[PostgreSQL, Greenplum] Window Functions, 윈도우 함수
Greenplum and PostgreSQL Database 2022. 2. 13. 22:47이번 포스팅에서는 PostgreSQL, Greenplum DB의 Window Function 의 함수 특징, 함수별 구문 사용법에 대해서 알아보겠습니다. Window Function을 알아두면 편리하고 또 강력한 SQL query 를 사용할 수 있습니다. 특히 MPP (Massively Parallel Processing) Architecture 의 Greenplum DB 에서는 Window Function 실행 시 분산병렬처리가 되기 때문에 성능 면에서 매우 우수합니다.
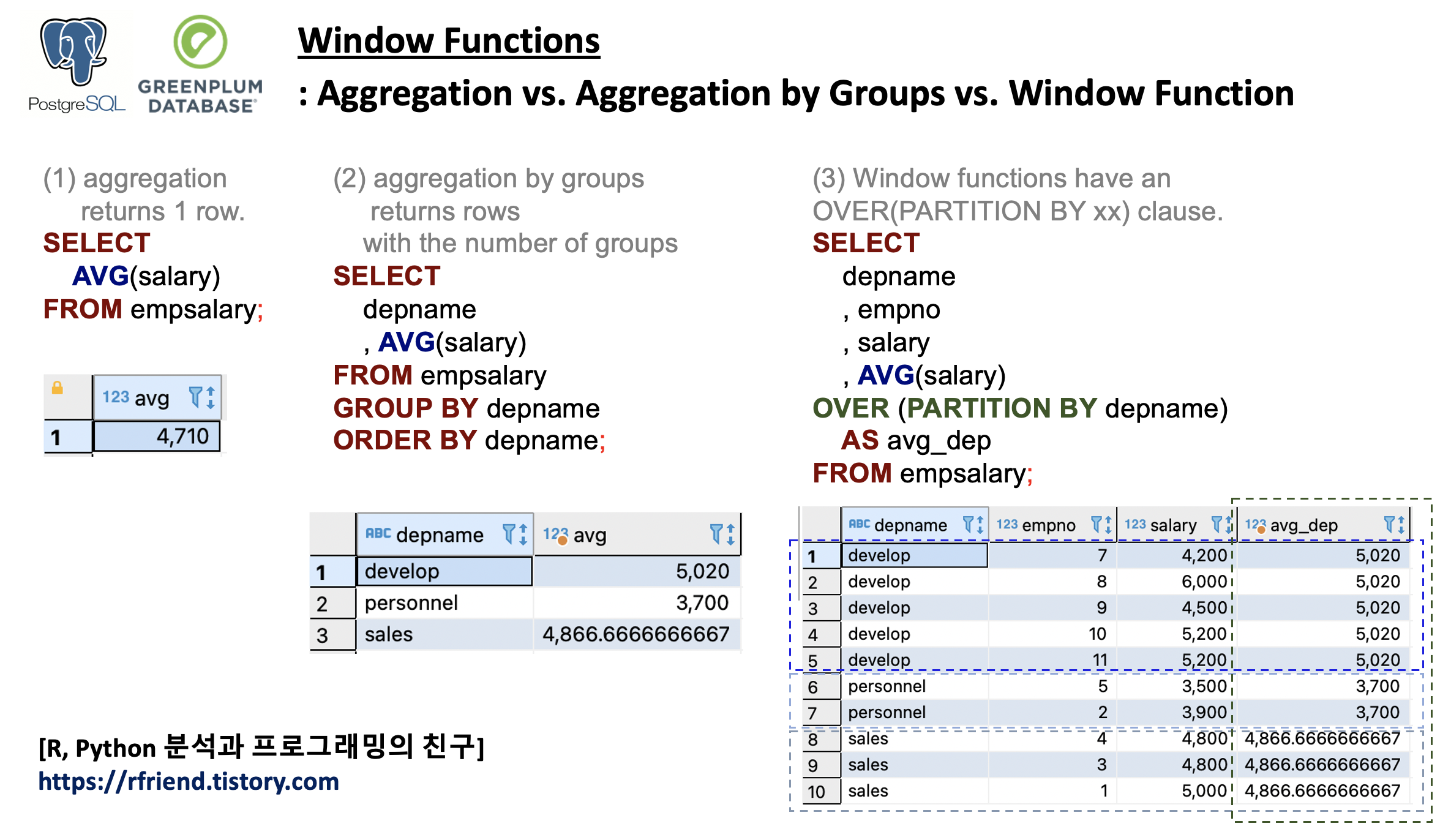
Window Function 은 현재 행과 관련된 테이블 행 집합(a set of table rows)에 대해 계산을 수행합니다. 이는 집계 함수(aggregate function)로 수행할 수 있는 계산 유형과 비슷합니다. 그러나 일반적인 집계 함수와 달리 Window Function을 사용하면 행이 단일 출력 행으로 그룹화되지 않으며 행은 별도의 ID를 유지합니다.
