[Python] 텍스트 데이터 전처리 및 토큰화 (Tokenization)
Deep Learning (TF, Keras, PyTorch)/Natural Language Processing 2022. 8. 1. 11:40이번 포스팅에서는 Python을 사용해서
(1) 텍스트 데이터 전처리 (text data pre-processing)
(2) 토큰화 (tokenization)
하는 방법을 소개하겠습니다.
(1) 텍스트 데이터 전처리 (text data pre-processing)
텍스트 데이터 전처리를 하는데는 (a) Python의 텍스트 처리 내장 메소드 (Python built-in methods)와 (b) 정규 표현식 매칭 연산(regular expression matching operations)을 제공하는 Python re 패키지를 사용하겠습니다. re 패키지는 Python을 설치할 때 디폴트로 같이 설치가 되므로 별도로 설치할 필요는 없습니다.
예제로 사용할 Input 텍스트는 인터넷쇼핑몰의 고객별 거래내역에 있는 구매 품목 텍스트 데이터이며, Output 은 텍스트 전처리 후의 고객별 구매 품목의 리스트입니다.
예) Input: '**[세일]** 말티즈 강아지사료 습식 소프트 신 3종 15Kg 39,000원!!...외5건'
예) Output: [말티즈, 강아지사료, 습식, 소프트]
[ 텍스트 데이터 전처리 절차 ]
(1-1) [], (), {}, <> 괄호와 괄호 안 문자 제거하기
(1-2) '...외', '...총' 제거하기
(1-3) 특수문자, 숫자 제거
(1-4) 단위 제거: cm, km, etc.
(1-5) 공백 기준으로 분할하기
(1-6) 글자 1개만 있으면 제외하기
(1-7) 텍스트 데이터 전처리 사용자 정의함수(User Defined Function) 정의
(1-8) pandas DataFrame의 텍스트 칼럼에 데이터 전처리 사용자 정의함수 적용
(1-1) [], (), {}, <> 괄호와 괄호 안 문자 제거하기
Python의 정규 표현식(regular expression)을 다루는 re 패키지를 사용해서 다양한 형태의 괄호와 괄호안의 문자를 매칭한 후에 '' 로 대체함으로써 결과적으로 제거하였습니다. re.sub() 는 pattern 과 매치되는 문자열을 repl 의 문자열로 대체를 시켜줍니다.
정규표현식에서 문자 클래스를 만드는 메타 문자인 [ ] 로 만들어지는 정규표현식은 [ ]사이에 들어가는 문자 중 어느 한개라도 매치가 되면 매치를 시켜줍니다. 가령, [abc] 의 경우 'a', 'b', 'c' 중에서 어느 하나의 문자라도 매치가 되면 매치가 되는 것으로 간주합니다.
## Python Regular expression operations
import re
## sample text
s = '**[세일]** 말티즈 강아지사료 습식 소프트 신 3종 15Kg 39,000원!!...외5건'
## (1-1) [], (), {}, <> 괄호와 괄호 안 문자 제거하기
pattern = r'\([^)]*\)' # ()
s = re.sub(pattern=pattern, repl='', string=s)
pattern = r'\[[^)]*\]' # []
s = re.sub(pattern=pattern, repl='', string=s)
pattern = r'\<[^)]*\>' # <>
s = re.sub(pattern=pattern, repl='', string=s)
pattern = r'\{[^)]*\}' # {}
s = re.sub(pattern=pattern, repl='', string=s)
print(s)
[Out]
# **** 말티즈 강아지사료 습식 소프트 신 3종 15Kg 39,000원!!...외5건
(1-2) '...외', '...총' 제거하기
Python의 내장 문자열 메소드인 replace() 를 사용해서 '...외', '...총' 을 ' ' 로 대체함으로써 제거하였습니다.
## (1-2) '...외', '...총' 제거하기
s = s.replace('...외', ' ')
s = s.replace('...총', ' ')
print(s)
[Out]
# **** 말티즈 강아지사료 습식 소프트 신 3종 15Kg 39,000원!! 5건
(1-3) 특수문자, 숫자 제거
정규표현식에서 하이픈(-)은 from ~ to 의 범위를 나타냅니다. [a-zA-Z] 는 소문자와 대문자 영어 모두를 의미하며, [가-힣] 은 한글 전체를 의미합니다.
