[Python numpy] 1차원 배열 내 고유한 원소 집합과 개수 구하고 정렬하기 (unique elements, counts in 1D array, sorting dict)
Python 분석과 프로그래밍/Python 데이터 전처리 2021. 2. 21. 17:45이번 포스팅에서는 1차원 배열 내 고유한 원소 집합 (a set with unique elements) 을 찾고, 더 나아가서 고유한 원소별 개수(counts per unique elements)도 세어보고, 원소 개수를 기준으로 정렬(sorting)도 해보는 여러가지 방법을 소개하겠습니다.
(1) numpy 1D 배열 안에서 고유한 원소 집합 찾기
(finding a set with unique elements in 1D numpy array)
(2) numpy 1D 배열 안에서 고유한 원소 별로 개수 구하기
(counts per unique elements in 1D numpy array)
(3) numpy 1D 배열 안에서 고유한 원소(key) 별 개수(value)를 사전형으로 만들기
(making a dictionary with unique sets and counts of 1D numpy array)
(4) numpy 1D 배열의 고유한 원소(key) 별 개수(value)의 사전을 정렬하기
(sorting a dictionary with unique sets and counts of 1D numpy array)
(5) numpy 1D 배열을 pandas Series 로 변환해서 고유한 원소 별 개수 구하고 정렬하기
(converting 1D array to pandas Series, and value_counts(), sort_values())
(6) numpy 1D 배열을 pandas DataFrame으로 변환해 고유 원소별 개수 구하고 정렬하기
(converting 1D array to pandas DataFrame, and value_counts(), sort_values())
먼저, 예제로 사용할 간단한 numpy 1D 배열을 만들어보겠습니다.
## simple 1D numpy array
import numpy as np
arr = np.array(['a', 'c', 'c', 'b', 'a',
'b', 'b', 'c', 'a', 'c',
'b', 'a', 'a', 'a', 'c'])
arr
[Out] array(['a', 'c', 'c', 'b', 'a', 'b', 'b', 'c', 'a', 'c',
'b', 'a', 'a', 'a', 'c'], dtype='<U1')
(1) numpy 1D 배열 안에서 고유한 원소 집합 찾기
(finding a set with unique elements in 1D numpy array)
np.unique() 메소드를 사용하면 numpy 배열 내 고유한 원소(unique elements)의 집합을 찾을 수 있습니다.
## np.unique(): Find the unique elements of an array
np.unique(arr)
[Out]
array(['a', 'b', 'c'], dtype='<U1')
더 나아가서, return_inverse=True 매개변수를 설정해주면, 아래의 예처럼 numpy 배열 내 고유한 원소의 집합 배열과 함께 '고유한 원소 집합 배열의 indices 의 배열' 을 추가로 반환해줍니다.
따라서 이 기능을 이용하면 array(['a', 'c', 'c', 'b', 'a', 'b', 'b', 'c', 'a', 'c', 'b', 'a', 'a', 'a', 'c']) 를 ==> array([0, 2, 2, 1, 0, 1, 1, 2, 0, 2, 1, 0, 0, 0, 2]) 로 쉽게 변환할 수 있습니다.
## return_inverse=True: If True, also return the indices of the unique array
np.unique(arr,
return_inverse=True)
[Out]
(array(['a', 'b', 'c'], dtype='<U1'),
array([0, 2, 2, 1, 0, 1, 1, 2, 0, 2, 1, 0, 0, 0, 2]))
(2) numpy 1D 배열 안에서 고유한 원소 별로 개수 구하기
(counts per unique elements in 1D numpy array)
위의 (1)번에서 np.unique() 로 numpy 배열 내 고유한 원소의 집합을 찾았다면, return_counts = True 매개변수를 설정해주면 각 고유한 원소별로 개수를 구해서 배열로 반환할 수 있습니다.
## return_counts: If True, also return the number of times each unique item appears in ar.
np.unique(arr,
return_counts = True)
[Out]
(array(['a', 'b', 'c'], dtype='<U1'), array([6, 4, 5]))
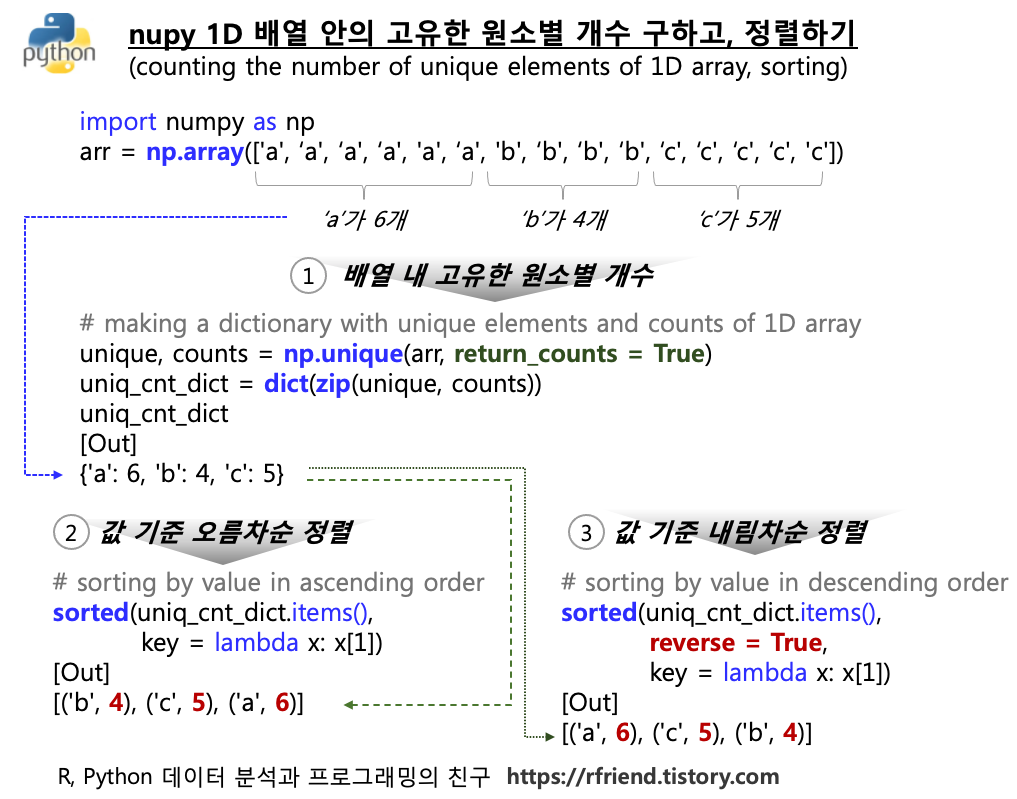
(3) numpy 1D 배열 안에서 고유한 원소(key) 별 개수(value)를 사전형으로 만들기
(making a dictionary with unique sets and counts of 1D numpy array)
위의 (2)번에서 각 고유한 원소별 개수를 구해봤는데요, 이를 파이썬의 키:값 쌍 (key: value pair) 형태의 사전(dictionary) 객체로 만들어보겠습니다.
