[Kubeflow] 파이프라인 개념과 구성요소 개요 (Conceptual overview of Kubeflow Pipelines)
Kubeflow 2021. 9. 26. 23:12지난번 포스팅에서는 K8s 의 툴인 kubectl을 설치하고 사용하는 방법 (https://rfriend.tistory.com/684) 을 소개하였습니다.
이번 포스팅에서는 Kubeflow를 이용했을 때 얻을 수 있는 큰 혜택 중의 하나인 파이프라인(Pipeline)의 구성요소에 대해서 코드 없이 개념적인 내용을 소개하겠습니다. (* Kubeflow.org 의 파이프라인 페이지 내용을 번역하였음.)
(1) Kubeflow Pipelines 의 개념적인 개요
(2) Kubeflow Pipelines 의 Component
(3) Kubeflow Pipelines 의 그래프 (Graph)
(4) Kubeflow Pipelines 의 실험 (Experiment)
(5) Kubeflow Pipelines 의 실행과 순환실행 (Run and Recurring Run)
(6) Kubeflow Pipelines 의 실행 트리거 (Run Trigger)
(7) Kubeflow Pipelines 의 단계(Step)
(8) Kubeflow Pipelines 의 산출물 Artifact (Output Artifact)
(1) Kubeflow Pipelines 의 개념적인 개요
파이프라인은 기계학습 워크플로우 (Machine Learning Workflow) 를 표현한 것으로서, 워크플로우의 모든 구성요소들을 포함하고, 이들 구성요소들이 서로 어떻게 관련되어 있는지를 그래프(Graph)의 형태로 표현합니다. 파이프라인을 실행하기 위해 필요한 파라미터의 입력값과, 각 구성요소(components)의 입력값과 출력값을 정의함으로써 파이프라인을 설정할 수 있습니다.
파이프라인을 실행시키면 시스템은 기계학습 워크플로우의 단계(steps)에 해당하는 만큼 한개 또는 여러개의 Kubernetes Pods 를 뜨웁니다. Pods는 Docker container를 시작하고, Container는 차례로 워크플로우 안의 프로그램을 실행시킵니다.
일단 파이프라인을 개발하고 나면, Kubeflow Pipelines UI 나 Kubeflow Pipelines SDK 를 이용해서 업로드할 수 있습니다.
Kubeflow Pipelines 플랫폼 구성은 아래와 같습니다.
- (a) 실험(experiments), 작업(jobs)과 실행(runs)을 관리하고 추적하는 사용자 인터페이스 (UI)
- (b) 다단계 기계학습 워크플로우를 스케줄링(scheduling multi-step ML workflows)하는 엔진
- (c) 파이프라인과 컴포넌트를 정의하고 조작하는 SDK(SW Development Kit)
- (d) SDK를 사용해서 시스템과 상호작용하는 노트북(notebooks)
Kubeflow Pipelines 의 목적은 다음과 같습니다.
- (a) End-to-End orchestration: 기계학습의 전체 파이프라인을 단순화하고 조정할 수 있게 함.
- (b) 쉬운 실험(easy experimentation): 수많은 아이디어와 기술을 시도하고 다양한 실험결과를 관리할 수 있게 함.
- (c) 쉬운 재사용(easy re-use): 매번 다시 구축할 필요 없이 기존의 컴포넌트와 파이프라인을 재사용해서 빠르게 end-to-end 솔루션을 생성할 수 있게 함.
(2) Kubeflow Pipelines 의 Component
Pipeline Component 는 기계학습 워크플로우에서 한 개의 단계를 실행하는 독립적이고 자기충족적인 코드 집합 (self-contained set of code)입니다. 가령, 데이터 전처리, 데이터 변환, 모델 훈련 등이 독립적인 워크플로우의 단계가 될 수 있습니다. Pipeline Component 는 함수(function)과 유사한데요, 이름, 파라미터, 반환값, (코드블록) 바디를 가지고 있습니다. 레고블록의 하나 하나의 조각블록을 생각하면 이해하기 쉬울거 같아요.
