[R] 시계열 데이터의 이동 평균, 누적 평균 구하기 (Average of time series using Rolling windows vs. Expanding windows)
R 분석과 프로그래밍/R 데이터 전처리 2021. 10. 13. 23:47주식을 하는 분들은 아마도 대표적인 시계열 데이터인 주가의 이동평균, 누적평균 그래프에 이미 익숙할 것입니다.
이번 포스팅에서는 R의 zoo 패키지의 rollapply() 라는 window function 의
(1) Rolling Windows 를 사용해서 시계열 데이터의 이동 평균 구하기
(average of time series using rolling windows)
(2) Expanding Windows 를 사용해서 시계열 데이터의 누적 평균 구하기
(average of time series using expanding windows)
방법을 소개하겠습니다.
[ 이동 평균 (average using Rolling Windows) vs. 누적 평균 (average using Expanding Windows) ]

시계열 데이터를 전처리하고 분석할 때 Window Function 을 자주 사용하는데요,
- Rolling Windows : 특정 window width (예: 10분, 1시간, 1일 등) 를 유지한채 측정 단위시간별로 이동하면서 분석
- Expanding Windows : 처음 시작 시점은 고정한 채, 시간이 흐름에 따라 신규로 포함되는 데이터까지 누적해서 분석
하는 차이가 있습니다. 바로 위에 Rolling Windows 와 Expanding Windows 를 도식화 해놓은 자료를 보면 금방 이해가 될거예요.
만약 시계열 데이터에 추세(trend) 나 계절성 (seasonality) 이 있다면 Rolling Windows 가 적당하며, 시계열 데이터에 추세나 계절성이 없이 안정적(stable) 이다면 Expanding Windows 를 사용해서 더 많은 데이터를 이용해서 요약 통계량을 계산하는게 유리할 수 있겠습니다.
시계열 예측 모델링할 때는 Rolling Windows 를 사용해서 모델 성능을 검증합니다.
R 의 zoo 패키지의 rollapply() 함수를 사용할 것이므로, zoo 패키지를 먼저 설치하고 임포팅합니다.
그리고 예제로 사용할 간단한 시계열 데이터를 만들어보겠습니다. 추세와 노이즈가 있는 시계열 데이터 입니다.
## ------------
## Wimdow functions in Time Series
## (1) Rolling window
## (2) Expanding window
## R zoo's rollapply(): https://www.rdocumentation.org/packages/zoo/versions/1.8-9/topics/rollapply
## ------------
install.packages("zoo")
library(zoo)
## generating a time series with trend and noise
set.seed(1) # for reproducibility
x <- rnorm(n=100, mean=0, sd=10) + 1:100
plot(x, type='l',
main="time series plot with trend and noise")
(1) Rolling Windows 를 사용해서 시계열 데이터의 이동 평균 구하기
(average of time series using rolling windows)
zoo 패키지의 rollapply() 함수에서
- width 매개변수는 'window width' 를 설정할 때 사용합니다.
- FUN 매개변수에는 원하는 함수를 지정해줄 수 있으므로 매우 강력하고 유연하게 사용할 수 있습니다. 아래 예에서는 평균(mean)과 최대값(max) 을 계산하는 함수를 사용해보았습니다.
- align 은 데이터의 기준을 정렬할 때 왼쪽("left"), 중앙("centered", default 설정), 오른쪽("right") 중에서 지정할 수 있습니다. 이때 align="left"로 설정해주면 자칫 잘못하면 미래의 데이터를 가져다가 요약 통계량을 만드는 실수 (lookahead) 를 할 수도 있으므로, 만약 예측 모델링이 목적이라면 lookahead 를 하는건 아닌지 유의해야 합니다.
- partial=TRUE 로 설정하면 양쪽 끝부분에 window width 의 개수에 데이터 포인트 개수가 모자라더라도 있는 데이터만 가지고 부분적으로라도 함수의 통계량을 계산해줍니다.
