[PostgreSQL, Greenplum] 사분위수와 IQR를 이용하여 이상치 찾기 (Identifying Outliers by the upper and lower limit based on Quartiles and IQR(Interquartile Range) using SQL in PostgreSQL)
Greenplum and PostgreSQL Database 2021. 12. 12. 22:49데이터셋에 이상치가 있으면 모델을 훈련시킬 때 적합된 모수에 큰 영향을 줍니다. 따라서 탐색적 데이터 분석을 할 때 이상치(outlier)를 찾고 제거하는 작업이 필요합니다.
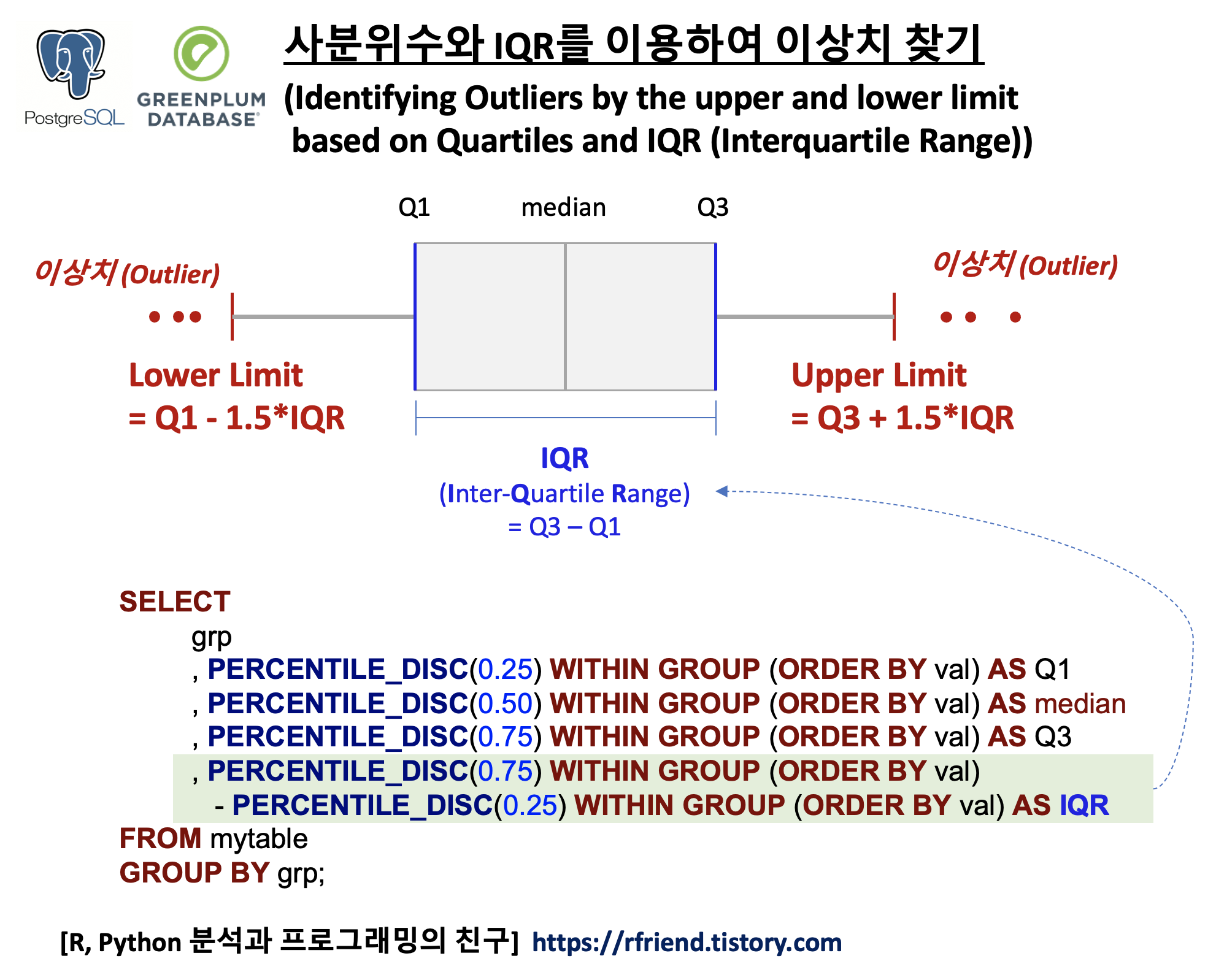
이번 포스팅에서는 PostgreSQL, Greenplum DB에서 SQL의 PERCENTILE_DISC() WITHIN GROUP (ORDER BY) 함수를 사용해서, 사분위수와 IQR 에 기반하여 이상치를 찾고 제거하는 방법(Identifying and removing Outliers by the upper and lower limit based on Quartiles and IQR(Interquartile Range))을 소개하겠습니다.