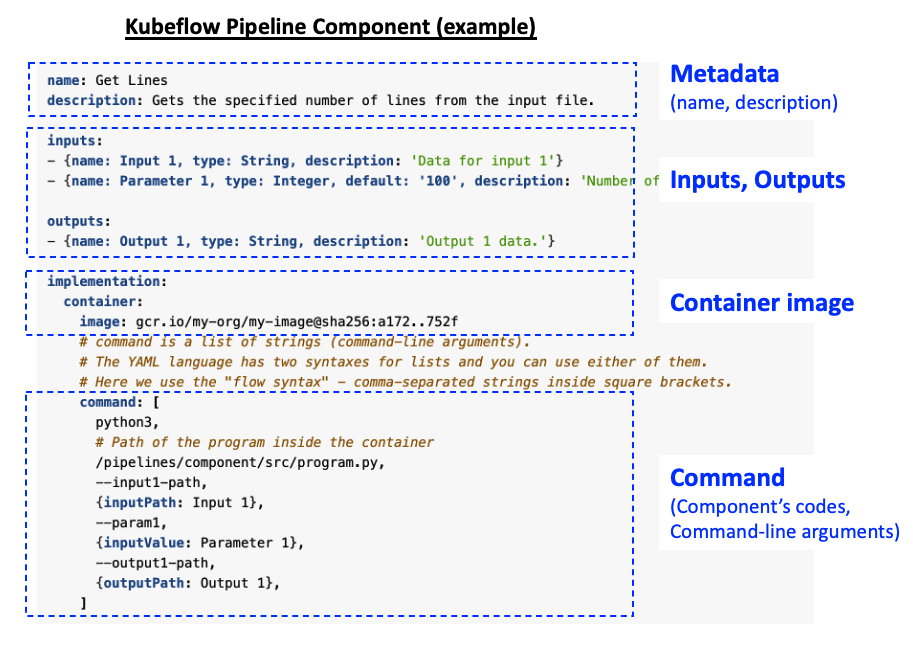
Component 세부 사항(component specifications)으로 아래의 것들을 정의합니다.
- (a) component 인터페이스: 인풋과 아웃풋
- (b) component 실행: 컨테이너 이미지, 실행 명령어
- (c) component 메타 데이터: 컴포넌트 이름, 설명
(3) Kubeflow Pipelines 의 그래프(Graph)
그래프(Graph)는 Pipeline의 실행을 Kubeflow Pipelines UI 에 노드(node)와 에지(edge)의 그래프 형태의 그림으로 표현한 것입니다. 그래프는 Pipeline이 실행되었거나 실행중인 단계(steps)를 보여주며, 화살표로 각 단계의 구성요소 간 부모/자식 관계 (parent/child relationships) 를 나타냅니다. 그래프는 파이프라인이 실행되기 시작하자마자 바로 볼 수 있습니다. 그래프 안의 각 노드는 파이프라인의 단계에 해당하며 각 단계에 맞추어서 이름이 부여됩니다.
[ Pipeline Graph 예시 ]
