지난번 포스팅에서는 R data.table에서 (a) 키(Key)와 빠른 이진 탐색 기반의 Subsetting 하는 방법 (rfriend.tistory.com/569), (b) 2차 인덱스 (secondary indices) 를 활용하여 data.table 의 재정렬 없이 빠른 탐색 기반 Subsetting 하는 방법을 소개하였습니다. (rfriend.tistory.com/615)
이번 포스팅에서는 R data.table에서 이진 연산자(binary operators) 인 '=='와 '%in%' 를 수행하는 과정에서 이차 인덱스(secondary indices)가 자동으로 인덱싱(Auto indexing)이 되어 빠르게 subsetting 하는 내용을 소개하겠습니다. (이 글을 쓰는 2021년 2월 현재는 '=='와 '%in%' 연산자만 자동 인덱싱이 지원되며, 향후 더 많은 연산자로 확대 전망)
(1) '==' 이진 연산자로 자동 인덱싱하고 속도 비교하기
(2) '%in%' 이진 연산자로 자동 인덱싱하고 속도 비교하기
(3) 전역으로 자동 인덱싱을 비활성화하기 (disable auto indexing globally)
자동 인덱싱의 속도 개선 효과를 확인해 보기 위해서 천만개의 행을 가진 예제 data.table을 난수를 발생시켜서 생성해 보겠습니다. DT data.table의 크기를 object.size()로 재어보니 114.4 Mb 이네요.
## =========================
## R data.table
## : Auto indexing
## =========================
library(data.table)
## create a data.table big enough
set.seed(1L)
DT = data.table(x = sample(x = 1e5L,
size = 1e7L,
replace = TRUE),
y = runif(100L))
head(DT)
# x y
# 1: 24388 0.4023457
# 2: 59521 0.9142361
# 3: 43307 0.2847435
# 4: 69586 0.3440578
# 5: 11571 0.1822614
# 6: 25173 0.8130521
dim(DT)
# [1] 10000000 2
print(object.size(DT), units = "Mb")
# 114.4 Mb
(1) '==' 이진 연산자로 자동 인덱싱하고 속도 비교하기
이전 포스팅의 이차 인덱스(secondary index)에서는 setindex(DT, column) 으로 이차 인덱스를 명시적으로 설정하거나, 또는 'on' 매개변수로 subsetting을 하면 실행 중에 (on the fly) 기존 이차 인덱스가 있는지 여부를 확인해서, 없으면 바로 이차 인덱스를 설정해주다고 하였습니다.
R data.table에서 '==' 이진 연산자를 사용해서 행의 부분집합을 가져오기(subsetting)을 하면 기존 이차 인덱스가 없을 경우 자동으로 인덱싱을 해줍니다. 그래서 처음에 '=='로 subsetting 할 때는 (a) 인덱스를 생성하고 + (b) 부분집합 행 가져오기 (subsetting)를 수행하느라 시간이 오래 소요되지만, 두번째로 실행할 때는 인덱스가 생성이 되어 있으므로 속도가 무척 빨라지게 됩니다!
아래의 예에서 보면 처음으로 DT[x == 500L] 을 실행했을 때는 0.406초가 소요(elapsed time)되었습니다. names(attributes(DT)) 로 확인해 보면 애초에 없던 index 가 새로 생성되었음을 확인할 수 있고, indices(DT) 로 확인해보면 "x" 칼럼에 대해 이차 인덱스가 생성되었네요.
## -- when we use '==' or '%in%' on a single column for the first time,
## a secondary index is created automatically, and used to perform the subset.
## have a look at all the attribute names (no index here)
names(attributes(DT))
# [1] "names" "row.names" "class" ".internal.selfref"
## run the first time
## system.time = the time to create the index + the time to subset
(t1 <- system.time(ans <- DT[x == 500L]))
# user system elapsed
# 0.392 0.014 0.406
head(ans)
# x y
# 1: 500 0.7845248
# 2: 500 0.9612705
# 3: 500 0.4023457
# 4: 500 0.9139429
# 5: 500 0.8280599
# 6: 500 0.2847435
## secondary index is created
names(attributes(DT))
# [1] "names" "row.names" "class" ".internal.selfref"
# [5] "index"
indices(DT)
# [1] "x"
이제 위에서 수행했던 연산과 동일하게 DT[x == 500L] 을 수행해서 소요 시간(elapsed time)을 측정해보면, 연속해서 두번째 수행했을 때는 0.001 초가 걸렸습니다.