요약통계량의 평균과 표준편차는 이상치에 매우 민감합니다. 따라서 정규분포가 아니라 이상치가 존재하여 한쪽으로 치우친 분포에서는 (average +-3 * standard deviation) 범위 밖의 값을 이상치로 간주하는 방법은 적합하지 않을 수 있습니다. 반면, 이상치에 덜 민감한 사분위수와 IQR 를 이용하여 이상치를 찾고 제거하는 방법은 간단하게 구현하여 사용할 수 있습니다.
먼저, 예제로 사용할 데이터셋 테이블을 만들어보겠습니다. 부산과 서울의 지역(region) 그룹별로 seller_id 별 판매금액(amt) 을 칼럼으로 가지며, 판매금액에 이상치(outliler)를 포함시켰습니다.
---------------------------------------------------------------------------------
-- Removing Outliers based on Quartiles and IQR using SQL
---------------------------------------------------------------------------------
-- creating a sample dataset with outliers
DROP TABLE IF EXISTS reg_sales;
CREATE TABLE reg_sales (
region text NOT NULL
, seller_id int NOT NULL
, amt int
);
INSERT INTO reg_sales VALUES
('Busan', 1, 10) -- outlier
, ('Busan', 2, 310)
, ('Busan', 3, 350)
, ('Busan', 4, 380)
, ('Busan', 5, 390)
, ('Busan', 6, 430)
, ('Busan', 7, 450)
, ('Busan', 8, 450)
, ('Busan', 9, 3200) -- outlier
, ('Busan', 10, 4600) -- outlier
, ('Seoul', 1, 20) -- outlier
, ('Seoul', 2, 300)
, ('Seoul', 3, 350)
, ('Seoul', 4, 370)
, ('Seoul', 5, 380)
, ('Seoul', 6, 400)
, ('Seoul', 7, 410)
, ('Seoul', 8, 440)
, ('Seoul', 9, 460)
, ('Seoul', 10, 2500) -- outlier
;
SELECT * FROM reg_sales ORDER BY region, amt;
--region|seller_id|amt |
--------+---------+----+
--Busan | 1| 10|
--Busan | 2| 310|
--Busan | 3| 350|
--Busan | 4| 380|
--Busan | 5| 390|
--Busan | 6| 430|
--Busan | 8| 450|
--Busan | 7| 450|
--Busan | 9|3200|
--Busan | 10|4600|
--Seoul | 1| 20|
--Seoul | 2| 300|
--Seoul | 3| 350|
--Seoul | 4| 370|
--Seoul | 5| 380|
--Seoul | 6| 400|
--Seoul | 7| 410|
--Seoul | 8| 440|
--Seoul | 9| 460|
--Seoul | 10|2500|
PostgreSQL, Greenplum 에서 PERCENTILE_DISC() 함수를 사용하여 사분위수(quartiles)와 IQR(Interquartile Range)를 구할 수 있습니다. 아래 예에서는 지역(region) 별로 1사분위수(Q1), 중앙값(median), 3사분위수(Q3), IQR (Interquartile Range) 를 구해보았습니다.
IQR (Interquartile Range) = Q3 - Q1
-- Quartiles by region groups
-- Interquartile Range (IQR) = Q3-Q1
-- : relatively robust statistic compared to range and std dev for the measure of spread.
