이번 포스팅에서는 Python을 사용해서 파워포인트와 PDF 파일에서 텍스트를 추출하는 방법을 소개하겠습니다.
(1) 파워포인트 파일에서 텍스트 추출하기 (Extracting text from a PowerPoint file)
(2) PDF 파일에서 텍스트 추출하기 (Extracting text from a PDF file)
예제로 사용할 파워포인트와 PDF 파일 첨부합니다.
* 예제 파워포인트 파일: "서울관광명소.pptx"
* 예제 PDF 파일: "서울관광명소.pdf"
예제로 사용하는 "서울관광명소.pptx" 파일은 아래와 같이 텍스트로 구성되어 있습니다.
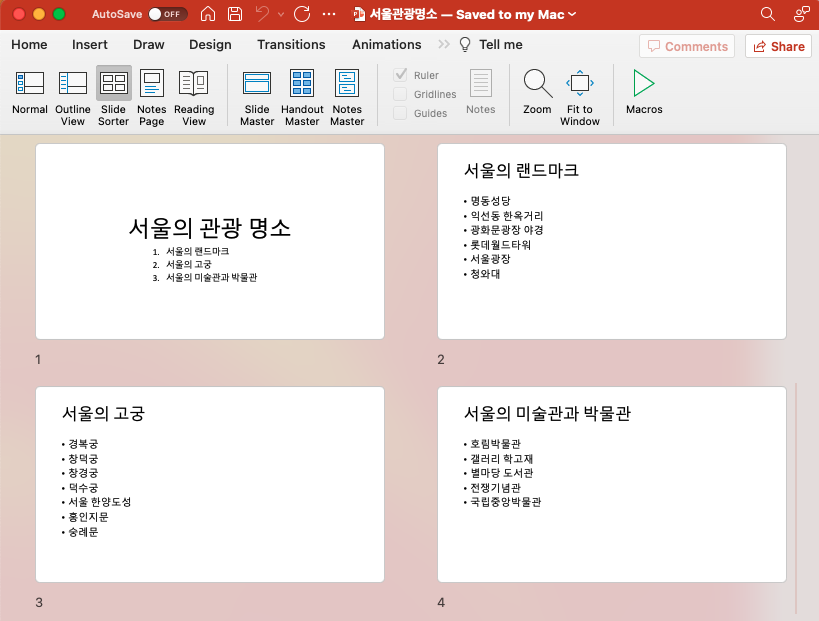
(1) 파워포인트 파일에서 텍스트 추출하기 (Extracting text from a PowerPoint file)
Python으로 파워포인트에 파일에서 텍스트를 추출하기 위해서 먼저 테미널에서 "python-pptx" 모듈을 설치합니다.
% python -m pip install python-pptx
파워포인트 파일이 저장되어 있는 경로와 파일 이름을 설정해주고, python-pptx 모듈을 사용해서 파워포인트 파일로 부터 텍스트를 추출해보겠습니다.
이때 가독성을 높이기 위해서 각 슬라이드의 제목(title)을 Key 로 하고, 각 슬라이드의 본문 내용을 Value 로 하는 사전형(Dictionary) 형태로 추출한 텍스트를 저장해보겠습니다.
## setting directory and file names
base_dir = "/Users/lhongdon/Documents/" # set with yours
ppt_nm = "서울관광명소.pptx"
pdf_nm = "서울관광명소.pdf"
ppt_path = base_dir + ppt_nm
pdf_path = base_dir + pdf_nm
print(ppt_path)
print(pdf_path)
# /Users/lhongdon/Documents/서울관광명소.pptx
# /Users/lhongdon/Documents/서울관광명소.pdf
## (1) extracting text from a PowerPoint file
from pptx import Presentation
prs = Presentation(ppt_path)
# text_runs will be populated with a list of strings,
# one for each text run in presentation
text_runs = {}
for slide in prs.slides:
text_run = []
for shape in slide.shapes:
if not shape.has_text_frame:
continue
for paragraph in shape.text_frame.paragraphs:
for run in paragraph.runs:
text_run.append(run.text)
text_runs[text_run[0]] = text_run[1:]
print(text_runs)
# {'서울의 관광 명소': ['서울의 랜드마크', '서울의 고궁', '서울의 미술관과 박물관'],
# '서울의 랜드마크': ['명동성당', '익선동 한옥거리', '광화문광장 야경', '롯데월드타워', '서울광장', '청와대'],
# '서울의 고궁': ['경복궁', '창덕궁', '창경궁', '덕수궁', '서울 한양도성', '홍인지문', '숭례문'],
# '서울의 미술관과 박물관': ['호림박물관', '갤러리 학고재', '별마당 도서관', '전쟁기념관', '국립중앙박물관']}
(2) PDF 파일에서 텍스트 추출하기 (Extracting text from a PDF file)
Python의 PyPDF2 모듈을 이용해서 PDF 파일로 부터 텍스트를 추출하기 위해, 먼저 터미널에서 "PyPDF2" 모듈을 설치합니다.
% python -m pip install PyPDF2
다음으로, PdfReader() 메소드를 사용해서 각 PDF 페이지로부터 텍스트를 추출해서 text_all 이라는 리스트에 차곡차곡 합쳐보도록 하겠습니다.
from PyPDF2 import PdfReader
## initiate PdfReader
reader = PdfReader(pdf_path)
print(len(reader.pages))
# 4
## extract text from a pdf file
text_all = []
for page in reader.pages:
text = page.extract_text()
text_all.append(text)
print(text_all)
# ['서울의관광명소1.서울의랜드마크2.서울의고궁3.서울의미술관과박물관',
# '서울의랜드마크•명동성당•익선동한옥거리•광화문광장야경•롯데월드타워•서울광장•청와대',
# '서울의고궁•경복궁•창덕궁•창경궁•덕수궁•서울한양도성•홍인지문•숭례문',
# '서울의미술관과박물관•호림박물관•갤러리학고재•별마당도서관•전쟁기념관•국립중앙박물관']
이번 포스팅이 많은 도움이 되었기를 바랍니다.
행복한 데이터 과학자 되세요! :-)

'Python 분석과 프로그래밍 > Python 데이터 전처리' 카테고리의 다른 글
| [Python] 리스트와 사전 자료형을 이용해서 문자열과 숫자 매핑하기 (0) | 2023.07.16 |
|---|---|
| [Python] Pandas 함수 적용: map(), applymap(), apply() (0) | 2023.06.06 |
| [Python Numpy] 반복자 enumerate() vs. 다차원 반복자np.ndenumerate() (0) | 2023.03.05 |
| [Python pandas] DataFrame.filter(): 특정 조건에 맞는 칼럼이나 행을 선택해 가져오기 (0) | 2023.01.17 |
| [Python pandas] pandas DataFrame의 데이터 유형별 칼럼 선택, 배제 (0) | 2023.01.03 |