먼저 np.unique(arr, return_counts = True) 의 결과를 unique, counts 라는 이름의 array로 할당을 받고, 이를 zip(unique, counts) 으로 쌍(pair)을 만들어준 다음에, dict() 를 사용해서 사전형으로 변환해주었습니다.
## making a dictionary with unique elements and counts of 1D array
unique, counts = np.unique(arr, return_counts = True)
uniq_cnt_dict = dict(zip(unique, counts))
uniq_cnt_dict
[Out]
{'a': 6, 'b': 4, 'c': 5}
(4) numpy 1D 배열의 고유한 원소(key) 별 개수(value)의 사전을 정렬하기
(sorting a dictionary with unique sets and counts of 1D numpy array)
위의 (3)번까지 잘 진행을 하셨다면 이제 (unique : counts) 쌍의 사전을 'counts' 의 값을 기준으로 오름차순 정렬(sorting a dict by value in ascending order) 또는 내림차순 정렬 (sorting a dict by value in descending order) 하고 싶은 마음이 생길 수 있는데요, 이럴 경우 sorted() 메소드를 사용하면 되겠습니다. (pytho dictionary 정렬 참조: rfriend.tistory.com/473)
## sorting a dictionary by value in ascending order
## -- reference: https://rfriend.tistory.com/473
sorted(uniq_cnt_dict.items(),
key = lambda x: x[1])
[Out]
[('b', 4), ('c', 5), ('a', 6)]
## sorting a dictionary by value in descending order
sorted(uniq_cnt_dict.items(),
reverse = True,
key = lambda x: x[1])
[Out]
[('a', 6), ('c', 5), ('b', 4)]
(5) numpy 1D 배열을 pandas Series 로 변환해 고유한 원소별 개수 구하고 정렬하기
(converting 1D array to pandas Series, and value_counts(), sort_values())
pandas 의 Series 나 DataFrame으로 변환해서 데이터 분석 하는 것이 더 익숙하거나 편리한 상황에서는 pandas.Series(array) 나 pandas.DataFrame(array) 로 변환을 해서, value_count() 메소드로 원소의 개수를 세거나, sort_values() 메소드로 값을 기준으로 정렬을 할 수 있습니다.
import pandas as pd
## converting an array to pandas Series
arr_s = pd.Series(arr)
arr_s
[Out]
0 a
1 c
2 c
3 b
4 a
5 b
6 b
7 c
8 a
9 c
10 b
11 a
12 a
13 a
14 c
dtype: object
## counting values by unique elements of pandas Series
arr_s.value_counts()
[Out]
a 6
c 5
b 4
dtype: int64
## sorting by values in ascending order of pandas Series
arr_s.value_counts().sort_values(ascending=True)
[Out]
b 4
c 5
a 6
dtype: int64
(6) numpy 1D 배열을 pandas DataFrame으로 변환해 고유한 원소별 개수 구하고 정렬하기
(converting 1D array to pandas DataFrame, and value_counts(), sort_values())
만약 pandas Series 내 고유한 원소별 개수를 구한 결과를 개수의 오름차순으로 정렬을 하고 싶다면 sort_values(ascending = True) 를 설정해주면 됩니다. (내림차순이 기본 설정, default to descending order)
import pandas as pd
## converting an array to pandas DataFrame
arr_df = pd.DataFrame(arr, columns=['x1'])
arr_df
[Out]
x1
0 a
1 c
2 c
3 b
4 a
5 b
6 b
7 c
8 a
9 c
10 b
11 a
12 a
13 a
14 c
## counting the number of unique elements in Series
arr_df['x1'].value_counts()
[Out]
a 6
c 5
b 4
Name: x1, dtype: int64
## # sorting by the counts of unique elements in ascending order
arr_df['x1'].value_counts().sort_values(ascending=True)
[Out]
b 4
c 5
a 6
Name: x1, dtype: int64
이번 포스팅이 많은 도움이 되었기를 바랍니다.
행복한 데이터 과학자 되세요! :-)