SELECT
region
, PERCENTILE_DISC(0.25) WITHIN GROUP (ORDER BY amt) AS q1
, PERCENTILE_DISC(0.50) WITHIN GROUP (ORDER BY amt) AS median
, PERCENTILE_DISC(0.75) WITHIN GROUP (ORDER BY amt) AS q3
, PERCENTILE_DISC(0.75) WITHIN GROUP (ORDER BY amt) -
PERCENTILE_DISC(0.25) WITHIN GROUP (ORDER BY amt) AS iqr
FROM reg_sales
GROUP BY region
ORDER BY region;
--region|q1 |median|q3 |iqr|
--------+---+------+---+---+
--Busan |350| 390|450|100|
--Seoul |350| 380|440| 90|
사분위수와 IQR 를 이용하여 이상치를 찾는 방식(identifying outliers by upper and lower limit based on quartiles and IQR using SQL in PostgreSQL)은 아래와 같습니다. (포스팅 상단의 도식 참조)
* Upper Limit = Q1 - 1.5 * IQR
* Lower Limit = Q3 + 1.5 * IQR
if value > Upper Limit then 'Outlier'
or if value < Lower Limit then 'Outlier'
-- Identifying outliers by the upper and lower limit based on Quartiles and IQR as:
-- : Lower Limit = Q1 – 1.5 * IQR
-- : Upper Limit = Q3 + 1.5 * IQR
WITH stats AS (
SELECT
region
, PERCENTILE_DISC(0.25) WITHIN GROUP (ORDER BY amt) AS q1
, PERCENTILE_DISC(0.75) WITHIN GROUP (ORDER BY amt) AS q3
, PERCENTILE_DISC(0.75) WITHIN GROUP (ORDER BY amt) -
PERCENTILE_DISC(0.25) WITHIN GROUP (ORDER BY amt) AS iqr
FROM reg_sales
GROUP BY region
)
SELECT
r.*
FROM reg_sales AS r
LEFT JOIN stats AS s ON r.region = s.region
WHERE r.amt < (s.q1 - 1.5 * s.iqr) OR r.amt > (s.q3 + 1.5 * s.iqr) -- identifying outliers
ORDER BY region, amt;
--region|seller_id|amt |
--------+---------+----+
--Busan | 1| 10|
--Busan | 9|3200|
--Busan | 10|4600|
--Seoul | 1| 20|
--Seoul | 10|2500|
아래의 예에서는 사분위수와 IQR에 기반하여 이상치를 제거 (Removing outliers by upper and lower limit based on quartiles and IQR using SQL in PostgreSQL) 하여 보겠습니다.
-- Removing outliers by the upper and lower limit based on Quartiles and IQR as:
-- : Lower Limit = Q1 – 1.5 * IQR
-- : Upper Limit = Q3 + 1.5 * IQR
WITH stats AS (
SELECT
region
, PERCENTILE_DISC(0.25) WITHIN GROUP (ORDER BY amt) AS q1
, PERCENTILE_DISC(0.75) WITHIN GROUP (ORDER BY amt) AS q3
, PERCENTILE_DISC(0.75) WITHIN GROUP (ORDER BY amt) -
PERCENTILE_DISC(0.25) WITHIN GROUP (ORDER BY amt) AS iqr
FROM reg_sales
GROUP BY region
)
SELECT
r.*
FROM reg_sales AS r
LEFT JOIN stats AS s ON r.region = s.region
WHERE r.amt > (s.q1 - 1.5 * s.iqr) AND r.amt < (s.q3 + 1.5 * s.iqr) -- removing outliers
ORDER BY region, amt;
--region|seller_id|amt|
--------+---------+---+
--Busan | 2|310|
--Busan | 3|350|
--Busan | 4|380|
--Busan | 5|390|
--Busan | 6|430|
--Busan | 7|450|
--Busan | 8|450|
--Seoul | 2|300|
--Seoul | 3|350|
--Seoul | 4|370|
--Seoul | 5|380|
--Seoul | 6|400|
--Seoul | 7|410|
--Seoul | 8|440|
--Seoul | 9|460|
[ Reference ]
* PostgreSQL PERCENTILE_DISC() function
: https://www.postgresql.org/docs/9.4/functions-aggregate.html
이번 포스팅이 많은 도움이 되었기를 바랍니다.
행복한 데이터 과학자 되세요! :-)