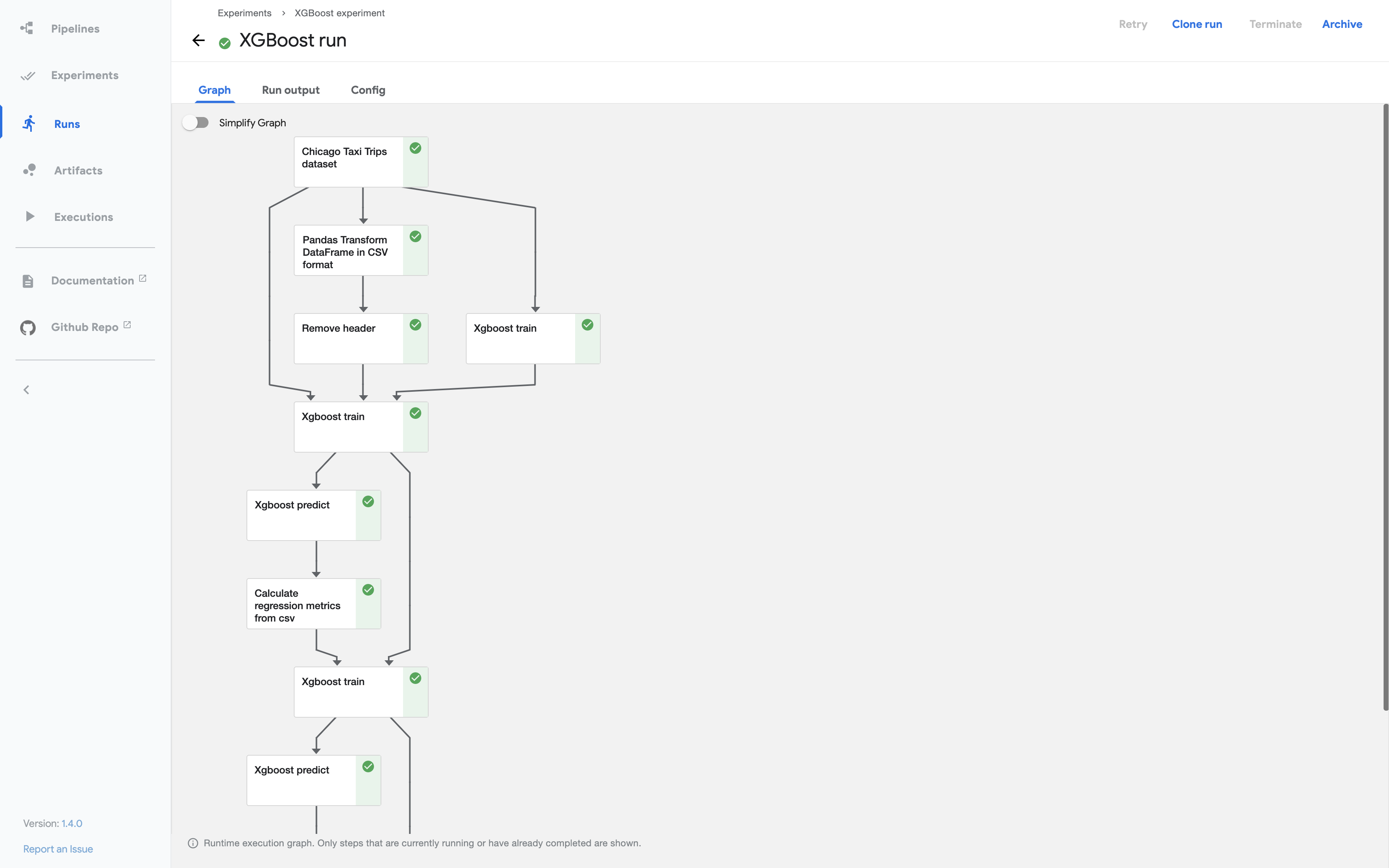
위의 그래프 예시화면에서 보면 각 노드의 상단 우측에 아이콘이 있는데요, 이 아이콘은 각 단계의 진행상태를 의미합니다. 진행상태에는 '실행 중 (running)', '실행 성공 (succeeded)', '실행 실패 (failed)', '건너뜀 (skipped)' 등이 있습니다. 만약 부모 노드에서 조건절이 있고 조건에 해당된다면 자식노드는 '건너뜀 (skipped)' 상태가 될 수 있습니다.
(4) Kubeflow Pipelines 의 실험 (Experiment)
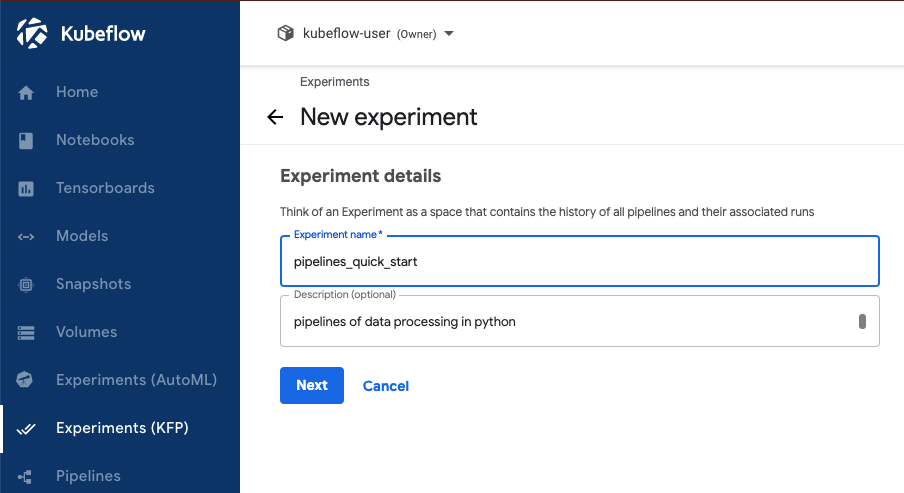
실험(Experiment) 메뉴는 Pipelines 에서 다른 종류의 설정들(different configurations)을 시도해볼 수 있는 작업공간입니다. 우리는 실험 화면에서 다양한 설정의 실험 실행을 논리적인 그룹들로 조직할 수 있습니다. 실험은 순환반복실행(recurring runs)과 같은 임의적인 실행도 포함할 수 있습니다.