정규표현식에서 [^] 는 not 의 의미이며, 아래의 [^a-zA-Z가-힣] 은 앞에 '^' 가 붙었으므로 영어와 한글이 아닌(not, ^) 문자, 즉 특수문자와 숫자와 매칭이 됩니다.
## (1-3) 특수문자, 숫자 제거
pattern = r'[^a-zA-Z가-힣]'
s = re.sub(pattern=pattern, repl=' ', string=s)
print(s)
[Out]
# 말티즈 강아지사료 습식 소프트 신 종 Kg 원 건
(1-4) 단위 제거: cm, km, etc.
## (1-4) 단위 제거: cm, km, etc.
units = ['mm', 'cm', 'km', 'ml', 'kg', 'g']
for unit in units:
s = s.lower() # 대문자를 소문자로 변환
s = s.replace(unit, '')
print(s)
[Out]
# 말티즈 강아지사료 습식 소프트 신 종 원 건
(1-5) 공백 기준으로 분할하기
Python 내장형 문자열 메소드인 split() 을 사용해서 공백(space)을 기준으로 문자열을 분할하였습니다.
## (1-5) 공백 기준으로 분할하기
s_split = s.split()
print(s_split)
[Out]
# ['말티즈', '강아지사료', '습식', '소프트', '신', '종', '원', '건']
(1-6) 글자 1개만 있으면 제외하기
글자 길이가 1 보다 큰 (len(word) != 1) 글자만 s_list 의 리스트에 계속 추가(append) 하였습니다.
## (1-6) 글자 1개만 있으면 제외하기
s_list = []
for word in s_split:
if len(word) !=1:
s_list.append(word)
print(s_list)
[Out]
# ['말티즈', '강아지사료', '습식', '소프트']
(1-7) 텍스트 데이터 전처리 사용자 정의함수(User Defined Function) 정의
위의 (1-1) ~ (1-6) 까지의 텍스트 전처리 과정을 아래에 사용자 정의함수로 정의하였습니다. 문자열 s 를 input으로 받아서 텍스트 전처리 후에 s_list 의 단어들을 분할해서 모아놓은 리스트를 반환합니다.
## 텍스트 전처리 사용자 정의함수(UDF of text pre-processing)
def text_preprocessor(s):
import re
## (1) [], (), {}, <> 괄호와 괄호 안 문자 제거하기
pattern = r'\([^)]*\)' # ()
s = re.sub(pattern=pattern, repl='', string=s)
pattern = r'\[[^)]*\]' # []
s = re.sub(pattern=pattern, repl='', string=s)
pattern = r'\<[^)]*\>' # <>
s = re.sub(pattern=pattern, repl='', string=s)
pattern = r'\{[^)]*\}' # {}
s = re.sub(pattern=pattern, repl='', string=s)
## (2) '...외', '...총' 제거하기
s = s.replace('...외', ' ')
s = s.replace('...총', ' ')
## (3) 특수문자 제거
pattern = r'[^a-zA-Z가-힣]'
s = re.sub(pattern=pattern, repl=' ', string=s)
## (4) 단위 제거: cm, km, etc.
units = ['mm', 'cm', 'km', 'ml', 'kg', 'g']
for unit in units:
s = s.lower() # 대문자를 소문자로 변환
s = s.replace(unit, '')
# (5) 공백 기준으로 분할하기
s_split = s.split()
# (6) 글자 1개만 있으면 제외하기
s_list = []
for word in s_split:
if len(word) !=1:
s_list.append(word)
return s_list
## sample text
s = '**[세일]** 말티즈 강아지사료 습식 소프트 신 3종 15Kg 39,000원!!...외5건'
## apply the UDF above
s_list = text_preprocessor(s)
print(s_list)
[Out]
# ['말티즈', '강아지사료', '습식', '소프트']
(1-8) pandas DataFrame의 텍스트 칼럼에 데이터 전처리 사용자정의함수 적용
pandas DataFrame에 위의 (1-7) 텍스트 전처리 사용자 정의함수를 적용하기 위해서는 apply() 와 lambda function 을 사용합니다.
