[Python numpy] 배열의 원소 값을 Dict 의 (key, value)를 매핑해서 변환하기 (transforming numpy array elements by mapping dict(key, value))
Python 분석과 프로그래밍/Python 데이터 전처리 2021. 2. 15. 19:35이번 포스팅에서는 Python numpy 의 배열의 원소 값을 사전(dictionary)의 {키: 값} 쌍 ({key: value} pair) 을 이용해서, 배열의 원소 값과 사전의 키를 매핑하여 사전의 값으로 배열의 원소값을 변환하는 방법을 소개하겠습니다.
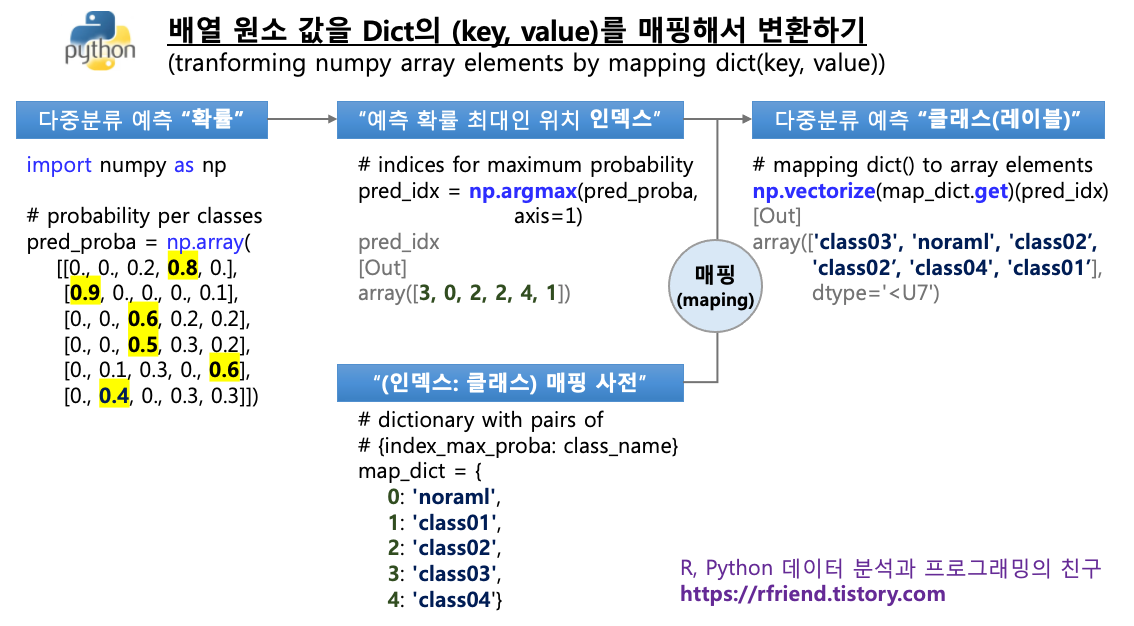
아래의 예에서는 다중분류 (multi-class classification) 기계학습 모델로 부터 각 관측치가 5개 classes 별 속할 확률을 배열로 반환받은 상황을 가정하여 만들어보았습니다.
(1) 다중분류 확률 배열로 부터 최대값의 위치 인덱스 가져오기
(2) np.vectorize() 와 dict.get() 을 사용해서 최대값 위치 인덱스와 분류 레이블을 매핑하기
(3) for loop 과 dict.get() 을 사용해서 최대값 위치 인덱스와 분류 레이블을 매핑하기
(1) 다중분류 확률 배열로 부터 최대값의 위치 인덱스 가져오기
먼저, 5개 class를 가지는 다중분류 문제에서 5개 class 별 속할 확률을 기계학습 분류 모델로 부터 아래의 'pred_proba' 라는 이름의 배열로 얻었다고 가정해보겠습니다.
import numpy as np
## probability for each classes
pred_proba = np.array([[0., 0., 0.2, 0.8, 0.],
[0.9, 0., 0., 0., 0.1],
[0., 0., 0.6, 0.2, 0.2],
[0., 0., 0.5, 0.3, 0.2],
[0., 0.1, 0.3, 0., 0.6],
[0., 0.4, 0., 0.3, 0.3]])
pred_proba
[Out]
array([[0. , 0. , 0.2, 0.8, 0. ],
[0.9, 0. , 0. , 0. , 0.1],
[0. , 0. , 0.6, 0.2, 0.2],
[0. , 0. , 0.5, 0.3, 0.2],
[0. , 0.1, 0.3, 0. , 0.6],
[0. , 0.4, 0. , 0.3, 0.3]])
이들 확률값 배열로 부터 하나의 예측값을 구하기 위해 이들 5개 각 class별 확률 중에서 가장 큰 값을 가지는 위치 (indices of maximum value) 의 class 를 모델이 예측한 class 라고 정의해보겠습니다.