## secondary indices are extremely fast in successive subsets.
## successive subsets
(t2 <- system.time(DT[x == 500L]))
# user system elapsed
# 0.001 0.000 0.001
처음 수행했을 때는 0.406초가 걸렸던 것이, 처음 수행할 때 자동 인덱싱(auto indexing)이 된 후에 연속해서 수행했을 때 0.001초가 걸려서 400배 이상 빨라졌습니다! 와우!!!
barplot(c(0.406, 0.001),
horiz = TRUE,
xlab = "elapsed time",
col = c("red", "blue"),
legend.text = c("first time", "second time(auto indexing)"),
main = "R data.table Auto Indexing")
(2) '%in%' 이진 연산자로 자동 인덱싱하고 속도 비교하기
'==' 연산자와 더불어 포함되어 있는지 여부를 확인해서 블리언을 반환하는 '%in%' 연산자를 활용해서 부분집합 행을 가져올 때도 R data.table은 자동 인덱싱(auto indexing)을 하여 이차 인덱스를 생성하고, 기존에 인덱스가 생성되어 있으면 이차 인덱스를 활용하여 빠르게 탐색하고 subsetting 결과를 반환합니다.
아래 예는 x 에 1989~2912 까지의 정수가 포함되어 있는 행을 부분집합으로 가져오기(DT[ x %in% 1989:2912]) 하는 것으로서, 이때 자동으로 인덱스를 생성(auto indexing)해 줍니다.
## '%in%' operator create auto indexing as well
system.time(DT[x %in% 1989:2912])
# user system elapsed
# 0.010 0.016 0.027
행을 subsetting 할 때 사용하는 조건절이 여러개의 칼럼을 대상으로 하는 경우 '&' 연산자를 사용하여 자동 인덱싱을 할 수 있습니다.
## auto indexing to expressions involving more than one column with '&' operator
(t3 <- system.time(DT[x == 500L & y >= 0.5]))
# user system elapsed
# 0.070 0.025 0.097
(3) 전역으로 자동 인덱싱을 비활성화하기 (disable auto indexing globally)
지난번 포스팅에서 지역적으로 특정 칼럼의 이차 인덱스를 제거할 때 setindex(DT, NULL) 을 사용한다고 소개하였습니다.
(a) '전역적으로 자동 인덱싱을 비활성화' 하려면 options(datatable.auto.index = FALSE) 를 설정해주면 됩니다.
(b) '전역으로 전체 인덱스를 비활성화' 하려면 options(datatable.use.index = FALSE) 를 설정해주면 됩니다.
## Auto indexing can be disabled by setting the global argument
options(datatable.auto.index = FALSE)
## You can disable indices fully by setting global argument
options(datatable.use.index = FALSE)
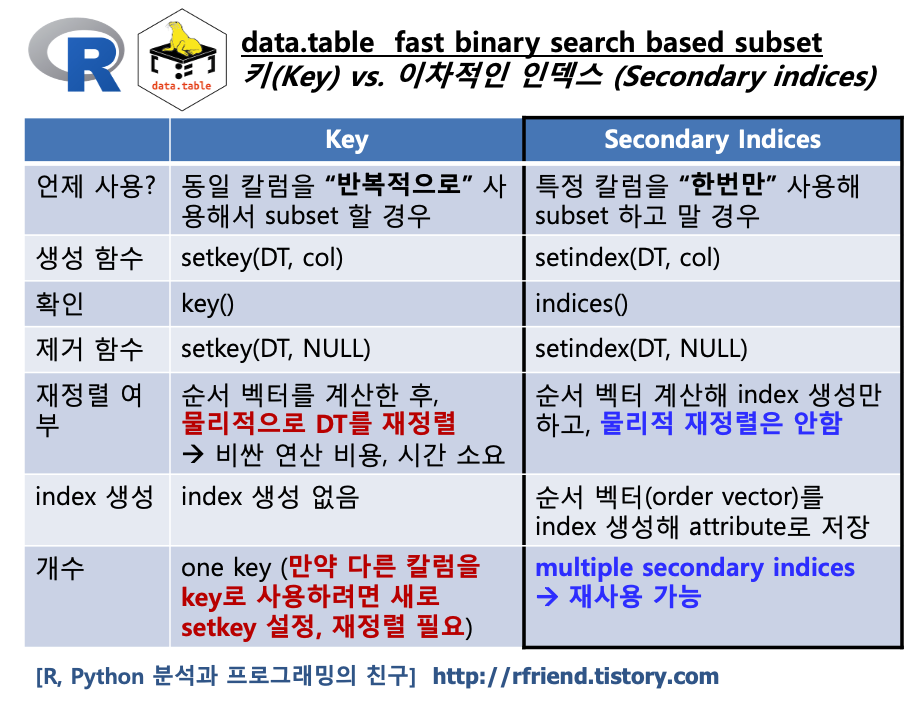
이차 인덱스(Secondary indices) 는 data.table의 키(Key)와 비슷하게 빠른 이진 탐색 기반의 부분집합 가져오기를 할 때 사용합니다.