[ Kubeflow Pipelines - Experiment UI]
(5) Kubeflow Pipelines 의 실행과 순환실행 (Run and Recurring Run)
실행(a run)은 파아프라인에서 한번 수행(a single execution)하는 것을 말합니다. 실행(runs)은 당신이 시도하는 모든 실험들의 불변하는 로그로 이루어지며, 재현이 가능하도록(reproducibility) 독립적이고 자기충족적(self-contained) 이도록 설계가 됩니다. 우리는 Kubeflow Pipeline UI 의 상세 페이지(details page)에서 실행의 진척도를 추적할 수 있으며, 수행시간 그래프와 산출물 artifacts, 그리고 실행의 각 단계별 로그도 볼 수 있습니다.
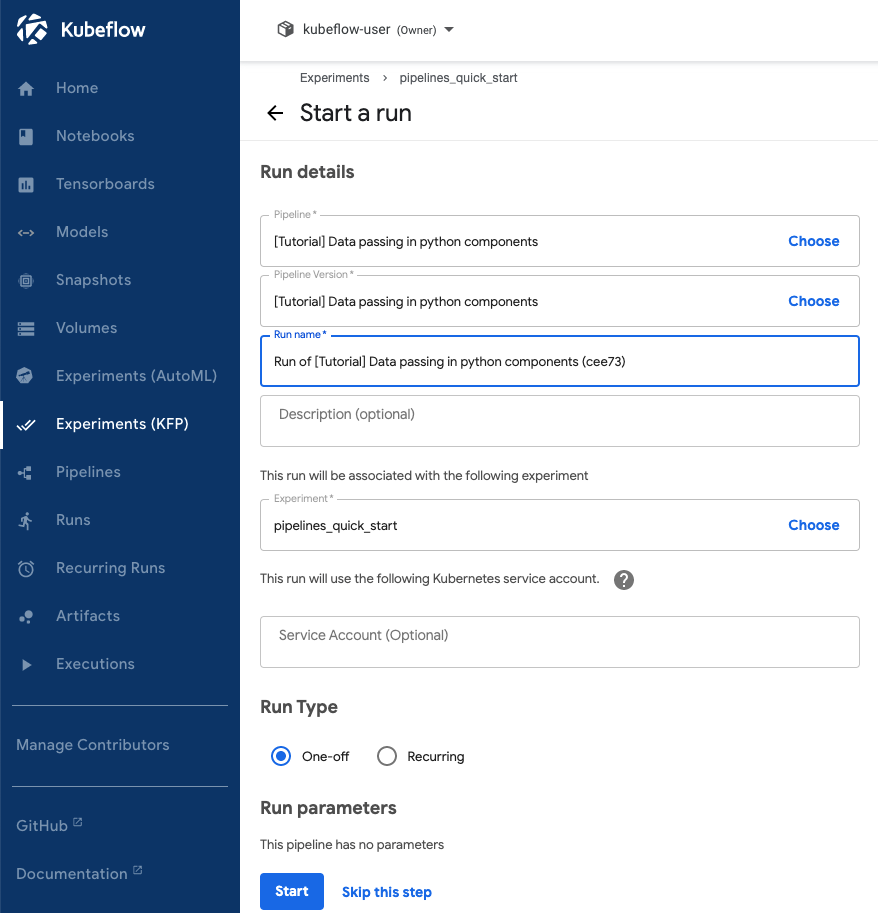
순환실행(recurring run), 또는 Kubeflow Pipelines backend APIs 안의 job, 은 파이프라인의 반복할 수 있는 실행(a repeatable run of a pipeline)을 말합니다. 순환실행을 위한 환경설정은 명시된 모든 파라미터값과 실행 트리거(run trigger) 를 가진 파이프라인의 복사를 포함합니다. 당신은 순환실행을 어느 실험 안에서나 시작할 수 있으며, 그것은 주기적으로 실행 환경설정의 새로운 복사를 시작할 것입니다. 당신은 Kubeflow Pipelines UI에서 순환실행의 활성화/비활성화를 선택할 수 있습니다. (위 Experiment UI의 하단에 있는 Run Type: One-off vs. Recurring). 당신은 또한 동시실행의 최대개수도 구체적으로 명시할 수 있으며, 병렬로 시작하는 실행의 숫자도 제한할 수 있습니다. 이런 기능들은 만약 파이프라인이 오랜 시간동안 수행이 될 것으로 예상되고 자주 실행이 된다면 유용하게 사용될 수 있습니다.