아래 화면의 예시는 AVG() 함수로 평균을 구하는데 있어,
(a) 전체 평균 집계: AVG() --> 한 개의 행 반환
(b) 그룹별 평균 집계: AVG() ... GROUP BY --> 그룹의 개수만큼 행 반환
(c) Window Function: AVG() OVER (PARTITION BY) --> ID의 개수만큼 행 반환
별로 차이를 비교해보았습니다.
[ PostgreSQL, Greenplum: Aggregation vs. Aggregation by Groups vs. Window Function ]
먼저, 부서(depname), 직원번호(empno), 급여(salary) 의 칼럼을 가지는 간단한 예제 테이블 empsalary 을 만들고 데이터를 입력해보겠습니다.
-- (0) making a sample table as an example
DROP TABLE IF EXISTS empsalary;
CREATE TABLE empsalary (
depname TEXT
, empno INT
, salary INT
);
INSERT INTO empsalary (depname, empno, salary)
VALUES
('sales', 1, 5000)
, ('personnel', 2, 3900)
, ('sales', 3, 4800)
, ('sales', 4, 4800)
, ('personnel', 5, 3500)
, ('develop', 7, 4200)
, ('develop', 8, 6000)
, ('develop', 9, 4500)
, ('develop', 10, 5200)
, ('develop' , 11, 5200);
SELECT * FROM empsalary ORDER BY empno LIMIT 2;
--depname |empno|salary|
-----------+-----+------+
--sales | 1| 5000|
--personnel| 2| 3900|
(1) AVG() vs. AVG() GROUP BY vs. AVG() OVER (PARTITION BY ORDER BY)
아래는 (a) AVG() 로 전체 급여의 전체 평균 집계, (b) AVG() GROUP BY depname 로 부서 그룹별 평균 집계, (c) AVG() OVER (PARTITION BY depname) 의 Window Function을 사용해서 부서 집합 별 평균을 계산해서 직원번호 ID의 행별로 결과를 반환하는 것을 비교해 본 것입니다. 반환하는 행의 개수, 결과를 유심히 비교해보시면 aggregate function 과 window function 의 차이를 이해하는데 도움이 될거예요.
-- (0) aggregation returns 1 row.
SELECT
AVG(salary)
FROM empsalary;
--avg |
-----------------------+
--4710.0000000000000000|
-- (0) aggregation by groups returns rows with the number of groups
SELECT
depname
, AVG(salary)
FROM empsalary
GROUP BY depname
ORDER BY depname;
--depname |avg |
-----------+---------------------+
--develop |5020.000000000000000
--personnel|3700.000000000000000
--sales |4866.6666666666666667|
-- (1) Window functions have an OVER(PARTITION BY xx) clause.
-- any function without an OVER clause is not a window function, but rather an aggregate or single-row (scalar) function.
SELECT
depname
, empno
, salary
, AVG(salary)
OVER (PARTITION BY depname)
AS avg_dep
FROM empsalary;
--depname |empno|salary|avg_dep |
-----------+-----+------+---------------------+
--develop | 7| 4200|5020.0000000000000000|
--develop | 8| 6000|5020.0000000000000000|
--develop | 9| 4500|5020.0000000000000000|
--develop | 10| 5200|5020.0000000000000000|
--develop | 11| 5200|5020.0000000000000000|
--personnel| 5| 3500|3700.0000000000000000|
--personnel| 2| 3900|3700.0000000000000000|
--sales | 4| 4800|4866.6666666666666667|
--sales | 3| 4800|4866.6666666666666667|
--sales | 1| 5000|4866.6666666666666667|
아래는 PostgreSQL, Greenplum 의 Window Function Syntax 구문입니다.
- window_function(매개변수) 바로 다음에 OVER() 가 있으며,
- OVER() 안에 PARTITION BY 로 연산이 실행될 집단(set) 기준을 지정해주고
- OVER() 안에 ORDER BY 로 시간(time), 순서(sequence)가 중요할 경우 정렬 기준을 지정해줍니다.