하지만 키(Key)가 (a) 순서 벡터를 계산한 다음에, (b) 물리적으로 data.table을 재정렬(physically reordering)하는데 비해, 이차 인덱스(secondary indices)는 순서 벡터를 계산해서 index 를 생성해 속성으로 저장만 하고, 물리적 재정렬은 하지 않는 차이점이 있습니다. 만약 data.table의 행과 열이 매우 많은 큰 크기의 데이터셋이라면 물리적으로 재정렬하는데 많은 처리 비용과 시간이 소요될 것입니다.
또 하나 큰 차이점은, 키(Key)는 하나의 칼럼을 키로 설정했을 때 다른 칼럼을 키로 사용하려면 키를 새로운 칼럼으로 재설정하고 data.table을 물리적으로 재정렬을 해야 하는 반면에, 이차 인덱스(secondary indices)는 복수의 이차 인덱스를 설정하고 재사용할 수 있습니다.
이러한 차이점을 고려했을 때, 키(Key)는 동일 칼럼을 "반복적으로" 사용해서 빠르게 부분집합 가져오기(subsetting)를 해야 할 때 유리하며, 이차 인덱스(Secondary indices)는 복수개의 칼럼을 단발성으로 사용하면서 빠르게 부분집합 가져오기를 해야 하는 경우에 유리합니다.
[ R data.table 키(Key) vs. 이차적인 인덱스 (Secondary indices) ]
(2) 이차 인덱스를 설정하고 확인하는 방법
R data.table 패키지를 importing 하고, 예제로 사용할 데이터로는 Lahman 패키지에 들어있는 투수의 투구 통계 데이터인 "Pitching"을 참조하여 Data.Table로 불러오겠습니다.
library(data.table)
## Lahman database on baseball
#install.packages("Lahman")
library(Lahman)
data("Pitching")
## coerce lists and data.frame to data.table by reference
setDT(Pitching)
str(Pitching)