## (1) Rolling Windows
## (1-1) moving average
f_avg_rolling_win <- rollapply(
data=zoo(x),
width=10, # window width
FUN=function(w) mean(w),
# 'align' specifies whether the index of the result should be left-aligned
# or right-aligned or centered (default)
# compared to the rolling window of observations.
align="right",
# If 'partial=TRUE', then the subset of indexes
# that are in range are passed to FUN.
partial=TRUE)
## (1-2) moving max
f_max_rolling_win <- rollapply(
zoo(x),
10,
function(w) max(w),
align="right",
partial=TRUE)
plot(x, col="gray", lwd=1, type="l", main="Average and Max using Rolling Window")
lines(f_avg_rolling_win, col="blue", lwd=2, lty="dotted")
lines(f_max_rolling_win, col="red", lwd=2, lty="dashed")
legend("topleft",
c("Average with Rolling Windows", "Max with Rolling Windows"),
col = c("blue", "red"),
lty = c("dotted", "dashed"))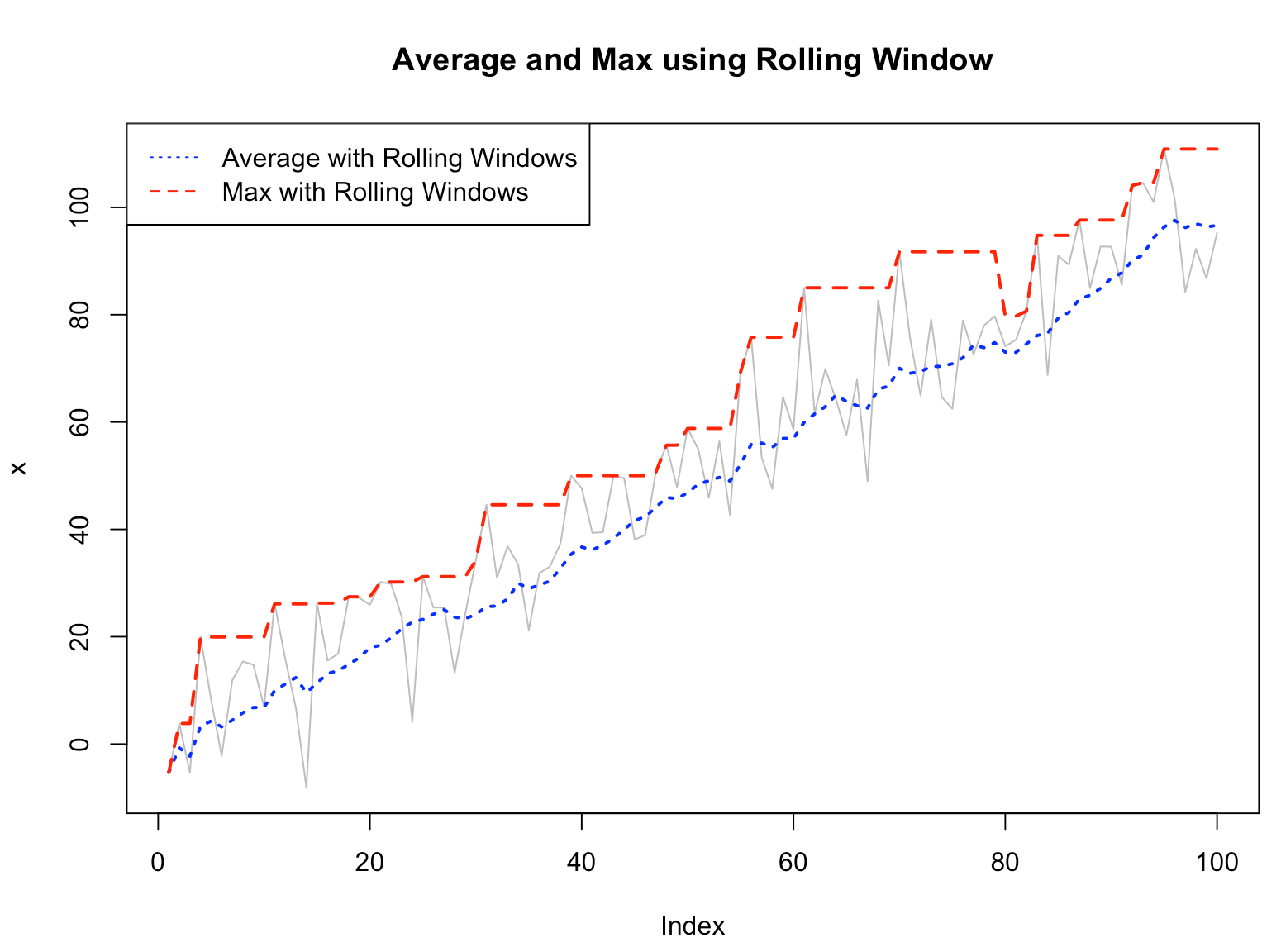
(2) Expanding Windows 를 사용해서 시계열 데이터의 누적 평균 구하기
(average of time series using expanding windows)
R 에서 zoo 패키지의 rollapply() 함수로 Expanding Windwos 를 사용하려면 width = seq_along(x) 를 지정해주면 누적으로 함수를 계산해줍니다.
아래 예에서는 누적으로 평균과 최대값을 계산해서 시각화 한건데요, 우상향 하는 추세가 있는 시계열이다보니 누적으로 평균을 구하면 시계열 초반의 낮은 값들까지 모두 포함이 되어서 누적평균 값이 최근 값들을 제대로 따라가지 못하고 있습니다.
반면, 누적으로 최대값을 계산한 값은 중간에 소폭 값이 줄어들더라도 계산 시점까지 누적으로 최대값을 계산하므로, 항상 우상향하는 누적 최대값을 보여주고 있습니다.
(위의 (1)번의 이동평균, 이동최대값과 (2) 누적평균, 누적최대값을 비교해서 보세요.)