-- PostgreSQL Window Function Syntax
WINDOW_FUNCTION(arg1, arg2,..) OVER (
[PARTITION BY partition_expression]
[ORDER BY sort_expression [ASC | DESC]
[NULLS {FIRST | LAST }]
)

PostgreSQL의 Window Functions 중에서 제가 그래도 자주 쓰는 함수로 AVG() OVER(), SUM() OVER(), RANK() OVER(), LAG() OVER(), LEAD() OVER(), FIRST_VALUE() OVER(), LAST_VALUE() OVER(), NTILE() OVER(), ROW_NUMBER() OVER() 등의 일부 함수 (제 맘대로... ㅎㅎ)에 대해서 아래에 예시를 들어보겠습니다.
(2) RANK() OVER ([PARTITION BY] ORDER BY) : 순위
아래 예는 PARTITION BY depname 로 '부서' 집단별로 구분해서, ORDER BY salary DESC로 급여 내림차순으로 정렬한 후의 직원별 순위(rank)를 계산해서 직원 ID 행별로 순위를 반환해줍니다.
PARTITION BY 집단 내에서 ORDER BY 정렬 기준칼럼의 값이 동일할 경우 순위는 동일한 값을 가지며, 동일한 순위의 개수만큼 감안해서 그 다음 순위의 값은 순위가 바뀝니다. (가령, develop 부서의 경우 순위가 1, 2, 2, 4, 5, 로서 동일 순위 '2'가 두명 있고, 급여가 네번째인 사람의 순위는 '4'가 되었음.)
-- (2) You can control the order
-- in which rows are processed by window functions using ORDER BY within OVER.
SELECT
depname
, empno
, salary
, RANK() OVER (PARTITION BY depname ORDER BY salary DESC)
FROM empsalary;
--depname |empno|salary|rank|
-----------+-----+------+----+
--personnel| 2| 3900| 1|
--personnel| 5| 3500| 2|
------------------------------------- set 1 (personnel)
--sales | 1| 5000| 1|
--sales | 3| 4800| 2|
--sales | 4| 4800| 2|
------------------------------------- set 2 (sales)
--develop | 8| 6000| 1|
--develop | 11| 5200| 2|
--develop | 10| 5200| 2|
--develop | 9| 4500| 4|
--develop | 7| 4200| 5|
------------------------------------- set 3 (develop)
(3) SUM() OVER () : PARTITION BY, ORDER BY 는 생략 가능
만약 집단별로 구분해서 연산할 필요가 없다면 OVER() 구문 안에서 PARTITON BY 는 생략할 수 있습니다.
만약 시간이나 순서가 중요하지 않다면 OVER() 구문 안에서 ORDER BY 는 생략할 수 있습니다.
아래 예에서는 SUM(salary) OVER () 를 사용해서 전체 직원의 급여 평균을 계산해서 각 직원 ID의 개수 만큼 행을 반환했습니다.
-- (3) ORDER BY can be omitted if the ordering of rows is not important.
-- It is also possible to omit PARTITION BY,
-- in which case there is just one partition containing all the rows.
SELECT
salary
, SUM(salary) OVER () -- same result
FROM empsalary;
--salary|sum |
--------+-----+
-- 5000|47100|
-- 3900|47100|
-- 4800|47100|
-- 4800|47100|
-- 3500|47100|
-- 4200|47100|
-- 6000|47100|
-- 4500|47100|
-- 5200|47100|
-- 5200|47100|
(4) SUM() OVER (ORDER BY) : ORDER BY 구문이 추가되면 누적 합으로 결과가 달라짐
만약 PARTITION BY 가 없어서 집단별 구분없이 전체 데이터셋을 대상으로 연산을 하게 될 때, SUM(salary) OVER (ORDER BY salary) 처럼 OVER () 절 안에 ORDER BY 를 추가하게 되면 salary 를 기준으로 정렬이 된 상태에서 누적 합이 계산되므로 위의 (3)번과 차이점을 알아두기 바랍니다.
-- (4) But if we add an ORDER BY clause, we get very different results:
SELECT
salary
, SUM(salary) OVER (ORDER BY salary)
FROM empsalary;
--salary|sum |
--------+-----+
-- 3500| 3500|
-- 3900| 7400|
-- 4200|11600|
-- 4500|16100|
-- 4800|25700|
-- 4800|25700|
-- 5000|30700|
-- 5200|41100|
-- 5200|41100|
-- 6000|47100|
(5) LAG(expression, offset) OVER (ORDER BY), LEAD(expression, offset) OVER (ORDER BY)
이번에는 시간(time), 순서(sequence)가 중요한 시계열 데이터(Time Series data) 로 예제 테이블을 만들어보겠습니다. 시계열 데이터에 대해 Window Function 을 사용하게 되면 OVER (ORDER BY timestamp) 처럼 ORDER BY 를 꼭 포함시켜줘야 겠습니다.