# Classes 'data.table' and 'data.frame': 47628 obs. of 30 variables:
# $ playerID: chr "bechtge01" "brainas01" "fergubo01" "fishech01" ...
# $ yearID : int 1871 1871 1871 1871 1871 1871 1871 1871 1871 1871 ...
# $ stint : int 1 1 1 1 1 1 1 1 1 1 ...
# $ teamID : Factor w/ 149 levels "ALT","ANA","ARI",..: 97 142 90 111 90 136 111 56 97 136 ...
# $ lgID : Factor w/ 7 levels "AA","AL","FL",..: 4 4 4 4 4 4 4 4 4 4 ...
# $ W : int 1 12 0 4 0 0 0 6 18 12 ...
# $ L : int 2 15 0 16 1 0 1 11 5 15 ...
# $ G : int 3 30 1 24 1 1 3 19 25 29 ...
# $ GS : int 3 30 0 24 1 0 1 19 25 29 ...
# $ CG : int 2 30 0 22 1 0 1 19 25 28 ...
# $ SHO : int 0 0 0 1 0 0 0 1 0 0 ...
# $ SV : int 0 0 0 0 0 0 0 0 0 0 ...
# $ IPouts : int 78 792 3 639 27 3 39 507 666 747 ...
# $ H : int 43 361 8 295 20 1 20 261 285 430 ...
# $ ER : int 23 132 3 103 10 0 5 97 113 153 ...
# $ HR : int 0 4 0 3 0 0 0 5 3 4 ...
# $ BB : int 11 37 0 31 3 0 3 21 40 75 ...
# $ SO : int 1 13 0 15 0 0 1 17 15 12 ...
# $ BAOpp : num NA NA NA NA NA NA NA NA NA NA ...
# $ ERA : num 7.96 4.5 27 4.35 10 0 3.46 5.17 4.58 5.53 ...
# $ IBB : int NA NA NA NA NA NA NA NA NA NA ...
# $ WP : int 7 7 2 20 0 0 1 15 3 44 ...
# $ HBP : int NA NA NA NA NA NA NA NA NA NA ...
# $ BK : int 0 0 0 0 0 0 0 2 0 0 ...
# $ BFP : int 146 1291 14 1080 57 3 70 876 1059 1334 ...
# $ GF : int 0 0 0 1 0 1 1 0 0 0 ...
# $ R : int 42 292 9 257 21 0 30 243 223 362 ...
# $ SH : int NA NA NA NA NA NA NA NA NA NA ...
# $ SF : int NA NA NA NA NA NA NA NA NA NA ...
# $ GIDP : int NA NA NA NA NA NA NA NA NA NA ...
# - attr(*, ".internal.selfref")=<externalptr>
이차 인덱스는 setindex(DT, column) 함수의 구문으로 설정할 수 있습니다. 그러면 순서 벡터를 계산해서 내부에 index 라는 속성(attribute)을 생성해서 저장하며, 물리적으로 data.table을 재정렬하는 것은 하지 않습니다(no physical reordering).
names(attributes(DT)) 으로 확인해보면 제일 마지막에 "index"라는 속성이 추가된 것을 알 수 있습니다. indices(DT) 함수를 사용하면 모든 이차 인덱스의 리스트를 얻을 수 있습니다. 이때 만약 아무런 이차 인덱스가 설정되어 있지 않다면 NULL 을 반환합니다.
## (1) Secondary indices
## set the column teamID as a secondary index in teh data.table Pitching
setindex(Pitching, teamID)
head(Pitching)
# playerID yearID stint teamID lgID W L G GS CG SHO SV IPouts H ER HR BB SO BAOpp ERA IBB WP HBP BK BFP GF R SH SF
# 1: bechtge01 1871 1 PH1 NA 1 2 3 3 2 0 0 78 43 23 0 11 1 NA 7.96 NA 7 NA 0 146 0 42 NA NA
# 2: brainas01 1871 1 WS3 NA 12 15 30 30 30 0 0 792 361 132 4 37 13 NA 4.50 NA 7 NA 0 1291 0 292 NA NA
# 3: fergubo01 1871 1 NY2 NA 0 0 1 0 0 0 0 3 8 3 0 0 0 NA 27.00 NA 2 NA 0 14 0 9 NA NA
# 4: fishech01 1871 1 RC1 NA 4 16 24 24 22 1 0 639 295 103 3 31 15 NA 4.35 NA 20 NA 0 1080 1 257 NA NA
# 5: fleetfr01 1871 1 NY2 NA 0 1 1 1 1 0 0 27 20 10 0 3 0 NA 10.00 NA 0 NA 0 57 0 21 NA NA
# 6: flowedi01 1871 1 TRO NA 0 0 1 0 0 0 0 3 1 0 0 0 0 NA 0.00 NA 0 NA 0 3 1 0 NA NA
# GIDP
# 1: NA
# 2: NA
# 3: NA
# 4: NA
# 5: NA
# 6: NA
## alternatively we can provide character vectors to the function 'setindexv()'
# setindexv(Pitching, "teamID") # useful to program with
## 'index' attribute added
names(attributes(Pitching))
# [1] "names" "row.names" "class" ".internal.selfref"
# [5] "index"
## get all the secondary indices set
indices(Pitching)
# [1] "teamID"
(3) 'on' 매개변수와 이차 인덱스를 사용해서 빠르게 부분집합 가져오기
'on' 매개변수를 사용하면 별도로 setindex()로 매번 이차 인덱스를 설정하는 절차 없이, 바로 실행 중에(on the fly) 이차 인덱스를 계산해서 부분집합 가져오기(subsetting)을 할 수 있습니다.
