[Python numpy] 배열로 순서대로 키를 추가해서 사전 만들기 (making a Dictionary from numpy array with key using a counter)
Python 분석과 프로그래밍/Python 데이터 전처리 2021. 2. 28. 17:29이전 포스팅에서는 numpy 배열의 원소 값을 사전(dictionary)의 (Key, Value)를 매핑해서 변환하는 방법을 소개하였습니다. (rfriend.tistory.com/620)
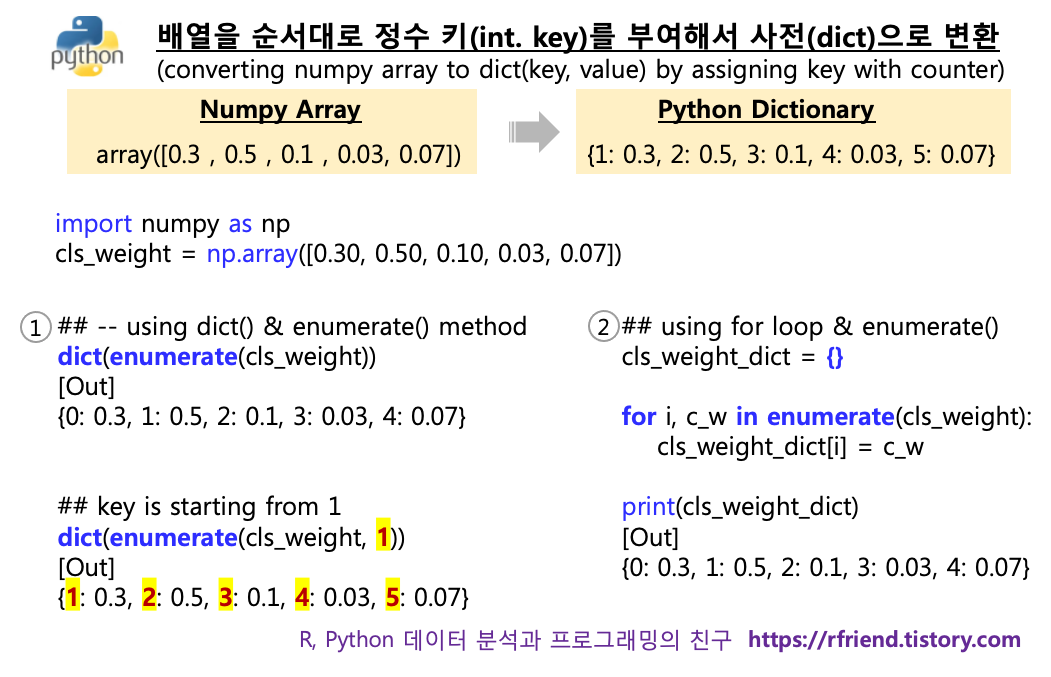
이번 포스팅에서는 Python numpy 의 array 배열의 순서대로 정수를 사전의 키(Key)로 하고, 배열 값을 사전의 값(Value)으로 하는 Python 사전(dictionary) 으로 변환하는 몇 가지 방법을 소개하겠습니다.
(1) dict() 와 enumerate() 함수를 이용해 배열로 부터 사전 만들기
(2) for loop 과 enumerate() 함수를 이용해 배열로 부터 사전 만들기
(1) dict() 와 enumerate() 함수를 이용해 배열로 부터 사전 만들기
먼저, numpy 라이브러리를 불러오고, 예제로 사용할 (5, 0) shape 의 numpy array 배열을 하나 만들어보겠습니다.
import numpy as np
cls_weight = np.array([0.30, 0.50, 0.10, 0.03, 0.07])
cls_weight
[Out]
array([0.3 , 0.5 , 0.1 , 0.03, 0.07])
cls_weight.shape
[Out]
(5,)
위의 'cls_weight' 배열을 사전(dictionary)으로 변환해보겠습니다. 사전(dict) 키(Key)가 '0' 부터 시작하고, 배열의 순서대로 사전의 키가 하나씩 증가하며, 배열의 순서대로 사전에 값을 할당하여 보겠습니다. dict() 함수는 객체를 '키(Key) : 값(Value)' 의 쌍을 가지는 사전형 자료구조를 만들어줍니다.
## converting numpy array to dictionary,
## dict key is starting from 0
cls_weight_dict_from_0 = dict(enumerate(cls_weight))
cls_weight_dict_from_0
[Out]
{0: 0.3, 1: 0.5, 2: 0.1, 3: 0.03, 4: 0.07}
이때 dict() 안의 enumerate() 메소드는 객체를 순환할 때 회수를 세어주는 counter 를 같이 생성해서 enumerate 객체를 반환합니다. for loop 으로 enumerate 객체를 순환하면서 counter 와 배열 내 값을 차례대로 출력을 해보면 아래와 같습니다.