# (2) Expanding Windows
## (2-1) cumulative average
f_avg_expanding_win <- rollapply(
data=zoo(x),
width=seq_along(x), # expanding windows
FUN=function(w) mean(w), # average
align="right",
partial=TRUE)
## (2-2) cumulative max
f_max_expanding_win <- rollapply(
zoo(x),
seq_along(x), # expanding windows
function(w) max(w), # max
align="right",
partial=TRUE)
## plotting
plot(x, col="gray", lwd=1, type="l", main="Average and Max using Expanding Window")
lines(f_avg_expanding_win, col="blue", lwd=2, lty="dotted")
lines(f_max_expanding_win, col="red", lwd=2, lty="dashed")
legend("topleft",
c("Average with Expanding Windows", "Max with Expanding Windows"),
col = c("blue", "red"),
lty = c("dotted", "dashed"))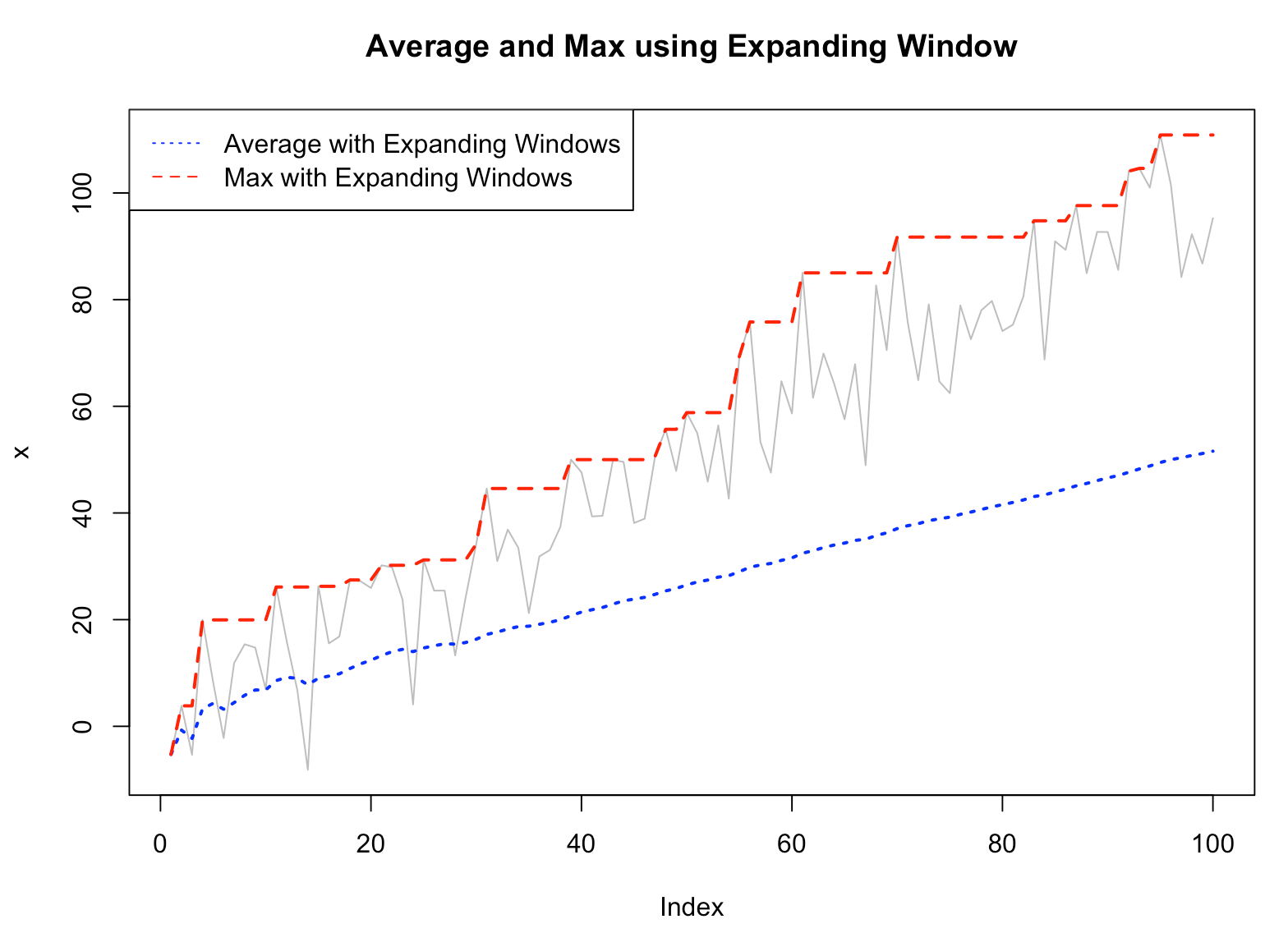
[ Reference ]
- R zoo's rollapply(): https://www.rdocumentation.org/packages/zoo/versions/1.8-9/topics/rollapply
이번 포스팅이 많은 도움이 되었기를 바랍니다.
행복한 데이터 과학자 되세요! :-)