(6) Kubeflow Pipelines 의 실행 트리거 (Run Trigger)
실행 트리거(run trigger)는 시스템에게 언제 순환실행 환경설정(recurring rum configuration)이 새로운 실행을 생성해야 할지를 알려주는 표시(flag)입니다. 아래의 두가지 유형의 순환실행을 사용할 수 있습니다.
-. 주기적 (Periodic): 가령 매 2시간 또는 매 45분 간격마다 주기적으로 실행하는 것과 같이, 시간간격 기반의 실행 스케줄링(for an interval-based scheduling of runs)에 사용.
-. 특정 시기 (Cron): 명시적으로 실행 스케줄링의 '특정 시간 문구(cron semactics)'를 지정하고자 할 때 사용.
(7) Kubeflow Pipelines 의 단계(Step)
단계(step)는 파이프라인 안의 구성요소들 중의 하나의 실행(an execution of one of the components in the pipeline)을 의미합니다. 단계(step)와 구성요소(component)와의 관계는 인스턴스화(steps = component instances)의 하나로서, 실행(run)과 파이프라인(pipeline)의 관계와 상당히 유사합니다.
복잡한 파이프라인에서는 구성요소(components)는 순환문에서 여러번 수행할 수도 있으며, 또는 파이프라인 코드 안에서 if/else 조건절을 분석한 후에 조건부로 수행할 수도 있습니다.
(8) Kubeflow Pipelines 의 산출물 Artifact (Output Artifact)
산출물 artifact 는 파이프라인 구성요소에 의해서 생성되는 산출물로서, Kubeflow Pipelines UI 가 이를 이해하고 풍부한 시각화를 생성할 수 있습니다. 파이프라인 구성요소(pipeline components)에 산출물 artifact 를 포함시킴으로써 모델 성능평가, 실행을 위한 빠른 신속한 의사결정, 또는 다른 실행들 간의 비교를 하는데 유용하게 사용할 수 있습니다. Artifact 는 또한 파이프라인의 다양한 구성요소가 어떻게 작동하는지를 이해하는 것을 가능하게 해줍니다. Artifact 는 평범한 텍스트 뷰부터 풍부한 상호작용 시각화까지 다양한 형태를 띨 수 있습니다.
[ Reference ]
* Kubeflow Pipelines: https://www.kubeflow.org/docs/components/pipelines/overview/concepts/
이번 포스팅이 많은 도움이 되었기를 바랍니다.
행복한 데이터 과학자 되세요! :-)

'Kubeflow' 카테고리의 다른 글
| [Docker] 컨테이너, 도커 컨테이너, 도커 이미지 (Dontainer, Docker Container, Docker Image) (0) | 2022.03.20 |
|---|---|
| [Visual Studio Code] Kubernetes YAML 확장 팩 설치 및 YAML 언어 설정 (1) | 2021.10.11 |
| [Kubeflow] K8s 툴인 kubectl 설치하고 사용하기 (0) | 2021.09.13 |
| [Kubeflow] MiniKF 를 맥북에 설치하기 (Installing MiniKF, Mini-Kubuflow on laptop/desktop) (0) | 2021.08.17 |
| Kubeflow 는 무엇인가요? (What is Kubeflow?) (0) | 2021.08.12 |