## pandas DataFrame
import pandas as pd
s1 = '**[세일] 몰티즈 강아지사료 습식 소프트 신 3종 15Kg 39,000원!!...외5건'
s2 = '[시크루즈] 50%+추가20%/여름신상 루즈핏 롱원피스/상하세트/점프슈트...외3건'
s3 = '올챌린지 KF94 마스크 100매 국내생산 여름용 황사 화이트...총2건'
s4 = '[최대혜택가] ##하림 용가리치킨 300gX3봉 외 닭가슴살/튀김 골라담기...외12건'
s5 = '[20%+15%] 종아리알 타파! 무로 요가링/마사지릴/압박스타킹/마사지볼...외4종'
df = pd.DataFrame({
'id': [1, 2, 3, 4, 5],
'items': [s1, s2, s3, s4, s5]
})
print(df)
[Out]
# id items
# 0 1 **[세일] 몰티즈 강아지사료 습식 소프트 신 3종 15Kg 39,000원!!...외5건
# 1 2 [시크루즈] 50%+추가20%/여름신상 루즈핏 롱원피스/상하세트/점프슈트...외3건
# 2 3 올챌린지 KF94 마스크 100매 국내생산 여름용 황사 화이트...총2건
# 3 4 [최대혜택가] ##하림 용가리치킨 300gX3봉 외 닭가슴살/튀김 골라담기...외12건
# 4 5 [20%+15%] 종아리알 타파! 무로 요가링/마사지릴/압박스타킹/마사지볼...외4종
## Apply the text preprocessing UDF using apply() and lambda function
df['items_list'] = df['items'].apply(lambda s: text_preprocessor(s))
print(df['items'])
print('-------------'*5)
print(df['items_list'])
[Out]
# 0 **[세일] 몰티즈 강아지사료 습식 소프트 신 3종 15Kg 39,000원!!...외5건
# 1 [시크루즈] 50%+추가20%/여름신상 루즈핏 롱원피스/상하세트/점프슈트...외3건
# 2 올챌린지 KF94 마스크 100매 국내생산 여름용 황사 화이트...총2건
# 3 [최대혜택가] ##하림 용가리치킨 300gX3봉 외 닭가슴살/튀김 골라담기...외12건
# 4 [20%+15%] 종아리알 타파! 무로 요가링/마사지릴/압박스타킹/마사지볼...외4종
# Name: items, dtype: object
# -----------------------------------------------------------------
# 0 [몰티즈, 강아지사료, 습식, 소프트]
# 1 [추가, 여름신상, 루즈핏, 롱원피스, 상하세트, 점프슈트]
# 2 [올챌린지, kf, 마스크, 국내생산, 여름용, 황사, 화이트]
# 3 [하림, 용가리치킨, 닭가슴살, 튀김, 골라담기]
# 4 [종아리알, 타파, 무로, 요가링, 마사지릴, 압박스타킹, 마사지볼]
# Name: items_list, dtype: object
위에 Jupyter Notebook 에서 pandas DataFrame을 출력한 결과가 중앙 정렬로 되어있어서 보기가 불편한데요, 아래처럼 좌측 정렬 (left alignment) 을 해서 보기에 편하도록 해보았습니다.
## align text of pandas DataFrame to left in Jupyter Notebook
dfStyler = df.style.set_properties(**{'text-align': 'left'})
dfStyler.set_table_styles([dict(selector='th', props=[('text-align', 'left')])])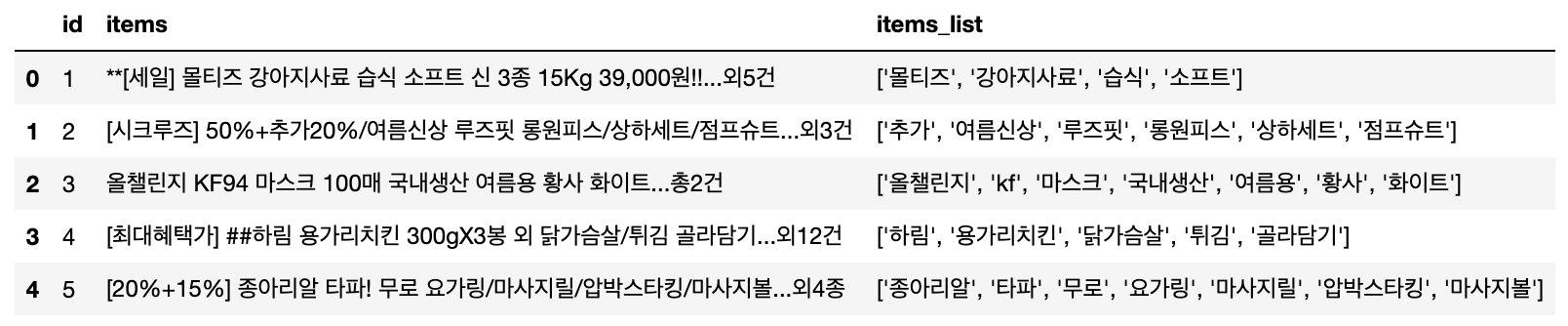
(2) 토큰화 (tokenization)
토큰화(Tokenization)는 말뭉치(Corpus)를 토큰이라고 불리는 단어 또는 문장으로 나누는 것을 말합니다. 이러한 토큰은 문맥(Context)을 이해하거나 NLP에 대한 모델을 개발하는 데 사용됩니다.
