[LangChain] Chroma Vector DB를 사용해서 RAG (Retireval-Augmented Generation) 구현
Deep Learning (TF, Keras, PyTorch)/Natural Language Processing 2023. 12. 25. 18:45지난번 포스팅에서 RAG (Retrieval-Augmented Generation) 이란 무엇이고 LangChain으로 어떻게 구현하나에 대해서 소개하였습니다.
이번 포스팅에서는 LangChain으로 RAG (Retrieval-Augmented Generation)을 구현할 때
- Web 에서 문서를 가져와서 분할하고
- OpenAI의 Text Embedding 모델을 사용해서 Embeddings 으로 변환을 하고
- Chroma Vector DB 에 저장, 검색하여
- ChatGPT 모델로 질문에 답변을 생성
하는 방법을 소개하겠습니다.
1. 시장 내 Vector DB 의 구분
먼저, 텍스트를 벡터 임베딩으로 변환하여 저장하고 의미론적 검색을 할 때 사용하는 Vector DB에 대해서 잠깐 살펴보겠습니다.
시장의 Vector DB는 (a) Database 용도가 Vector DB 전용인지 아니면 Vector search를 지원하는 일반 DB인지 여부, (b) Open source 인지 상업용인지 여부에 따라서 아래 그림처럼 4/4분위로 구분할 수 있습니다. 일반 DB가 최근 매우 빠른 속도로 Vector DB 기능 (벡터 데이터 유형 지원, 저장, 인덱싱, 검색 등) 을 지원하기 시작했습니다. 따라서 일반 DB가 Vector DB 기능을 지원하는 것은 시간 문제일것 같습니다.
이번 포스팅에서는 Vector DB 전용 (dedicated vector database) 이면서 오픈소스인 Croma DB를 사용해서 RAG 를 구현해 보겠습니다.
[ Vector DB Landscape ]

* 이미지 출처: https://blog.det.life/why-you-shouldnt-invest-in-vector-databases-c0cd3f59d23c
2. Croma Vector DB와 LangChain을 사용한 RAG(Retrieval-Augmented Generation) 구현
Chroma는 오픈소스 임베딩 데이터베이스 (Open-source Vector Database)입니다. Chroma는 지식, 사실, 기술을 LLM에 쉽게 플러그인 할 수 있게 함으로써 LLM 앱을 구축하는 것을 쉽게 해줍니다. Chroma DB 를 사용해서 텍스트 문서를 쉽게 관리하고, 텍스트를 임베딩으로 변환하며, 유사성 검색을 할 수 있습니다.
Chroma DB의 주요 기능으로는 다음과 같은 것이 있습니다.
- 풍부한 기능: 쿼리, 필터링, 밀도 추정, 그 외 여러 기능들
- LangChain (파이썬 및 자바스크립트), LlamaIndex 지원 가능
- 파이썬 노트북에서 실행되는 것과 동일한 API가 프로덕션 클러스터로 확장
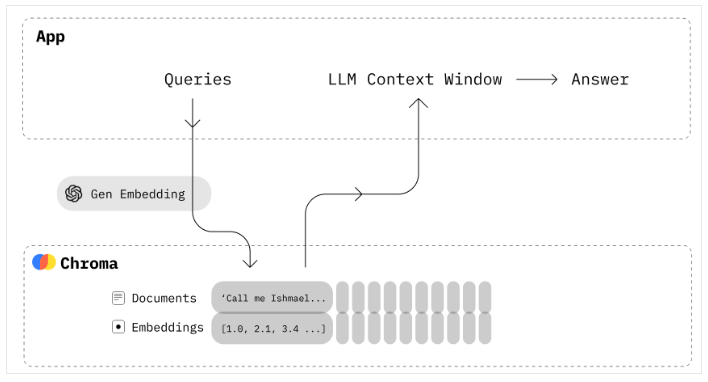
* 이미지 출처: https://docs.trychroma.com/
먼저 openai, langchain, langchainhub, tiktoken, chromadb 모듈을 터미널에서 pip install을 사용해서 설치합니다.
