[PyTorch] NumPy의 array 대비 PyTorch 의 성능 비교
Deep Learning (TF, Keras, PyTorch)/PyTorch basics 2023. 2. 19. 23:13이번 포스팅에서는 PyTorch tensor 와 NumPy ndarrays 의 행렬 곱셈(matrix multiplication) 성능을 비교해보겠습니다. GPU 는 Google Colab 을 사용해서 성능을 테스트했습니다.
(1) PyTorch tensor & GPU 로 행렬 곱셈 (matrix multiplication)
(2) PyTorch tensor & CPU 로 행렬 곱셈
(3) NumPy ndarrays & CPU 로 행렬 곱셈

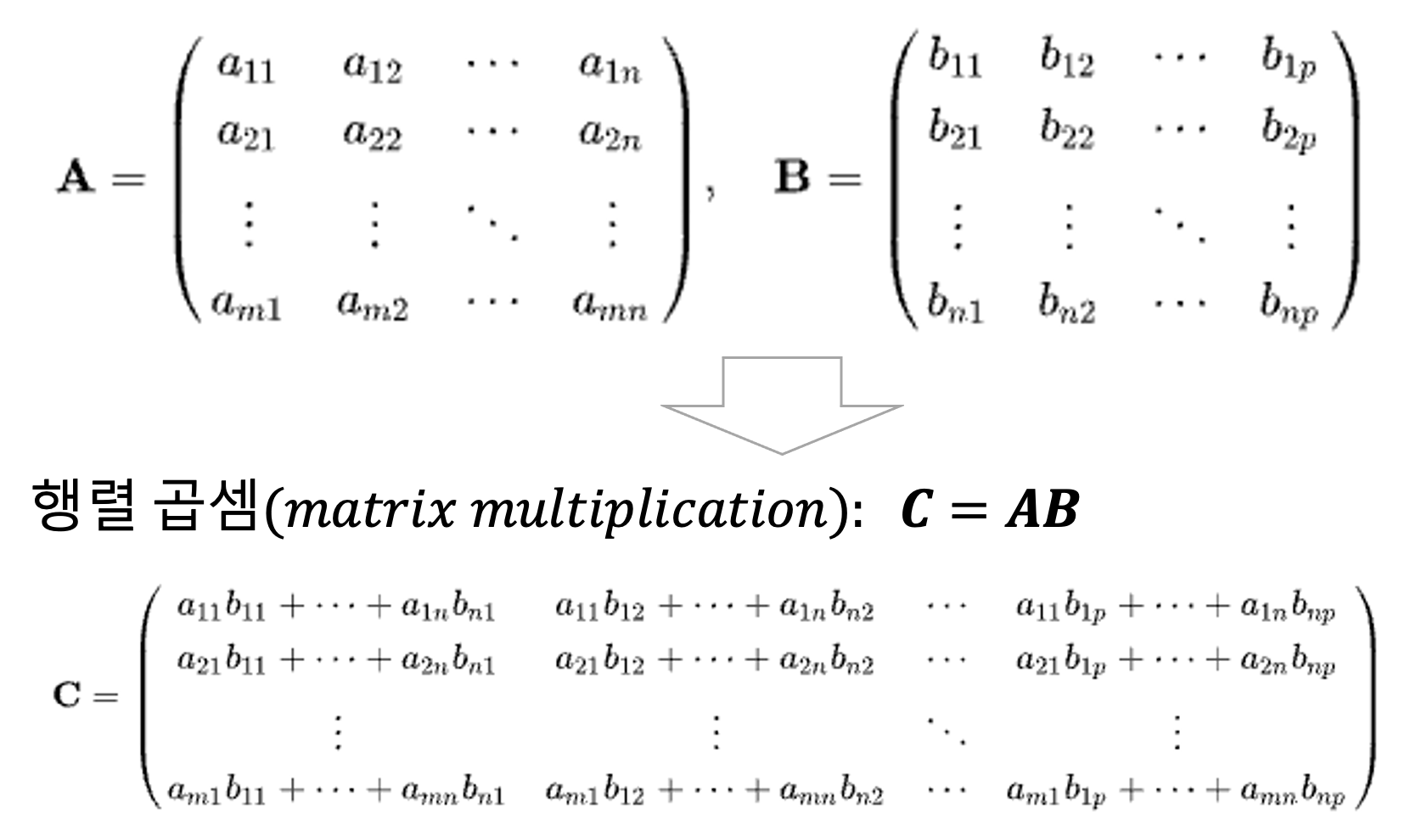
m * n 행렬 A 와 n * p 행렬 B 가 있다고 했을 때, 행렬 곱셈(matrix multiplication) C = AB 는 아래와 같이 정의할 수 있습니다. 행렬 곱셈 연산은 A 의 i번째 행과 B의 j번째 열의 성분들을 각각 곱한 후 더한 것이며, 서로 독립적으로 병렬 연산 (calculation in parallel) 이 가능합니다. GPU 는 수 천 개의 cores 를 가지고 있으므로 단지 수 개의 cores를 가지는 CPU 보다 병렬로 행렬 곱셈을 매우 빠르게 수행할 수 있습니다.