-- (5) LAG() over (), LEAD() over ()
-- making a sample TimeSeries table
DROP TABLE IF EXISTS ts;
CREATE TABLE ts (
dt DATE
, id INT
, val INT
);
INSERT INTO ts (dt, id, val) VALUES
('2022-02-10', 1, 25)
, ('2022-02-11', 1, 28)
, ('2022-02-12', 1, 35)
, ('2022-02-13', 1, 34)
, ('2022-02-14', 1, 39)
, ('2022-02-10', 2, 40)
, ('2022-02-11', 2, 35)
, ('2022-02-12', 2, 30)
, ('2022-02-13', 2, 25)
, ('2022-02-14', 2, 15);
SELECT * FROM ts ORDER BY id, dt;
--dt |id|val|
------------+--+---+
--2022-02-10| 1| 25|
--2022-02-11| 1| 28|
--2022-02-12| 1| 35|
--2022-02-13| 1| 34|
--2022-02-14| 1| 39|
--2022-02-10| 2| 40|
--2022-02-11| 2| 35|
--2022-02-12| 2| 30|
--2022-02-13| 2| 25|
--2022-02-14| 2| 15|
LAG(expression, offset) OVER (PARTITION BY id ORDER BY timestamp) 윈도우 함수는 ORDER BY timestamp 기준으로 정렬을 한 상태에서, id 집합 내에서 현재 행에서 offset 만큼 앞에 있는 행의 값(a row which comes before the current row)을 가져옵니다. 아래의 예를 살펴보는 것이 이해하기 빠르고 쉬울거예요.
-- (5-1) LAG() function to access a row which comes before the current row
-- at a specific physical offset.
SELECT
dt
, id
, val
, LAG(val, 1) OVER (PARTITION BY id ORDER BY dt) AS lag_val_1
, LAG(val, 2) OVER (PARTITION BY id ORDER BY dt) AS lag_val_2
FROM ts
;
--dt |id|val|lag_val_1|lag_val_2|
------------+--+---+---------+---------+
--2022-02-10| 1| 25| | |
--2022-02-11| 1| 28| 25| |
--2022-02-12| 1| 35| 28| 25|
--2022-02-13| 1| 34| 35| 28|
--2022-02-14| 1| 39| 34| 35|
--2022-02-10| 2| 40| | |
--2022-02-11| 2| 35| 40| |
--2022-02-12| 2| 30| 35| 40|
--2022-02-13| 2| 25| 30| 35|
--2022-02-14| 2| 15| 25| 30|
LEAD(expression, offset) OVER (PARTITION BY id ORDER BY timestamp) 윈도우 함수는 ORDER BY timestamp 기준으로 정렬을 한 후에, id 집합 내에서 현재 행에서 offset 만큼 뒤에 있는 행의 값(a row which follows the current row)을 가져옵니다. 아래의 예를 살펴보는 것이 이해하기 빠르고 쉬울거예요.
-- (5-2) LEAD() function to access a row that follows the current row,
-- at a specific physical offset.
SELECT
dt
, id
, val
, LEAD(val, 1) OVER (PARTITION BY id ORDER BY dt) AS lead_val_1
, LEAD(val, 2) OVER (PARTITION BY id ORDER BY dt) AS lead_val_2
FROM ts
;
--dt |id|val|lead_val_1|lead_val_2|
------------+--+---+----------+----------+
--2022-02-10| 1| 25| 28| 35|
--2022-02-11| 1| 28| 35| 34|
--2022-02-12| 1| 35| 34| 39|
--2022-02-13| 1| 34| 39| |
--2022-02-14| 1| 39| | |
--2022-02-10| 2| 40| 35| 30|
--2022-02-11| 2| 35| 30| 25|
--2022-02-12| 2| 30| 25| 15|
--2022-02-13| 2| 25| 15| |
--2022-02-14| 2| 15| | |
(6) FIRST_VALUE() OVER (), LAST_VALUE() OVER ()
OVER (PARTITION BY id ORDER BY dt) 로 id 집합 내에서 dt 순서를 기준으로 정렬한 상태에서, FIRST_VALUE() 는 첫번째 값을 반환하며, LAST_VALUE() 는 마지막 값을 반환합니다.
OVER() 절 안에 RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING 은 partion by 집합 내의 처음과 끝의 모든 행의 범위를 다 고려하라는 의미입니다.
-- (6) FIRST_VALUE() OVER (), LAST_VALUE() OVER ()
-- The FIRST_VALUE() function returns a value evaluated
-- against the first row in a sorted partition of a result set.