그리고 만약 기존이 이미 이차 인덱스가 설정이 되어 있다면 속성을 확인하여 존재하는 이차 인덱스를 재활용해서 부분집합 가져오기를 빠르게 할 수 있습니다 (on 매개변수는 Key에 대해서도 동일하게 작동합니다).
또 'on' 매개변수는 무슨 칼럼을 기준으로 subsetting 이 실행될지에 대해서 명확하게 코드 구문으로 확인할 수 있게 해주어 코드 가독성을 높여줍니다.
아래 예제는 Pitching data.table에서 이차 인덱스(secondary indices)를 설정한 'teamID' 칼럼의 값이 "NY2" 인 팀을 subsetting 해서 가져온 것입니다. (칼럼 개수가 너무 많아서 1~10번까지 칼럼만 가져왔습니다. [, 1:10])
Pirthcing["NY2", on = "teamID"], Pitching[.("NY2"), on = "teamID"], Pitching[list("NY2"), on = "teamID"] 모두 동일한 결과를 반환합니다.
## subset all rows where the teamID matches "NY2" using 'on'
Pitching["NY2", on = "teamID"][,1:10]
# playerID yearID stint teamID lgID W L G GS CG
# 1: fergubo01 1871 1 NY2 NA 0 0 1 0 0
# 2: fleetfr01 1871 1 NY2 NA 0 1 1 1 1
# 3: woltery01 1871 1 NY2 NA 16 16 32 32 31
# 4: cummica01 1872 1 NY2 NA 33 20 55 55 53
# 5: mcmuljo01 1872 1 NY2 NA 1 0 3 1 1
# 6: martiph01 1873 1 NY2 NA 0 1 6 1 1
# 7: mathebo01 1873 1 NY2 NA 29 23 52 52 47
# 8: hatfijo01 1874 1 NY2 NA 0 1 3 0 0
# 9: mathebo01 1874 1 NY2 NA 42 22 65 65 62
# 10: gedneco01 1875 1 NY2 NA 1 0 2 1 1
# 11: mathebo01 1875 1 NY2 NA 29 38 70 70 69
## or alternatively
# Pitching[.("NY2"), on = "teamID"]
# Pitching[list("NY2"), on = "teamID"]
복수개의 이차 인덱스 (multiple secondary indices)를 setindex(DT, col_1, col_2, ...) 구문 형식으로 설정할 수도 있습니다.
아래 예에서는 Pitching data.table에 "teamID", "yearID"의 2개 칼럼을 이차 인덱스로 설정하고, teamID가 "NY2", yearID가 1873 인 행을 subsetting 해본 것입니다.
## set multiple secondary indices
setindex(Pitching, teamID, yearID)
indices(Pitching)
# [1] "teamID" "teamID__yearID"
## subset based on teamID and yearID columns.
Pitching[.("NY2", 1873), # i
on = c("teamID", "yearID")]
# playerID yearID stint teamID lgID W L G GS CG SHO SV IPouts H ER HR BB SO BAOpp ERA IBB WP HBP BK BFP GF R SH SF
# 1: martiph01 1873 1 NY2 NA 0 1 6 1 1 0 0 102 50 13 0 6 1 NA 3.44 NA 1 NA 0 177 5 37 NA NA
# 2: mathebo01 1873 1 NY2 NA 29 23 52 52 47 2 0 1329 489 127 5 62 79 NA 2.58 NA 23 NA 0 2008 0 348 NA NA
# GIDP
# 1: NA
# 2: NA
이차 인덱스도 DT[i, j, by] 의 구문 형식을 그대로 따르므로 이차 인덱스로 i 에 대해 행을 subsetting 하고, j 에 대해서 특정 칼럼들을 선택해서 가져올 수 있습니다.
아래 예에서는 이차 인덱스인 teamID가 "NY2", yearID가 1873인 행을 subsetting하고, j 부분에 .(teamID, yearID, playerID, W, L) 로 지정해줘서 칼럼은 teamID, yearID, playerID, W, L 만 선별적으로 선택해서 가져온 것입니다.