## enumerate() method adds a counter to an iterable
## and returns it in a form of enumerate object
for i, j in enumerate(cls_weight):
print(i, ':', j)
[Out]
0 : 0.3
1 : 0.5
2 : 0.1
3 : 0.03
4 : 0.07
경우에 따라서는 배열의 값으로 사전을 만들었을 때, 사전의 키 값이 '0'이 아니라 '1'이나 혹은 다른 숫자로 부터 시작하는 것을 원할 수도 있습니다. 이럴 경우 enumerate(iterable_object, 1) 처럼 원하는 숫자(아래 예에서는 '1')를 추가해주면 그 값이 더해져서 counter 가 생성이 됩니다.
## converting numpy array to dictionary,
## dict key is starting from 1
cls_weight_dict_from_1 = dict(enumerate(cls_weight, 1))
cls_weight_dict_from_1
[Out]
{1: 0.3, 2: 0.5, 3: 0.1, 4: 0.03, 5: 0.07}
만약 사전(dictionary)으로 변환하려고 하는 numpy array의 axis 1의 축이 있다면 flatten() 메소드를 사용해서 axis 0 만 있는 배열로 먼저 평평하게 펴준 (axis 1 축을 없앰) 후에 위의 dict(enumerate()) 를 똑같이 사용해주면 됩니다. 아래 예는 shape (5, 1) 의 배열을 flatten() 메소드를 써서 shape (5, 0) 으로 바꿔준 후에 dict(enumerate()) 로 배열을 사전으로 변환해주었습니다.
## array with axis1
cls_weight_2 = np.array([[0.30], [0.50], [0.10], [0.03], [0.07]])
cls_weight_2
[Out]
array([[0.3 ],
[0.5 ],
[0.1 ],
[0.03],
[0.07]])
cls_weight_2.shape
[Out]
(5, 1)
## use flatten() method to convert shape (5, 1) to (5, 0)
cls_weight_dict_2 = dict(enumerate(cls_weight_2.flatten()))
print(cls_weight_dict_2)
[Out]
{0: 0.3, 1: 0.5, 2: 0.1, 3: 0.03, 4: 0.07}
(2) for loop 과 enumerate() 함수를 이용해 배열로 부터 사전 만들기
이번에는 for loop 과 enumerate() 메소드를 같이 이용하는 방법입니다. 위의 (1) 번 대비 좀 복잡한 느낌이 있기는 하지만, (1) 번 대비 (2) 방법은 for loop 안의 코드 블럭에 좀더 자유롭게 원하는 복잡한 로직을 녹여서 사전(dictionary)을 구성할 수 있다는 장점이 있습니다.
아래 예에서는 (a) 먼저 cls_weight_dict_3 = {} 로 비어있는 사전을 만들어 놓고, (b) for loop 으로 순환 반복을 하면서 enumerate(cls_weight) 가 반환해주는 (counter, 배열값) 로 부터 counter 정수 숫자를 받아서 cls_weight_dict_3 의 키(Key) 로 할당해주고, 배열의 값을 사전의 해당 키에 할당해주는 방식입니다. 사전의 키에 값 할당(assinging Value to dict by mapping Key)은 Dict[Key] = Value 구문으로 해줍니다.
cls_weight = np.array([0.30, 0.50, 0.10, 0.03, 0.07])
cls_weight
[Out]
array([0.3 , 0.5 , 0.1 , 0.03, 0.07])
## Converting a numpy array to a dictionary
## Dict key is starting from 0
cls_weight_dict_3 = {}
for i, c_w in enumerate(cls_weight):
cls_weight_dict_3[i] = c_w
print(cls_weight_dict_3)
[Out]
{0: 0.3, 1: 0.5, 2: 0.1, 3: 0.03, 4: 0.07}
사전의 키를 '0' 이 아니라 '1'부터 시작하게 하려면 enumerate()의 counter가 0부터 시작하므로, counter를 사전의 키에 할당할 때 'counter+1' 을 해주면 됩니다.
## converting a numpy array to a dictionary using for loop
## dict key is strating from 1
## null dict
cls_weight_dict_3_from_1 = {}
## assigning values by keys + 1
for i, c_w in enumerate(cls_weight):
cls_weight_dict_3_from_1[i+1] = c_w
print(cls_weight_dict_3_from_1)
[Out]
{1: 0.3, 2: 0.5, 3: 0.1, 4: 0.03, 5: 0.07}
이번 포스팅이 많은 도움이 되었기를 바랍니다.
행복한 데이터 과학자 되세요! :-)