-- The LAST_VALUE() function returns a value evaluated
-- against the last row in a sorted partition of a result set.
-- The RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING clause defined
-- the frame starting from the first row and ending at the last row of each partition.
SELECT
dt
, id
, val
, FIRST_VALUE(val)
OVER (
PARTITION BY id
ORDER BY dt
RANGE BETWEEN UNBOUNDED PRECEDING
AND UNBOUNDED FOLLOWING) AS first_val
, LAST_VALUE(val)
OVER (
PARTITION BY id
ORDER BY dt
RANGE BETWEEN UNBOUNDED PRECEDING
AND UNBOUNDED FOLLOWING) AS last_val
FROM ts
;
--dt |id|val|first_val|last_val|
------------+--+---+---------+--------+
--2022-02-10| 1| 25| 25| 39|
--2022-02-11| 1| 28| 25| 39|
--2022-02-12| 1| 35| 25| 39|
--2022-02-13| 1| 34| 25| 39|
--2022-02-14| 1| 39| 25| 39|
--2022-02-10| 2| 40| 40| 15|
--2022-02-11| 2| 35| 40| 15|
--2022-02-12| 2| 30| 40| 15|
--2022-02-13| 2| 25| 40| 15|
--2022-02-14| 2| 15| 40| 15|
(7) NTILE(buckets) OVER (PARTITION BY ORDER BY)
NTINE(buckets) 의 buckets 개수 만큼 가능한 동일한 크기(equal size)를 가지는 집단으로 나누어줍니다.
아래 예 NTILE(2) OVER (PARTITION BY id ORDER BY val) 는 id 집합 내에서 val 을 기준으로 정렬을 한 상태에서 NTILE(2) 의 buckets = 2 개 만큼의 동일한 크기를 가지는 집단으로 나누어주었습니다.
짝수개면 정확하게 동일한 크기로 나누었을텐데요, id 집단 내 행의 개수가 5개로 홀수개인데 2개의 집단으로 나누려다 보니 가능한 동일한 크기인 3개, 2개로 나뉘었네요.
-- (7) NTILE() function allows you to divide ordered rows in the partition
-- into a specified number of ranked groups as EQUAL SIZE as possible.
SELECT
dt
, id
, val
, NTILE(2) OVER (PARTITION BY id ORDER BY val) AS ntile_val
FROM ts
ORDER BY id, val
;
--dt |id|val|ntile_val|
------------+--+---+---------+
--2022-02-10| 1| 25| 1|
--2022-02-11| 1| 28| 1|
--2022-02-13| 1| 34| 1|
--2022-02-12| 1| 35| 2|
--2022-02-14| 1| 39| 2|
--2022-02-14| 2| 15| 1|
--2022-02-13| 2| 25| 1|
--2022-02-12| 2| 30| 1|
--2022-02-11| 2| 35| 2|
--2022-02-10| 2| 40| 2|
(8) ROW_NUMBER() OVER (ORDER BY)
아래의 예 ROW_NUMBER() OVER (PARTITION BY id ORDER BY dt) 는 id 집합 내에서 dt 를 기준으로 올림차순 정렬 (sort in ascending order) 한 상태에서, 1 부터 시작해서 하나씩 증가시켜가면서 행 번호 (row number) 를 부여한 것입니다. 집합 내에서 특정 기준으로 정렬한 상태에서 특정 순서/위치의 값을 가져오기 한다거나, 집합 내에서 unique 한 ID 를 생성하고 싶을 때 종종 사용합니다.
-- (8) ROW_NUMBER() : Number the current row within its partition starting from 1.
SELECT
dt
, id
, val
, ROW_NUMBER() OVER (PARTITION BY id ORDER BY dt) AS seq_no
FROM ts
;
--dt |id|val|seq_no|
------------+--+---+------+
--2022-02-10| 1| 25| 1|
--2022-02-11| 1| 28| 2|
--2022-02-12| 1| 35| 3|
--2022-02-13| 1| 34| 4|
--2022-02-14| 1| 39| 5|
--2022-02-10| 2| 40| 1|
--2022-02-11| 2| 35| 2|
--2022-02-12| 2| 30| 3|
--2022-02-13| 2| 25| 4|
--2022-02-14| 2| 15| 5|
[ Reference ]
* PostgreSQL Window Functions
: https://www.postgresql.org/docs/9.6/tutorial-window.html
* PostgreSQL Window Functions Tutorial
: https://www.postgresqltutorial.com/postgresql-window-function/
이번 포스팅이 많은 도움이 되었기를 바랍니다.
행복한 데이터 과학자 되세요! :-)




