2021-06-12 241 242.3
--2021-06-13 246 243.7
--2021-06-14 247 244.7
--2021-06-15 249 247.3
--2021-06-16 245 247.0
--2021-06-17 242 245.3
--2021-06-18 246 244.3
--2021-06-19 245 244.3
--2021-06-20 190 227.0
--2021-06-21 230 221.7
--2021-06-22 235 218.3
--2021-06-23 231 232.0
--2021-06-24 238 234.7
--2021-06-25 241 236.7
--2021-06-26 245 241.3
--2021-06-27 242 242.7
--2021-06-28 243 243.3
--2021-06-29 240 241.7
--2021-06-30 238 240.3
(2-2) LAG(), OVER() window function을 사용하여 단순이동평균 계산하고, 이동평균계산 날짜 모자라면 NULL 처리하는 방법
아래 LAG() 함수를 사용한 방법은 이렇게도 가능하다는 예시를 보여준 것이구요, 위의 (2-1) 과 비교했을 때 'x일 단순이동평균'에서 'x일'이 숫자가 커질 경우 수작업으로 LAG() 함수를 'x일' 날짜만큼 모두 써줘야 하는 수고를 해줘야 하고, 그 와중에 휴먼 에러가 개입될 여지도 있어서 아무래도 위의 (2-1) 방법이 더 나아보입니다.
-- Calculating a Simple Moving Average using LAG() Window Function
SELECT
sale_dt
, sale_amt
, ROUND(
(sale_amt::NUMERIC
+ LAG(sale_amt::NUMERIC, 1) OVER(ORDER BY sale_dt)
+ LAG(sale_amt::NUMERIC, 2) OVER(ORDER BY sale_dt)
)/3
, 1) AS avg_sale_amt
FROM sales
ORDER BY sale_dt;
--sale_dt sale_amt avg_sale_amt
--2021-06-01 230 NULL
--2021-06-02 235 NULL
--2021-06-03 231 232.0
--2021-06-04 244 236.7
--2021-06-05 202 225.7
--2021-06-06 260 235.3
--2021-06-07 240 234.0
--2021-06-08 235 245.0
--2021-06-09 239 238.0
--2021-06-10 242 238.7
--2021-06-11 244 241.7
--2021-06-12 241 242.3
--2021-06-13 246 243.7
--2021-06-14 247 244.7
--2021-06-15 249 247.3
--2021-06-16 245 247.0
--2021-06-17 242 245.3
--2021-06-18 246 244.3
--2021-06-19 245 244.3
--2021-06-20 190 227.0
--2021-06-21 230 221.7
--2021-06-22 235 218.3
--2021-06-23 231 232.0
--2021-06-24 238 234.7
--2021-06-25 241 236.7
--2021-06-26 245 241.3
--2021-06-27 242 242.7
--2021-06-28 243 243.3
--2021-06-29 240 241.7
--2021-06-30 238 240.3
(3) 누적 단순이동평균 계산하기 (Calculating a Cumulative Simpe Moving Average)
처음 시작하는 날짜부터 해서 누적으로 단순이동 평균 (Cumulative Moving Average) 을 계산하고 싶을 때는 아래처럼 AVG(sale_amt) OVER(ORDER BY sale_dt ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) 처럼 window 범위를 처음부터 현재까지로 설정해주면 됩니다.
아래 예에서 '2021-06-05'일까지의 누적 단순이동평균 값은 아래와 같이 계산되었습니다.
Cumulative simple moving average('2021-06-05') = (230 + 235 + 231 + 244 + 202) / 5 = 228.4
-- Calculating a Cumulative Moving Average
SELECT
sale_dt
, sale_amt
, ROUND(
AVG(sale_amt)
OVER(
ORDER BY sale_dt
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
, 1) AS avg_cum_sale_amt
FROM sales
ORDER BY sale_dt;
--sale_dt sale_amt avg_cum_sale_amt
--2021-06-01 230 230.0
--2021-06-02 235 232.5
--2021-06-03 231 232.0
--2021-06-04 244 235.0
--2021-06-05 202 228.4
--2021-06-06 260 233.7
--2021-06-07 240 234.6
--2021-06-08 235 234.6
--2021-06-09 239 235.1
--2021-06-10 242 235.8
--2021-06-11 244 236.5
--2021-06-12 241 236.9
--2021-06-13 246 237.6
--2021-06-14 247 238.3
--2021-06-15 249 239.0
--2021-06-16 245 239.4
--2021-06-17 242 239.5
--2021-06-18 246 239.9
--2021-06-19 245 240.2
--2021-06-20 190 237.7
--2021-06-21 230 237.3
--2021-06-22 235 237.2
--2021-06-23 231 236.9
--2021-06-24 238 237.0
--2021-06-25 241 237.1
--2021-06-26 245 237.4
--2021-06-27 242 237.6
--2021-06-28 243 237.8
--2021-06-29 240 237.9
--2021-06-30 238 237.9
이번 포스팅이 많은 도움이 되었기를 바랍니다.
행복한 데이터 과학자 되세요. :-)




