[LangChain] RunnableParallel() 로 독립적인 Chain들 병렬처리 하기 (Running independent processes in parallel using RunnableParallel)
Deep Learning (TF, Keras, PyTorch)/Natural Language Processing 2023. 12. 20. 18:12지난번 포스팅에서는 LangChain을 사용해서 RAG (Retrieval-Agumented Generation) 을 구현해보았습니다.
그때 RunnableParallel() 메소드를 사용해서 사용자 질문을 RunnablePassThrough()와 Retriever 에 동시에 병렬로 처리하는 방법을 한번 소개한 적이 있습니다.
이번 포스팅에서는 LangChain의 RunnableParallel() 을 사용해서 독립적인 다수의 Chain들을 병렬로 처리하는 방법을 소개하겠습니다.
먼저, langchain, openai 모듈이 설치되어 있지 않다면 터미널에서 pip install 을 사용해서 먼저 설치하시기 바랍니다. (만약 Jupyter Notebook을 사용중이라면, 셀의 제일 앞부분에 '!' 를 추가해주세요)
! pip install langchain openai
예시에서 진행한 과업은
- 사용자로 부터 topic 을 인풋으로 받아서
- ChatOpenAI 모델을 사용해서 (1) Joke, (2) Poem, (3) Question 을 생성
하기 입니다.
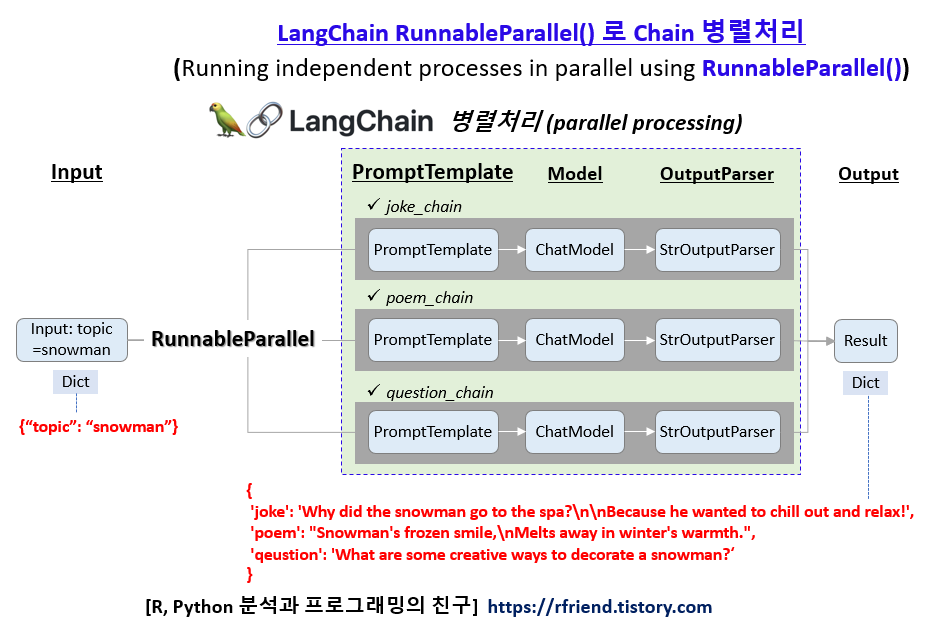
이들 3개의 각 과업에 '|' 을 사용해서 PomtptTemplate + ChatModel + OutputParser 를 chaining 했습니다. 이들 3개 과업의 chain 들은 동일한 topic을 인풋으로 받아서 서로 독립적으로 처리가 가능합니다.
이처럼 독립적으로 수행 가능한 3개의 chain을 'RunnableParallel()' 을 사용해서 병렬로 처리합니다. 그리고 아웃풋은 Dictionary 형태로 chian 의 이름과 매핑이 되어서 생성한 답변을 반환합니다. (아래 제일 마지막 줄의 {'joke': xxx, 'poem': xxx, 'question': xxxx} 결과 참조)
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableParallel
## define PromptTemplates
joke_template = ChatPromptTemplate.from_template("tell me a joke about {topic}")
poem_template = ChatPromptTemplate.from_template("write a 2-line poem about {topic}")
question_template = ChatPromptTemplate.from_template("make a question about {topic}")
## define a ChatModel
#openai_api_key = "sk-xxxxxx..." # set with your API key
model = ChatOpenAI(openai_api_key=OPENAI_API_KEY)
## define a OutputParser
parser = StrOutputParser()
## Chaining Prompt + ChatModel + OutputParser
joke_chain = joke_template | model | parser
poem_chain = poem_template | model | parser
question_chain = question_template | model | parser
## execute multiple runnables in parallel using RunnableParallel()
map_chain = RunnableParallel(
joke=joke_chain,
poem=poem_chain,
qeustion=question_chain
)
# Run all chains
map_chain.invoke({"topic": "snowman"})
# {'joke': 'Why did the snowman go to the spa?\n\nBecause he wanted to chill out and relax!',
# 'poem': "Snowman's frozen smile,\nMelts away in winter's warmth.",
# 'qeustion': 'What are some creative ways to decorate a snowman?'}
RunnableParallel()을 사용하기 전에 각 과업의 chain을 개별적으로 수행했을 때의 소요 시간과, RunnableParallel()을 사용해서 3개의 chain을 동시에 병렬로 처리했을 때의 소요 시간을 측정해서 비교해보았습니다. 그랬더니, RunnableParallel()로 병렬처리했을 때의 시간과 개별로 처리했을 때의 시간이 별 차이가 없음을 알 수 있습니다!
[ 'joke' chain 단독 수행 소요 시간: 11s +- 112ms ]
%%timeit
joke_chain.invoke({"topic":"snowman"})
# 11 s ± 112 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
[ 'poem' chain 단독 수행 소요 시간: 891 ms +- 197ms ]
%%timeit
poem_chain.invoke({"topic": "snowman"})
# 891 ms ± 197 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
[ 'question' chain 단독 수행 소요 시간: 751ms +- 128ms ]
%%timeit
question_chain.invoke({"topic": "snowman"})
# 751 ms ± 128 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
[ 'map' chain 으로 3개의 모든 chain 병렬 처리 소요 시간: 922ms +- 101ms]
%%timeit
map_chain.invoke({"topic": "snowman"})
# 922 ms ± 101 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
이번 포스팅이 많은 도움이 되었기를 바랍니다.
행복한 데이터 과학자 되세요! :-)