## -- select in j
## return palyerID, W, L columns as a data.table corresponding to teamID = "NY2" and yearID = 1873
Pitching[.("NY2", 1873), # i
.(teamID, yearID, playerID, W, L), # j
on = c("teamID", "yearID")] # secondary indices
# teamID yearID playerID W L
# 1: NY2 1873 martiph01 0 1
# 2: NY2 1873 mathebo01 29 23
(4) Chaining 해서 정렬하기
이차 인덱스를 사용해서 subsetting 한 후의 결과에 DT[i, j, by][order()] 처럼 chaining을 해서 특정 칼럼을 기준으로 정렬을 할 수 있습니다.
아래 예에서는 이차 인덱스 'teamID' 의 값이 "NY2" 인 행을 subsetting 하고, 칼럼은 .(teamID, yearID, playerID, W, L) 만 선별해서 가져오는데, 이 결과에 chaining을 해서 [order(-W)] 로 W (승리 회수) 를 기준으로 내림차순 정렬 (sorting in descending order) 을 해본 것입니다. order(-W) 에서 마이너스 부호('-')는 내림차순 정렬을 하라는 의미입니다. (order()의 기본설정은 오름차순 정렬임)
## -- Chaining
## use chaining to order the W column in descending order
Pitching[.("NY2"), # i
.(teamID, yearID, playerID, W, L), # j
on = c("teamID")][ # secondary indices
order(-W)] # order by W in decreasing order
# teamID yearID playerID W L
# 1: NY2 1874 mathebo01 42 22
# 2: NY2 1872 cummica01 33 20
# 3: NY2 1873 mathebo01 29 23
# 4: NY2 1875 mathebo01 29 38
# 5: NY2 1871 woltery01 16 16
# 6: NY2 1872 mcmuljo01 1 0
# 7: NY2 1875 gedneco01 1 0
# 8: NY2 1871 fergubo01 0 0
# 9: NY2 1871 fleetfr01 0 1
# 10: NY2 1873 martiph01 0 1
# 11: NY2 1874 hatfijo01 0 1
(5) j 에 대해 계산하기 (compute or do in j)
이차 인덱스로 i 행을 Subsetting 한 다음에 j 열에 대해서 연산을 할 수 있습니다.
아래 예에서는 (a) 이차 인덱스 'teamID' 의 값이 "NY2"인 행을 subsetting 한 후에, 그 결과 안에서 W (승리회수) 의 최대값을 계산, (b) 복수의 이차 인덱스 'teamID', 'yearID'의 값이 각각 "NY2", 1873인 값을 subsetting 해서 W의 값의 최대값을 계산(max(W))한 것입니다.
## -- Compute or do in j
## Find the maximum W corresponding to teamID="NY2"
Pitching[.("NY2"), max(W), on = c("teamID")]
# [1] 42
Pitching[.("NY2", 1873), max(W), on = c("teamID", "yearID")]
# [1] 29
(6) j 에 := 를 사용해서 참조하여 부분할당하기 (sub-assign by reference using := in j)
DT[i, j, by] 에서 j 부분에 := 사용해 'on'으로 이차 인덱스를 참조하여 부분 할당(sub-assign) 하면 매우 빠르게 특정 일부분의 행의 값만을 대체할 수 있습니다.
만약 행의 개수가 매우 많은 데이터셋에서 Key() 를 사용해서 참조하여 부분할당을 하려고 한다면 data.table에 대한 물리적인 재정렬(physical reordering)이 발생하여 연산비용과 시간이 많이 소요될텐데요, 이를 이차 인덱스(secondary indices)를 사용하면 data.table에 대한 재정렬 없이 일부 행의 값을 다른 값으로 대체하는 일을 빠르게 할 수 있는 장점이 있습니다.
아래의 예는 이차 인덱스인 yearID 의 값이 '2019' 인 행의 값을 '2020' 으로 대체하는 부분할당을 해본 것입니다. (2019년을 2020년으로 바꾼 것은 별 의미는 없구요, 그냥 이차 인덱스 참조에 의한 부분할당 기능 예시를 들어본 것입니다.)
만약 'on' 매개변수로 이차 인덱스를 사용해 "그룹별로 집계나 연산"을 하고 싶다면 by를 추가해주면 됩니다.
아래 예에서는 이차 인덱스 'teamID'의 값이 "NY2"인 팀을 subsetting 해서, keyby = yearID를 사용해연도(yearID) 그룹 별로 나누어서 승리회수(W)의 최대값을 계산한 것입니다.