np.argmax(pred_proba, axis=1) 은 배열 내의 각 관측치 별 (axis = 1) 로 가장 큰 확률값의 위치의 인덱스를 반환합니다. 가령, 위의 pred_proba 의 첫번째 관측치의 5개 class 별 속할 확률은 [0., 0., 0.2, 0.8, 0.] 의 배열로서, 확률 0.8 이 가장 큰 값이므로 위치 인덱스 '3'을 반환하였습니다.
## positional index for maximum probability
pred_idx = np.argmax(pred_proba, axis=1)
pred_idx
[Out]
array([3, 0, 2, 2, 4, 1])
(2) np.vectorize() 와 dict.get() 을 사용해서 최대값 위치 인덱스와 분류 레이블을 매핑하기
위의 (1)번에서 구한 확률 최대값의 위치 인덱스 가지고, 이번에는 아래의 'class_map_dict'와 같이 {키: 값} 쌍 사전의 '키(key)'를 기준으로 매핑을 해서, 다중분류 모델의 예측값을 'class 이름'으로 변환을 해보겠습니다.
## dictionary with pairs of {index_max_proba: class_name}
class_map_dict = {
0: 'noraml',
1: 'class01',
2: 'class02',
3: 'class03',
4: 'class04'
}
class_map_dict
[Out]
{0: 'noraml', 1: 'class01', 2: 'class02', 3: 'class03', 4: 'class04'}
이때 dict.get(key) 를 유용하게 사용할 수 있습니다. dict.get(key) 메소드는 사전(dict)의 키에 쌍으로 대응하는 값을 반환해줍니다. 따라서 바로 위에서 정의해준 'class_map_dict'의 키 값을 넣어주면, 각 키에 해당하는 'normal'~'class04' 의 사전 값을 반환해줍니다.
## get() returns the value for the specified key if key is in dict.
class_map_dict.get(pred_idx[0])
[Out]
'class03'
class_map_dict.get(0)
[Out]
'noraml'
사전의 (키: 값)을 매핑하려는 배열 내 원소가 많을 경우, np.vectorize() 메소드를 이용하면 매우 편리하고 또 빠르게 사전의 (키: 값)을 매핑을 해서 배열의 값을 변환할 수 있습니다. 아래 예에서는 'class_map_dict' 의 (키: 값) 사전을 사용해서 'pred_idx'의 확률 최대값 위치 인덱스 배열을 'pred_cls' 의 예측한 클래스(레이블) 이름('normal'~'class04')으로 변환해주었습니다.
np.vectorize() 는 numpy의 broadcasting 규칙을 사용해서 매핑을 하므로 코드가 깔끔하고, for loop을 사용하지 않으므로 원소가 많은 배열을 처리해야 할 경우 빠릅니다.
## vectorization of dict.get(array_idx) for all elements of array
pred_cls = np.vectorize(class_map_dict.get)(pred_idx)
pred_cls
[Out]
array(['class03', 'noraml', 'class02', 'class02', 'class04', 'class01'],
dtype='<U7')
* np.vectorize() reference: numpy.org/doc/stable/reference/generated/numpy.vectorize.html
(3) for loop 과 dict.get() 을 사용해서 최대값 위치 인덱스와 분류 레이블을 매핑하기
만약 위의 (2)번 처럼 np.vectorize() 메소드를 사용하지 않는다면, 아래처럼 for loop 사용해서 확률 최대값 위치 인덱스의 개수 만큼 순환 반복을 하면서 dict.get() 함수를 적용해주어야 합니다. 위의 (2)번 대비 코드도 길고, 또 대상 배열이 클 경우 시간도 더 오래 걸리므로 np.vectorize() 사용을 권합니다.
## manually using for loop
pred_cls_mat = np.empty(pred_idx.shape, dtype='object')
for i in range(len(pred_idx)):
pred_cls_mat[i] = class_map_dict.get(pred_idx[i])
pred_cls_mat
[Out]
array(['class03', 'noraml', 'class02', 'class02', 'class04', 'class01'],
dtype=object)
이번 포스팅이 많은 도움이 되었기를 바랍니다.
행복한 데이터 과학자 되세요! :-)