(1) PyTorch tensor & GPU 로 행렬 곱셈 (matrix multiplication)
PyTorch를 불러오고, torch.manual_seed() 로 초기값을 설정해서 매번 동일한 난수가 발생하게 설정을 해준 다음, torch.rand() 함수로 난수를 생성해서 torch 객체를 만들어보겠습니다.
import torch
print(torch.__version__)
#1.13.1+cu116
## generate the torch objects with random numbers
torch.manual_seed(1004)
x = torch.rand(1, 25600)
y = torch.rand(25600, 100)
다음으로, torch tensor 객체를 저장할 디바이스를 정의하겠습니다. 아래 코드는 GPU 를 사용할 수 있으면 (torch.cuda.is_available() == True) 'cuda' 로 디바이스를 정의하고, 그렇지 않으면 'cpu'로 디바이스를 정의합니다.
## define the device
device = 'cuda' if torch.cuda.is_available() else 'cpu'
이제 x, y의 두 개 tensor 객체를 위에서 정의한 디바이스에 등록(register)해서 정보를 저장하겠습니다.
## register and save the tensor objects with the device
x, y = x.to(device), y.to(device)
마지막으로, PyTorch tensor 객체인 행렬 x와 y 의 행렬 곱셉(matrix multiplication, z = (x@y))을 GPU 를 사용해서 해보겠습니다. 이때 실행 성능을 확인하기 위해 %timeit 으로 실행 시간을 측정해보겠습니다.
행렬 곱셉에 25.4 µs ± 26.9 µs per loop 의 시간이 걸렸네요.
## (1) run matrix multiplication of the Torch objects on GPU
%timeit z = (x@y)
# The slowest run took 6.94 times longer than the fastest.
# This could mean that an intermediate result is being cached.
# 25.4 µs ± 26.9 µs per loop (mean ± std. dev. of 7 runs, 1 loop each)
(2) PyTorch tensor & CPU 로 행렬 곱셈 (matrix multiplication)
이번에는 PyTorch tensor 에 대해 CPU 를 사용(x.cpu(), y.cpu())해서 행렬 곱셉을 해보겠습니다.
PyTorch tensor에 대해 CPU 로는 932 µs ± 292 µs per loop 의 시간이 소요되었으며, 이는 위의 PyTorch tensor & GPU 대비 약 37배 더 시간이 소요되었습니다.
## (2) run matrix multiplication of the same tensors on CPU
x, y = x.cpu(), y.cpu()
%timeit z = (x@y)
# 932 µs ± 292 µs per loop
# (mean ± std. dev. of 7 runs, 1000 loops each)
(3) NumPy ndarrays & CPU 로 행렬 곱셈
마지막으로 NumPy의 ndarrays 로 위의 PyTorch로 했던 행렬 곱셉을 똑같이 실행해서, 소요시간을 측정(%timeit)해 보겠습니다.
NumPy의 ndarrays 로 행렬 곱셉은 1.17 ms ± 46.4 µs per loop 이 걸려서, 위의 PyTorch tensor & GPU 는 NumPy ndarrays 보다 46배 빠르고, 위의 PyTorch tensor & CPU 는 NumPy ndarrays 보다 1.25 배 빠르걸로 나왔습니다.
역시 GPU 가 행렬 곱셉 성능에 지대한 영향을 끼치고 있음을 확인할 수 있습니다!
## (3) run matrix multiplication on NumPy arrays
import numpy as np
x = np.random.random((1, 25600))
y = np.random.random((25600, 100))
%timeit z = np.matmul(x, y)
# 1.17 ms ± 46.4 µs per loop
# (mean ± std. dev. of 7 runs, 1000 loops each)
PyTorch tensor & GPU 의 강력한 성능을 이용해서 멋진 딥러닝 모델 학습하세요.
이번 포스팅이 많은 도움이 되었기를 바랍니다.
행복한 데이터 과학자 되세요! :-)

'Deep Learning (TF, Keras, PyTorch) > PyTorch basics' 카테고리의 다른 글
| [PyTorch] 텐서 나누기 (splitting a PyTorch tensor into multiple tensors) (0) | 2023.02.23 |
|---|---|
| [PyTorch] 텐서 합치기 (concat, stack) (0) | 2023.02.21 |
| [PyTorch] 텐서의 인덱싱과 슬라이싱 (indexing & slicing of PyTorch tensor) (0) | 2023.02.19 |
| [PyTorch] 난수를 생성해서 텐서 만들기 (generating a tensor with random numbers) (0) | 2023.02.12 |
| [PyTorch] 텐서 객체 만들기 (PyTorch tensor objects) (0) | 2023.02.05 |