## -- aggregation using by
## get the maximum W for each yearID corresponding to teamID="NY2". order the result by yearID
Pitching[.("NY2"), # i
max(W), # j
keyby = yearID, # order by
on = "teamID"] # secondary indices
# yearID V1
# 1: 1871 16
# 2: 1872 33
# 3: 1873 29
# 4: 1874 42
# 5: 1875 29
(8) mult 매개변수를 사용해 첫번째 행, 마지막행 가져오기
이차 인덱스(secondary indices)로 빠르게 탐색하여 참조해 행을 subsetting을 해 온 다음에, mult = "first" 매개변수를 사용해서 첫번째 행, 또는 mult = "last"로 마지막 행만을 반환할 수 있습니다.
## -- melt argument
## subset only the first matching row where teamID matches "NY2" and "WS3"
Pitching[c("NY2", "WS3"), on = "teamID",
mult = "first"] # subset the first matching row
# playerID yearID stint teamID lgID W L G GS CG SHO SV IPouts H ER HR BB SO BAOpp ERA IBB WP HBP BK BFP GF R SH SF
# 1: fergubo01 1871 1 NY2 NA 0 0 1 0 0 0 0 3 8 3 0 0 0 NA 27.0 NA 2 NA 0 14 0 9 NA NA
# 2: brainas01 1871 1 WS3 NA 12 15 30 30 30 0 0 792 361 132 4 37 13 NA 4.5 NA 7 NA 0 1291 0 292 NA NA
# GIDP
# 1: NA
# 2: NA
이차 인덱스로 참조할 기준이 많아지다 보면 그 조건들에 해당하는 행의 값이 존재하지 않을 때도 있습니다. 아래 예의 경우 이차 인덱스 teamID 가 "WS3" 이고 yearID가 '1873'인 행이 존재하지 않아서 mult = "last"로 마지막 을 반환하라고 했을 때 NA 가 반환되었습니다.(두번째 행)
## subset only the last matching row where teamID matches "NY2", "WS3" and yearID matches 1873
Pitching[.(c("NY2", "WS3"), 1873), on = c("teamID", "yearID"),
mult = "last"] # subset the last matching row
# playerID yearID stint teamID lgID W L G GS CG SHO SV IPouts H ER HR BB SO BAOpp ERA IBB WP HBP BK BFP GF R SH SF
# 1: mathebo01 1873 1 NY2 NA 29 23 52 52 47 2 0 1329 489 127 5 62 79 NA 2.58 NA 23 NA 0 2008 0 348 NA NA
# 2: <NA> 1873 NA WS3 <NA> NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA
# GIDP
# 1: NA
# 2: NA
이처럼 참조할 값이 존재하지 않을 경우 nomatch = NULL 매개변수를 추가해주면 매칭이 되는 행의 값만을 가져올 수 있습니다. (아래 예에서는 teamID "WS3" & yearID 1873 과 매칭되는 행이 존재하지 않으므로 nomatch = NULL 옵션이 추가되니 결과값에서 없어졌습니다.)
## -- the nomatch argument
## From the previous example, setset all rows only if there is a match
Pitching[.(c("NY2", "WS3"), 1873), on = c("teamID", "yearID"),
mult = "last",
nomatch = NULL] # subset only if there's a match
# playerID yearID stint teamID lgID W L G GS CG SHO SV IPouts H ER HR BB SO BAOpp ERA IBB WP HBP BK BFP GF R SH SF
# 1: mathebo01 1873 1 NY2 NA 29 23 52 52 47 2 0 1329 489 127 5 62 79 NA 2.58 NA 23 NA 0 2008 0 348 NA NA
# GIDP
# 1: NA
(9) 이차 인덱스 제거하기 (remove all secondary indices)
이차 인덱스를 제거할 때는 setindex(DT, NULL) 처럼 해주면 기존의 모든 이차 인데스들이 모두 한꺼번에 NULL로 할당되어 제거됩니다.
## remove all secondary indices
setindex(Pitching, NULL)
indices(Pitching)
# NULL
참고로, Key를 설정, 확인, 제거하는 함수는 setkey(DT, col), key(DT), setkey(DT, NULL) 입니다.