POS 태킹 (Part-of-Speech Tagging) 은 널리 사용되는 자연어 처리 프로세스로, 단어의 정의와 문맥에 따라 언어의 특정 부분에 대응하여 텍스트(corpus)의 단어를 분류하는 것을 말합니다.
아래 코드는 위 (1)번의 텍스트 전처리에 이어서, 띄어쓰기가 제대로 되지 않아서 붙어 있는 단어들을, Python KoNLpy 패키지를 사용해서 형태소 분석의 명사를 기준으로 단어 토근화를 한 것입니다. ((2)번 words_tokonizer() UDF 안에 (1)번 text_preprocessor() UDF가 포함되어 있으며, 순차적으로 수행됩니다.)
KoNLpy 패키지는 Python으로 한국어 자연어 처리(NLP) 을 할 수 있게 해주는 패키지입니다. 그리고 Kkma 는 서울대학교의 IDS 랩에서 JAVA로 개발한 형태소 분석기(morphological analyzer)입니다.
## insatll konlpy if it is not istalled yet
# ! pip install konlpy
## KoNLpy : NLP of the Korean language
## reference ==> https://konlpy.org/en/latest/
## Kkma is a morphological analyzer
## and natural language processing system written in Java,
## developed by the Intelligent Data Systems (IDS) Laboratory at SNU.
from konlpy.tag import Kkma
## define words tokenizer UDF
def words_tokonizer(text):
from konlpy.tag import Kkma # NLP of the Korean language
kkma = Kkma()
words = []
# Text preprocessing using the UDF above
s_list = text_preprocessor(text)
# POS tagging
for s in s_list:
words_ = kkma.pos(s)
# NNG indexing
for word in words_:
if word[1] == 'NNG':
words.append(word[0])
return words
## apply the UDF above as an example
words_tokonizer('강아지사료')
[Out] ['강아지', '사료']
words_tokonizer('상하세트')
[Out] ['상하', '세트']
위의 (2) words_tokenizer() UDF를 pandas DataFrame에 적용하기 위해서 apply() 함수와 lambda function 을 사용하면 됩니다.
## apply the text tokenization UDF to pandas DataFrame using apply() and lambda function
df['items'].apply(lambda text: words_tokonizer(text))
[Out]
# 0 [몰티즈, 강아지, 사료, 습식, 소프트]
# 1 [추가, 여름, 신상, 루즈, 핏, 원피스, 상하, 세트, 점프, 슈트]
# 2 [챌린지, 마스크, 국내, 생산, 여름, 황사, 화이트]
# 3 [하림, 용가리, 치킨, 닭, 가슴살, 튀김]
# 4 [종아리, 타파, 무로, 요가, 링, 마사지, 압박, 스타, 킹, 마사지]
# Name: items, dtype: object
이번 포스팅이 많은 도움이 되었기를 바랍니다.
행복한 데이터 과학자 되세요! :-)

'Deep Learning (TF, Keras, PyTorch) > Natural Language Processing' 카테고리의 다른 글
| ChatGPT를 사용하기 위한 OpenAI API Key 발급하는 방법 (0) | 2023.04.09 |
|---|---|
| OpenAI ChatGPT API 사용하는 방법 (0) | 2023.03.19 |
| [NLP] TF-IDF (Term Frequency - Inverse Document Frequency) (2) | 2022.04.10 |
| [NLP] 언어 구조의 구성 요소 (Building Blocks of Language Structure) (0) | 2022.02.20 |
| [NLP] 자연어 처리(NLP, Natural Language Processing)란 무엇이고, NLP 응용분야는 무엇이 있나? (0) | 2022.02.20 |