!pip install --q openai langchain langchainhub tiktoken chromadb
(1) WebBaseLoader() 를 이용해서 웹사이트 문서 로딩하기
# Load documents from web
from langchain.document_loaders import WebBaseLoader
web_loader = WebBaseLoader([
"https://python.langchain.com/docs/get_started/introduction", # LangChain Introduction
"https://python.langchain.com/docs/modules/data_connection/" # LangChain Retrieval
]
)
data = web_loader.load()
(2) LangChain의 RecursiveCharacterTextSplitter()를 사용해서 문서를 Chunk 로 분할하기
# Split documents into chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 500,
chunk_overlap = 0
)
all_splits = text_splitter.split_documents(data)
all_splits[0]
# Document(page_content='Introduction | \uf8ffü¶úÔ∏è\uf8ffüîó Langchain',
# metadata={'source': 'https://python.langchain.com/docs/get_started/introduction',
# 'title': 'Introduction | \uf8ffü¶úÔ∏è\uf8ffüîó Langchain',
# 'description': 'LangChain is a framework for developing applications
# powered by language models. It enables applications that:',
# 'language': 'en'})
(3) OpenAIEmbeddings()를 사용해서 텍스트를 임베팅으로 변환하여 Chroma Vector DB에 저장하기
# Transform into Text Embeddings and Store at Chroma Vector DB
import os
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
os.environ["OPENAI_API_KEY"] = "sk-xxxxx...."
vectorstore = Chroma.from_documents(
documents=all_splits,
embedding=OpenAIEmbeddings()
)
(4) LangChainHub에서 RAG Prompt 가져오기
필요에 따라서는 아래 RAG Prompt template을 참고해서 일부 수정해서 사용해도 됩니다.
# RAG prompt
from langchain import hub
prompt = hub.pull("rlm/rag-prompt")
print(prompt)
# ChatPromptTemplate(input_variables=['context', 'question'],
# messages=[HumanMessagePromptTemplate(prompt=PromptTemplate(
# input_variables=['context', 'question'],
# template=
# "You are an assistant for question-answering tasks.
# Use the following pieces of retrieved context to answer the question.
# If you don't know the answer, just say that you don't know.
# Use three sentences maximum and keep the answer concise.
# \nQuestion: {question}
# \nContext: {context}
# \nAnswer:"))
# ])
(5) ChatOpenAI() 모델로 언어 모델 설정하기
model_name="gpt-4"로 설정해주었으며, temperature=0 으로 해서 보수적이고 일관적인 답변이 생성되도록 하였습니다.
# LLM model
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
model = ChatOpenAI(model_name="gpt-4", temperature=0)
(6) RetrievalQA() 을 사용해서 LLM Model, Retriever, Prompt 를 하나의 객체로 묶기
# Retrieval QA
qa_chain = RetrievalQA.from_chain_type(
llm=model,
retriever=vectorstore.as_retriever(),
chain_type_kwargs={"prompt": prompt}
)
question ="What is a LangChain?"
result = qa_chain({"query": question})
result["result"]
# LangChain is a framework for developing applications powered by language models.
# It enables applications to be context-aware and reason based on provided context.
# The LangChain framework includes composable tools and integrations for working with
# language models, off-the-shelf chains for higher-level tasks,
# and allows for customization of existing chains and building new ones.
사용자의 질문과 관련이 있는 웹사이트 문서를 검색(Retrieval)하여 이를 Context 정보로 참조해서(Augmented) 답변을 잘 생성(Generation)하고 있네요.
question ="What is Retrieval in LangChain?"
result = qa_chain({"query": question})
result["result"]
# Retrieval in LangChain is a part of the Retrieval Augmented Generation (RAG) process
# where external data is fetched and passed to the Language Model during the generation step.
# LangChain supports various retrieval algorithms and provides all the necessary components
# for RAG applications.
# It also allows for easy swapping between vector stores and supports simple semantic search
# along with a collection of algorithms to enhance performance.
이번 포스팅이 많은 도움이 되었기를 바랍니다.
행복한 데이터 과학자 되세요! :-)








